


Jina AI anuncia nuevos modelos en su familia de modelos reranker de última generación, ahora disponibles en AWS Sagemaker y Hugging Face: jina-reranker-v1-turbo-en y jina-reranker-v1-tiny-en. Estos modelos priorizan la velocidad y el tamaño mientras mantienen un alto rendimiento en los benchmarks estándar, ofreciendo un proceso de reranking más rápido y eficiente en memoria para entornos donde el tiempo de respuesta y el uso de recursos son críticos.




Reranker Turbo y Tiny están optimizados para tiempos de respuesta ultrarrápidos en aplicaciones de recuperación de información. Al igual que nuestros modelos de embedding, utilizan la arquitectura JinaBERT, una variante de la arquitectura BERT mejorada con una variante bidireccional simétrica de ALiBi. Esta arquitectura permite el soporte de secuencias de texto largas, con nuestros modelos aceptando hasta 8.192 tokens, ideal para el análisis profundo de documentos más grandes y consultas complejas que requieren una comprensión detallada del lenguaje.
Los modelos Turbo y Tiny se basan en los conocimientos adquiridos de Jina Reranker v1. El reranking puede ser un cuello de botella importante para las aplicaciones de recuperación de información. Las aplicaciones de búsqueda tradicionales son una tecnología muy madura cuyo rendimiento está bien comprendido. Los rerankers añaden mucha precisión a la recuperación basada en texto, pero los modelos de IA son grandes y pueden ser lentos y costosos de ejecutar.
Muchos usuarios preferirían un modelo más pequeño, más rápido y más económico, incluso si esto implica algún costo en precisión. Tener un único objetivo –reordenar los resultados de búsqueda– hace posible optimizar el modelo y ofrecer a los usuarios un rendimiento competitivo en modelos mucho más compactos. Al usar menos capas ocultas, aceleramos el procesamiento y reducimos el tamaño del modelo. Estos modelos cuestan menos de ejecutar, y la mayor velocidad los hace más útiles para aplicaciones que no pueden tolerar mucha latencia, mientras mantienen casi todo el rendimiento de los modelos más grandes.
En este artículo, te mostraremos la arquitectura de Reranker Turbo y Reranker Tiny, mediremos su rendimiento y te mostraremos cómo empezar a usarlos.
tagArquitectura Optimizada
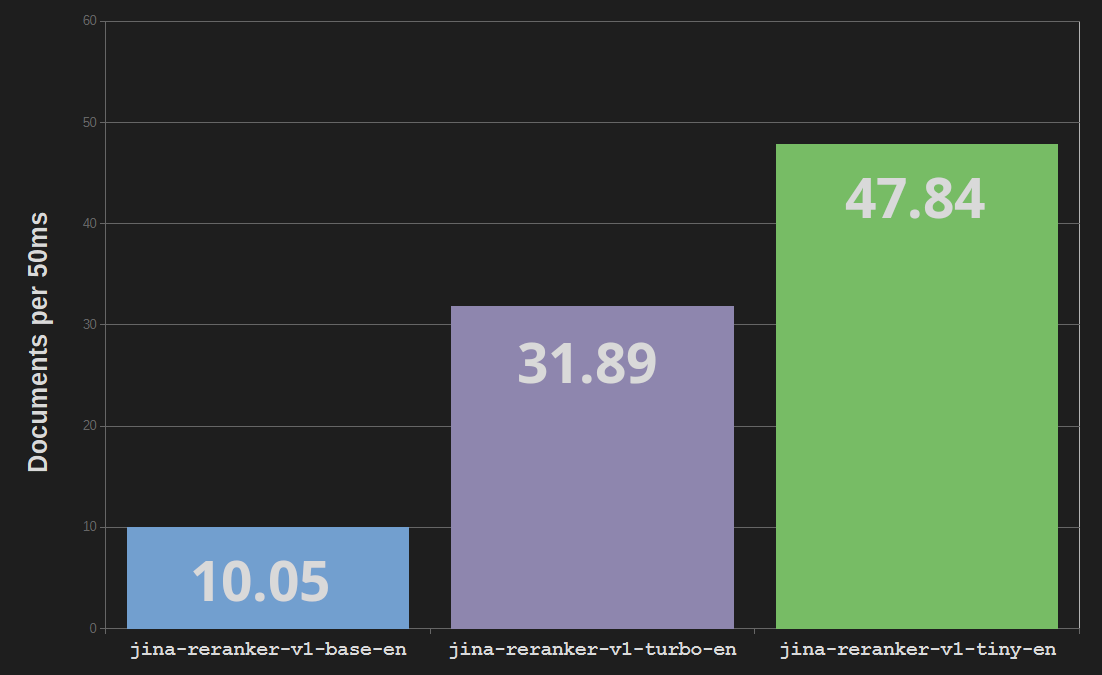
Jina Reranker Turbo (jina-reranker-v1-turbo-en) utiliza una arquitectura de seis capas, con un total de 37,8 millones de parámetros, en contraste con los 137 millones de parámetros y doce capas del modelo base reranker jina-reranker-v1-base-en. Esto representa una reducción del tamaño del modelo de tres cuartos y hasta una triplicación de la velocidad de procesamiento.
Reranker Tiny (jina-reranker-v1-tiny-en) utiliza cuatro capas con 33 millones de parámetros, proporcionando un procesamiento paralelo aún mayor y velocidades más rápidas –casi cinco veces más rápido que el modelo Reranker base– mientras ahorra un 13% de costos de memoria sobre el modelo Turbo.
tagDestilación del Conocimiento
Hemos entrenado Reranker Turbo y Tiny usando destilación del conocimiento. Esta es una técnica que utiliza un modelo de IA existente para entrenar otro que coincida con su comportamiento. En lugar de usar fuentes de datos externos, usamos un modelo existente para generar datos para el entrenamiento. Utilizamos el modelo base de Jina Reranker para clasificar colecciones de documentos y luego usamos esos resultados para entrenar tanto Turbo como Tiny. De esta manera, podemos incorporar muchos más datos en el proceso de entrenamiento porque no estamos limitados por los datos disponibles del mundo real.
Esto es un poco como un estudiante aprendiendo de un profesor: El modelo de alto rendimiento ya entrenado –el modelo Base de Jina Reranker– "enseña" a los modelos sin entrenar Jina Turbo y Jina Tiny generando nuevos datos de entrenamiento. Esta técnica se utiliza ampliamente para crear modelos pequeños a partir de grandes. En el mejor de los casos, la diferencia en el rendimiento de las tareas entre el modelo "profesor" y el "estudiante" puede ser muy pequeña.
tagEvaluación en BEIR
Los beneficios de la optimización y la destilación del conocimiento tienen un costo relativamente bajo en la calidad del rendimiento. En el benchmark BEIR para recuperación de información, jina-reranker-v1-turbo-en obtiene poco menos del 95% de la precisión de jina-reranker-v1-base-en, y jina-reranker-v1-tiny-en obtiene el 92,5% de la puntuación del modelo base.
Todos los modelos Jina Reranker son competitivos con otros modelos reranker populares, la mayoría de los cuales tienen tamaños mucho mayores.
| Model | BEIR Score (NDCC@10) | Parameters |
|---|---|---|
| Jina Reranker models | ||
| jina-reranker-v1-base-en | 52.45 | 137M |
| jina-reranker-v1-turbo-en | 49.60 | 38M |
| jina-reranker-v1-tiny-en | 48.54 | 33M |
| Other reranking models | ||
mxbai-rerank-base-v1 |
49.19 | 184M |
mxbai-rerank-xsmall-v1 |
48.80 | 71M |
ms-marco-MiniLM-L-6-v2 |
48.64 | 23M |
bge-reranker-base |
47.89 | 278M |
ms-marco-MiniLM-L-4-v2 |
47.81 | 19M |
NDCC@10: Puntuaciones calculadas usando Ganancia Acumulada Descontada Normalizada para los 10 primeros resultados.
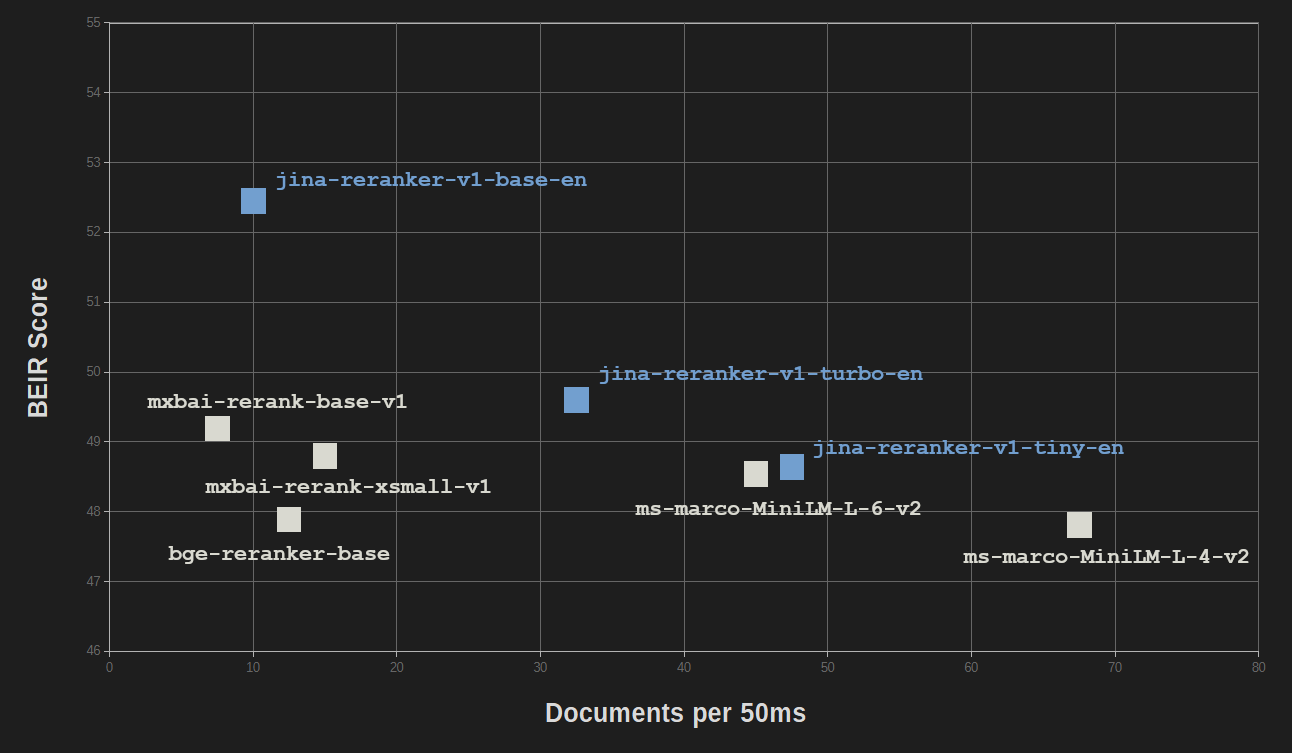
Solo MiniLM-L6 (ms-marco-MiniLM-L-6-v2) y MiniLM-L4 (ms-marco-MiniLM-L-4-v2) tienen tamaños y velocidades comparables, con jina-reranker-v1-turbo-en y jina-reranker-v1-tiny-en rindiendo de manera comparable o significativamente mejor.
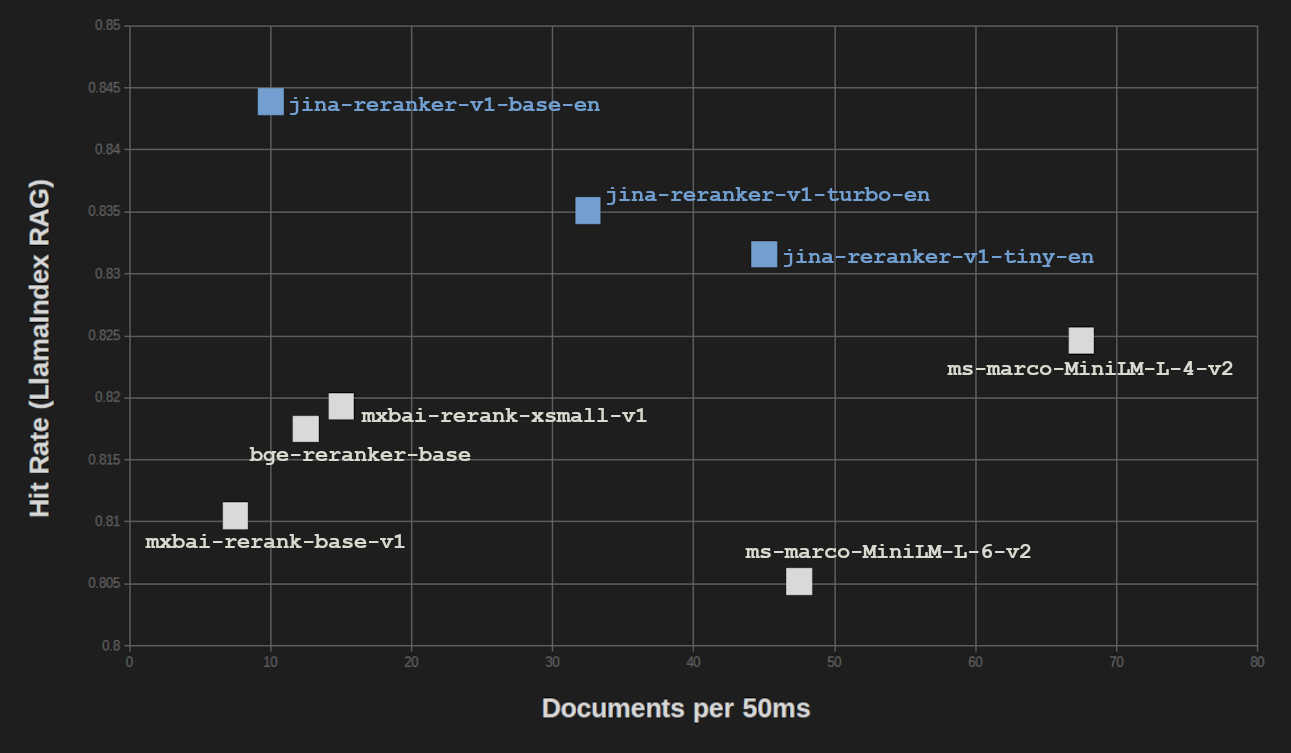
Obtenemos resultados similares en el Benchmark RAG de LlamaIndex. Probamos los tres Jina Rerankers en una configuración RAG utilizando tres modelos de embedding para búsqueda vectorial (jina-embeddings-v2-base-en, bge-base-en-v1.5, y Cohere-embed-english-v3.0) y promediamos las puntuaciones.
| Reranker Model | Avg. Hit Rate | Avg. MRR |
|---|---|---|
| Jina Reranker models | ||
| jina-reranker-v1-base-en | 0.8439 | 0.7006 |
| jina-reranker-v1-turbo-en | 0.8351 | 0.6498 |
| jina-reranker-v1-tiny-en | 0.8316 | 0.6761 |
| Other reranking models | ||
mxbai-rerank-base-v1 |
0.8105 | 0.6583 |
mxbai-rerank-xsmall-v1 |
0.8193 | 0.6673 |
ms-marco-MiniLM-L-6-v2 |
0.8052 | 0.6121 |
bge-reranker-base |
0.8175 | 0.6480 |
ms-marco-MiniLM-L-4-v2 |
0.8246 | 0.6354 |
MRR: Mean Reciprocal Rank
Para tareas de generación aumentada por recuperación (RAG), las pérdidas en la calidad de los resultados son incluso menores que en el benchmark de recuperación de información pura BEIR. Y cuando se compara el rendimiento RAG con la velocidad de procesamiento, vemos que solo ms-marco-MiniLM-L-4-v2 proporciona significativamente más rendimiento, con un costo significativo en la calidad de los resultados.
tagAhorro de Costos en AWS
Usar Reranker Turbo y Reranker Tiny proporciona grandes ahorros para usuarios de AWS y Azure que pagan por uso de memoria y tiempo de CPU. Aunque el grado de ahorro varía para diferentes casos de uso, la reducción aproximada del 75% en el uso de memoria se corresponde directamente con un 75% de ahorro para sistemas en la nube que cobran por memoria.
Además, el mayor rendimiento significa que puedes ejecutar más consultas en instancias AWS más económicas.
tagPrimeros Pasos
Los modelos Jina Reranker son fáciles de usar e integrar en tus aplicaciones y flujo de trabajo. Para empezar, puedes visitar la página de la API Reranker para ver cómo usar nuestro servicio y obtener 1 millón de tokens gratuitos para probarlo tú mismo.

Nuestros modelos también están disponibles en AWS SageMaker. Para más información, consulta nuestro tutorial sobre cómo configurar un sistema de generación aumentada por recuperación en AWS.

Los modelos Jina Reranker también están disponibles para descargar bajo la licencia Apache 2.0 desde Hugging Face:
