



En octubre de 2023, presentamos jina-embeddings-v2, la primera familia de modelos de embeddings de código abierto capaz de manejar entradas de hasta 8.192 tokens. Sobre esta base, este año lanzamos jina-embeddings-v3, ofreciendo el mismo amplio soporte de entrada con mejoras adicionales.

En esta publicación profundizaremos en los embeddings de contexto largo y responderemos algunas preguntas: ¿Cuándo es práctico consolidar un volumen tan grande de texto en un solo vector? ¿La segmentación mejora la recuperación y, si es así, ¿cómo? ¿Cómo podemos preservar el contexto de diferentes partes de un documento mientras segmentamos el texto?
Para responder estas preguntas, compararemos varios métodos para generar embeddings:
- Embedding de contexto largo (codificación de hasta 8.192 tokens en un documento) vs contexto corto (es decir, truncando a 192 tokens).
- Sin fragmentación vs. fragmentación simple vs. fragmentación tardía.
- Diferentes tamaños de fragmentos con fragmentación tanto simple como tardía.
tag¿Es Útil el Contexto Largo?
Con la capacidad de codificar hasta diez páginas de texto en un solo embedding, los modelos de embedding de contexto largo abren posibilidades para la representación de texto a gran escala. Sin embargo, ¿es realmente útil? Según mucha gente... no.




Fuentes: Cita de Nils Reimer en el podcast How AI Is Built, tweet de brainlag, comentario de egorfine en Hacker News, comentario de andy99 en Hacker News
Vamos a abordar todas estas preocupaciones con una investigación detallada de las capacidades de contexto largo, cuándo el contexto largo es útil y cuándo deberías (y no deberías) usarlo. Pero primero, escuchemos a estos escépticos y veamos algunos de los problemas que enfrentan los modelos de embedding de contexto largo.
tagProblemas con los Embeddings de Contexto Largo
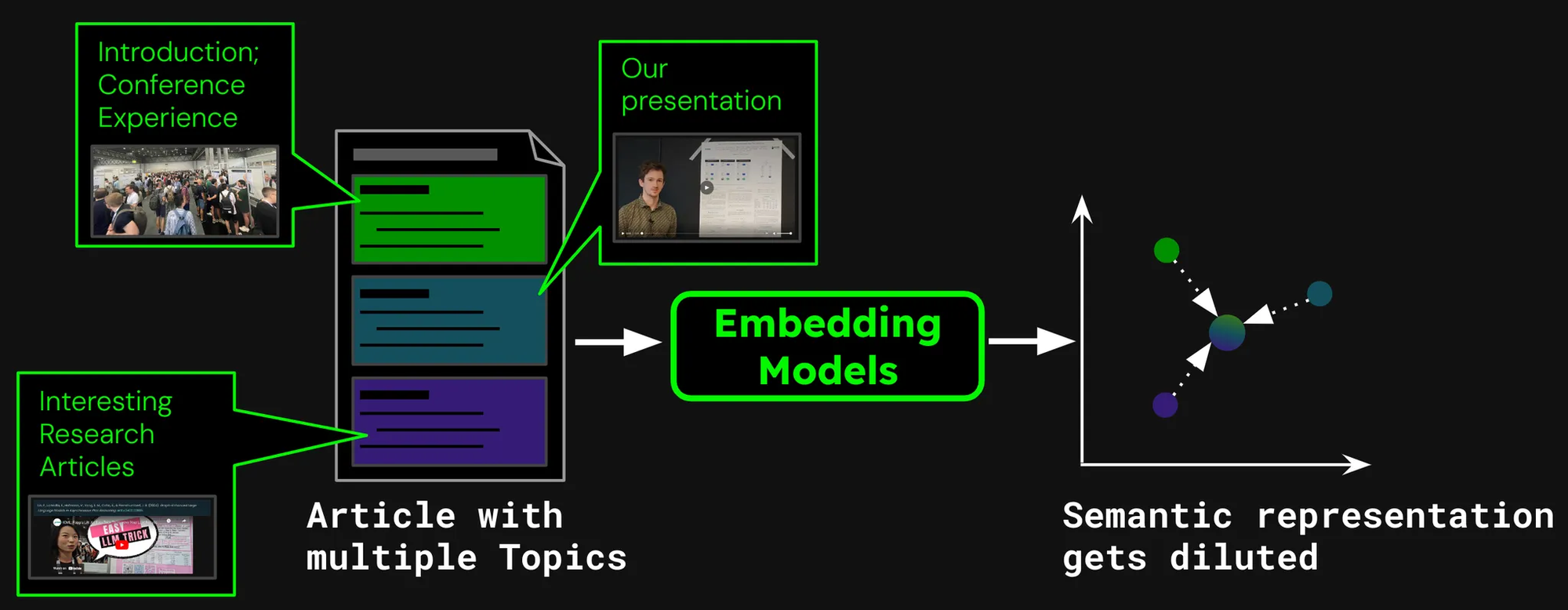
Imaginemos que estamos construyendo un sistema de búsqueda de documentos para artículos, como los de nuestro blog de Jina AI. A veces un solo artículo puede cubrir múltiples temas, como el informe sobre nuestra visita a la conferencia ICML 2024, que contiene:
- Una introducción, capturando información general sobre ICML (número de participantes, ubicación, alcance, etc).
- La presentación de nuestro trabajo (jina-clip-v1).
- Resúmenes de otros trabajos de investigación interesantes presentados en ICML.
Si creamos un solo embedding para este artículo, ese embedding representa una mezcla de tres temas dispares:
Esto lleva a varios problemas:
- Dilución de la Representación: Si bien todos los temas en un texto dado podrían estar relacionados, solo uno puede ser relevante para la consulta de búsqueda del usuario. Sin embargo, un solo embedding (en este caso, el del post completo) es solo un punto en el espacio vectorial. A medida que se agrega más texto a la entrada del modelo, el embedding se desplaza para capturar el tema general del artículo, haciéndolo menos efectivo en representar el contenido cubierto en párrafos específicos.
- Capacidad Limitada: Los modelos de embedding producen vectores de tamaño fijo, independientemente de la longitud de entrada. A medida que se agrega más contenido a la entrada, se vuelve más difícil para el modelo representar toda esta información en el vector. Piensa en ello como reducir una imagen a 16×16 píxeles — Si reduces una imagen de algo simple, como una manzana, aún puedes derivar significado de la imagen escalada. ¿Reducir un mapa callejero de Berlín? No tanto.
- Pérdida de Información: En algunos casos, incluso los modelos de embedding de contexto largo alcanzan sus límites; Muchos modelos admiten codificación de texto de hasta 8.192 tokens. Los documentos más largos necesitan ser truncados antes del embedding, lo que lleva a pérdida de información. Si la información relevante para el usuario se encuentra al final del documento, no será capturada por el embedding en absoluto.
- Podrías Necesitar Segmentación de Texto: Algunas aplicaciones requieren embeddings para segmentos específicos del texto pero no para todo el documento, como identificar el pasaje relevante en un texto.
tagContexto Largo vs. Truncamiento
Para ver si el contexto largo vale la pena, veamos el rendimiento de dos escenarios de recuperación:
- Codificación de documentos de hasta 8.192 tokens (aproximadamente 10 páginas de texto).
- Truncamiento de documentos a 192 tokens y codificación hasta ahí.
Compararemos resultados usandojina-embeddings-v3 con la métrica de recuperación nDCG@10. Probamos los siguientes conjuntos de datos:
| Dataset | Descripción | Ejemplo de Consulta | Ejemplo de Documento | Longitud Media del Documento (caracteres) |
|---|---|---|---|---|
| NFCorpus | Un conjunto de datos de recuperación médica de texto completo con 3,244 consultas y documentos principalmente de PubMed. | "Using Diet to Treat Asthma and Eczema" | "Statin Use and Breast Cancer Survival: A Nationwide Cohort Study from Finland Recent studies have suggested that [...]" | 326,753 |
| QMSum | Un conjunto de datos de resúmenes de reuniones basado en consultas que requiere resumir segmentos relevantes de reuniones. | "The professor was the one to raise the issue and suggested that a knowledge engineering trick [...]" | "Project Manager: Is that alright now ? {vocalsound} Okay . Sorry ? Okay , everybody all set to start the meeting ? [...]" | 37,445 |
| NarrativeQA | Conjunto de datos de preguntas y respuestas con historias largas y preguntas correspondientes sobre contenido específico. | "What kind of business Sophia owned in Paris?" | "The Project Gutenberg EBook of The Old Wives' Tale, by Arnold Bennett\n\nThis eBook is for the use of anyone anywhere [...]" | 53,336 |
| 2WikiMultihopQA | Un conjunto de datos de preguntas y respuestas multi-paso con hasta 5 pasos de razonamiento, diseñado con plantillas para evitar atajos. | "What is the award that the composer of song The Seeker (The Who Song) earned?" | "Passage 1:\nMargaret, Countess of Brienne\nMarguerite d'Enghien (born 1365 - d. after 1394), was the ruling suo jure [...]" | 30,854 |
| SummScreenFD | Un conjunto de datos de resúmenes de guiones con transcripciones y resúmenes de series de TV que requieren integración dispersa de la trama. | "Penny gets a new chair, which Sheldon enjoys until he finds out that she picked it up from [...]" | "[EXT. LAS VEGAS CITY (STOCK) - NIGHT]\n[EXT. ABERNATHY RESIDENCE - DRIVEWAY -- NIGHT]\n(The lamp post light over the [...]" | 1,613 |
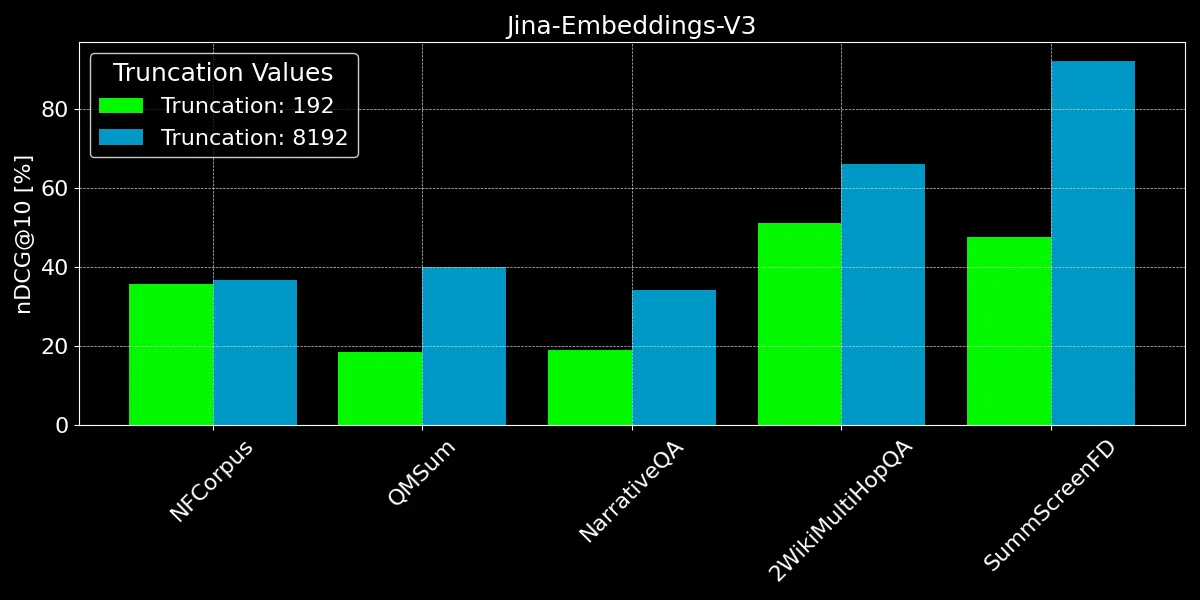
Como podemos ver, codificar más de 192 tokens puede dar mejoras notables de rendimiento:
Sin embargo, en algunos conjuntos de datos, vemos mejoras más grandes que en otros:
- Para NFCorpus, el truncamiento apenas hace diferencia. Esto se debe a que los títulos y resúmenes están justo al comienzo de los documentos, y estos son altamente relevantes para los términos típicos de búsqueda del usuario. Ya sea truncado o no, los datos más pertinentes permanecen dentro del límite de tokens.
- QMSum y NarrativeQA son consideradas tareas de "comprensión lectora", donde los usuarios típicamente buscan hechos específicos dentro de un texto. Estos hechos a menudo están dispersos en detalles a lo largo del documento y pueden caer fuera del límite truncado de 192 tokens. Por ejemplo, en el documento NarrativeQA Percival Keene, la pregunta "¿Quién es el matón que roba el almuerzo de Percival?" se responde mucho más allá de este límite. De manera similar, en 2WikiMultiHopQA, la información relevante está dispersa a lo largo de documentos completos, requiriendo que los modelos naveguen y sinteticen conocimiento de múltiples secciones para responder consultas efectivamente.
- SummScreenFD es una tarea dirigida a identificar el guion correspondiente a un resumen dado. Debido a que el resumen abarca información distribuida a lo largo del guion, codificar más texto mejora la precisión de hacer coincidir el resumen con el guion correcto.
tagSegmentando Texto para un Mejor Rendimiento de Recuperación
• Segmentación: Detectar señales de límite en un texto de entrada, por ejemplo, oraciones o un número fijo de tokens.
• Fragmentación ingenua: Dividir el texto en fragmentos basados en señales de segmentación, antes de codificarlo.
• Fragmentación tardía: Codificar el documento primero y luego segmentarlo (preservando el contexto entre fragmentos).
En lugar de incrustar un documento completo en un vector, podemos usar varios métodos para primero segmentar el documento asignando señales de límite:

Algunos métodos comunes incluyen:
- Segmentación por tamaño fijo: El documento se divide en segmentos de un número fijo de tokens, determinado por el tokenizador del modelo de embedding. Esto asegura que la tokenización de los segmentos corresponda a la tokenización del documento completo (segmentar por un número específico de caracteres podría llevar a una tokenización diferente).
- Segmentación por oración: El documento se segmenta en oraciones, y cada fragmento consiste en n número de oraciones.
- Segmentación por semántica: Cada segmento corresponde a múltiples oraciones y un modelo de embedding determina la similitud de oraciones consecutivas. Las oraciones con altas similitudes de embedding se asignan al mismo fragmento.
Por simplicidad, usamos segmentación de tamaño fijo en este artículo.
tagRecuperación de Documentos Usando Fragmentación Ingenua
Una vez que hemos realizado la segmentación de tamaño fijo, podemos fragmentar ingenuamente el documento de acuerdo con esos segmentos:
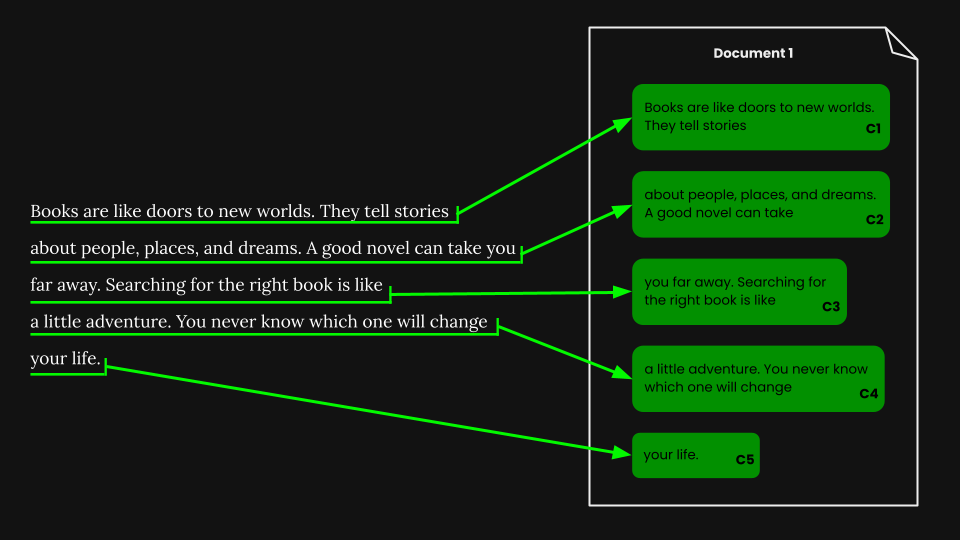
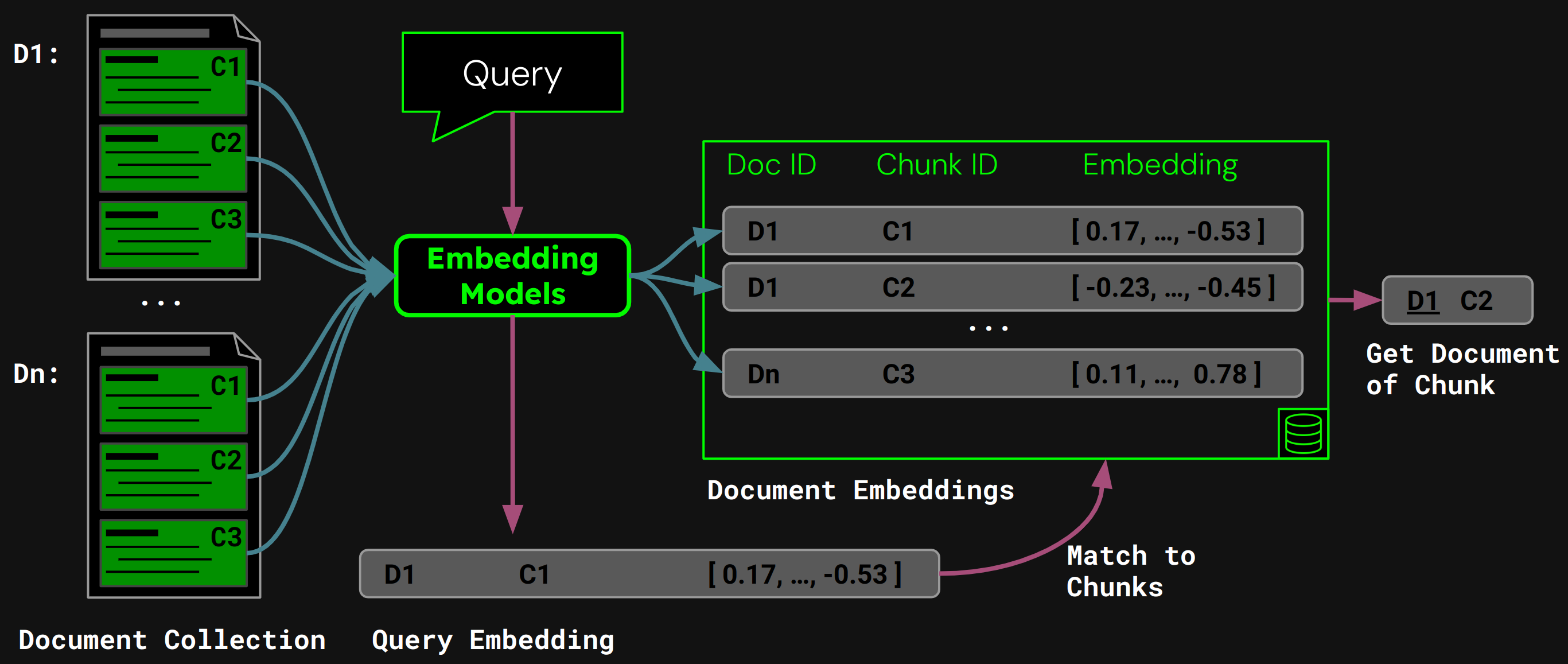
Usando jina-embeddings-v3, codificamos cada fragmento en un embedding que captura con precisión su semántica, luego almacenamos esos embeddings en una base de datos vectorial.
En tiempo de ejecución, el modelo codifica la consulta del usuario en un vector de consulta. Comparamos esto contra nuestra base de datos vectorial de embeddings de fragmentos para encontrar el fragmento con la mayor similitud del coseno, y luego devolvemos el documento correspondiente al usuario:
tagProblemas con la Segmentación Ingenua

Si bien la segmentación ingenua aborda algunas de las limitaciones de los modelos de embedding de contexto largo, también tiene sus desventajas:
- Pérdida de la Visión General: En cuanto a la recuperación de documentos, múltiples embeddings de fragmentos más pequeños pueden fallar en capturar el tema general del documento. Es como no ver el bosque por los árboles.
- Problema de Contexto Faltante: Los fragmentos no pueden interpretarse con precisión ya que falta información de contexto, como se ilustra en la Figura 6.
- Eficiencia: Más fragmentos requieren más almacenamiento y aumentan el tiempo de recuperación.
tagLa Segmentación Tardía Resuelve el Problema del Contexto
La segmentación tardía funciona en dos pasos principales:
- Primero, utiliza las capacidades de contexto largo del modelo para codificar el documento completo en embeddings de tokens. Esto preserva el contexto completo del documento.
- Luego, crea embeddings de fragmentos aplicando mean pooling a secuencias específicas de embeddings de tokens, correspondientes a las señales de límites identificadas durante la segmentación.
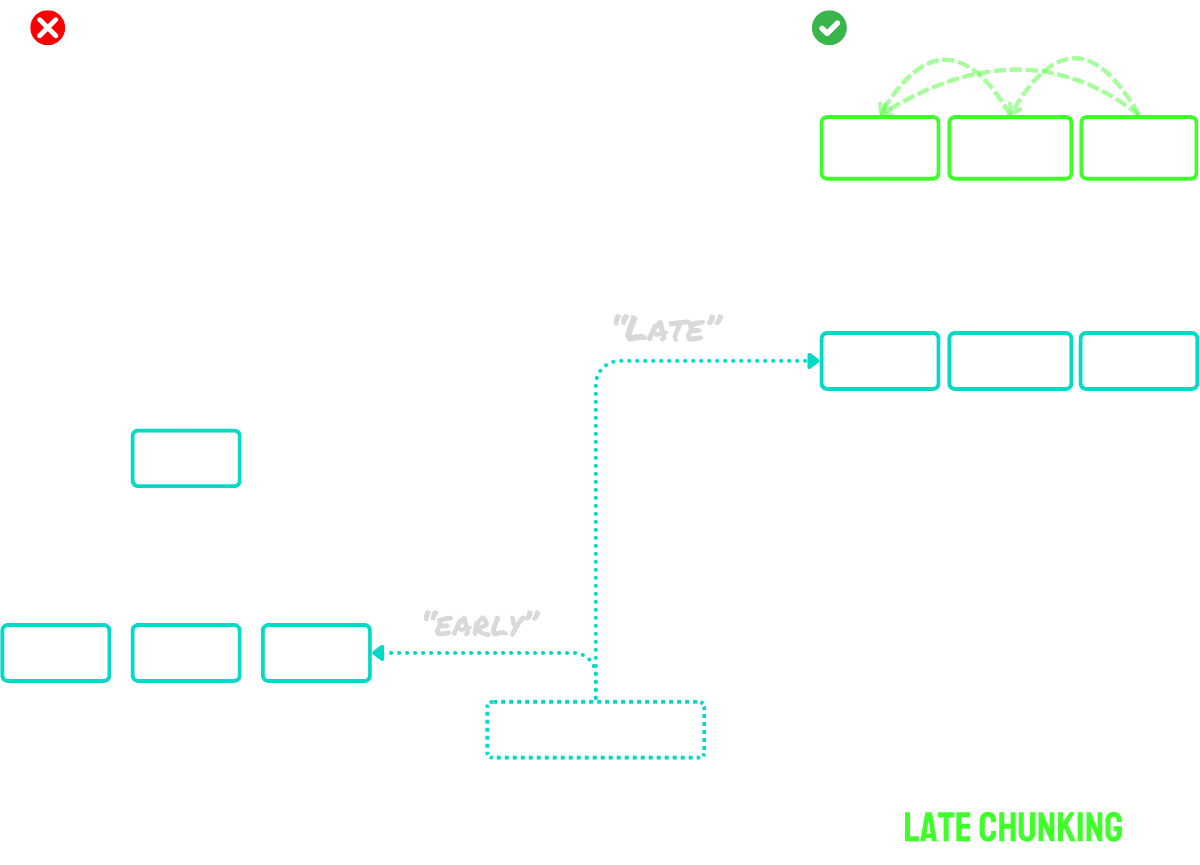
La ventaja clave de este enfoque es que los embeddings de tokens están contextualizados - lo que significa que naturalmente capturan referencias y relaciones con otras partes del documento. Dado que el proceso de embedding ocurre antes de la segmentación, cada fragmento mantiene la conciencia del contexto más amplio del documento, resolviendo el problema del contexto faltante que afecta a los enfoques de segmentación ingenua.
Para documentos que exceden el tamaño máximo de entrada del modelo, podemos usar "segmentación tardía larga":
- Primero, dividimos el documento en "macro-fragmentos" superpuestos. Cada macro-fragmento tiene un tamaño que cabe dentro de la longitud máxima de contexto del modelo (por ejemplo, 8.192 tokens).
- El modelo procesa estos macro-fragmentos para crear embeddings de tokens.
- Una vez que tenemos los embeddings de tokens, procedemos con la segmentación tardía estándar - aplicando mean pooling para crear los embeddings finales de los fragmentos.
Este enfoque nos permite manejar documentos de cualquier longitud mientras se preservan los beneficios de la segmentación tardía. Piensa en ello como un proceso de dos etapas: primero hacer el documento digerible para el modelo, luego aplicar el procedimiento regular de segmentación tardía.
En resumen:
- Segmentación ingenua: Segmentar el documento en fragmentos pequeños, luego codificar cada fragmento por separado.
- Segmentación tardía: Codificar el documento completo de una vez para crear embeddings de tokens, luego crear embeddings de fragmentos mediante pooling de los embeddings de tokens basados en los límites de segmentos.
- Segmentación tardía larga: Dividir documentos grandes en macro-fragmentos superpuestos que se ajusten a la ventana de contexto del modelo, codificarlos para obtener embeddings de tokens, luego aplicar la segmentación tardía normalmente.
Para una descripción más extensa de la idea, consulta nuestro paper o los posts del blog mencionados anteriormente.
tag¿Segmentar o No Segmentar?
Ya hemos visto que el embedding de contexto largo generalmente supera a los embeddings de texto más cortos, y hemos dado una visión general de las estrategias de segmentación ingenua y tardía. La pregunta ahora es: ¿Es la segmentación mejor que el embedding de contexto largo?
Para realizar una comparación justa, truncamos los valores de texto a la longitud máxima de secuencia del modelo (8.192 tokens) antes de comenzar a segmentarlos. Usamos segmentación de tamaño fijo con 64 tokens por segmento (tanto para segmentación ingenua como para segmentación tardía). Comparemos tres escenarios:
- Sin segmentación: Codificamos cada texto en un solo embedding. Esto lleva a los mismos puntajes que el experimento anterior (ver Figura 2), pero los incluimos aquí para compararlos mejor.
- Segmentación ingenua: Segmentamos los textos, luego aplicamos segmentación ingenua basada en las señales de límites.
- Segmentación tardía: Segmentamos los textos, luego usamos segmentación tardía para determinar los embeddings.
Tanto para la segmentación tardía como para la segmentación ingenua, usamos recuperación de fragmentos para determinar el documento relevante (como se muestra en la Figura 5, anteriormente en este post).
Los resultados no muestran un claro ganador:
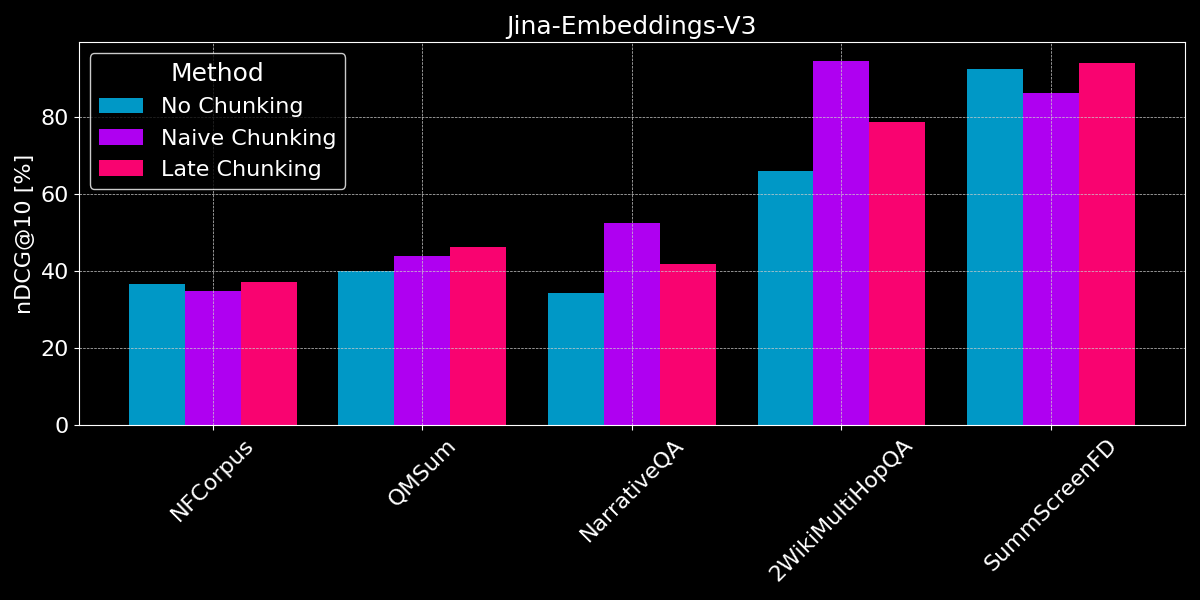
- Para la recuperación de hechos, la segmentación ingenua funciona mejor: Para los conjuntos de datos QMSum, NarrativeQA y 2WikiMultiHopQA, el modelo tiene que identificar pasajes relevantes en el documento. Aquí, la segmentación ingenua es claramente mejor que codificar todo en un solo embedding, ya que probablemente solo unos pocos fragmentos incluyen información relevante, y dichos fragmentos la capturan mucho mejor que un solo embedding de todo el documento.
- El chunking tardío funciona mejor con documentos coherentes y contexto relevante: Para documentos que cubren un tema coherente donde los usuarios buscan temas generales en lugar de hechos específicos (como en NFCorpus), el chunking tardío supera ligeramente al no chunking, ya que equilibra el contexto general del documento con el detalle local. Sin embargo, mientras que el chunking tardío generalmente funciona mejor que el chunking ingenuo al preservar el contexto, esta ventaja puede convertirse en una desventaja cuando se buscan hechos aislados dentro de documentos que contienen información mayormente irrelevante - como se ve en las regresiones de rendimiento para NarrativeQA y 2WikiMultiHopQA, donde el contexto adicional se vuelve más distractor que útil.
tag¿El Tamaño del Chunk Hace la Diferencia?
La efectividad de los métodos de chunking realmente depende del dataset, destacando cómo la estructura del contenido juega un papel crucial:
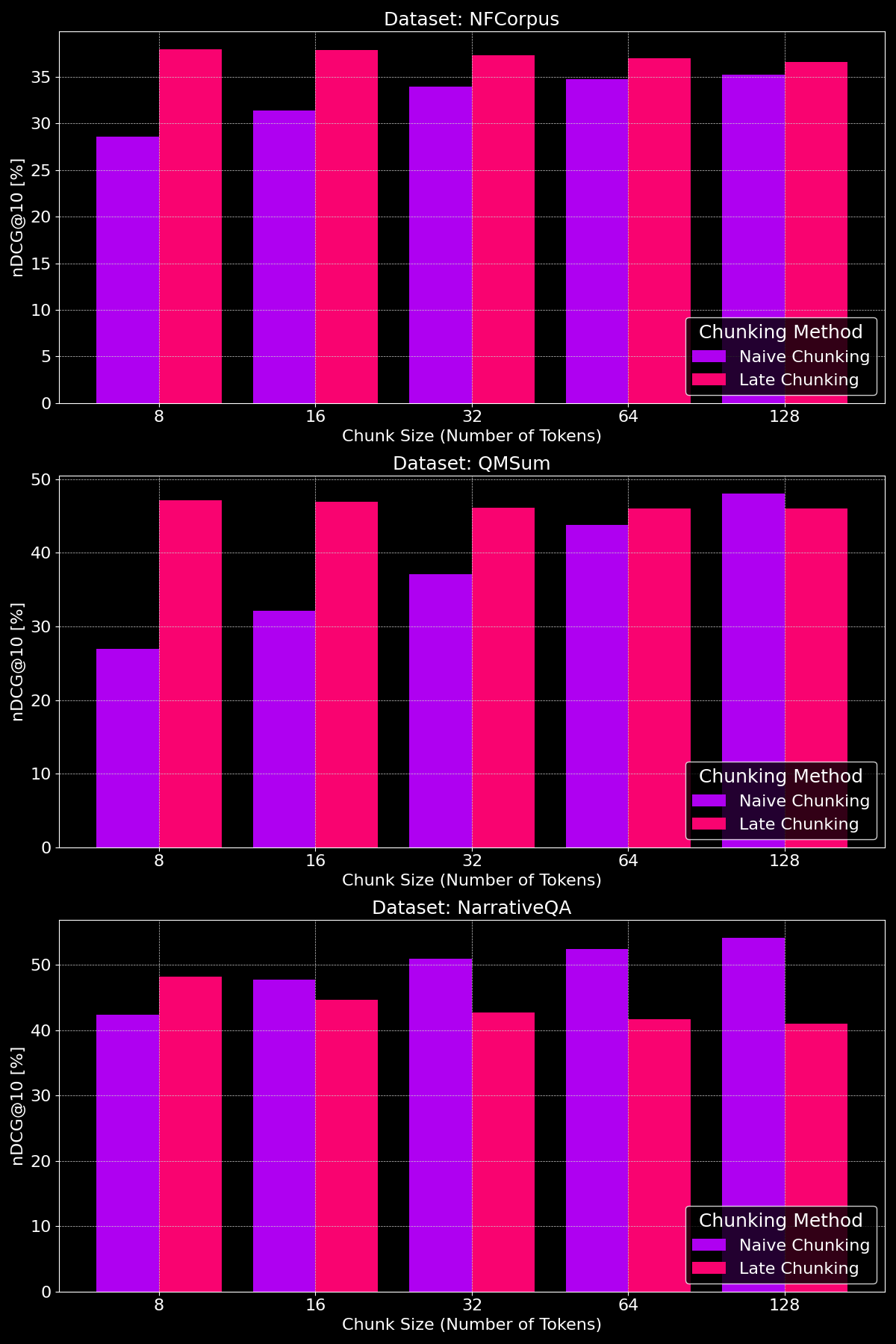
Como podemos ver, el chunking tardío generalmente supera al chunking ingenuo en tamaños de chunk más pequeños, ya que los chunks ingenuos pequeños son demasiado reducidos para contener mucho contexto, mientras que los chunks tardíos pequeños retienen el contexto del documento completo, haciéndolos más significativos semánticamente. La excepción a esto es el dataset NarrativeQA donde hay simplemente tanto contexto irrelevante que el chunking tardío se queda atrás. Con tamaños de chunk más grandes, el chunking ingenuo muestra una mejora notable (ocasionalmente superando al chunking tardío) debido al mayor contexto, mientras que el rendimiento del chunking tardío disminuye gradualmente.
tagConclusiones: ¿Cuándo Usar Qué?
En esta publicación, hemos examinado diferentes tipos de tareas de recuperación de documentos para entender mejor cuándo usar la segmentación y cuándo ayuda el chunking tardío. Entonces, ¿qué hemos aprendido?
tag¿Cuándo Debería Usar Embedding de Contexto Largo?
En general, no perjudica la precisión de recuperación incluir tanto texto de tus documentos como puedas en la entrada de tu modelo de embedding. Sin embargo, los modelos de embedding de contexto largo a menudo se enfocan en el inicio de los documentos, ya que contienen contenido como títulos e introducción que son más importantes para juzgar la relevancia, pero los modelos pueden perder contenido en la mitad del documento.
tag¿Cuándo Debería Usar Chunking Ingenuo?
Cuando los documentos cubren múltiples aspectos, o las consultas de usuarios apuntan a información específica dentro de un documento, el chunking generalmente mejora el rendimiento de recuperación.
Finalmente, las decisiones de segmentación dependen de factores como la necesidad de mostrar texto parcial a los usuarios (por ejemplo, como Google presenta los pasajes relevantes en las vistas previas de los resultados de búsqueda), lo que hace que la segmentación sea esencial, o las limitaciones de cómputo y memoria, donde la segmentación puede ser menos favorable debido al incremento en la sobrecarga de recuperación y uso de recursos.
tag¿Cuándo Debería Usar Chunking Tardío?
Al codificar el documento completo antes de crear chunks, el chunking tardío resuelve el problema de que los segmentos de texto pierdan su significado debido a la falta de contexto. Esto funciona particularmente bien con documentos coherentes, donde cada parte se relaciona con el todo. Nuestros experimentos muestran que el chunking tardío es especialmente efectivo cuando se divide el texto en chunks más pequeños, como se demuestra en nuestro paper. Sin embargo, hay una advertencia: si partes del documento no están relacionadas entre sí, incluir este contexto más amplio puede realmente empeorar el rendimiento de recuperación, ya que agrega ruido a los embeddings.
tagConclusión
La elección entre embedding de contexto largo, chunking ingenuo y chunking tardío depende de los requisitos específicos de tu tarea de recuperación. Los embeddings de contexto largo son valiosos para documentos coherentes con consultas generales, mientras que el chunking sobresale en casos donde los usuarios buscan hechos o información específica dentro de un documento. El chunking tardío mejora aún más la recuperación al mantener la coherencia contextual dentro de segmentos más pequeños. En última instancia, entender tus datos y objetivos de recuperación guiará el enfoque óptimo, equilibrando precisión, eficiencia y relevancia contextual.
Si estás explorando estas estrategias, considera probar jina-embeddings-v3—sus capacidades avanzadas de contexto largo, chunking tardío y flexibilidad lo convierten en una excelente opción para diversos escenarios de recuperación.

