



Recientemente, Christoph Schuhmann, fundador de LAION AI compartió una observación interesante sobre los modelos de embeddings de texto:
Cuando las palabras dentro de una oración se mezclan aleatoriamente, la similitud coseno entre sus embeddings de texto permanece sorprendentemente alta en comparación con la oración original.
Por ejemplo, veamos dos oraciones: Berlin is the capital of Germany y the Germany Berlin is capital of. Aunque la segunda oración no tiene sentido, los modelos de embeddings de texto realmente no pueden distinguirlas. Usando jina-embeddings-v3, estas dos oraciones tienen una puntuación de similitud coseno de 0.9295.
El orden de las palabras no es lo único para lo que los embeddings parecen no ser muy sensibles. Las transformaciones gramaticales pueden cambiar dramáticamente el significado de una oración pero tienen poco impacto en la distancia de embedding. Por ejemplo, She ate dinner before watching the movie y She watched the movie before eating dinner tienen una similitud coseno de 0.9833, a pesar de tener el orden opuesto de acciones.
La negación también es notoriamente difícil de codificar consistentemente sin entrenamiento especial — This is a useful model y This is not a useful model se ven prácticamente igual en el espacio de embeddings. A menudo, reemplazar las palabras en un texto con otras de la misma clase, como cambiar "hoy" por "ayer", o alterar el tiempo verbal, no cambia los embeddings tanto como uno pensaría que debería.
Esto tiene serias implicaciones. Consideremos dos consultas de búsqueda: Flight from Berlin to Amsterdam y Flight from Amsterdam to Berlin. Tienen embeddings casi idénticos, con jina-embeddings-v3 asignándoles una similitud coseno de 0.9884. Para una aplicación del mundo real como búsqueda de viajes o logística, esta deficiencia es fatal.
En este artículo, analizamos los desafíos que enfrentan los modelos de embeddings, examinando sus persistentes dificultades con el orden y la elección de palabras. Analizamos los principales modos de fallo en categorías lingüísticas —incluyendo contextos direccionales, temporales, causales, comparativos y de negación— mientras exploramos estrategias para mejorar el rendimiento del modelo.
tag¿Por qué las oraciones mezcladas tienen puntuaciones coseno sorprendentemente cercanas?
Al principio, pensamos que esto podría deberse a cómo el modelo combina los significados de las palabras - crea un embedding para cada palabra (6-7 palabras en cada una de nuestras oraciones de ejemplo anteriores) y luego promedia estos embeddings juntos con mean pooling. Esto significa que hay muy poca información sobre el orden de las palabras disponible para el embedding final. Un promedio es el mismo sin importar el orden de los valores.
Sin embargo, incluso los modelos que usan CLS pooling (que mira una primera palabra especial para entender toda la oración y debería ser más sensible al orden de las palabras) tienen el mismo problema. Por ejemplo, bge-1.5-base-en todavía da una puntuación de similitud coseno de 0.9304 para las oraciones Berlin is the capital of Germany y the Germany Berlin is capital of.
Esto señala una limitación en cómo se entrenan los modelos de embeddings. Mientras que los modelos de lenguaje inicialmente aprenden la estructura de la oración durante el pre-entrenamiento, parecen perder algo de esta comprensión durante el entrenamiento contrastivo — el proceso que usamos para crear modelos de embeddings.
tag¿Cómo impactan la longitud del texto y el orden de las palabras en la similitud de embeddings?
¿Por qué los modelos tienen problemas con el orden de las palabras en primer lugar? Lo primero que viene a la mente es la longitud (en tokens) del texto. Cuando el texto se envía a la función de codificación, el modelo primero genera una lista de embeddings de tokens (es decir, cada palabra tokenizada tiene un vector dedicado que representa su significado), luego los promedia.
Para ver cómo la longitud del texto y el orden de las palabras impactan la similitud de embeddings, generamos un conjunto de datos de 180 oraciones sintéticas de diferentes longitudes, como 3, 5, 10, 15, 20 y 30 tokens. También mezclamos aleatoriamente los tokens para formar una variación de cada oración:

Aquí hay algunos ejemplos:
| Length (tokens) | Original sentence | Shuffled sentence |
|---|---|---|
| 3 | The cat sleeps | cat The sleeps |
| 5 | He drives his car carefully | drives car his carefully He |
| 15 | The talented musicians performed beautiful classical music at the grand concert hall yesterday | in talented now grand classical yesterday The performed musicians at hall concert the music |
| 30 | The passionate group of educational experts collaboratively designed and implemented innovative teaching methodologies to improve learning outcomes in diverse classroom environments worldwide | group teaching through implemented collaboratively outcomes of methodologies across worldwide diverse with passionate and in experts educational classroom for environments now by learning to at improve from innovative The designed |
Codificaremos el conjunto de datos usando nuestro propio modelo jina-embeddings-v3 y el modelo de código abierto bge-base-en-v1.5, luego calcularemos la similitud coseno entre la oración original y la mezclada:
| Length (tokens) | Mean cosine similarity | Standard deviation in cosine similarity |
|---|---|---|
| 3 | 0.947 | 0.053 |
| 5 | 0.909 | 0.052 |
| 10 | 0.924 | 0.031 |
| 15 | 0.918 | 0.019 |
| 20 | 0.899 | 0.021 |
| 30 | 0.874 | 0.025 |
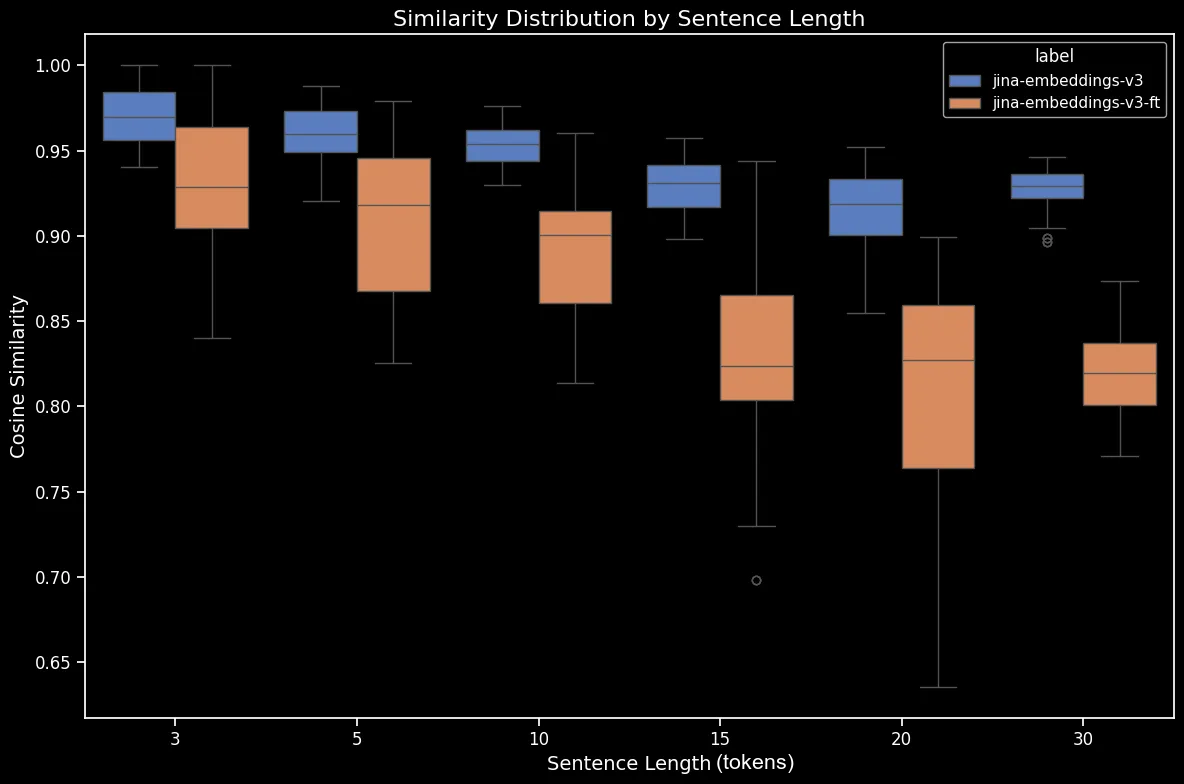
Ahora podemos generar un diagrama de caja, que hace más clara la tendencia en la similitud coseno:
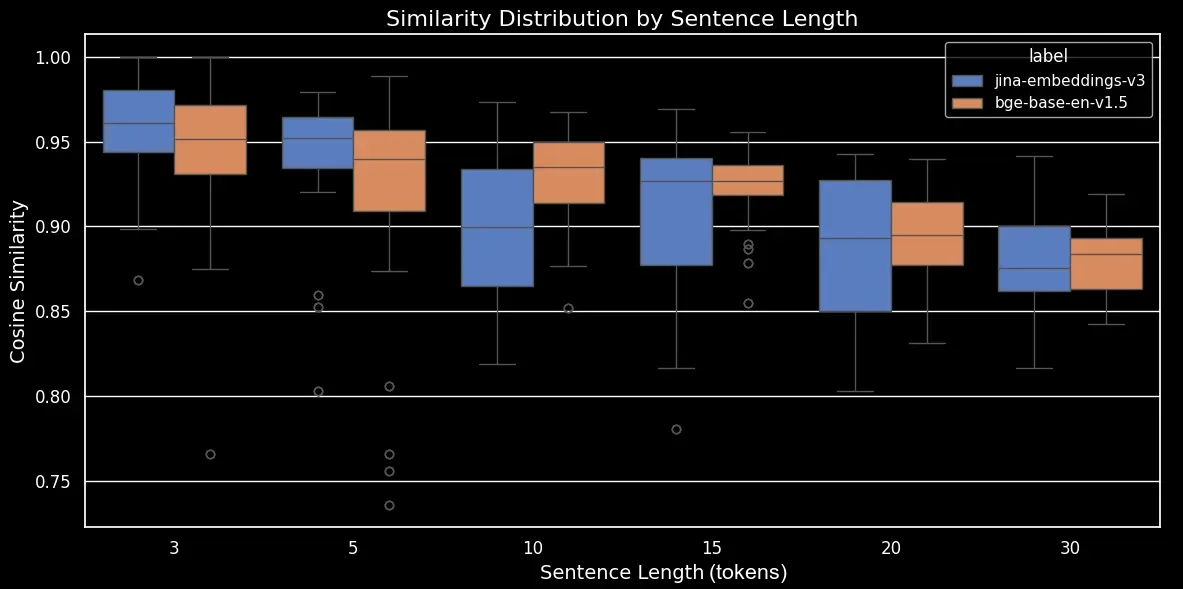
bge-base-en-1.5 (sin ajuste fino)Como podemos ver, hay una clara relación lineal en la similitud coseno promedio de los embeddings. Cuanto más largo es el texto, menor es la puntuación promedio de similitud coseno entre las oraciones originales y las mezcladas aleatoriamente. Esto probablemente ocurre debido al "desplazamiento de palabras", es decir, qué tan lejos se han movido las palabras de sus posiciones originales después de la mezcla aleatoria. En un texto más corto, simplemente hay menos "espacios" a los que un token puede ser mezclado por lo que no puede moverse tan lejos, mientras que un texto más largo tiene un mayor número de permutaciones potenciales y las palabras pueden moverse una distancia mayor.
Como se muestra en la figura siguiente (Similitud del Coseno vs Desplazamiento Promedio de Palabras), cuanto más largo es el texto, mayor es el desplazamiento de palabras:
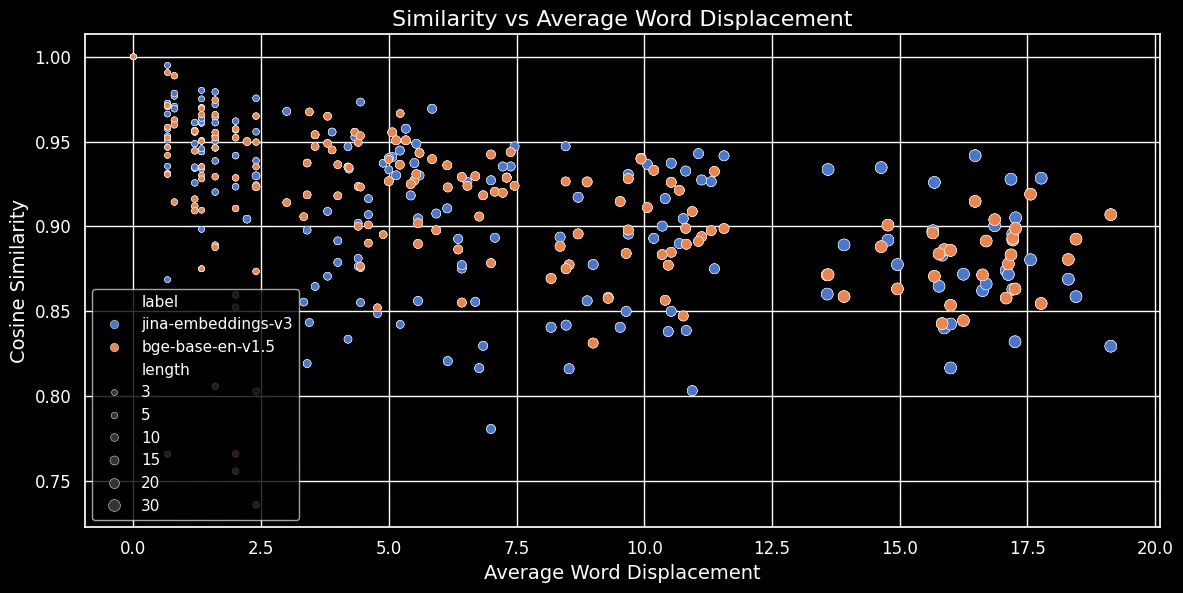
Las incrustaciones de tokens dependen del contexto local, es decir, de las palabras más cercanas a ellos. En un texto corto, reorganizar las palabras no puede cambiar mucho ese contexto. Sin embargo, en un texto más largo, una palabra puede moverse muy lejos de su contexto original y eso puede cambiar significativamente su incrustación de token. Como resultado, mezclar las palabras en un texto más largo produce una incrustación más distante que en uno más corto. La figura anterior muestra que tanto para jina-embeddings-v3, usando agrupación media, como para bge-base-en-v1.5, usando agrupación CLS, se mantiene la misma relación: mezclar textos más largos y desplazar palabras más lejos resulta en puntuaciones de similitud más pequeñas.
tag¿Los Modelos Más Grandes Resuelven el Problema?
Normalmente, cuando nos enfrentamos a este tipo de problema, una táctica común es simplemente usar un modelo más grande. Pero, ¿puede un modelo de incrustación de texto más grande realmente capturar mejor la información del orden de las palabras? Según la ley de escalado de los modelos de incrustación de texto (referenciada en nuestra publicación de lanzamiento de jina-embeddings-v3), los modelos más grandes generalmente proporcionan un mejor rendimiento:
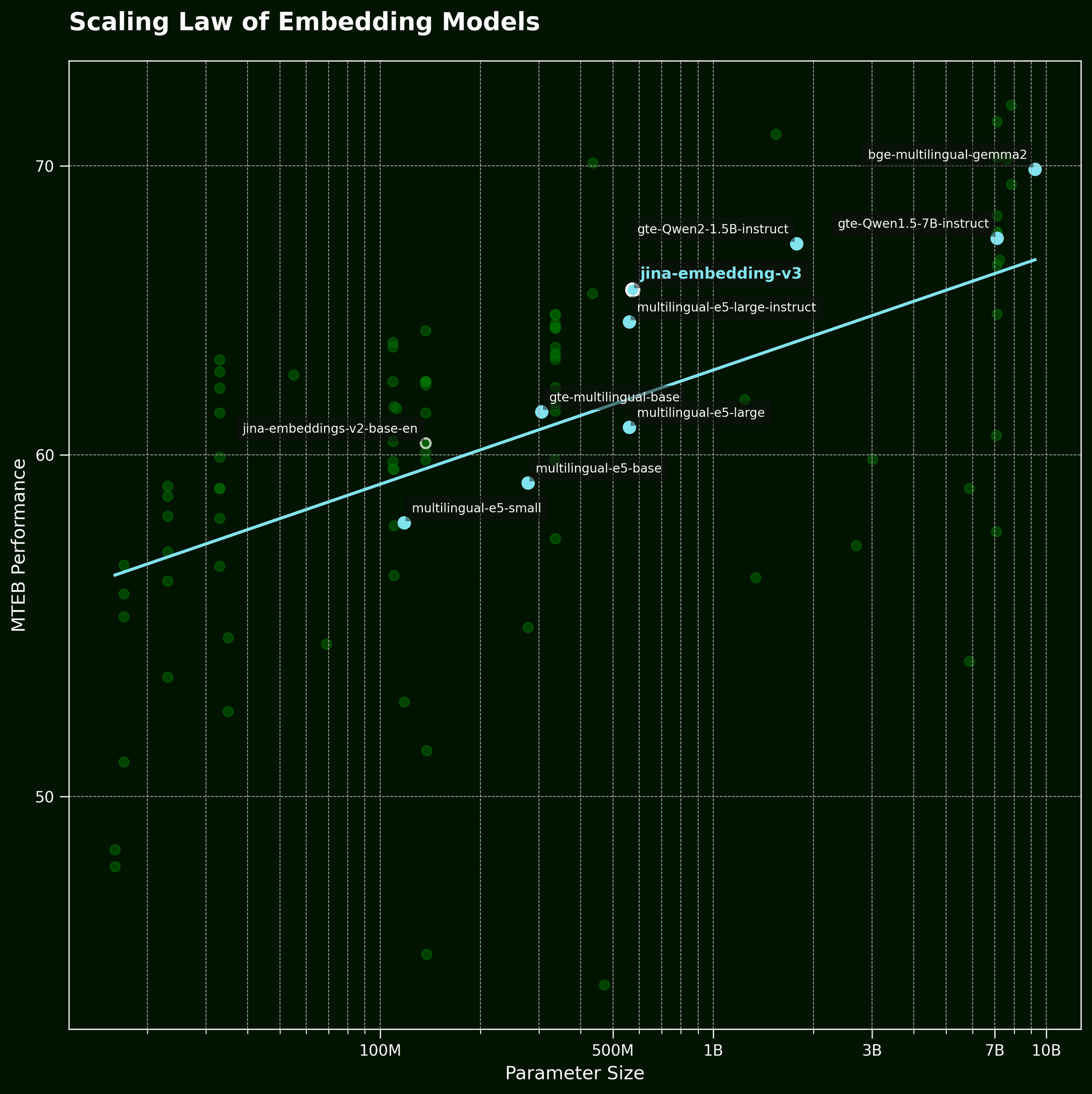
Pero ¿puede un modelo más grande capturar la información del orden de las palabras de manera más efectiva? Probamos tres variaciones del modelo BGE: bge-small-en-v1.5, bge-base-en-v1.5, y bge-large-en-v1.5, con tamaños de parámetros de 33 millones, 110 millones y 335 millones, respectivamente.
Usaremos las mismas 180 oraciones que antes, pero ignoraremos la información de longitud. Codificaremos tanto las oraciones originales como sus mezclas aleatorias usando las tres variantes del modelo y graficaremos la similitud del coseno promedio:
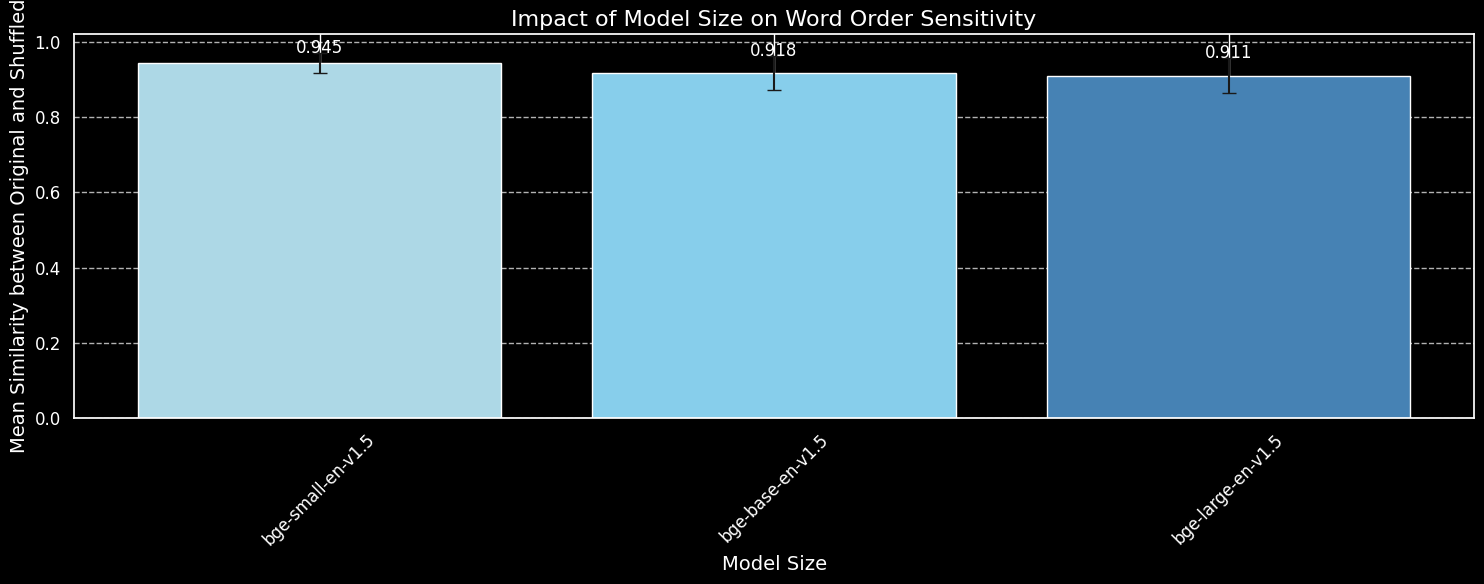
bge-small-en-v1.5, bge-base-en-v1.5, y bge-large-en-v1.5.Aunque podemos ver que los modelos más grandes son más sensibles a la variación del orden de las palabras, la diferencia es pequeña. Incluso el mucho más grande bge-large-en-v1.5 es apenas un poco mejor para distinguir las oraciones mezcladas de las no mezcladas. Otros factores entran en juego para determinar qué tan sensible es un modelo de incrustación a las reordenaciones de palabras, particularmente las diferencias en el régimen de entrenamiento. Además, la similitud del coseno es una herramienta muy limitada para medir la capacidad de un modelo para hacer distinciones. Sin embargo, podemos ver que el tamaño del modelo no es una consideración importante. No podemos simplemente hacer nuestro modelo más grande y resolver este problema.
tagOrden de Palabras y Elección de Palabras en el Mundo Real
jina-embeddings-v2 (no nuestro modelo más reciente, jina-embeddings-v3) ya que v2 es mucho más pequeño y por lo tanto más rápido para experimentar en nuestras GPUs locales, con 137m parámetros frente a los 580m de v3.Como mencionamos en la introducción, el orden de las palabras no es el único desafío para los modelos de incrustación. Un desafío más realista del mundo real es sobre la elección de palabras. Hay muchas formas de cambiar las palabras en una oración — formas que no se reflejan bien en las incrustaciones. Podemos tomar "Ella voló de París a Tokio" y alterarla para obtener "Ella condujo de Tokio a París", y las incrustaciones permanecen similares. Hemos mapeado esto a través de varias categorías de alteración:
| Categoría | Ejemplo - Izquierda | Ejemplo - Derecha | Similitud del Coseno (jina) |
|---|---|---|---|
| Direccional | Ella voló de París a Tokio | Ella condujo de Tokio a París | 0.9439 |
| Temporal | Ella cenó antes de ver la película | Ella vio la película antes de cenar | 0.9833 |
| Causal | La temperatura en aumento derritió la nieve | La nieve derretida enfrió la temperatura | 0.8998 |
| Comparativa | El café sabe mejor que el té | El té sabe mejor que el café | 0.9457 |
| Negación | Él está de pie junto a la mesa | Él está de pie lejos de la mesa | 0.9116 |
La tabla anterior muestra una lista de "casos de fallo" donde un modelo de embeddings de texto falla al capturar alteraciones sutiles de palabras. Esto coincide con nuestras expectativas: los modelos de embeddings de texto carecen de la capacidad de razonar. Por ejemplo, el modelo no comprende la relación entre "desde" y "hacia". Los modelos de embeddings de texto realizan coincidencias semánticas, con semántica típicamente capturada a nivel de token y luego comprimida en un único vector denso después del pooling. En contraste, los LLM (modelos autorregresivos) entrenados en conjuntos de datos más grandes, a escala de billones de tokens, están comenzando a demostrar capacidades emergentes de razonamiento.
Esto nos hizo preguntarnos, ¿podemos ajustar el modelo de embeddings con aprendizaje contrastivo usando tripletas para acercar la consulta y el positivo, mientras alejamos la consulta del negativo?

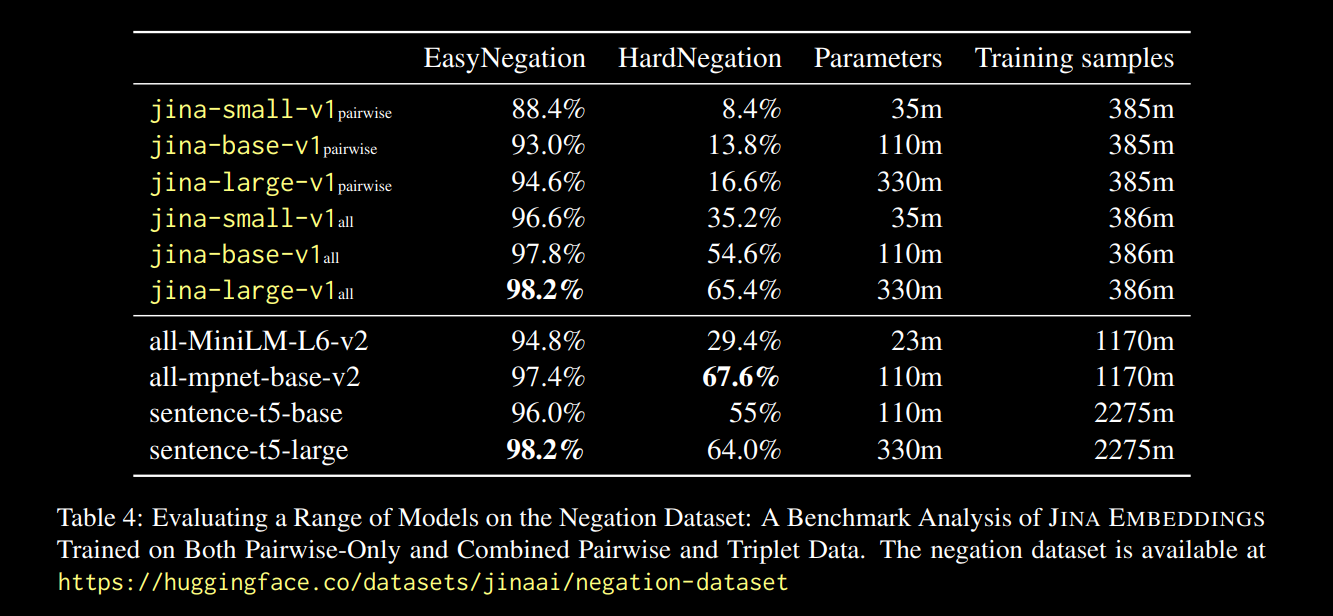
Por ejemplo, "Vuelo desde Ámsterdam a Berlín" podría considerarse el par negativo de "Vuelo desde Berlín a Ámsterdam". De hecho, en el informe técnico de jina-embeddings-v1 (Michael Guenther, et al.), abordamos brevemente este problema a pequeña escala: ajustamos el modelo jina-embeddings-v1 en un conjunto de datos de negación de 10.000 ejemplos generados por modelos de lenguaje grandes.

Los resultados, reportados en el enlace del informe anterior, fueron prometedores:
Observamos que en todos los tamaños de modelo, el ajuste fino en datos de tripletas (que incluye nuestro conjunto de datos de entrenamiento de negación) mejora dramáticamente el rendimiento, particularmente en la tarea HardNegation.
jina-embeddings con entrenamiento por pares y combinado de tripletas/pares.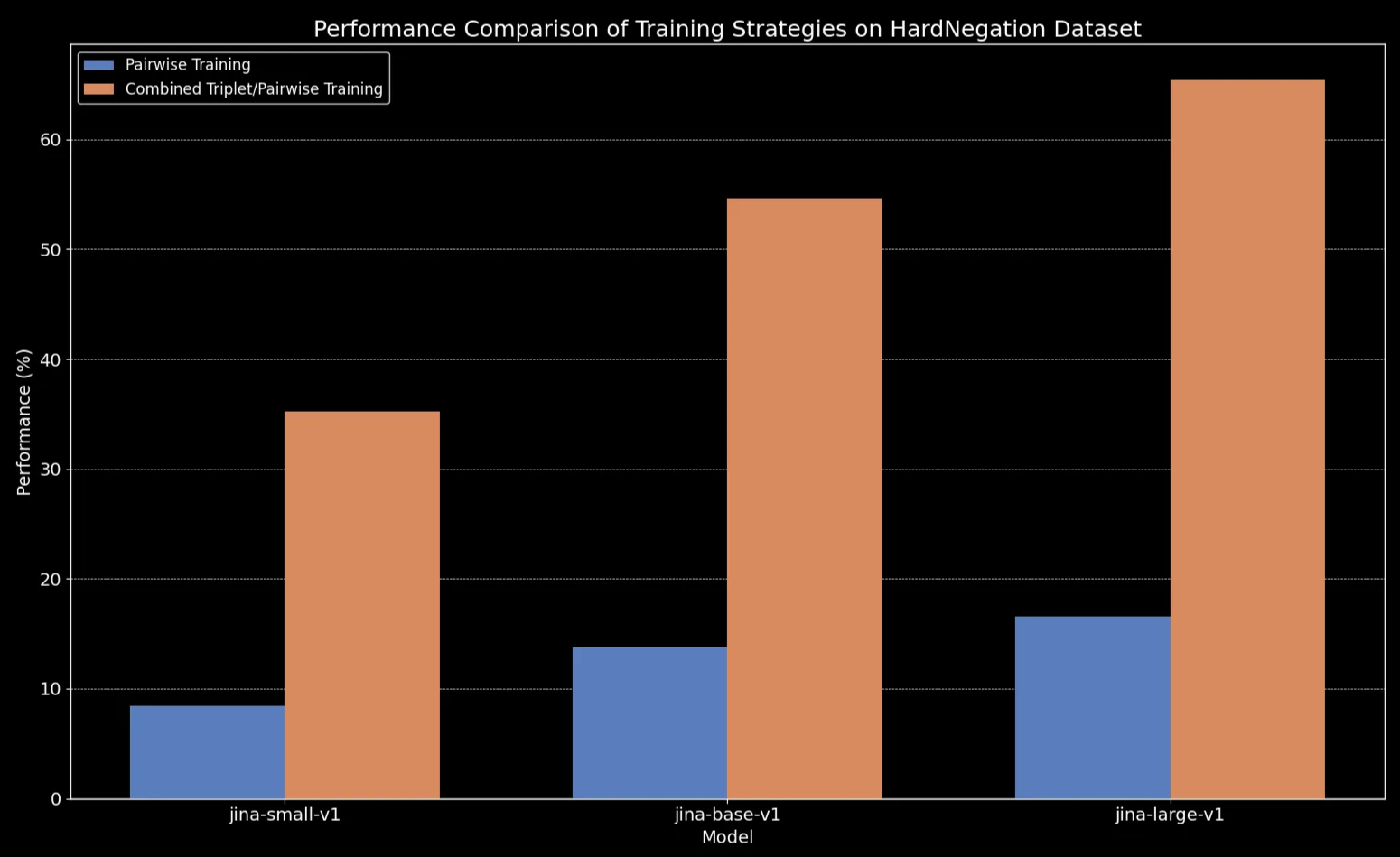
jina-embeddings.tagAjuste Fino de Modelos de Embeddings de Texto con Conjuntos de Datos Curados
En las secciones anteriores, exploramos varias observaciones clave sobre los embeddings de texto:
- Los textos más cortos son más propensos a errores en la captura del orden de las palabras.
- Aumentar el tamaño del modelo de embeddings de texto no necesariamente mejora la comprensión del orden de las palabras.
- El aprendizaje contrastivo podría ofrecer una solución potencial a estos problemas.
Con esto en mente, ajustamos jina-embeddings-v2-base-en y bge-base-en-1.5 en nuestros conjuntos de datos de negación y orden de palabras (aproximadamente 11.000 muestras de entrenamiento en total):


Para ayudar a evaluar el ajuste fino, generamos un conjunto de datos de 1.000 tripletas que consisten en un caso query, positive (pos), y negative (neg):

Aquí hay una fila de ejemplo:
| Anchor | The river flows from the mountains to the sea |
| Positive | Water travels from mountain peaks to ocean |
| Negative | The river flows from the sea to the mountains |
Estas tripletas están diseñadas para cubrir varios casos de fallo, incluyendo cambios de significado direccionales, temporales y causales debido a cambios en el orden de las palabras.
Ahora podemos evaluar los modelos en tres conjuntos de evaluación diferentes:
- El conjunto de 180 oraciones sintéticas (del principio de este post), mezcladas aleatoriamente.
- Cinco ejemplos revisados manualmente (de la tabla direccional/causal/etc anterior).
- 94 tripletas curadas de nuestro conjunto de datos de tripletas que acabamos de generar.
Aquí está la diferencia para oraciones mezcladas antes y después del ajuste fino:
| Longitud de Oración (tokens) | Similitud Coseno Media (jina) |
Similitud Coseno Media (jina-ft) |
Similitud Coseno Media (bge) |
Similitud Coseno Media (bge-ft) |
|---|---|---|---|---|
| 3 | 0.970 | 0.927 | 0.929 | 0.899 |
| 5 | 0.958 | 0.910 | 0.940 | 0.916 |
| 10 | 0.953 | 0.890 | 0.934 | 0.910 |
| 15 | 0.930 | 0.830 | 0.912 | 0.875 |
| 20 | 0.916 | 0.815 | 0.901 | 0.879 |
| 30 | 0.927 | 0.819 | 0.877 | 0.852 |
El resultado parece claro: a pesar de que el proceso de fine-tuning solo tomó cinco minutos, vemos una mejora dramática en el rendimiento en el conjunto de datos de oraciones aleatorias:
bge-base-en-1.5 (ajustado).También vemos mejoras en los casos direccionales, temporales, causales y comparativos. El modelo muestra una mejora sustancial en el rendimiento reflejada por una caída en la similitud coseno promedio. La mayor ganancia de rendimiento se da en el caso de negación, debido a que nuestro conjunto de datos de fine-tuning contiene 10,000 ejemplos de entrenamiento de negación.
| Categoría | Ejemplo - Izquierda | Ejemplo - Derecha | Similitud Coseno Media (jina) |
Similitud Coseno Media (jina-ft) |
Similitud Coseno Media (bge) |
Similitud Coseno Media (bge-ft) |
|---|---|---|---|---|---|---|
| Direccional | She flew from Paris to Tokyo. | She drove from Tokyo to Paris | 0.9439 | 0.8650 | 0.9319 | 0.8674 |
| Temporal | She ate dinner before watching the movie | She watched the movie before eating dinner | 0.9833 | 0.9263 | 0.9683 | 0.9331 |
| Causal | The rising temperature melted the snow | The melting snow cooled the temperature | 0.8998 | 0.7937 | 0.8874 | 0.8371 |
| Comparativo | Coffee tastes better than tea | Tea tastes better than coffee | 0.9457 | 0.8759 | 0.9723 | 0.9030 |
| Negación | He is standing by the table | He is standing far from the table | 0.9116 | 0.4478 | 0.8329 | 0.4329 |
tagConclusión
En esta publicación, profundizamos en los desafíos que enfrentan los modelos de embedding de texto, especialmente su dificultad para manejar efectivamente el orden de las palabras. Para desglosarlo, hemos identificado cinco tipos principales de fallas: Direccional, Temporal, Causal, Comparativo y Negación. Estos son los tipos de consultas donde el orden de las palabras realmente importa, y si tu caso de uso involucra alguno de estos, vale la pena conocer las limitaciones de estos modelos.
También realizamos un experimento rápido, expandiendo un conjunto de datos centrado en la negación para cubrir las cinco categorías de fallas. Los resultados fueron prometedores: el fine-tuning con "negativos difíciles" cuidadosamente seleccionados mejoró la capacidad del modelo para reconocer qué elementos pertenecen juntos y cuáles no. Dicho esto, aún hay más trabajo por hacer. Los próximos pasos incluyen profundizar en cómo el tamaño y la calidad del conjunto de datos afectan el rendimiento.
