



Los embeddings semánticos son el núcleo de los modelos modernos de IA, incluso de los chatbots y modelos de arte con IA. A veces están ocultos para los usuarios, pero siguen ahí, acechando justo bajo la superficie.
La teoría de los embeddings tiene solo dos partes:
- Las cosas — elementos fuera del modelo de IA, como textos e imágenes — están representadas por vectores creados por modelos de IA a partir de datos sobre esas cosas.
- Las relaciones entre las cosas fuera del modelo de IA están representadas por relaciones espaciales entre esos vectores. Entrenamos modelos de IA específicamente para crear vectores que funcionen de esa manera.
Cuando creamos un modelo multimodal de imagen-texto, entrenamos el modelo para que los embeddings de las imágenes y los embeddings de los textos que describen o se relacionan con esas imágenes estén relativamente cerca entre sí. Las similitudes semánticas entre las cosas que esos dos vectores representan — una imagen y un texto — se reflejan en la relación espacial entre los dos vectores.
Por ejemplo, podríamos esperar razonablemente que los vectores de embedding para una imagen de una naranja y el texto "una naranja fresca" estén más cerca entre sí que la misma imagen y el texto "una manzana fresca".
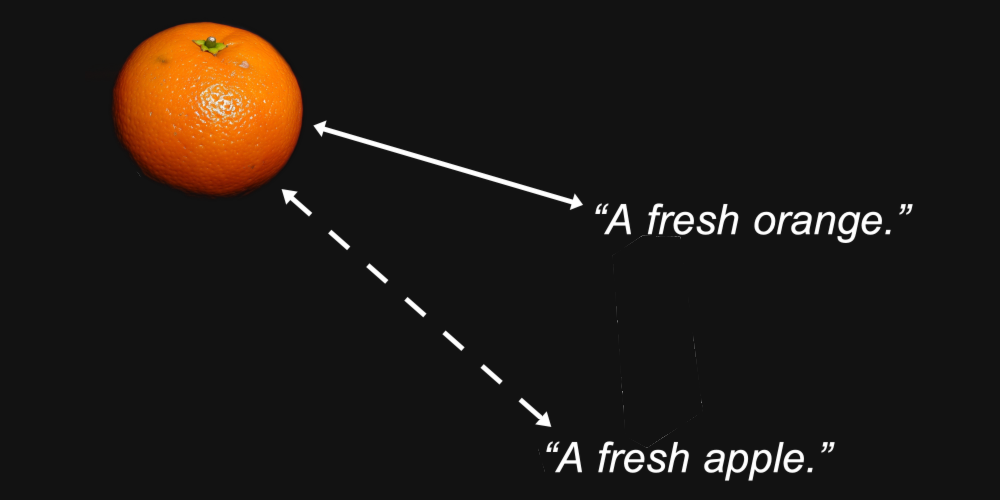
Ese es el propósito de un modelo de embedding: generar representaciones donde las características que nos importan — como qué tipo de fruta se muestra en una imagen o se nombra en un texto — se preserven en la distancia entre ellas.
Pero la multimodalidad introduce algo más. Podríamos encontrar que una imagen de una naranja está más cerca de una imagen de una manzana que del texto "una naranja fresca", y que el texto "una manzana fresca" está más cerca de otro texto que de una imagen de una manzana.
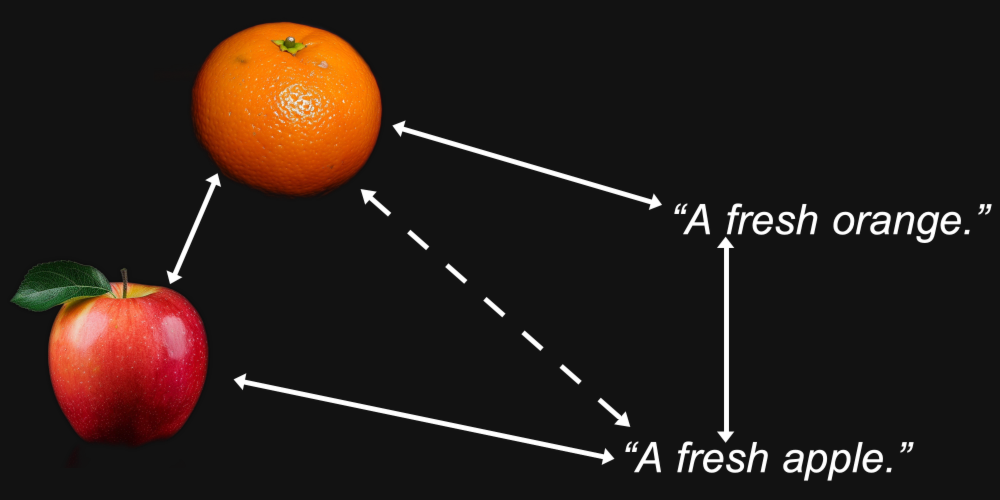
Resulta que esto es exactamente lo que sucede con los modelos multimodales, incluido el modelo Jina CLIP (jina-clip-v1) de Jina AI.
Para probarlo, tomamos una muestra de 1,000 pares de texto-imagen del conjunto de prueba Flickr8k. Cada par contiene cinco textos de leyenda (así que técnicamente no es un par) y una sola imagen, con los cinco textos describiendo la misma imagen.
Por ejemplo, la siguiente imagen (1245022983_fb329886dd.jpg en el conjunto de datos Flickr8k):

Sus cinco leyendas:
A child in all pink is posing nearby a stroller with buildings in the distance.
A little girl in pink dances with her hands on her hips.
A small girl wearing pink dances on the sidewalk.
The girl in a bright pink skirt dances near a stroller.
The little girl in pink has her hands on her hips.
Usamos Jina CLIP para incrustar las imágenes y textos y luego:
- Comparamos las similitudes de coseno de los embeddings de imágenes con los embeddings de sus textos de leyenda.
- Tomamos los embeddings de los cinco textos de leyenda que describen la misma imagen y comparamos sus similitudes de coseno entre sí.
El resultado es una brecha sorprendentemente grande, visible en la Figura 1:
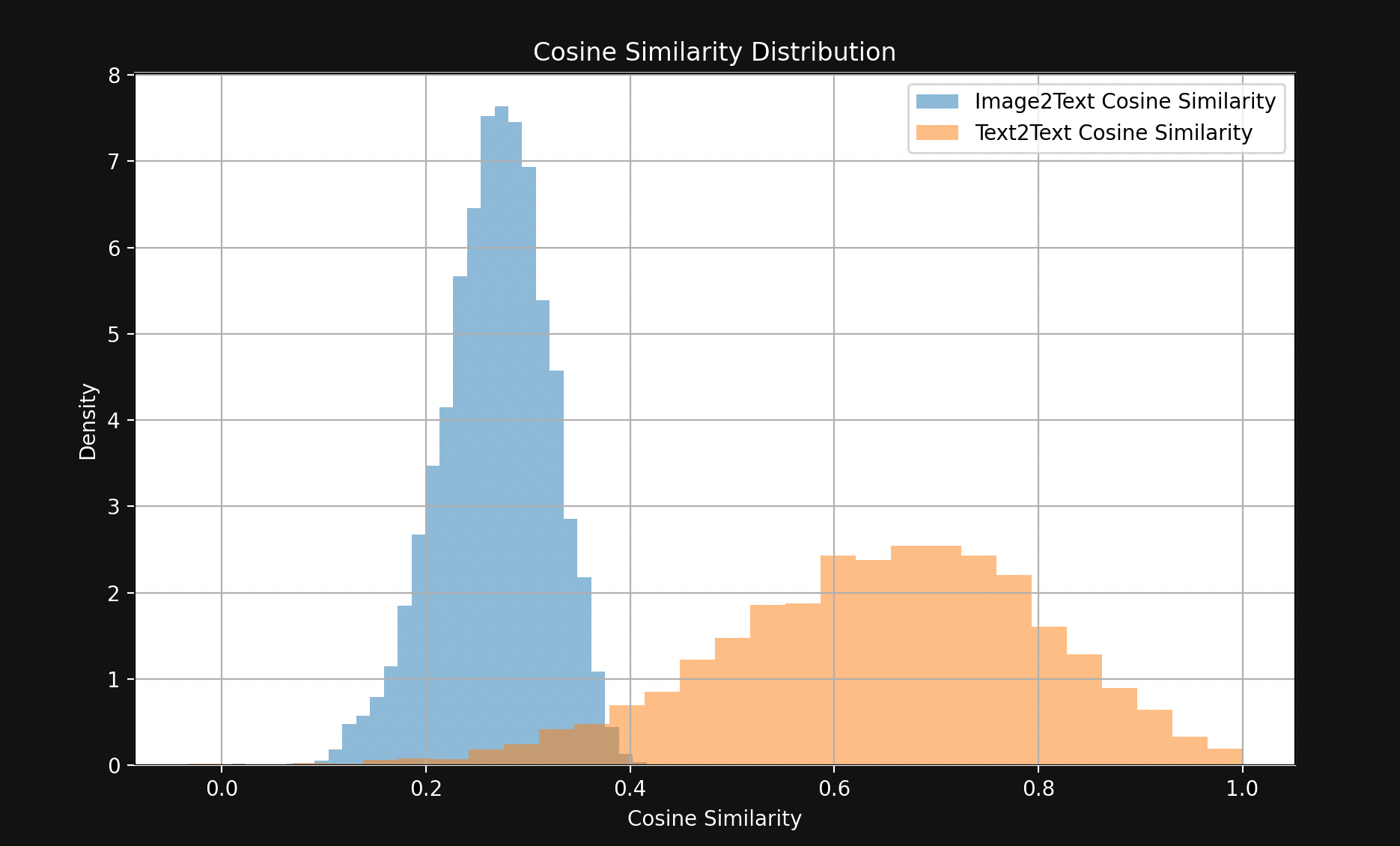
Con pocas excepciones, los pares de texto coincidentes están mucho más cerca entre sí que los pares de imagen-texto coincidentes. Esto indica fuertemente que Jina CLIP está codificando textos en una parte del espacio de embedding e imágenes en una parte mayormente disjunta relativamente alejada de ella. Este espacio entre los textos y las imágenes es la brecha multimodal.

Los modelos de embedding multimodales están codificando más que la información semántica que nos importa: están codificando el medio de su entrada. Según Jina CLIP, una imagen no vale, como dice el dicho, mil palabras. Tiene un contenido que ninguna cantidad de palabras puede igualar realmente. Codifica el medio de entrada en la semántica de sus embeddings sin que nadie lo haya entrenado para hacerlo.
Este fenómeno ha sido investigado en el artículo Mind the Gap: Understanding the Modality Gap in Multi-modal Contrastive Representation Learning [Liang et al., 2022] que se refiere a él como la "brecha de modalidad". La brecha de modalidad es la separación espacial, en el espacio de embedding, entre entradas en un medio y entradas en otro. Aunque los modelos no están intencionalmente entrenados para tener tal brecha, son omnipresentes en los modelos multimodales.
Nuestras investigaciones sobre la brecha de modalidad en Jina CLIP se basan fuertemente en Liang et al. [2022].
tag¿De dónde viene la brecha de modalidad?
Liang et al. [2022] identifican tres fuentes principales detrás de la brecha de modalidad:
- Un sesgo de inicialización que llaman el "efecto cono".
- Reducciones en la temperatura (aleatoriedad) durante el entrenamiento que hacen muy difícil "desaprender" este sesgo.
- Procedimientos de aprendizaje contrastivo, que son ampliamente utilizados en modelos multimodales, que involuntariamente refuerzan la brecha.
Examinaremos cada uno por turno.
tagEfecto Cono
Un modelo construido con una arquitectura CLIP o tipo CLIP es en realidad dos modelos de embedding separados conectados entre sí. Para modelos multimodales de imagen-texto, esto significa un modelo para codificar textos y otro completamente separado para codificar imágenes, como se muestra en el esquema a continuación.
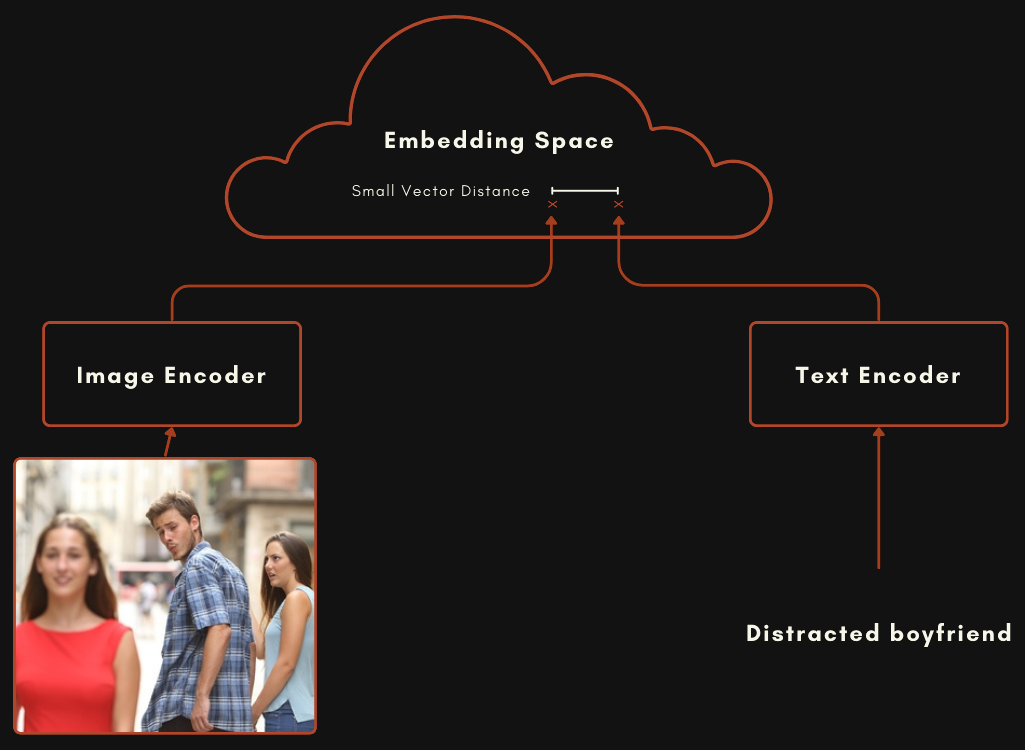
Estos dos modelos son entrenados de manera que un embedding de imagen y un embedding de texto estén relativamente cerca cuando el texto describe bien la imagen.
Puedes entrenar un modelo como este aleatorizando los pesos en ambos modelos, luego presentando pares de imagen y texto juntos, entrenándolo desde cero para minimizar la distancia entre las dos salidas. El modelo CLIP original de OpenAI fue entrenado de esta manera. Sin embargo, esto requiere muchos pares de imagen-texto y un entrenamiento computacionalmente costoso. Para el primer modelo CLIP, OpenAI extrajo 400 millones de pares de imagen-texto de materiales con subtítulos en Internet.
Los modelos más recientes tipo CLIP utilizan componentes pre-entrenados. Esto significa entrenar cada componente por separado como un buen modelo de embedding de modo único, uno para textos y otro para imágenes. Estos dos modelos luego se entrenan juntos usando pares de imagen-texto, un proceso llamado ajuste contrastivo. Los pares alineados de imagen-texto se utilizan para "empujar" lentamente los pesos para hacer que los embeddings de texto e imagen coincidentes estén más cerca entre sí, y los no coincidentes más separados.
Este enfoque generalmente requiere menos datos de pares imagen-texto, que son difíciles y costosos de obtener, y grandes cantidades de textos e imágenes sin subtítulos, que son mucho más fáciles de obtener. Jina CLIP (jina-clip-v1) fue entrenado usando este último método. Pre-entrenamos un modelo JinaBERT v2 para codificación de texto usando datos de texto generales y utilizamos un codificador de imágenes EVA-02 pre-entrenado, luego los entrenamos más usando una variedad de técnicas de entrenamiento contrastivo, como se describe en Koukounas et al. [2024]
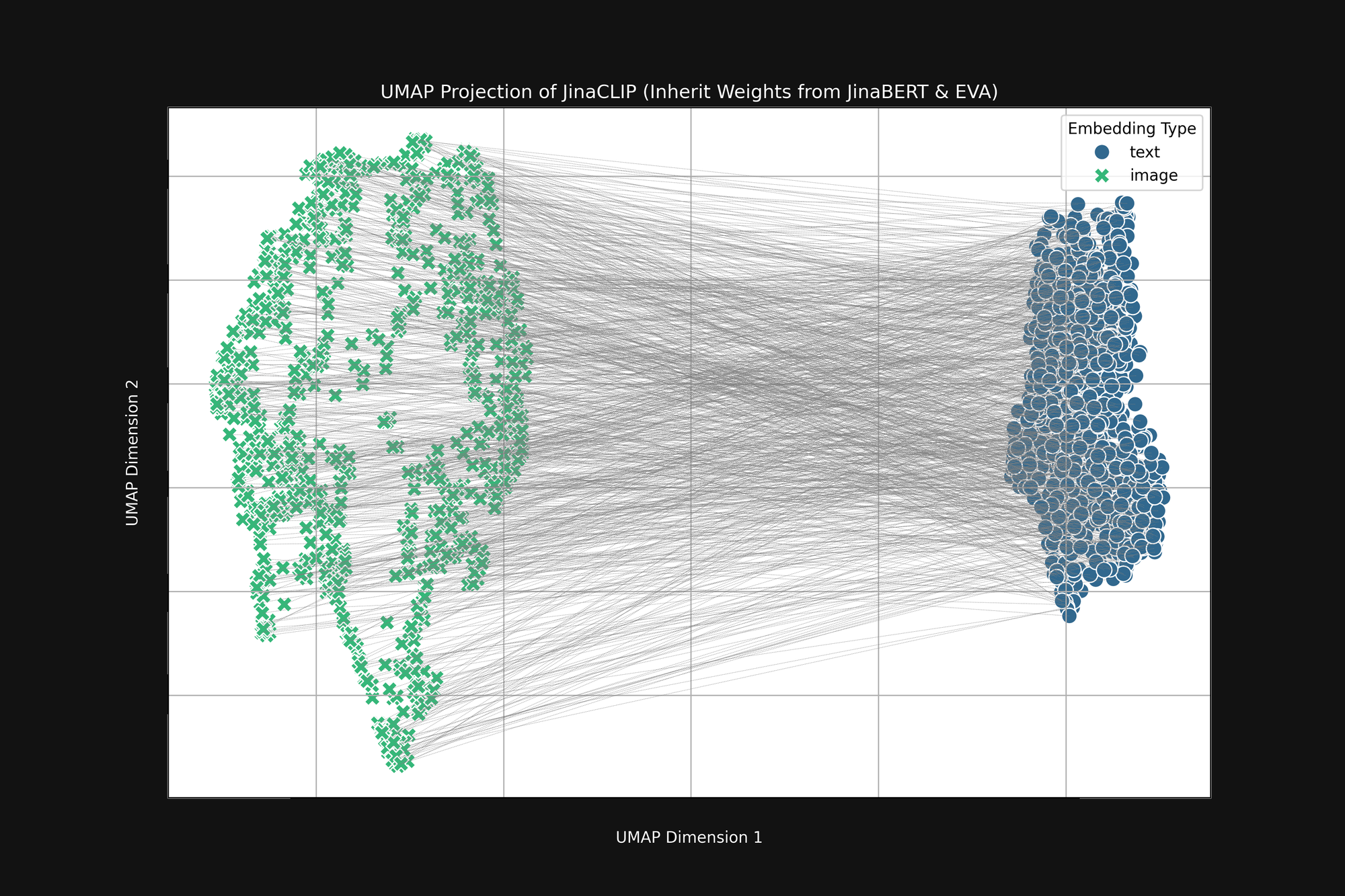
Si tomamos estos dos modelos pre-entrenados y observamos su salida, antes de entrenarlos con pares de imagen-texto, notamos algo importante. La Figura 2 (arriba) es una proyección UMAP en dos dimensiones de los embeddings de imagen producidos por el codificador EVA-02 pre-entrenado y los embeddings de texto producidos por JinaBERT v2 pre-entrenado, con las líneas grises indicando pares imagen-texto coincidentes. Esto es antes de cualquier entrenamiento cross-modal.
El resultado es una especie de "cono" truncado, con embeddings de imagen en un extremo y embeddings de texto en el otro. Esta forma de cono se traduce pobremente a proyecciones bidimensionales, pero se puede ver ampliamente en la imagen de arriba. Todos los textos se agrupan en una parte del espacio de embedding, y todas las imágenes en otra parte. Si, después del entrenamiento, los textos siguen siendo más similares a otros textos que a las imágenes coincidentes, este estado inicial es una gran razón por la que sucede. El objetivo de mejor coincidencia de imágenes con textos, textos con textos e imágenes con imágenes, es completamente compatible con esta forma de cono.
El modelo tiene prejuicios de nacimiento y lo que aprende no cambia eso. La Figura 3 (abajo) es el mismo análisis del modelo Jina CLIP tal como se lanzó, después del entrenamiento completo usando pares de imagen-texto. Si acaso, la brecha multimodal es aún más pronunciada.
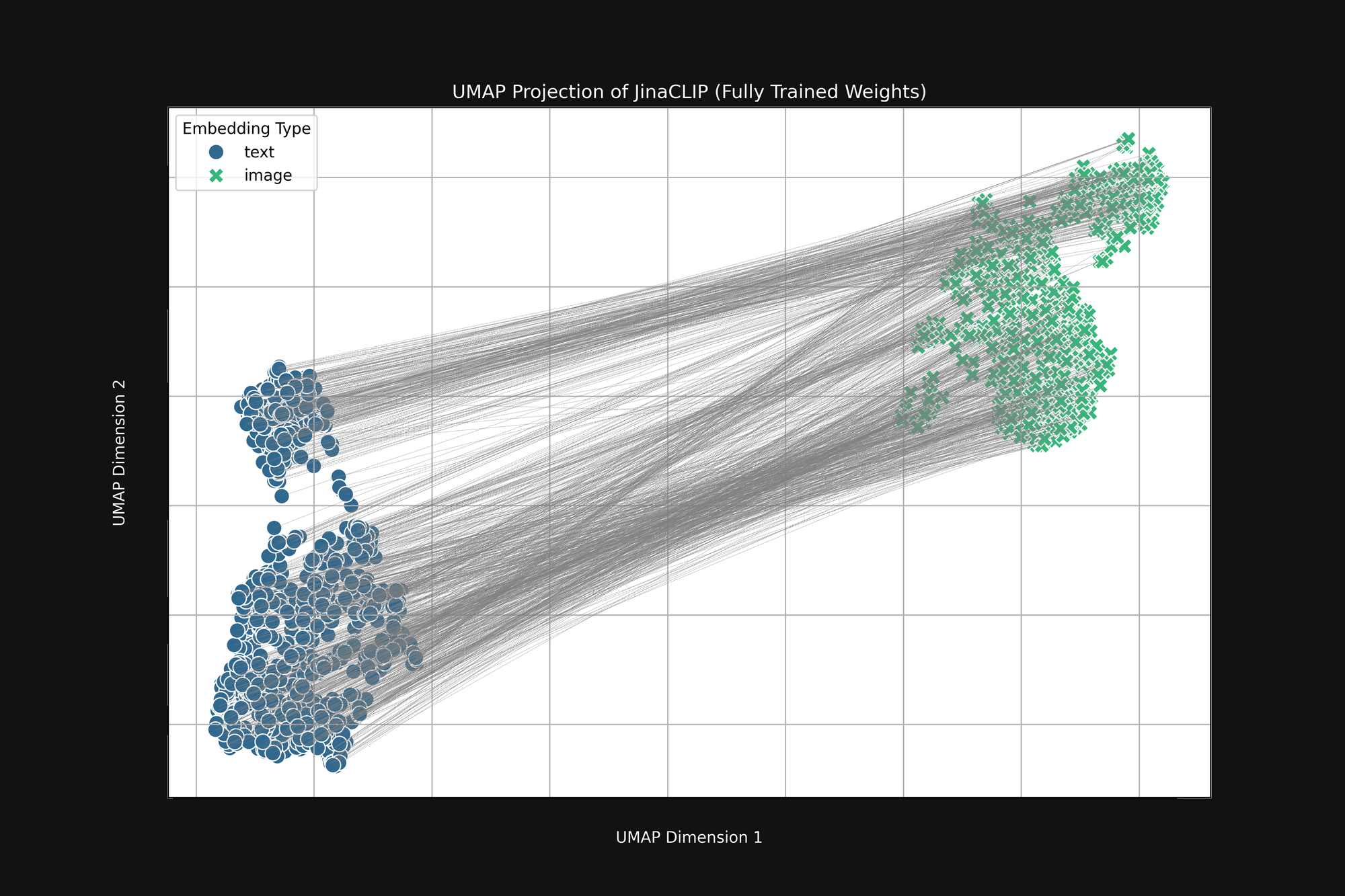
Incluso después de un entrenamiento extensivo, Jina CLIP aún codifica el medio como parte del mensaje.
Usar el enfoque más costoso de OpenAI, con inicialización puramente aleatoria, no elimina este sesgo. Tomamos la arquitectura original de OpenAI CLIP y aleatorizamos completamente todos los pesos, luego hicimos el mismo análisis que arriba. El resultado sigue siendo una forma de cono truncado, como se ve en la Figura 4:
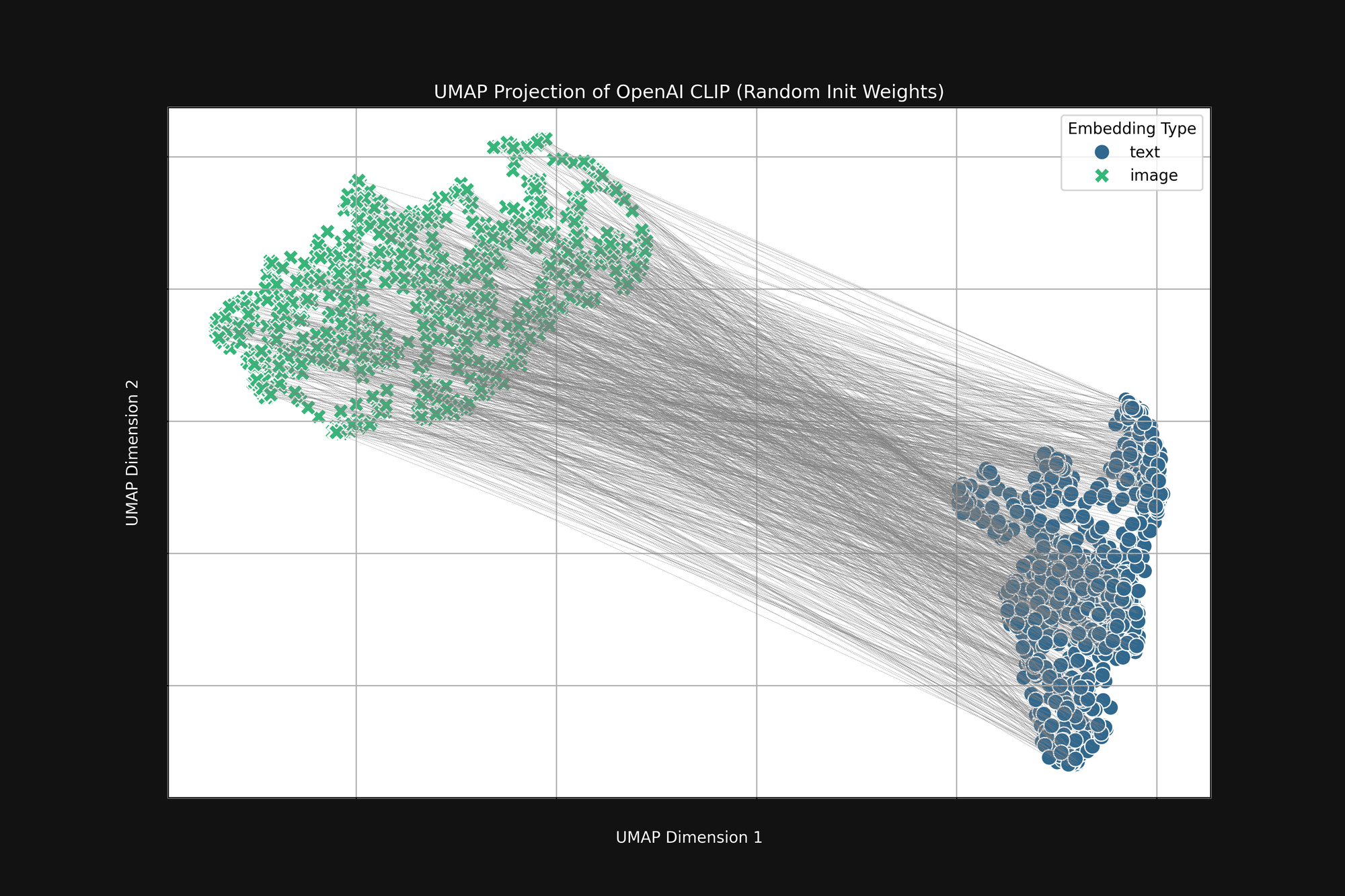
Este sesgo es un problema estructural y puede no tener solución. Si es así, solo podemos buscar formas de corregirlo o mitigarlo durante el entrenamiento.
tagTemperatura de Entrenamiento
Durante el entrenamiento de modelos de IA, típicamente agregamos algo de aleatoriedad al proceso. Calculamos cuánto debería cambiar un lote de muestras de entrenamiento los pesos en el modelo, luego agregamos un pequeño factor aleatorio a esos cambios antes de realmente cambiar los pesos. Llamamos a la cantidad de aleatoriedad la temperatura, por analogía con la forma en que usamos la aleatoriedad en termodinámica.
Las temperaturas altas crean cambios grandes en los modelos muy rápido, mientras que las temperaturas bajas reducen la cantidad que un modelo puede cambiar cada vez que ve algunos datos de entrenamiento. El resultado es que con temperaturas altas, podemos esperar que los embeddings individuales se muevan mucho en el espacio de embedding durante el entrenamiento, y con temperaturas bajas, se moverán mucho más lentamente.
La mejor práctica para entrenar modelos de IA es comenzar con una temperatura alta y luego reducirla progresivamente. Esto ayuda al modelo a hacer grandes saltos en el aprendizaje al principio cuando los pesos son aleatorios o están lejos de donde necesitan estar y luego le permite aprender los detalles de manera más estable.
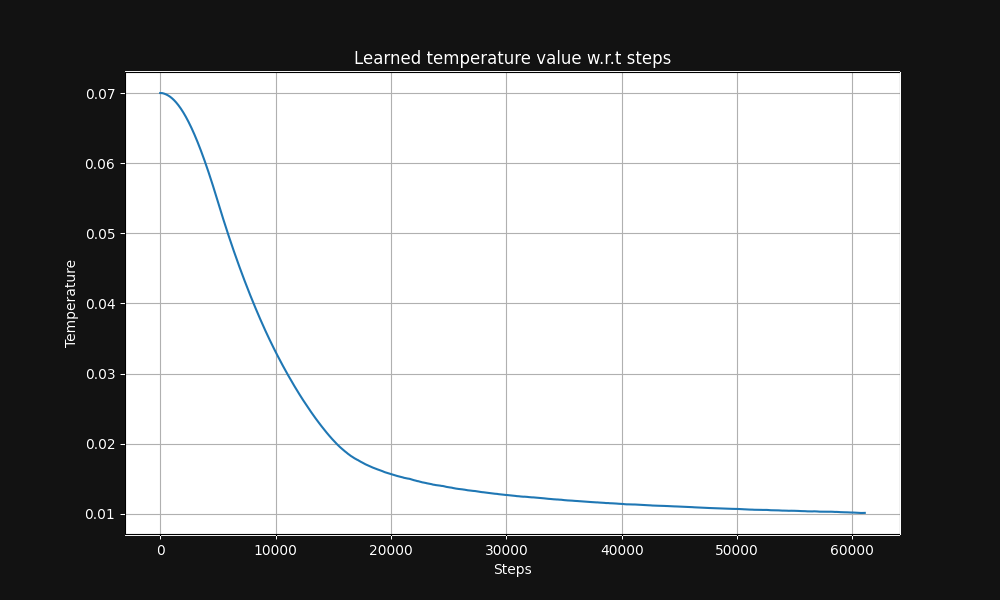
El entrenamiento de pares imagen-texto de Jina CLIP comienza con una temperatura de 0.07 (esta es una temperatura relativamente alta) y la reduce exponencialmente durante el curso del entrenamiento a 0.01, como se muestra en la Figura 5 a continuación, un gráfico de temperatura vs. pasos de entrenamiento:
Queríamos saber si aumentar la temperatura — añadiendo aleatoriedad — reduciría el efecto cono y acercaría los embeddings de imagen y texto en general. Así que reentrenamos Jina CLIP con una temperatura fija de 0.1 (un valor muy alto). Después de cada época de entrenamiento, verificamos la distribución de distancias entre pares de imagen-texto y pares de texto-texto, al igual que en la Figura 1. Los resultados se muestran a continuación en la Figura 6:
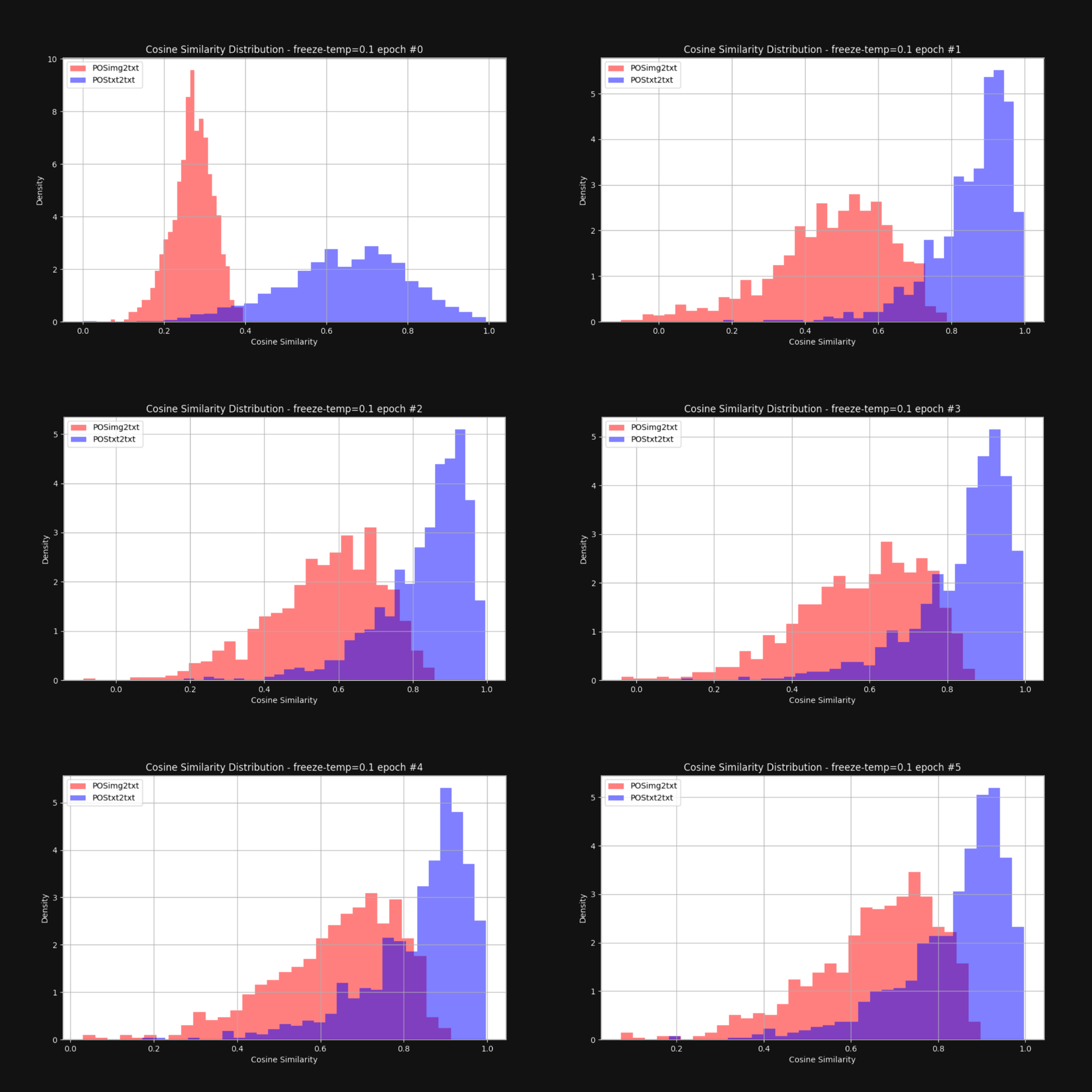
Como puede verse, mantener una temperatura alta reduce dramáticamente la brecha multimodal. Permitir que los embeddings se muevan mucho durante el entrenamiento ayuda significativamente a superar el sesgo inicial en la distribución de embeddings.
Sin embargo, esto tiene un costo. También probamos el rendimiento del modelo utilizando seis pruebas de recuperación diferentes: Tres pruebas de recuperación texto-texto y tres de texto-imagen, de los conjuntos de datos MS-COCO, Flickr8k y Flickr30k. En todas las pruebas, vemos que el rendimiento cae al principio del entrenamiento y luego sube muy lentamente, como puede verse en la Figura 7:
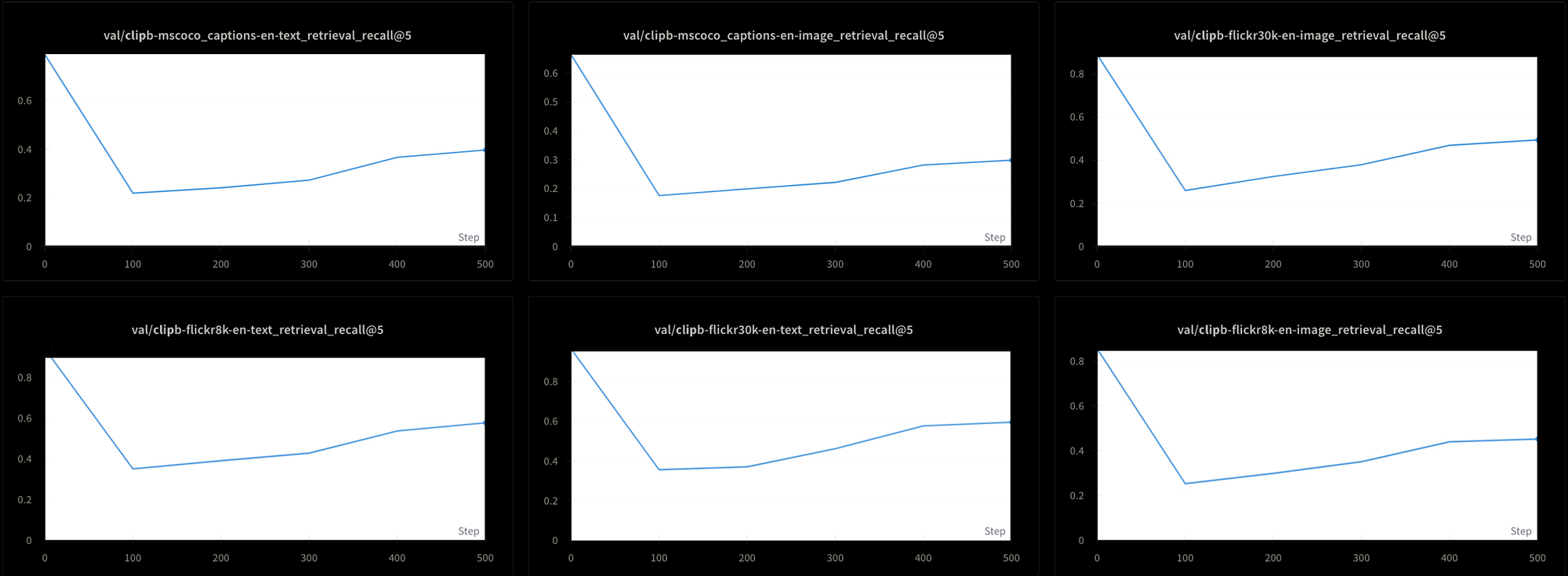
Probablemente sería extremadamente largo y costoso entrenar un modelo como Jina CLIP usando esta temperatura alta constante. Aunque teóricamente es factible, no es una solución práctica.
tagAprendizaje Contrastivo y el Problema de los Falsos Negativos
Liang et al. [2022] también descubrieron que las prácticas estándar de aprendizaje contrastivo — el mecanismo que usamos para entrenar modelos multimodales tipo CLIP — tienden a reforzar la brecha multimodal.
El aprendizaje contrastivo es fundamentalmente un concepto simple. Tenemos un embedding de imagen y un embedding de texto y sabemos que deberían estar más cerca entre sí, así que ajustamos los pesos en el modelo durante el entrenamiento para lograr esto. Vamos despacio, ajustando los pesos en pequeñas cantidades, y los ajustamos en proporción a qué tan separados están los dos embeddings: Más cerca significa un cambio más pequeño que más lejos.
Esta técnica funciona mucho mejor si no solo acercamos los embeddings cuando coinciden, sino que también los alejamos cuando no coinciden. Queremos tener no solo pares de imagen-texto que pertenezcan juntos, sino también pares que sabemos que deben estar separados.
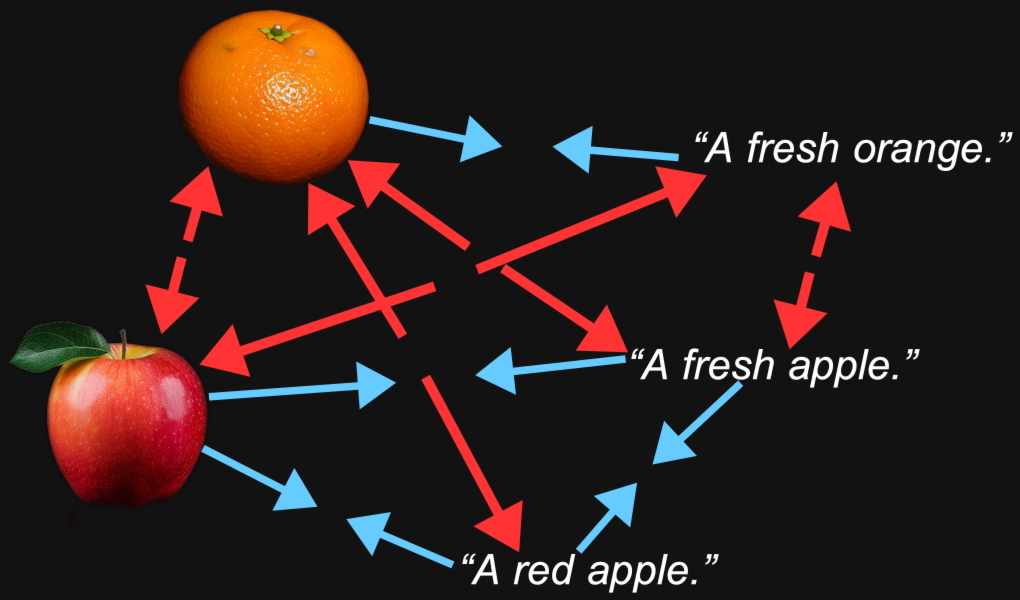
Esto plantea algunos problemas:
- Nuestras fuentes de datos consisten enteramente en pares coincidentes. Nadie haría una base de datos de textos e imágenes que un humano haya verificado como no relacionados, ni tampoco se podría construir fácilmente una mediante web scraping u otra técnica no supervisada o semi-supervisada.
- Incluso los pares de imagen-texto que superficialmente parecen completamente disjuntos no necesariamente lo son. No tenemos una teoría de la semántica que nos permita hacer objetivamente tales juicios negativos. Por ejemplo, una imagen de un gato acostado en un porche no es una coincidencia completamente negativa para el texto "un hombre durmiendo en un sofá". Ambos involucran estar acostado sobre algo.
Idealmente, querríamos entrenar con pares de imagen-texto que supiéramos con certeza que están relacionados y no relacionados, pero no hay una manera obvia de obtener pares conocidos no relacionados. Es posible preguntarle a la gente "¿Esta frase describe esta imagen?" y esperar respuestas consistentes. Es mucho más difícil obtener respuestas consistentes preguntando "¿Esta frase no tiene nada que ver con esta imagen?"
En su lugar, obtenemos pares de imagen-texto no relacionados seleccionando aleatoriamente imágenes y textos de nuestros datos de entrenamiento, esperando que prácticamente siempre sean malas coincidencias. En la práctica, esto funciona dividiendo nuestros datos de entrenamiento en lotes. Para entrenar Jina CLIP, usamos lotes que contenían 32,000 pares coincidentes de imagen-texto, pero para este experimento, los tamaños de lote fueron solo de 16.
La tabla siguiente muestra 16 pares de imagen-texto muestreados aleatoriamente de Flickr8k:
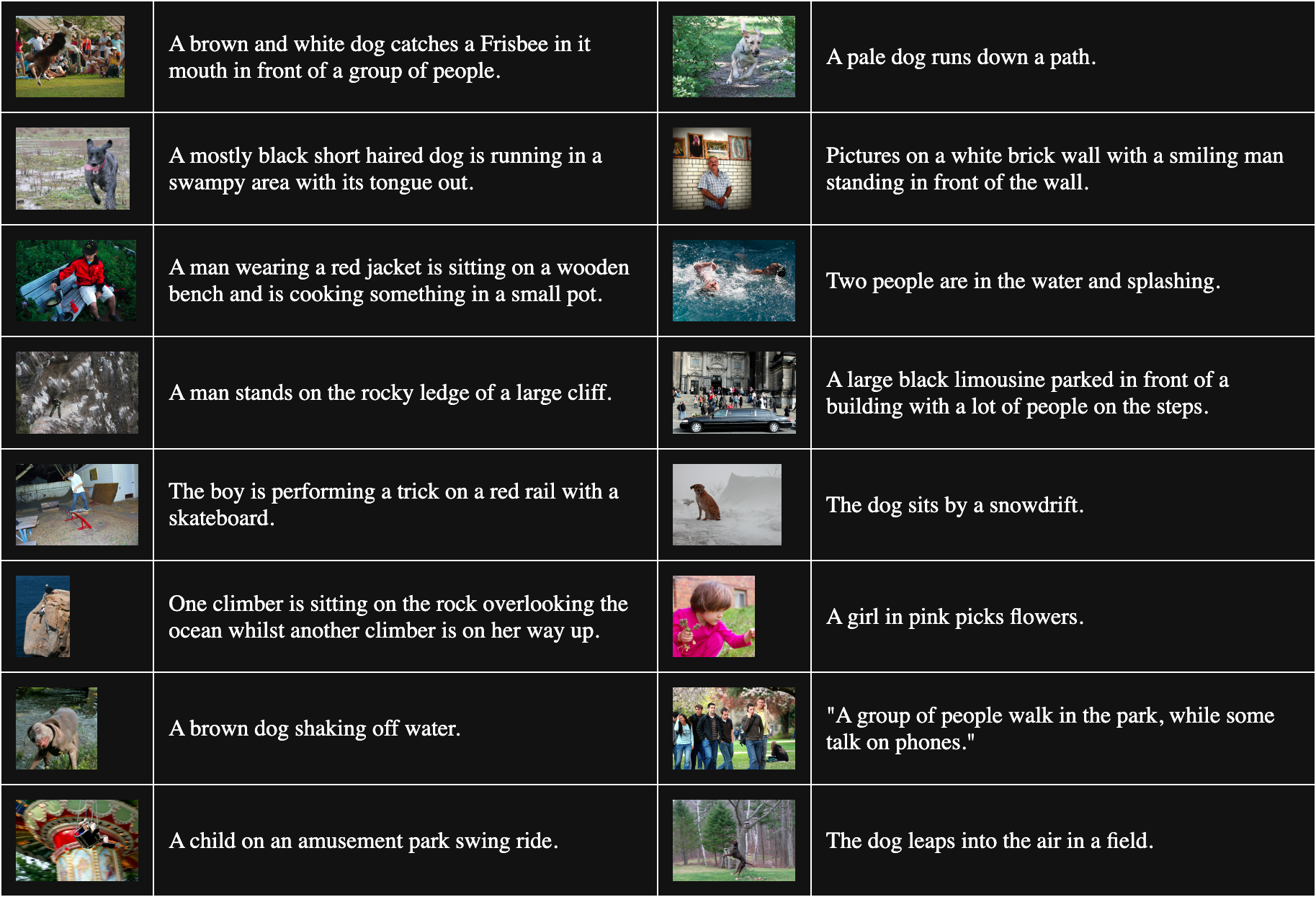
Para obtener pares no coincidentes, combinamos cada imagen en el lote con cada texto excepto con el que coincide. Por ejemplo, el siguiente par es una imagen y texto que no coinciden:

Descripción: Una niña de rosa recoge flores.
Pero este procedimiento asume que todos los textos que coinciden con otras imágenes son igualmente malas coincidencias. Esto no siempre es cierto. Por ejemplo:

Descripción: El perro se sienta junto a un montón de nieve.
Aunque el texto no describe esta imagen, tienen un perro en común. Tratar este par como no coincidente tenderá a alejar la palabra "perro" de cualquier imagen de un perro.
Liang et al. [2022] muestran que estos pares no coincidentes imperfectos empujan todas las imágenes y textos a alejarse entre sí.
Nos propusimos verificar su afirmación con un modelo de imagen vit-b-32 completamente inicializado aleatoriamente y un modelo de texto JinaBERT v2 similarmente aleatorizado, con la temperatura de entrenamiento establecida en una constante de 0.02 (una temperatura moderadamente baja). Construimos dos conjuntos de datos de entrenamiento:
- Uno con lotes aleatorios extraídos de Flickr8k, con pares no coincidentes construidos como se describió anteriormente.
- Otro donde los lotes se construyen intencionalmente con múltiples copias de la misma imagen con diferentes textos en cada lote. Esto garantiza que un número significativo de pares "no coincidentes" son en realidad coincidencias correctas entre sí.
Luego entrenamos dos modelos durante una época, uno con cada conjunto de datos de entrenamiento, y medimos la distancia coseno promedio entre 1,000 pares de texto-imagen en el conjunto de datos Flickr8k para cada modelo. El modelo entrenado con lotes aleatorios tuvo una distancia coseno promedio de 0.7521, mientras que el entrenado con muchos pares "no coincidentes" intencionalmente coincidentes tuvo una distancia coseno promedio de 0.7840. El efecto de los pares "no coincidentes" incorrectos es bastante significativo. Dado que el entrenamiento real del modelo es mucho más largo y usa muchos más datos, podemos ver cómo este efecto crecería y aumentaría la brecha entre imágenes y textos en su conjunto.
tagEl Medio es el Mensaje
El teórico canadiense de las comunicaciones Marshall McLuhan acuñó la frase "El medio es el mensaje" en su libro de 1964 Understanding Media: The Extensions of Man para enfatizar que los mensajes no son autónomos. Nos llegan en un contexto que afecta fuertemente su significado, y él afirmó famosamente que una de las partes más importantes de ese contexto es la naturaleza del medio de comunicación.
La brecha de multimodalidad nos ofrece una oportunidad única para estudiar una clase de fenómenos semánticos emergentes en modelos de IA. Nadie le dijo a Jina CLIP que codificara el medio de los datos con los que fue entrenado — simplemente lo hizo de todos modos. Incluso si no hemos resuelto el problema para modelos multimodales, al menos tenemos una buena comprensión teórica de dónde proviene el problema.
Debemos asumir que nuestros modelos están codificando otras cosas que aún no hemos buscado debido al mismo tipo de sesgo. Por ejemplo, probablemente tenemos el mismo problema en modelos de embedding multilingües. El entrenamiento conjunto en dos o más idiomas probablemente conduce a la misma brecha entre idiomas, especialmente porque se utilizan ampliamente métodos de entrenamiento similares. Las soluciones al problema de la brecha pueden tener implicaciones muy amplias.
Una investigación sobre el sesgo de inicialización en una gama más amplia de modelos probablemente también conducirá a nuevos hallazgos. Si el medio es el mensaje para un modelo de embedding, ¿quién sabe qué más se está codificando en nuestros modelos sin que nos demos cuenta?
