


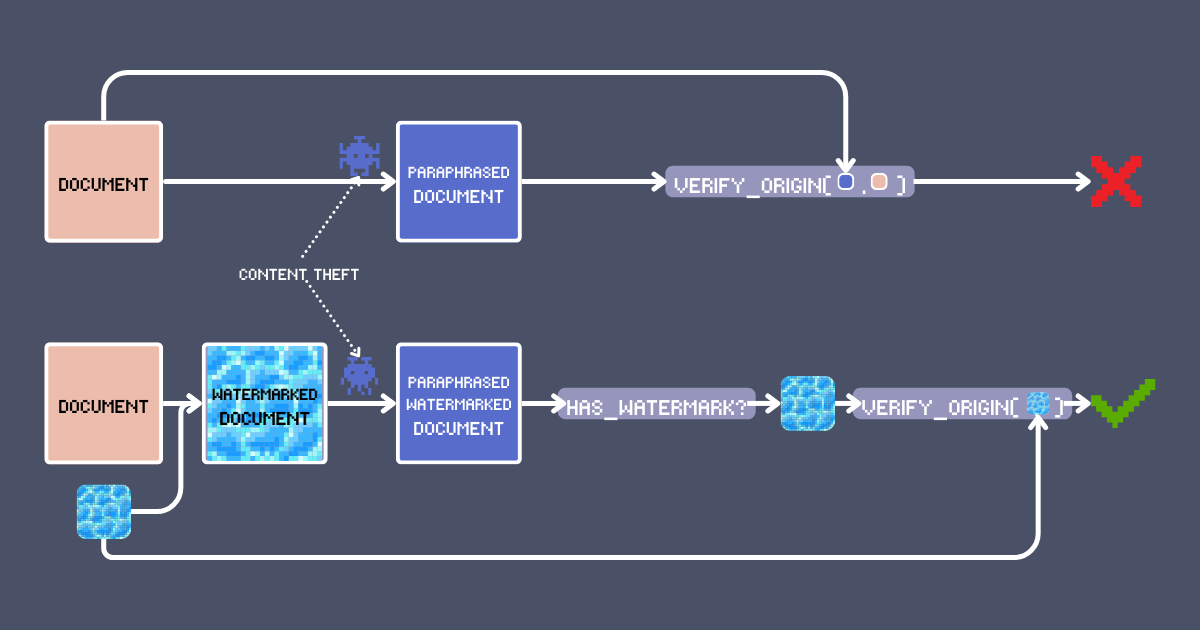
Domingo por la noche. Das "publicar" a ese artículo en el que has puesto tu corazón todo el fin de semana. Cada palabra, cada idea - únicamente tuyas. Llegan algunos "me gusta". No es viral, pero es tuyo.
Tres días después, mientras navegas por tu feed, ahí está: ¡El alma de tu artículo en el cuerpo de otra persona! Han reorganizado las palabras, pero reconoces tu propia creación. ¿Lo peor? Su versión está en todas partes, un éxito viral construido sobre tu creatividad robada. Esta no es la economía creativa a la que nos suscribimos.
La solución obvia es poner tu nombre en tu trabajo. Pero seamos honestos - eso también es lo más fácil de eliminar. ¿Podemos hacerlo mejor? En este artículo, te mostraremos una técnica de marca de agua usando modelos de embedding que puede tanto firmar como detectar contenido original. Esto no es solo otro cliché de búsqueda/RAG - aprovecha características únicas de jina-embeddings-v3 como el contexto largo y la alineación multilingüe para crear un sistema de autenticación robusto, y nos permite mantener una verificación de contenido confiable a través de transformaciones como el parafraseo por LLM o incluso la traducción.
tagEntendiendo las Marcas de Agua en Texto
Las marcas de agua digitales han sido una piedra angular de la protección de contenido durante años. Cuando encuentras un meme con un logo semitransparente superpuesto, estás viendo la forma más básica de marca de agua en imágenes. Las técnicas modernas de marca de agua han evolucionado mucho más allá de simples superposiciones visuales – muchas son ahora imperceptibles para los observadores humanos mientras siguen siendo legibles por máquinas.
La marca de agua en texto sigue principios similares pero opera en el espacio semántico. En lugar de alterar píxeles, una marca de agua de texto modifica sutilmente el contenido de manera que preserva el significado original mientras incrusta una firma detectable. Así que los requisitos clave para una marca de agua de texto efectiva son:
- Preservación semántica: El texto con marca de agua debe mantener su significado y legibilidad original, tal como una marca de agua visual no debería oscurecer los elementos clave de una imagen.
- Imperceptibilidad: La marca de agua debe ser imperceptible para los lectores humanos, asegurando que no puedan preservarla o eliminarla intencionalmente durante la transformación del contenido.
- Detectable por máquina: Aunque la marca de agua pueda ser sutil para los lectores humanos, debe crear patrones claros y medibles que los algoritmos puedan identificar de manera confiable.
- Invariante a transformaciones: Cualquier transformación del contenido (como parafraseo o traducción), ya sea intencional o inconsciente de la existencia de la marca de agua, debe preservar la marca de agua o requerir cambios tan sustanciales que altere fundamentalmente la estructura o significado del contenido original.
tagUsando Embeddings para Marca de Agua en Texto
Vamos a construir un sistema de marca de agua en texto usando embeddings. Primero, definamos los componentes clave de este sistema:
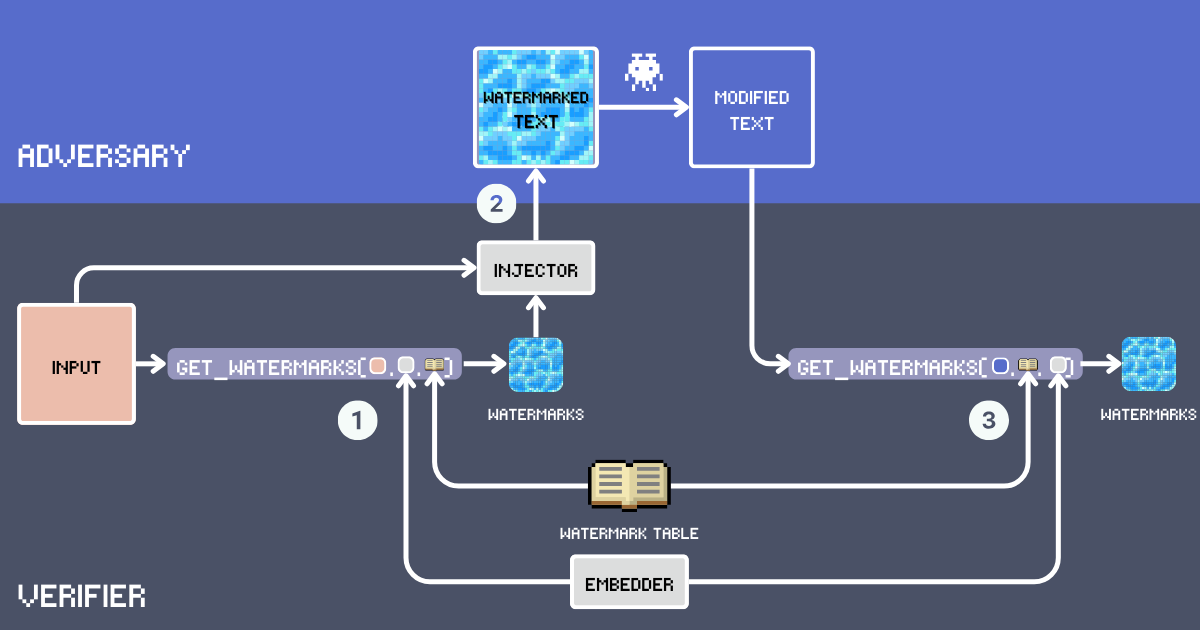
- Input: El texto original a marcar.
- Tabla de Marcas de Agua: Un léxico secreto que contiene palabras candidatas para marca de agua. Para una efectividad óptima, las palabras deben ser lo suficientemente comunes para encajar naturalmente en varios contextos. El vocabulario excluye palabras funcionales, nombres propios y palabras raras que podrían parecer fuera de lugar, por ejemplo,
delve into,embarkson buenos candidatos mientras quegoodes demasiado común. A continuación, construiremos nuestra WatermarkTable usando palabras del vocabulario inglés avanzado. - Embedder: Un modelo de embedding que sirve dos propósitos: selecciona palabras semánticamente apropiadas de la
WatermarkTablebasándose en el texto deinputy ayuda a detectar marcas de agua en texto potencialmente parafraseado. Usamos jina-embeddings-v3 porque maneja muy bien tanto textos súper largos como diferentes idiomas. Esto significa que podemos marcar documentos extensos y aun así atrapar a los copiones incluso si traducen el texto. - Marcas de agua: Palabras seleccionadas de la WatermarkTable calculando la similitud del coseno entre el embedding del texto de entrada y los embeddings en la tabla. El número de palabras está determinado por una ratio de inserción, típicamente 12% del conteo de palabras del input.
- Inyector: Un LLM que sigue instrucciones e integra las palabras de marca de agua en el texto de entrada mientras mantiene la coherencia, precisión factual, fluidez natural y distribución uniforme de las palabras de marca de agua a lo largo del texto.
- Texto Marcado: La salida después de que el Inyector inserta las palabras de marca de agua en el
input. - Adversario (Robo de Contenido): Una entidad que intenta reutilizar el texto marcado sin atribución, típicamente mediante parafraseo, traducción o ediciones menores. Hoy en día, esto simplemente significa usar un LLM con el prompt
Paraphrase [text]para reescritura automatizada. - Texto Modificado: El resultado después de las modificaciones del adversario al texto marcado. Este es el texto que necesitamos verificar en busca de marcas de agua.
tagAlgoritmo


tagConclusión
A partir de estos ejemplos, podemos ver que nuestro sistema de marcas de agua basado en embeddings es bastante robusto incluso con esta configuración básica. Lo particularmente notable es que las marcas de agua siguen siendo detectables incluso después de la traducción. Esta robustez entre idiomas es posible gracias a las potentes capacidades multilingües del modelo jina-embeddings-v3; sin fuertes capacidades multilingües y translingüísticas, tal persistencia a través de la traducción no sería posible.
Hay varias formas de mejorar la precisión y robustez de este sistema de marcas de agua. Primero, la tabla de marcas de agua podría expandirse y construirse cuidadosamente para asegurar la diversidad. Esto es importante porque un vocabulario más grande y diverso proporciona una mejor cobertura de espacios semánticos, facilitando la búsqueda de marcas de agua contextualmente apropiadas para cualquier texto mientras se reduce el riesgo de patrones repetitivos u obvios.
El componente Injector podría mejorarse implementando estrategias de inserción más sofisticadas. Por ejemplo, podría instruirse para distribuir las marcas de agua uniformemente a lo largo del texto para mantener la imperceptibilidad. Además, podríamos emplear la técnica de late chunking para generar marcas de agua para segmentos o oraciones individuales, permitiendo que el Injector tome decisiones más matizadas sobre la ubicación de las marcas de agua. Esto ayudaría a mantener tanto la imperceptibilidad general como la coherencia semántica en el texto final.
Para los lectores interesados en una exploración más profunda, "POSTMARK: A Robust Blackbox Watermark for Large Language Models" (Chang et al., EMNLP 2024) presenta un marco integral que incluye formulaciones matemáticas y experimentos extensos. Los autores exploran sistemáticamente la construcción del vocabulario de marcas de agua, las estrategias óptimas de inserción y la robustez contra varios tipos de ataques. También analizan exhaustivamente el equilibrio entre la detección de marcas de agua y la calidad del texto mediante evaluación tanto automatizada como humana.
