
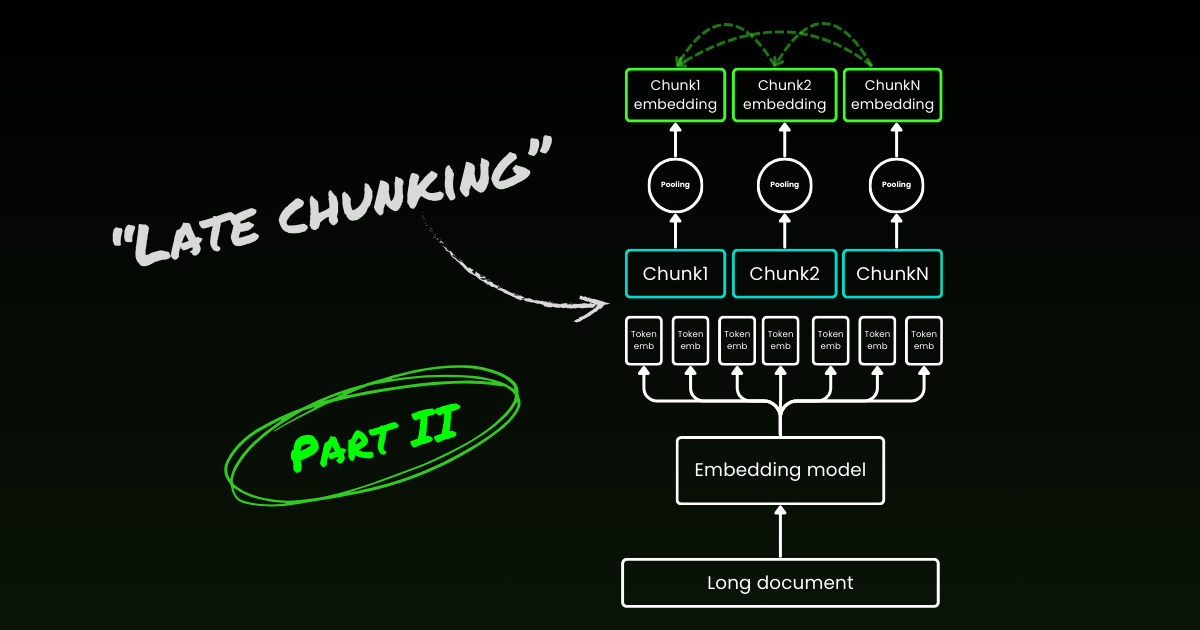

La segmentación de un documento largo tiene dos problemas: primero, determinar los puntos de corte, es decir, cómo segmentar el documento. Se pueden considerar longitudes fijas de tokens, un número fijo de oraciones o técnicas más avanzadas como expresiones regulares o modelos de segmentación semántica. Los límites precisos de los segmentos no solo mejoran la legibilidad de los resultados de búsqueda, sino que también aseguran que los segmentos alimentados a un LLM en un sistema RAG sean precisos y suficientes, ni más ni menos.
El segundo problema es la pérdida de contexto dentro de cada segmento. Una vez que el documento está segmentado, el siguiente paso lógico para la mayoría de las personas es incrustar cada segmento por separado en un proceso por lotes. Sin embargo, esto lleva a una pérdida del contexto global del documento original. Muchos trabajos anteriores han abordado primero el primer problema, argumentando que una mejor detección de límites mejora la representación semántica. Por ejemplo, la "segmentación semántica" agrupa oraciones con alta similitud de coseno en el espacio de incrustación para minimizar la disrupción de unidades semánticas.
Desde nuestro punto de vista, estos dos problemas son casi ortogonales y pueden abordarse por separado. Si tuviéramos que priorizar, diríamos que el segundo problema es más crítico.
| Problema 2: Información contextual | |||
|---|---|---|---|
| Preservada | Perdida | ||
| Problema 1: Puntos de corte | Buenos | Escenario ideal | Resultados de búsqueda pobres |
| Pobres | Buenos resultados de búsqueda, pero los resultados pueden no ser legibles para humanos o para razonamiento LLM | Peor escenario posible |
tagLate Chunking para la Pérdida de Contexto
El late chunking comienza abordando el segundo problema: la pérdida de contexto. No se trata de encontrar los puntos de corte ideales o límites semánticos. Aún necesitas usar expresiones regulares, heurísticas u otras técnicas para dividir un documento largo en pequeños segmentos. Pero en lugar de incrustar cada segmento tan pronto como se segmenta, el late chunking primero codifica todo el documento en una ventana de contexto (para jina-embeddings-v3 es de 8192 tokens). Luego, sigue las señales de límites para aplicar el agrupamiento medio para cada segmento, de ahí el término "late" en late chunking.

tagEl Late Chunking es Resistente a Señales de Límites Deficientes
Lo realmente interesante es que los experimentos muestran que el late chunking elimina la necesidad de límites semánticos perfectos, lo que aborda parcialmente el primer problema mencionado anteriormente. De hecho, el late chunking aplicado a límites de tokens fijos supera al chunking ingenuo con señales de límites semánticos. Los modelos de segmentación simples, como los que usan límites de longitud fija, funcionan a la par de los algoritmos avanzados de detección de límites cuando se combinan con late chunking. Probamos tres tamaños diferentes de modelos de incrustación, y los resultados muestran que todos ellos se benefician consistentemente del late chunking en todos los conjuntos de datos de prueba. Dicho esto, el modelo de incrustación en sí sigue siendo el factor más significativo en el rendimiento: no hay un solo caso en el que un modelo más débil con late chunking supere a un modelo más fuerte sin él.

jina-embeddings-v2-small con señales de límite de longitud de token fija y chunking ingenuo). Como parte de un estudio de ablación, probamos late chunking con diferentes señales de límites (longitud de token fija, límites de oraciones y límites semánticos) y diferentes modelos (jina-embeddings-v2-small, nomic-v1, y jina-embeddings-v3). Basado en su rendimiento en MTEB, la clasificación de estos tres modelos de incrustación es: jina-embeddings-v2-small < nomic-v1 < jina-embeddings-v3. Sin embargo, el objetivo de este experimento no es evaluar el rendimiento de los modelos de embedding en sí, sino entender cómo un mejor modelo de embedding interactúa con el chunking tardío y las señales de límites. Para los detalles del experimento, por favor consulte nuestro paper de investigación.| Combo | SciFact | NFCorpus | FiQA | TRECCOVID |
|---|---|---|---|---|
| Baseline | 64.2 | 23.5 | 33.3 | 63.4 |
| Late | 66.1 | 30.0 | 33.8 | 64.7 |
| Nomic | 70.7 | 35.3 | 37.0 | 72.9 |
| Jv3 | 71.8 | 35.6 | 46.3 | 73.0 |
| Late + Nomic | 70.6 | 35.3 | 38.3 | 75.0 |
| Late + Jv3 | 73.2 | 36.7 | 47.6 | 77.2 |
| SentBound | 64.7 | 28.3 | 30.4 | 66.5 |
| Late + SentBound | 65.2 | 30.0 | 33.9 | 66.6 |
| Nomic + SentBound | 70.4 | 35.3 | 34.8 | 74.3 |
| Jv3 + SentBound | 71.4 | 35.8 | 43.7 | 72.4 |
| Late + Nomic + SentBound | 70.5 | 35.3 | 36.9 | 76.1 |
| Late + Jv3 + SentBound | 72.4 | 36.6 | 47.6 | 76.2 |
| SemanticBound | 64.3 | 27.4 | 30.3 | 66.2 |
| Late + SemanticBound | 65.0 | 29.3 | 33.7 | 66.3 |
| Nomic + SemanticBound | 70.4 | 35.3 | 34.8 | 74.3 |
| Jv3 + SemanticBound | 71.2 | 36.1 | 44.0 | 74.7 |
| Late + Nomic + SemanticBound | 70.5 | 36.9 | 36.9 | 76.1 |
| Late + Jv3 + SemanticBound | 72.4 | 36.6 | 47.6 | 76.2 |
Ten en cuenta que ser resiliente a límites deficientes no significa que podamos ignorarlos—siguen siendo importantes tanto para la legibilidad humana como para los LLM. Así es como lo vemos: al optimizar la segmentación, es decir, el primer problema mencionado anteriormente, podemos enfocarnos completamente en la legibilidad sin preocuparnos por la pérdida semántica/contextual. El Chunking Tardío maneja bien o mal los puntos de corte, así que la legibilidad es todo lo que necesitas considerar.
tagEl Chunking Tardío es Bidireccional
Otro malentendido común sobre el chunking tardío es que sus embeddings condicionales de chunks dependen solo de los chunks anteriores sin "mirar adelante". Esto es incorrecto. La dependencia condicional en el chunking tardío es realmente bidireccional, no unidireccional. Esto se debe a que la matriz de atención en el modelo de embedding—un transformador de solo codificador—está completamente conectada, a diferencia de la matriz triangular enmascarada utilizada en modelos autorregresivos. Formalmente, el embedding del chunk , , en lugar de , donde denota una factorización del modelo de lenguaje. Esto también explica por qué el chunking tardío no depende de la ubicación precisa de los límites.

tagEl Chunking Tardío Puede Ser Entrenado
El chunking tardío no requiere entrenamiento adicional para los modelos de embedding. Puede aplicarse a cualquier modelo de embedding de contexto largo que use agrupación media, haciéndolo muy atractivo para los profesionales. Dicho esto, si estás trabajando en tareas como respuesta a preguntas o recuperación de documentos por consulta, el rendimiento aún puede mejorarse más con algo de ajuste fino. Específicamente, los datos de entrenamiento consisten en tuplas que contienen:
- Una consulta (por ejemplo, una pregunta o término de búsqueda).
- Un documento que contiene información relevante para responder la consulta.
- Un segmento relevante dentro del documento, que es el fragmento específico de texto que responde directamente a la consulta.
El modelo se entrena emparejando consultas con sus segmentos relevantes, usando una función de pérdida contrastiva como InfoNCE. Esto asegura que los segmentos relevantes estén estrechamente alineados con la consulta en el espacio de embeddings, mientras que los segmentos no relacionados se alejan. Como resultado, el modelo aprende a enfocarse en las partes más relevantes del documento al generar embeddings de chunks. Para más detalles, consulte nuestro paper de investigación.
tagChunking Tardío vs. Recuperación Contextual
Poco después de que se introdujo el chunking tardío, Anthropic presentó una estrategia separada llamada Recuperación Contextual. El método de Anthropic es un enfoque de fuerza bruta para abordar el problema del contexto perdido, y funciona de la siguiente manera:
- Cada chunk se envía al LLM junto con el documento completo.
- El LLM agrega contexto relevante a cada chunk.
- Esto resulta en embeddings más ricos e informativos.
En nuestra opinión, esto es esencialmente enriquecimiento de contexto, donde el contexto global se codifica explícitamente en cada chunk usando un LLM, lo cual es costoso en términos de costo, tiempo y almacenamiento. Además, no está claro si este enfoque es resiliente a los límites de los chunks, ya que el LLM depende de chunks precisos y legibles para enriquecer el contexto de manera efectiva. En contraste, el chunking tardío es altamente resiliente a las señales de límites, como se demostró anteriormente. No requiere almacenamiento adicional ya que el tamaño del embedding permanece igual. A pesar de aprovechar la longitud completa del contexto del modelo de embedding, sigue siendo significativamente más rápido que usar un LLM para generar enriquecimiento. En el estudio cualitativo de nuestro paper de investigación, mostramos que la recuperación contextual de Anthropic tiene un rendimiento similar al chunking tardío. Sin embargo, el chunking tardío proporciona una solución más de bajo nivel, genérica y natural al aprovechar la mecánica inherente del transformador de solo codificador.
tag¿Qué Modelos de Embedding Soportan el Chunking Tardío?
El chunking tardío no es exclusivo de jina-embeddings-v3 o v2. Es un enfoque bastante genérico que puede aplicarse a cualquier modelo de embedding de contexto largo que use agrupación media. Por ejemplo, en esta publicación, mostramos que nomic-v1 también lo soporta. Damos una cálida bienvenida a todos los proveedores de embeddings para que implementen soporte para el chunking tardío en sus soluciones.
Como usuario de modelos, al evaluar un nuevo modelo de embedding o API, puedes seguir estos pasos para verificar si podría soportar chunking tardío:
- Salida Única: ¿El modelo/API te da solo un embedding final por oración en lugar de embeddings a nivel de token? Si es así, probablemente no pueda soportar late chunking (especialmente para esas APIs web).
- Soporte de Contexto Largo: ¿El modelo/API maneja contextos de al menos 8192 tokens? Si no, el late chunking no será aplicable—o más precisamente, no tiene sentido adaptar late chunking para un modelo de contexto corto. Si es así, asegúrate de que realmente funcione bien con contextos largos, no solo que afirme soportarlos. Normalmente puedes encontrar esta información en el informe técnico del modelo, como evaluaciones en LongMTEB u otros benchmarks de contexto largo.
- Mean Pooling: Para modelos autohospedados o APIs que proporcionan embeddings a nivel de token antes del pooling, verifica si el método de pooling predeterminado es mean pooling. Los modelos que usan CLS o max pooling no son compatibles con late chunking.
En resumen, si un modelo de embedding soporta contexto largo y usa mean pooling por defecto, puede soportar fácilmente late chunking. Consulta nuestro repositorio de GitHub para detalles de implementación y más discusión.
tagConclusión
Entonces, ¿qué es late chunking? Late chunking es un método sencillo para generar embeddings de chunks utilizando modelos de embedding de contexto largo. Es rápido, resistente a las señales de límites y altamente efectivo. No es una heurística ni una sobreingeniería—es un diseño reflexivo basado en una comprensión profunda del mecanismo transformer.
Hoy en día, el bombo publicitario alrededor de los LLMs es innegable. En muchos casos, problemas que podrían abordarse eficientemente con modelos más pequeños como BERT son en cambio delegados a LLMs, impulsados por el atractivo de soluciones más grandes y complejas. No es sorprendente que los grandes proveedores de LLM impulsen una mayor adopción de sus modelos, mientras que los proveedores de embeddings aboguen por los embeddings — ambos juegan según sus fortalezas comerciales. Pero al final, no se trata del bombo publicitario, sino de la acción, de lo que realmente funciona. Dejemos que la comunidad, la industria y, lo más importante, el tiempo revelen qué enfoque es verdaderamente más eficiente, más ligero y construido para perdurar.
Asegúrate de leer nuestro paper de investigación, y te animamos a que evalúes late chunking en varios escenarios y compartas tus comentarios con nosotros.
