




La Conferencia Internacional sobre Aprendizaje Automático es una de las conferencias más prestigiosas en la comunidad de aprendizaje automático e inteligencia artificial y celebró su reunión de 2024 en Viena del 21 al 27 de julio de este año.

La conferencia fue una experiencia intensiva de aprendizaje de 7 días, con presentaciones orales y oportunidades para intercambiar ideas directamente con otros investigadores. Hay una gran cantidad de trabajo interesante en curso en aprendizaje por refuerzo, IA para ciencias de la vida, aprendizaje de representaciones, modelos multimodales y, por supuesto, en elementos fundamentales del desarrollo de modelos de IA. De particular importancia fue el tutorial sobre la Física de los Modelos de Lenguaje Grandes, que exploró extensivamente el funcionamiento interno de los LLMs y ofreció respuestas convincentes a la pregunta de si los LLMs memorizan información o aplican razonamiento al decir las cosas.
tagNuestro Trabajo en Jina-CLIP-v1
Realizamos una presentación de póster sobre el trabajo detrás de nuestro nuevo modelo multimodal jina-clip-v1 como parte del taller Multi-modal Foundation Models meet Embodied AI.
Reunirnos y discutir nuestro trabajo con colegas internacionales que trabajan en muchos campos fue muy inspirador. Nuestra presentación recibió muchos comentarios positivos, con muchas personas interesadas en la forma en que Jina CLIP unifica los paradigmas de aprendizaje contrastivo multimodal y unimodal. Las discusiones abarcaron desde las limitaciones de la arquitectura CLIP hasta extensiones a modalidades adicionales y aplicaciones en el emparejamiento de péptidos y proteínas.
Michael Günther presenta Jina CLIP
tagNuestros Favoritos
Tuvimos la oportunidad de discutir muchos proyectos y presentaciones de otros investigadores, y aquí están algunos de nuestros favoritos:
tagPlan Like a Graph (PLaG)
Muchas personas conocen el "Few-Shot Prompting" o el "Chain of Thought prompting". Fangru Lin presentó un método nuevo y mejor en ICML: Plan Like a Graph (PLaG).
Su idea es simple: una tarea dada a un LLM se descompone en subtareas que un LLM puede resolver ya sea en paralelo o secuencialmente. Estas subtareas forman un grafo de ejecución. Ejecutar el grafo completo resuelve la tarea de alto nivel.
En el video anterior, Fangru Lin explica el método usando un ejemplo fácil de entender. Ten en cuenta que aunque esto mejora tus resultados, los LLMs siguen sufriendo una degradación drástica cuando aumenta la complejidad de las tareas. Dicho esto, sigue siendo un gran paso en la dirección correcta y proporciona beneficios prácticos inmediatos.
Para nosotros, es interesante ver cómo su trabajo tiene paralelismos con nuestras aplicaciones de prompts en Jina AI. Ya hemos implementado una estructura de prompts similar a un grafo, sin embargo, generar dinámicamente un grafo de ejecución como ella lo hizo es una nueva dirección que exploraremos.
tagDescubriendo Entornos con XRM
Este artículo presenta un algoritmo simple para descubrir entornos de entrenamiento que pueden hacer que un modelo se base en características que se correlacionan con las etiquetas pero no inducen una clasificación/relevancia precisa. Un ejemplo famoso es el conjunto de datos de aves acuáticas (ver arXiv:1911.08731), que contiene fotos de aves con diferentes fondos que deben clasificarse como aves acuáticas o terrestres. Durante el entrenamiento, el clasificador detecta si el fondo de las imágenes muestra agua o no, en lugar de basarse en las características de las aves mismas. Tal modelo clasificará erróneamente a las aves acuáticas si no hay agua en el fondo.
Para mitigar este comportamiento, es necesario detectar muestras donde el modelo se basa en características de fondo engañosas. Este artículo presenta el algoritmo XRM para hacer esto.
El algoritmo entrena dos modelos en dos partes distintas del conjunto de datos de entrenamiento. Durante el entrenamiento, las etiquetas de algunas muestras se invierten. Específicamente, esto ocurre si el otro modelo (que no está entrenado en la muestra respectiva) clasifica una muestra de manera diferente. De esta manera, se anima a los modelos a basarse en correlaciones espurias. Posteriormente, puedes extraer muestras de los datos de entrenamiento donde una etiqueta predicha por uno de los modelos difiere de la verdad fundamental. Más adelante, uno puede usar esta información para entrenar modelos de clasificación más robustos, por ejemplo, con el algoritmo Group DRO.
tag¡Reduce tus Costos de Evaluación de LLM en un Factor de 140!
Sí, lo has oído bien. Con este truco, el costo de la Evaluación de LLM puede reducirse a una pequeña fracción.
La idea central es simple: Eliminar todas las muestras de evaluación que prueben la misma capacidad del modelo. Las matemáticas detrás son menos directas pero están bien explicadas por Felipe Maia Polo quien presentó su trabajo durante la sesión de pósters. Ten en cuenta que la reducción por un factor de 140 se aplica al popular conjunto de datos MMLU (Massive Multitask Language Understanding). Para tus propios conjuntos de datos de evaluación, depende de cuánto se correlacionan entre sí los resultados de evaluación de las muestras. Tal vez puedas omitir muchas muestras o solo unas pocas.
Solo inténtalo. Te mantendremos informado sobre cuánto pudimos reducir las muestras de evaluación en Jina AI.
tagContrastando Múltiples Representaciones con la Brecha de Coincidencia Multi-Marginal
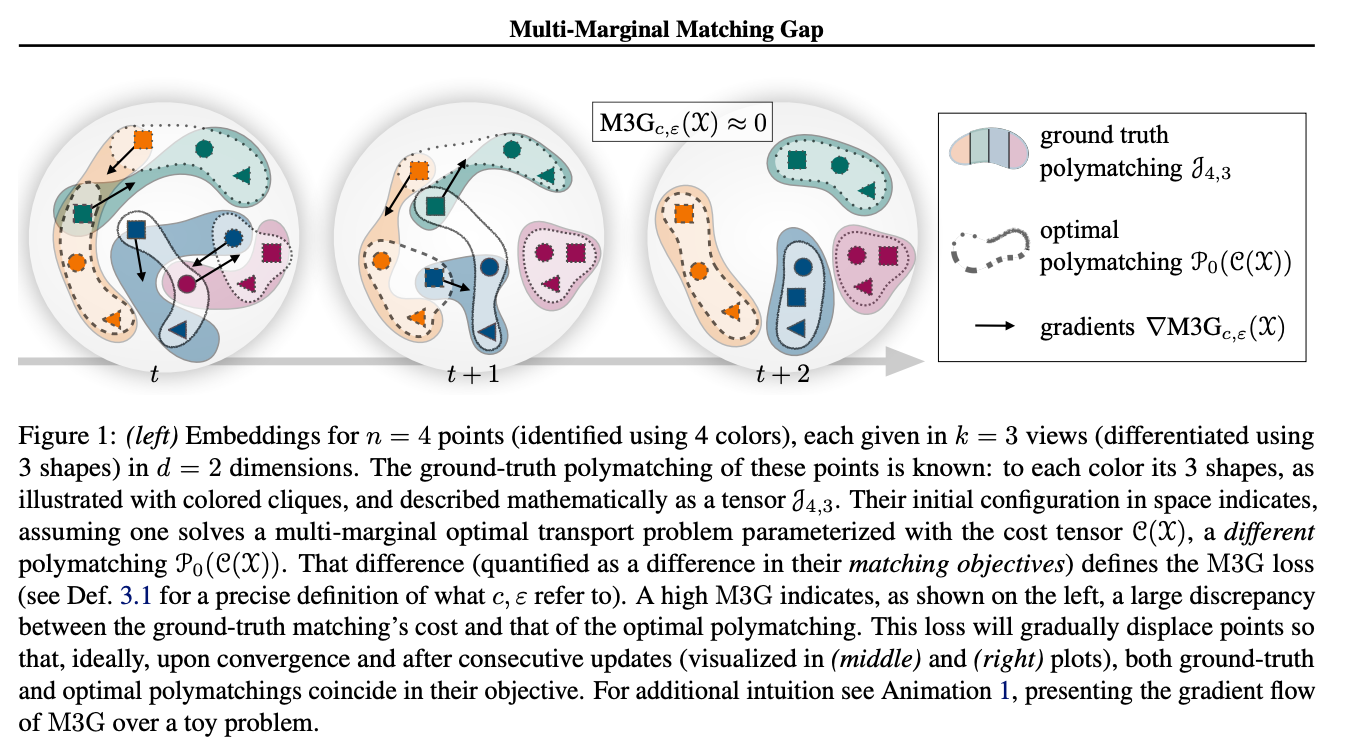
Este trabajo aborda un desafío común en el aprendizaje contrastivo: La mayoría de las funciones de pérdida contrastiva como la pérdida InfoNCE operan en pares de puntos de datos y miden la distancia entre pares positivos. Para expandir las tuplas positivas de tamaño k > 2, el aprendizaje contrastivo generalmente intenta reducir el problema a múltiples pares y acumular pérdidas por pares para todos los pares positivos. Los autores aquí proponen la pérdida M3G (Multi-Marginal Matching Gap), una versión modificada del algoritmo Sinkhorn, que resuelve el problema de Transporte Óptimo Multi-Marginal. Esta función de pérdida puede usarse en escenarios donde los conjuntos de datos consisten en tuplas positivas con tamaño k > 2, por ejemplo, >2 imágenes del mismo objeto, problemas multimodales con tres o más modalidades, o una extensión SimCLR con tres o más aumentaciones de la misma imagen. Los resultados empíricos muestran que este método supera la reducción ingenua del problema a pares.
tag¡No Se Necesita Verdad Fundamental!
Zachary Robertson de Stanford University presentó su trabajo sobre evaluar tu LLM sin ningún dato etiquetado. Ten en cuenta que aunque este es un trabajo teórico, tiene mucho potencial para la supervisión escalable de sistemas avanzados de IA. Esto no es para usuarios casuales de LLM, pero si trabajas en evaluación de LLM, definitivamente es algo que querrás investigar. Ya podemos ver que podríamos evaluar nuestros agentes en Jina AI de esta manera. Compartiremos los resultados una vez que ejecutemos los primeros experimentos.
tag¿Es Inevitable el Colapso del Modelo? Rompiendo la Maldición de la Recursión Acumulando Datos Reales y Sintéticos
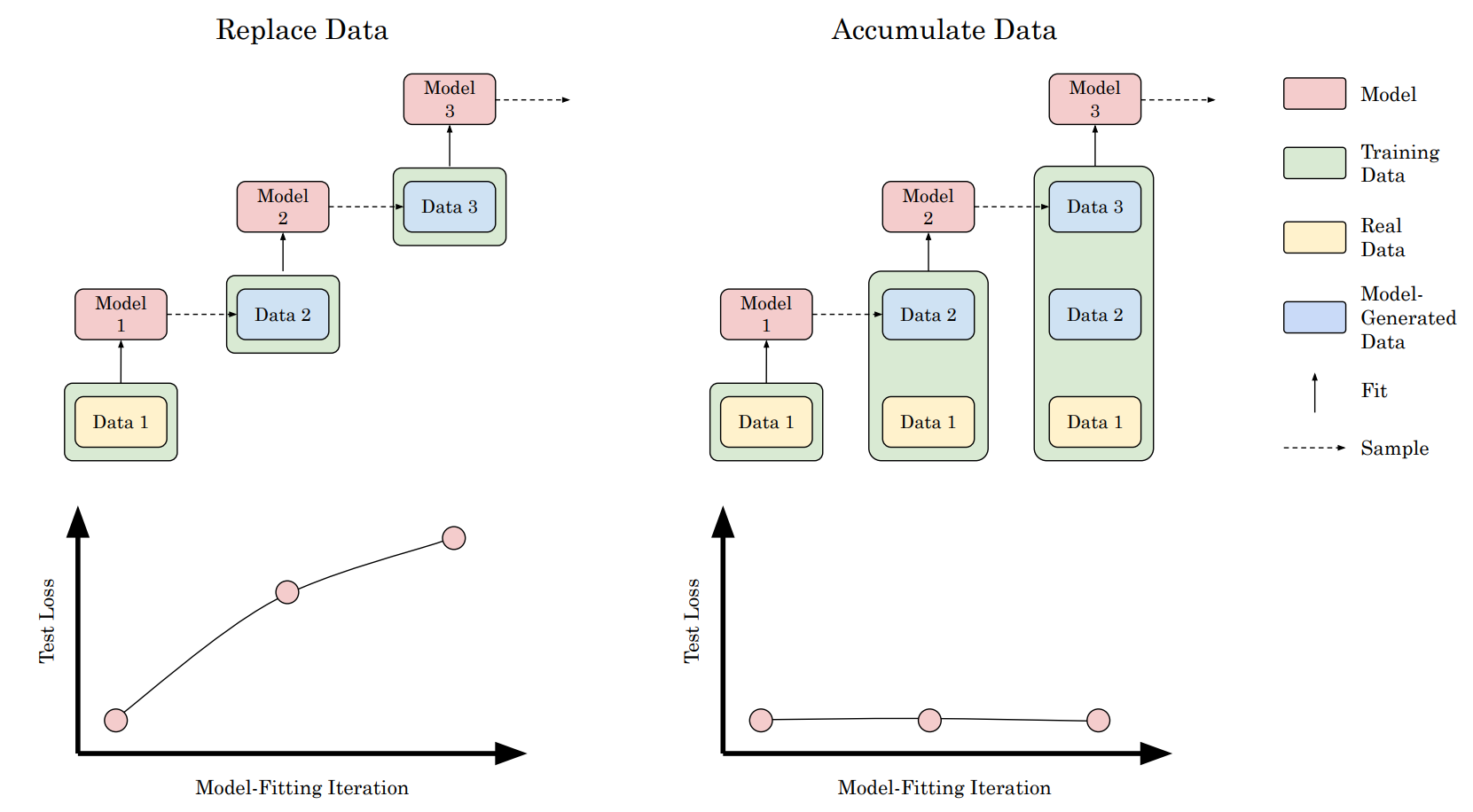
Varios artículos (como este artículo de Nature) han predicho recientemente que el rendimiento de los modelos recién entrenados puede empeorar con el tiempo debido a que los datos de entrenamiento extraídos de la web contienen una cantidad cada vez mayor de datos sintéticos.
Nuestro colega Scott Martens también ha publicado un artículo sobre el colapso de modelos y ha discutido casos donde los datos sintéticos pueden ser útiles para el entrenamiento de modelos.

Los entrenamientos de modelos podrían colapsar porque los datos de entrenamiento son producidos por una versión anterior del modelo o un modelo entrenado con los mismos datos. Este artículo realiza experimentos que muestran una imagen ligeramente diferente: Un colapso solo ocurre cuando se reemplazan datos reales con sintéticos, lo cual se hizo en experimentos anteriores. Sin embargo, cuando se aumentan los datos reales con datos sintéticos adicionales, no hay cambios medibles en el rendimiento de los modelos resultantes. Estos resultados sugieren que algo como el colapso del modelo no sucederá. Sin embargo, nuevamente prueba que usar datos sintéticos adicionales no ayudará a entrenar un modelo que sea generalmente superior al modelo usado para crear dichos puntos de datos sintéticos.
tagLa Cirugía Cerebral para la IA Ya es Posible
Digamos que quieres predecir la profesión de alguien pero no su género. Este trabajo de Google Research, ETH Zürich, International Institute of Information Technology Hyderabad (IIITH) y Bar-Ilan University muestra cómo los vectores de dirección y el emparejamiento de covarianza pueden usarse para controlar el sesgo.
tagMagicLens - Recuperación de Imágenes Auto-Supervisada con Instrucciones Abiertas

Este artículo presenta los modelos MagicLens, una serie de modelos de recuperación de imágenes auto-supervisados entrenados en tripletes de imagen de consulta + instrucción + imagen objetivo.
Los autores introducen un pipeline de recolección/curación de datos que recopila pares de imágenes de la web y usa LLMs para sintetizar instrucciones de texto abiertas que vinculan las imágenes con diversas relaciones semánticas más allá de la mera similitud visual. Este pipeline se usa para producir 36.7M tripletes de alta calidad sobre una amplia distribución. El conjunto de datos se usa luego para entrenar una arquitectura simple de codificador dual con parámetros compartidos. Los codificadores base de visión y lenguaje se inicializan con variantes base y grandes de CoCa o CLIP. Se introduce un único pooler de atención multi-cabezal para comprimir las dos entradas multimodales en una sola incrustación. El objetivo del entrenamiento contrasta el par de imagen-consulta e instrucción con la imagen-objetivo y la instrucción de cadena vacía con una simple pérdida InfoNCE para entrenar MagicLens. Los autores presentan resultados de evaluación en recuperación de imágenes basada en instrucciones.
tagPrompt Sketching - La Nueva Forma de Prompting
La forma en que hacemos prompting a los LLMs está cambiando. Prompt Sketching nos permite dar restricciones fijas a los modelos generativos. En lugar de solo proporcionar una instrucción y esperar que el modelo haga lo que queremos, defines una plantilla completa, forzando al modelo a generar lo que deseas.
No confundas esto con LLMs fine-tuneados para proporcionar un formato JSON estructurado. Con el enfoque de fine-tuning, el modelo aún tiene la libertad de generar lo que quiera. No así con Prompt Sketching. Proporciona un conjunto de herramientas completamente nuevo para los ingenieros de prompts y abre áreas de investigación que necesitan ser exploradas. En el video anterior, Mark Müller explica en detalle de qué se trata este nuevo paradigma.
También puedes consultar su proyecto de código abierto LMQL.
tagRepoformer - Recuperación Selectiva para Completado de Código a Nivel de Repositorio
Para muchas consultas, RAG realmente no ayuda al modelo porque la consulta es demasiado fácil o el sistema de recuperación no puede encontrar documentos relevantes, posiblemente porque no existen. Esto lleva a tiempos de generación más largos y menor rendimiento si el modelo se basa en fuentes engañosas o ausentes.
Este artículo aborda el problema permitiendo que los LLMs se autoevalúen para determinar si la recuperación es útil. Demuestran este enfoque en un modelo de completado de código que está entrenado para llenar un hueco en una plantilla de código. Para una plantilla dada, el sistema primero decide si los resultados de recuperación son útiles y, si es así, llama al recuperador. Finalmente, el LLM de código genera el contexto faltante ya sea que se agreguen o no resultados de recuperación a su prompt.
tagLa Hipótesis de la Representación Platónica

La Hipótesis de la Representación Platónica argumenta que los modelos de redes neuronales tenderán a converger hacia una representación común del mundo. Tomando prestada la Teoría de las Formas de Platón, la idea de que existe un reino de "ideales", que se nos aparece en una forma distorsionada que solo podemos observar indirectamente, los autores afirman que nuestros modelos de IA parecen converger en una única representación de la realidad, independientemente de la arquitectura de entrenamiento, los datos de entrenamiento o incluso la modalidad de entrada. Cuanto mayor es la escala de los datos y el tamaño del modelo, más similares parecen ser sus representaciones.
Los autores consideran las representaciones vectoriales y miden el alineamiento de representaciones utilizando métricas de alineamiento de kernel, específicamente una métrica de vecinos más cercanos mutuos que mide la intersección media de los conjuntos de k vecinos más cercanos inducidos por dos kernels, K1 y K2, normalizada por k. Este trabajo presenta evidencia empírica de que a medida que el tamaño de los modelos y conjuntos de datos crece y el rendimiento mejora, los kernels se vuelven más alineados. Este alineamiento también puede observarse incluso cuando se comparan modelos de diferentes modalidades, como modelos de texto y modelos de imagen.
tagResumen
Parte del entusiasmo inicial que vino con la ley de escalamiento está comenzando a disminuir, pero ICML 2024 ha demostrado que tanto talento nuevo, diverso y creativo ha entrado en nuestro campo que podemos estar seguros de que el progreso está lejos de terminar.
La pasamos increíble en ICML 2024 y pueden apostar que volveremos en 2025 🇨🇦.





