Lector
Convierta una URL en una entrada compatible con LLM anteponiendo
r.jina.ai.API de lector
Convierta una URL en una entrada compatible con LLM anteponiendo
r.jina.ai.chevron_leftchevron_right
globe_book
Utilice
r.jina.ai para leer una URL y obtener su contenidotravel_explore
Utilice
s.jina.ai para buscar en la web y obtener SERP
Agregue
mcp.jina.ai como su servidor MCP para acceder a nuestra API en LLMupload
Pedido
GET
curl "https://r.jina.ai/https://www.example.com"
Jina VLM: Modelo de lenguaje de visión multilingüe pequeño
Un modelo de visión-lenguaje de parámetros 2.4B que logra respuestas visuales a preguntas multilingües de última generación entre VLM abiertos de escala 2B.

ReaderLM v2: un pequeño modelo de lenguaje para convertir HTML a Markdown y JSON
ReaderLM-v2 es un modelo de lenguaje de parámetros 1500 millones especializado en la conversión de HTML a Markdown y la extracción de HTML a JSON. Admite documentos de hasta 512 000 tokens en 29 idiomas y ofrece un 20 % más de precisión en comparación con su predecesor.


Integrar información web en los LLM es un paso fundamental para su integración, aunque puede resultar complejo. El método más sencillo consiste en extraer el contenido de la página web y generar el HTML sin procesar. Sin embargo, esta extracción puede ser compleja y a menudo se bloquea, y el HTML sin procesar suele estar saturado de elementos superfluos como marcado y scripts. La API Reader resuelve estos problemas extrayendo el contenido principal de una URL y convirtiéndolo en texto limpio y compatible con LLM, lo que garantiza una entrada de alta calidad para sus sistemas de agentes y RAG. La API Reader es una infraestructura para desarrolladores: convierte la URL que usted proporciona en texto compatible con LLM para que pueda crear sus propios sistemas de búsqueda, RAG y agentes. No es un motor de búsqueda para consumidores y no indexa ni clasifica la web en su nombre; usted controla qué URL se procesan y es responsable de cómo se utiliza el resultado.
HTML sin formato
Salida del lector

Reader se puede utilizar como API SERP. Le permite alimentar su LLM con el contenido detrás de la página del motor de resultados de búsqueda. Simplemente anteponga
https://s.jina.ai/?q= a su consulta y Reader buscará en la web y devolverá los cinco primeros resultados con sus URL y contenidos, cada uno en un texto limpio y compatible con LLM. De esta manera, puede mantener siempre actualizado su LLM, mejorar su veracidad y reducir las alucinaciones.info Tenga en cuenta que, a diferencia de la demostración que se muestra arriba, en la práctica no busca la pregunta original en la web para fundamentarse. Lo que la gente suele hacer es reescribir la pregunta original o utilizar preguntas de múltiples saltos. Leen los resultados recuperados y luego generan consultas adicionales para recopilar más información según sea necesario antes de llegar a una respuesta final.

Las imágenes de la página web se subtitulan automáticamente utilizando un modelo de lenguaje de visión en el lector y se formatean como etiquetas alternativas de imagen en la salida. Esto le brinda a su LLM posterior suficientes sugerencias para incorporar esas imágenes en sus procesos de razonamiento y resumen. Esto significa que puede hacer preguntas sobre las imágenes, seleccionar imágenes específicas o incluso reenviar sus URL a un VLM más potente para un análisis más profundo.
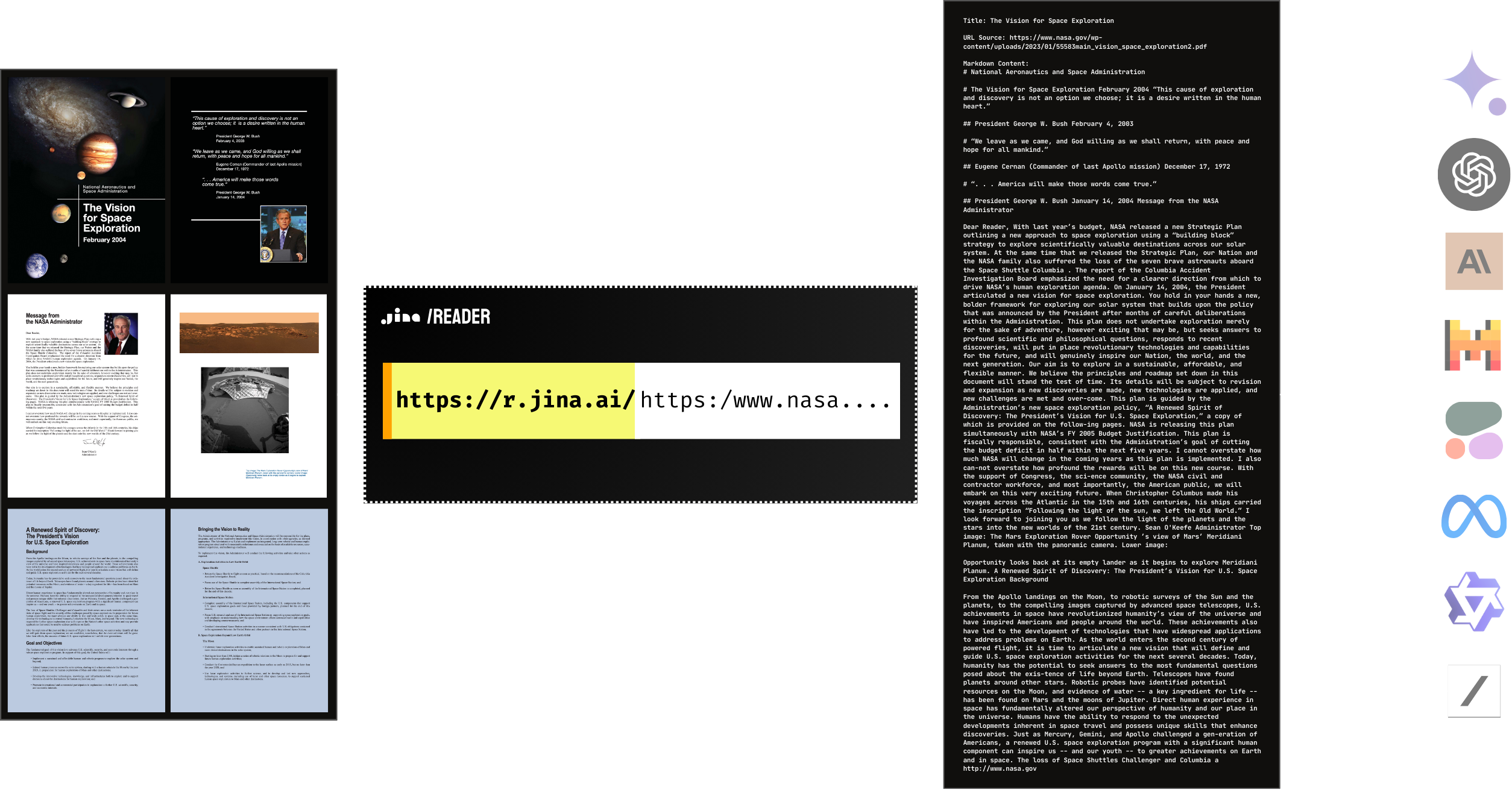
Sí, Reader admite de forma nativa la lectura de PDF. Es compatible con la mayoría de los archivos PDF, incluidos aquellos con muchas imágenes, ¡y es ultrarrápido! Combinado con un LLM, puede crear fácilmente un ChatPDF o una IA de análisis de documentos en poco tiempo.
¿La mejor parte? ¡Es gratis!
Reader API está disponible de forma gratuita y ofrece límites de tarifas y precios flexibles. Construido sobre una infraestructura escalable, ofrece alta accesibilidad, simultaneidad y confiabilidad. Nos esforzamos por ser su solución de conexión a tierra preferida para sus LLM.
Límite de velocidad
Los límites de velocidad se controlan de tres maneras: RPM (solicitudes por minuto) y TPM (tokens por minuto). Los límites se aplican por IP/clave API y se activan cuando se alcanza primero el umbral de RPM o TPM. Al proporcionar una clave API en el encabezado de la solicitud, controlamos los límites de velocidad por clave, no por dirección IP.
| Producto | Punto final de API | Descripciónarrow_upward | Sin clave APIkey_off | con clave API gratuitakey | con clave API de pagokey | con clave API Premiumkey | Latencia media | Recuento de uso de tokens | Solicitud Permitida | |
|---|---|---|---|---|---|---|---|---|---|---|
| API de lector | https://r.jina.ai | Convertir URL a texto compatible con LLM | 20 RPM | 500 RPM | 500 RPM | trending_up5000 RPM | 7.9s | Cuente la cantidad de tokens en la respuesta de salida. | GET/POST | |
| API de lector | https://s.jina.ai | Busque en la web y convierta los resultados en texto compatible con LLM | block | 100 RPM | 100 RPM | trending_up1000 RPM | 2.5s | Cada solicitud cuesta una cantidad fija de tokens, a partir de 10000 tokens | GET/POST | |
| API de incrustación | https://api.jina.ai/v1/embeddings | Convertir texto/imágenes en vectores de longitud fija | block | 100 RPM & 100,000 TPM | 500 RPM & 2,000,000 TPM | trending_up5,000 RPM & 50,000,000 TPM | ssid_chart depende del tamaño de entrada help | Cuente la cantidad de tokens en la solicitud de entrada. | POST | |
| API de reclasificación | https://api.jina.ai/v1/rerank | Clasificar documentos por consulta | block | 100 RPM & 100,000 TPM | 500 RPM & 2,000,000 TPM | trending_up5,000 RPM & 50,000,000 TPM | ssid_chart depende del tamaño de entrada help | Cuente la cantidad de tokens en la solicitud de entrada. | POST | |
| API de clasificador | https://api.jina.ai/v1/train | Entrenar un clasificador usando ejemplos etiquetados | block | 25 RPM & 25,000 TPM | 125 RPM & 500,000 TPM | 1,250 RPM & 12,000,000 TPM | ssid_chart depende del tamaño de entrada | Los tokens se cuentan como: input_tokens × num_iters | POST | |
| API de clasificador (Disparo cero) | https://api.jina.ai/v1/classify | Clasificar las entradas utilizando la clasificación de disparo cero | block | 25 RPM & 25,000 TPM | 125 RPM & 500,000 TPM | 1,250 RPM & 12,000,000 TPM | ssid_chart depende del tamaño de entrada | Los tokens se cuentan como: input_tokens + label_tokens | POST | |
| API de clasificador (Pocos disparos) | https://api.jina.ai/v1/classify | Clasifique las entradas utilizando un clasificador de pocos disparos entrenado | block | 25 RPM & 25,000 TPM | 125 RPM & 500,000 TPM | 1,250 RPM & 12,000,000 TPM | ssid_chart depende del tamaño de entrada | Los tokens se cuentan como: input_tokens | POST | |
| API de segmentación | https://api.jina.ai/v1/segment | Tokenizar y segmentar textos largos | 20 RPM | 200 RPM | 200 RPM | 1,000 RPM | 0.3s | El token no se cuenta como uso. | GET/POST | |
| Búsqueda profunda | https://deepsearch.jina.ai/v1/chat/completions | Razonar, buscar e iterar para encontrar la mejor respuesta. | block | 50 RPM | 50 RPM | 500 RPM | 56.7s | Cuente el número total de tokens en todo el proceso. | POST |





¡Que no cunda el pánico! ¡Cada nueva clave API contiene diez millones de tokens gratis!
Precios de API
El precio de la API se basa en el uso de tokens. Una clave API le otorga acceso a todos los productos de Search Foundation.

Con la API de Jina Search Foundation
La forma más sencilla de acceder a todos nuestros productos. Recarga tokens a medida que avanzas.
Recarga esta clave API con más tokens
Ingrese la clave API correcta para recargar
Entender el límite de velocidad
Los límites de velocidad son la cantidad máxima de solicitudes que se pueden realizar a una API en un minuto por dirección IP/clave API (RPM). Obtenga más información sobre los límites de velocidad para cada producto y nivel a continuación.
keyboard_arrow_down

¿Cuáles son los costos asociados con el uso de Reader API?
keyboard_arrow_down
¿Cómo funciona la API Reader?
keyboard_arrow_down
¿La API Reader es de código abierto?
keyboard_arrow_down
¿Cuál es la latencia típica de la API Reader?
keyboard_arrow_down
¿Por qué debería utilizar Reader API en lugar de raspar la página yo mismo?
keyboard_arrow_down
¿La API Reader admite varios idiomas?
keyboard_arrow_down
¿La API de Reader respeta los controles de acceso del sitio web?
keyboard_arrow_down
¿Puede la API Reader extraer contenido de archivos PDF?
keyboard_arrow_down
¿Puede la API Reader procesar contenido multimedia de páginas web?
keyboard_arrow_down
¿Es posible utilizar la API de Reader en archivos HTML locales?
keyboard_arrow_down
¿Reader API almacena en caché el contenido?
keyboard_arrow_down
¿Puedo usar Reader API para acceder al contenido tras un inicio de sesión?
keyboard_arrow_down
¿Puedo utilizar la API de Reader para acceder a PDF en arXiv?
keyboard_arrow_down
¿Cómo funciona el título de imagen en Reader?
keyboard_arrow_down
¿Cuál es la escalabilidad del Reader? ¿Puedo usarlo en producción?
keyboard_arrow_down
¿Cuál es el límite de velocidad de la API Reader?
keyboard_arrow_down
¿Qué es Reader-LM? ¿Cómo puedo utilizarlo?
keyboard_arrow_down
¿Cómo extraigo datos estructurados de páginas web?
keyboard_arrow_down
¿Reader elude activamente la protección anti-bots del sitio web?
keyboard_arrow_down
¿Actualizar de una clave API gratuita a una paga me dará acceso a más sitios web?
keyboard_arrow_down
Límite de velocidad
Los límites de velocidad se controlan de tres maneras: RPM (solicitudes por minuto) y TPM (tokens por minuto). Los límites se aplican por IP/clave API y se activan cuando se alcanza primero el umbral de RPM o TPM. Al proporcionar una clave API en el encabezado de la solicitud, controlamos los límites de velocidad por clave, no por dirección IP.
| Producto | Punto final de API | Descripciónarrow_upward | Sin clave APIkey_off | con clave API gratuitakey | con clave API de pagokey | con clave API Premiumkey | Latencia media | Recuento de uso de tokens | Solicitud Permitida | |
|---|---|---|---|---|---|---|---|---|---|---|
| API de lector | https://r.jina.ai | Convertir URL a texto compatible con LLM | 20 RPM | 500 RPM | 500 RPM | trending_up5000 RPM | 7.9s | Cuente la cantidad de tokens en la respuesta de salida. | GET/POST | |
| API de lector | https://s.jina.ai | Busque en la web y convierta los resultados en texto compatible con LLM | block | 100 RPM | 100 RPM | trending_up1000 RPM | 2.5s | Cada solicitud cuesta una cantidad fija de tokens, a partir de 10000 tokens | GET/POST | |
| API de incrustación | https://api.jina.ai/v1/embeddings | Convertir texto/imágenes en vectores de longitud fija | block | 100 RPM & 100,000 TPM | 500 RPM & 2,000,000 TPM | trending_up5,000 RPM & 50,000,000 TPM | ssid_chart depende del tamaño de entrada help | Cuente la cantidad de tokens en la solicitud de entrada. | POST | |
| API de reclasificación | https://api.jina.ai/v1/rerank | Clasificar documentos por consulta | block | 100 RPM & 100,000 TPM | 500 RPM & 2,000,000 TPM | trending_up5,000 RPM & 50,000,000 TPM | ssid_chart depende del tamaño de entrada help | Cuente la cantidad de tokens en la solicitud de entrada. | POST | |
| API de clasificador | https://api.jina.ai/v1/train | Entrenar un clasificador usando ejemplos etiquetados | block | 25 RPM & 25,000 TPM | 125 RPM & 500,000 TPM | 1,250 RPM & 12,000,000 TPM | ssid_chart depende del tamaño de entrada | Los tokens se cuentan como: input_tokens × num_iters | POST | |
| API de clasificador (Disparo cero) | https://api.jina.ai/v1/classify | Clasificar las entradas utilizando la clasificación de disparo cero | block | 25 RPM & 25,000 TPM | 125 RPM & 500,000 TPM | 1,250 RPM & 12,000,000 TPM | ssid_chart depende del tamaño de entrada | Los tokens se cuentan como: input_tokens + label_tokens | POST | |
| API de clasificador (Pocos disparos) | https://api.jina.ai/v1/classify | Clasifique las entradas utilizando un clasificador de pocos disparos entrenado | block | 25 RPM & 25,000 TPM | 125 RPM & 500,000 TPM | 1,250 RPM & 12,000,000 TPM | ssid_chart depende del tamaño de entrada | Los tokens se cuentan como: input_tokens | POST | |
| API de segmentación | https://api.jina.ai/v1/segment | Tokenizar y segmentar textos largos | 20 RPM | 200 RPM | 200 RPM | 1,000 RPM | 0.3s | El token no se cuenta como uso. | GET/POST | |
| Búsqueda profunda | https://deepsearch.jina.ai/v1/chat/completions | Razonar, buscar e iterar para encontrar la mejor respuesta. | block | 50 RPM | 50 RPM | 500 RPM | 56.7s | Cuente el número total de tokens en todo el proceso. | POST |
Preguntas comunes relacionadas con API
code
¿Puedo usar la misma clave API para las API de lectura, inserción, reclasificación, clasificación y ajuste?
keyboard_arrow_down
code
¿Puedo monitorear el uso del token de mi clave API?
keyboard_arrow_down
code
¿Qué debo hacer si olvido mi clave API?
keyboard_arrow_down
code
¿Caducan las claves API?
keyboard_arrow_down
code
¿Puedo transferir tokens entre claves API?
keyboard_arrow_down
code
¿Puedo revocar mi clave API?
keyboard_arrow_down
code
¿Por qué la primera solicitud de algunos modelos es lenta?
keyboard_arrow_down
code
¿Se utilizan mis datos de API para entrenar sus modelos?
keyboard_arrow_down
code
¿Cuáles son los límites de velocidad para las API de Jina?
keyboard_arrow_down
code
¿Existen límites de tamaño de lote para las API?
keyboard_arrow_down
Preguntas comunes relacionadas con la facturación
attach_money
¿La facturación se basa en el número de sentencias o solicitudes?
keyboard_arrow_down
attach_money
¿Hay una prueba gratuita disponible para nuevos usuarios?
keyboard_arrow_down
attach_money
¿Se cobran tokens por solicitudes fallidas?
keyboard_arrow_down
attach_money
¿Qué métodos de pago se aceptan?
keyboard_arrow_down
attach_money
¿Está disponible la facturación para compras de tokens?
keyboard_arrow_down