Votre base de recherche survoltée!
Intégrez et testez notre API publique en quelques minutes.
'%3e%3cpath%20d='M7.27417%2043.8897L7.26016%2060.2323L0%2060.244V19.4258L10.3647%2019.4352C16.5608%2019.4398%2017.8745%2022.5128%2017.8698%2027.5038L17.8628%2035.6752C17.8582%2040.665%2015.827%2043.899%2010.7275%2043.8943L7.273%2043.8908L7.27417%2043.8897ZM7.28%2037.2537H8.652C10.297%2037.256%2010.5175%2036.2153%2010.5187%2034.9542L10.5245%2028.1537C10.5245%2026.728%2010.3075%2025.741%208.6625%2025.7398H7.2905L7.28117%2037.2548H7.28V37.2537ZM35.6335%2019.455L35.6277%2026.6382L27.3362%2026.6312L27.3292%2035.5153L33.5802%2035.52L33.5743%2042.8677L27.3233%2042.863L27.3152%2052.8987L35.651%2052.9057L35.6452%2060.2545L20.0165%2060.2417L20.0503%2019.441L35.6358%2019.455H35.6335ZM53.4088%2019.469L53.4018%2026.6522L45.0975%2026.6452L45.0905%2035.5293L51.3415%2035.5352L51.3357%2042.8828L45.0847%2042.877L45.0765%2052.9138L53.4123%2052.9208L53.4065%2060.2685L37.7778%2060.2557L37.8117%2019.4562L53.41%2019.4667L53.4088%2019.469ZM62.8285%2060.2767L55.5345%2060.2708L55.5683%2019.4713L67.0833%2019.4807C71.526%2019.4842%2073.7718%2021.954%2073.7683%2026.2858L73.7625%2032.8122C73.7601%2036.1022%2071.8947%2037.7472%2070.5227%2038.2932C71.729%2038.733%2073.647%2040.0513%2073.6446%2043.122L73.633%2056.996C73.633%2058.7507%2073.9597%2059.5183%2074.2338%2060.013V60.2872L66.9398%2060.2813C66.6108%2059.8427%2066.2842%2058.9653%2066.2853%2057.1547L66.2947%2045.2547C66.2947%2043.3903%2065.8572%2042.842%2064.3767%2042.8408H62.8413L62.8273%2060.2778L62.8285%2060.2767ZM62.8483%2035.5048H64.274C65.6985%2035.5072%2066.3028%2034.9588%2066.304%2033.0397L66.3098%2028.0895C66.3098%2026.3348%2065.982%2025.7853%2064.5015%2025.7842H62.8565L62.8483%2035.5048ZM85.9506%2019.0023C91.6533%2019.007%2093.7906%2021.6413%2093.786%2027.015L93.7813%2032.4983L86.7615%2032.4925L86.7661%2027.3918C86.7661%2026.0758%2086.4943%2025.2522%2085.1783%2025.251C83.9171%2025.251%2083.587%2026.0723%2083.5858%2027.4443V28.3765C83.5835%2030.2945%2084.021%2031.6117%2085.8293%2033.6417L89.9931%2038.3083C93.6635%2042.4232%2094.4288%2045.3305%2094.4265%2048.785V50.703C94.4195%2056.7907%2091.5658%2060.7912%2085.533%2060.7865H84.1085C78.5692%2060.7807%2075.775%2057.8173%2075.7785%2052.3328L75.7855%2044.9852L82.9686%2044.991L82.9628%2051.5173C82.9628%2053.1623%2083.5111%2053.9848%2084.826%2053.986C86.086%2053.986%2086.6366%2053.0013%2086.6378%2051.0262V50.2585C86.6401%2047.406%2086.422%2046.2545%2084.2858%2043.8955L80.066%2039.23C77.0536%2035.9377%2076.1787%2032.7013%2076.1822%2028.863V27.1095C76.188%2021.8992%2079.3718%2018.9953%2084.4713%2019H85.9518L85.9506%2019.0023ZM103.854%2043.8897L103.84%2060.2323L96.5463%2060.2265L96.5813%2019.4258L106.945%2019.434C113.142%2019.4387%20114.455%2022.5117%20114.451%2027.5027L114.444%2035.674C114.439%2040.6638%20112.408%2043.8978%20107.309%2043.8932L103.855%2043.8908L103.854%2043.8897ZM103.86%2037.2537H105.231C106.876%2037.256%20107.096%2036.2153%20107.098%2034.9542L107.103%2028.1537C107.103%2026.728%20106.886%2025.741%20105.241%2025.7398H103.871L103.861%2037.2548L103.86%2037.2537ZM125.098%2053.3945L120.711%2053.391L120.046%2060.2463L113.575%2060.2405L118.764%2019.4433L127.429%2019.4503L132.933%2060.2557L125.859%2060.2498L125.097%2053.3933L125.098%2053.3945ZM121.43%2046.3723L124.391%2046.3747L122.866%2030.8953L121.43%2046.3723ZM145.139%2042.9435L152.378%2042.9493L152.37%2051.5745C152.367%2056.4558%20150.388%2061.0058%20143.916%2061H142.436C135.417%2060.993%20133.831%2056.4407%20133.834%2051.34L133.853%2028.3077C133.856%2023.3727%20135.999%2019.042%20142.47%2019.0467H143.95C150.915%2019.0537%20152.392%2023.3867%20152.389%2028.0487L152.383%2035.527L145.144%2035.5212L145.15%2028.317C145.15%2026.7817%20144.657%2025.958%20143.288%2025.9568C141.917%2025.9568%20141.477%2026.7233%20141.476%2028.3135L141.457%2051.3458C141.456%2052.9372%20142.004%2053.8133%20143.319%2053.8145C144.635%2053.8145%20145.13%2052.8298%20145.131%2051.3493L145.139%2042.9435ZM170.144%2019.469L170.138%2026.6522L161.833%2026.6452L161.826%2035.5293L168.077%2035.5352L168.071%2042.8828L161.82%2042.877L161.812%2052.9138L170.148%2052.9208L170.142%2060.2685L154.513%2060.2557L154.547%2019.4562L170.147%2019.4667H170.144V19.469Z'%20fill='white'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_13_1016'%3e%3crect%20width='170.148'%20height='80'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
'%3e%3cmask%20id='mask0_112_1446'%20style='mask-type:luminance'%20maskUnits='userSpaceOnUse'%20x='0'%20y='29'%20width='80'%20height='22'%3e%3cpath%20d='M80%2029.5H0V50.5H80V29.5Z'%20fill='white'/%3e%3c/mask%3e%3cg%20mask='url(%23mask0_112_1446)'%3e%3cpath%20d='M0%2029.9443V50.0854H2.98807V39.067C2.98807%2034.1502%206.62302%2032.3434%209.94994%2032.3434C13.1844%2032.3434%2015.0019%2034.6241%2015.0019%2038.3265V50.0557H17.99V38.3265C18.0516%2032.847%2015.0636%2029.5%209.94994%2029.5C7.51633%2029.5%204.31267%2030.6255%202.98807%2033.2616V29.9443H0Z'%20fill='white'/%3e%3cpath%20d='M31.8829%2047.6269L33.9161%2050.2631C38.7832%2049.3152%2042.5106%2045.4351%2042.5106%2039.9259C42.5106%2033.5578%2037.5202%2029.5%2031.5749%2029.5C25.5988%2029.5%2020.6392%2033.5578%2020.6392%2039.9259C20.6392%2045.4351%2024.3666%2049.3152%2029.2337%2050.2631L31.2668%2047.6269C27.0466%2047.4788%2023.5964%2044.4577%2023.5964%2039.9259C23.5964%2035.2757%2027.2314%2032.3434%2031.5749%2032.3434C35.9184%2032.3434%2039.5533%2035.2757%2039.5533%2039.9259C39.5533%2044.4577%2036.1032%2047.5084%2031.8829%2047.6269Z'%20fill='white'/%3e%3cpath%20d='M44.636%2029.944V41.6436C44.6052%2047.1231%2047.5933%2050.4701%2052.7068%2050.4701C55.1404%2050.4701%2058.3441%2049.3446%2059.6687%2046.7085V50.0258H62.6567V29.8848H59.6687V40.8735C59.6687%2045.7903%2056.0338%2047.5971%2052.7068%2047.5971C49.4723%2047.5971%2047.6548%2045.3163%2047.6548%2041.614V29.944H44.636Z'%20fill='white'/%3e%3cpath%20d='M74.7016%2038.7115L71.8369%2038.06C70.3582%2037.7045%2068.2943%2037.0233%2068.7564%2034.6834C68.972%2033.2616%2070.6355%2032.225%2072.6686%2032.225C74.455%2032.225%2075.9956%2033.1432%2076.3347%2034.6834H79.2609C78.706%2031.0106%2075.8723%2029.5%2072.6378%2029.5C69.2185%2029.5%2066.2612%2031.3956%2065.8299%2034.2983C65.3063%2039.0078%2068.5099%2040.2518%2071.1284%2040.8441L74.055%2041.4958C76.2422%2041.9993%2077.0429%2043.2729%2077.0429%2044.6058C77.0429%2046.5014%2075.2873%2047.8047%2072.607%2047.8047C69.0644%2047.8047%2068.0787%2045.8202%2067.6782%2044.3096H65.0291C65.2139%2048.2193%2068.7872%2050.5296%2072.3298%2050.5296C76.673%2050.5296%2080%2048.1305%2080%2044.6354C80%2041.8216%2078.6444%2039.6297%2074.7016%2038.7115Z'%20fill='white'/%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_112_1446'%3e%3crect%20width='80'%20height='21'%20fill='white'%20transform='translate(0%2029.5)'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
'%3e%3cg%20clip-path='url(%23clip1_98_1414)'%3e%3cpath%20d='M17.9243%2041.4064H11.3163L14.8357%2029.9236L17.9243%2041.4064ZM7.88892%2054.0607L10.1448%2046.4991H19.0474L21.1581%2054.0414H29.3877L21.2113%2025.2859C20.7272%2023.5867%2019.7106%2022.8025%2017.9243%2022.8025H6.25267V25.5183H7.22086C8.44079%2025.5183%209.09916%2026.0024%209.09916%2026.927C9.09916%2027.5418%208.96362%2028.055%208.47952%2029.454L0.288574%2054.0607H7.88892Z'%20fill='white'/%3e%3cpath%20d='M38.9099%2054.0607V25.1988C38.9099%2023.6932%2038.0289%2022.8025%2036.5717%2022.8025H29.3345V25.5183H29.8186C31.0337%2025.5183%2031.5516%2026.0363%2031.5516%2027.2659V54.0607H38.9099Z'%20fill='white'/%3e%3cpath%20d='M51.4191%2054.0607V25.1988C51.4191%2023.6932%2050.5236%2022.8025%2049.0761%2022.8025H41.863V25.5183H42.3471C43.5671%2025.5183%2044.085%2026.0363%2044.085%2027.2659V54.0607H51.4191Z'%20fill='white'/%3e%3cpath%20d='M64.2524%2025.6538C64.2524%2023.5577%2062.6985%2022.2651%2060.0359%2022.2651C57.3734%2022.2651%2055.8097%2023.5335%2055.8097%2025.6538C55.8097%2027.7742%2057.4121%2029.0425%2060.0359%2029.0425C62.6597%2029.0425%2064.2524%2027.7839%2064.2524%2025.6538ZM64.112%2054.0607V33.0218C64.112%2031.5211%2063.2213%2030.6352%2061.7642%2030.6352H54.6431V33.2977H55.0642C56.2793%2033.2977%2056.7973%2033.8593%2056.7973%2035.0792V54.0607H64.112Z'%20fill='white'/%3e%3cpath%20d='M80.2228%2042.8101V47.3655C78.9981%2048.6289%2077.507%2049.4035%2076.2435%2049.4035C74.98%2049.4035%2074.4621%2048.7548%2074.4621%2046.983C74.4621%2045.2112%2074.83%2044.4609%2076.1467%2043.9526C77.4578%2043.4188%2078.8253%2043.0355%2080.2228%2042.8101ZM70.3279%2037.3398C72.5766%2036.2242%2075.0371%2035.6004%2077.5458%2035.5099C79.5209%2035.5099%2080.2228%2036.2118%2080.2228%2038.2596V38.7824C77.2263%2039.2665%2076.2871%2039.4504%2074.5976%2039.8232C73.6513%2040.0316%2072.7249%2040.3216%2071.8286%2040.6897C68.8707%2041.8758%2067.4717%2044.1607%2067.4717%2047.6704C67.4717%2052.1241%2069.4081%2054.2735%2073.3728%2054.2735C74.7215%2054.2791%2076.0588%2054.0277%2077.3134%2053.5329C78.4514%2053.0149%2079.5094%2052.3367%2080.4552%2051.519V51.8482C80.4552%2053.3005%2081.2007%2054.0412%2082.6578%2054.0412H89.3626V51.5384H89.0334C87.7699%2051.5384%2087.3052%2050.972%2087.3052%2049.4761V38.3177C87.3052%2032.3681%2085.2381%2030.2961%2079.2788%2030.2961C77.3896%2030.3056%2075.5075%2030.528%2073.6681%2030.9594C71.9303%2031.3469%2070.2564%2031.9793%2068.6964%2032.8377L70.3279%2037.3398Z'%20fill='white'/%3e%3cpath%20d='M100.037%2054.0605V38.2208C101.262%2036.8605%20102.52%2036.2457%20103.973%2036.2457C105.527%2036.2457%20105.909%2036.8605%20105.909%2039.2181V54.0605H113.219V38.1337C113.219%2034.4255%20112.953%2033.254%20111.767%2031.9953C110.799%2030.9061%20109.283%2030.3542%20107.352%2030.3542C104.491%2030.3542%20102.477%2031.2401%2099.7708%2033.772V32.8377C99.7708%2031.3854%2099.0108%2030.635%2097.5149%2030.635H90.5681V33.2976H90.9893C92.2044%2033.2976%2092.7272%2033.8591%2092.7272%2035.079V54.0605H100.037Z'%20fill='white'/%3e%3cpath%20d='M134.902%2049.1422H124.702L134.456%2035.4665V30.6255H119.159C117.426%2030.6255%20116.627%2031.4194%20116.627%2033.1573V37.4174H119.343V37.0011C119.343%2035.9215%20119.904%2035.4084%20121.071%2035.4084H126.328L116.472%2049.2391V54.0801H134.868L134.902%2049.1422Z'%20fill='white'/%3e%3cpath%20d='M173.276%2053.4651V26.9801C173.276%2024.8694%20172.526%2024.1578%20170.478%2024.1578H164.277V27.135H164.65C166.063%2027.135%20166.339%2027.4545%20166.339%2029.1585V53.4651H173.276ZM176.336%2053.4651H183.22V32.8377C183.22%2030.7657%20182.421%2030.0202%20180.402%2030.0202H176.336V53.4651ZM163.299%2053.4651V30.0396H159.218C157.199%2030.0396%20156.41%2030.7851%20156.41%2032.857V53.4651H163.299ZM189.736%2040.0023C189.736%2051.6739%20181.341%2060.1602%20169.815%2060.1602C158.289%2060.1602%20149.875%2051.6739%20149.875%2040.0023C149.875%2028.3307%20158.284%2019.8445%20169.815%2019.8445C181.346%2019.8445%20189.736%2028.3791%20189.736%2040.0023ZM193.812%2040.0023C193.812%2026.2781%20183.544%2016.0007%20169.815%2016.0007C156.086%2016.0007%20145.809%2026.2781%20145.809%2040.0023C145.809%2053.7265%20156.076%2063.9991%20169.815%2063.9991C183.554%2063.9991%20193.812%2053.7604%20193.812%2040.0023Z'%20fill='white'/%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_98_1414'%3e%3crect%20width='193.523'%20height='80'%20fill='white'%20transform='translate(0.288574)'/%3e%3c/clipPath%3e%3cclipPath%20id='clip1_98_1414'%3e%3crect%20width='193.523'%20height='48'%20fill='white'%20transform='translate(0.288574%2016)'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
'%3e%3cpath%20fill-rule='evenodd'%20clip-rule='evenodd'%20d='M11%2065H68.1212V15H11V65ZM38.3407%2030.4427C38.3094%2032.6371%2038.3094%2034.7152%2036.4541%2036.6463C34.1968%2039.017%2029.9914%2039.8069%2026.6828%2039.8069C25.1366%2039.8069%2023.5914%2039.66%2022.0754%2039.3097C21.0241%2039.0758%2019.6637%2038.6656%2018.3033%2037.817C14.8705%2035.6225%2014.8402%2032.9004%2014.8402%2030.4427V18.4445H20.2828V30.5896C20.2828%2032.4326%2020.6837%2033.983%2022.7562%2034.9197C24.5185%2035.7107%2026.095%2035.6519%2027.7039%2035.5932C29.7753%2035.4169%2031.1054%2034.8903%2031.971%2033.9547C32.4961%2033.3693%2032.9607%2032.6959%2032.8981%2030.6179V18.4445H38.3407V30.4427ZM38.5449%2055.5673C38.5449%2056.7662%2038.2542%2058.025%2037.513%2059.0488C35.7409%2061.4782%2032.8084%2061.4782%2030.5857%2061.5065H14.9569V40.8481H29.7148C32.0671%2040.9057%2034.9349%2040.9645%2036.4822%2042.9838C37.2872%2044.0369%2037.3844%2045.1782%2037.3844%2045.9104C37.3844%2046.4664%2037.3196%2047.637%2036.4822%2048.6608C35.5475%2049.7727%2034.3233%2050.1241%2033.6144%2050.2993C35.0321%2050.6507%2038.5449%2051.4406%2038.5449%2055.5673ZM57.7438%2030.4721L64.361%2039.1041H57.9296L52.085%2030.7941H45.8698V39.1041H40.3959V18.4445H55.4239C57.8983%2018.4445%2060.1555%2018.6502%2061.9795%2020.6401C63.0935%2021.8684%2063.4025%2023.4198%2063.4025%2024.6199C63.4025%2026.1996%2062.8461%2028.0731%2061.2998%2029.185C60.1253%2030.0336%2058.6093%2030.3252%2057.7438%2030.4721ZM64.4852%2061.5392H59.0739L48.2513%2049.8924C47.107%2048.6347%2046.6435%2048.1081%2045.4376%2046.6448C45.5921%2048.2245%2045.5921%2048.576%2045.6224%2050.1557V61.5392H40.4283V40.8796H45.8709L56.5693%2052.3795C57.8681%2053.8135%2058.1155%2054.1072%2059.4759%2055.7163C59.2911%2053.7547%2059.2911%2053.2281%2059.2598%2051.4439V40.8796H64.4852V61.5392ZM57.867%2024.6786C57.867%2024.2684%2057.8054%2023.5656%2057.4348%2023.0684C57.0328%2022.5712%2056.5066%2022.074%2054.3423%2022.074H45.8698V27.1363H54.5897C55.7643%2027.1363%2057.867%2026.9895%2057.867%2024.6786ZM32.8408%2055.069C32.8408%2052.5819%2030.6819%2052.5819%2029.8445%2052.5819H20.5962V57.8792H29.1356C30.4236%2057.8792%2032.8408%2057.9075%2032.8408%2055.069ZM31.9385%2046.6709C31.9385%2044.4765%2030.1016%2044.4471%2029.1994%2044.4471H20.5962V48.9829H28.7488C29.4252%2048.9829%2030.0692%2048.9535%2030.5857%2048.7772C31.9385%2048.28%2031.9385%2046.9048%2031.9385%2046.6709Z'%20fill='white'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_112_905'%3e%3crect%20width='58'%20height='50'%20fill='white'%20transform='translate(11%2015)'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
'%3e%3cg%20clip-path='url(%23clip1_44_705)'%3e%3cpath%20d='M100.279%2020C99.542%2020%2098.658%2020%2097.9212%2020.1468L93.648%2027.6268C95.5636%2026.4532%2097.9212%2025.8668%20100.279%2025.8668C107.941%2025.8668%20114.277%2032.1732%20114.277%2039.8C114.277%2047.4268%20107.941%2053.7332%20100.279%2053.7332C92.6164%2053.7332%2086.4276%2047.5732%2086.2804%2039.9468L81.86%2047.4268C84.8068%2054.6132%2092.0272%2059.6%20100.132%2059.6C111.036%2059.6%20120.024%2050.6532%20120.024%2039.8C120.172%2028.9468%20111.183%2020%20100.279%2020ZM40.1596%2040.68L43.5484%2034.8132L51.2108%2047.8668L60.0516%2032.76L68.8924%2047.8668L84.07%2022.2C84.8068%2020.88%2086.2804%2020%2087.9012%2020H92.1744L68.8928%2059.6L60.052%2044.4932L51.2108%2059.6L40.1596%2040.68ZM46.4956%2020L23.214%2059.6L0.0795898%2020H4.35279C5.97359%2020%207.44719%2020.88%208.18399%2022.2L23.214%2048.0132L38.3912%2022.2C39.128%2020.88%2040.6012%2020%2042.2224%2020H46.4956Z'%20fill='white'/%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_44_705'%3e%3crect%20width='120'%20height='80'%20fill='white'%20transform='translate(0.0795898)'/%3e%3c/clipPath%3e%3cclipPath%20id='clip1_44_705'%3e%3crect%20width='120'%20height='40'%20fill='white'%20transform='translate(0.0795898%2020)'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
'%3e%3cpath%20d='M41.7347%2052.0487C47.7084%2051.2192%2052.3016%2046.1645%2052.3016%2040.0576C52.3016%2036.345%2050.6061%2033.0234%2047.9344%2030.8013L41.7347%2036.9047V52.0487Z'%20fill='white'/%3e%3cpath%20d='M38.2629%2052.0487V36.9047L32.0632%2030.8013C29.3915%2033.0234%2027.696%2036.345%2027.696%2040.0576C27.696%2046.1679%2032.2893%2051.2192%2038.2629%2052.0487Z'%20fill='white'/%3e%3cpath%20d='M50.6936%2029.5263C53.5503%2032.3387%2055.1225%2036.0783%2055.1225%2040.0539C55.1225%2044.0297%2053.5503%2047.7693%2050.6936%2050.5816C47.8369%2053.3939%2044.0384%2054.9417%2040%2054.9417C35.9616%2054.9417%2032.1631%2053.3939%2029.3064%2050.5816C26.4497%2047.7693%2024.8775%2044.0297%2024.8775%2040.0539C24.8775%2036.0783%2026.4497%2032.3387%2029.3064%2029.5263C29.553%2029.2835%2029.803%2029.0542%2030.0634%2028.8316L26.6073%2025.4292C26.3504%2025.6551%2026.1004%2025.8912%2025.8572%2026.1306C24.0212%2027.938%2022.5792%2030.0422%2021.5722%2032.3892C20.5275%2034.8171%2020%2037.3968%2020%2040.0539C20%2042.7111%2020.5275%2045.2909%2021.5722%2047.7187C22.5792%2050.0623%2024.0212%2052.1698%2025.8572%2053.9773C27.6931%2055.7847%2029.8305%2057.2044%2032.2145%2058.1958C34.6806%2059.2243%2037.3009%2059.7436%2040%2059.7436C42.6991%2059.7436%2045.3194%2059.2243%2047.7855%2058.1958C50.1662%2057.2044%2052.3069%2055.7847%2054.1429%2053.9773C55.9788%2052.1698%2057.4208%2050.0657%2058.4278%2047.7187C59.4725%2045.2909%2060%2042.7111%2060%2040.0539C60%2037.3968%2059.4725%2034.8171%2058.4278%2032.3892C57.4208%2030.0456%2055.9788%2027.938%2054.1429%2026.1306C53.8997%2025.8912%2053.6462%2025.6551%2053.3927%2025.4292L49.9366%2028.8316C50.1935%2029.0542%2050.447%2029.2869%2050.6936%2029.5263Z'%20fill='white'/%3e%3cpath%20d='M39.9999%2020.2563C43.4423%2020.2563%2046.2339%2023.0046%2046.2339%2026.3936C46.2339%2029.7825%2043.4423%2032.5308%2039.9999%2032.5308C36.5576%2032.5308%2033.766%2029.7825%2033.766%2026.3936C33.766%2023.0046%2036.5576%2020.2563%2039.9999%2020.2563Z'%20fill='white'/%3e%3c/g%3e%3c/svg%3e)
'%3e%3cpath%20d='M64.8036%2038.3683H52.3798C53.1413%2035.5541%2055.687%2033.6997%2058.385%2033.6997C61.7357%2033.6997%2063.955%2035.3577%2064.8036%2038.3683ZM52.3146%2042.6442H70.5476V41.488C70.5476%2038.4774%2069.8513%2036.0558%2068.4371%2034.0051C66.0219%2030.7982%2062.4319%2028.8347%2058.5591%2028.8347C55.4476%2028.8347%2052.4451%2030.1873%2050.1388%2032.6089C48.0282%2034.856%2046.9404%2037.6702%2046.9404%2040.8553C46.9404%2043.8659%2048.2023%2046.9856%2050.3346%2049.2327C52.6845%2051.5888%2055.4912%2052.745%2058.8854%2052.745C63.9332%2052.745%2067.9366%2049.9308%2069.8513%2044.9567H64.129C63.0412%2046.8111%2061.0176%2047.7709%2058.7113%2047.7709C54.9908%2047.9019%2052.5757%2045.8512%2052.3146%2042.6442ZM78.7721%2041.0735C78.7721%2037.1684%2081.5788%2034.2451%2085.2777%2034.2451C88.9765%2034.2451%2091.8921%2037.3648%2091.8921%2040.9644C91.8921%2044.7386%2089.0853%2047.6837%2084.9948%2047.6837C81.7094%2047.7056%2078.7721%2044.7822%2078.7721%2041.0735ZM78.5762%2031.3435V22.2026H73.3543V52.3742H78.5762V50.5198C80.6867%2052.1779%2082.9714%2052.9413%2085.6476%2052.9413C88.563%2052.9413%2091.0652%2051.9815%2093.1105%2050.3235C95.852%2047.9673%2097.3751%2044.5858%2097.3751%2040.9862C97.3751%2037.6702%2096.026%2034.3542%2093.4803%2032.1071C91.3699%2030.0563%2088.6284%2029.0965%2085.6258%2029.0965C82.8625%2029.031%2080.6215%2029.6856%2078.5762%2031.3435ZM101.009%2029.6201H106.056V52.3742H101.009V29.6201ZM101.009%2022.2026H106.056V27.264H101.009V22.2026ZM114.912%2040.6808C114.912%2036.9721%20117.827%2034.1579%20121.418%2034.1579C124.725%2034.1579%20127.814%2037.0812%20127.814%2040.9862C127.814%2044.4987%20124.812%2047.5092%20121.505%2047.5092C117.914%2047.5092%20114.912%2044.695%20114.912%2040.6808ZM128.401%2052.3742H133.449V29.6201H128.401V32.347C126.857%2030.1%20124.507%2029.031%20121.2%2029.031C117.806%2029.031%20115.086%2030.1218%20112.78%2032.5434C110.669%2034.7905%20109.581%2037.7138%20109.581%2040.9208C109.581%2047.7492%20114.629%2052.876%20121.309%2052.876C124.812%2052.876%20127.118%2051.916%20128.379%2049.5599V52.3742H128.401Z'%20fill='%23F8F8FF'/%3e%3cpath%20d='M0.487325%2062.2786H14.3253L29.2947%2047.3129L44.2205%2062.2786H58.2326L36.3007%2040.2881L58.4283%2018.123H44.4164L29.2947%2033.307L14.26%2018.123H0.291504L22.2887%2040.2881L0.487325%2062.2786Z'%20fill='%23F8F8FF'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_44_247'%3e%3crect%20width='133.158'%20height='46'%20fill='white'%20transform='translate(0.291504%2017)'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
'%3e%3cg%20clip-path='url(%23clip1_98_1801)'%3e%3cpath%20d='M173.848%2028.6394V33.5192H188.992V55.0778H193.891V31.1174L191.48%2028.6394H173.848Z'%20fill='white'/%3e%3cpath%20d='M173.848%2033.519H168.949V55.0777H173.848V33.519Z'%20fill='white'/%3e%3cpath%20d='M173.848%2014H168.949V28.6393H173.848V14Z'%20fill='white'/%3e%3cpath%20d='M141.519%2050.198V33.5192H161.267V28.6394H139.032L136.62%2031.1174V52.5998L139.032%2055.0778H161.267V50.198H141.519Z'%20fill='white'/%3e%3cpath%20d='M113.718%2039.4187V44.2985H126.518L128.929%2041.8205V31.1174L126.518%2028.6394H106.398L103.987%2031.1174V52.5998L106.398%2055.0778H128.929V50.198H108.886V33.5192H124.03V39.4187H113.718Z'%20fill='white'/%3e%3cpath%20d='M84.83%2033.519H79.9312V52.5997L82.4187%2055.0777H96.3146V50.1979H84.83V33.519Z'%20fill='white'/%3e%3cpath%20d='M84.83%2028.6394V18.8799H79.9312V28.6394H84.83V33.5192H96.3146V28.6394H84.83Z'%20fill='white'/%3e%3cpath%20d='M49.8616%2028.6394L47.374%2031.1174V52.5998L49.8616%2055.0778H62.5185V50.1981H52.2824V33.5192H67.4268V61.1203H47.3836V66.0001L69.9143%2065.9239L72.3256%2063.4459V31.1174L69.9143%2028.6394H49.8711H49.8616Z'%20fill='white'/%3e%3cpath%20d='M38.8153%2028.6394H33.9165V55.0016H38.8153V28.6394Z'%20fill='white'/%3e%3cpath%20d='M2.90331%2028.6394L0.415771%2031.1174V41.8205L2.90331%2044.2985H20.459V50.198H0.415771V55.0778H22.9466L25.3578%2052.5998V41.8205L22.9466%2039.4187H5.3146V33.5192H25.3578V28.6394H2.90331Z'%20fill='white'/%3e%3cpath%20d='M38.7963%2019.0227H33.8975V23.9025H38.7963V19.0227Z'%20fill='white'/%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_98_1801'%3e%3crect%20width='193.475'%20height='80'%20fill='white'%20transform='translate(0.415771)'/%3e%3c/clipPath%3e%3cclipPath%20id='clip1_98_1801'%3e%3crect%20width='193.475'%20height='52'%20fill='white'%20transform='translate(0.415771%2014)'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
'%3e%3cpath%20d='M24.355%2018C37.3439%2019.1127%2051.4435%2025.6157%2059.607%2034.8835C69.9982%2046.7575%2066.4717%2058.6337%2051.6296%2061.4156C36.7876%2064.1974%2016.3755%2056.7785%205.97804%2044.9044C-1.993%2035.8122%20-1.80684%2026.7199%205.42803%2021.7105L46.6181%2052.1393L24.355%2018Z'%20fill='white'/%3e%3cpath%20d='M227.708%2061.6037L222.513%2040.8236C221.841%2038.3887%20221.346%2035.9086%20221.032%2033.4025H220.846C220.594%2035.9687%20220.16%2038.5137%20219.547%2041.0182L214.351%2061.6143H205.443L217.501%2018.3722H224.552L236.982%2061.6037H227.708Z'%20fill='white'/%3e%3cpath%20d='M90.969%2018.186L96.1646%2038.9662C96.8359%2041.4011%2097.3308%2043.8812%2097.6454%2046.3872H97.8316C98.0833%2043.8211%2098.5174%2041.2761%2099.1305%2038.7716L104.324%2018.186H113.23L101.354%2061.6037H94.303L81.8726%2018.186H90.969Z'%20fill='white'/%3e%3cpath%20d='M128.258%2018.186V61.6037H119.722V18.186H128.258Z'%20fill='white'/%3e%3cpath%20d='M176.686%2018.186L180.952%2043.7831L184.479%2018.186H195.983L200.425%2061.4175H191.722L189.674%2030.2441H189.488L188.189%2041.0055L184.479%2061.4154H177.798L173.529%2040.6374L172.048%2030.9888V30.2441H171.862L170.75%2061.6016H161.471L165.182%2018.3722H176.686V18.186Z'%20fill='white'/%3e%3cpath%20d='M149.597%2018.186C148.084%2019.401%20146.929%2021.0046%20146.257%2022.8252C144.031%2028.207%20146.443%2032.2877%20148.482%2035.9982C148.852%2036.5546%20149.039%2037.1109%20149.411%2037.6673C154.05%2045.6447%20155.905%2051.3966%20152.372%2059.7463C152.186%2060.3027%20151.63%2061.4154%20151.63%2061.4154H141.252C142.587%2060.2998%20143.663%2058.9065%20144.406%2057.3326C146.817%2051.5807%20144.035%2046.3851%20141.252%2041.3757C138.097%2035.2536%20134.573%2029.1293%20138.29%2020.4094L139.392%2018.186H149.597Z'%20fill='white'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_13_1210'%3e%3crect%20width='236.982'%20height='80'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)


'/%3e%3cdefs%3e%3cpattern%20id='pattern0_112_1504'%20patternContentUnits='objectBoundingBox'%20width='1'%20height='1'%3e%3cuse%20xlink:href='%23image0_112_1504'%20transform='matrix(0.00865385%200%200%200.0384615%20-0.00625%200)'/%3e%3c/pattern%3e%3cimage%20id='image0_112_1504'%20width='117'%20height='26'%20preserveAspectRatio='none'%20xlink:href='data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAHUAAAAaCAYAAACJphMzAAAAAXNSR0IArs4c6QAAAERlWElmTU0AKgAAAAgAAYdpAAQAAAABAAAAGgAAAAAAA6ABAAMAAAABAAEAAKACAAQAAAABAAAAdaADAAQAAAABAAAAGgAAAAD5rtLRAAAIwElEQVRoBe2aeYiWVRTGZ0yzTVMrU7McrLSw1GyhTCuizBbFIG2lJGjfCAzKqGxBrH+koj9aUWyDlLIyURA1okXbLNPUzNF0rNw1bcZt+j2v94znO74zk/C51Rx45p57nnPuvr2flpQEqa6uPhQMAuPA44E+YLP0pRHoDV4Ekw/YjuxOw+loJ/Au+AuYDN6dMvZXXzozHPxmnSIdt7+2tajtoqMPuU6bel5RK9kHhdGRI6wzLn1mHzRlr1XZyNV0itNN/dmUAzjtnNP2eTm2/4ypsetJJ6dLXVFaWrom2LIsK74V3GrSJhiuAJeCI0E5GAW3kDRXiDkC4krQAzQDf4JvwVSwCZSBLuAHyiknLRDim2K4CJwP2oDDwCrwOXifmM2kmeB7OoratovAdU/GjcQsiA7wp2LrAzqCVqAKzAVj8V9MmivEdYPQmJwIFCPfKUB9VHvPBi0pYzRpgRCrTdYcbi16e/TrgPpQCuaD1+B+Jy2Bb0dyNdBp2hz8BkbDzyDdITitBF4+NU4pRGtwJ5gGvk76EtIoGzGo4QWCrRTcD9TgPNmCsdIRZ/gCsDcBDwMtptpkDkRbxZE2Bdtqc3T28aGennBfOT6qVRiu9zGpvvbYJ0Rnl9/k9DEWj03jci54AVSAoWAU2AqiLMVwLVA92yNJXv0dmJWN0irH4XVX8VspIMct1/SRxSrFQy/PMbmetRu1ozPB5UjwqXNV498EI8Afzi71VQWRnhbstWWf21FLFnMXTn4hzCL/NJgSgrVwdTJlgq5H5rLgU1f2MQXi0B3kbYy6Yuvj5lijtDqjDEkVa0L+DuR68vrkeR7MDJyyy7KC0x/yT+b4TMM2AHQBU4EXHSWZYFT9kz2JfrPjtXK96IjUgB0NVL5Wt5fvyMhu0DEp/4HeCV3tOzhxOiVWBL534g7DPi9w2s3qcw/QN3DKDkqxWkRRfsLwMngNrIskec3FB+BZMAnsIipbHRq8C1Nd3T9xZTlcNuGJV4fLg88icRLsnUE8SrTzdX9kgv4j8KI7yLjbPYGuu6lGyPcP/Cwjseto88eeXF8x3lJsLcAqkU7OMV4p9rgTdZfJ/riLkaqdfpk4CXo/GYPo3hU3MtgVqzdDJuhxocl9hPFKyX8po5MtNrCdvWPS7eXbKYfTpZ0JF/MWlIqUtWSlKaQPgINcXo+ae4jbLhuNERfrmJc4te8R6U4+NJ1YPSBusnxKv3b5E9APdXmpWdnBdid5PYZM/vAPDuq5BEIPE5NKFN3f2sn3mjGlbxI7ydli30TZ+MVxX0xslYtd6HRTo63ciJSustdv/JzZisOvySlyMtuEJ5eS401JaTbJacJuCNw7NHyts3VA1+B4sYHvirHME+h6pB1LqtfrPaAfMNmMMtIypCc73VQbUMsrHeAz6J9TRwtSLQqV/zDw8hJ90NHYF+MxnkB/PeTj+C0h9u/kE7k4rnoBR4nt1/h5WWqTGlfMQirWxEriSvMTrp12OD6xcpsUPcdrHhQqDJm+I6n5GzsmwuIvrPHaqRQ8wnaaS1aj30i7ZzubPkuiWNmZnfbrk+is4KRPBSFPXsE4NBEXBAeNzZfBFscvmxTq1UKOE1LQNvgYq6KjTxy/uY0pXBN7kryd+MAY9IubcIXkVWwrLm9Q7QSw6uKCkt3qj4vFYizVMa879GOg72N/Asgn7lQN+iIRTo5D99eDozK1ir+aiKlgNHX4Oz2OWwX85ixq5584PjY2stv1Z97GWT6O/XrK/91I5q41uk4UL/M1oWWgibei26DKHBvluTxeNvuYP0qZIOtDPjZcg7g4+RwdfDeQ15GsVD8aVAY+ZmPZi4jRG8BLS59J+n2k48Am/Nfl8Gby97Bsm4xQyqDrlGrjbejZTiWNC05uxkmXxLGPfOyfYuZqUvOIbMXQKB2t8b6Mk5oXn31WEKvyo2j3/eKMseELGMjtid/o/KRq8elOMj7Qu2TjwMVTQgGxDtk0mcul1CNxh7djzBq59sX6VZztxrxxq29sLdaaFcdO9vna/rlEisprVKw4+qyhU/b6XZHK8cltdLzUGeLx61dj7MQhxF3sYutT2wWHuPNF6ziOu/fyEFdbNk58cxxvdM5dnG6q9S/2ewPjVmFOjJFOkPgIs1hziwujGiKb1EgowHZarFhcfQX7Sff3j2IlN4AZNPptoOd5WxmdWN0yjQdxwPWNq4VxKigDXcFV4EFXho6+ZuQP9jb0M7G/Dx4Bw8UxkDoyJ0h3cg28fgA4D6gOfWv3AreCHs7Pfz6ZeTQ+ej3rN9g3zJhSvXqXJD1upvrGVWF+bJWPZSymP5Xq/HTgZZW8JRif8ETSC+5JbPFXj1FZcPoDrwncHbklxD/1L4PLfZx04lbWEbvA/PE5BehXsn8jNbsYZx238ceNusqY5eqMv2GPMU4phQzOKah78JkffCaK1/Ebd6pfDfFoXc1K8JPehngdOV58vOx3gPg42obtbTAMRIlH7hM4PAoKHiEhSHfspGBTdliOTSYdUzX+9El16lj/CdQlSyF/NAfiKtDvBuqPl3VkhoBPvBE9GxsmQhujZeDiTq3zlKSMJsR3DGVk5etntMGBKKex02SD60uiiTPRpH5oGXi9/vpbPqWf4eMfQiqnA9xdQMeFjtyX5YN9GLomzYv+WSp+mqgMDUIf0A2o3q1Ad/ZsMJ0Yu8fJ7hTiziZ3JWgLtDA0cRPwX05aIPjqrj8f9ATHAX3DrgF6YH0B9M+BWhAFQtzpGAYB3dlzgH5VWoO9H7o/2eZg18lV77jh04vYk4DJZmK1ETKBPxxlYMpaMhOf+ham+e6ZlIZNBF6W7ZmaGkrdKyPATLYHVX5G0cftlcobKinuCDBx+hWrJ/geRInHSXErbyitOCPArLUEY4FeiWuB/odDnnyDMX7MF6cRDaUUbwSYJH3nlefNYLDNJn9C8Wr+f5fUeA93vynlvwT0OjwN6Amu30P1CaLX5w/gPaDX4hbSBinCCPwDokcGmWxPCt0AAAAASUVORK5CYII='/%3e%3c/defs%3e%3c/svg%3e)
'%3e%3cg%20clip-path='url(%23clip1_44_1058)'%3e%3cpath%20d='M59.1335%2034.6053H64.7716C68.1417%2034.6053%2070.4225%2032.7473%2070.4225%2030.0051C70.4413%2029.3716%2070.3256%2028.7412%2070.0831%2028.1556C69.8405%2027.5701%2069.4766%2027.0425%2069.0153%2026.6079C68.554%2026.1732%2068.0058%2025.8413%2067.4068%2025.6339C66.8079%2025.4266%2066.1718%2025.3485%2065.5404%2025.4049H59.1335V34.6053ZM64.7332%2041.4735H59.1335V53.6081H50.8174V18.5367H66.463C73.9976%2018.5367%2079.0206%2023.1241%2079.0206%2030.0692C79.0513%2032.103%2078.5009%2034.1034%2077.434%2035.8352C76.3672%2037.5671%2074.8283%2038.9586%2072.9981%2039.8461L81.9677%2053.6338H72.1524L64.7332%2041.4735Z'%20fill='white'/%3e%3cpath%20d='M83.929%2027.776H91.9889V53.6086H83.929V27.776ZM83.314%2020.0877C83.314%2018.8507%2083.8054%2017.6643%2084.6801%2016.7896C85.5548%2015.9149%2086.7412%2015.4235%2087.9782%2015.4235C89.2152%2015.4235%2090.4016%2015.9149%2091.2763%2016.7896C92.151%2017.6643%2092.6424%2018.8507%2092.6424%2020.0877C92.6424%2021.3247%2092.151%2022.5111%2091.2763%2023.3858C90.4016%2024.2605%2089.2152%2024.7519%2087.9782%2024.7519C86.7412%2024.7519%2085.5548%2024.2605%2084.6801%2023.3858C83.8054%2022.5111%2083.314%2021.3247%2083.314%2020.0877Z'%20fill='white'/%3e%3cpath%20d='M94.001%2027.7759H102.766L108.596%2044.4595L114.375%2027.7759H123.191L112.619%2053.6085H104.611L94.001%2027.7759Z'%20fill='white'/%3e%3cpath%20d='M131.25%2038.1036H140.681C140.168%2035.1692%20138.605%2033.6059%20135.901%2033.6059C133.197%2033.6059%20131.775%2035.2204%20131.25%2038.1036ZM148.933%2043.511H131.211C131.685%2046.1634%20133.108%2047.778%20136.183%2047.778C137.174%2047.7983%20138.157%2047.5958%20139.06%2047.1856C139.963%2046.7753%20140.762%2046.1676%20141.398%2045.4074L147.651%2048.4443C146.369%2050.2515%20144.658%2051.7125%20142.672%2052.6964C140.686%2053.6804%20138.488%2054.1565%20136.273%2054.0824C128.123%2054.0824%20122.677%2048.8672%20122.677%2040.9482C122.677%2032.7986%20127.931%2027.3015%20135.901%2027.3015C143.871%2027.3015%20149.125%2032.427%20149.125%2040.2819C149.125%2041.3839%20149.022%2042.614%20148.933%2043.511Z'%20fill='white'/%3e%3cpath%20d='M168.051%2027.3013L167.538%2034.6948C162.605%2034.6948%20159.145%2036.9629%20159.145%2040.3329V53.608H151.137V27.7754H158.915L159.081%2030.8763C160.243%2029.6856%20161.641%2028.7521%20163.186%2028.1363C164.732%2027.5204%20166.389%2027.2359%20168.051%2027.3013Z'%20fill='white'/%3e%3cpath%20d='M194.96%2027.7755V50.8404C194.96%2059.0412%20189.079%2064.4358%20180.173%2064.4358C176.495%2064.5791%20172.879%2063.4625%20169.922%2061.2708L171.677%2054.9664C174.073%2056.7307%20176.995%2057.6338%20179.968%2057.5292C180.856%2057.589%20181.748%2057.4652%20182.586%2057.1655C183.425%2056.8657%20184.192%2056.3964%20184.842%2055.7869C185.491%2055.1774%20186.008%2054.4407%20186.359%2053.6227C186.711%2052.8048%20186.891%2051.923%20186.887%2051.0326C185.96%2051.9861%20184.847%2052.7395%20183.617%2053.2464C182.388%2053.7532%20181.067%2054.0028%20179.737%2053.9798C173.997%2053.9798%20170.165%2049.9434%20170.165%2043.8312V27.7755H178.212V42.7549C178.18%2043.3443%20178.269%2043.9341%20178.472%2044.4882C178.676%2045.0423%20178.99%2045.5491%20179.396%2045.9777C179.802%2046.4063%20180.291%2046.7477%20180.833%2046.981C181.375%2047.2143%20181.96%2047.3346%20182.55%2047.3346C183.14%2047.3346%20183.724%2047.2143%20184.267%2046.981C184.809%2046.7477%20185.298%2046.4063%20185.704%2045.9777C186.11%2045.5491%20186.424%2045.0423%20186.627%2044.4882C186.831%2043.9341%20186.919%2043.3443%20186.887%2042.7549V27.7755H194.96Z'%20fill='white'/%3e%3cpath%20d='M3.73985%2024.6109L15.9642%2031.5688L3.73985%2038.5651V24.6109ZM3.73985%2053.6085V42.6399L22.9606%2053.6085H30.0594L7.25084%2040.5897L23.0631%2031.62L0.19043%2018.5371V53.6085H3.73985Z'%20fill='white'/%3e%3cpath%20d='M31.7124%2047.5348L19.488%2040.564L31.7124%2033.6061V47.5348ZM31.7124%2018.5371V29.5057L12.4917%2018.5371H5.31592L28.2014%2031.5559L12.3891%2040.5256L35.2618%2053.6085V18.5371H31.7124Z'%20fill='white'/%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_44_1058'%3e%3crect%20width='194.731'%20height='80'%20fill='white'%20transform='translate(0.19043)'/%3e%3c/clipPath%3e%3cclipPath%20id='clip1_44_1058'%3e%3crect%20width='194.731'%20height='49'%20fill='white'%20transform='translate(0.19043%2015.5)'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
'%3e%3cpath%20d='M20.9248%2032.5938L16.9654%2048.0895H13.8115L10.4593%2036.1065L7.10709%2048.0895H3.95941L0%2032.5938H2.8131L5.57664%2045.1935L9.04655%2032.5938H11.8782L15.3667%2045.1935L18.1117%2032.5938H20.9248Z'%20fill='white'/%3e%3cpath%20d='M33.745%2042.5394H24.209C24.1876%2043.0451%2024.2697%2043.5499%2024.4506%2044.0244C24.6314%2044.4987%2024.9074%2044.9332%2025.2624%2045.3024C25.9349%2045.909%2026.8254%2046.2327%2027.7409%2046.2032C28.5171%2046.2264%2029.2801%2046.0037%2029.9157%2045.5684C30.4755%2045.1672%2030.8568%2044.5724%2030.9815%2043.9057H33.7264C33.573%2044.7411%2033.2096%2045.5262%2032.669%2046.1909C32.1283%2046.8556%2031.4272%2047.3792%2030.6283%2047.7147C29.7434%2048.0989%2028.7836%2048.2907%2027.8152%2048.277C26.707%2048.2999%2025.6117%2048.0416%2024.6365%2047.5273C23.7131%2047.0306%2022.9575%2046.2829%2022.4616%2045.3749C21.9133%2044.3439%2021.6466%2043.1924%2021.6871%2042.0315C21.6586%2040.8858%2021.9295%2039.7519%2022.474%2038.7365C22.972%2037.8316%2023.7273%2037.0863%2024.6489%2036.5902C25.6241%2036.0759%2026.7194%2035.8176%2027.8276%2035.8405C28.9365%2035.8161%2030.0331%2036.0701%2031.0125%2036.5781C31.8948%2037.0411%2032.6219%2037.7421%2033.1068%2038.5974C33.6023%2039.4829%2033.8542%2040.4786%2033.838%2041.4874C33.8408%2041.8401%2033.8097%2042.1923%2033.745%2042.5394ZM30.8328%2039.4076C30.5558%2038.8906%2030.1233%2038.4687%2029.5935%2038.1984C29.0397%2037.9537%2028.4352%2037.8378%2027.8276%2037.8598C26.9022%2037.8307%2026.001%2038.1513%2025.3119%2038.7546C24.9547%2039.1032%2024.6729%2039.5184%2024.4834%2039.9754C24.2939%2040.4324%2024.2006%2040.9219%2024.209%2041.4148H31.2479C31.3058%2040.7209%2031.162%2040.0252%2030.8328%2039.4076Z'%20fill='white'/%3e%3cpath%20d='M45.4124%2036.5903C46.2747%2037.1024%2046.9657%2037.8481%2047.4014%2038.7366C47.9026%2039.7647%2048.1489%2040.8935%2048.1202%2042.0317C48.1518%2043.1759%2047.9055%2044.3112%2047.4014%2045.3449C46.9677%2046.2362%2046.2763%2046.9843%2045.4124%2047.4972C44.5383%2048.0054%2043.536%2048.265%2042.5188%2048.2469C41.5006%2048.2732%2040.4995%2047.9878%2039.6561%2047.4307C38.8758%2046.9114%2038.2905%2046.1578%2037.9893%2045.2844V48.0897H35.4116V31.8442H37.9769V38.8031C38.2802%2037.9257%2038.8701%2037.1697%2039.6561%2036.6508C40.503%2036.0912%2041.5088%2035.8057%2042.5311%2035.8346C43.5448%2035.8205%2044.5425%2036.0822%2045.4124%2036.5903ZM39.7986%2038.531C39.222%2038.8652%2038.7538%2039.3514%2038.4478%2039.9337C38.1086%2040.5827%2037.9384%2041.3032%2037.9521%2042.0317C37.9355%2042.7642%2038.1059%2043.4893%2038.4478%2044.1417C38.7559%2044.7194%2039.2239%2045.2011%2039.7986%2045.5323C40.3845%2045.8666%2041.0531%2046.0381%2041.7318%2046.028C42.2403%2046.0494%2042.7478%2045.9656%2043.2208%2045.7822C43.6939%2045.5989%2044.1219%2045.32%2044.4768%2044.9639C45.2043%2044.1578%2045.5762%2043.104%2045.5115%2042.0317C45.5715%2040.9637%2045.2%2039.9152%2044.4768%2039.1115C44.1234%2038.7526%2043.696%2038.4711%2043.2228%2038.2855C42.7496%2038.1%2042.2414%2038.0147%2041.7318%2038.0353C41.0533%2038.0268%2040.3852%2038.1981%2039.7986%2038.531Z'%20fill='white'/%3e%3cpath%20d='M80%2050H51.3047V30H80V50ZM54.5957%2047.2725H58.3438V41.7285H63.4248V38.6211H58.3438V36.1602H64.6084L62.6689%2033.0771H54.5957V47.2725ZM64.1377%2033.0771L68.6426%2040.1738L68.6416%2040.1748H68.6426L64.1377%2047.2725H68.6426L70.9346%2043.6562L73.3145%2047.2725H77.6455L73.1406%2040.1748L77.6455%2033.0771H73.1406L70.8477%2036.6943L68.4629%2033.0771H64.1377Z'%20fill='white'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_112_698'%3e%3crect%20width='80'%20height='20'%20fill='white'%20transform='translate(0%2030)'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)

'%3e%3cpath%20d='M13.5361%2027.5H8.10821L0%2047.4076H5.42791L13.5361%2027.5Z'%20fill='white'/%3e%3cpath%20d='M14.7779%2028.1279L12.0527%2034.8187L17.1798%2047.4076H22.9336L14.7779%2028.1279Z'%20fill='white'/%3e%3cpath%20d='M32.7429%2033.2363C31.7703%2033.2363%2030.8967%2033.4341%2030.122%2033.8284C29.346%2034.2227%2028.7152%2034.7962%2028.2296%2035.5489V33.5748H24.1082V47.4236H28.3417V39.6669C28.3417%2038.727%2028.6083%2037.9743%2029.1415%2037.4101C29.6733%2036.8459%2030.3794%2036.5631%2031.2583%2036.5631C31.9881%2036.5631%2032.5239%2036.7795%2032.8709%2037.2123C33.2167%2037.645%2033.3896%2038.3314%2033.3896%2039.2713V47.4223H37.6232V39.0735C37.6232%2037.118%2037.2207%2035.6564%2036.417%2034.6873C35.612%2033.7209%2034.3873%2033.2363%2032.7429%2033.2363Z'%20fill='white'/%3e%3cpath%20d='M47.7597%2039.2727L45.4331%2038.7364C44.8722%2038.5864%2044.479%2038.4271%2044.2546%2038.2572C44.0316%2038.0873%2043.9194%2037.8523%2043.9194%2037.5523C43.9194%2037.1394%2044.1055%2036.8195%2044.479%2036.5938C44.8525%2036.3681%2045.3671%2036.2553%2046.0217%2036.2553C47.4417%2036.2553%2048.8815%2036.7624%2050.3398%2037.7779L51.4615%2034.9583C50.7132%2034.4127%2049.8726%2033.9905%2048.9382%2033.6892C48.0039%2033.3891%2047.0405%2033.2378%2046.0507%2033.2378C44.8907%2033.2378%2043.8587%2033.4263%2042.9521%2033.802C42.0455%2034.1777%2041.3447%2034.6954%2040.8498%2035.3525C40.3536%2036.011%2040.1068%2036.773%2040.1068%2037.6372C40.1068%2038.7284%2040.4209%2039.5887%2041.0465%2040.2179C41.672%2040.8485%2042.6499%2041.3131%2043.9775%2041.6145L46.221%2042.1229C46.9125%2042.2729%2047.3836%2042.4429%2047.637%2042.6301C47.8891%2042.8186%2048.0158%2043.0814%2048.0158%2043.4199C48.0158%2043.7969%2047.8337%2044.093%2047.4694%2044.308C47.1052%2044.5244%2046.5945%2044.632%2045.9412%2044.632C45.0253%2044.632%2044.1187%2044.4912%2043.2213%2044.2098C42.3252%2043.927%2041.5017%2043.5328%2040.7535%2043.0257L39.6331%2045.9582C40.3985%2046.5038%2041.3104%2046.9219%2042.3661%2047.214C43.4219%2047.5047%2044.5859%2047.6508%2045.8567%2047.6508C47.707%2047.6508%2049.1599%2047.2698%2050.217%2046.5078C51.2728%2045.7458%2051.8007%2044.6983%2051.8007%2043.3628C51.8007%2042.2544%2051.4787%2041.3742%2050.8333%2040.7264C50.1853%2040.0759%2049.1626%2039.5927%2047.7597%2039.2727Z'%20fill='white'/%3e%3cpath%20d='M79.0313%2040.725C78.386%2040.0759%2077.3632%2039.5927%2075.9617%2039.2727L73.6338%2038.7364C73.0742%2038.5864%2072.6809%2038.4271%2072.4566%2038.2572C72.2322%2038.0873%2072.1201%2037.8523%2072.1201%2037.5523C72.1201%2037.1394%2072.3075%2036.8195%2072.6809%2036.5938C73.0544%2036.3681%2073.5691%2036.2553%2074.2237%2036.2553C75.6437%2036.2553%2077.0835%2036.7624%2078.5417%2037.7779L79.6621%2034.9583C78.9152%2034.4127%2078.0732%2033.9905%2077.1389%2033.6892C76.2045%2033.3891%2075.2425%2033.2378%2074.2514%2033.2378C73.0927%2033.2378%2072.0594%2033.4263%2071.154%2033.802C70.2461%2034.1777%2069.5453%2034.6954%2069.0505%2035.3525C68.5556%2036.011%2068.3075%2036.773%2068.3075%2037.6372C68.3075%2038.7284%2068.6202%2039.5887%2069.2471%2040.2179C69.8726%2040.8485%2070.8492%2041.3131%2072.1768%2041.6145L74.4203%2042.1229C75.1118%2042.2729%2075.5843%2042.4429%2075.8363%2042.6301C76.0897%2042.8186%2076.2151%2043.0814%2076.2151%2043.4199C76.2151%2043.7969%2076.033%2044.093%2075.6687%2044.308C75.3045%2044.5244%2074.7951%2044.632%2074.1405%2044.632C73.2247%2044.632%2072.318%2044.4912%2071.4206%2044.2098C70.5232%2043.927%2069.6997%2043.5328%2068.9528%2043.0257L67.8311%2045.9582C68.5978%2046.5038%2069.5084%2046.9219%2070.5655%2047.214C71.6212%2047.5047%2072.7839%2047.6508%2074.0561%2047.6508C75.9063%2047.6508%2077.3593%2047.2698%2078.4163%2046.5078C79.4721%2045.7458%2080%2044.6983%2080%2043.3628C79.9973%2042.253%2079.6753%2041.3742%2079.0313%2040.725Z'%20fill='white'/%3e%3cpath%20d='M63.4748%2033.5918L60.165%2041.7176L56.8539%2033.5918H52.7642L58.1195%2046.7396L55.7731%2052.4998H59.8628L67.5646%2033.5918H63.4748Z'%20fill='white'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_113_1895'%3e%3crect%20width='80'%20height='25'%20fill='white'%20transform='translate(0%2027.5)'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
'%3e%3cg%20clip-path='url(%23clip1_98_1401)'%3e%3cpath%20fill-rule='evenodd'%20clip-rule='evenodd'%20d='M195.697%2026C185.987%2026%20179.561%2031.584%20179.561%2040C179.561%2048.414%20186.023%2054%20195.697%2054C205.373%2054%20211.833%2048.414%20211.833%2040C211.833%2031.586%20205.409%2026%20195.697%2026ZM195.697%2030.552C202.121%2030.552%20206.405%2034.186%20206.405%2040C206.405%2045.814%20202.121%2049.41%20195.697%2049.41C189.273%2049.41%20184.991%2045.814%20184.991%2040C184.991%2034.186%20189.273%2030.552%20195.697%2030.552Z'%20fill='white'/%3e%3cpath%20d='M5.48114%2026.2661H0.421143V53.7381H5.99114V33.9581L26.5071%2053.7381H31.6071V26.2661H26.0371V46.0461L5.48114%2026.2661ZM63.1811%2026.2661H36.7051V53.7381H63.1811V49.0261H42.2751V42.3361H63.1811V37.6681H42.2751V30.9361H63.1811V26.2661ZM66.4031%2026.2661H72.4431L79.7411%2046.5161L86.6411%2026.2661H92.0971L98.9591%2046.5161L106.295%2026.2661H112.335L102.175%2053.7381H95.9011L89.3871%2034.3901L82.7971%2053.7381H76.5631L66.4031%2026.2661ZM220.059%2026.2661H215.001V53.7381H220.571V33.9581L241.085%2053.7381H246.185V26.2661H240.615V46.0461L220.059%2026.2661ZM262.651%2030.9361H250.491V26.2661H280.421V30.9361H268.221V53.7361H262.651V30.9361Z'%20fill='white'/%3e%3cpath%20fill-rule='evenodd'%20clip-rule='evenodd'%20d='M176.661%2034.2999C176.662%2036.1937%20175.994%2038.027%20174.775%2039.4761C173.555%2040.9252%20171.863%2041.897%20169.997%2042.2199L169.993%2042.2159L177.757%2053.7359H171.953L164.269%2042.3359H152.621V53.7359H147.129V26.2639H168.625C173.061%2026.2639%20176.657%2029.8639%20176.657%2034.2999H176.661ZM152.623%2030.9379L152.663%2037.6679H168.065C168.958%2037.6679%20169.814%2037.3134%20170.445%2036.6823C171.076%2036.0513%20171.43%2035.1954%20171.43%2034.3029C171.43%2033.4105%20171.076%2032.5546%20170.445%2031.9235C169.814%2031.2924%20168.958%2030.9379%20168.065%2030.9379H152.623Z'%20fill='white'/%3e%3cpath%20d='M115.557%2026.2661H142.035V30.9361H121.127V37.6661H142.035V42.3361H121.127V53.7361H115.557V26.2681V26.2661Z'%20fill='white'/%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_98_1401'%3e%3crect%20width='280'%20height='80'%20fill='white'%20transform='translate(0.421143)'/%3e%3c/clipPath%3e%3cclipPath%20id='clip1_98_1401'%3e%3crect%20width='280'%20height='40'%20fill='white'%20transform='translate(0.421143%2020)'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
'%3e%3cpath%20d='M34.0341%2035.715H31.7327V38.1282H34.0341V43.3997C34.0341%2046.0238%2035.7079%2047.5233%2038.2652%2047.5233H40.1482V44.9226H38.5905C37.5212%2044.9226%2036.8936%2044.3135%2036.8936%2043.1186V38.1282H40.1482V35.715H36.8936V32.1538H34.0341V35.715Z'%20fill='white'/%3e%3cpath%20d='M41.4807%2033.8645H44.6425V30.5845H41.4807V33.8645ZM44.4798%2047.5237V35.7154H41.6202V47.5237H44.4798Z'%20fill='white'/%3e%3cpath%20d='M49.092%2047.5235V41.0805C49.092%2039.3468%2050.2081%2038.0816%2051.812%2038.0816C53.2766%2038.0816%2054.2529%2039.2062%2054.2529%2040.8228V47.5235H57.1125V40.2136C57.1125%2037.449%2055.3922%2035.5278%2052.742%2035.5278C51.068%2035.5278%2049.743%2036.2541%2049.092%2037.5427V35.7153H46.2327V47.5235H49.092Z'%20fill='white'/%3e%3cpath%20d='M66.9258%2043.5874C66.6236%2044.712%2065.6704%2045.3212%2064.2058%2045.3212C62.3924%2045.3212%2061.1836%2044.1029%2060.9744%2042.2051H69.6224C69.6458%2041.9708%2069.6689%2041.6194%2069.6689%2041.2211C69.6689%2038.4096%2067.9021%2035.5278%2063.9734%2035.5278C60.1376%2035.5278%2058.2312%2038.4565%2058.2312%2041.5725C58.2312%2044.6652%2060.3699%2047.711%2064.2058%2047.711C67.0885%2047.711%2069.2737%2046.0944%2069.7154%2043.5874H66.9258ZM63.9734%2037.6833C65.6704%2037.6833%2066.6932%2038.8079%2066.8096%2040.3074H61.0442C61.3464%2038.5268%2062.3693%2037.6833%2063.9734%2037.6833Z'%20fill='white'/%3e%3cpath%20d='M75.4092%2047.711C78.1524%2047.711%2079.9424%2046.2584%2079.9424%2044.0326C79.9424%2038.6908%2073.4332%2041.5022%2073.4332%2038.9485C73.4332%2038.1519%2074.1073%2037.6833%2075.1302%2037.6833C76.0368%2037.6833%2077.0365%2038.2456%2077.1992%2039.3468H79.803C79.6867%2037.0507%2077.8037%2035.5278%2075.0605%2035.5278C72.6427%2035.5278%2070.8528%2036.9804%2070.8528%2039.0422C70.8528%2044.0326%2077.2691%2041.5257%2077.2691%2044.1497C77.2691%2044.8526%2076.5251%2045.4149%2075.4092%2045.4149C74.1307%2045.4149%2073.2705%2044.712%2073.1542%2043.5874H70.5505C70.6901%2046.1178%2072.5731%2047.711%2075.4092%2047.711Z'%20fill='white'/%3e%3cpath%20fill-rule='evenodd'%20clip-rule='evenodd'%20d='M8.82656%2027.5C5.89073%2027.5%203.29493%2029.4199%202.41631%2032.2411L0%2040L2.41631%2047.7588C3.29493%2050.58%205.89073%2052.5%208.82656%2052.5H15.3353C18.2711%2052.5%2020.867%2050.58%2021.7455%2047.7588L24.1619%2040L21.7455%2032.2411C20.867%2029.4199%2018.2711%2027.5%2015.3353%2027.5H8.82656ZM15.3354%2029.4503C17.425%2029.4503%2019.2726%2030.8168%2019.8979%2032.8248L20.4903%2034.727C19.2986%2033.7356%2017.7894%2033.1775%2016.2121%2033.1774L7.93211%2033.1772C6.3654%2033.1773%204.86596%2033.7279%203.67799%2034.7069L4.26412%2032.8248C4.88949%2030.8168%206.73705%2029.4503%208.82665%2029.4503H15.3354ZM4.12496%2037.0301L2.62042%2039.0249H21.5237L20.0193%2037.0304C19.1152%2035.8317%2017.7066%2035.1278%2016.212%2035.1276H7.88703C6.40926%2035.1418%205.01993%2035.8436%204.12496%2037.0301ZM21.5206%2040.9752L20.0191%2042.9679C19.115%2044.1679%2017.7054%2044.8726%2016.2097%2044.8725L7.93435%2044.8723C6.43864%2044.8724%205.02902%2044.1676%204.12486%2042.9676L2.62359%2040.9752H21.5206ZM4.264%2047.1751C4.88936%2049.1831%206.73695%2050.5498%208.82654%2050.5498H15.3353C17.4249%2050.5498%2019.2725%2049.1831%2019.8978%2047.1751L20.4906%2045.2715C19.2984%2046.2642%2017.7881%2046.8229%2016.2095%2046.8228L7.93449%2046.8226C6.36647%2046.8227%204.86582%2046.2714%203.67727%2045.2911L4.264%2047.1751Z'%20fill='white'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_112_1019'%3e%3crect%20width='80'%20height='25'%20fill='white'%20transform='translate(0%2027.5)'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
'%3e%3cpath%20d='M7.29037%2040.5861H4.55874L6.01361%2035.8016L7.29037%2040.5861ZM3.14189%2045.8587L4.07444%2042.7081H7.75465L8.62718%2045.8507H12.0292L8.64919%2033.8692C8.44907%2033.1612%208.02882%2032.8345%207.29037%2032.8345H2.46548V33.9661H2.86572C3.37002%2033.9661%203.64219%2034.1678%203.64219%2034.553C3.64219%2034.8092%203.58615%2035.023%203.38603%2035.6059L0%2045.8587H3.14189Z'%20fill='white'/%3e%3cpath%20d='M15.9657%2045.8587V33.8329C15.9657%2033.2056%2015.6015%2032.8345%2014.9991%2032.8345H12.0073V33.9661H12.2074C12.7097%2033.9661%2012.9239%2034.1819%2012.9239%2034.6942V45.8587H15.9657Z'%20fill='white'/%3e%3cpath%20d='M21.1367%2045.8587V33.8329C21.1367%2033.2056%2020.7664%2032.8345%2020.1681%2032.8345H17.1863V33.9661H17.3864C17.8907%2033.9661%2018.1048%2034.1819%2018.1048%2034.6942V45.8587H21.1367Z'%20fill='white'/%3e%3cpath%20d='M26.4419%2034.0223C26.4419%2033.1489%2025.7995%2032.6104%2024.6988%2032.6104C23.5982%2032.6104%2022.9518%2033.1388%2022.9518%2034.0223C22.9518%2034.9058%2023.6142%2035.4343%2024.6988%2035.4343C25.7835%2035.4343%2026.4419%2034.9098%2026.4419%2034.0223ZM26.3838%2045.8585V37.0923C26.3838%2036.467%2026.0156%2036.0979%2025.4132%2036.0979H22.4695V37.2073H22.6436C23.1459%2037.2073%2023.36%2037.4413%2023.36%2037.9496V45.8585H26.3838Z'%20fill='white'/%3e%3cpath%20d='M33.0439%2041.1707V43.0688C32.5376%2043.5952%2031.9212%2043.9179%2031.3989%2043.9179C30.8766%2043.9179%2030.6624%2043.6477%2030.6624%2042.9094C30.6624%2042.1712%2030.8145%2041.8585%2031.3589%2041.6467C31.9009%2041.4243%2032.4661%2041.2646%2033.0439%2041.1707ZM28.9534%2038.8914C29.883%2038.4266%2030.9002%2038.1666%2031.9372%2038.1289C32.7537%2038.1289%2033.0439%2038.4214%2033.0439%2039.2746V39.4925C31.8051%2039.6942%2031.4169%2039.7708%2030.7185%2039.9261C30.3273%2040.013%2029.9443%2040.1338%2029.5738%2040.2872C28.3511%2040.7814%2027.7727%2041.7335%2027.7727%2043.1958C27.7727%2045.0515%2028.5732%2045.9471%2030.2122%2045.9471C30.7697%2045.9494%2031.3225%2045.8447%2031.8411%2045.6385C32.3116%2045.4227%2032.7489%2045.1401%2033.1399%2044.7994V44.9366C33.1399%2045.5417%2033.4481%2045.8503%2034.0505%2045.8503H36.8221V44.8075H36.6861C36.1637%2044.8075%2035.9716%2044.5715%2035.9716%2043.9482V39.2988C35.9716%2036.8199%2035.1171%2035.9565%2032.6536%2035.9565C31.8727%2035.9605%2031.0946%2036.0532%2030.3342%2036.2329C29.6159%2036.3944%2028.9239%2036.6579%2028.279%2037.0155L28.9534%2038.8914Z'%20fill='white'/%3e%3cpath%20d='M41.2347%2045.8586V39.2587C41.741%2038.6919%2042.2613%2038.4357%2042.8616%2038.4357C43.504%2038.4357%2043.6621%2038.6919%2043.6621%2039.6742V45.8586H46.6839V39.2224C46.6839%2037.6773%2046.5739%2037.1892%2046.0836%2036.6647C45.6833%2036.2109%2045.057%2035.981%2044.2585%2035.981C43.0758%2035.981%2042.2433%2036.3501%2041.1246%2037.405V37.0157C41.1246%2036.4106%2040.8104%2036.0979%2040.192%2036.0979H37.3203V37.2073H37.4944C37.9967%2037.2073%2038.2128%2037.4413%2038.2128%2037.9496V45.8586H41.2347Z'%20fill='white'/%3e%3cpath%20d='M55.6474%2043.8091H51.4308L55.4633%2038.1108V36.0938H49.1395C48.423%2036.0938%2048.0928%2036.4246%2048.0928%2037.1487V38.9237H49.2155V38.7502C49.2155%2038.3004%2049.4477%2038.0866%2049.9299%2038.0866H52.1033L48.0288%2043.8494V45.8665H55.6334L55.6474%2043.8091Z'%20fill='white'/%3e%3cpath%20d='M71.5108%2045.6106V34.5752C71.5108%2033.6958%2071.2006%2033.3993%2070.3541%2033.3993H67.7906V34.6398H67.9447C68.529%2034.6398%2068.6431%2034.7729%2068.6431%2035.4829V45.6106H71.5108ZM72.7756%2045.6106H75.6213V37.0159C75.6213%2036.1526%2075.2911%2035.8419%2074.4566%2035.8419H72.7756V45.6106ZM67.3863%2045.6106V35.85H65.6993C64.8648%2035.85%2064.5386%2036.1606%2064.5386%2037.0239V45.6106H67.3863ZM78.3149%2040.0012C78.3149%2044.8643%2074.8448%2048.4003%2070.08%2048.4003C65.3151%2048.4003%2061.837%2044.8643%2061.837%2040.0012C61.837%2035.138%2065.3131%2031.602%2070.08%2031.602C74.8468%2031.602%2078.3149%2035.1582%2078.3149%2040.0012ZM79.9999%2040.0012C79.9999%2034.2827%2075.7554%2030.0005%2070.08%2030.0005C64.4046%2030.0005%2060.156%2034.2827%2060.156%2040.0012C60.156%2045.7196%2064.4006%2049.9998%2070.08%2049.9998C75.7594%2049.9998%2079.9999%2045.7337%2079.9999%2040.0012Z'%20fill='white'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_113_1974'%3e%3crect%20width='80'%20height='20'%20fill='white'%20transform='translate(0%2030)'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)



'%3e%3cmask%20id='mask0_112_1202'%20style='mask-type:luminance'%20maskUnits='userSpaceOnUse'%20x='0'%20y='28'%20width='80'%20height='24'%3e%3cpath%20d='M80%2028.9458H0V51.0542H80V28.9458Z'%20fill='white'/%3e%3c/mask%3e%3cg%20mask='url(%23mask0_112_1202)'%3e%3cpath%20d='M11.9306%2036.0376C11.9306%2034.191%2011.0019%2033.2213%208.77647%2033.2213H5.93007V38.8848H8.77313C11.0031%2038.8848%2011.9306%2037.9461%2011.9306%2036.0376ZM18.1438%2036.0994C18.1438%2038.3701%2016.9947%2039.9451%2014.8386%2041.161L19.5983%2050.5487H12.9343L9.1301%2042.7646H5.93007V50.5464H0V29.3447H9.70408C15.5144%2029.3447%2018.1438%2032.1014%2018.1438%2036.0994Z'%20fill='white'/%3e%3cpath%20d='M62.258%2029.394L59.9419%2033.8769H67.5145V50.5925H73.4804V33.8769H80.0001V29.394H62.258Z'%20fill='white'/%3e%3cpath%20d='M57.0629%2029.3706H60.3077L47.5413%2039.6959V36.1032L57.0629%2029.3706Z'%20fill='white'/%3e%3cpath%20d='M57.0294%2029.3706H60.4196L55.4965%2038.8389L50.126%2041.2433L57.0294%2029.3706Z'%20fill='white'/%3e%3cpath%20d='M50.1147%2041.2432L55.4853%2038.8389L61.3371%2050.5293H54.6451L50.1147%2041.2432Z'%20fill='white'/%3e%3cpath%20d='M47.6509%2029.3877H41.7153V50.5563H47.6509V29.3877Z'%20fill='white'/%3e%3cpath%20fill-rule='evenodd'%20clip-rule='evenodd'%20d='M29.7679%2028.9458C26.7067%2028.9458%2024.234%2029.9398%2022.3833%2031.9145C20.5327%2033.8892%2019.6018%2036.5476%2019.6018%2039.9691V40.0298C19.6018%2043.4535%2020.529%2046.1491%2022.3833%2048.1165C24.2396%2050.0846%2026.7101%2051.0543%2029.7679%2051.0543C32.8259%2051.0543%2035.2997%2050.0846%2037.1235%2048.1165C38.9779%2046.1476%2039.905%2043.4521%2039.905%2040.0298V39.9691C39.905%2036.5453%2038.9775%2033.8848%2037.1235%2031.9145C35.2997%2029.9453%2032.8281%2028.9458%2029.7679%2028.9458ZM29.7389%2033.2531C28.4902%2033.2531%2027.481%2033.8771%2026.7246%2035.1085C25.9683%2036.34%2025.5889%2038.0032%2025.5889%2040.1425V40.18C25.5889%2042.3204%2025.9675%2044.0054%2026.7246%2045.2351C27.4821%2046.4653%2028.4902%2047.0706%2029.7389%2047.0706C30.9875%2047.0706%2031.9968%2046.4653%2032.7408%2045.2351C33.4849%2044.0047%2033.8765%2042.3193%2033.8765%2040.18V40.1425C33.8765%2038.0032%2033.4984%2036.34%2032.7408%2035.1085C31.9833%2033.8771%2030.9931%2033.2575%2029.7389%2033.2575V33.2531Z'%20fill='white'/%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_112_1202'%3e%3crect%20width='80'%20height='23'%20fill='white'%20transform='translate(0%2028.5)'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)

'%3e%3cpath%20d='M16.7029%2030H3.35106C1.50011%2030%200%2031.4944%200%2033.3384V46.6395C0%2048.4835%201.50011%2049.9779%203.35106%2049.9779H16.7029C18.5538%2049.9779%2020.0539%2048.4835%2020.0539%2046.6395V33.3384C20.0539%2031.4944%2018.5538%2030%2016.7029%2030ZM16.4085%2045.2918C16.4085%2045.8743%2015.9347%2046.3463%2015.3499%2046.3463H4.70398C4.11926%2046.3463%203.64544%2045.8743%203.64544%2045.2918V34.6862C3.64544%2034.1036%204.11926%2033.6316%204.70398%2033.6316H15.3499C15.9347%2033.6316%2016.4085%2034.1036%2016.4085%2034.6862V45.2918ZM7.89979%2042.7006C7.56307%2042.7006%207.29289%2042.4294%207.29289%2042.094V37.8598C7.29289%2037.5244%207.56307%2037.2512%207.89979%2037.2512H12.1562C12.4909%2037.2512%2012.7631%2037.5223%2012.7631%2037.8598V42.092C12.7631%2042.4274%2012.4909%2042.6986%2012.1562%2042.6986H7.89979V42.7006ZM25.3709%2042.4114H27.5606C27.6694%2043.6467%2028.5102%2044.6108%2030.2059%2044.6108C31.7201%2044.6108%2032.6517%2043.8656%2032.6517%2042.7388C32.6517%2041.6842%2031.9218%2041.2122%2030.6072%2040.9029L28.9094%2040.5393C27.0666%2040.1396%2025.6794%2038.9585%2025.6794%2037.0302C25.6794%2034.9031%2027.5767%2033.4488%2030.0406%2033.4488C32.6496%2033.4488%2034.3292%2034.8127%2034.4744%2036.8294H32.3573C32.1052%2035.8853%2031.3189%2035.3229%2030.0426%2035.3229C28.6917%2035.3229%2027.7622%2036.05%2027.7622%2036.978C27.7622%2037.906%2028.5647%2038.4684%2029.9519%2038.7777L31.6314%2039.1413C33.4743%2039.541%2034.7325%2040.6498%2034.7325%2042.5942C34.7325%2045.0668%2032.8714%2046.5391%2030.2079%2046.5391C27.2137%2046.5371%2025.5544%2044.9202%2025.3709%2042.4114ZM42.5657%2049.9779V46.3603L42.7089%2044.7735H42.5657C42.0637%2045.9144%2041.0091%2046.5391%2039.5776%2046.5391C37.2689%2046.5391%2035.5511%2044.6671%2035.5511%2041.7967C35.5511%2038.9264%2037.2689%2037.0543%2039.5776%2037.0543C40.991%2037.0543%2041.9931%2037.7132%2042.5657%2038.7476H42.7089V37.2311H44.6062V49.9779H42.5657ZM42.6363%2041.7947C42.6363%2039.9588%2041.5092%2038.8882%2040.13%2038.8882C38.7509%2038.8882%2037.6238%2039.9588%2037.6238%2041.7947C37.6238%2043.6306%2038.7509%2044.7012%2040.13%2044.7012C41.5092%2044.7012%2042.6363%2043.6326%2042.6363%2041.7947ZM46.1204%2042.7408V37.2311H48.1609V42.562C48.1609%2044.0062%2048.8585%2044.7012%2050.0219%2044.7012C51.4535%2044.7012%2052.385%2043.6848%2052.385%2042.098V37.2311H54.4255V46.3583H52.5282V44.4682H52.385C51.9374%2045.6814%2050.9534%2046.5371%2049.4332%2046.5371C47.2475%2046.5371%2046.1204%2045.1471%2046.1204%2042.7408ZM55.6675%2043.8094C55.6675%2042.098%2056.8672%2041.0997%2058.9964%2040.9752L61.5188%2040.8145V40.1014C61.5188%2039.2458%2060.8917%2038.7295%2059.7827%2038.7295C58.7625%2038.7295%2058.1536%2039.2458%2057.9923%2039.9769H55.9518C56.1675%2038.1229%2057.706%2037.0523%2059.7807%2037.0523C62.1257%2037.0523%2063.5572%2038.0506%2063.5572%2039.9769V46.3583H61.6599V44.6651H61.5167C61.0873%2045.7879%2060.192%2046.5371%2058.4742%2046.5371C56.8309%2046.5371%2055.6675%2045.4324%2055.6675%2043.8094ZM61.5208%2042.6866V42.2045L59.4622%2042.3471C58.3532%2042.4174%2057.8511%2042.8292%2057.8511%2043.6487C57.8511%2044.3437%2058.4238%2044.8438%2059.2283%2044.8438C60.68%2044.8438%2061.5208%2043.9178%2061.5208%2042.6866ZM65.0795%2046.3603V37.2311H66.9768V38.9786H67.12C67.3882%2037.7835%2068.3015%2037.2311%2069.6605%2037.2311H70.592V39.067H69.4286C68.1039%2039.067%2067.12%2039.9227%2067.12%2041.5456V46.3583H65.0795V46.3603ZM79.9274%2042.1703H72.9652C73.0721%2043.8455%2074.2536%2044.7916%2075.5601%2044.7916C76.6691%2044.7916%2077.3667%2044.3457%2077.7619%2043.5965H79.7843C79.2298%2045.4504%2077.6006%2046.5371%2075.542%2046.5371C72.8402%2046.5371%2070.9429%2044.5224%2070.9429%2041.7947C70.9429%2039.067%2072.8926%2037.0523%2075.5601%2037.0523C78.2438%2037.0523%2079.998%2038.8882%2079.998%2041.17C80%2041.618%2079.9637%2041.849%2079.9274%2042.1703ZM77.9777%2040.7623C77.9071%2039.4968%2076.8506%2038.6412%2075.5622%2038.6412C74.3443%2038.6412%2073.3261%2039.4085%2073.0741%2040.7623H77.9777Z'%20fill='white'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_112_1099'%3e%3crect%20width='80'%20height='20'%20fill='white'%20transform='translate(0%2030)'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)

'%3e%3cpath%20d='M90.8374%2034.037H86.3199L78.0963%2042.4935V25.5823H74.6212V54.4232H78.0963V44.9261L87.4789%2054.3068L87.5934%2054.4232H91.7635V54.0757L81.2238%2043.6506L90.8374%2034.037ZM68.4883%2049.483C67.2128%2050.7566%2065.3588%2051.4516%2063.2757%2051.4516C59.6842%2051.4516%2056.0927%2049.2501%2056.0927%2044.154C56.0927%2039.8694%2059.1057%2036.8565%2063.2757%2036.8565C65.1278%2036.8565%2066.8653%2037.5515%2068.2553%2038.8269L68.3718%2038.9415L70.5714%2036.6254L70.4568%2036.5089C68.3718%2034.5404%2065.9393%2033.6162%2063.1592%2033.6162C56.7877%2033.6162%2052.5031%2037.9008%2052.5031%2044.1559C52.5031%2051.4535%2057.8302%2054.6975%2063.1592%2054.6975H63.2757C66.0557%2054.6975%2068.7193%2053.655%2070.5714%2051.6845L70.6879%2051.5699L68.3718%2049.252L68.4883%2049.483ZM44.8561%2044.9674C44.8561%2048.6735%2042.309%2051.4535%2038.7175%2051.5699C34.895%2051.5699%2032.5789%2049.2539%2032.5789%2045.3149V34.0802H29.1039V45.3149C29.1039%2051.106%2032.5789%2054.8139%2038.0225%2054.8139H38.139C40.8025%2054.8139%2043.2351%2053.5385%2044.8561%2051.5699L44.9726%2051.3389L45.0891%2054.4664H48.3312V34.0802H44.8561V44.9674ZM10.5416%2025.464H0V54.4232H10.5416C20.6192%2054.4232%2025.0202%2047.0092%2025.0202%2039.7116C25.0202%2032.878%2020.5027%2025.464%2010.5416%2025.464ZM21.4288%2039.597C21.4288%2045.1571%2018.0702%2050.7172%2010.6562%2050.7172H3.70608V29.0536H10.5416C17.9537%2029.0536%2021.4288%2034.4991%2021.4288%2039.597ZM201.789%2041.7948H210.707V48.5138C208.508%2050.3659%20205.842%2051.4084%20202.948%2051.4084C195.072%2051.4084%20191.48%2045.7338%20191.48%2040.1737C191.48%2034.4972%20195.072%2028.3586%20202.831%2028.3586C205.959%2028.3586%20208.855%2029.5175%20211.171%2031.6026L211.288%2031.7172L213.373%2029.2846L213.256%2029.17C210.476%2026.39%20206.77%2025%20202.717%2025C198.314%2025%20194.608%2026.39%20191.944%2029.17C189.164%2031.9501%20187.658%2035.8872%20187.774%2040.2902C187.774%2047.1238%20191.711%2054.9999%20202.831%2054.9999H203.064C205.12%2055.0076%20207.154%2054.5777%20209.031%2053.7389C210.908%2052.9001%20212.586%2051.6716%20213.951%2050.1348V38.6691H201.674V41.7966L201.789%2041.7948ZM105.65%2025.464H95.1089V54.4232H105.65C115.728%2054.4232%20120.129%2047.0092%20120.129%2039.7116C120.129%2032.878%20115.612%2025.464%20105.65%2025.464ZM116.538%2039.597C116.538%2045.1571%20113.179%2050.7172%20105.765%2050.7172H98.9314V29.0555H105.765C113.063%2029.0555%20116.538%2034.4991%20116.538%2039.597ZM228.233%2033.6143C222.092%2033.6143%20217.691%2038.1319%20217.691%2044.2705C217.691%2050.4091%20222.092%2054.8102%20228.233%2054.8102C234.371%2054.8102%20238.889%2050.4091%20238.889%2044.2705C238.889%2038.0154%20234.488%2033.6143%20228.233%2033.6143ZM235.414%2044.2705C235.414%2048.557%20232.403%2051.5681%20228.233%2051.5681C224.177%2051.5681%20221.166%2048.557%20221.166%2044.2705C221.166%2039.8694%20224.063%2036.7419%20228.347%2036.7419C232.403%2036.8564%20235.414%2039.984%20235.414%2044.2705ZM139.965%2044.9674C139.965%2048.6735%20137.418%2051.4535%20133.826%2051.5699C130.004%2051.5699%20127.688%2049.2539%20127.688%2045.3149V34.0802H124.213V45.3149C124.213%2051.106%20127.688%2054.8139%20133.015%2054.8139H133.131C135.795%2054.8139%20138.228%2053.5385%20139.849%2051.5699L139.965%2051.3389L140.082%2054.4664H143.324V34.0802H139.849V44.9674H139.965ZM163.595%2049.483C162.322%2050.7566%20160.468%2051.4516%20158.383%2051.4516C154.793%2051.4516%20151.202%2049.2501%20151.202%2044.154C151.202%2039.8694%20154.213%2036.8565%20158.383%2036.8565C160.237%2036.8565%20161.974%2037.5515%20163.364%2038.8269L163.481%2038.9415L165.68%2036.6254L165.566%2036.5089C163.481%2034.5404%20161.048%2033.6143%20158.268%2033.6143C151.897%2033.6143%20147.612%2037.899%20147.612%2044.154C147.612%2051.4516%20152.939%2054.6956%20158.268%2054.6956H158.383C161.163%2054.6956%20163.828%2053.6531%20165.68%2051.6826L165.797%2051.5681L163.481%2049.2501L163.595%2049.483ZM185.946%2034.037H181.429L173.205%2042.4935V25.5823H169.73V54.4232H173.205V44.9261L182.586%2054.3068L182.702%2054.4232H186.872V54.0757L176.333%2043.6506L185.946%2034.037Z'%20fill='white'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_101_2165'%3e%3crect%20width='238.889'%20height='80'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
'%3e%3cg%20clip-path='url(%23clip1_101_2384)'%3e%3cpath%20d='M0.194336%2060.6577H23.4595V63.9881H0.194336V60.6577Z'%20fill='white'/%3e%3cpath%20d='M0.194336%2054.2698H23.4595V57.6119H0.194336V54.2698Z'%20fill='white'/%3e%3cpath%20d='M6.83154%2047.8933H16.8108V51.2356H6.83154V47.8933Z'%20fill='white'/%3e%3cpath%20d='M6.83154%2041.5171H16.8108V44.8593H6.83154V41.5171Z'%20fill='white'/%3e%3cpath%20d='M6.83154%2035.1406H16.8108V38.4829H6.83154V35.1406Z'%20fill='white'/%3e%3cpath%20d='M6.83154%2028.7527H16.8108V32.0949H6.83154V28.7527Z'%20fill='white'/%3e%3cpath%20d='M23.4595%2022.3762H0.194336V25.7185H23.4595V22.3762Z'%20fill='white'/%3e%3cpath%20d='M23.4595%2016H0.194336V19.3422H23.4595V16Z'%20fill='white'/%3e%3cpath%20d='M26.7781%2057.6118H62.5588C63.1632%2056.5807%2063.6135%2055.4547%2063.8862%2054.2695H26.7781V57.6118Z'%20fill='white'/%3e%3cpath%20d='M59.7736%2041.5171H33.427V44.8593H62.5589C61.8003%2043.5792%2060.864%2042.4534%2059.7736%2041.5171Z'%20fill='white'/%3e%3cpath%20d='M33.427%2035.1406V38.4829H59.7736C60.8878%2037.5466%2061.824%2036.4206%2062.5589%2035.1406H33.427Z'%20fill='white'/%3e%3cpath%20d='M62.5589%2022.3762H26.7781V25.7185H63.8862C63.5781%2024.5333%2063.1277%2023.4074%2062.5589%2022.3762Z'%20fill='white'/%3e%3cpath%20d='M51.5603%2016H26.7781V19.3422H60.1055C57.8773%2017.28%2054.8552%2016%2051.5603%2016Z'%20fill='white'/%3e%3cpath%20d='M43.3944%2028.7527H33.427V32.0949H43.3944V28.7527Z'%20fill='white'/%3e%3cpath%20d='M53.3735%2032.0949H63.8031C64.0994%2031.0283%2064.2535%2029.9023%2064.2535%2028.7527H53.3735V32.0949Z'%20fill='white'/%3e%3cpath%20d='M33.427%2047.8933H43.3944V51.2356H33.427V47.8933Z'%20fill='white'/%3e%3cpath%20d='M53.3735%2047.8933V51.2356H64.2535C64.2535%2050.0859%2064.0994%2048.96%2063.8031%2047.8933H53.3735Z'%20fill='white'/%3e%3cpath%20d='M26.7781%2063.9644L51.5603%2064C54.8789%2064%2057.8773%2062.72%2060.1173%2060.6577H26.7781V63.9644Z'%20fill='white'/%3e%3cpath%20d='M66.6714%2060.6577H83.2876V63.9881H66.6714V60.6577Z'%20fill='white'/%3e%3cpath%20d='M66.6714%2054.2698H83.2876V57.6119H66.6714V54.2698Z'%20fill='white'/%3e%3cpath%20d='M73.3083%2047.8933H83.2876V51.2356H73.3083V47.8933Z'%20fill='white'/%3e%3cpath%20d='M73.3083%2041.5171H83.2876V44.8593H73.3083V41.5171Z'%20fill='white'/%3e%3cpath%20d='M87.9099%2022.3762H66.6714V25.7185H89.0594L87.9099%2022.3762Z'%20fill='white'/%3e%3cpath%20d='M85.7053%2016H66.6714V19.3422H86.855L85.7053%2016Z'%20fill='white'/%3e%3cpath%20d='M103.222%2060.6577H119.851V63.9881H103.222V60.6577Z'%20fill='white'/%3e%3cpath%20d='M103.222%2054.2698H119.851V57.6119H103.222V54.2698Z'%20fill='white'/%3e%3cpath%20d='M103.222%2047.8933H113.202V51.2356H103.222V47.8933Z'%20fill='white'/%3e%3cpath%20d='M103.222%2041.5171H113.202V44.8593H103.222V41.5171Z'%20fill='white'/%3e%3cpath%20d='M103.222%2038.4829H113.202V35.1406H103.222H94.1914L93.2551%2037.8429L92.3187%2035.1406H83.2876H73.3083V38.4829H83.2876V35.4132L84.3425%2038.4829H102.168L103.222%2035.4132V38.4829Z'%20fill='white'/%3e%3cpath%20d='M113.202%2028.7527H96.3957L95.2461%2032.0949H113.202V28.7527Z'%20fill='white'/%3e%3cpath%20d='M100.816%2016L99.6667%2019.3422H119.85V16H100.816Z'%20fill='white'/%3e%3cpath%20d='M93.2551%2063.9644L94.4047%2060.6577H92.1055L93.2551%2063.9644Z'%20fill='white'/%3e%3cpath%20d='M91.0505%2057.6119H95.4594L96.6446%2054.2698H89.8772L91.0505%2057.6119Z'%20fill='white'/%3e%3cpath%20d='M88.8106%2051.2356H97.6995L98.8728%2047.8933H87.6372L88.8106%2051.2356Z'%20fill='white'/%3e%3cpath%20d='M86.5825%2044.8593H99.9395L101.077%2041.5171H85.4329L86.5825%2044.8593Z'%20fill='white'/%3e%3cpath%20d='M73.3083%2032.0949H91.2639L90.1143%2028.7527H73.3083V32.0949Z'%20fill='white'/%3e%3cpath%20d='M97.4624%2025.7185H119.851V22.3762H98.6002L97.4624%2025.7185Z'%20fill='white'/%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_101_2384'%3e%3crect%20width='119.656'%20height='80'%20fill='white'%20transform='translate(0.194336)'/%3e%3c/clipPath%3e%3cclipPath%20id='clip1_101_2384'%3e%3crect%20width='119.656'%20height='48'%20fill='white'%20transform='translate(0.194336%2016)'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
'%3e%3cpath%20fill-rule='evenodd'%20clip-rule='evenodd'%20d='M4.47436%2013.501L36.5661%2011.1323C40.5069%2010.7935%2041.5209%2011.0204%2043.9978%2012.8239L54.2419%2020.0404C54.3293%2020.1046%2054.4137%2020.1664%2054.4952%2020.226L54.4972%2020.2275C55.9894%2021.3194%2056.4956%2021.6898%2056.4956%2022.9721V62.5524C56.4956%2065.033%2055.594%2066.5%2052.4419%2066.7244L15.1741%2068.9801C12.8079%2069.0932%2011.6818%2068.7552%2010.4426%2067.1755L2.89876%2057.3652C1.54698%2055.5595%200.984863%2054.2085%200.984863%2052.6278V17.4462C0.984863%2015.4177%201.88666%2013.7256%204.47436%2013.501ZM10.5567%2021.1686C12.2846%2022.5756%2012.976%2022.5288%2016.0187%2022.3228L16.4115%2022.2964L48.2741%2020.3787C48.9499%2020.3787%2048.3879%2019.703%2048.1626%2019.5907L42.8709%2015.7564C41.8569%2014.9675%2040.5061%2014.0639%2037.917%2014.2899L7.06444%2016.5454C5.93929%2016.6572%205.71451%2017.2211%206.16267%2017.6731L10.5567%2021.1686ZM12.4702%2062.2136V28.6113C12.4702%2027.1457%2012.9206%2026.4686%2014.271%2026.3549L50.8641%2024.2131C52.1052%2024.1004%2052.6673%2024.8903%2052.6673%2026.3549V59.7316C52.6673%2061.1986%2052.4415%2062.4408%2050.414%2062.5525L15.3971%2064.5833C13.3706%2064.695%2012.4702%2064.0195%2012.4702%2062.2136Z'%20fill='white'/%3e%3cpath%20d='M47.0379%2030.4136C47.2624%2031.4295%2047.0379%2032.4444%2046.0226%2032.5586L44.3353%2032.8955V57.7029C42.8705%2058.492%2041.5196%2058.9432%2040.394%2058.9432C38.5918%2058.9432%2038.1404%2058.3789%2036.7905%2056.6884L25.7544%2039.3231V56.1246L29.2466%2056.9144C29.2466%2056.9144%2029.2466%2058.9432%2026.4291%2058.9432L18.6618%2059.3948C18.4362%2058.9432%2018.6618%2057.8165%2019.4497%2057.5907L21.4766%2057.0277V34.8132L18.6623%2034.5871C18.4366%2033.5713%2018.9987%2032.1066%2020.5762%2031.9929L28.9088%2031.4299L40.394%2049.0212V33.4594L37.4657%2033.1225C37.2409%2031.8806%2038.1404%2030.9788%2039.2665%2030.867L47.0379%2030.4136Z'%20fill='white'/%3e%3cpath%20d='M76.9489%2052.086V36.7917H77.2137L88.2405%2052.086H91.7137V29.6118H87.8512V44.8905H87.5864L76.5595%2029.6118H73.0708V52.086H76.9489Z'%20fill='white'/%3e%3cpath%20d='M102.625%2052.4287C107.718%2052.4287%20110.818%2049.0957%20110.818%2043.5667C110.818%2038.0533%20107.703%2034.7047%20102.625%2034.7047C97.5635%2034.7047%2094.433%2038.0689%2094.433%2043.5667C94.433%2049.0957%2097.5168%2052.4287%20102.625%2052.4287ZM102.625%2049.1892C99.9309%2049.1892%2098.389%2047.1333%2098.389%2043.5667C98.389%2040.0157%2099.9309%2037.9443%20102.625%2037.9443C105.304%2037.9443%20106.846%2040.0157%20106.846%2043.5667C106.846%2047.1333%20105.32%2049.1892%20102.625%2049.1892Z'%20fill='white'/%3e%3cpath%20d='M114.347%2030.8734V35.1564H111.652V38.2402H114.347V47.5382C114.347%2050.8401%20115.904%2052.1639%20119.813%2052.1639C120.561%2052.1639%20121.277%2052.086%20121.838%2051.977V48.9555C121.371%2049.0023%20121.075%2049.0334%20120.53%2049.0334C118.91%2049.0334%20118.194%2048.2858%20118.194%2046.6038V38.2402H121.838V35.1564H118.194V30.8734H114.347Z'%20fill='white'/%3e%3cpath%20d='M124.153%2052.086H128V35.0474H124.153V52.086ZM126.068%2032.2284C127.345%2032.2284%20128.373%2031.2004%20128.373%2029.9077C128.373%2028.615%20127.345%2027.5715%20126.068%2027.5715C124.807%2027.5715%20123.763%2028.615%20123.763%2029.9077C123.763%2031.2004%20124.807%2032.2284%20126.068%2032.2284Z'%20fill='white'/%3e%3cpath%20d='M138.553%2052.4287C143.646%2052.4287%20146.745%2049.0957%20146.745%2043.5667C146.745%2038.0533%20143.63%2034.7047%20138.553%2034.7047C133.491%2034.7047%20130.361%2038.0689%20130.361%2043.5667C130.361%2049.0957%20133.444%2052.4287%20138.553%2052.4287ZM138.553%2049.1892C135.858%2049.1892%20134.317%2047.1333%20134.317%2043.5667C134.317%2040.0157%20135.858%2037.9443%20138.553%2037.9443C141.232%2037.9443%20142.774%2040.0157%20142.774%2043.5667C142.774%2047.1333%20141.247%2049.1892%20138.553%2049.1892Z'%20fill='white'/%3e%3cpath%20d='M149.044%2052.086H152.907V42.165C152.907%2039.6575%20154.355%2038.0689%20156.66%2038.0689C159.012%2038.0689%20160.102%2039.3771%20160.102%2041.9781V52.086H163.965V41.0592C163.965%2036.9942%20161.893%2034.7047%20158.093%2034.7047C155.554%2034.7047%20153.841%2035.8728%20153.031%2037.7729H152.766V35.0474H149.044V52.086Z'%20fill='white'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_103_2725'%3e%3crect%20width='162.98'%20height='80'%20fill='white'%20transform='translate(0.984863)'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
'%3e%3cpath%20d='M4.90497%2033C5.70516%2033%206.86321%2033.1594%208.37798%2033.4785V35.9733C7.25094%2035.4861%206.20474%2035.243%205.2381%2035.243C3.877%2035.243%203.19645%2035.6475%203.19645%2036.4581C3.19645%2036.7611%203.33363%2037.0082%203.6081%2037.1998C3.83635%2037.3549%204.46544%2037.6823%205.49387%2038.1833C6.97461%2038.8949%207.96041%2039.5136%208.45163%2040.0397C9.03449%2040.6639%209.32638%2041.4714%209.32638%2042.4612C9.32638%2043.8841%208.75456%2044.9695%207.61148%2045.7173C6.6855%2046.3236%205.48469%2046.6257%204.00977%2046.6257C2.76436%2046.6257%201.50943%2046.4671%200.245899%2046.1479V43.5545C1.61002%2044.019%202.81709%2044.2514%203.86713%2044.2514C5.31697%2044.2514%206.04189%2043.8368%206.04189%2043.008C6.04189%2042.699%205.93642%2042.4395%205.7249%2042.2292C5.50862%2042.0061%204.9548%2041.697%204.06459%2041.301C2.46758%2040.5905%201.42614%2039.9844%200.94178%2039.4833C0.313849%2038.8215%200%2037.9872%200%2036.9789C0%2035.6806%200.457416%2034.6909%201.37155%2034.0109C2.27558%2033.3367%203.45281%2033%204.90497%2033ZM75.266%2033C76.0824%2033%2077.1405%2033.1403%2078.4382%2033.4222L78.738%2033.4785V35.9733C77.6107%2035.4861%2076.5614%2035.243%2075.5897%2035.243C74.2336%2035.243%2073.5574%2035.6475%2073.5574%2036.4581C73.5574%2036.7611%2073.6939%2037.0082%2073.9675%2037.1998C74.1852%2037.349%2074.8167%2037.6765%2075.8624%2038.1833C77.3321%2038.8949%2078.3158%2039.5136%2078.8112%2040.0397C79.395%2040.6639%2079.6863%2041.4714%2079.6863%2042.4612C79.6863%2043.8841%2079.1176%2044.9695%2077.9803%2045.7173C77.0489%2046.3236%2075.8451%2046.6257%2074.3705%2046.6257C73.1237%2046.6257%2071.8683%2046.4671%2070.6058%2046.1479V43.5545C71.9584%2044.019%2073.1653%2044.2514%2074.2277%2044.2514C75.6774%2044.2514%2076.4017%2043.8368%2076.4017%2043.008C76.4017%2042.699%2076.299%2042.4395%2076.0944%2042.2292C75.8771%2042.0061%2075.321%2041.697%2074.4254%2041.301C72.8332%2040.5964%2071.7907%2039.9906%2071.3017%2039.4833C70.6742%2038.8274%2070.3609%2037.99%2070.3609%2036.97C70.3609%2035.6773%2070.8171%2034.6909%2071.7323%2034.0109C72.635%2033.3367%2073.8135%2033%2075.266%2033ZM33.1815%2033.2282L36.235%2041.6191L39.365%2033.2282H43.5397V46.3603H40.3256V37.0625L36.7666%2046.4937H34.6653L31.1747%2037.0625V46.3603H28.7864V33.2282H33.1815ZM14.6306%2033.2282V46.3603H11.2407V33.2282H14.6306ZM26.4336%2033.2282V35.6035H21.0065V38.5688H25.7305V40.7353H21.0065V43.8517H26.5734V46.3603H17.7394V33.2282H26.4336ZM55.3432%2033.2282V35.6035H49.9166V38.5688H54.6405V40.7353H49.9166V43.8517H55.484V46.3603H46.6492V33.2282H55.3432ZM61.6433%2033.2282L65.8115%2042.0192V33.2282H68.1993V46.3603H64.382L60.1031%2037.4511V46.3603H57.7145V33.2282H61.6433Z'%20fill='white'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_112_1124'%3e%3crect%20width='80'%20height='14'%20fill='white'%20transform='translate(0%2033)'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
'%3e%3cg%20clip-path='url(%23clip1_98_1160)'%3e%3cpath%20d='M29.887%2037.1442C30.1599%2037.1442%2030.2964%2037.3489%2030.2282%2037.6218L23.4738%2053.9278C23.3373%2054.2007%2023.0644%2054.4054%2022.7915%2054.4054H15.0137H13.3081C13.0352%2054.4054%2012.6941%2054.2007%2012.6258%2053.9278L1.02739%2025.8186C0.890934%2025.5457%201.02739%2025.3411%201.36852%2025.3411H9.1463C9.4192%2025.3411%209.76033%2025.5457%209.82856%2025.8186L18.0839%2045.8089L21.4952%2037.6218C21.6317%2037.3489%2021.9046%2037.1442%2022.1775%2037.1442H29.887ZM34.7993%2025.3411H27.0215C26.7486%2025.3411%2026.4075%2025.5457%2026.3393%2025.8186L23.9514%2031.6861C23.8831%2031.8908%2023.9514%2032.0955%2024.2243%2032.0955H32.1385C32.3432%2032.0955%2032.6161%2031.8908%2032.7525%2031.6861L35.1404%2025.8186C35.2087%2025.5457%2035.0722%2025.3411%2034.7993%2025.3411Z'%20fill='white'/%3e%3cpath%20d='M65.5694%2047.6511C65.3647%2047.6511%2065.1601%2047.4465%2065.1601%2047.2418V43.2847C65.1601%2043.08%2065.3647%2042.8753%2065.5694%2042.8753H77.7137C77.9183%2042.8753%2078.123%2042.6706%2078.123%2042.466V37.6219C78.123%2037.4172%2077.9183%2037.2125%2077.7137%2037.2125H65.5694C65.3647%2037.2125%2065.1601%2037.0079%2065.1601%2036.8032V32.5049C65.1601%2032.3003%2065.3647%2032.0956%2065.5694%2032.0956H79.5558C79.7605%2032.0956%2079.9651%2031.8909%2079.9651%2031.6862V25.8188C79.9651%2025.6141%2079.7605%2025.4094%2079.5558%2025.4094H57.5187C57.3141%2025.4094%2057.1094%2025.6141%2057.1094%2025.8188V53.9962C57.1094%2054.2009%2057.3141%2054.4055%2057.5187%2054.4055H80.8521C81.0567%2054.4055%2081.2614%2054.2009%2081.2614%2053.9962V48.1287C81.2614%2047.924%2081.0567%2047.7194%2080.8521%2047.7194H65.5694V47.6511Z'%20fill='white'/%3e%3cpath%20d='M40.6667%2025.6823V53.9279C40.6667%2054.1326%2040.8714%2054.3373%2041.0761%2054.3373H48.3081C48.5128%2054.3373%2048.7174%2054.1326%2048.7174%2053.9279V25.6823C48.7174%2025.4776%2048.5128%2025.2729%2048.3081%2025.2729H41.0761C40.8714%2025.3412%2040.6667%2025.4776%2040.6667%2025.6823Z'%20fill='white'/%3e%3cpath%20d='M116.739%2053.9278C116.875%2054.0643%20116.739%2054.3372%20116.534%2054.3372H109.029C108.688%2054.3372%20108.483%2054.2007%20108.279%2053.9278L101.866%2045.8089C101.729%2045.6042%20101.388%2045.4678%20101.183%2045.4678H97.0897C96.885%2045.4678%2096.6803%2045.6724%2096.6803%2045.8771V53.8596C96.6803%2054.0643%2096.4756%2054.2689%2096.271%2054.2689H89.039C88.8343%2054.2689%2088.6296%2054.0643%2088.6296%2053.8596V25.7504C88.6296%2025.5457%2088.8343%2025.3411%2089.039%2025.3411C89.039%2025.3411%20101.047%2025.3411%20105.004%2025.3411C110.462%2025.5457%20115.306%2029.9804%20115.238%2035.575C115.238%2039.6686%20113.327%2043.1481%20110.121%2044.6491C110.053%2044.7173%20109.78%2044.8537%20109.78%2044.8537M107.46%2035.7797C107.46%2033.2553%20106.096%2032.0272%20103.571%2032.0272H97.0897C96.885%2032.0272%2096.6803%2032.2319%2096.6803%2032.4366V38.9863C96.6803%2039.191%2096.885%2039.3956%2097.0897%2039.3956H103.571C106.096%2039.4639%20107.46%2038.3723%20107.46%2035.7797Z'%20fill='white'/%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_98_1160'%3e%3crect%20width='116.667'%20height='80'%20fill='white'%20transform='translate(0.754395)'/%3e%3c/clipPath%3e%3cclipPath%20id='clip1_98_1160'%3e%3crect%20width='116.667'%20height='30'%20fill='white'%20transform='translate(0.754395%2025)'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)


'%3e%3cmask%20id='mask0_113_1623'%20style='mask-type:luminance'%20maskUnits='userSpaceOnUse'%20x='0'%20y='26'%20width='80'%20height='28'%3e%3cpath%20d='M79.7573%2026H0V54H79.7573V26Z'%20fill='white'/%3e%3c/mask%3e%3cg%20mask='url(%23mask0_113_1623)'%3e%3cpath%20fill-rule='evenodd'%20clip-rule='evenodd'%20d='M76.8544%2038.2668L74.6246%2045.5094H74.5852L72.2758%2038.2668H69.4316V34.2363H66.6289V48.8439H69.4316V38.6953L72.868%2048.1895C72.9472%2048.3941%2072.9862%2048.6192%2072.9862%2048.8439C72.9862%2049.4992%2072.6311%2050.0919%2071.901%2050.1738C71.3486%2050.1944%2070.7963%2050.1328%2070.2632%2050.0715V52.4657C70.8356%2052.5267%2071.4075%2052.5678%2071.98%2052.5678C73.8939%2052.5678%2074.8808%2051.8719%2075.4926%2050.1738L79.7556%2038.2668H76.8544Z'%20fill='white'/%3e%3cpath%20fill-rule='evenodd'%20clip-rule='evenodd'%20d='M36.4302%2038.2668H34.4958V37.6322C34.4958%2036.7528%2034.792%2036.4252%2035.5619%2036.4252C35.8974%2036.4252%2036.2523%2036.4463%2036.5877%2036.4871V34.3182C36.1146%2034.298%2035.6009%2034.2363%2035.1083%2034.2363C32.8184%2034.2363%2031.6935%2035.5661%2031.6935%2037.4485V38.2668H30.0159V40.2099H31.6935V48.8439H34.4958V40.2099H36.4302V38.2668Z'%20fill='white'/%3e%3cpath%20fill-rule='evenodd'%20clip-rule='evenodd'%20d='M63.2132%2039.5561H63.1736C62.5426%2038.5126%2061.3581%2037.9805%2060.1544%2037.9805C57.3842%2037.9805%2055.8766%2040.2319%2055.6617%2042.8161C55.359%2040.1648%2053.6905%2037.9805%2050.7404%2037.9805C48.0196%2037.9805%2046.0596%2039.8433%2045.6228%2042.4452C45.2123%2039.9642%2043.5648%2037.9805%2040.7535%2037.9805C37.6547%2037.9805%2035.543%2040.3948%2035.543%2043.5657C35.543%2046.8395%2037.5363%2049.1308%2040.7535%2049.1308C43.0622%2049.1308%2044.74%2048.0879%2045.5292%2045.5711H43.0622C42.8846%2046.2252%2041.9773%2046.9413%2040.852%2046.9413C39.2735%2046.9413%2038.425%2046.1234%2038.346%2044.2616H45.5624C45.8271%2047.1597%2047.7575%2049.1308%2050.7404%2049.1308C53.0497%2049.1308%2054.7272%2048.0879%2055.5169%2045.5711H53.0497C52.872%2046.2252%2051.9643%2046.9413%2050.8398%2046.9413C49.2607%2046.9413%2048.4119%2046.1234%2048.3327%2044.2616H55.6727C55.9221%2046.8833%2057.4154%2049.1308%2060.2137%2049.1308C61.5357%2049.1308%2062.6608%2048.6401%2063.3117%2047.4941H63.3511V48.8443H66.016V34.2363H63.2132V39.5561ZM38.346%2042.4205C38.4052%2041.6022%2038.8588%2040.1697%2040.6744%2040.1697C42.0362%2040.1697%2042.648%2040.9468%2042.9047%2042.4205H38.346ZM48.3327%2042.4205C48.3921%2041.6022%2048.8464%2040.1697%2050.6612%2040.1697C52.0231%2040.1697%2052.6352%2040.9468%2052.8915%2042.4205H48.3327ZM60.9043%2046.9413C59.1673%2046.9413%2058.4376%2045.2031%2058.4376%2043.5456C58.4376%2041.827%2059.0691%2040.1697%2060.9043%2040.1697C62.7198%2040.1697%2063.3117%2041.8066%2063.3117%2043.5249C63.3117%2045.2638%2062.7401%2046.9413%2060.9043%2046.9413Z'%20fill='white'/%3e%3cpath%20d='M11.6674%2030.2853C12.6766%2029.2389%2014.3281%2029.2389%2015.3373%2030.2853L24.5639%2039.8497C25.5733%2040.8961%2025.5733%2042.6091%2024.5639%2043.6554L18.1108%2050.3448C17.6388%2050.834%2016.9864%2051.1368%2016.266%2051.1368H10.7377C10.0825%2051.1367%209.48388%2050.8862%209.02581%2050.4728L2.44475%2043.6505C1.43541%2042.604%201.4354%2040.8913%202.44475%2039.8448L11.6674%2030.2853ZM13.7641%2045.839C13.6203%2045.6899%2013.3847%2045.69%2013.2406%2045.839L11.9242%2047.2032C11.7807%2047.3522%2011.7808%2047.5961%2011.9242%2047.7452L12.8637%2048.7189C12.9293%2048.7778%2013.0142%2048.8136%2013.1078%2048.8136H13.8969C13.9993%2048.8135%2014.0923%2048.771%2014.1596%2048.7013L15.0805%2047.7462C15.2244%2047.5969%2015.2246%2047.3525%2015.0805%2047.2032L13.7641%2045.839ZM13.7641%2040.1173C13.6201%2039.9678%2013.3847%2039.9678%2013.2406%2040.1173L9.16448%2044.3419C9.02063%2044.4911%209.02058%2044.7356%209.16448%2044.8849L10.1039%2045.8575C10.1691%2045.9166%2010.2548%2045.9532%2010.3481%2045.9532H11.1371C11.2396%2045.953%2011.3327%2045.9097%2011.3998%2045.8399L15.0805%2042.0245C15.2245%2041.8753%2015.2245%2041.6308%2015.0805%2041.4815L13.7641%2040.1173ZM13.7641%2034.3946C13.6201%2034.2455%2013.3847%2034.2456%2013.2406%2034.3946L6.40471%2041.4806C6.26081%2041.6299%206.26085%2041.8744%206.40471%2042.0235L7.34416%2042.9972C7.40941%2043.0561%207.49498%2043.0919%207.58831%2043.0919H8.37737C8.47976%2043.0918%208.5729%2043.0483%208.64006%2042.9786L15.0805%2036.3019C15.2244%2036.1526%2015.2246%2035.9081%2015.0805%2035.7589L13.7641%2034.3946Z'%20fill='white'/%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_113_1623'%3e%3crect%20width='80'%20height='28'%20fill='white'%20transform='translate(0%2026)'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)

'%3e%3cg%20clip-path='url(%23clip1_101_2238)'%3e%3cpath%20d='M32.9211%2027.3C35.4211%2027.1333%2040.4211%2027%2047.6877%2027V31.7333H26.2544V24.9667C33.6211%2022.6%2038.6211%2021.1333%2041.0211%2020.6333V20.4667C38.5877%2020.6%2033.5544%2020.7333%2026.2544%2020.7333V16H47.7211V22.7667C40.4544%2025.1333%2035.3877%2026.6%2032.9544%2027.1333V27.3H32.9211Z'%20fill='white'/%3e%3cpath%20d='M26.2544%2035.1001H47.7211V46.0334H44.2877V40.4668H39.1877V46.0668H35.7544V40.4668H26.2544V35.1001Z'%20fill='white'/%3e%3cpath%20d='M37.5877%2058.6668C37.0877%2062.0668%2035.4544%2063.7001%2032.2211%2063.7001C27.8877%2063.7001%2026.2544%2060.4668%2026.2544%2055.6668V48.6001H47.7211V54.8334C47.7211%2059.6668%2046.6211%2062.9001%2042.4544%2062.9001C39.3877%2062.9001%2037.9544%2061.0334%2037.7211%2058.6668H37.5877ZM39.1544%2053.9668V55.4668C39.1544%2056.9334%2039.9877%2057.7001%2041.7877%2057.7001C43.5544%2057.7001%2044.2544%2056.8334%2044.2544%2055.4334V53.9668H39.1544ZM29.7211%2053.9668V55.4334C29.7211%2057.3001%2030.5211%2058.2334%2032.5544%2058.2334C34.4544%2058.2334%2035.7211%2057.3668%2035.7211%2055.5001V54.0001H29.7211V53.9668Z'%20fill='white'/%3e%3cpath%20d='M11.1877%2063.9999C3.48765%2063.9999%200.0876465%2061.2332%200.0876465%2055.9999C0.0876465%2050.7999%203.52098%2048.0332%2011.221%2048.0332C18.9543%2048.0332%2022.3877%2050.7999%2022.3877%2055.9999C22.3877%2061.2332%2018.9543%2063.9999%2011.1877%2063.9999ZM3.52098%2056.0665C3.52098%2057.4332%205.15432%2058.5332%2011.2543%2058.5332C17.2877%2058.5332%2018.921%2057.4332%2018.921%2056.0332C18.921%2054.6332%2017.2877%2053.5332%2011.2543%2053.5332C5.15432%2053.5332%203.52098%2054.6332%203.52098%2056.0665Z'%20fill='white'/%3e%3cpath%20d='M15.2877%2034.6001C12.7877%2034.7667%207.78766%2034.9001%200.520996%2034.9001V30.1667H21.9877V36.9334C14.621%2039.3001%209.62099%2040.7668%207.22099%2041.2668V41.4334C9.65433%2041.3001%2014.6877%2041.1667%2021.9877%2041.1667V45.9001H0.520996V39.1334C7.78766%2036.7667%2012.8543%2035.3001%2015.2877%2034.7667V34.6001Z'%20fill='white'/%3e%3cpath%20d='M21.9543%2026.9333H0.520996V16H3.95433V21.6H9.05433V16H12.4877V21.6H21.9543V26.9333Z'%20fill='white'/%3e%3cpath%20d='M85.7209%2043.7999C90.6876%2043.1333%2095.4876%2040.7333%2099.2209%2036.5666V36.4999C95.5209%2032.3333%2090.7209%2029.9333%2085.7543%2029.2666C88.6543%2030.3999%2090.6876%2033.2333%2090.6876%2036.5333C90.6876%2039.8333%2088.6209%2042.6666%2085.7209%2043.7999Z'%20fill='white'/%3e%3cpath%20d='M80.0543%2029.2666C75.0543%2029.9333%2070.2543%2032.3333%2066.521%2036.5333C70.2543%2040.7333%2075.0543%2043.1333%2080.0543%2043.7999C77.121%2042.6666%2075.0877%2039.8333%2075.0877%2036.5333C75.0877%2033.2333%2077.121%2030.3999%2080.0543%2029.2666Z'%20fill='white'/%3e%3cpath%20d='M92.8209%2050.4666L92.2876%2050.6666V51.2332C92.2876%2051.2332%2092.2876%2057.0666%2092.2876%2063.2332H99.1876V47.3999C97.2209%2048.6332%2095.0876%2049.6666%2092.8209%2050.4666Z'%20fill='white'/%3e%3cpath%20d='M73.4542%2050.6667L72.9209%2050.5C65.9209%2048.1%2060.1209%2043.2667%2056.1542%2036.5667C61.8209%2027%2071.4209%2021.2667%2082.0542%2021H83.6542C89.2876%2021.1667%2094.5876%2022.8333%2099.1876%2025.7667V16H51.9875V63.2H73.4542C73.4542%2056.8333%2073.4542%2050.6667%2073.4542%2050.6667Z'%20fill='white'/%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_101_2238'%3e%3crect%20width='98.6667'%20height='80'%20fill='white'%20transform='translate(0.0876465)'/%3e%3c/clipPath%3e%3cclipPath%20id='clip1_101_2238'%3e%3crect%20width='98.6667'%20height='48'%20fill='white'%20transform='translate(0.0876465%2016)'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)

'%3e%3cpath%20fill-rule='evenodd'%20clip-rule='evenodd'%20d='M36.4402%2056.8893C37.0969%2056.8893%2037.7766%2056.8015%2038.4849%2056.6278C39.1932%2056.456%2039.9015%2056.2288%2040.6098%2055.9519C41.3181%2055.6732%2041.9844%2055.3353%2042.6049%2054.9363C43.2292%2054.5353%2043.781%2054.1115%2044.2659%2053.6609V46.9998H39.2887C36.7685%2046.9998%2034.9281%2047.4332%2033.7711%2048.3C32.6142%2049.1686%2032.0338%2050.5394%2032.0338%2052.4123C32.0338%2055.3945%2033.5019%2056.8893%2036.4402%2056.8893ZM27.4556%2052.6204C27.4556%2049.7414%2028.4159%2047.5458%2030.3442%2046.0376C32.2686%2044.5293%2035.0713%2043.7733%2038.7464%2043.7733H44.264V41.9519C44.264%2037.5456%2042.3204%2035.3443%2038.4353%2035.3443C37.1886%2035.3443%2035.877%2035.5161%2034.5081%2035.8636C33.1354%2036.211%2031.8791%2036.6444%2030.7336%2037.1637L29.3285%2033.7826C30.7508%2032.9845%2032.2877%2032.3698%2033.9353%2031.9345C35.581%2031.5011%2037.1886%2031.2834%2038.7464%2031.2834C45.4782%2031.2834%2048.8422%2034.8727%2048.8422%2042.055V60.2686H45.3064L44.7336%2057.1471C43.3113%2058.2926%2041.7935%2059.1765%2040.1802%2059.8008C38.567%2060.4271%2037.032%2060.7363%2035.5715%2060.7363C33.0418%2060.7363%2031.0563%2060.0185%2029.6148%2058.579C28.1753%2057.1394%2027.4556%2055.1539%2027.4556%2052.6223'%20fill='white'/%3e%3cpath%20fill-rule='evenodd'%20clip-rule='evenodd'%20d='M74.9499%2031.0778L78.6977%2033.7812L69.4897%2045.3355L80.1544%2058.1366L76.462%2061.0004L63.8691%2045.5933L74.9499%2031.0778ZM62.1508%2060.2691H57.3645V20.0427L62.1508%2019.0042V60.2691Z'%20fill='white'/%3e%3cpath%20fill-rule='evenodd'%20clip-rule='evenodd'%20d='M93.3806%2056.8893C94.0354%2056.8893%2094.7189%2056.8015%2095.4272%2056.6278C96.1355%2056.456%2096.8438%2056.2288%2097.5521%2055.9519C98.2585%2055.6732%2098.9229%2055.3353%2099.5472%2054.9363C100.166%2054.5353%20100.719%2054.1115%20101.204%2053.6609V46.9998H96.2291C93.7052%2046.9998%2091.8666%2047.4332%2090.7116%2048.3C89.5527%2049.1686%2088.9761%2050.5394%2088.9761%2052.4123C88.9761%2055.3945%2090.4424%2056.8893%2093.3806%2056.8893ZM84.396%2052.6204C84.396%2049.7414%2085.3582%2047.5458%2087.2827%2046.0376C89.2109%2044.5293%2092.0079%2043.7733%2095.6888%2043.7733H101.204V41.9519C101.204%2037.5456%2099.2628%2035.3443%2095.3757%2035.3443C94.1252%2035.3443%2092.8174%2035.5161%2091.4466%2035.8636C90.0739%2036.211%2088.8177%2036.6444%2087.676%2037.1637L86.2689%2033.7826C87.6931%2032.9845%2089.2281%2032.3698%2090.8738%2031.9345C92.5196%2031.5011%2094.1252%2031.2834%2095.6888%2031.2834C102.417%2031.2834%20105.785%2034.8727%20105.785%2042.055V60.2686H102.243L101.67%2057.1471C100.248%2058.2926%2098.7339%2059.1765%2097.1169%2059.8008C95.5055%2060.4271%2093.9705%2060.7363%2092.5138%2060.7363C89.9803%2060.7363%2087.9929%2060.0185%2086.5553%2058.579C85.1138%2057.1394%2084.396%2055.1539%2084.396%2052.6223'%20fill='white'/%3e%3cpath%20fill-rule='evenodd'%20clip-rule='evenodd'%20d='M125.045%2035.1836C122.548%2035.1836%20120.631%2036.121%20119.297%2037.9939C117.958%2039.8687%20117.292%2042.6084%20117.292%2046.2167C117.292%2049.7907%20117.958%2052.4884%20119.297%2054.3097C120.631%2056.1311%20122.548%2057.0418%20125.045%2057.0418C127.577%2057.0418%20129.513%2056.1311%20130.849%2054.3097C132.186%2052.4884%20132.852%2049.7907%20132.852%2046.2167C132.852%2042.6084%20132.184%2039.8687%20130.849%2037.9939C129.513%2036.121%20127.577%2035.1836%20125.045%2035.1836ZM125.045%2031.3328C128.999%2031.3328%20132.107%2032.6176%20134.358%2035.1836C136.615%2037.7533%20137.743%2041.4304%20137.743%2046.2186C137.743%2050.9343%20136.626%2054.5617%20134.387%2057.0952C132.149%2059.6249%20129.034%2060.8926%20125.045%2060.8926C121.093%2060.8926%20117.985%2059.6249%20115.732%2057.0933C113.476%2054.5636%20112.347%2050.9362%20112.347%2046.2167C112.347%2041.4304%20113.481%2037.7533%20115.755%2035.1836C118.029%2032.6176%20121.126%2031.3328%20125.045%2031.3328Z'%20fill='white'/%3e%3cpath%20fill-rule='evenodd'%20clip-rule='evenodd'%20d='M5.20936%2019.0017L0.421143%2020.0422V60.2686H5.20936V18.9998V19.0017ZM6.92762%2045.5946L19.5186%2060.9998L23.2167%2058.136L12.5463%2045.335L21.7581%2033.7825L18.0123%2031.0753L6.92762%2045.5946Z'%20fill='white'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_98_2083'%3e%3crect%20width='137.322'%20height='80'%20fill='white'%20transform='translate(0.421143)'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)

'%3e%3cpath%20fill-rule='evenodd'%20clip-rule='evenodd'%20d='M42.5198%2049.7583C37.2743%2056.7013%2031.6578%2064.1353%2026.702%2080C21.7494%2064.1456%2016.137%2056.7109%2010.8987%2049.7718C7.98004%2045.9056%205.17754%2042.1932%202.67002%2037.264C-6.01798%2020.24%208.15802%200%2026.702%200C45.246%200%2059.438%2020.24%2050.75%2037.264C48.2397%2042.1874%2045.4371%2045.8969%2042.5198%2049.7583ZM41.07%2028.1121L37.966%2025.7281C39.07%2023.8081%2039.71%2021.6001%2039.71%2019.2161C39.71%2012.0321%2033.886%206.20809%2026.702%206.20809C19.518%206.20809%2013.694%2012.0321%2013.694%2019.2161C13.694%2026.4001%2019.518%2032.2241%2026.702%2032.2241C29.998%2032.2241%2032.99%2031.0081%2035.278%2028.9921L38.446%2031.4241L41.07%2028.1121ZM26.702%2027.2481C22.27%2027.2481%2018.686%2023.6641%2018.686%2019.2321C18.686%2014.8001%2022.27%2011.2161%2026.702%2011.2161C31.134%2011.2161%2034.718%2014.8001%2034.718%2019.2321C34.718%2020.4641%2034.446%2021.6161%2033.95%2022.6561L30.574%2020.0641L27.95%2023.3761L31.198%2025.8721C29.918%2026.7361%2028.366%2027.2481%2026.702%2027.2481ZM28.03%2039.616C28.03%2039.968%2028.046%2040.288%2028.046%2040.288H30.958C30.958%2040.288%2030.942%2040.176%2030.942%2039.904C30.942%2038.544%2031.694%2037.504%2033.23%2037.504C34.686%2037.504%2035.422%2038.432%2035.422%2039.488C35.422%2040.496%2034.942%2041.248%2033.71%2041.984L31.326%2043.408C28.734%2044.976%2027.934%2047.04%2027.918%2049.584H38.606V46.928H31.678C31.902%2046.368%2032.366%2045.968%2032.926%2045.616L35.71%2043.92C37.502%2042.832%2038.526%2041.312%2038.526%2039.44C38.526%2036.928%2036.542%2034.784%2033.31%2034.784C29.95%2034.784%2028.062%2037.024%2028.03%2039.616ZM17.4539%2044.304L21.0859%2038.88V44.304H17.4539ZM21.0699%2035.184L14.4459%2044.448V46.912H21.0859V49.568H24.0779V46.912H25.8859V44.288H24.0779V35.184H21.0699Z'%20fill='white'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_101_2471'%3e%3crect%20width='53.3186'%20height='80'%20fill='white'%20transform='translate(0.0498047)'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
'%3e%3cpath%20fill-rule='evenodd'%20clip-rule='evenodd'%20d='M0%2040V49.5H9.56967H19.1393V40V30.5H9.56967H0V40ZM35.6148%2035.5128V36.4021H37.3156H39.0164V40.8691V45.3362H40H40.9836V40.8691V36.4021H42.6844H44.3852V35.5128V34.6234H40H35.6148V35.5128ZM47.9098%2039.9798V45.3362H51.7008H55.4918V44.4468V43.5574H52.6639H49.8361V39.0904V34.6234H48.873H47.9098V39.9798ZM58.9754%2039.9798V45.3362H62.9918H67.0082V44.467V43.5979H63.8525H60.6967V42.2032V40.8085H63.1148H65.5328V39.9394V39.0702H63.1148H60.6967V37.716V36.3617H63.8525H67.0082V35.4926V34.6234H62.9918H58.9754V39.9798ZM70.8197%2039.9798V45.3362H71.7828H72.7459V43.4766V41.617L73.9242%2041.6192L75.1025%2041.6214L76.4164%2043.4687L77.7307%2045.316L78.8701%2045.3267C79.7852%2045.3354%2080.0053%2045.3272%2079.9889%2045.2854C79.9779%2045.2569%2079.3709%2044.4061%2078.6406%2043.3949C77.9098%2042.3837%2077.2701%2041.4972%2077.2189%2041.4248C77.1311%2041.3012%2077.1299%2041.2918%2077.2%2041.2683C77.4271%2041.1921%2077.9463%2040.9589%2078.1484%2040.8421C78.2762%2040.768%2078.5488%2040.5432%2078.7537%2040.3425C79.057%2040.0457%2079.1582%2039.9136%2079.2971%2039.635C79.5693%2039.0884%2079.6422%2038.7527%2079.6422%2038.0394C79.6422%2037.3307%2079.5689%2036.9878%2079.3053%2036.4628C78.7918%2035.4384%2077.7365%2034.8142%2076.2672%2034.6654C76.0283%2034.6412%2074.7844%2034.6234%2073.3357%2034.6234H70.8197V39.9798ZM12.7538%2039.9394C14.0321%2042.8298%2015.0875%2045.2174%2015.0992%2045.2452C15.1158%2045.2848%2014.9102%2045.2955%2014.1483%2045.2949L13.1762%2045.294L11.3767%2041.1007C10.3869%2038.7944%209.5648%2036.8933%209.54971%2036.876C9.53467%2036.8587%208.70471%2038.7461%207.70541%2041.0701L5.88844%2045.2957H4.95451H4.02057L4.07627%2045.1644C4.21902%2044.8276%208.65959%2034.798%208.69406%2034.7345C8.73008%2034.6681%208.80229%2034.6631%209.58148%2034.6731L10.4297%2034.684L12.7538%2039.9394ZM22.7049%2040V45.3362H23.6473H24.5898L24.6002%2041.5991L24.6107%2037.8621L27.541%2041.5987L30.4713%2045.3354L31.3012%2045.3358L32.1311%2045.3362V40V34.6638H31.1682H30.2054L30.1949%2038.3022L30.1844%2041.9407L27.3361%2038.3044L24.4877%2034.668L23.5963%2034.6659L22.7049%2034.6638V40ZM76.2295%2036.4594C76.8217%2036.5835%2077.3135%2036.9242%2077.5189%2037.3526C77.9291%2038.2077%2077.6094%2039.1886%2076.7795%2039.6234C76.2865%2039.8816%2076.2119%2039.8905%2074.3955%2039.9085L72.7459%2039.9248V38.1635V36.4021L74.3545%2036.4028C75.5648%2036.4033%2076.0291%2036.4174%2076.2295%2036.4594Z'%20fill='white'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_113_1912'%3e%3crect%20width='80'%20height='19'%20fill='white'%20transform='translate(0%2030.5)'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)


'%3e%3cpath%20d='M140.013%2019.6537H144.14V60.7591H140.425V61.2026H170.747V45.7611H170.536C169.804%2061.8905%20151.133%2060.7731%20151.133%2060.7731L151.24%2060.7927V40.0225C154.89%2040.0225%20159.842%2039.4975%20160.575%2048.928H160.704V30.794H160.575C159.635%2039.4975%20154.794%2039.5592%20151.24%2039.5592V19.7351C158.259%2019.7351%20165.924%2018.3566%20168.902%2033.3882H169.074V19.2354H140.013V19.6537Z'%20fill='white'/%3e%3cpath%20d='M140.872%2019.6481V19.2354H132.225V19.6481H136.049V50.3627C135.908%2058.0694%20130.313%2061.5929%20125.997%2061.4497C118.08%2061.169%20117.173%2053.67%20117.173%2052.1258V19.6481H120.961V19.2354H106.229V19.6481H110.135V48.3637C110.135%2056.062%20114.046%2062%20125.467%2062C133.126%2062%20136.641%2055.6381%20136.562%2050.3627V19.6481H140.872Z'%20fill='white'/%3e%3cpath%20d='M103.27%2043.939H106.482V43.5235H93.2867V43.939H96.6755V53.2404C96.6755%2057.5444%2094.8197%2061.475%2088.9406%2061.5901C84.7125%2061.649%2082.3906%2059.2542%2081.1525%2055.9385C79.8133%2052.3897%2079.3192%2048.6669%2079.3192%2040.2302C79.3192%2034.8172%2079.8133%2026.7876%2081.6691%2023.1827C82.545%2021.4982%2084.1453%2018.5082%2088.8368%2018.5278C94.7326%2018.5531%2098.1494%2023.3568%20100.676%2033.4219H100.803V18H100.668C99.4297%2020.9676%2094.7719%2019.5161%2094.7719%2019.5161C92.1918%2018.7019%2091.0575%2018.1123%2088.789%2018.1123C81.5062%2018.1207%2071.5085%2025.5102%2071.5085%2040.7524C71.5085%2053.2039%2078.9851%2062%2089.1961%2062C93.4243%2062%2096.0044%2058.9117%2099.6122%2058.9117C100.749%2058.9117%20102.827%2059.622%20103.189%2061.4385H103.276L103.27%2043.939Z'%20fill='white'/%3e%3cpath%20d='M59.947%2039.9944C59.947%2042.9648%2059.714%2052.4543%2057.2349%2057.171C55.6851%2060.2003%2053.0011%2061.4806%2049.8482%2061.4806C46.6953%2061.4806%2044.0141%2060.2003%2042.4644%2057.171C39.9853%2052.4543%2039.7523%2042.9648%2039.7523%2039.9944C39.7523%2037.024%2039.9853%2027.8236%2042.4644%2022.9329C43.9608%2019.9035%2046.6981%2018.6261%2049.8482%2018.6261C52.9983%2018.6261%2055.7441%2019.9035%2057.2349%2022.9329C59.714%2027.8236%2059.947%2037.024%2059.947%2039.9944ZM67.9261%2039.9944C67.9261%2026.8354%2058.473%2018.2162%2049.8482%2018.2162C41.2234%2018.2162%2031.7732%2026.8354%2031.7732%2039.9944C31.7732%2053.1534%2041.5351%2061.8933%2049.8482%2061.8933C58.1614%2061.8933%2067.9261%2053.159%2067.9261%2039.9944Z'%20fill='white'/%3e%3cpath%20d='M27.8846%2019.241V19.6424H31.7787L22.1937%2051.7187L10.6154%2019.6424H13.962V19.241H0V19.6424H3.83231L19.535%2061.4301H19.7568L32.2532%2019.6424H35.5942V19.241H27.8846Z'%20fill='white'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_13_1145'%3e%3crect%20width='170.747'%20height='80'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
'%3e%3cpath%20d='M75.7098%2040.248L79.823%2034.7231H76.9857L74.302%2038.4645L71.6167%2034.7231H68.7126L72.8274%2040.3132L68.5574%2046.0761H71.3963L74.2352%2042.0982L77.0959%2046.0761H80L75.7098%2040.2495V40.248Z'%20fill='white'/%3e%3cpath%20d='M68.6831%2040.4012C68.6831%2043.6664%2065.9637%2046.3249%2062.6219%2046.3249C59.28%2046.3249%2056.5591%2043.6664%2056.5591%2040.4012C56.5591%2037.1361%2059.2785%2034.4775%2062.6219%2034.4775C65.9652%2034.4775%2068.6831%2037.1345%2068.6831%2040.4012ZM66.3222%2040.3967C66.3222%2038.4039%2064.663%2036.7842%2062.625%2036.7842C60.587%2036.7842%2058.9277%2038.4039%2058.9277%2040.3967C58.9277%2042.3894%2060.587%2044.0076%2062.625%2044.0076C64.663%2044.0076%2066.3222%2042.3879%2066.3222%2040.3967Z'%20fill='white'/%3e%3cpath%20d='M47.5301%2034.7231H44.6694L49.4455%2046.0746H51.8436L56.5963%2034.7231H53.8009L50.6546%2042.9778L47.5301%2034.7231Z'%20fill='white'/%3e%3cpath%20d='M42.9946%2034.7231H40.3311V46.0746H42.9946V34.7231Z'%20fill='white'/%3e%3cpath%20d='M32.3049%2039.8963V46.0763H34.9685V39.8963C34.9685%2039.8296%2034.9716%2039.7234%2034.9886%2039.59C35.074%2038.9015%2035.5086%2037.5017%2037.6118%2037.3364C37.7437%2037.3258%2037.885%2037.3212%2038.034%2037.3212V34.7173C37.9424%2034.7173%2037.8539%2034.7173%2037.767%2034.7218C34.107%2034.8371%2032.3887%2037.3333%2032.308%2039.7189C32.3065%2039.778%2032.3049%2039.8357%2032.3049%2039.8948V39.8963Z'%20fill='white'/%3e%3cpath%20d='M30.5013%2040.6059C30.5013%2040.8425%2030.4796%2041.0578%2030.4579%2041.3156H21.9178C22.2267%2043.1643%2023.5476%2044.1971%2025.2643%2044.1971C26.5619%2044.1971%2027.487%2043.7239%2028.4106%2042.8428L29.9736%2044.1971C28.8731%2045.4862%2027.3551%2046.3263%2025.2209%2046.3263C21.8542%2046.3263%2019.2559%2043.9393%2019.2559%2040.4133C19.2559%2037.1451%2021.6105%2034.479%2024.9337%2034.479C28.631%2034.479%2030.5013%2037.318%2030.5013%2040.6059ZM27.8611%2039.5959C27.6842%2037.9186%2026.6721%2036.6082%2024.912%2036.6082C23.2822%2036.6082%2022.1382%2037.8336%2021.8961%2039.5959H27.8611Z'%20fill='white'/%3e%3cpath%20d='M16.1374%2034.7231L12.3501%2044.7006L12.3206%2044.7794C12.0071%2045.5802%2011.2652%2046.1731%2010.3696%2046.2945C10.2593%2046.3096%2010.146%2046.3172%2010.0296%2046.3172C9.91321%2046.3172%209.79214%2046.3081%209.67573%2046.2929C8.80341%2046.1701%208.0801%2045.5984%207.7588%2044.8264L7.69671%2044.6596L3.90941%2034.7231H7.04635L10.0296%2042.5577L13.0005%2034.7231L13.283%2033.9649C13.7657%2032.7319%2012.0692%2031%206.89113%2031C1.71308%2031%20-0.191431%2033.1308%200.0150081%2035.5633C0.221447%2037.9959%203.09917%2043.5829%204.56908%2045.7864C5.99553%2047.9248%207.94661%2049%209.94736%2049C11.9481%2049%2014.0746%2048.0173%2015.3024%2044.9538C16.2352%2042.6289%2019.3085%2034.7231%2019.3085%2034.7231H16.1328H16.1374Z'%20fill='white'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_112_801'%3e%3crect%20width='80'%20height='18'%20fill='white'%20transform='translate(0%2031)'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
'%3e%3cg%20clip-path='url(%23clip1_45_1332)'%3e%3cpath%20d='M25.4642%2056.8002L49.6642%2042.8002V37.0002L25.4642%2051.0002V56.8002ZM25.4642%2012.0002L1.26416%2026.0002V54.0002L25.4642%2068.0002L49.6642%2054.0002V48.2002L25.4642%2062.2002L6.26416%2051.0002V28.8002L25.4642%2017.6002L44.6642%2028.8002L25.4642%2040.0002V45.8002L49.6642%2031.8002V26.0002L25.4642%2012.0002Z'%20fill='white'/%3e%3cpath%20d='M73.2642%2040.8003C73.2642%2034.4003%2078.0642%2029.2003%2084.8642%2029.2003C89.0642%2029.2003%2091.4642%2030.6003%2093.6642%2032.6003L91.0642%2035.6003C89.2642%2034.0003%2087.2642%2032.8003%2084.8642%2032.8003C80.6642%2032.8003%2077.4642%2036.4003%2077.4642%2040.8003C77.4642%2045.2003%2080.6642%2048.8003%2084.8642%2048.8003C87.6642%2048.8003%2089.4642%2047.8003%2091.2642%2046.0003L93.8642%2048.6003C91.4642%2051.0003%2089.0642%2052.6003%2084.8642%2052.6003C78.2642%2052.4003%2073.2642%2047.2003%2073.2642%2040.8003Z'%20fill='white'/%3e%3cpath%20d='M96.2642%2040.8004C96.2642%2034.4004%20101.064%2029.2004%20108.064%2029.2004C115.064%2029.2004%20119.664%2034.4004%20119.664%2040.8004C119.664%2047.2004%20114.864%2052.4004%20107.864%2052.4004C100.864%2052.4004%2096.2642%2047.2004%2096.2642%2040.8004ZM115.664%2040.8004C115.664%2036.4004%20112.464%2032.8004%20108.064%2032.8004C103.664%2032.8004%20100.464%2036.4004%20100.464%2040.8004C100.464%2045.2004%20103.664%2048.8004%20108.064%2048.8004C112.464%2048.8004%20115.664%2045.2004%20115.664%2040.8004Z'%20fill='white'/%3e%3cpath%20d='M123.864%2029.6003H128.064L134.864%2040.2003L141.664%2029.6003H145.864V52.0003H141.864V36.0003L134.864%2046.6003H134.664L127.664%2036.0003V52.0003H123.864V29.6003Z'%20fill='white'/%3e%3cpath%20d='M151.665%2029.6003H160.465C165.665%2029.6003%20169.065%2032.6003%20169.065%2037.0003C169.065%2042.0003%20165.065%2044.6003%20160.065%2044.6003H155.665V52.0003H151.665V29.6003ZM160.065%2041.2003C163.065%2041.2003%20164.865%2039.6003%20164.865%2037.2003C164.865%2034.6003%20163.065%2033.2003%20160.065%2033.2003H155.465V41.2003H160.065Z'%20fill='white'/%3e%3cpath%20d='M171.464%2048.8004L173.864%2046.0004C176.064%2047.8004%20178.264%2049.0004%20180.864%2049.0004C183.264%2049.0004%20184.864%2047.8004%20184.864%2046.2004C184.864%2044.6004%20184.064%2043.8004%20179.864%2042.8004C175.064%2041.6004%20172.464%2040.2004%20172.464%2036.2004C172.464%2032.4004%20175.664%2029.8004%20180.064%2029.8004C183.264%2029.8004%20185.864%2030.8004%20188.264%2032.6004L186.064%2035.6004C184.064%2034.0004%20182.064%2033.2004%20180.064%2033.2004C177.664%2033.2004%20176.464%2034.4004%20176.464%2035.8004C176.464%2037.6004%20177.464%2038.2004%20181.864%2039.4004C186.664%2040.6004%20189.064%2042.2004%20189.064%2046.0004C189.064%2050.2004%20185.864%2052.6004%20181.064%2052.6004C177.464%2052.4004%20174.264%2051.2004%20171.464%2048.8004Z'%20fill='white'/%3e%3cpath%20d='M197.865%2033.2003H190.665V29.6003H208.865V33.2003H201.665V52.0003H197.665V33.2003H197.865Z'%20fill='white'/%3e%3cpath%20d='M217.464%2029.4004H221.064L230.864%2052.0004H226.664L224.464%2046.6004H213.864L211.464%2052.0004H207.464L217.464%2029.4004ZM223.064%2043.0004L219.264%2034.0004L215.464%2043.0004H223.064Z'%20fill='white'/%3e%3cpath%20d='M234.864%2029.6003H238.864V40.8003L249.464%2029.6003H254.264L244.864%2039.2003L254.664%2052.0003H249.864L242.264%2042.0003L238.864%2045.6003V52.0003H234.864V29.6003Z'%20fill='white'/%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_45_1332'%3e%3crect%20width='254'%20height='80'%20fill='white'%20transform='translate(0.964355)'/%3e%3c/clipPath%3e%3cclipPath%20id='clip1_45_1332'%3e%3crect%20width='254'%20height='56'%20fill='white'%20transform='translate(0.964355%2012)'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
'%3e%3cpath%20d='M42.0343%2019.6756C41.6065%2018.9657%2041.0026%2018.3784%2040.281%2017.9708C39.5594%2017.5631%2038.7446%2017.3489%2037.9159%2017.3489C37.0871%2017.3489%2036.2723%2017.5631%2035.5508%2017.9708C34.8292%2018.3784%2034.2252%2018.9657%2033.7975%2019.6756L27.0227%2031.2792C32.1983%2033.8632%2036.608%2037.7561%2039.814%2042.5713C43.0199%2047.3865%2044.9105%2052.9565%2045.2981%2058.7284H40.5413C40.1545%2053.7808%2038.4824%2049.0201%2035.6906%2044.9172C32.8987%2040.8143%2029.084%2037.5116%2024.6237%2035.3358L18.3534%2046.1775C20.8609%2047.3021%2023.0453%2049.039%2024.7059%2051.2285C26.3665%2053.4181%2027.45%2055.99%2027.8567%2058.7078H16.9326C16.803%2058.6986%2016.6778%2058.6573%2016.5682%2058.5877C16.4585%2058.518%2016.368%2058.4222%2016.3046%2058.3088C16.2413%2058.1954%2016.2072%2058.068%2016.2054%2057.9382C16.2036%2057.8083%2016.2341%2057.68%2016.2942%2057.5649L19.3213%2052.4169C18.2957%2051.5613%2017.1236%2050.8985%2015.8618%2050.4607L12.8657%2055.6087C12.5538%2056.1437%2012.3513%2056.7353%2012.27%2057.3493C12.1886%2057.9632%2012.2301%2058.5872%2012.392%2059.1849C12.5539%2059.7827%2012.833%2060.3423%2013.213%2060.8313C13.593%2061.3203%2014.0664%2061.7289%2014.6057%2062.0334C15.3162%2062.4337%2016.1171%2062.6463%2016.9326%2062.6511H31.8927C32.1705%2059.2226%2031.5583%2055.7805%2030.1152%2052.6581C28.6722%2049.5356%2026.4472%2046.8388%2023.6559%2044.8288L26.0343%2040.7104C29.557%2043.1298%2032.3879%2046.4261%2034.2476%2050.2738C36.1074%2054.1215%2036.9317%2058.3876%2036.6392%2062.6511H49.3135C49.6087%2056.1924%2048.2036%2049.7694%2045.2387%2044.0238C42.2738%2038.2783%2037.8529%2033.4115%2032.4178%2029.9098L37.226%2021.673C37.3332%2021.4935%2037.5069%2021.3636%2037.7093%2021.3115C37.9118%2021.2595%2038.1267%2021.2895%2038.3071%2021.395C38.8528%2021.6936%2059.1977%2057.1943%2059.5787%2057.6061C59.6458%2057.7264%2059.6799%2057.8624%2059.6777%2058.0001C59.6754%2058.1379%2059.6368%2058.2726%2059.5657%2058.3907C59.4947%2058.5088%2059.3937%2058.606%2059.273%2058.6725C59.1524%2058.739%2059.0163%2058.7725%2058.8785%2058.7696H53.9776C54.0394%2060.0806%2054.0394%2061.3882%2053.9776%2062.6923H58.8991C59.5241%2062.6964%2060.1436%2062.5765%2060.7219%2062.3396C61.3002%2062.1026%2061.8257%2061.7533%2062.2681%2061.3119C62.7105%2060.8704%2063.061%2060.3457%2063.2992%2059.7679C63.5374%2059.1901%2063.6586%2058.5708%2063.6559%2057.9459C63.6565%2057.1204%2063.4361%2056.3099%2063.0175%2055.5984L42.0343%2019.6756ZM140.176%2046.4658L124.979%2026.8416H121.19V53.1479H125.03V32.9883L140.66%2053.1479H144.016V26.8416H140.176V46.4658ZM101.906%2041.5855H115.527V38.1672H101.895V30.2496H117.267V26.8313H97.9828V53.1479H117.463V49.7297H101.895L101.906%2041.5855ZM85.885%2038.2496C80.5825%2036.9729%2079.0999%2035.9639%2079.0999%2033.5134C79.0999%2031.3101%2081.0458%2029.8172%2083.9493%2029.8172C86.5935%2029.8946%2089.1438%2030.8145%2091.2286%2032.4427L93.2878%2029.5289C90.6485%2027.4599%2087.3742%2026.3685%2084.0214%2026.4401C78.8116%2026.4401%2075.1771%2029.5289%2075.1771%2033.9253C75.1771%2038.6614%2078.2659%2040.2985%2083.8875%2041.6679C88.8914%2042.821%2090.4255%2043.8918%2090.4255%2046.2908C90.4255%2048.6898%2088.3663%2050.1724%2085.1848%2050.1724C82.0175%2050.1579%2078.9697%2048.9608%2076.6392%2046.8159L74.3225%2049.5855C77.3077%2052.1505%2081.1152%2053.5573%2085.051%2053.5495C90.6932%2053.5495%2094.3174%2050.5122%2094.3174%2045.8172C94.2865%2041.8429%2091.939%2039.7116%2085.885%2038.2496ZM213.669%2026.8416L205.751%2039.1968L197.885%2026.8416H193.293L203.682%2042.749V53.1582H207.635V42.6254L218.096%2026.8416H213.669ZM147.126%2030.404H155.743V53.1582H159.697V30.404H168.315V26.8416H147.136L147.126%2030.404ZM186.601%2042.8828C190.575%2041.7811%20192.778%2039.0012%20192.778%2035.027C192.778%2029.9716%20189.082%2026.7901%20183.12%2026.7901H171.424V53.1376H175.337V43.6859H181.978L188.649%2053.1582H193.221L186.014%2043.0475L186.601%2042.8828ZM175.326%2040.3088V30.3217H182.709C186.559%2030.3217%20188.763%2032.1441%20188.763%2035.3049C188.763%2038.4658%20186.405%2040.3088%20182.75%2040.3088H175.326Z'%20fill='white'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_98_1901'%3e%3crect%20width='228.571'%20height='80'%20fill='white'%20transform='translate(0.850342)'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
'%3e%3cpath%20d='M0%2016H48V64H0V16ZM43.0272%2059.0272V20.9728H4.9728V59.0368H43.0368L43.0272%2059.0272ZM9.2928%2028.384V42.928C9.2928%2049.5808%2012.9408%2053.4688%2019.1136%2053.4688C25.2864%2053.4688%2029.1264%2049.504%2029.1264%2042.928V28.384H24.1536V42.928C24.1536%2046.6912%2022.5504%2048.7744%2019.2288%2048.7744C15.9072%2048.7744%2014.256%2046.5664%2014.256%2042.928V28.384H9.2832H9.2928ZM35.5392%2031.3504C37.3056%2031.3504%2038.5824%2030.1504%2038.5824%2028.384C38.5824%2026.6176%2037.296%2025.3408%2035.5392%2025.3408C33.7824%2025.3408%2032.496%2026.5792%2032.496%2028.384C32.496%2030.1888%2033.7824%2031.3504%2035.5392%2031.3504ZM33.0528%2033.712V53.2288H38.0256V33.712H33.0528ZM62.7456%2045.2128C68.1504%2045.2128%2071.6832%2042.0448%2071.6832%2036.7168C71.6832%2031.3888%2068.2368%2028.384%2062.7456%2028.384H53.2896V53.2288H58.2624V45.2128H62.7456ZM62.2272%2041.248H58.2624V32.3968H62.2272C65.0688%2032.3968%2066.6336%2034%2066.6336%2036.7264C66.6336%2039.6544%2065.0688%2041.2576%2062.2272%2041.2576V41.248ZM73.3632%2043.4944C73.3632%2049.3024%2077.088%2053.4688%2082.3776%2053.4688C85.5072%2053.4688%2087.5424%2052.3456%2088.704%2050.464V53.2288H93.6768V33.712H88.704V36.7552C87.504%2034.7488%2085.4208%2033.472%2082.3776%2033.472C77.0112%2033.472%2073.3632%2037.7152%2073.3632%2043.4848V43.4944ZM88.704%2043.4944C88.704%2046.9024%2086.5824%2049.1008%2083.5392%2049.1008C80.1696%2049.1008%2078.4128%2046.7392%2078.4128%2043.4944C78.4128%2040.0096%2080.3808%2037.8016%2083.5392%2037.8016C86.6976%2037.8016%2088.704%2040.1248%2088.704%2043.4944ZM106.214%2048.9856C104.294%2048.9856%20103.766%2048.1408%20103.766%2046.4224V37.9264H108.134V33.7216H103.766V28.3936H98.7936V33.7216H96.4704V37.9264H98.7936V46.384C98.7936%2050.992%20100.838%2053.2384%20105.562%2053.2384H108.163V48.9952H106.195L106.214%2048.9856ZM115.91%2036.448V27.1936H110.938V53.2384H115.91V42.8992C115.91%2039.5776%20117.677%2037.5712%20120.595%2037.5712C123.514%2037.5712%20125.04%2039.4912%20125.04%2042.4576V53.2384H130.013V41.9008C130.013%2036.7744%20126.403%2033.4432%20121.795%2033.4432C118.829%2033.4432%20117.024%2034.5664%20115.901%2036.448H115.91Z'%20fill='white'/%3e%3cpath%20d='M134.774%2035.2474C131.702%2035.2474%20129.6%2033.1066%20129.6%2030.1211C129.6%2027.1355%20131.769%2025.0234%20134.774%2025.0234C137.779%2025.0234%20139.92%2027.0779%20139.92%2030.1211C139.92%2033.1642%20137.808%2035.2474%20134.774%2035.2474ZM134.774%2025.9259C132.201%2025.9259%20130.569%2027.5387%20130.569%2030.1115C130.569%2032.6842%20132.288%2034.2682%20134.774%2034.2682C137.261%2034.2682%20138.96%2032.5978%20138.96%2030.1115C138.96%2027.6251%20137.328%2025.9259%20134.774%2025.9259ZM135.945%2030.9179L137.03%2032.9434H135.744L134.717%2031.081H133.901V32.9434H132.739V27.1739H134.957C136.214%2027.1739%20137.145%2027.9131%20137.145%2029.1035C137.145%2029.9867%20136.675%2030.6203%20135.945%2030.9179ZM133.901%2030.1595H134.813C135.485%2030.1595%20135.945%2029.7851%20135.945%2029.1035C135.945%2028.4795%20135.485%2028.1051%20134.813%2028.1051H133.901V30.1595Z'%20fill='white'/%3e%3c/g%3e%3c/svg%3e)
'%3e%3cg%20clip-path='url(%23clip1_98_795)'%3e%3cpath%20d='M12.5048%2054.9711C10.23%2053.9075%208.36204%2053.0483%208.36204%2051.3099C8.36204%2049.9812%209.42509%2049.0146%2011.5256%2049.0146C12.2984%2049.0146%2012.9301%2049.106%2013.5829%2049.2255C13.9244%2049.2842%2014.2889%2049.3344%2014.5897%2049.3344C16.4241%2049.3344%2017.4595%2048.2408%2018.1479%2046.1649L18.4327%2045.3172C18.1399%2045.1977%2015.1426%2043.8816%2011.2343%2043.8816C5.01672%2043.8816%201.73467%2047.8692%201.73668%2052.0059C1.73668%2054.0933%202.38997%2055.6048%203.41285%2056.7964C4.7305%2058.3284%206.60954%2059.3312%208.36757%2060.1884C10.929%2061.4453%2013.2409%2062.3743%2013.2409%2064.2372C13.2424%2065.8898%2011.5341%2066.8303%209.25035%2066.8303C6.12145%2066.8303%203.38724%2065.0417%203.03775%2064.8263L0.46875%2069.6414C0.925706%2069.8995%204.23437%2072%209.67968%2072C15.482%2071.996%2019.8758%2068.6697%2019.8758%2063.5508C19.8753%2058.4575%2015.8029%2056.5694%2012.5048%2054.9711Z'%20fill='white'/%3e%3cpath%20d='M35.1999%2057.3493L45.7255%2044.4441H38.2259L29.8309%2055.5808H29.7054V44.4441H23.5244L23.5259%2071.7816H23.8935C26.5659%2071.7816%2029.7471%2070.5453%2029.7471%2066.0807V59.8044H29.8726L38.4302%2071.4412H46.2964L35.1999%2057.3493Z'%20fill='white'/%3e%3cpath%20d='M46.076%2015.1606C43.8996%2015.5714%2040.6728%2017.5469%2040.6834%2021.0403C40.6919%2024.2124%2043.2855%2026.1351%2043.2936%2030.2919C43.3061%2033.4193%2041.5827%2035.5248%2039.7188%2036.6923C40.472%2036.6255%2041.297%2036.5824%2042.2049%2036.5803C44.109%2036.5753%2045.257%2036.7571%2045.3283%2036.7686L55.0916%2024.7879C52.38%2020.7285%2049.2134%2017.5785%2046.076%2015.1606Z'%20fill='white'/%3e%3cpath%20d='M54.2771%2047.5141C55.5078%2045.6009%2055.662%2042.5519%2055.7664%2039.4461C55.8814%2036.5492%2056.486%2034.3694%2060.3616%2034.3558C61.2203%2034.3528%2062.0383%2034.4708%2063.5196%2034.4668C69.1969%2034.4417%2072.9038%2032.4868%2075.2097%2031.2038C70.4985%2028.1999%2063.6221%2025.1328%2055.0911%2024.7878C54.5352%2026.3561%2050.2117%2038.3775%2049.8848%2039.3477C49.934%2039.4059%2050.6912%2040.2546%2051.6368%2041.9096C53.0317%2044.1829%2053.7804%2046.1086%2054.2771%2047.5141Z'%20fill='white'/%3e%3cpath%20d='M33.6554%2037.6951C33.1618%2037.6982%2032.9163%2037.3702%2032.8495%2036.8013C32.7867%2036.2364%2030.3448%2013.8973%2029.9812%2010.5163C29.9285%2010.0227%2029.806%209.11629%2029.8044%208.79341C29.8034%208.27268%2030.1424%208.00101%2030.5421%208.00001C31.6991%207.99549%2038.004%209.47231%2044.6952%2014.1619C42.7674%2014.7057%2039.28%2016.7108%2039.2961%2020.8626C39.3086%2024.5373%2041.9399%2026.56%2041.9535%2030.2468C41.9735%2036.2424%2035.0825%2037.6926%2033.6554%2037.6951Z'%20fill='white'/%3e%3cpath%20d='M54.8381%2049.1085C54.9431%2049.3867%2055.042%2049.6207%2055.1414%2049.7844C55.2951%2050.0455%2055.4954%2050.164%2055.7415%2050.163C55.8972%2050.161%2056.088%2050.1093%2056.2989%2050.0139C56.8146%2049.7769%2077.2014%2040.2862%2080.276%2038.8677C80.7219%2038.6538%2081.5666%2038.2761%2081.8453%2038.1129C82.134%2037.9487%2082.2661%2037.7082%2082.2661%2037.4642C82.265%2037.3276%2082.2249%2037.1895%2082.1475%2037.064C81.7634%2036.4423%2079.791%2034.3488%2076.4933%2032.061C73.8746%2033.5027%2069.7861%2035.7323%2063.7041%2035.7569C62.2137%2035.7584%2061.8763%2035.6584%2060.8584%2035.6625C57.8892%2035.673%2057.148%2036.9429%2057.0396%2039.5456C57.0215%2040.0372%2057.0129%2040.699%2056.9843%2041.4246C56.8904%2043.7516%2056.6157%2046.9608%2054.8381%2049.1085Z'%20fill='white'/%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_98_795'%3e%3crect%20width='81.7977'%20height='80'%20fill='white'%20transform='translate(0.46875)'/%3e%3c/clipPath%3e%3cclipPath%20id='clip1_98_795'%3e%3crect%20width='81.7977'%20height='64'%20fill='white'%20transform='translate(0.46875%208)'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
'%3e%3cg%20clip-path='url(%23clip1_98_1579)'%3e%3cmask%20id='mask0_98_1579'%20style='mask-type:luminance'%20maskUnits='userSpaceOnUse'%20x='0'%20y='18'%20width='133'%20height='44'%3e%3cpath%20d='M132.745%2018H0.133789V62H132.745V18Z'%20fill='white'/%3e%3c/mask%3e%3cg%20mask='url(%23mask0_98_1579)'%3e%3cpath%20d='M26.6999%2019.3879L24.4297%2032.2578H16.549C9.19685%2032.2578%202.1891%2038.2121%200.890254%2045.5614L0.340492%2048.6896C-0.952299%2056.0389%203.95312%2061.9934%2011.3052%2061.9934H17.878C23.2365%2061.9934%2028.3413%2057.6574%2029.2838%2052.3009L35.3371%2018L26.6999%2019.3879ZM21.108%2051.0871C20.8182%2052.7417%2019.3279%2054.0886%2017.6726%2054.0886H13.6794C10.3749%2054.0886%208.16384%2051.407%208.74376%2048.0978L9.08814%2046.1474C9.67411%2042.8441%2012.8276%2040.1566%2016.1321%2040.1566H23.0362L21.108%2051.0871ZM87.3915%2061.9927L92.5626%2032.6678H100.742L95.5711%2061.9927H87.3915ZM88.276%2033.0059C87.8661%2035.3319%2087.4544%2037.6579%2087.0444%2039.984C83.1691%2038.7801%2079.171%2039.1635%2077.9427%2039.4084C76.6161%2046.9383%2075.2878%2054.4701%2073.9594%2062H65.7743C66.8858%2055.6996%2070.6832%2034.1826%2070.6832%2034.1826C73.3454%2033.0806%2079.8829%2030.8441%2088.276%2033.0059ZM55.1111%2032.2528H48.7437C42.5395%2032.2528%2036.6254%2037.2771%2035.5318%2043.4791L34.2452%2050.7681C33.1516%2056.9699%2037.29%2061.9943%2043.4943%2061.9943H57.0384L58.4279%2054.1137H45.6989C43.6331%2054.1137%2042.2495%2052.4408%2042.6182%2050.3695L42.6605%2050.1218H63.1823L64.3542%2043.4791C65.4476%2037.2771%2061.3094%2032.2528%2055.1052%2032.2528H55.1111ZM56.1441%2042.851L56.0959%2043.2738H43.8929L43.9594%2042.8994C44.3278%2040.834%2046.2128%2039.0164%2048.2846%2039.0164H53.0511C55.0991%2039.0164%2056.4828%2040.8039%2056.1441%2042.851ZM124.472%2032.6678H132.658C129.869%2040.0785%20123.479%2052.6847%20117.289%2061.9927H109.103C106.262%2053.1336%20104.427%2040.7902%20104.077%2032.6678H112.263C112.41%2035.3173%20113.597%2045.1447%20114.951%2052.0102C118.665%2045.3312%20122.76%2036.568%20124.466%2032.6678H124.472Z'%20fill='white'/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_98_1579'%3e%3crect%20width='133.833'%20height='80'%20fill='white'%20transform='translate(0.133789)'/%3e%3c/clipPath%3e%3cclipPath%20id='clip1_98_1579'%3e%3crect%20width='133.833'%20height='44'%20fill='white'%20transform='translate(0.133789%2018)'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)

'%3e%3cmask%20id='mask0_44_657'%20style='mask-type:luminance'%20maskUnits='userSpaceOnUse'%20x='0'%20y='5'%20width='89'%20height='70'%3e%3cpath%20d='M88.6809%205H0V75H88.6809V5Z'%20fill='white'/%3e%3c/mask%3e%3cg%20mask='url(%23mask0_44_657)'%3e%3cpath%20d='M40.4621%2051.718V22.1797L34.3599%2028.282V57.8202L40.4621%2051.718Z'%20fill='white'/%3e%3cpath%20d='M0.000244141%2028.282V57.8202L6.10253%2051.718V22.1797L0.000244141%2028.282Z'%20fill='white'/%3e%3cpath%20d='M14.6924%2029.4077V13.5896L8.59009%2019.6919V35.5099L14.6924%2029.4077Z'%20fill='white'/%3e%3cpath%20d='M17.1802%2011.1022V26.9202L23.2825%2020.8179V4.99988L17.1802%2011.1022Z'%20fill='white'/%3e%3cpath%20d='M31.8716%2029.4077V13.5896L25.7693%2019.6919V35.5099L31.8716%2029.4077Z'%20fill='white'/%3e%3cpath%20d='M23.2825%2051.7179L17.1802%2057.8202L23.2825%2051.7179Z'%20fill='white'/%3e%3cpath%20d='M17.1802%2058.5011V75L23.2825%2068.8977V52.3988L17.1802%2058.5011Z'%20fill='white'/%3e%3cpath%20d='M31.8716%2043.1279L25.7693%2049.2302L31.8716%2043.1279Z'%20fill='white'/%3e%3cpath%20d='M25.7693%2049.911V66.4099L31.8716%2060.3076V43.8087L25.7693%2049.911Z'%20fill='white'/%3e%3cpath%20d='M8.59009%2049.911V66.4099L14.6924%2060.3076V43.8087L8.59009%2049.911Z'%20fill='white'/%3e%3cpath%20d='M17.1802%2041.3213V44.1L23.2825%2037.9977V35.219L17.1802%2041.3213Z'%20fill='white'/%3e%3cpath%20d='M31.8716%2030.7697L25.7693%2036.8719V49.2305L31.8716%2043.1282V30.7697Z'%20fill='white'/%3e%3cpath%20d='M23.2825%2039.3594L17.1802%2045.4617V57.8202L23.2825%2051.7179V39.3594Z'%20fill='white'/%3e%3cpath%20d='M17.1802%2028.282V40.6405L23.2825%2034.5382V22.1797L17.1802%2028.282Z'%20fill='white'/%3e%3cpath%20d='M8.59009%2036.8719V49.2305L14.6924%2043.1282V30.7697L8.59009%2036.8719Z'%20fill='white'/%3e%3cpath%20d='M47.8804%2051.7179V48.73L62.6507%2025.0017H48.4614V22.1797H66.2173V24.8357L51.3243%2048.8972H66.2173V51.7179H47.8804Z'%20fill='white'/%3e%3cmask%20id='mask1_44_657'%20style='mask-type:luminance'%20maskUnits='userSpaceOnUse'%20x='0'%20y='5'%20width='89'%20height='70'%3e%3cpath%20d='M88.6809%205H0V75H88.6809V5Z'%20fill='white'/%3e%3c/mask%3e%3cg%20mask='url(%23mask1_44_657)'%3e%3cpath%20d='M88.5833%2045.4519C87.9542%2049.5863%2084.1001%2052.1881%2078.7015%2052.1881C74.258%2052.1881%2071.3495%2051.067%2068.5684%2048.2847L70.7336%2046.1195C73.1839%2048.5698%2075.467%2049.3601%2078.793%2049.3601C82.2104%2049.3601%2084.6041%2047.9936%2085.309%2045.6311C85.4009%2045.3178%2085.4562%2044.9949%2085.4738%2044.6688C85.5294%2043.8802%2085.4116%2043.089%2085.1286%2042.3508C84.9133%2041.7494%2084.2373%2040.9519%2083.7152%2040.5958C82.5652%2039.7538%2080.9197%2039.0441%2079.2284%2038.4691L75.9277%2037.3384C73.7023%2036.5649%2072.0399%2035.5052%2070.9597%2034.1832C69.6882%2032.6267%2069.2564%2030.3592%2069.6281%2028.0725C69.6281%2028.0569%2069.6546%2027.9161%2069.6546%2027.9161C70.5784%2023.9971%2073.7973%2021.6984%2078.8555%2021.6984C82.635%2021.6984%2084.7304%2022.8351%2087.2637%2025.1194L85.2284%2027.1547C83.4012%2025.4935%2081.8459%2024.4398%2078.7328%2024.4398C75.0508%2024.4398%2073.0167%2026.3921%2072.6137%2029.0023C72.4585%2030.4458%2072.8543%2031.5284%2073.5977%2032.4438C74.3591%2033.3809%2075.6943%2034.1279%2077.1642%2034.6463L80.2677%2035.7C82.5219%2036.4543%2084.9975%2037.6427%2086.3772%2038.8817C86.3772%2038.8817%2089.2533%2041.1095%2088.5941%2045.4447'%20fill='white'/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_44_657'%3e%3crect%20width='88.6809'%20height='80'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
chevron_leftchevron_right



chevron_leftchevron_right
globe_book
Utilisez
r.jina.ai pour lire une URL et récupérer son contenutravel_explore
Utilisez
s.jina.ai pour rechercher sur le Web et obtenir le SERP
Ajoutez
mcp.jina.ai comme serveur MCP pour accéder à notre API dans les LLMupload
Demande
GET
curl "https://r.jina.ai/https://www.example.com"

Pour une meilleure recherche
Nos modèles de frontière constituent la base de recherche pour les systèmes de recherche d'entreprise et RAG de haute qualité.







Nos publications
Découvrez comment nos modèles de recherche de frontière ont été formés à partir de zéro, consultez nos dernières publications. Rencontrez notre équipe chez EMNLP, SIGIR, ICLR, NeurIPS et ICML !
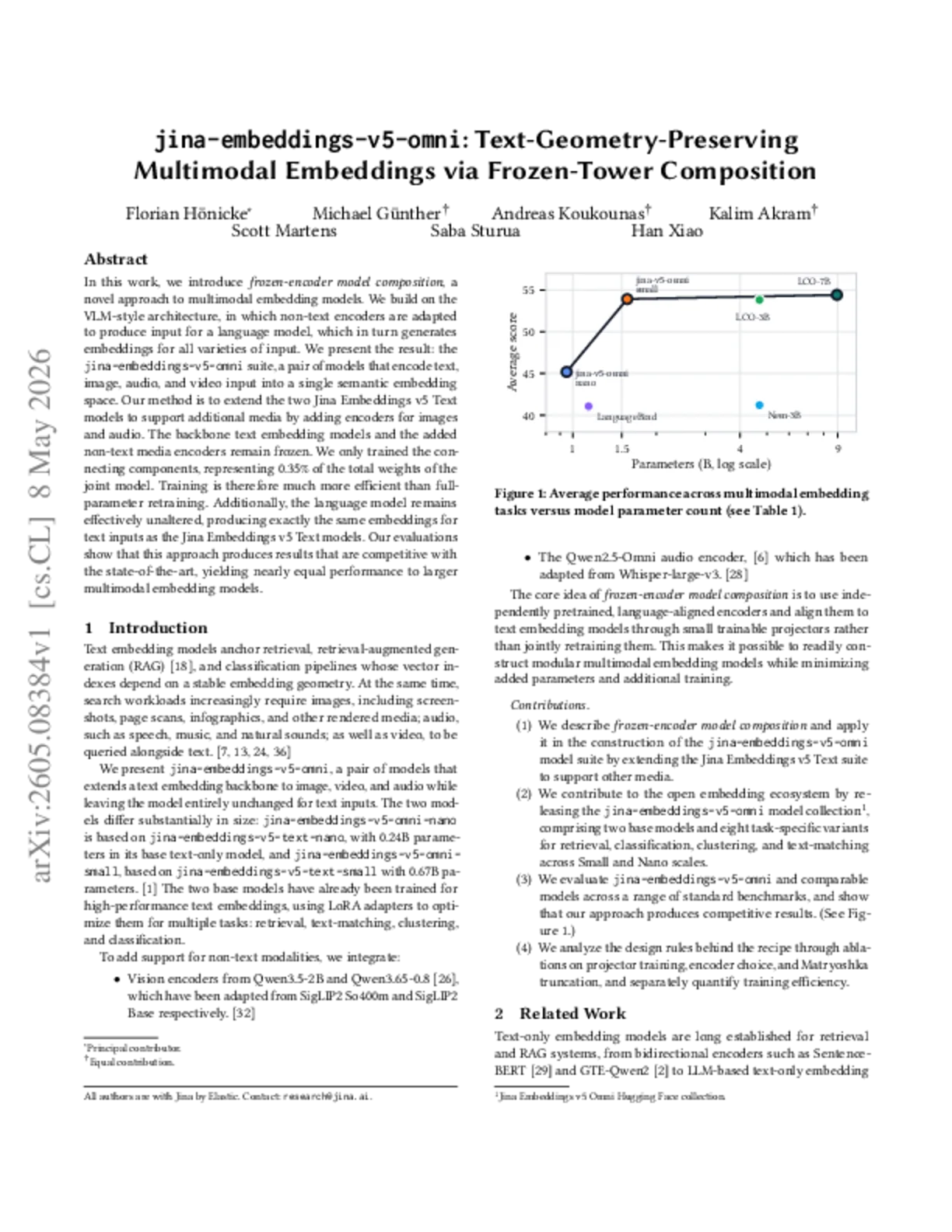
mai 11, 2026

SIGIR 2026
février 17, 2026

ICLR 2026
janvier 22, 2026

décembre 29, 2025

ICLR 2026
décembre 04, 2025

AAAI 2026
octobre 01, 2025

NeurIPS 2025
août 31, 2025

EMNLP 2025
juin 24, 2025

ICLR 2025
mars 04, 2025

ACL 2025
décembre 17, 2024

ICLR 2025
décembre 12, 2024

ECIR 2025
septembre 18, 2024

SIGIR 2025
septembre 07, 2024

EMNLP 2024
août 30, 2024

WWW 2025
juin 21, 2024

ICML 2024
mai 30, 2024

février 26, 2024

octobre 30, 2023

EMNLP 2023
juillet 20, 2023
19 publications au total.