


Il existe de nombreux obstacles à la compréhension des modèles d'IA, certains étant assez importants, et ils peuvent entraver la mise en œuvre des processus d'IA. Mais le premier que beaucoup rencontrent est de comprendre ce que nous entendons par tokens.

L'un des paramètres pratiques les plus importants dans le choix d'un modèle de langage IA est la taille de sa fenêtre contextuelle — la taille maximale du texte d'entrée — qui est donnée en tokens, et non en mots ou en caractères ou toute autre unité automatiquement reconnaissable.
De plus, les services d'embedding sont généralement facturés « par token », ce qui signifie que les tokens sont importants pour comprendre votre facture.
Cela peut être très déroutant si vous ne savez pas clairement ce qu'est un token.
Mais de tous les aspects déroutants de l'IA moderne, les tokens sont probablement les moins compliqués. Cet article tentera de clarifier ce qu'est la tokenisation, ce qu'elle fait et pourquoi nous procédons ainsi.
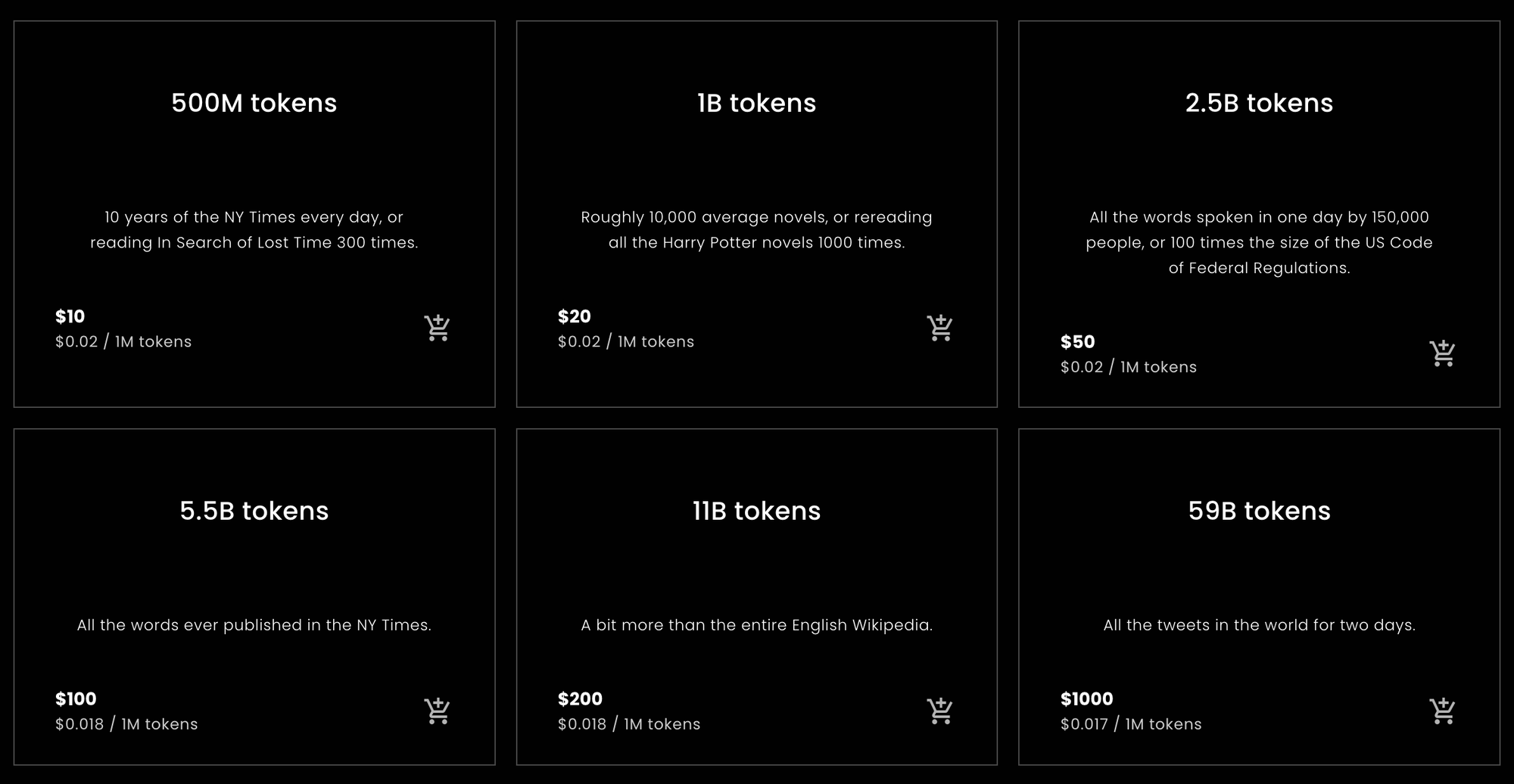
tagtl;dr
Pour ceux qui veulent ou ont besoin d'une réponse rapide pour calculer combien de tokens acheter auprès de Jina Embeddings ou estimer combien ils devront en acheter, voici les statistiques que vous recherchez.
tagTokens par mot en anglais
Lors des tests empiriques, décrits plus loin dans cet article, divers textes anglais ont été convertis en tokens à un taux d'environ 10% de tokens de plus que de mots, en utilisant les modèles anglais uniquement de Jina Embeddings. Ce résultat était assez robuste.
Les modèles Jina Embeddings v2 ont une fenêtre contextuelle de 8192 tokens. Cela signifie que si vous passez à un modèle Jina un texte anglais de plus de 7 400 mots, il y a de fortes chances qu'il soit tronqué.
tagTokens par caractère chinois
Pour le chinois, les résultats sont plus variables. Selon le type de texte, les ratios varient de 0,6 à 0,75 tokens par caractère chinois (汉字). Les textes anglais donnés à Jina Embeddings v2 pour le chinois produisent environ le même nombre de tokens que Jina Embeddings v2 pour l'anglais : environ 10% de plus que le nombre de mots.
tagTokens par mot en allemand
Les ratios mots-tokens en allemand sont plus variables qu'en anglais mais moins qu'en chinois. Selon le genre du texte, j'ai obtenu en moyenne 20% à 30% de tokens de plus que de mots. Donner des textes anglais à Jina Embeddings v2 pour l'allemand et l'anglais utilise un peu plus de tokens que les modèles anglais uniquement et chinois/anglais : 12% à 15% de tokens de plus que de mots.
tagAttention !
Ce sont des calculs simples, mais ils devraient être approximativement corrects pour la plupart des textes en langage naturel et la plupart des utilisateurs. En fin de compte, nous pouvons seulement promettre que le nombre de tokens sera toujours inférieur ou égal au nombre de caractères dans votre texte, plus deux. Il sera pratiquement toujours beaucoup moins que cela, mais nous ne pouvons pas promettre un compte spécifique à l'avance.
Ce sont des estimations basées sur des calculs statistiquement naïfs. Nous ne garantissons pas le nombre de tokens que prendra une requête particulière.
Si vous avez seulement besoin de conseils sur le nombre de tokens à acheter pour Jina Embeddings, vous pouvez vous arrêter ici. D'autres modèles d'embedding, d'entreprises autres que Jina AI, peuvent ne pas avoir les mêmes ratios token-mot et token-caractère-chinois que les modèles Jina, mais ils ne seront généralement pas très différents dans l'ensemble.
Si vous voulez comprendre pourquoi, le reste de cet article est une plongée plus profonde dans la tokenisation pour les modèles de langage.
tagMots, Tokens, Nombres
La tokenisation fait partie du traitement du langage naturel depuis plus longtemps que l'existence des modèles d'IA modernes.
C'est un peu un cliché de dire que tout dans un ordinateur n'est que des nombres, mais c'est aussi majoritairement vrai. Le langage, cependant, n'est pas naturellement qu'un ensemble de nombres. Il peut s'agir de parole, composée d'ondes sonores, ou d'écriture, composée de marques sur du papier, ou même d'une image d'un texte imprimé ou d'une vidéo de quelqu'un utilisant la langue des signes. Mais la plupart du temps, quand nous parlons d'utiliser des ordinateurs pour traiter le langage naturel, nous parlons de textes composés de séquences de caractères : lettres (a, b, c, etc.), chiffres (0, 1, 2…), ponctuation et espaces, dans différentes langues et encodages textuels.
Les ingénieurs informatiques appellent cela des « chaînes de caractères ».
Les modèles de langage IA prennent des séquences de nombres comme entrée. Donc, vous pourriez écrire la phrase :
What is today's weather in Berlin?
Mais, après tokenisation, le modèle IA reçoit comme entrée :
[101, 2054, 2003, 2651, 1005, 1055, 4633, 1999, 4068, 1029, 102]
La tokenisation est le processus de conversion d'une chaîne d'entrée en une séquence spécifique de nombres que votre modèle IA peut comprendre.
Lorsque vous utilisez un modèle IA via une API web qui facture les utilisateurs par token, chaque requête est convertie en une séquence de nombres comme celle ci-dessus. Le nombre de tokens dans la requête est la longueur de cette séquence de nombres. Donc, demander à Jina Embeddings v2 pour l'anglais de vous donner un embedding pour "What is today's weather in Berlin?" vous coûtera 11 tokens car il a converti cette phrase en une séquence de 11 nombres avant de la passer au modèle IA.
Les modèles IA basés sur l'architecture Transformer ont une fenêtre contextuelle de taille fixe dont la taille est mesurée en tokens. Parfois, on l'appelle « fenêtre d'entrée », « taille de contexte » ou « longueur de séquence » (particulièrement sur le leaderboard MTEB de Hugging Face). Cela signifie la taille maximale de texte que le modèle peut voir à la fois.
Donc, si vous voulez utiliser un modèle d'embedding, c'est la taille d'entrée maximale autorisée.
Les modèles Jina Embeddings v2 ont tous une fenêtre contextuelle de 8 192 tokens. D'autres modèles auront des fenêtres contextuelles différentes (généralement plus petites). Cela signifie que quelle que soit la quantité de texte que vous y mettez, le tokenizer associé à ce modèle Jina Embeddings doit le convertir en pas plus de 8 192 tokens.
tagMapping du langage vers les nombres
La façon la plus simple d'expliquer la logique des tokens est celle-ci :
Pour les modèles de langage naturel, la partie de la chaîne qu'un token représente est un mot, une partie d'un mot, ou un signe de ponctuation. Les espaces ne reçoivent généralement aucune représentation explicite dans la sortie du tokenizer.
La tokenisation fait partie d'un groupe de techniques de traitement du langage naturel appelées segmentation de texte, et le module qui effectue la tokenisation est appelé, très logiquement, un tokenizer.
Pour montrer comment fonctionne la tokenisation, nous allons tokeniser quelques phrases en utilisant le plus petit modèle Jina Embeddings v2 pour l'anglais : jina-embeddings-v2-small-en. L'autre modèle anglais uniquement de Jina Embeddings — jina-embeddings-v2-base-en — utilise le même tokenizer, donc il n'y a pas d'intérêt à télécharger des mégaoctets supplémentaires de modèle IA que nous n'utiliserons pas dans cet article.
Tout d'abord, installez le module transformers dans votre environnement Python ou notebook. Utilisez le
-U permet de s'assurer que vous passez à la dernière version, car ce modèle ne fonctionnera pas avec certaines versions plus anciennes :pip install -U transformers
Ensuite, téléchargez jina-embeddings-v2-small-en en utilisant AutoModel.from_pretrained :
from transformers import AutoModel
model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-small-en', trust_remote_code=True)
Pour tokeniser une chaîne de caractères, utilisez la méthode encode de l'objet membre tokenizer du modèle :
model.tokenizer.encode("What is today's weather in Berlin?")
Le résultat est une liste de nombres :
[101, 2054, 2003, 2651, 1005, 1055, 4633, 1999, 4068, 1029, 102]
Pour reconvertir ces nombres en chaînes de caractères, utilisez la méthode convert_ids_to_tokens de l'objet tokenizer :
model.tokenizer.convert_ids_to_tokens([101, 2054, 2003, 2651, 1005, 1055, 4633, 1999, 4068, 1029, 102])
Le résultat est une liste de chaînes :
['[CLS]', 'what', 'is', 'today', "'", 's', 'weather', 'in',
'berlin', '?', '[SEP]']
Notez que le tokenizer du modèle a :
- Ajouté
[CLS]au début et[SEP]à la fin. C'est nécessaire pour des raisons techniques et signifie que chaque demande d'embedding coûtera deux tokens supplémentaires, en plus du nombre de tokens que le texte nécessite. - Séparé la ponctuation des mots, transformant « Berlin? » en :
berlinet?, et « today's » entoday,', ets. - Mis tout en minuscules. Tous les modèles ne le font pas, mais cela peut aider lors de l'entraînement en anglais. Cela peut être moins utile dans les langues où la capitalisation a une signification différente.
Différents algorithmes de comptage de mots dans différents programmes peuvent compter les mots de cette phrase différemment. OpenOffice compte ceci comme six mots. L'algorithme de segmentation de texte Unicode (Unicode Standard Annex #29) compte sept mots. D'autres logiciels peuvent arriver à d'autres nombres, selon la façon dont ils gèrent la ponctuation et les clitiques comme « 's ».
Le tokenizer de ce modèle produit neuf tokens pour ces six ou sept mots, plus les deux tokens supplémentaires nécessaires à chaque requête.
Maintenant, essayons avec un nom de lieu moins courant que Berlin :
token_ids = model.tokenizer.encode("I live in Kinshasa.")
tokens = model.tokenizer.convert_ids_to_tokens(token_ids)
print(tokens)
Le résultat :
['[CLS]', 'i', 'live', 'in', 'kin', '##sha', '##sa', '.', '[SEP]']
Le nom « Kinshasa » est divisé en trois tokens : kin, ##sha, et ##sa. Le ## indique que ce token n'est pas le début d'un mot.
Si nous donnons au tokenizer quelque chose de complètement étranger, le nombre de tokens par rapport au nombre de mots augmente encore plus :
token_ids = model.tokenizer.encode("Klaatu barada nikto")
tokens = model.tokenizer.convert_ids_to_tokens(token_ids)
print(tokens)
['[CLS]', 'k', '##la', '##at', '##u', 'bar', '##ada', 'nik', '##to', '[SEP]']
Trois mots deviennent huit tokens, plus les tokens [CLS] et [SEP].
La tokenisation en allemand est similaire. Avec le modèle Jina Embeddings v2 pour l'allemand, nous pouvons tokeniser une traduction de « What is today's weather in Berlin? » de la même manière qu'avec le modèle anglais.
german_model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-de', trust_remote_code=True)
token_ids = german_model.tokenizer.encode("Wie wird das Wetter heute in Berlin?")
tokens = german_model.tokenizer.convert_ids_to_tokens(token_ids)
print(tokens)
Le résultat :
['<s>', 'Wie', 'wird', 'das', 'Wetter', 'heute', 'in', 'Berlin', '?', '</s>']
Ce tokenizer est légèrement différent de celui de l'anglais car <s> et </s> remplacent [CLS] et [SEP] mais servent la même fonction. De plus, le texte n'est pas normalisé en minuscules — les majuscules et minuscules restent telles quelles — car la capitalisation a une signification différente en allemand par rapport à l'anglais.
(Pour simplifier cette présentation, j'ai supprimé un caractère spécial indiquant le début d'un mot.)
Maintenant, essayons une phrase plus complexe tirée d'un texte de journal :
Ein Großteil der milliardenschweren Bauern-Subventionen bleibt liegen – zu genervt sind die Landwirte von bürokratischen Gängelungen und Regelwahn.
sentence = """
Ein Großteil der milliardenschweren Bauern-Subventionen
bleibt liegen – zu genervt sind die Landwirte von
bürokratischen Gängelungen und Regelwahn.
"""
token_ids = german_model.tokenizer.encode(sentence)
tokens = german_model.tokenizer.convert_ids_to_tokens(token_ids)
print(tokens)Le résultat tokenisé :
['<s>', 'Ein', 'Großteil', 'der', 'mill', 'iarden', 'schwer',
'en', 'Bauern', '-', 'Sub', 'ventionen', 'bleibt', 'liegen',
'–', 'zu', 'gen', 'ervt', 'sind', 'die', 'Landwirte', 'von',
'büro', 'krat', 'ischen', 'Gän', 'gel', 'ungen', 'und', 'Regel',
'wahn', '.', '</s>']
Ici, vous voyez que de nombreux mots allemands ont été divisés en plus petits morceaux et pas nécessairement selon les règles grammaticales allemandes. En conséquence, un long mot allemand qui ne compterait que comme un seul mot pour un compteur de mots peut représenter un nombre quelconque de tokens pour le modèle AI de Jina.
Faisons de même en chinois, en traduisant « What is today's weather in Berlin? » par :
柏林今天的天气怎么样?
chinese_model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-zh', trust_remote_code=True)
token_ids = chinese_model.tokenizer.encode("柏林今天的天气怎么样?")
tokens = chinese_model.tokenizer.convert_ids_to_tokens(token_ids)
print(tokens)
Le résultat tokenisé :
['<s>', '柏林', '今天的', '天气', '怎么样', '?', '</s>']
En chinois, il n'y a généralement pas d'espaces entre les mots dans le texte écrit, mais le tokenizer de Jina Embeddings regroupe souvent plusieurs caractères chinois ensemble :
| Token string | Pinyin | Meaning |
|---|---|---|
| 柏林 | Bólín | Berlin |
| 今天的 | jīntiān de | today's |
| 天气 | tiānqì | weather |
| 怎么样 | zěnmeyàng | how |
Utilisons une phrase plus complexe d'un journal de Hong Kong :
sentence = """
新規定執行首日,記者在下班高峰前的下午5時來到廣州地鐵3號線,
從繁忙的珠江新城站啟程,向機場北方向出發。
"""
token_ids = chinese_model.tokenizer.encode(sentence)
tokens = chinese_model.tokenizer.convert_ids_to_tokens(token_ids)
print(tokens)
(Traduction : « Le premier jour de l'entrée en vigueur des nouvelles réglementations, ce journaliste est arrivé à la ligne 3 du métro de Guangzhou à 17h, pendant l'heure de pointe, en partant de la station Zhujiang New Town en direction de l'aéroport. »)
Le résultat :
['<s>', '新', '規定', '執行', '首', '日', ',', '記者', '在下', '班',
'高峰', '前的', '下午', '5', '時', '來到', '廣州', '地', '鐵', '3',
'號', '線', ',', '從', '繁忙', '的', '珠江', '新城', '站', '啟',
'程', ',', '向', '機場', '北', '方向', '出發', '。', '</s>']
Ces tokens ne correspondent à aucun dictionnaire spécifique de mots chinois (词典). Par exemple, "啟程" - qǐchéng (partir, se mettre en route) serait généralement catégorisé comme un seul mot mais est ici divisé en ses deux caractères constitutifs. De même, "在下班" serait normalement reconnu comme deux mots, avec la séparation entre "在" - zài (à, pendant) et "下班" - xiàbān (la fin de la journée de travail, heure de pointe), et non entre "在下" et "班" comme l'a fait le tokenizer ici.
Dans les trois langues, les endroits où le tokenizer découpe le texte ne sont pas directement liés aux endroits logiques où un lecteur humain les séparerait.
Ce n'est pas une caractéristique spécifique des modèles Jina Embeddings. Cette approche de la tokenization est presque universelle dans le développement des modèles d'IA. Bien que deux modèles d'IA différents puissent ne pas avoir des tokenizers identiques, dans l'état actuel du développement, ils utiliseront pratiquement tous des tokenizers avec ce type de comportement.
La section suivante discutera de l'algorithme spécifique utilisé dans la tokenization et la logique qui le sous-tend.
tagPourquoi tokeniser ? Et pourquoi de cette manière ?
Les modèles de langage IA prennent en entrée des séquences de nombres qui représentent des séquences de texte, mais il se passe un peu plus de choses avant d'exécuter le réseau neuronal sous-jacent et de créer un embedding. Lorsqu'on lui présente une liste de nombres représentant de petites séquences de texte, le modèle recherche chaque nombre dans un dictionnaire interne qui stocke un vecteur unique pour chaque nombre. Il les combine ensuite, et cela devient l'entrée du réseau neuronal.
Cela signifie que le tokenizer doit être capable de convertir n'importe quel texte d'entrée que nous lui donnons en tokens qui apparaissent dans le dictionnaire de vecteurs de tokens du modèle. Si nous prenions nos tokens d'un dictionnaire conventionnel, la première fois que nous rencontrerions une faute d'orthographe ou un nom propre rare ou un mot étranger, le modèle entier s'arrêterait. Il ne pourrait pas traiter cette entrée.
En traitement du langage naturel, on appelle cela le problème du vocabulaire hors-vocabulaire (OOV), et il est omniprésent dans tous les types de textes et toutes les langues. Il existe quelques stratégies pour résoudre le problème OOV :
- L'ignorer. Remplacer tout ce qui n'est pas dans le dictionnaire par un token "inconnu".
- Le contourner. Au lieu d'utiliser un dictionnaire qui associe des séquences de texte à des vecteurs, utiliser un qui associe des caractères individuels à des vecteurs. L'anglais n'utilise que 26 lettres la plupart du temps, donc cela doit être plus petit et plus robuste contre les problèmes OOV que n'importe quel dictionnaire.
- Trouver des sous-séquences fréquentes dans le texte, les mettre dans le dictionnaire et utiliser des caractères (tokens d'une seule lettre) pour ce qui reste.
La première stratégie signifie que beaucoup d'informations importantes sont perdues. Le modèle ne peut même pas apprendre des données qu'il a vues si elles prennent la forme de quelque chose qui n'est pas dans le dictionnaire. Beaucoup de choses dans le texte ordinaire ne sont tout simplement pas présentes dans les plus grands dictionnaires.
La deuxième stratégie est possible, et les chercheurs l'ont étudiée. Cependant, cela signifie que le modèle doit accepter beaucoup plus d'entrées et doit apprendre beaucoup plus. Cela signifie un modèle beaucoup plus grand et beaucoup plus de données d'entraînement pour un résultat qui ne s'est jamais avéré meilleur que la troisième stratégie.
Les modèles de langage IA mettent pratiquement tous en œuvre la troisième stratégie sous une forme ou une autre. La plupart utilisent une variante de l'algorithme Wordpiece [Schuster et Nakajima 2012] ou une technique similaire appelée Byte-Pair Encoding (BPE). [Gage 1994, Senrich et al. 2016] Ces algorithmes sont agnostiques au langage. Cela signifie qu'ils fonctionnent de la même manière pour toutes les langues écrites sans aucune connaissance au-delà d'une liste complète des caractères possibles. Ils ont été conçus pour des modèles multilingues comme BERT de Google qui prennent n'importe quelle entrée du scraping d'Internet — des centaines de langues et des textes autres que le langage humain comme les programmes informatiques — afin qu'ils puissent être entraînés sans faire de linguistique compliquée.
Certaines recherches montrent des améliorations significatives en utilisant des tokenizers plus spécifiques et conscients de la langue. [Rust et al. 2021] Mais construire des tokenizers de cette manière prend du temps, de l'argent et de l'expertise. Mettre en œuvre une stratégie universelle comme BPE ou Wordpiece est beaucoup moins cher et plus facile.
Cependant, en conséquence, il n'y a aucun moyen de savoir combien de tokens représente un texte spécifique autre que de le faire passer par un tokenizer puis de compter le nombre de tokens qui en sortent. Parce que la plus petite sous-séquence possible d'un texte est une lettre, vous pouvez être sûr que le nombre de tokens ne sera pas plus grand que le nombre de caractères (moins les espaces) plus deux.
Pour obtenir une bonne estimation, nous devons soumettre beaucoup de texte à notre tokenizer et calculer empiriquement combien de tokens nous obtenons en moyenne, par rapport au nombre de mots ou de caractères que nous avons entrés. Dans la section suivante, nous ferons quelques mesures empiriques pas très systématiques pour tous les modèles Jina Embeddings v2 actuellement disponibles.
tagEstimations empiriques des tailles de sortie des tokens
Pour l'anglais et l'allemand, j'ai utilisé l'algorithme de segmentation de texte Unicode (Unicode Standard Annex #29) pour obtenir le nombre de mots des textes. Cet algorithme est largement utilisé pour sélectionner des extraits de texte lorsque vous double-cliquez sur quelque chose. C'est ce qui se rapproche le plus d'un compteur de mots objectif universel.
J'ai installé la bibliothèque polyglot en Python, qui implémente ce segmenteur de texte :
pip install -U polyglot
Pour obtenir le nombre de mots d'un texte, vous pouvez utiliser un code comme cet extrait :
from polyglot.text import Text
txt = "What is today's weather in Berlin?"
print(len(Text(txt).words))
Le résultat devrait être 7.
Pour obtenir un nombre de tokens, des segments du texte ont été passés aux tokenizers de divers modèles Jina Embeddings, comme décrit ci-dessous, et chaque fois, j'ai soustrait deux du nombre de tokens retournés.
tagAnglais
(jina-embeddings-v2-small-en et jina-embeddings-v2-base-en)
Pour calculer les moyennes, j'ai téléchargé deux corpus de texte anglais depuis Wortschatz Leipzig, une collection de corpus librement téléchargeables dans plusieurs langues et configurations hébergée par l'Université de Leipzig :
- Un corpus d'un million de phrases de données d'actualités en anglais de 2020 (
eng_news_2020_1M) - Un corpus d'un million de phrases de données de Wikipédia en anglais de 2016 (
eng_wikipedia_2016_1M)
Les deux peuvent être trouvés sur leur page de téléchargements en anglais.
Pour la diversité, j'ai également téléchargé la traduction Hapgood des Misérables de Victor Hugo depuis Project Gutenberg, et une copie de la version King James de la Bible, traduite en anglais en 1611.
Pour chacun des quatre textes, j'ai compté les mots en utilisant le segmenteur Unicode implémenté dans polyglot, puis compté les tokens créés par jina-embeddings-v2-small-en, en soustrayant deux tokens pour chaque requête de tokenization. Les résultats sont les suivants :
| Texte | Nombre de mots (Segmenteur Unicode) | Nombre de tokens (Jina Embeddings v2 pour l'anglais) | Ratio tokens/mots (à 3 décimales) |
|---|---|---|---|
eng_news_2020_1M | 22 825 712 | 25 270 581 | 1,107 |
eng_wikipedia_2016_1M | 24 243 607 | 26 813 877 | 1,106 |
les_miserables_en | 688 911 | 764 121 | 1,109 |
kjv_bible | 1 007 651 | 1 099 335 | 1,091 |
L'utilisation de chiffres précis ne signifie pas que c'est un résultat précis. Le fait que des documents de genres si différents aient tous entre 9 % et 11 % de tokens de plus que de mots indique que vous pouvez probablement vous attendre à environ 10 % de tokens de plus que de mots, selon le segmenteur Unicode. Les traitements de texte ne comptent souvent pas la ponctuation, alors que le segmenteur Unicode le fait, donc vous ne pouvez pas vous attendre à ce que les décomptes de mots des logiciels de bureautique correspondent nécessairement à ceci.
tagAllemand
(jina-embeddings-v2-base-de)
Pour l'allemand, j'ai téléchargé trois corpus depuis la page allemande de Wortschatz Leipzig :
deu_mixed-typical_2011_1M— Un million de phrases provenant d'un mélange équilibré de textes de différents genres, datant de 2011.deu_newscrawl-public_2019_1M— Un million de phrases de textes d'actualités de 2019.deu_wikipedia_2021_1M— Un million de phrases extraites de Wikipédia en allemand en 2021.
Et pour la diversité, j'ai également téléchargé les trois volumes du Capital de Karl Marx depuis les Archives de textes allemands.
J'ai ensuite suivi la même procédure que pour l'anglais :
| Texte | Nombre de mots (Segmenteur Unicode) | Nombre de tokens (Jina Embeddings v2 pour l'allemand et l'anglais) | Ratio tokens/mots (à 3 décimales) |
|---|---|---|---|
deu_mixed-typical_2011_1M | 7 924 024 | 9 772 652 | 1,234 |
deu_newscrawl-public_2019_1M | 17 949 120 | 21 711 555 | 1,210 |
deu_wikipedia_2021_1M | 17 999 482 | 22 654 901 | 1,259 |
marx_kapital | 784 336 | 1 011 377 | 1,289 |
Ces résultats ont une plus grande dispersion que le modèle anglais uniquement, mais suggèrent toujours que le texte allemand produira, en moyenne, 20 % à 30 % de tokens de plus que de mots.
Les textes anglais produisent plus de tokens avec le tokenizer allemand-anglais qu'avec celui uniquement anglais :
| Texte | Nombre de mots (Segmenteur Unicode) | Nombre de tokens (Jina Embeddings v2 pour l'allemand et l'anglais) | Ratio tokens/mots (à 3 décimales) |
|---|---|---|---|
eng_news_2020_1M | 24 243 607 | 27 758 535 | 1,145 |
eng_wikipedia_2016_1M | 22 825 712 | 25 566 921 | 1,120 |
Vous devriez vous attendre à avoir besoin de 12 % à 15 % de tokens de plus que de mots pour intégrer des textes anglais avec le modèle bilingue allemand/anglais plutôt qu'avec celui uniquement anglais.
tagChinois
(jina-embeddings-v2-base-zh)
Le chinois est généralement écrit sans espaces et n'avait pas de notion traditionnelle de "mots" avant le XXe siècle. Par conséquent, la taille d'un texte chinois est généralement mesurée en caractères (字数). Donc, au lieu d'utiliser le segmenteur Unicode, j'ai mesuré la longueur des textes chinois en supprimant tous les espaces puis en obtenant simplement la longueur en caractères.
J'ai téléchargé trois corpus depuis la page des corpus chinois de Wortschatz Leipzig :
zho_wikipedia_2018_1M— Un million de phrases de Wikipédia en chinois, extraites en 2018.zho_news_2007-2009_1M— Un million de phrases de sources d'actualités chinoises, collectées de 2007 à 2009.zho-trad_newscrawl_2011_1M— Un million de phrases de sources d'actualités qui utilisent exclusivement des caractères chinois traditionnels (繁體字).
De plus, pour plus de diversité, j'ai également utilisé L'Histoire véritable d'Ah Q (阿Q正傳), une nouvelle de Lu Xun (魯迅) écrite au début des années 1920. J'ai téléchargé la version en caractères traditionnels depuis Project Gutenberg.
| Texte | Nombre de caractères (字数) | Nombre de tokens (Jina Embeddings v2 pour le chinois et l'anglais) | Ratio tokens/caractères (à 3 décimales) |
|---|---|---|---|
zho_wikipedia_2018_1M | 45 116 182 | 29 193 028 | 0,647 |
zho_news_2007-2009_1M | 44 295 314 | 28 108 090 | 0,635 |
zho-trad_newscrawl_2011_1M | 54 585 819 | 40 290 982 | 0,738 |
Ah_Q | 41 268 | 25 346 | 0,614 |
Cette variation dans les ratios tokens/caractères est inattendue, et particulièrement la valeur aberrante pour le corpus en caractères traditionnels mérite une enquête plus approfondie. Néanmoins, nous pouvons conclure que pour le chinois, vous devriez vous attendre à avoir besoin de moins de tokens qu'il n'y a de caractères dans votre texte. Selon votre contenu, vous pouvez vous attendre à avoir besoin de 25 % à 40 % de moins.
Les textes anglais dans Jina Embeddings v2 pour le chinois et l'anglais ont produit à peu près le même nombre de tokens que dans le modèle anglais uniquement :
| Text | Word count (Unicode Segmenter) | Token count (Jina Embeddings v2 for Chinese and English) | Ratio of tokens to words (to 3 decimal places) |
|---|---|---|---|
eng_news_2020_1M | 24 243 607 | 26 890 176 | 1,109 |
eng_wikipedia_2016_1M | 22 825 712 | 25 060 352 | 1,097 |
tagPrendre les tokens au sérieux
Les tokens sont une structure importante pour les modèles de langage d'IA, et la recherche se poursuit dans ce domaine.
L'un des domaines où les modèles d'IA se sont révélés révolutionnaires est la découverte qu'ils sont très robustes face aux données bruitées. Même si un modèle particulier n'utilise pas la stratégie de tokenisation optimale, si le réseau est assez grand, dispose de suffisamment de données et est correctement entraîné, il peut apprendre à faire la bonne chose à partir d'entrées imparfaites.
Par conséquent, on consacre beaucoup moins d'efforts à l'amélioration de la tokenisation que dans d'autres domaines, mais cela pourrait changer.
En tant qu'utilisateur d'embeddings, qui les achète via une API comme Jina Embeddings, vous ne pouvez pas savoir précisément combien de tokens vous aurez besoin pour une tâche spécifique et devrez peut-être faire vos propres tests pour obtenir des chiffres solides. Mais les estimations fournies ici — environ 110 % du nombre de mots pour l'anglais, environ 125 % du nombre de mots pour l'allemand, et environ 70 % du nombre de caractères pour le chinois — devraient être suffisantes pour une budgétisation de base.
