


La recherche multimodale, qui combine texte et images dans une expérience de recherche transparente, a gagné en popularité grâce à des modèles comme CLIP d'OpenAI. Ces modèles comblent efficacement le fossé entre les données visuelles et textuelles, permettant de relier les images aux textes pertinents et vice versa.
Bien que CLIP et les modèles similaires soient puissants, ils présentent des limitations notables, particulièrement lors du traitement de textes plus longs ou de relations textuelles complexes. C'est là qu'intervient jina-clip-v1.
Conçu pour répondre à ces défis, jina-clip-v1 offre une meilleure compréhension du texte tout en maintenant de solides capacités d'association texte-image. Il fournit une solution plus rationalisée pour les applications utilisant les deux modalités, simplifiant le processus de recherche et éliminant la nécessité de jongler avec des modèles séparés pour le texte et les images.
Dans cet article, nous explorerons ce que jina-clip-v1 apporte aux applications de recherche multimodale, en présentant des expériences qui démontrent comment il améliore à la fois la précision et la variété des résultats grâce aux embeddings intégrés de texte et d'image.
tagQu'est-ce que CLIP ?
CLIP (Contrastive Language–Image Pretraining) est une architecture de modèle d'IA développée par OpenAI qui relie texte et images en apprenant des représentations conjointes. CLIP est essentiellement un modèle de texte et un modèle d'image soudés ensemble — il transforme les deux types d'entrées en un espace d'embedding partagé, où les textes et images similaires sont positionnés à proximité. CLIP a été entraîné sur un vaste ensemble de données de paires texte-image, lui permettant de comprendre la relation entre le contenu visuel et textuel. Cela lui permet de bien généraliser à travers différents domaines, le rendant très efficace dans les scénarios d'apprentissage zero-shot, comme la génération de légendes ou la recherche d'images.
Depuis la sortie de CLIP, d'autres modèles comme SigLiP, LiT, et EvaCLIP ont développé ses fondations, améliorant des aspects tels que l'efficacité de l'entraînement, le passage à l'échelle et la compréhension multimodale. Ces modèles utilisent souvent des ensembles de données plus volumineux, des architectures améliorées et des techniques d'entraînement plus sophistiquées pour repousser les limites de l'alignement texte-image, faisant progresser davantage le domaine des modèles image-langage.
Bien que CLIP puisse fonctionner avec du texte seul, il présente des limitations importantes. Premièrement, il a été entraîné uniquement sur de courtes légendes, pas sur des textes longs, ne gérant qu'un maximum d'environ 77 mots. Deuxièmement, CLIP excelle dans la connexion du texte aux images mais peine à comparer du texte avec d'autre texte, comme reconnaître que les chaînes a crimson fruit et a red apple peuvent faire référence à la même chose. C'est là que les modèles de texte spécialisés, comme jina-embeddings-v3, brillent.
Ces limitations compliquent les tâches de recherche impliquant à la fois du texte et des images, par exemple, une boutique en ligne "shop the look" où un utilisateur peut rechercher des produits de mode en utilisant soit une chaîne de texte, soit une image. Lors de l'indexation de vos produits, vous devez traiter chacun plusieurs fois - une fois pour l'image, une fois pour le texte, et une fois de plus avec un modèle spécifique au texte. De même, lorsqu'un utilisateur recherche un produit, votre système doit effectuer au moins deux recherches pour trouver à la fois les cibles textuelles et visuelles :
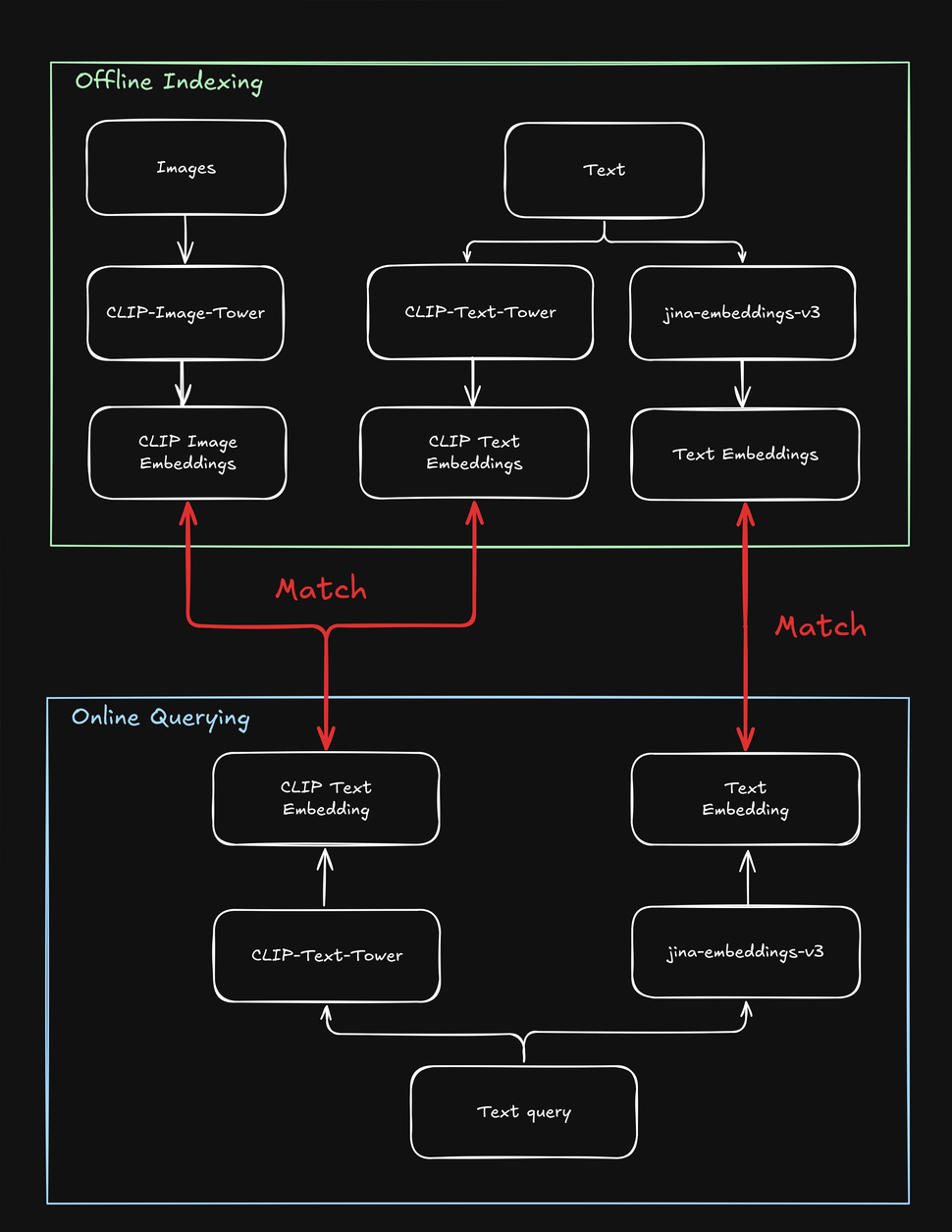
tagComment jina-clip-v1 résout les limitations de CLIP
Pour surmonter les limitations de CLIP, nous avons créé jina-clip-v1 pour comprendre des textes plus longs et faire correspondre plus efficacement les requêtes textuelles aux textes et aux images. Qu'est-ce qui rend jina-clip-v1 si spécial ? Tout d'abord, il utilise un modèle de compréhension du texte plus intelligent (JinaBERT), l'aidant à comprendre des textes plus longs et plus complexes (comme des descriptions de produits), pas seulement de courtes légendes (comme des noms de produits). Deuxièmement, nous avons entraîné jina-clip-v1 pour être performant sur deux aspects simultanément : faire correspondre le texte aux images et le texte à d'autres textes.
Avec OpenAI CLIP, ce n'est pas le cas : pour l'indexation et la recherche, vous devez invoquer deux modèles (CLIP pour les images et les textes courts comme les légendes, un autre embedding de texte pour les textes plus longs comme les descriptions). Non seulement cela ajoute une surcharge, mais cela ralentit la recherche, une opération qui devrait être très rapide. jina-clip-v1 fait tout cela dans un seul modèle, sans sacrifier la vitesse :

Cette approche unifiée ouvre de nouvelles possibilités qui étaient difficiles avec les modèles précédents, remodelant potentiellement notre approche de la recherche. Dans cet article, nous avons mené deux expériences :
- Améliorer les résultats de recherche en combinant la recherche de texte et d'images : Pouvons-nous combiner ce que jina-clip-v1 comprend du texte avec ce qu'il comprend des images ? Que se passe-t-il lorsque nous mélangeons ces deux types de compréhension ? L'ajout d'informations visuelles modifie-t-il nos résultats de recherche ? En bref, pouvons-nous obtenir de meilleurs résultats si nous recherchons avec du texte et des images simultanément ?
- Utiliser les images pour diversifier les résultats de recherche : La plupart des moteurs de recherche maximisent les correspondances textuelles. Mais pouvons-nous utiliser la compréhension des images de jina-clip-v1 comme un "mélange visuel" ? Au lieu de montrer uniquement les résultats les plus pertinents, nous pourrions inclure des résultats visuellement diversifiés. Il ne s'agit pas de trouver plus de résultats liés, mais de montrer une plus grande variété de perspectives, même si elles sont moins étroitement liées. Ce faisant, nous pourrions découvrir des aspects d'un sujet auxquels nous n'avions pas pensé auparavant. Par exemple, dans le contexte de la recherche de mode, si un utilisateur recherche "robe de cocktail multicolore", veut-il que les premiers résultats se ressemblent tous (c'est-à-dire des correspondances très proches), ou une plus grande variété parmi laquelle choisir (via le mélange visuel) ?
Ces deux approches sont précieuses dans une variété de cas d'utilisation où les utilisateurs peuvent rechercher avec du texte ou des images, comme dans le e-commerce, les médias, l'art et le design, l'imagerie médicale, et au-delà.
tagMoyenner les embeddings de texte et d'image pour une performance supérieure à la moyenne
Lorsqu'un utilisateur soumet une requête (généralement sous forme de chaîne de texte), nous pouvons utiliser la tour de texte de jina-clip-v1 pour encoder la requête en un embedding de texte. La force de jina-clip-v1 réside dans sa capacité à comprendre à la fois le texte et les images en alignant les signaux texte-à-texte et texte-à-image dans le même espace sémantique.
Pouvons-nous améliorer les résultats de la recherche si nous combinons les embeddings pré-indexés de texte et d'image de chaque produit en les moyennant ?
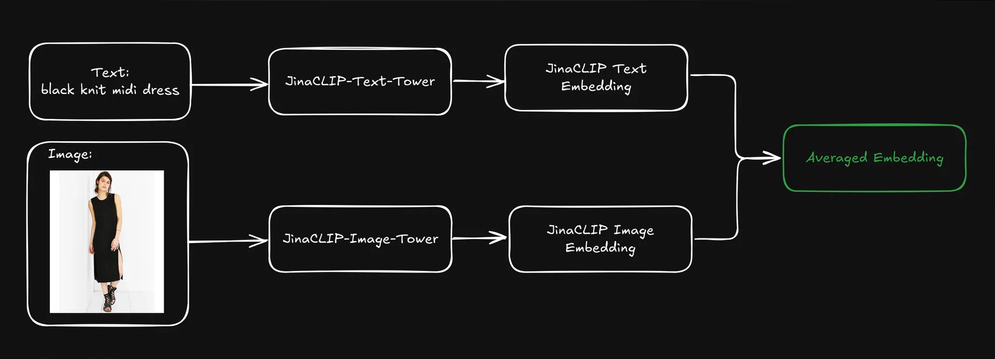
Cela crée une représentation unique qui inclut à la fois les informations textuelles (par exemple, la description du produit) et visuelles (par exemple, l'image du produit). Nous pouvons ensuite utiliser l'embedding de la requête textuelle pour rechercher dans ces représentations mélangées. Comment cela affecte-t-il nos résultats de recherche ?
Pour le découvrir, nous avons utilisé le jeu de données Fashion200k, un ensemble de données à grande échelle spécifiquement créé pour les tâches liées à la recherche d'images de mode et à la compréhension cross-modale. Il se compose de plus de 200 000 images d'articles de mode, tels que des vêtements, des chaussures et des accessoires, accompagnées des descriptions de produits et métadonnées correspondantes.
 xthan
xthanNous avons ensuite catégorisé chaque article dans une catégorie générale (par exemple, dress) et une catégorie plus précise (comme knit midi dress).
tagAnalyse de trois méthodes de recherche
Pour voir si la moyenne des embeddings de texte et d'image donnait de meilleurs résultats de recherche, nous avons expérimenté trois types de recherche, chacune utilisant une chaîne de texte (par exemple red dress) comme requête :
- Requête vers Description utilisant les embeddings de texte : Recherche dans les descriptions de produits basée sur les embeddings de texte.
- Requête vers Image utilisant la recherche cross-modal : Recherche dans les images de produits basée sur les embeddings d'images.
- Requête vers Embedding Moyen : Recherche dans les embeddings moyens des descriptions et des images de produits.
Nous avons d'abord indexé l'ensemble du jeu de données, puis généré aléatoirement 1 000 requêtes pour évaluer les performances. Nous avons encodé chaque requête en un embedding de texte et effectué la correspondance séparément, selon les méthodes décrites ci-dessus. Nous avons mesuré la précision en fonction de la correspondance entre les catégories des produits retournés et la requête d'entrée.
Lorsque nous avons utilisé la requête multicolor henley t-shirt dress, la recherche Requête vers Description a obtenu la meilleure précision top-5, mais les trois dernières robes classées étaient visuellement identiques. C'est moins qu'idéal, car une recherche efficace devrait équilibrer pertinence et diversité pour mieux capter l'attention de l'utilisateur.

La recherche cross-modal Requête vers Image a utilisé la même requête et a adopté l'approche opposée, présentant une collection très diverse de robes. Bien qu'elle ait correspondu à deux résultats sur cinq avec la bonne catégorie générale, aucun ne correspondait à la catégorie précise.

La recherche avec les embeddings moyens de texte et d'image a donné le meilleur résultat : les cinq résultats correspondaient à la catégorie générale, et deux sur cinq correspondaient à la catégorie précise. De plus, les articles visuellement dupliqués ont été éliminés, offrant une sélection plus variée. L'utilisation des embeddings de texte pour rechercher dans les embeddings moyens de texte et d'image semble maintenir la qualité de la recherche tout en incorporant des indices visuels, conduisant à des résultats plus diversifiés et équilibrés.

tagMonter en échelle : Évaluation avec plus de requêtes
Pour voir si cela fonctionnerait à plus grande échelle, nous avons poursuivi l'expérience sur d'autres catégories générales et précises. Nous avons effectué plusieurs itérations, récupérant un nombre différent de résultats (« valeurs k ») à chaque fois.
Pour les catégories générales comme précises, la Requête vers Embedding Moyen a constamment obtenu la plus haute précision pour toutes les valeurs k (10, 20, 50, 100). Cela montre que la combinaison des embeddings de texte et d'image fournit les résultats les plus précis pour retrouver les articles pertinents, que la catégorie soit générale ou spécifique :

| k | Type de recherche | Précision catégorie générale (similarité cosinus) | Précision catégorie fine (similarité cosinus) |
|---|---|---|---|
| 10 | Requête vers Description | 0.9026 | 0.2314 |
| 10 | Requête vers Image | 0.7614 | 0.2037 |
| 10 | Requête vers Embedding Moyen | 0.9230 | 0.2711 |
| 20 | Requête vers Description | 0.9150 | 0.2316 |
| 20 | Requête vers Image | 0.7523 | 0.1964 |
| 20 | Requête vers Embedding Moyen | 0.9229 | 0.2631 |
| 50 | Requête vers Description | 0.9134 | 0.2254 |
| 50 | Requête vers Image | 0.7418 | 0.1750 |
| 50 | Requête vers Embedding Moyen | 0.9226 | 0.2390 |
| 100 | Requête vers Description | 0.9092 | 0.2139 |
| 100 | Requête vers Image | 0.7258 | 0.1675 |
| 100 | Requête vers Embedding Moyen | 0.9150 | 0.2286 |
- La Requête vers Description utilisant les embeddings de texte a bien performé dans les deux catégories mais était légèrement en retrait par rapport à l'approche des embeddings moyens. Cela suggère que les descriptions textuelles seules fournissent des informations précieuses, particulièrement pour les catégories plus larges comme "robe", mais peuvent manquer de subtilité pour la classification précise (par exemple pour distinguer différents types de robes).
- La Requête vers Image utilisant la recherche cross-modal a constamment eu la plus faible précision dans les deux catégories. Cela suggère que si les caractéristiques visuelles peuvent aider à identifier les catégories générales, elles sont moins efficaces pour capturer les distinctions précises des articles de mode. La difficulté de distinguer les catégories précises uniquement à partir des caractéristiques visuelles est particulièrement évidente, où les différences visuelles peuvent être subtiles et nécessiter un contexte supplémentaire fourni par le texte.
- Globalement, la combinaison d'informations textuelles et visuelles (via les embeddings moyens) a atteint une haute précision dans les tâches de recherche de mode tant générales que précises. Les descriptions textuelles jouent un rôle important, particulièrement dans l'identification des catégories générales, tandis que les images seules sont moins efficaces dans les deux cas.
Dans l'ensemble, la précision était beaucoup plus élevée pour les catégories générales par rapport aux catégories précises, principalement parce que les articles des catégories générales (par exemple dress) sont plus représentés dans le jeu de données que les catégories précises (par exemple henley dress), simplement parce que ces dernières sont des sous-ensembles des premières. Par nature, une catégorie générale est plus facile à généraliser qu'une catégorie précise. En dehors de l'exemple de la mode, il est simple d'identifier qu'un objet est, en général, un oiseau. C'est beaucoup plus difficile de l'identifier comme un Paradisier superbe de Vogelkop.
Il est également à noter que l'information dans une requête textuelle correspond plus facilement à d'autres textes (comme les noms ou descriptions de produits) qu'aux caractéristiques visuelles. Par conséquent, si un texte est utilisé comme entrée, les textes sont une sortie plus probable que les images. Nous obtenons les meilleurs résultats en combinant à la fois les images et le texte (via la moyenne des embeddings) dans notre index.
tagRécupérer les résultats avec le texte ; les diversifier avec les images
Dans la section précédente, nous avons abordé le problème des résultats de recherche visuellement dupliqués. Dans la recherche, la précision seule n'est pas toujours suffisante. Dans de nombreux cas, maintenir une liste classée concise mais hautement pertinente et diverse est plus efficace, particulièrement lorsque la requête de l'utilisateur est ambiguë (par exemple, si un utilisateur rechercheblack jacket — s'agit-il d'une veste de motard noire, d'un blouson aviateur, d'un blazer ou d'un autre type ?).
Maintenant, au lieu d'utiliser la capacité multimodale de jina-clip-v1, utilisons les embeddings textuels de sa tour de texte pour la recherche textuelle initiale, puis appliquons les embeddings d'images de la tour d'images comme "reclasseur visuel" pour diversifier les résultats de recherche. Ceci est illustré dans le diagramme ci-dessous :
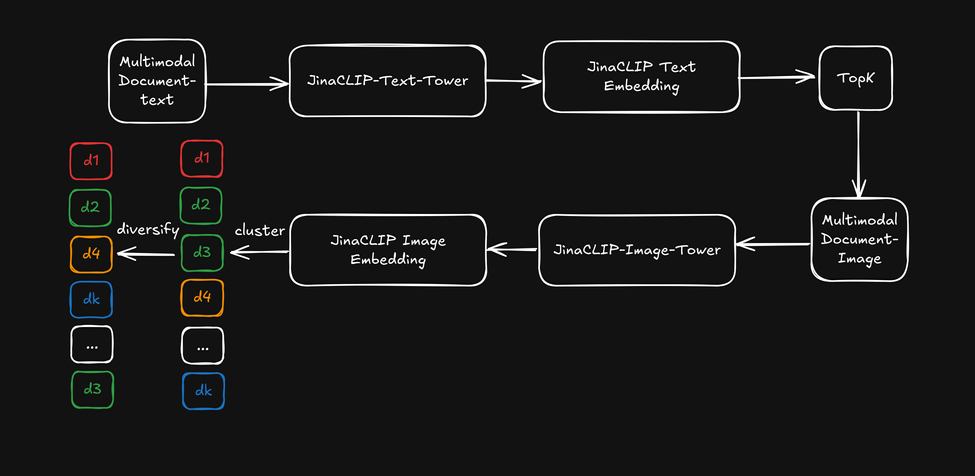
- D'abord, récupérer les k meilleurs résultats de recherche basés sur les embeddings textuels.
- Pour chaque meilleur résultat de recherche, extraire les caractéristiques visuelles et les regrouper en utilisant les embeddings d'images.
- Réorganiser les résultats de recherche en sélectionnant un élément de chaque cluster et présenter une liste diversifiée à l'utilisateur.
Après avoir récupéré les cinquante meilleurs résultats, nous avons appliqué un clustering k-means léger (k=5) aux embeddings d'images, puis sélectionné des éléments de chaque cluster. La précision des catégories est restée cohérente avec la performance Query-to-Description, car nous avons utilisé la requête vers la catégorie de produit comme métrique de mesure. Cependant, les résultats classés ont commencé à couvrir plus d'aspects différents (comme le tissu, la coupe et le motif) avec la diversification basée sur l'image. Pour référence, voici l'exemple de la robe t-shirt henley multicolore mentionné précédemment :

Voyons maintenant comment la diversification affecte les résultats de recherche en utilisant la recherche par embedding textuel combinée avec l'embedding d'image comme reclasseur de diversification :

Les résultats classés proviennent de la recherche textuelle mais commencent à couvrir des "aspects" plus diversifiés dans les cinq premiers exemples. Cela produit un effet similaire à la moyenne des embeddings sans réellement les moyenner.
Cependant, cela a un coût : nous devons appliquer une étape de clustering supplémentaire après avoir récupéré les k meilleurs résultats, ce qui ajoute quelques millisecondes supplémentaires, selon la taille du classement initial. De plus, la détermination de la valeur de k pour le clustering k-means implique une part de devinettes heuristiques. C'est le prix à payer pour une meilleure diversification des résultats !
tagConclusion
jina-clip-v1 comble efficacement l'écart entre la recherche textuelle et la recherche d'images en unifiant les deux modalités dans un modèle unique et efficace. Nos expériences ont montré que sa capacité à traiter des textes plus longs et plus complexes aux côtés des images offre des performances de recherche supérieures par rapport aux modèles traditionnels comme CLIP.
Nos tests ont couvert diverses méthodes, notamment la correspondance du texte avec les descriptions, les images et les embeddings moyennés. Les résultats ont systématiquement montré que la combinaison des embeddings textuels et d'images produisait les meilleurs résultats, améliorant à la fois la précision et la diversité des résultats de recherche. Nous avons également découvert que l'utilisation des embeddings d'images comme "reclasseur visuel" améliorait la variété des résultats tout en maintenant la pertinence.
Ces avancées ont des implications significatives pour les applications du monde réel où les utilisateurs recherchent en utilisant à la fois des descriptions textuelles et des images. En comprenant simultanément les deux types de données, jina-clip-v1 rationalise le processus de recherche, fournissant des résultats plus pertinents et permettant des recommandations de produits plus diversifiées. Cette capacité de recherche unifiée s'étend au-delà du e-commerce pour bénéficier à la gestion des actifs médias, aux bibliothèques numériques et à la curation de contenu visuel, facilitant la découverte de contenu pertinent à travers différents formats.
Bien que jina-clip-v1 ne prenne actuellement en charge que l'anglais, nous travaillons actuellement sur jina-clip-v2. Dans la lignée de jina-embeddings-v3 et jina-colbert-v2, cette nouvelle version sera un système de recherche multimodal multilingue à la pointe de la technologie prenant en charge 89 langues. Cette mise à niveau ouvrira de nouvelles possibilités pour les tâches de recherche et de récupération à travers différents marchés et industries, en faisant un modèle d'embedding plus puissant pour les applications mondiales dans le e-commerce, les médias et au-delà.





