




Dans les modèles multilingues, l'un des principaux défis est le "fossé linguistique" — un phénomène où les phrases ayant la même signification dans différentes langues ne sont pas aussi étroitement alignées ou regroupées qu'elles devraient l'être. Idéalement, un texte dans une langue et son équivalent dans une autre devraient avoir des représentations similaires — c'est-à-dire des embeddings très proches — permettant aux applications multilingues de fonctionner de manière identique sur des textes en différentes langues. Cependant, les modèles représentent souvent subtilement la langue d'un texte, créant un "fossé linguistique" qui conduit à des performances sous-optimales entre les langues.
Dans cet article, nous explorerons ce fossé linguistique et son impact sur les performances des modèles d'embedding de texte. Nous avons mené des expériences pour évaluer l'alignement sémantique des paraphrases dans une même langue et des traductions entre différentes paires de langues, en utilisant notre modèle jina-xlm-roberta et le dernier jina-embeddings-v3. Ces expériences révèlent à quel point les phrases ayant des significations similaires ou identiques se regroupent dans différentes conditions d'entraînement.

Nous avons également expérimenté des techniques d'entraînement pour améliorer l'alignement sémantique entre les langues, en particulier l'introduction de données multilingues parallèles pendant l'apprentissage contrastif. Dans cet article, nous partagerons nos observations et nos résultats.
tagL'entraînement des modèles multilingues crée et réduit le fossé linguistique
L'entraînement des modèles d'embedding de texte implique généralement un processus en plusieurs étapes avec deux parties principales :
- Masked Language Modeling (MLM) : Le pré-entraînement implique généralement de très grandes quantités de texte dans lesquelles certains tokens sont masqués aléatoirement. Le modèle est entraîné à prédire ces tokens masqués. Cette procédure enseigne au modèle les motifs de la ou des langues dans les données d'entraînement, y compris les dépendances de sélection entre les tokens qui peuvent découler de la syntaxe, de la sémantique lexicale et des contraintes pragmatiques du monde réel.
- Apprentissage contrastif : Après le pré-entraînement, le modèle est entraîné davantage avec des données organisées ou semi-organisées pour rapprocher les embeddings de textes sémantiquement similaires et (optionnellement) éloigner ceux qui sont dissemblables. Cet entraînement peut utiliser des paires, des triplets ou même des groupes de textes dont la similarité sémantique est déjà connue ou du moins estimée de manière fiable. Il peut comporter plusieurs sous-étapes et il existe diverses stratégies d'entraînement pour cette partie du processus, avec de nouvelles recherches publiées fréquemment et pas de consensus clair sur l'approche optimale.
Pour comprendre comment le fossé linguistique se crée et comment il peut être comblé, nous devons examiner le rôle des deux étapes.
tagPré-entraînement par masquage de langue
Une partie de la capacité multilingue des modèles d'embedding de texte est acquise pendant le pré-entraînement.
Les mots apparentés et empruntés permettent au modèle d'apprendre un certain alignement sémantique entre les langues à partir de grandes quantités de données textuelles. Par exemple, le mot anglais banana et le mot français banane (et l'allemand Banane) sont fréquents et suffisamment similaires dans leur orthographe pour qu'un modèle d'embedding puisse apprendre que les mots qui ressemblent à "banan-" ont des modèles de distribution similaires entre les langues. Il peut utiliser cette information pour apprendre, dans une certaine mesure, que d'autres mots qui ne se ressemblent pas entre les langues ont aussi des significations similaires, et même comprendre comment certaines structures grammaticales sont traduites.
Cependant, cela se produit sans entraînement explicite.
Nous avons testé le modèle jina-xlm-roberta, la base pré-entraînée de jina-embeddings-v3, pour voir comment il a appris les équivalences entre langues à partir du pré-entraînement par masquage de langue. Nous avons tracé des représentations de phrases bidimensionnelles UMAP d'un ensemble de phrases anglaises traduites en allemand, néerlandais, chinois simplifié et japonais. Les résultats sont dans la figure ci-dessous :
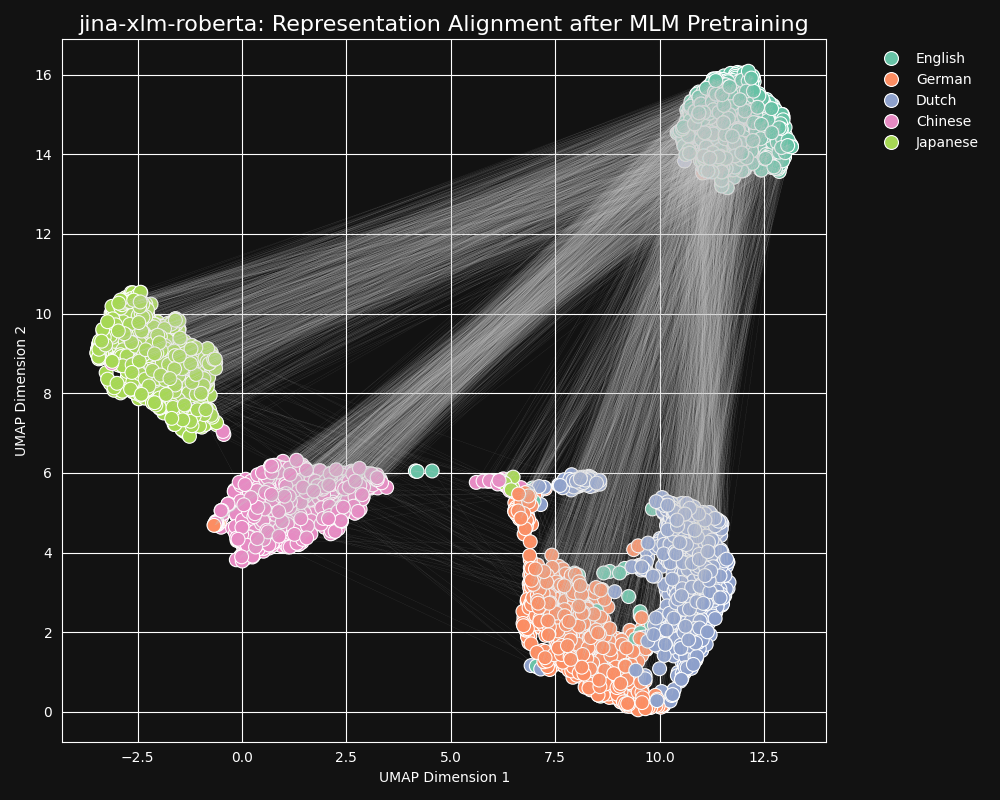
Ces phrases ont tendance à former des clusters spécifiques à chaque langue dans l'espace d'embedding de
jina-xlm-roberta, bien que vous puissiez voir quelques valeurs aberrantes dans cette projection qui peuvent être un effet secondaire de la projection bidimensionnelle.On peut voir que le pré-entraînement a très fortement regroupé les embeddings des phrases dans la même langue. Il s'agit d'une projection en deux dimensions d'une distribution dans un espace de dimension beaucoup plus élevée, il est donc toujours possible que, par exemple, une phrase allemande qui est une bonne traduction d'une phrase anglaise soit encore la phrase allemande dont l'embedding est le plus proche de l'embedding de sa source anglaise. Mais cela montre qu'un embedding d'une phrase anglaise est probablement plus proche d'une autre phrase anglaise que d'une phrase allemande sémantiquement identique ou presque identique.
Notez également comment l'allemand et le néerlandais forment des clusters beaucoup plus proches que les autres paires de langues. Ce n'est pas surprenant pour deux langues relativement proches. L'allemand et le néerlandais sont suffisamment similaires pour être parfois partiellement mutuellement compréhensibles.
Le japonais et le chinois semblent également plus proches l'un de l'autre que des autres langues. Bien qu'ils ne soient pas apparentés de la même manière, le japonais écrit utilise généralement des kanji (漢字), ou hànzì en chinois. Le japonais partage la plupart de ces caractères écrits avec le chinois, et les deux langues partagent de nombreux mots écrits avec un ou plusieurs kanji/hànzì ensemble. Du point de vue du MLM, c'est le même type de similarité visible qu'entre le néerlandais et l'allemand.
Nous pouvons voir ce "fossé linguistique" de manière plus simple en regardant seulement deux langues avec deux phrases chacune :

Puisque le MLM semble naturellement regrouper les textes par langue, "my dog is blue" et "my cat is red" sont regroupés ensemble, loin de leurs équivalents allemands. Contrairement au "fossé de modalité" discuté dans un article de blog précédent, nous pensons que cela provient des similarités et dissimilarités superficielles entre les langues : orthographes similaires, utilisation des mêmes séquences de caractères dans l'écriture, et possiblement des similarités dans la morphologie et la structure syntaxique — ordres des mots communs et façons communes de construire les mots.
En bref, quel que soit le degré d'apprentissage des équivalences entre langues lors du pré-entraînement MLM, ce n'est pas suffisant pour surmonter une forte tendance à regrouper les textes par langue. Cela laisse un grand fossé linguistique.
tagApprentissage contrastif
Idéalement, nous voulons qu'un modèle d'embedding soit indifférent à la langue et n'encode que les significations générales dans ses embeddings. Dans un tel modèle, nous ne verrions aucun regroupement par langue et n'aurions aucun fossé linguistique. Les phrases dans une langue devraient être très proches de bonnes traductions et éloignées d'autres phrases qui signifient autre chose, même dans la même langue, comme dans la figure ci-dessous :

Le pré-entraînement MLM n'accomplit pas cela, nous utilisons donc des techniques d'apprentissage contrastif supplémentaires pour améliorer la représentation sémantique des textes dans les embeddings.
L'apprentissage contrastif implique l'utilisation de paires de textes dont on sait qu'ils sont similaires ou différents en signification, et des triplets où une paire est connue pour être plus similaire que l'autre. Les poids sont ajustés pendant l'entraînement pour refléter cette relation connue entre les paires et triplets de textes.
Il y a 30 langues représentées dans notre jeu de données d'apprentissage contrastif, mais 97% des paires et triplets sont dans une seule langue, avec seulement 3% impliquant des paires ou triplets multilingues. Mais ces 3% suffisent à produire un résultat spectaculaire : les embeddings montrent très peu de regroupement par langue et les textes sémantiquement similaires produisent des embeddings proches quelle que soit leur langue, comme le montre la projection UMAP des embeddings de jina-embeddings-v3.
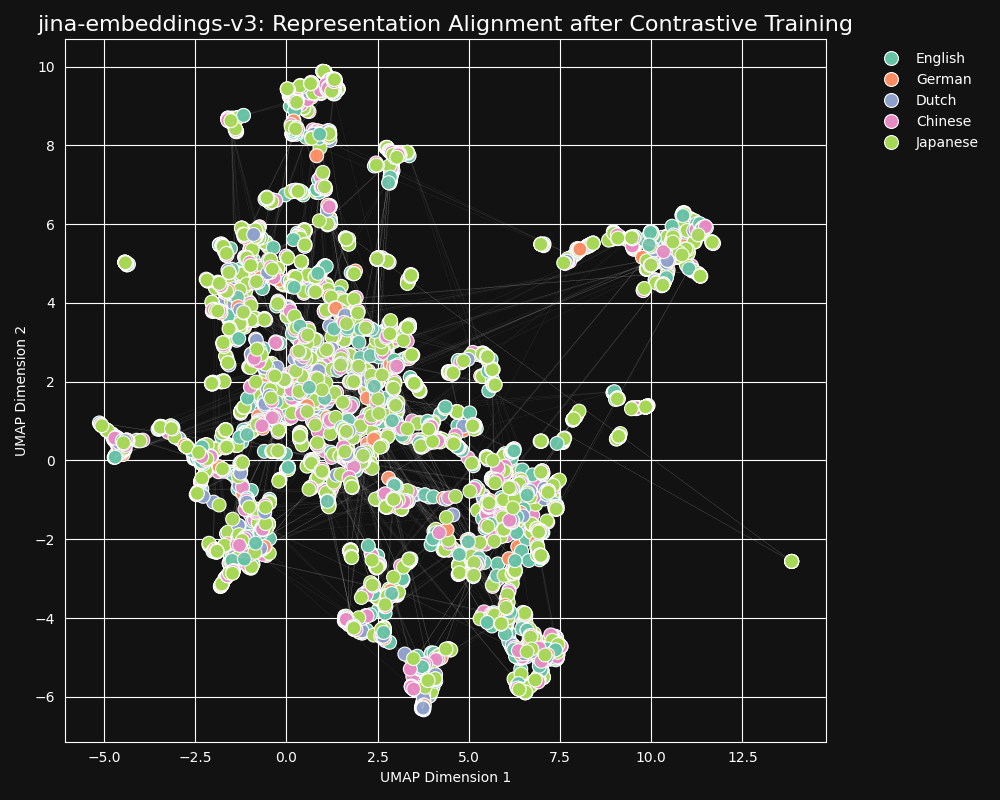
Pour confirmer cela, nous avons mesuré la Corrélation de Spearman des représentations générées par jina-xlm-roberta et jina-embeddings-v3 sur le jeu de données STS17.
Le tableau ci-dessous montre la Corrélation de Spearman entre les classements de similarité sémantique pour les textes traduits dans différentes langues. Nous prenons un ensemble de phrases en anglais puis mesurons la similarité de leurs embeddings avec l'embedding d'une phrase de référence spécifique et les trions du plus similaire au moins similaire. Ensuite, nous traduisons toutes ces phrases dans une autre langue et répétons le processus de classement. Dans un modèle d'embedding multilingue idéal, les deux listes ordonnées seraient identiques, et la Corrélation de Spearman serait de 1,0.
Le graphique et le tableau ci-dessous montrent nos résultats comparant l'anglais et les six autres langues du benchmark STS17, en utilisant à la fois jina-xlm-roberta et jina-embeddings-v3.
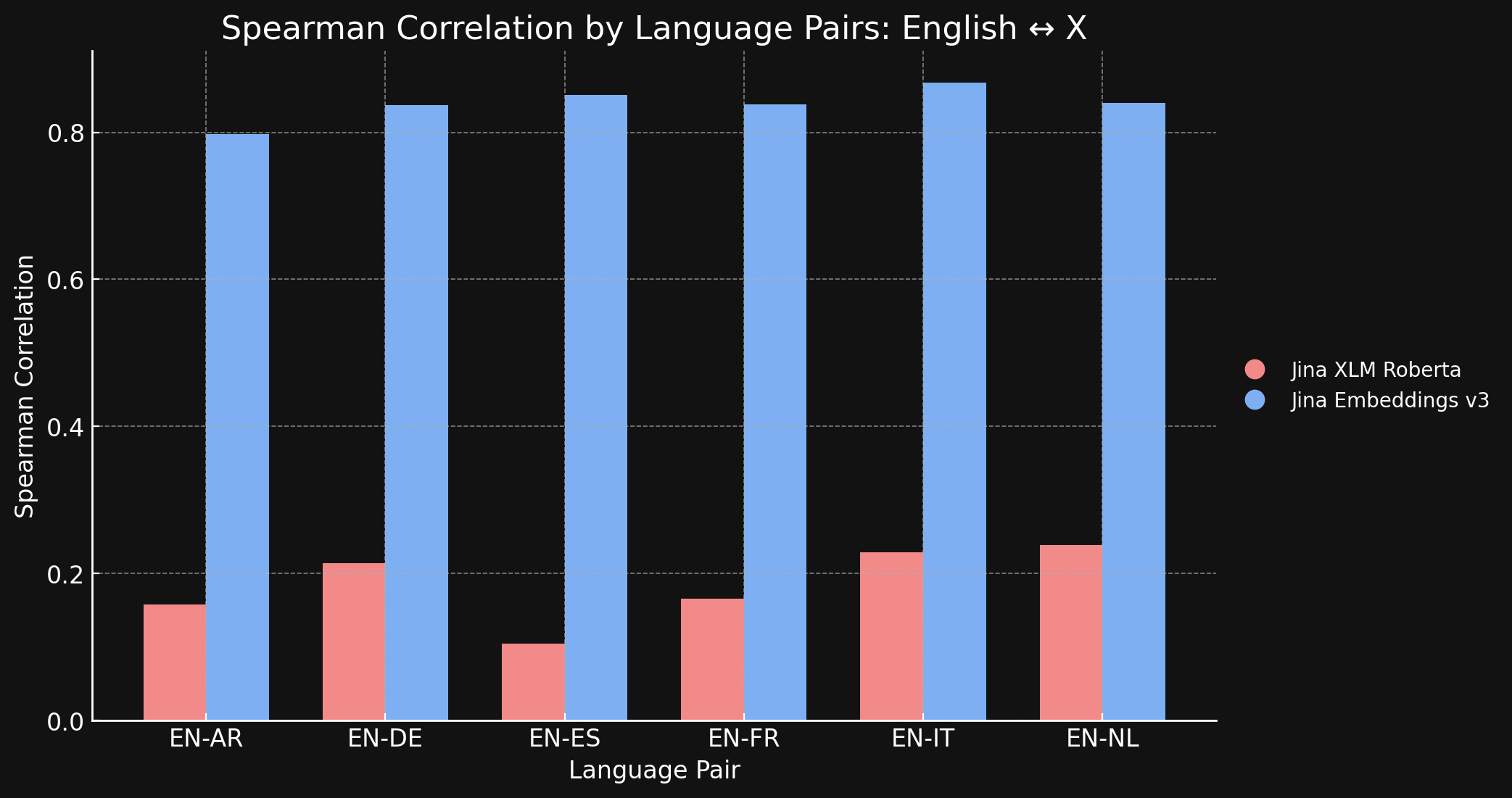
| Task | jina-xlm-roberta |
jina-embeddings-v3 |
|---|---|---|
| English ↔ Arabic | 0.1581 | 0.7977 |
| English ↔ German | 0.2136 | 0.8366 |
| English ↔ Spanish | 0.1049 | 0.8509 |
| English ↔ French | 0.1659 | 0.8378 |
| English ↔ Italian | 0.2293 | 0.8674 |
| English ↔ Dutch | 0.2387 | 0.8398 |
Vous pouvez voir ici l'énorme différence que fait l'apprentissage contrastif, comparé au pré-entraînement initial. Bien que n'ayant que 3 % de données multilingues dans son mix d'entraînement, le modèle jina-embeddings-v3 a suffisamment appris la sémantique multilingue pour pratiquement éliminer l'écart linguistique acquis lors du pré-entraînement.
tagL'anglais contre le monde : les autres langues peuvent-elles suivre en termes d'alignement ?
Nous avons entraîné jina-embeddings-v3 sur 89 langues, avec un accent particulier sur 30 langues écrites très largement utilisées. Malgré nos efforts pour construire un corpus d'entraînement multilingue à grande échelle, l'anglais représente encore près de la moitié des données que nous avons utilisées dans l'entraînement contrastif. Les autres langues, y compris les langues mondiales largement utilisées pour lesquelles un matériel textuel abondant est disponible, sont encore relativement sous-représentées par rapport à l'énormité des données anglaises dans l'ensemble d'entraînement.
Étant donné cette prédominance de l'anglais, les représentations en anglais sont-elles mieux alignées que celles des autres langues ? Pour explorer cela, nous avons mené une expérience complémentaire.
Nous avons construit un jeu de données, parallel-sentences, composé de 1 000 paires de textes en anglais, une "ancre" et un "positif", où le texte positif est logiquement impliqué par le texte ancre.

Par exemple, la première ligne du tableau ci-dessous. Ces phrases n'ont pas un sens identique, mais elles ont des significations compatibles. Elles décrivent de manière informative la même situation.
Nous avons ensuite traduit ces paires dans cinq langues en utilisant GPT-4o : allemand, néerlandais, chinois (simplifié), chinois (traditionnel) et japonais. Enfin, nous les avons inspectées manuellement pour garantir leur qualité.
| Language | Anchor | Positive |
|---|---|---|
| English | Two young girls are playing outside in a non-urban environment. | Two girls are playing outside. |
| German | Zwei junge Mädchen spielen draußen in einer nicht urbanen Umgebung. | Zwei Mädchen spielen draußen. |
| Dutch | Twee jonge meisjes spelen buiten in een niet-stedelijke omgeving. | Twee meisjes spelen buiten. |
| Chinese (Simplified) | 两个年轻女孩在非城市环境中玩耍。 | 两个女孩在外面玩。 |
| Chinese (Traditional) | 兩個年輕女孩在非城市環境中玩耍。 | 兩個女孩在外面玩。 |
| Japanese | 2人の若い女の子が都市環境ではない場所で遊んでいます。 | 二人の少女が外で遊んでいます。 |
Nous avons ensuite encodé chaque paire de textes avec jina-embeddings-v3 et calculé la similarité cosinus entre eux. La figure et le tableau ci-dessous montrent la distribution des scores de similarité cosinus pour chaque langue, et la similarité moyenne :
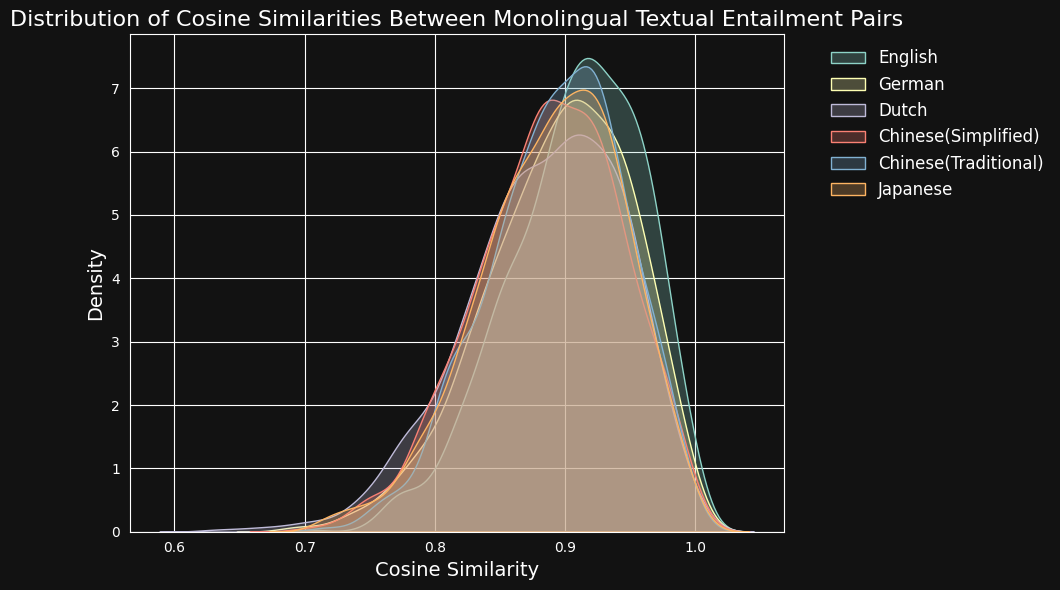
| Language | Average Cosine Similarity |
|---|---|
| English | 0.9078 |
| German | 0.8949 |
| Dutch | 0.8844 |
| Chinese (Simplified) | 0.8876 |
| Chinese (Traditional) | 0.8933 |
| Japanese | 0.8895 |
Malgré la prédominance de l'anglais dans les données d'entraînement, jina-embeddings-v3 reconnaît la similarité sémantique en allemand, néerlandais, japonais et dans les deux formes de chinois presque aussi bien qu'en anglais.
tagBriser les barrières linguistiques : l'alignement multilingue au-delà de l'anglais
Les études sur l'alignement des représentations entre langues portent généralement sur des paires de langues incluant l'anglais. Cette orientation pourrait, en théorie, masquer ce qui se passe réellement. Un modèle pourrait simplement optimiser pour représenter tout le plus près possible de son équivalent anglais, sans examiner si d'autres paires de langues sont correctement prises en charge.
Pour explorer cela, nous avons mené des expériences en utilisant le dataset parallel-sentences, en nous concentrant sur l'alignement multilingue au-delà des simples paires bilingues avec l'anglais.
Le tableau ci-dessous montre la distribution des similarités cosinus entre des textes équivalents dans différentes paires de langues — des textes qui sont des traductions d'une source anglaise commune. Idéalement, toutes les paires devraient avoir un cosinus de 1 — c'est-à-dire des embeddings sémantiques identiques. En pratique, cela ne pourrait jamais arriver, mais nous nous attendrions à ce qu'un bon modèle ait des valeurs cosinus très élevées pour les paires de traductions.
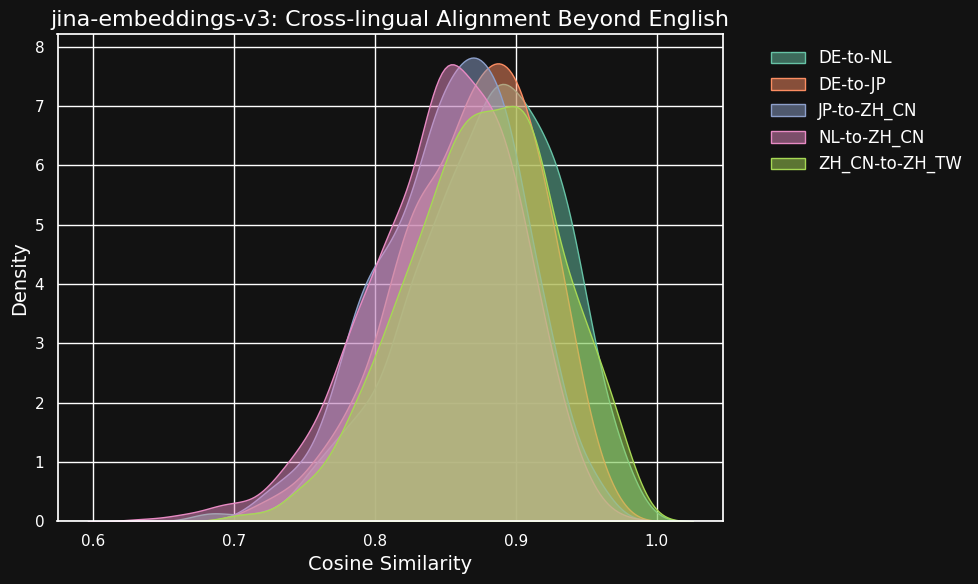
| Language Pair | Average Cosine Similarity |
|---|---|
| German ↔ Dutch | 0.8779 |
| German ↔ Japanese | 0.8664 |
| Chinese (Simplified) ↔ Japanese | 0.8534 |
| Dutch ↔ Chinese (Simplified) | 0.8479 |
| Chinese (Simplified) ↔ Chinese (Traditional) | 0.8758 |
Bien que les scores de similarité entre différentes langues soient légèrement inférieurs à ceux des textes compatibles dans la même langue, ils restent très élevés. La similarité cosinus des traductions néerlandais/allemand est presque aussi élevée qu'entre les textes compatibles en allemand.
Cela n'est peut-être pas surprenant car l'allemand et le néerlandais sont des langues très similaires. De même, les deux variétés de chinois testées ici ne sont pas vraiment deux langues différentes, mais plutôt des formes stylistiquement différentes de la même langue. Mais on peut voir que même des paires de langues très dissemblables comme le néerlandais et le chinois ou l'allemand et le japonais montrent encore une très forte similarité entre les textes sémantiquement équivalents.
Nous avons envisagé la possibilité que ces valeurs de similarité très élevées puissent être un effet secondaire de l'utilisation de ChatGPT comme traducteur. Pour le tester, nous avons téléchargé des transcriptions de conférences TED traduites par des humains en anglais et en allemand et vérifié si les phrases traduites alignées auraient la même corrélation élevée.
Le résultat était encore plus fort que pour nos données traduites par machine, comme vous pouvez le voir sur la figure ci-dessous.
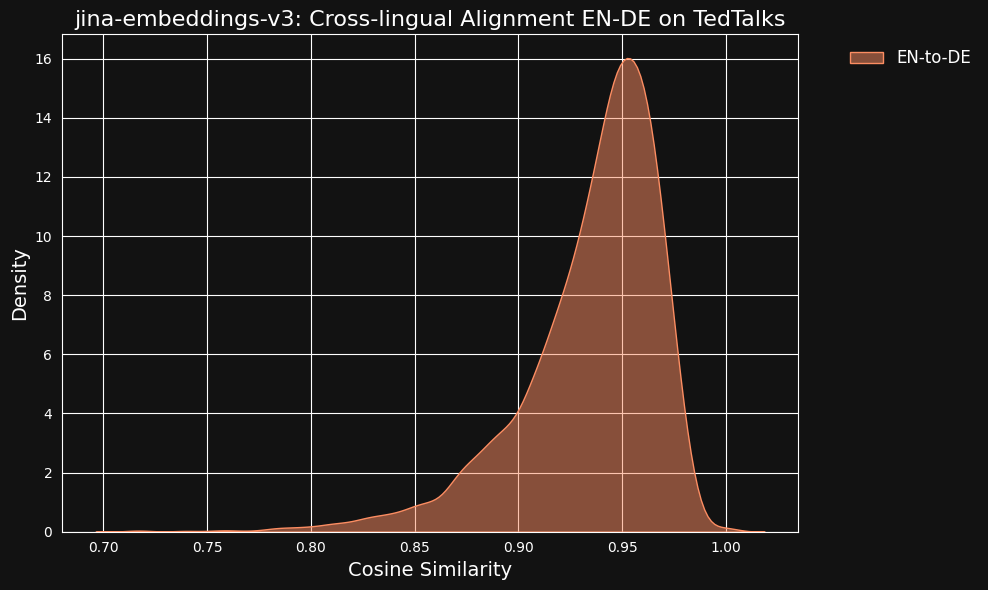
tagDans quelle mesure les données multilingues contribuent-elles à l'alignement multilingue ?
L'écart linguistique qui s'estompe et le haut niveau de performance multilingue semblent disproportionnés par rapport à la très petite partie des données d'entraînement qui était explicitement multilingue. Seuls 3 % des données d'entraînement contrastives enseignent spécifiquement au modèle comment faire des alignements entre les langues.
Nous avons donc fait un test pour voir si le multilingue apportait une contribution quelconque.
Réentraîner complètement jina-embeddings-v3 sans aucune donnée multilingue serait excessivement coûteux pour une petite expérience, nous avons donc téléchargé le modèle xlm-roberta-base de Hugging Face et l'avons entraîné davantage avec l'apprentissage contrastif, en utilisant un sous-ensemble des données que nous avons utilisées pour entraîner jina-embeddings-v3. Nous avons spécifiquement ajusté la quantité de données multilingues pour tester deux cas : un sans données multilingues, et un où 20 % des paires étaient multilingues. Vous pouvez voir les méta-paramètres d'entraînement dans le tableau ci-dessous :
| Backbone | % Cross-Language | Learning Rate | Loss Function | Temperature |
xlm-roberta-base without X-language data | 0% | 5e-4 | InfoNCE | 0.05 |
xlm-roberta-base with X-language data | 20% | 5e-4 | InfoNCE | 0.05 |
Nous avons ensuite évalué les performances multilingues des deux modèles en utilisant les benchmarks STS17 et STS22 de MTEB et la corrélation de Spearman. Nous présentons les résultats ci-dessous :
tagSTS17
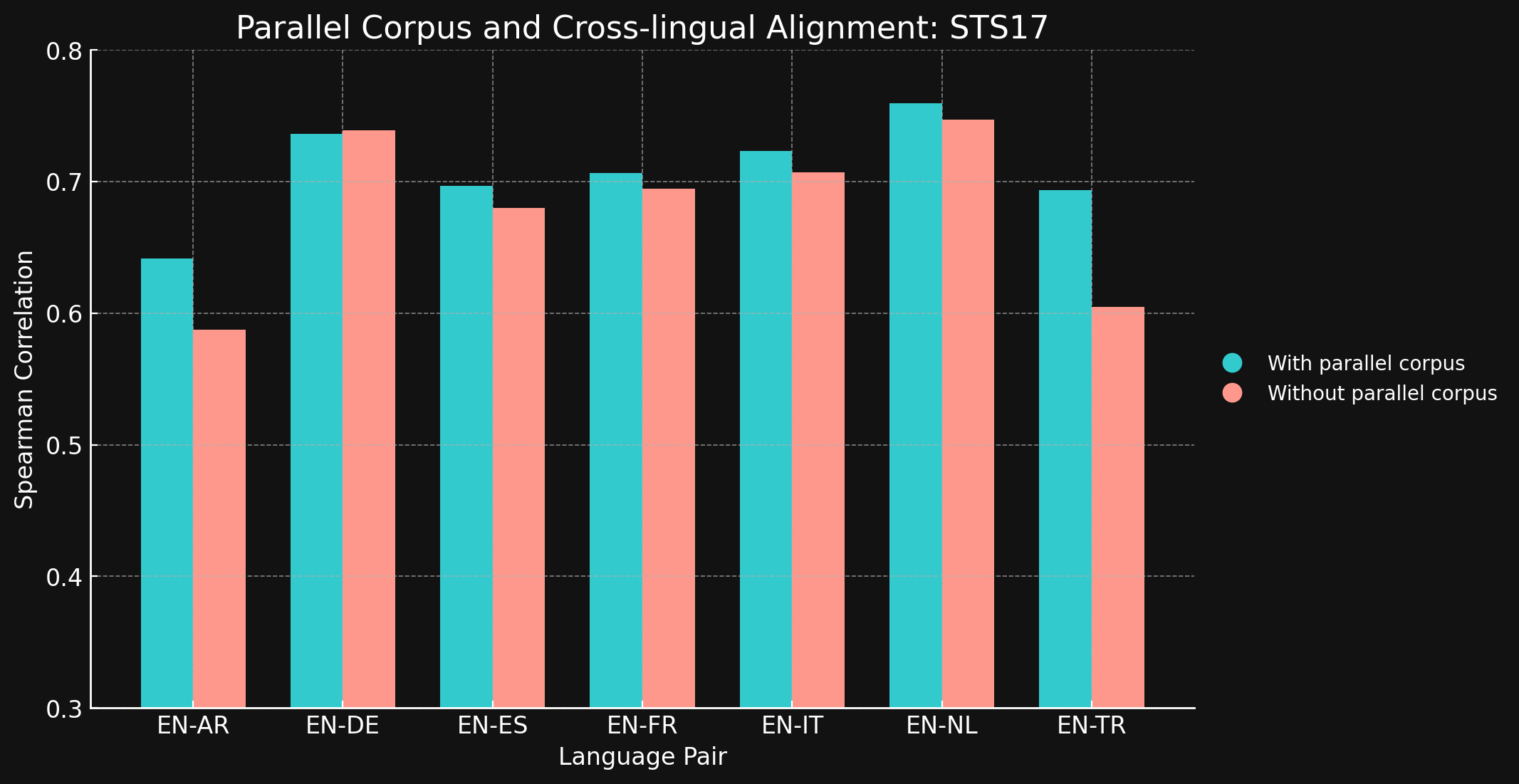
| Language Pair | With parallel corpora | Without parallel corpora |
| English ↔ Arabic | 0.6418 | 0.5875 |
| English ↔ German | 0.7364 | 0.7390 |
| English ↔ Spanish | 0.6968 | 0.6799 |
| English ↔ French | 0.7066 | 0.6944 |
| English ↔ Italian | 0.7232 | 0.7070 |
| English ↔ Dutch | 0.7597 | 0.7468 |
| English ↔ Turkish | 0.6933 | 0.6050 |
tagSTS22
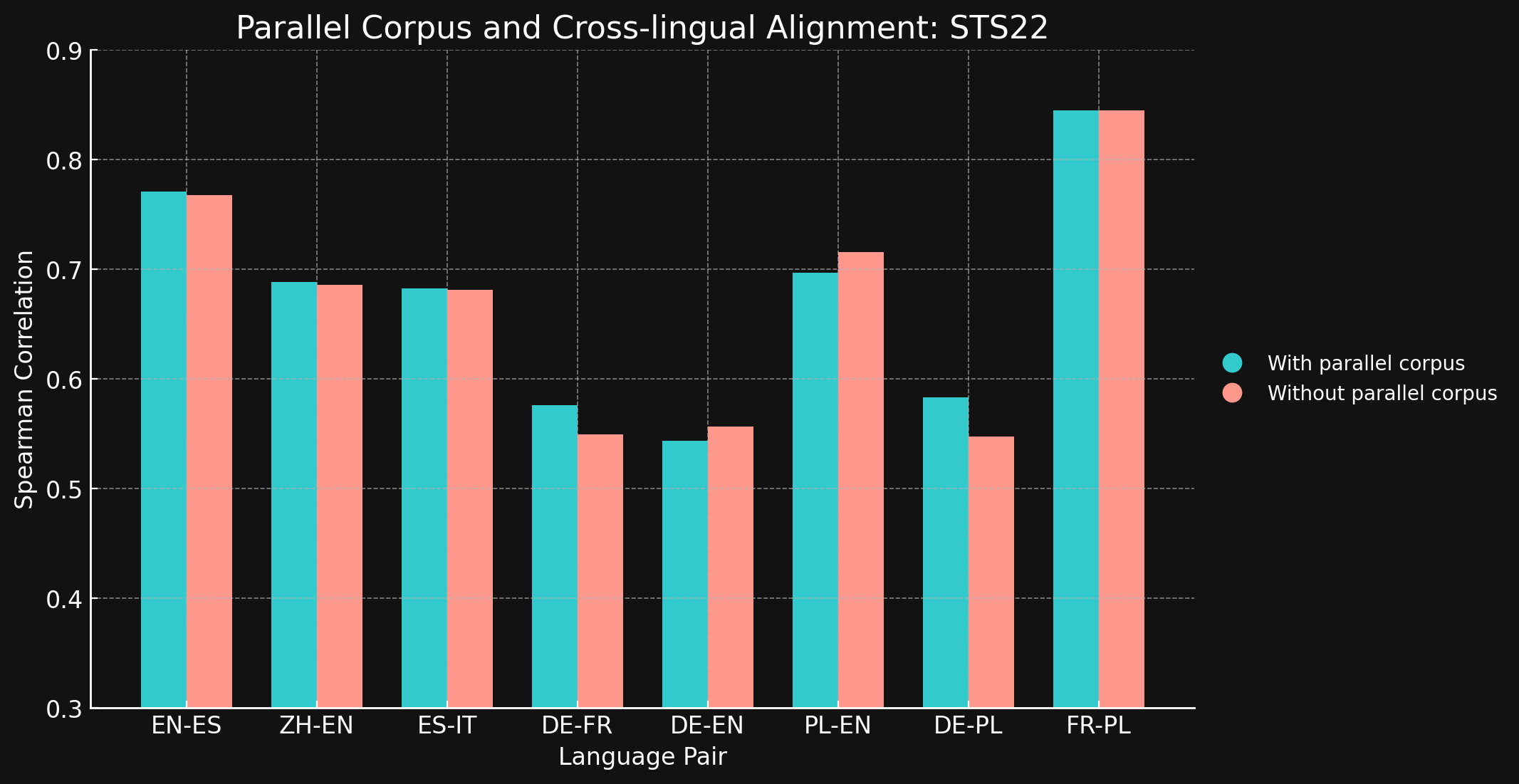
| Paire de langues | Avec corpus parallèles | Sans corpus parallèles |
| English ↔ Spanish | 0.7710 | 0.7675 |
| Simplified Chinese ↔ English | 0.6885 | 0.6860 |
| Spanish ↔ Italian | 0.6829 | 0.6814 |
| German ↔ French | 0.5763 | 0.5496 |
| German ↔ English | 0.5439 | 0.5566 |
| Polish ↔ English | 0.6966 | 0.7156 |
| German ↔ English | 0.5832 | 0.5478 |
| French ↔ Polish | 0.8451 | 0.8451 |
Nous avons été surpris de constater que pour la plupart des paires de langues testées, les données d'entraînement interlingues n'ont apporté que peu ou pas d'amélioration. Il est difficile d'être certain que cela resterait vrai pour des modèles complètement entraînés avec des jeux de données plus importants, mais cela suggère certainement que l'entraînement explicite entre langues n'apporte pas grand-chose.
Cependant, notez que STS17 inclut des paires anglais/arabe et anglais/turc. Ce sont deux langues beaucoup moins bien représentées dans nos données d'entraînement. Le modèle XML-RoBERTa que nous avons utilisé a été pré-entraîné avec des données qui ne contenaient que 2,25 % d'arabe et 2,32 % de turc, bien moins que pour les autres langues testées. Le petit jeu de données d'apprentissage contrastif que nous avons utilisé dans cette expérience ne contenait que 1,7 % d'arabe et 1,8 % de turc.
Ces deux paires de langues sont les seules testées où l'entraînement avec des données interlingues a fait une différence notable. Nous pensons que les données interlingues explicites sont plus efficaces pour les langues qui sont moins bien représentées dans les données d'entraînement, mais nous devons explorer davantage ce domaine avant de tirer une conclusion. Le rôle et l'efficacité des données interlingues dans l'apprentissage contrastif est un domaine où Jina AI mène des recherches actives.
tagConclusion
Les méthodes conventionnelles de pré-entraînement linguistique, comme le Masked Language Modeling, laissent un « écart linguistique », où des textes sémantiquement similaires dans différentes langues ne s'alignent pas aussi étroitement qu'ils le devraient. Nous avons montré que le régime d'apprentissage contrastif de Jina Embeddings est très efficace pour réduire, voire éliminer cet écart.
Les raisons de cette efficacité ne sont pas entièrement claires. Nous utilisons explicitement des paires de textes interlingues dans l'entraînement contrastif, mais seulement en très petites quantités, et il n'est pas clair quel rôle elles jouent réellement pour assurer des résultats interlingues de haute qualité. Nos tentatives de démontrer un effet clair dans des conditions plus contrôlées n'ont pas produit de résultat sans ambiguïté.
Cependant, il est clair que jina-embeddings-v3 a surmonté l'écart linguistique du pré-entraînement, en faisant un outil puissant pour les applications multilingues. Il est prêt à être utilisé pour toute tâche nécessitant des performances fortes et identiques dans plusieurs langues.
Vous pouvez utiliser jina-embeddings-v3 via notre API Embeddings (avec un million de tokens gratuits) ou via AWS ou Azure. Si vous souhaitez l'utiliser en dehors de ces plateformes ou sur site dans votre entreprise, gardez simplement à l'esprit qu'il est sous licence CC BY-NC 4.0. Contactez-nous si vous êtes intéressé par une utilisation commerciale.
