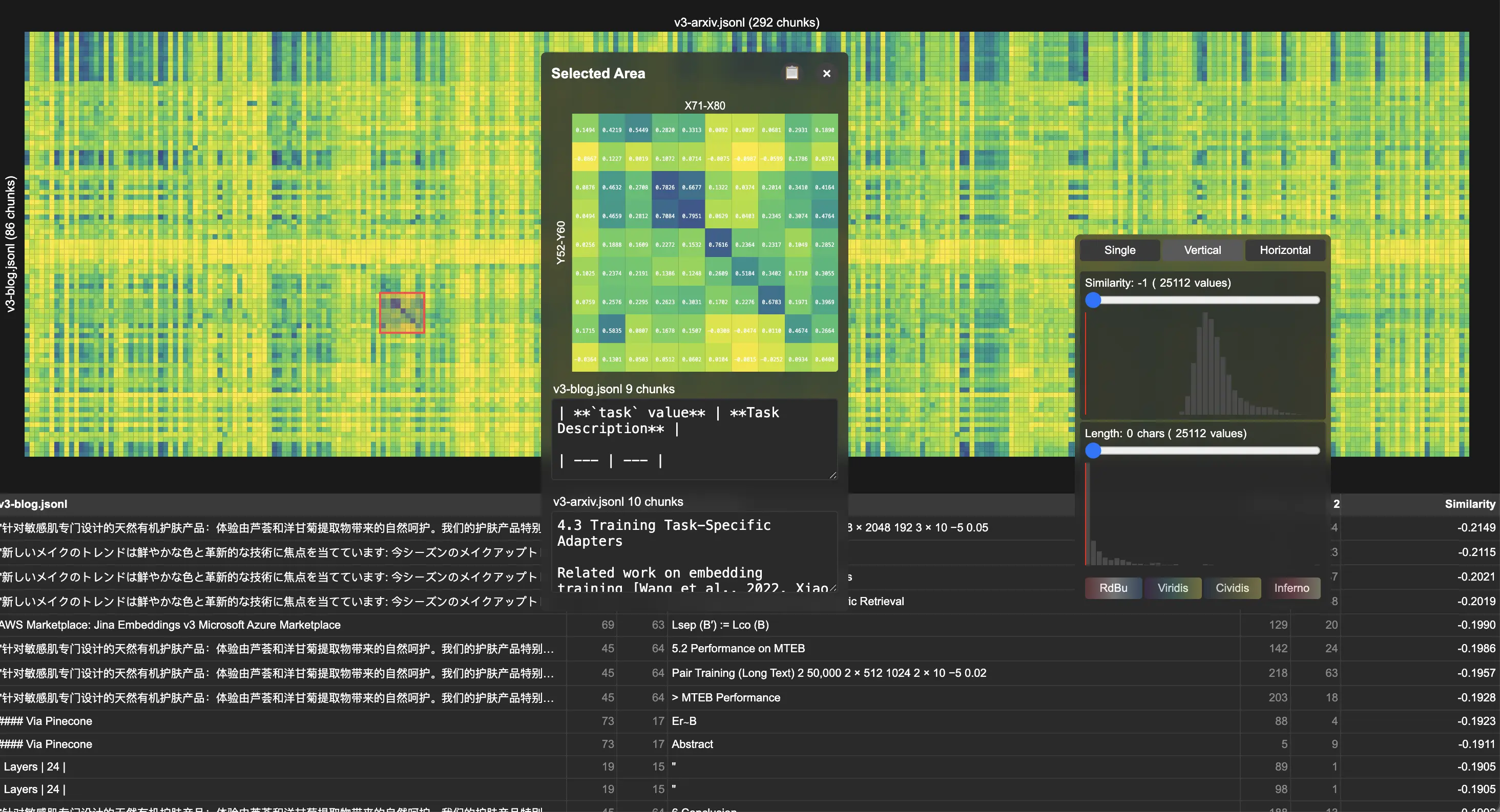


L'une des questions intéressantes que les gens nous posent est la suivante : "Comment faites-vous pour vérifier la qualité de vos vecteurs modèles (Embeddings) ?" Bien sûr, il existe MTEB pour une évaluation sérieuse et quantitative sur des benchmarks publics, mais que faites-vous pour les problèmes de domaine ouvert ou les nouveaux problèmes ? Aujourd'hui, nous souhaitons partager un petit outil interne que nous utilisons pour le débogage et la visualisation. Vous pouvez l'appeler notre boîte à outils de test de qualité. Nous l'appelons Correlations, et il est open source sur GitHub.
tagConception
Correlations génère des cartes thermiques interactives où chaque cellule affiche la similarité cosinus entre deux éléments, qu'il s'agisse de morceaux provenant de collections de documents identiques ou différentes, de modalités, d'hyperparamètres ou de modèles. Il prend en charge plusieurs interactions :
- Inspection au survol : Texte/image original et scores de similarité pour les paires de cellules individuelles
- Sélection de région : Sélection interactive de zone pour une analyse ciblée des schémas de similarité
- Filtrage par seuil : Filtres de score de similarité et de longueur de texte pour réduire le bruit
L'outil fonctionne via un pipeline en deux étapes :
npm run embed: Utilisation de l'API Jina Embeddings avec des stratégies de segmentation configurables (nouvelle ligne, ponctuation, basé sur les caractères ou modèles regex)npm run corr: Interface utilisateur basée sur navigateur servant des cartes thermiques de corrélation avec interactivité en temps réel
Pour commencer :
npm install
export JINA_API_KEY=your_jina_key_here
npm run embed -- https://jina.ai/news/jina-embeddings-v3-a-frontier-multilingual-embedding-model -o v3-blog.jsonl -t retrieval.query
npm run embed -- https://arxiv.org/pdf/2409.10173 -o v3-arxiv.jsonl -t retrieval.passage
npm run corr -- v3-blog.jsonl v3-arxiv.jsonlJINA_API_KEY est utilisé pour l'intégration et la lecture de contenu à partir d'une URL si nécessaire, la lecture à partir d'un fichier texte local est bien sûr prise en charge. Vous pouvez également apporter vos propres vecteurs modèles (Embeddings) et faire npm run corr pour la visualisation uniquement, auquel cas vous n'avez pas besoin de JINA_API_KEY. L'outil prend en charge à la fois l'analyse d'auto-corrélation (au sein d'une seule collection) et l'analyse de corrélation croisée (entre deux collections).
tagCas d'utilisation
tagDéduplication de contenu et analyse d'alignement
Nous démontrons l'utilité de l'outil grâce à l'analyse de nos publications jina-embeddings-v3. En comparant l'article académique avec la note de version, la visualisation a révélé des schémas diagonaux distincts dans la carte thermique de corrélation, indiquant un fort alignement morceau par morceau entre les documents. Un examen détaillé a montré une réutilisation systématique du contenu, en particulier dans les sections techniques décrivant les types de tâches LoRA.
tagValidation des citations et des références
L'outil s'avère précieux pour valider l'exactitude des citations dans les systèmes de génération augmentée par la récupération, où il devient essentiel de vérifier que les passages récupérés soutiennent réellement les affirmations générées. L'analyse basée sur la similarité est un outil puissant et intuitif pour explorer de grands ensembles de données, par exemple, pour révéler des schémas en regroupant les éléments par similarité.
tagExploration de la stratégie de segmentation (Chunking)
La segmentation tardive (late chunking) et d'autres stratégies de segmentation peuvent être évaluées en examinant comment différentes approches affectent la cohérence sémantique au sein et entre les segments de texte. La visualisation permet d'identifier l'effet de la segmentation tardive et les limites optimales des segments en révélant des modèles de similarité qui s'alignent sur la structure sémantique.
tagAnalyse intermodale
L'outil s'étend au-delà du texte pour prendre en charge les 向量模型 (Embeddings) d'images via jina-clip-v2, permettant l'analyse des modèles de corrélation texte-image pour les applications multimodales.
tagTravaux connexes en matière de visualisation des 向量模型 (Embeddings)
Le défi de l'interprétabilité est particulièrement aigu lorsqu'on travaille avec des 向量模型 (Embeddings) de haute dimension. Le paysage des techniques de visualisation des 向量模型 (Embeddings) a considérablement évolué, avec différentes approches qui peuvent être classées comme :
- Basées sur la réduction de dimensionnalité : approches traditionnelles utilisant PCA, t-SNE, UMAP qui projettent les espaces de haute dimension en 2D/3D
- Basées sur l'exploration interactive : outils comme Parallax et TextEssence qui permettent la manipulation et l'exploration directes
- Solutions spécifiques au domaine : outils spécialisés comme Clustergrammer pour les données biologiques
- Visualisation directe de la similarité : notre approche et les méthodes similaires basées sur la carte thermique qui préservent toutes les informations relationnelles
| Méthode | Approche | Cas d'utilisation |
|---|---|---|
| Correlations | Cartes thermiques de similarité par paires directes | Débogage de la similarité de texte, analyse d'alignement |
| Embedding Projector | PCA, t-SNE et projections linéaires personnalisées | Visualisation et interprétation interactives |
| Parallax | Formules algébriques pour l'exploration sémantique | Compréhension des relations sémantiques |
| TextEssence | Analyse comparative de corpus | Analyse diachronique, comparaison de corpus |
| Nomic Atlas | Visualisation évolutive basée sur le cloud | Ensembles de données à grande échelle, collaboration |
| Clustergrammer | Carte thermique interactive avec clustering | Données biologiques de haute dimension |
| t-SNE | Visualisation de cluster non linéaire | Débogage de modèle, identification de la confusion |
| UMAP | Préservation de la structure locale et globale | Ensembles de données de taille moyenne à grande, analyse générale |
| PCA | Réduction linéaire de dimensionnalité | Exploration initiale, comparaison de base |
tagLimites des approches point par point
Les outils de visualisation existants se concentrent principalement sur les représentations point par point dans les espaces 2D, ce qui peut entraîner la perte d'informations critiques sur les relations par paires. De plus, la plupart des outils sont conçus pour l'analyse d'un seul espace de 向量模型 (Embeddings) plutôt que pour l'évaluation comparative entre différentes sources, modalités ou stratégies de 向量模型 (Embeddings) (par exemple, la segmentation tardive (late chunking) activée ou désactivée).
Par exemple, nous avons récemment rencontré deux cas d'utilisation chez Jina. Le premier consiste à vérifier les citations croisées dans DeepSearch, où nous devons faire correspondre le rapport généré aux extraits originaux du matériel de référence. Le second est la recherche multimodale, où nous devons vérifier l'alignement image-texte et image-image sur de nouvelles données non étiquetées. Dans les deux cas, nous devons explorer les relations entre deux collections de 向量模型 (Embeddings). Nous utilisons donc Correlations pour avoir une idée de la qualité de l'alignement des correspondances et pour valider si les corrélations les plus élevées correspondent systématiquement aux correspondances correctes.
tagConclusion
Au-delà de la simple vérification de l'ambiance, correlations peut fournir des informations plus approfondies sur les relations sémantiques. Comme point de départ, plusieurs statistiques clés peuvent être extraites de la matrice de corrélation :
- Densité de la matrice : la proportion de corrélations au-dessus des seuils spécifiés, indiquant la cohésion sémantique globale
- Distribution des valeurs propres : l'analyse des composantes principales révèle les modèles dominants dans la structure de similarité
- Rang de la matrice : indique la dimensionnalité effective des relations de similarité
- Nombre de conditionnement : mesure la stabilité numérique et les problèmes potentiels de multicolinéarité
Une analyse avancée peut également impliquer l'extraction de sous-matrices significatives qui représentent des régions sémantiques cohérentes. L'extraction d'une sous-matrice principale de somme maximale d'ordre k à partir d'une matrice réelle d'ordre n est un problème d'optimisation combinatoire typique qui peut identifier les segments les plus fortement corrélés.





