

J'ai récemment étudié DSPy, un framework de pointe développé par le groupe Stanford NLP visant à optimiser algorithmiquement les prompts des modèles de langage (LM). Au cours des trois derniers jours, j'ai recueilli quelques premières impressions et des insights précieux sur DSPy. Notez que mes observations ne sont pas destinées à remplacer la documentation officielle de DSPy. En fait, je recommande vivement de lire leur documentation et leur README au moins une fois avant de plonger dans cet article. Ma discussion ici reflète une compréhension préliminaire de DSPy, après avoir passé quelques jours à explorer ses capacités. Il existe plusieurs fonctionnalités avancées, telles que les DSPy Assertions, le Typed Predictor et l'ajustement des poids LM, que je n'ai pas encore explorées en profondeur.
 stanfordnlp
stanfordnlpMalgré mon expérience avec Jina AI, qui se concentre principalement sur les fondamentaux de la recherche, mon intérêt pour DSPy n'a pas été directement motivé par son potentiel en matière de Retrieval-Augmented Generation (RAG). J'étais plutôt intrigué par la possibilité d'utiliser DSPy pour l'ajustement automatique des prompts afin de résoudre certaines tâches de génération.
Si vous débutez avec DSPy et cherchez un point d'entrée accessible, ou si vous connaissez déjà le framework mais trouvez la documentation officielle confuse ou overwhelming, cet article est fait pour vous. J'ai également choisi de ne pas suivre strictement l'idiome de DSPy, qui peut sembler intimidant pour les nouveaux venus. Cela étant dit, plongeons plus profondément.
tagCe que j'apprécie dans DSPy
tagDSPy ferme la boucle de l'ingénierie de prompts
Ce qui m'enthousiasme le plus avec DSPy, c'est son approche pour fermer la boucle du cycle d'ingénierie de prompts, transformant ce qui est souvent un processus manuel et artisanal en un workflow structuré et bien défini d'apprentissage automatique : c'est-à-dire la préparation des datasets, la définition du modèle, l'entraînement, l'évaluation et les tests. À mon avis, c'est l'aspect le plus révolutionnaire de DSPy.
En voyageant dans la Bay Area et en parlant à de nombreux fondateurs de startups focalisés sur l'évaluation des LLM, j'ai souvent entendu des discussions sur les métriques, les hallucinations, l'observabilité et la conformité. Cependant, ces conversations ne progressent souvent pas vers les étapes cruciales suivantes : Avec toutes ces métriques en main, que faisons-nous ensuite ? Peut-on considérer comme une approche stratégique le fait de modifier la formulation de nos prompts, en espérant que certains mots magiques (par exemple, « ma grand-mère est mourante ») pourraient améliorer nos métriques ? Cette question est restée sans réponse pour de nombreuses startups d'évaluation LLM, et c'était une question que je ne pouvais pas non plus aborder — jusqu'à ce que je découvre DSPy. DSPy introduit une méthode claire et programmatique pour optimiser les prompts basée sur des métriques spécifiques, ou même pour optimiser l'ensemble du pipeline LLM, y compris les prompts et les poids LLM.
Harrison, le PDG de LangChain, et Logan, l'ancien responsable des relations développeurs d'OpenAI, ont tous deux déclaré sur le podcast Unsupervised Learning que 2024 devrait être une année charnière pour l'évaluation des LLM. C'est pour cette raison que je pense que DSPy mérite plus d'attention qu'il n'en reçoit actuellement, car DSPy fournit la pièce manquante cruciale du puzzle.
tagDSPy sépare la logique de la représentation textuelle
Un autre aspect de DSPy qui m'impressionne est qu'il transforme l'ingénierie de prompts en un module reproductible et agnostique aux LLM. Pour y parvenir, il extrait la logique du prompt, créant une séparation claire des préoccupations entre la logique et la représentation textuelle, comme illustré ci-dessous.
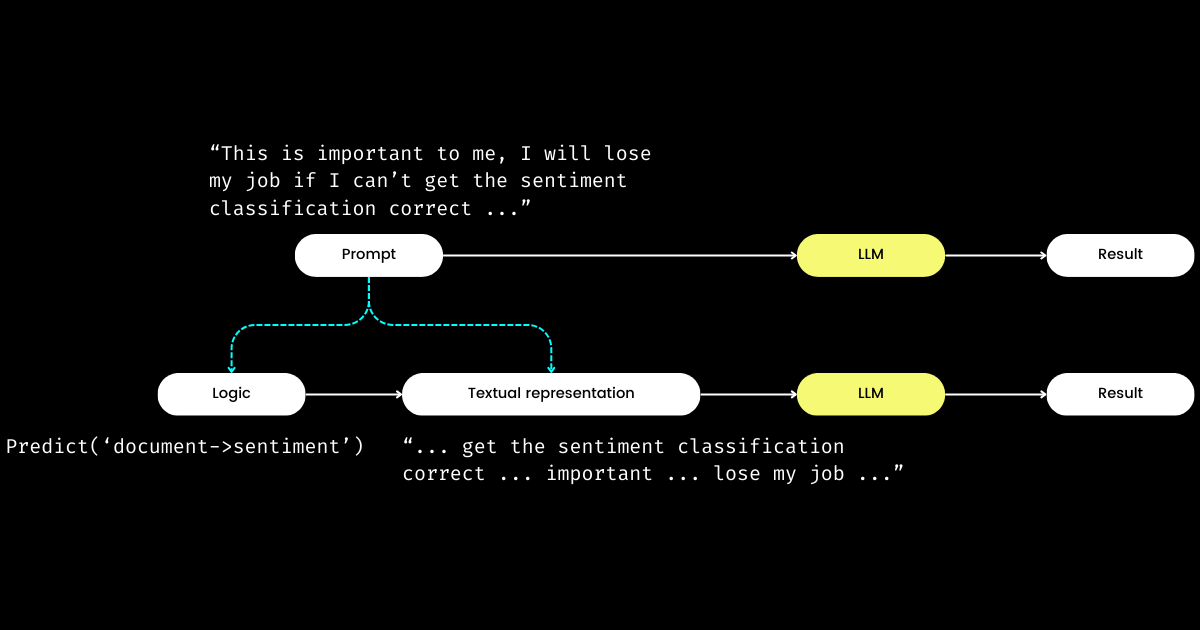
dspy.Module) et de sa représentation textuelle. La logique est immuable, reproductible, testable et agnostique au LLM. La représentation textuelle n'est que la conséquence de la logique.Le concept de DSPy de la logique comme "cause" immuable, testable et agnostique au LLM, avec la représentation textuelle simplement comme sa "conséquence", peut sembler initialement déroutant. C'est particulièrement vrai à la lumière de la croyance répandue selon laquelle "le futur du langage de programmation est le langage naturel". En adhérant à l'idée que "l'ingénierie de prompts est l'avenir", on pourrait éprouver un moment de confusion face à la philosophie de conception de DSPy. Contrairement à l'attente de simplification, DSPy introduit une gamme de modules et de syntaxes de signatures, semblant faire régresser le prompting en langage naturel vers la complexité de la programmation en C !
Mais pourquoi adopter cette approche ? Selon ma compréhension, au cœur de la programmation de prompts se trouve la logique fondamentale, la communication servant d'amplificateur, pouvant potentiellement améliorer ou diminuer son efficacité. La directive "Do sentiment classification" représente la logique fondamentale, tandis qu'une phrase comme "Follow these demonstrations or I will fire you" est une façon de la communiquer. Comme dans les interactions réelles, les difficultés à accomplir les choses proviennent souvent non pas d'une logique défaillante mais d'une communication problématique. Cela explique pourquoi beaucoup, particulièrement les non-natifs, trouvent l'ingénierie de prompts difficile. J'ai observé des ingénieurs logiciels très compétents dans mon entreprise lutter avec l'ingénierie de prompts, non pas par manque de logique, mais parce qu'ils ne "parlent pas le même langage". En séparant la logique du prompt, DSPy permet une programmation déterministe de la logique via dspy.Module, permettant aux développeurs de se concentrer sur la logique de la même manière qu'en ingénierie traditionnelle, quel que soit le LLM utilisé.
Alors, si les développeurs se concentrent sur la logique, qui gère la représentation textuelle ? DSPy assume ce rôle, utilisant vos données et métriques d'évaluation pour affiner la représentation textuelle—tout, de la détermination du focus narratif à l'optimisation des indices, en passant par le choix de bonnes démonstrations. Remarquablement, DSPy peut même utiliser des métriques d'évaluation pour affiner les poids du LLM !
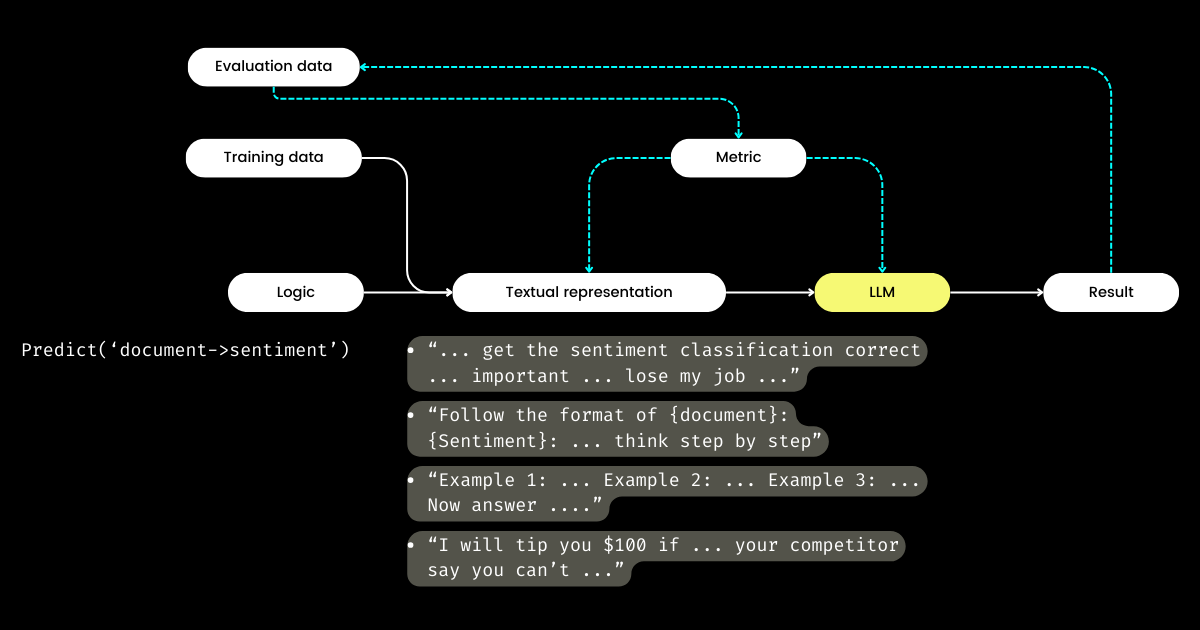
Pour moi, les contributions clés de DSPy — fermer la boucle d'entraînement et d'évaluation dans l'ingénierie de prompts et séparer la logique de la représentation textuelle — soulignent son importance potentielle pour les systèmes LLM/Agent. Une vision ambitieuse certes, mais définitivement nécessaire !
tagCe que je pense que DSPy peut améliorer
Premièrement, DSPy présente une courbe d'apprentissage abrupte pour les nouveaux venus en raison de ses idiomes. Des termes comme signature, module, program, teleprompter, optimization, et compile peuvent être overwhelming. Même pour ceux qui maîtrisent l'ingénierie de prompts, naviguer parmi ces concepts dans DSPy peut être un véritable labyrinthe.
Cette complexité fait écho à mon expérience avec Jina 1.0, où nous avions introduit une série d'expressions idiomatiques telles que chunk, document, driver, executor, pea, pod, querylang et flow (nous avions même conçu d'adorables autocollants pour aider les utilisateurs à s'en souvenir !).






La plupart de ces concepts initiaux ont été supprimés lors des restructurations ultérieures de Jina. Aujourd'hui, seuls Executor, Document, et Flow ont survécu à la "grande purge." Nous avons ajouté un nouveau concept, Deployment, dans Jina 3.0 ; donc cela équilibre les choses. 🤷
Ce problème n'est pas unique à DSPy ou Jina ; rappelez-vous la myriade de concepts et d'abstractions introduits par TensorFlow entre les versions 0.x et 1.x. Je pense que ce problème émerge souvent dans les premiers stades des frameworks logiciels, où il y a une volonté de refléter directement les notations académiques dans le code pour assurer une précision et une reproductibilité maximales. Cependant, tous les utilisateurs ne valorisent pas ces abstractions granulaires, les préférences variant du désir de lignes de code simples aux demandes de plus grande flexibilité. J'ai discuté en détail de ce sujet d'abstraction dans les frameworks logiciels dans un article de blog de 2020, que les lecteurs intéressés pourraient trouver utile.


Deuxièmement, la documentation de DSPy manque parfois de cohérence. Des termes comme module et program, teleprompter et optimizer, ou optimize et compile (parfois appelés training ou bootstrapping) sont utilisés de manière interchangeable, ajoutant à la confusion. Par conséquent, j'ai passé mes premières heures avec DSPy à essayer de comprendre exactement ce qu'il optimizes et ce que le processus de bootstrapping implique.
Malgré ces obstacles, en approfondissant DSPy et en revenant sur la documentation, vous vivrez probablement des moments de clarté où tout commence à prendre sens, révélant les connexions entre sa terminologie unique et les constructions familières vues dans des frameworks comme PyTorch. Cependant, DSPy a indéniablement une marge d'amélioration pour les versions futures, particulièrement pour rendre le framework plus accessible aux ingénieurs de prompts sans expérience préalable avec PyTorch.
tagPoints d'achoppement courants pour les débutants avec DSPy
Dans les sections ci-dessous, j'ai compilé une liste de questions qui ont initialement entravé ma progression avec DSPy. Mon but est de partager ces insights dans l'espoir qu'ils puissent clarifier des défis similaires pour d'autres apprenants.
tagQue sont teleprompter, optimization, et compile ? Qu'est-ce qui est exactement optimisé dans DSPy ?
Dans DSPy, "Teleprompters" est l'optimiseur (et il semble que @lateinteraction remanie la documentation et le code pour clarifier cela). La fonction compile agit au cœur de cet optimiseur, similaire à l'appel de optimizer.optimize(). Pensez-y comme l'équivalent de l'entraînement dans DSPy. Ce processus de compile() vise à ajuster :
- les démonstrations few-shot,
- les instructions,
- les poids du LLM
Cependant, la plupart des tutoriels DSPy pour débutants n'abordent pas l'ajustement des poids et des instructions, ce qui mène à la question suivante.
tagQu'est-ce que bootstrap dans DSPy ?
Bootstrap fait référence à la création de démonstrations auto-générées pour l'apprentissage few-shot en contexte, une partie cruciale du processus compile() (c'est-à-dire, l'optimisation/entraînement comme mentionné ci-dessus). Ces démos few-shot sont générées à partir de données étiquetées fournies par l'utilisateur ; et une démo comprend souvent l'entrée, la sortie, le raisonnement (par exemple, dans les Chaînes de Pensée), et les entrées & sorties intermédiaires (pour les prompts multi-étapes). Bien sûr, des démos few-shot de qualité sont essentielles pour l'excellence des résultats. Pour cela, DSPy permet des fonctions métriques définies par l'utilisateur pour s'assurer que seules les démos répondant à certains critères sont choisies, ce qui mène à la question suivante.
tagQu'est-ce que la fonction métrique de DSPy ?
Après une expérience pratique avec DSPy, j'en suis venu à croire que la fonction métrique mérite beaucoup plus d'attention que ce que la documentation actuelle lui accorde. La fonction métrique dans DSPy joue un rôle crucial dans les phases d'évaluation et d'entraînement, agissant également comme une fonction de "perte", grâce à sa nature implicite (contrôlée par trace=None) :
def keywords_match_jaccard_metric(example, pred, trace=None):
# Jaccard similarity between example keywords and predicted keywords
A = set(normalize_text(example.keywords).split())
B = set(normalize_text(pred.keywords).split())
j = len(A & B) / len(A | B)
if trace is not None:
# act as a "loss" function
return j
return j > 0.8 # act as evaluationCette approche diffère significativement de l'apprentissage automatique traditionnel, où la fonction de perte est généralement continue et dérivable (par exemple, hinge/MSE), tandis que la métrique d'évaluation peut être totalement différente et discrète (par exemple, NDCG). Dans DSPy, les fonctions d'évaluation et de perte sont unifiées dans la fonction métrique, qui peut être discrète et renvoie le plus souvent une valeur booléenne. La fonction métrique peut également intégrer un LLM ! Dans l'exemple ci-dessous, j'ai implémenté une correspondance approximative utilisant un LLM pour déterminer si la valeur prédite et la réponse de référence sont similaires en magnitude, par exemple, "1 million de dollars" et "1M$" renverraient vrai.
class Assess(dspy.Signature):
"""Assess the if the prediction is in the same magnitude to the gold answer."""
gold_answer = dspy.InputField(desc='number, could be in natural language')
prediction = dspy.InputField(desc='number, could be in natural language')
assessment = dspy.OutputField(desc='yes or no, focus on the number magnitude, not the unit or exact value or wording')
def same_magnitude_correct(example, pred, trace=None):
return dspy.Predict(Assess)(gold_answer=example.answer, prediction=pred.answer).assessment.lower() == 'yes'Aussi puissante soit-elle, la fonction métrique influence significativement l'expérience utilisateur de DSPy, déterminant non seulement l'évaluation finale de la qualité mais affectant également les résultats d'optimisation. Une fonction métrique bien conçue peut conduire à des prompts optimisés, tandis qu'une fonction mal conçue peut faire échouer l'optimisation. Lorsque vous abordez un nouveau problème avec DSPy, vous pourriez passer autant de temps à concevoir la logique (c'est-à-dire DSPy.Module) que sur la fonction métrique. Cette double attention portée à la logique et aux métriques peut être intimidante pour les débutants.
tag"Bootstrapped 0 full traces after 20 examples in round 0" que signifie ce message ?
Ce message qui apparaît discrètement pendant compile() mérite toute votre attention, car il signifie essentiellement que l'optimisation/compilation a échoué, et que le prompt que vous obtenez n'est pas meilleur qu'un simple few-shot. Que se passe-t-il ? J'ai résumé quelques conseils pour vous aider à déboguer votre programme DSPy lorsque vous rencontrez ce message :
Votre fonction métrique est incorrecte
Est-ce que la fonction your_metric, utilisée dans BootstrapFewShot(metric=your_metric), est correctement implémentée ? Effectuez quelques tests unitaires. Est-ce que your_metric renvoie parfois True, ou renvoie-t-elle toujours False ? Notez que renvoyer True est crucial car c'est le critère pour que DSPy considère l'exemple bootstrappé comme un "succès". Si vous renvoyez chaque évaluation comme True, alors chaque exemple est considéré comme un "succès" dans le bootstrapping ! Ce n'est pas idéal, bien sûr, mais c'est ainsi que vous pouvez ajuster la rigueur de la fonction métrique pour modifier le résultat "Bootstrapped 0 full traces". Notez que bien que la documentation de DSPy indique que les métriques peuvent également renvoyer des valeurs scalaires, après avoir examiné le code sous-jacent, je ne le recommanderais pas aux débutants.
Votre logique (DSPy.Module) est incorrecte
Si la fonction métrique est correcte, vous devez alors vérifier si votre logique dspy.Module est correctement implémentée. Tout d'abord, vérifiez que la signature DSPy est correctement attribuée pour chaque étape. Les signatures en ligne, comme dspy.Predict('question->answer'), sont faciles à utiliser, mais pour la qualité, je suggère fortement d'implémenter avec des signatures basées sur des classes. Plus précisément, ajoutez des docstrings descriptives à la classe, remplissez les champs desc pour InputField et OutputField—tout cela fournit au LM des indices sur chaque champ. Ci-dessous, j'ai implémenté deux DSPy.Module multi-étapes pour résoudre des problèmes de Fermi, l'un avec une signature en ligne, l'autre avec une signature basée sur des classes.
class FermiSolver(dspy.Module):
def __init__(self):
super().__init__()
self.step1 = dspy.Predict('question -> initial_guess')
self.step2 = dspy.Predict('question, initial_guess -> calculated_estimation')
self.step3 = dspy.Predict('question, initial_guess, calculated_estimation -> variables_and_formulae')
self.step4 = dspy.ReAct('question, initial_guess, calculated_estimation, variables_and_formulae -> gathering_data')
self.step5 = dspy.Predict('question, initial_guess, calculated_estimation, variables_and_formulae, gathering_data -> answer')
def forward(self, q):
step1 = self.step1(question=q)
step2 = self.step2(question=q, initial_guess=step1.initial_guess)
step3 = self.step3(question=q, initial_guess=step1.initial_guess, calculated_estimation=step2.calculated_estimation)
step4 = self.step4(question=q, initial_guess=step1.initial_guess, calculated_estimation=step2.calculated_estimation, variables_and_formulae=step3.variables_and_formulae)
step5 = self.step5(question=q, initial_guess=step1.initial_guess, calculated_estimation=step2.calculated_estimation, variables_and_formulae=step3.variables_and_formulae, gathering_data=step4.gathering_data)
return step5Solveur de problèmes de Fermi utilisant uniquement une signature en ligne
class FermiStep1(dspy.Signature):
question = dspy.InputField(desc='Fermi problems involve the use of estimation and reasoning')
initial_guess = dspy.OutputField(desc='Have a guess – don't do any calculations yet')
class FermiStep2(FermiStep1):
initial_guess = dspy.InputField(desc='Have a guess – don't do any calculations yet')
calculated_estimation = dspy.OutputField(desc='List the information you'll need to solve the problem and make some estimations of the values')
class FermiStep3(FermiStep2):
calculated_estimation = dspy.InputField(desc='List the information you'll need to solve the problem and make some estimations of the values')
variables_and_formulae = dspy.OutputField(desc='Write a formula or procedure to solve your problem')
class FermiStep4(FermiStep3):
variables_and_formulae = dspy.InputField(desc='Write a formula or procedure to solve your problem')
gathering_data = dspy.OutputField(desc='Research, measure, collect data and use your formula. Find the smallest and greatest values possible')
class FermiStep5(FermiStep4):
gathering_data = dspy.InputField(desc='Research, measure, collect data and use your formula. Find the smallest and greatest values possible')
answer = dspy.OutputField(desc='the final answer, must be a numerical value')
class FermiSolver2(dspy.Module):
def __init__(self):
super().__init__()
self.step1 = dspy.Predict(FermiStep1)
self.step2 = dspy.Predict(FermiStep2)
self.step3 = dspy.Predict(FermiStep3)
self.step4 = dspy.Predict(FermiStep4)
self.step5 = dspy.Predict(FermiStep5)
def forward(self, q):
step1 = self.step1(question=q)
step2 = self.step2(question=q, initial_guess=step1.initial_guess)
step3 = self.step3(question=q, initial_guess=step1.initial_guess, calculated_estimation=step2.calculated_estimation)
step4 = self.step4(question=q, initial_guess=step1.initial_guess, calculated_estimation=step2.calculated_estimation, variables_and_formulae=step3.variables_and_formulae)
step5 = self.step5(question=q, initial_guess=step1.initial_guess, calculated_estimation=step2.calculated_estimation, variables_and_formulae=step3.variables_and_formulae, gathering_data=step4.gathering_data)
return step5Solveur de problèmes de Fermi utilisant une signature basée sur des classes avec une description plus complète de chaque champ.
Vérifiez également la partie def forward(self, ). Pour les Modules multi-étapes, assurez-vous que la sortie (ou toutes les sorties comme dans FermiSolver) de la dernière étape est fournie comme entrée à l'étape suivante.
Votre problème est simplement trop difficile
Si la métrique et le module semblent corrects, il est possible que votre problème soit simplement trop difficile et que la logique que vous avez implémentée ne soit pas suffisante pour le résoudre. Par conséquent, DSPy trouve qu'il est impossible de bootstrapper une démonstration avec votre logique et votre fonction métrique. À ce stade, voici quelques options à considérer :
- Utilisez un LM plus puissant. Par exemple, remplacez
gpt-35-turbo-instructpargpt-4-turbocomme LM étudiant, utilisez un LM plus puissant comme professeur. Cela peut souvent être très efficace. Après tout, un modèle plus puissant signifie une meilleure compréhension des prompts. - Améliorez votre logique. Ajoutez ou remplacez certaines étapes dans votre
dspy.Modulepar des étapes plus complexes. Par exemple, remplacezPredictparChainOfThoughtProgramOfThought, ajoutez une étapeRetrieval. - Ajoutez plus d'exemples d'entraînement. Si 20 exemples ne suffisent pas, visez-en 100 ! Vous pouvez alors espérer qu'un exemple passe la vérification métrique et soit sélectionné par
BootstrapFewShot. - Reformulez le problème. Souvent, un problème devient insoluble lorsque la formulation est incorrecte. Mais si vous changez d'angle pour le regarder, les choses pourraient être beaucoup plus faciles et plus évidentes.
En pratique, le processus implique un mélange d'essais et d'erreurs. Par exemple, j'ai abordé un problème particulièrement difficile : générer une icône SVG similaire aux icônes Google Material Design basée sur deux ou trois mots-clés. Ma stratégie initiale était d'utiliser un simple DSPy.Module qui utilise dspy.ChainOfThought('keywords -> svg'), couplé à une fonction métrique qui évaluait la similarité visuelle entre le SVG généré et le SVG Material Design de référence, similaire à un algorithme pHash. J'ai commencé avec 20 exemples d'entraînement, mais après le premier tour, j'ai obtenu "Bootstrapped 0 full traces after 20 examples in round 0", indiquant que l'optimisation avait échoué. En augmentant le jeu de données à 100 exemples, en révisant mon module pour incorporer plusieurs étapes, et en ajustant le seuil de la fonction métrique, j'ai finalement obtenu 2 démonstrations bootstrappées et réussi à obtenir des prompts optimisés.
