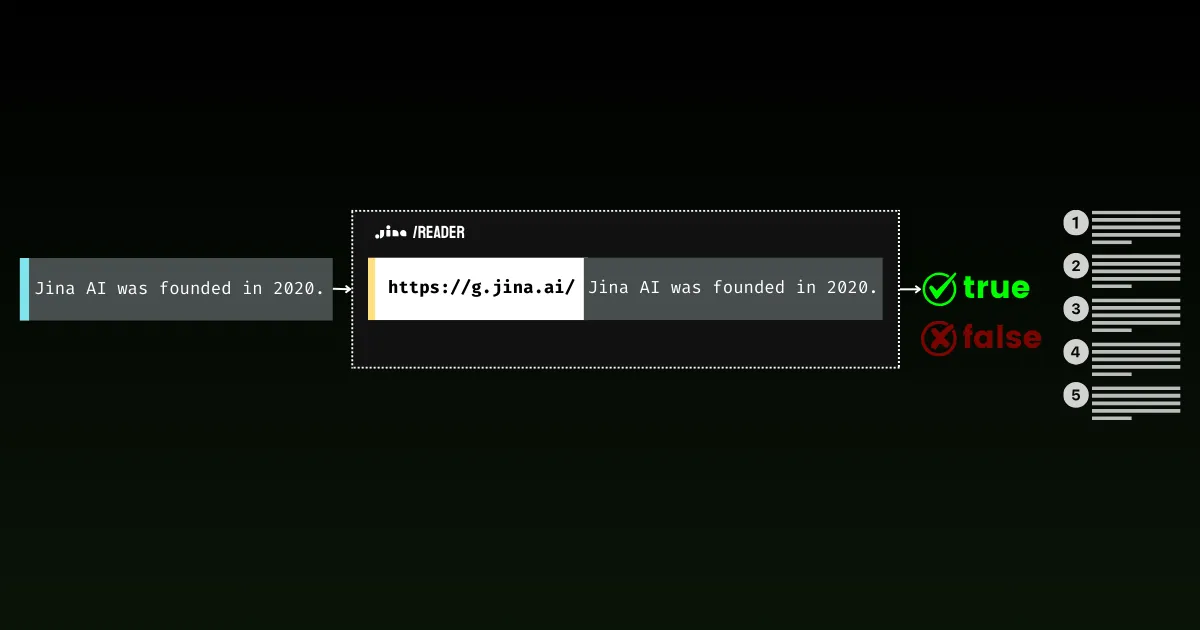

L'ancrage est absolument essentiel pour les applications d'IA générative.
Sans ancrage, les LLM sont plus enclins aux hallucinations et à générer des informations inexactes, en particulier lorsque leurs données d'entraînement manquent de connaissances actualisées ou spécifiques. Peu importe la puissance de raisonnement d'un LLM, il ne peut tout simplement pas fournir une réponse correcte si l'information a été introduite après sa date limite de connaissance.
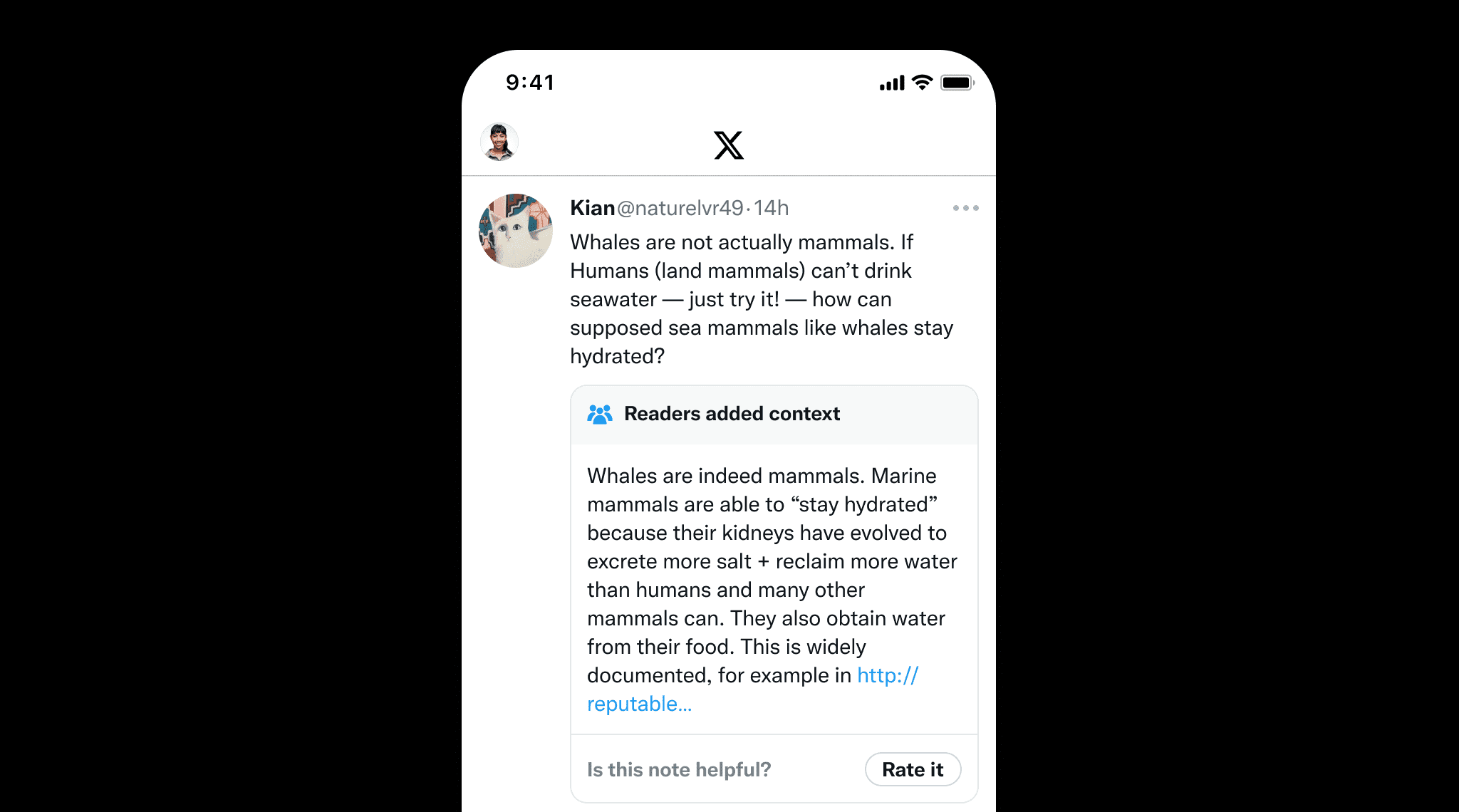
L'ancrage n'est pas seulement important pour les LLM mais aussi pour le contenu rédigé par des humains afin de prévenir la désinformation. Un excellent exemple est Community Notes de X, où les utilisateurs ajoutent collaborativement du contexte aux publications potentiellement trompeuses. Cela souligne la valeur de l'ancrage, qui garantit l'exactitude factuelle en fournissant des sources et références claires, tout comme Community Notes aide à maintenir l'intégrité de l'information.
Avec Jina Reader, nous avons activement développé une solution d'ancrage facile à utiliser. Par exemple, r.jina.ai convertit les pages web en markdown adapté aux LLM, et s.jina.ai agrège les résultats de recherche dans un format markdown unifié basé sur une requête donnée.

Aujourd'hui, nous sommes ravis de présenter un nouveau point de terminaison à cette suite : g.jina.ai. La nouvelle API prend un énoncé donné, l'ancre en utilisant des résultats de recherche web en temps réel, et renvoie un score de factualité et les références exactes utilisées. Nos expériences montrent que cette API atteint un score F1 plus élevé pour la vérification des faits par rapport aux modèles comme GPT-4, o1-mini et Gemini 1.5 Flash & Pro avec ancrage de recherche.

Ce qui distingue g.jina.ai de la recherche ancrée de Gemini, c'est que chaque résultat inclut jusqu'à 30 URLs (fournissant généralement au moins 10), chacune accompagnée de citations directes qui contribuent à la conclusion. Voici un exemple d'ancrage de l'énoncé, "The latest model released by Jina AI is jina-embeddings-v3," utilisant g.jina.ai (au 14 octobre 2024). Explorez le terrain de jeu de l'API pour découvrir toutes les fonctionnalités. Notez que des limitations s'appliquent :
curl -X POST https://g.jina.ai \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $YOUR_JINA_TOKEN" \
-d '{
"statement":"the last model released by Jina AI is jina-embeddings-v3"
}'YOUR_JINA_TOKEN est votre clé API Jina AI. Vous pouvez obtenir 1M de jetons gratuits sur notre page d'accueil, ce qui permet environ trois ou quatre essais gratuits. Avec le prix actuel de l'API de 0,02 USD par million de jetons, chaque requête d'ancrage coûte environ 0,006 USD.
{
"code": 200,
"status": 20000,
"data": {
"factuality": 0.95,
"result": true,
"reason": "The majority of the references explicitly support the statement that the last model released by Jina AI is jina-embeddings-v3. Multiple sources, such as the arXiv paper, Jina AI's news, and various model documentation pages, confirm this assertion. Although there are a few references to the jina-embeddings-v2 model, they do not provide evidence contradicting the release of a subsequent version (jina-embeddings-v3). Therefore, the statement that 'the last model released by Jina AI is jina-embeddings-v3' is well-supported by the provided documentation.",
"references": [
{
"url": "https://arxiv.org/abs/2409.10173",
"keyQuote": "arXiv September 18, 2024 jina-embeddings-v3: Multilingual Embeddings With Task LoRA",
"isSupportive": true
},
{
"url": "https://arxiv.org/abs/2409.10173",
"keyQuote": "We introduce jina-embeddings-v3, a novel text embedding model with 570 million parameters, achieves state-of-the-art performance on multilingual data and long-context retrieval tasks, supporting context lengths of up to 8192 tokens.",
"isSupportive": true
},
{
"url": "https://azuremarketplace.microsoft.com/en-us/marketplace/apps/jinaai.jina-embeddings-v3?tab=Overview",
"keyQuote": "jina-embeddings-v3 is a multilingual multi-task text embedding model designed for a variety of NLP applications.",
"isSupportive": true
},
{
"url": "https://docs.pinecone.io/models/jina-embeddings-v3",
"keyQuote": "Jina Embeddings v3 is the latest iteration in the Jina AI's text embedding model series, building upon Jina Embedding v2.",
"isSupportive": true
},
{
"url": "https://haystack.deepset.ai/integrations/jina",
"keyQuote": "Recommended Model: jina-embeddings-v3 : We recommend jina-embeddings-v3 as the latest and most performant embedding model from Jina AI.",
"isSupportive": true
},
{
"url": "https://huggingface.co/jinaai/jina-embeddings-v2-base-en",
"keyQuote": "The embedding model was trained using 512 sequence length, but extrapolates to 8k sequence length (or even longer) thanks to ALiBi.",
"isSupportive": false
},
{
"url": "https://huggingface.co/jinaai/jina-embeddings-v2-base-en",
"keyQuote": "With a standard size of 137 million parameters, the model enables fast inference while delivering better performance than our small model.",
"isSupportive": false
},
{
"url": "https://huggingface.co/jinaai/jina-embeddings-v2-base-en",
"keyQuote": "We offer an `encode` function to deal with this.",
"isSupportive": false
},
{
"url": "https://huggingface.co/jinaai/jina-embeddings-v3",
"keyQuote": "jinaai/jina-embeddings-v3 Feature Extraction • Updated 3 days ago • 278k • 375",
"isSupportive": true
},
{
"url": "https://huggingface.co/jinaai/jina-embeddings-v3",
"keyQuote": "the latest version (3.1.0) of [SentenceTransformers] also supports jina-embeddings-v3",
"isSupportive": true
},
{
"url": "https://huggingface.co/jinaai/jina-embeddings-v3",
"keyQuote": "jina-embeddings-v3: Multilingual Embeddings With Task LoRA",
"isSupportive": true
},
{
"url": "https://jina.ai/embeddings/",
"keyQuote": "v3: Frontier Multilingual Embeddings is a frontier multilingual text embedding model with 570M parameters and 8192 token-length, outperforming the latest proprietary embeddings from OpenAI and Cohere on MTEB.",
"isSupportive": true
},
{
"url": "https://jina.ai/news/jina-embeddings-v3-a-frontier-multilingual-embedding-model",
"keyQuote": "Jina Embeddings v3: A Frontier Multilingual Embedding Model jina-embeddings-v3 is a frontier multilingual text embedding model with 570M parameters and 8192 token-length, outperforming the latest proprietary embeddings from OpenAI and Cohere on MTEB.",
"isSupportive": true
},
{
"url": "https://jina.ai/news/jina-embeddings-v3-a-frontier-multilingual-embedding-model/",
"keyQuote": "As of its release on September 18, 2024, jina-embeddings-v3 is the best multilingual model ...",
"isSupportive": true
}
],
"usage": {
"tokens": 112073
}
}
}La réponse de l'ancrage de l'énoncé "The latest model released by Jina AI is jina-embeddings-v3", utilisant g.jina.ai (au 14 octobre 2024).
tagComment ça marche ?
À sa base, g.jina.ai enveloppe s.jina.ai et r.jina.ai , ajoutant un raisonnement multi-étapes grâce à la Chaîne de Pensée (CoT). Cette approche garantit que chaque énoncé ancré est analysé en profondeur à l'aide de recherches en ligne et de lecture de documents.

s.jina.ai et r.jina.ai, ajoutant CoT pour la planification et le raisonnement.tagExplication étape par étape
Examinons l'ensemble du processus pour mieux comprendre comment g.jina.ai gère la vérification des faits, de l'entrée à la sortie finale :
- Déclaration d'entrée :
Le processus commence lorsqu'un utilisateur fournit une déclaration qu'il souhaite vérifier, comme "Le dernier modèle publié par Jina AI est jina-embeddings-v3." Notez qu'il n'est pas nécessaire d'ajouter des instructions de vérification des faits avant la déclaration. - Génération des requêtes de recherche :
Un LLM est utilisé pour générer une liste de requêtes de recherche uniques pertinentes pour la déclaration. Ces requêtes visent à cibler différents éléments factuels, assurant une recherche complète couvrant tous les aspects clés de la déclaration. - Appel à
s.jina.aipour chaque requête :
Pour chaque requête générée,g.jina.aieffectue une recherche web en utilisants.jina.ai. Les résultats de recherche comprennent un ensemble diversifié de sites web ou de documents liés aux requêtes. En arrière-plan,s.jina.aiappeller.jina.aipour récupérer le contenu de la page. - Extraction des références des résultats de recherche :
Pour chaque document récupéré lors de la recherche, un LLM extrait les références clés. Ces références incluent :url: L'adresse web de la source.keyQuote: Une citation directe ou un extrait du document.isSupportive: Une valeur booléenne indiquant si la référence soutient ou contredit la déclaration originale.
- Agrégation et tri des références :
Toutes les références des documents récupérés sont combinées en une seule liste. Si le nombre total de références dépasse 30, le système sélectionne 30 références aléatoires pour maintenir une sortie gérable. - Évaluation de la déclaration :
Le processus d'évaluation implique l'utilisation d'un LLM pour évaluer la déclaration sur la base des références recueillies (jusqu'à 30). En plus de ces références externes, les connaissances internes du modèle jouent également un rôle dans l'évaluation. Le résultat final comprend :factuality: Un score entre 0 et 1 qui estime l'exactitude factuelle de la déclaration.result: Une valeur booléenne indiquant si la déclaration est vraie ou fausse.reason: Une explication détaillée de pourquoi la déclaration est jugée correcte ou incorrecte, avec référence aux sources qui la soutiennent ou la contredisent.
- Production du résultat :
Une fois la déclaration entièrement évaluée, la sortie est générée. Celle-ci inclut le score de factualité, l'assertion de la déclaration, un raisonnement détaillé, et une liste de références avec citations et URLs. Les références sont limitées à la citation, l'URL, et si elles soutiennent ou non la déclaration, maintenant la sortie claire et concise.
tagBenchmark
Nous avons manuellement collecté 100 déclarations avec des étiquettes de vérité terrain soit true (62 déclarations) soit false (38 déclarations) et utilisé différentes méthodes pour déterminer si elles pouvaient être vérifiées. Ce processus convertit essentiellement la tâche en un problème de classification binaire, où la performance finale est mesurée par la précision, le rappel et le score F1 — plus ils sont élevés, meilleurs ils sont.
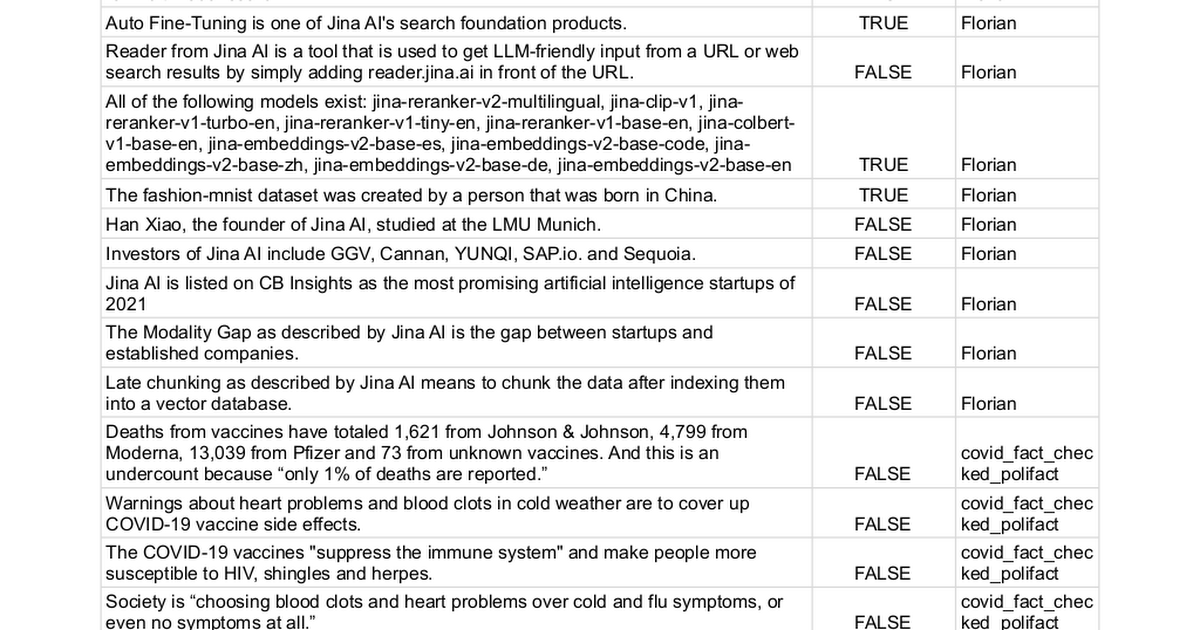
La liste complète des déclarations peut être trouvée ici.
| Model | Precision | Recall | F1 Score |
|---|---|---|---|
| Jina AI Grounding API (g.jina.ai) | 0.96 | 0.88 | 0.92 |
| Gemini-flash-1.5-002 w/ grounding | 1.00 | 0.73 | 0.84 |
| Gemini-pro-1.5-002 w/ grounding | 0.98 | 0.71 | 0.82 |
| gpt-o1-mini | 0.87 | 0.66 | 0.75 |
| gpt-4o | 0.95 | 0.58 | 0.72 |
| Gemini-pro-1.5-001 w/ grounding | 0.97 | 0.52 | 0.67 |
| Gemini-pro-1.5-001 | 0.95 | 0.32 | 0.48 |
Notez qu'en pratique, certains LLMs renvoient une troisième classe, Je ne sais pas, dans leurs prédictions. Pour l'évaluation, ces instances sont exclues du calcul du score. Cette approche évite de pénaliser l'incertitude aussi sévèrement que les réponses incorrectes. Admettre l'incertitude est préféré à la devinette, pour décourager les modèles de faire des prédictions incertaines.
tagLimitations
Malgré les résultats prometteurs, nous souhaitons souligner certaines limitations de la version actuelle de l'API de grounding :
- Latence élevée et consommation de tokens : Un seul appel à
g.jina.aipeut prendre environ 30 secondes et utiliser jusqu'à 300K tokens, en raison de la recherche web active, de la lecture des pages et du raisonnement multi-étapes par le LLM. Avec une clé API gratuite de 1M de tokens, cela signifie que vous ne pouvez le tester que trois ou quatre fois. Pour maintenir la disponibilité du service pour les utilisateurs payants, nous avons également mis en place une limite de taux conservative pourg.jina.ai. Avec notre tarification API actuelle de 0,02 $ par 1M de tokens, chaque requête de grounding coûte environ 0,006 USD. - Contraintes d'applicabilité : Toutes les déclarations ne peuvent pas ou ne devraient pas être vérifiées. Les opinions ou expériences personnelles, comme "Je me sens paresseux", ne se prêtent pas à la vérification. De même, les événements futurs ou les déclarations hypothétiques ne s'appliquent pas. Il existe de nombreux cas où la vérification serait non pertinente ou absurde. Pour éviter les appels API inutiles, nous recommandons aux utilisateurs de soumettre sélectivement uniquement les phrases ou sections qui nécessitent réellement une vérification des faits. Côté serveur, nous avons mis en place un ensemble complet de codes d'erreur pour expliquer pourquoi une déclaration pourrait être rejetée pour la vérification.
- Dépendance à la qualité des données web : La précision de l'API de grounding n'est que aussi bonne que la qualité des sources qu'elle récupère. Si les résultats de recherche contiennent des informations de faible qualité ou biaisées, le processus de vérification pourrait le refléter, conduisant potentiellement à des conclusions inexactes ou trompeuses. Pour prévenir ce problème, nous permettons aux utilisateurs de spécifier manuellement le paramètre
referenceset de restreindre les URLs que le système recherche. Cela donne aux utilisateurs plus de contrôle sur les sources utilisées pour la vérification, assurant un processus de vérification des faits plus ciblé et pertinent.
tagConclusion
L'API de grounding offre une expérience de vérification des faits de bout en bout, quasi en temps réel. Les chercheurs peuvent l'utiliser pour trouver des références qui soutiennent ou remettent en question leurs hypothèses, ajoutant de la crédibilité à leur travail. Dans les réunions d'entreprise, elle garantit que les stratégies sont construites sur des informations précises et à jour en validant les hypothèses et les données. Dans les discussions politiques, elle vérifie rapidement les affirmations, apportant plus de responsabilité aux débats.
Pour l'avenir, nous prévoyons d'améliorer l'API en intégrant des sources de données privées comme les rapports internes, les bases de données et les PDFs pour une vérification des faits plus personnalisée. Nous visons également à augmenter le nombre de sources vérifiées par requête pour des évaluations plus approfondies. L'amélioration des questions-réponses multi-étapes ajoutera de la profondeur à l'analyse, et l'augmentation de la cohérence est une priorité pour garantir que les requêtes répétées produisent des résultats plus fiables et cohérents.




