



Il est important de suivre l'évolution des technologies de recherche d'information, mais il est tout aussi important de ne pas perturber les composants qui ont fait leurs preuves et qui ont déjà démontré leur valeur pour l'entreprise.
Malgré la croissance de la recherche vectorielle basée sur l'IA, la réalité est que la plupart des entreprises s'appuient encore sur des technologies de recherche traditionnelles, utilisant souvent des variantes de l'algorithme BM25. C'est une technologie fiable et éprouvée. Passer à un système complètement nouveau n'est pas seulement une étape majeure, cela s'avère souvent peu pratique, nécessitant des ressources substantielles et une refonte complète des opérations. De plus, BM25 est une pierre angulaire des moteurs de recherche lexicale, couramment utilisée dans les plateformes de moteur de recherche répandues comme Elasticsearch et Solr. Il délivre déjà de bons résultats pour de nombreux cas d'utilisation.
De nombreuses entreprises hésitent donc à passer complètement à la recherche neuronale, malgré des preuves convaincantes que la recherche basée sur l'IA améliore significativement la satisfaction des utilisateurs et la qualité des résultats.
tagReclassement Neuronal Indépendant de la Recherche
Reranker est une innovation révolutionnaire dans le paysage des systèmes de recherche. Conçu pour améliorer la valeur des moteurs de recherche existants comme Elasticsearch, il sert de couche supplémentaire, fonctionnant comme un add-on pour affiner la qualité de recherche délivrée. Il n'a pas besoin de connaître le type de technologie de recherche auquel il est connecté, il prend simplement une liste de correspondances et les réordonne pour les améliorer.
Jina Reranker ajoute un niveau de compréhension plus profond aux technologies de recherche traditionnelles. Les algorithmes comme BM25 font un bon travail de récupération des documents basée sur la fréquence des termes mais peinent à évaluer le sens des textes qu'ils récupèrent au regard de l'intention de l'utilisateur. C'est là que l'IA excelle : Reranker aide à produire des résultats qui sont mieux alignés avec ce que les utilisateurs recherchent.
Par conséquent, pour les entreprises qui souhaitent apporter les puissants avantages des modèles d'IA à leurs systèmes de recherche, l'ajout de Jina Reranker peut être une décision judicieuse qui n'entraîne pas les contraintes du remplacement d'une infrastructure de recherche existante. Il s'agit d'affiner les résultats de recherche pour les rendre non seulement acceptables, mais exceptionnels : plus pertinents et plus précis.
tagPourquoi Jina Reranker ?
Parmi les modèles de reclassement, les modèles Jina Reranker se distinguent comme des leaders avec des scores state-of-the-art sur les tests de performance.

Dans cet article, nous vous montrerons comment implémenter un système de recommandation pour les plateformes e-commerce. D'abord, nous analyserons la performance d'un retrieveur BM25 seul. Ensuite, nous ajouterons Jina Reranker au pipeline de recherche et verrons comment les résultats deviennent plus pertinents et efficaces.
tagAjoutez Jina Reranker à Votre Workflow Existant :
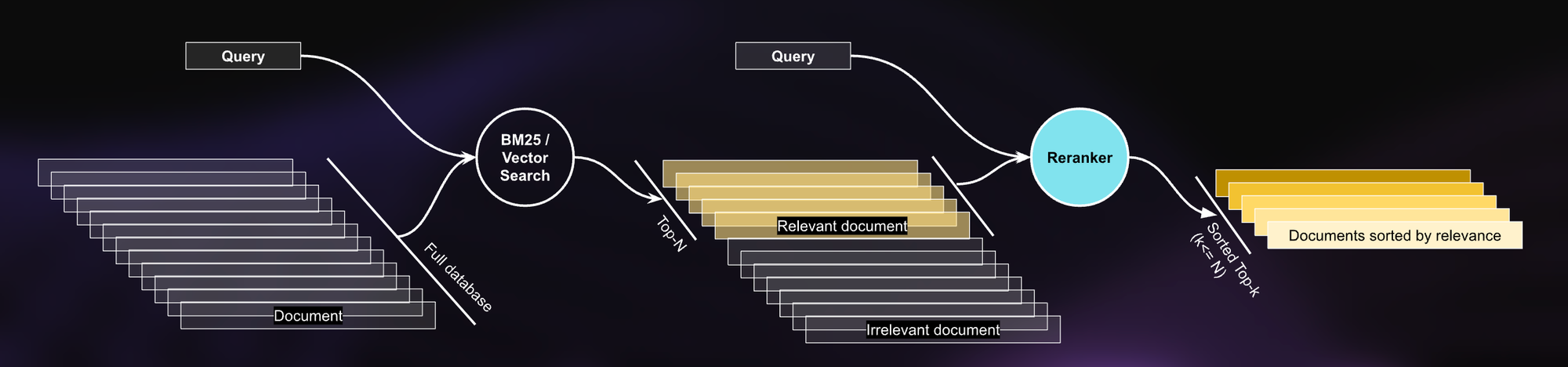
Voici une décomposition du workflow mis à jour intégrant Jina Reranker :
- Recherche Initiale : Lorsqu'une requête est saisie, le moteur de recherche BM25 récupère les documents pertinents en se basant principalement sur la correspondance des termes de la requête avec les documents.
- Reclassement : jina-reranker-v1-base-en prend ces résultats initiaux et utilise l'IA state-of-the-art pour évaluer la pertinence de chaque document récupéré au regard de la requête de l'utilisateur.
- Retour des Résultats : Jina Reranker réordonne ensuite les résultats de recherche, s'assurant que les documents les plus pertinents sont présentés en premier.
Notre API facile à utiliser et notre documentation complète vous guideront tout au long du processus, ne nécessitant que des changements minimes à votre système.

tagVoyez-le en Action : Amélioration de la Recherche E-commerce avec Jina Reranker
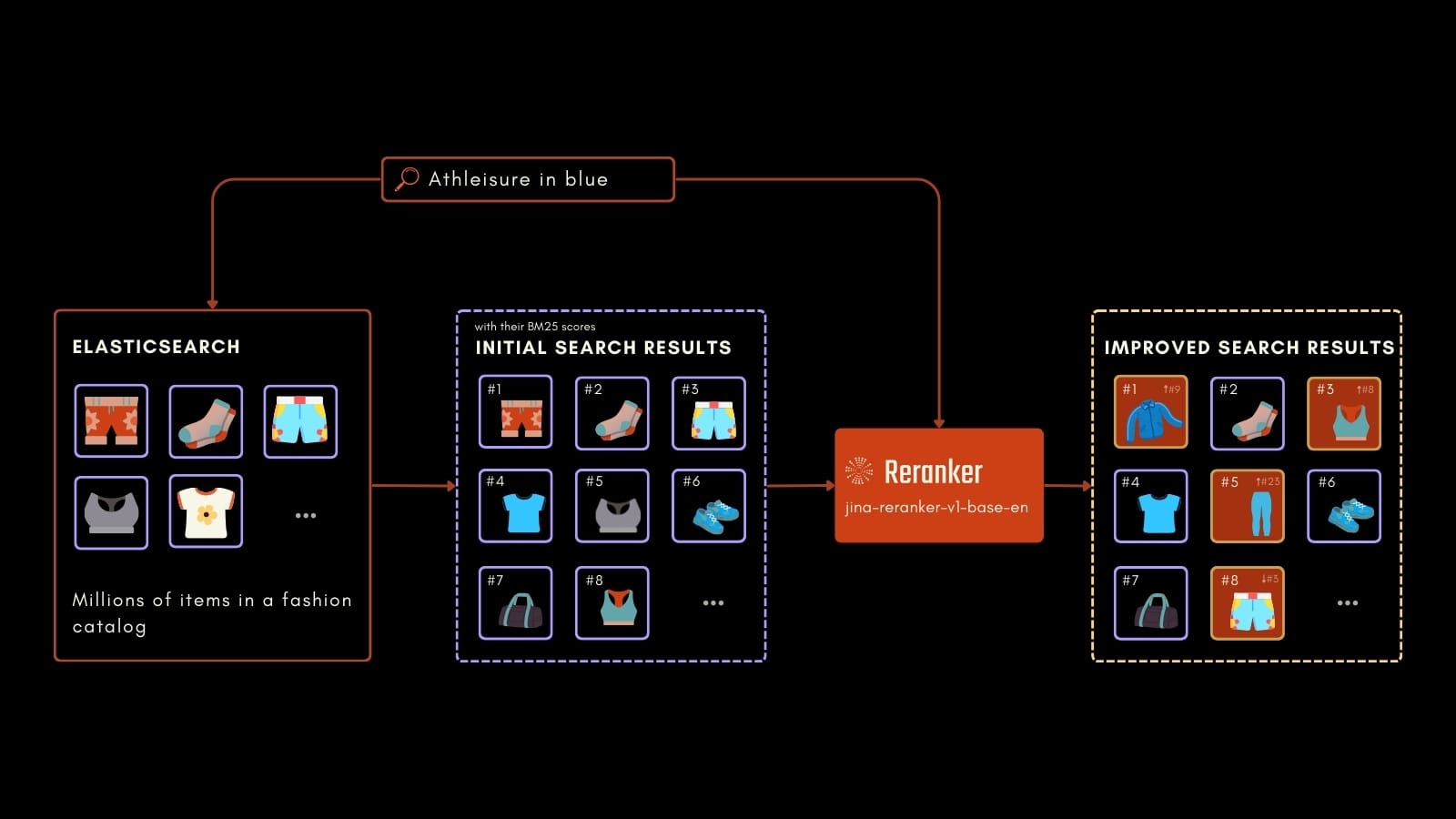
Parcourons un exemple pratique d'e-commerce pour démontrer l'impact de Jina Reranker dans des applications du monde réel. L'objectif ici est de rechercher des listes de produits basées sur la requête d'un utilisateur.
Pour illustrer cela, nous allons mettre en place deux pipelines de recherche utilisant le framework populaire de recherche et d'orchestration IA Haystack by deepset. Le premier pipeline utilise BM25 seul. Le second intègre jina-reranker-v1-base-en dans le système BM25. Vous pouvez facilement remplacer le composant InMemoryDocumentStore de Haystack par ElasticsearchDocumentStore pour faire la même expérience si vous avez un cluster Elasticsearch existant.
Nous utiliserons un jeu de données exemple de Kaggle. Vous pouvez directement télécharger le CSV ici. Cette comparaison côte à côte met en évidence les améliorations apportées par l'intégration de Jina Reranker dans le workflow de recherche.
Pour commencer, installez tous les composants nécessaires :
pip install --q haystack-ai jina-haystack
Définissez la Clé API Jina comme variable d'environnement. Vous pouvez en générer une ici.
import os
import getpass
os.environ["JINA_API_KEY"] = getpass.getpass()
Effectuez une recherche de produit basée sur les noms de produits. Par exemple :
short_query = "Nightwear for Women"
Transformez chaque ligne CSV en un Document :
import csv
from haystack import Document
documents = []
with open("fashion_data.csv") as f:
data = csv.reader(f, delimiter=";")
for row in data:
row_text = ''.join(row)
row_doc = Document(content=row_text, meta={"prod_id": row[0], "prod_image": row[1]})
documents.append(row_doc)
tagPipeline #1 : BM25 uniquement
from haystack import Pipeline
from haystack.document_stores.types import DuplicatePolicy
from haystack.document_stores.in_memory import InMemoryDocumentStore
from haystack.components.retrievers.in_memory import InMemoryBM25Retriever
document_store=InMemoryDocumentStore()
document_store.write_documents(documents=documents, policy=DuplicatePolicy.OVERWRITE)
retriever = InMemoryBM25Retriever(document_store=document_store)
rag_pipeline = Pipeline()
rag_pipeline.add_component("retriever", retriever)
result = rag_pipeline.run(
{
"retriever": {"query": query, "top_k": 50},
}
)
for doc in result["retriever"]["documents"]:
print("Product ID:", doc.meta["prod_id"])
print("Product Image:", doc.meta["prod_image"])
print("Score:", doc.score)
print("-"*100)
Voici les vignettes des 50 résultats retournés par BM25 :

Nous pouvons voir que les résultats sont liés aux vêtements de nuit, correspondant partiellement à la requête, mais les correspondances les plus pertinentes (images en gras dans la grille ci-dessus) semblent se perdre parmi la multitude de produits récupérés par BM25. En pratique, l'utilisation de BM25 seul signifie qu'un utilisateur recevrait principalement des résultats non pertinents en haut de page.
tagPipeline #2 : BM25 + Jina Reranker
Le script ci-dessous décrit comment construire ce pipeline étape par étape :
from haystack_integrations.components.rankers.jina import JinaRanker
ranker_retriever = InMemoryBM25Retriever(document_store=document_store)
ranker = JinaRanker()
ranker_pipeline = Pipeline()
ranker_pipeline.add_component("ranker_retriever", ranker_retriever)
ranker_pipeline.add_component("ranker", ranker)
ranker_pipeline.connect("ranker_retriever.documents", "ranker.documents")
result = ranker_pipeline.run(
{
"ranker_retriever": {"query": query, "top_k": 50},
"ranker": {"query": query, "top_k": 10},
}
)
for doc in result["ranker"]["documents"]:
print("Product ID:", doc.meta["prod_id"])
print("Product Image:", doc.meta["prod_image"])
print("Score:", doc.score)
print("-"*100)
Voici les 10 premiers résultats retournés par Jina Reranker :

Par rapport à BM25, Jina Reranker retourne une collection de réponses beaucoup plus pertinente. Dans notre contexte e-commerce, cela se traduit par une meilleure expérience utilisateur et une probabilité accrue d'achats.
tagImpact de l'intégration de Jina Reranker avec BM25
Suite à notre étude de cas dans le domaine du e-commerce, il est clair que l'intégration de Jina Reranker avec les moteurs de recherche traditionnels comme Elasticsearch marque une avancée significative dans la technologie de recherche. Voici un aperçu de la façon dont cette intégration améliore l'expérience de recherche :
- Taux de réussite améliorés : La fusion de Jina Reranker et de la recherche traditionnelle a notablement augmenté la fréquence des résultats pertinents. Cela rend le processus de recherche plus précis, s'alignant étroitement avec les requêtes des utilisateurs.
- Expérience utilisateur améliorée : Il y a une amélioration tangible dans la qualité des résultats de recherche. Cela indique que les capacités combinées de Jina Reranker et BM25 sont mieux alignées avec les besoins spécifiques des utilisateurs, améliorant leur expérience globale de recherche.
- Haute précision pour les requêtes complexes : Pour les recherches difficiles, cette synergie assure une compréhension plus détaillée de la requête et du contenu associé. Cela se traduit par des résultats plus précis et plus pertinents.
tagPrêt à améliorer votre expérience de recherche ?
Jina Reranker est votre solution idéale pour augmenter la pertinence de vos résultats de recherche. Il s'intègre parfaitement à votre système de recherche existant et peut être implémenté rapidement avec un minimum de code.
Si vous êtes intrigué par ce que vous avez lu jusqu'ici et désireux de voir la différence que Jina Reranker peut apporter, pourquoi ne pas l'essayer ? Commencez votre voyage et découvrez la puissance transformative des modèles Search Foundation de Jina AI dans votre propre environnement.
