

Berlin, Allemagne - 15 janvier 2023 - Faisant écho à l'iconique "Ich bin ein Berliner" de JFK, chez Jina AI, nous sommes ravis de créer des ponts entre les langues à notre manière. Aujourd'hui, nous sommes fiers d'annoncer notre dernière innovation : jina-embeddings-v2-base-de, un modèle d'embedding allemand/anglais. Ce modèle bilingue à la pointe de la technologie représente une avancée significative dans la représentation du langage, avec une longueur de contexte de 8 192 tokens. Ce qui le distingue, c'est son efficacité remarquable : il atteint des performances de premier ordre tout en étant 7 fois plus petit que les modèles comparables.
Les embeddings sont cruciaux pour les entreprises allemandes cherchant à s'étendre sur le marché américain. Selon les German American Business Outlook (GABO) 2022, environ un tiers des entreprises allemandes génèrent plus de 20 % de leurs ventes et profits mondiaux aux États-Unis, et 93 % s'attendent à une augmentation des ventes américaines. Cette tendance se poursuit alors que 93 % prévoient d'accroître leurs investissements aux États-Unis dans les trois prochaines années, 85 % anticipant une croissance des ventes nettes et un accent important sur la transformation numérique. De bons embeddings peuvent jouer un rôle essentiel dans cette expansion en facilitant une meilleure compréhension des préférences clients, en permettant une communication plus efficace et en positionnant des produits culturellement pertinents.
Notre percée est particulièrement bénéfique pour les entreprises allemandes souhaitant mettre en œuvre des applications bilingues dans les pays anglophones. Avec jina-embeddings-v2-base-de, nous sommes impatients de voir comment les entreprises allemandes vont innover et prospérer dans un monde de plus en plus connecté.
tagPoints forts du modèle
- Performance à la pointe : jina-embeddings-v2-base-de se classe systématiquement en tête des benchmarks pertinents et mène parmi les modèles open-source de taille similaire.
- Modèle bilingue : Ce modèle encode les textes en allemand et en anglais, permettant l'utilisation de l'une ou l'autre langue comme requête ou document cible dans les applications de recherche. Les textes ayant des significations équivalentes dans les deux langues sont mappés dans le même espace d'embedding, formant la base d'applications multilingues.
- Contexte étendu : Une longueur de 8 192 tokens permet à jina-embeddings-v2-base-de de prendre en charge des textes et fragments de documents plus longs, dépassant largement les modèles qui ne supportent que quelques centaines de tokens à la fois.
- Taille compacte : jina-embeddings-v2-base-de est conçu pour des performances élevées sur du matériel informatique standard. Avec seulement 161 millions de paramètres, le modèle complet fait 322 Mo et tient dans la mémoire d'ordinateurs courants. Les embeddings eux-mêmes font 768 dimensions, une taille de vecteur relativement petite comparée à de nombreux modèles, économisant de l'espace et du temps d'exécution pour les applications.
- Minimisation des biais : Des recherches récentes montrent que les modèles multilingues sans formation linguistique spécifique présentent de forts biais envers les structures grammaticales anglaises dans les embeddings. Les modèles d'embedding devraient se concentrer sur la capture du sens et non favoriser des paires de phrases simplement similaires en surface.
- Intégration transparente : Les modèles Jina Embeddings v2 disposent d'intégrations natives avec les principales bases de données vectorielles, notamment MongoDB, Qdrant, et Weaviate, ainsi qu'avec des frameworks RAG et LLM comme Haystack et LlamaIndex.
tagPerformance leader en NLP allemand
Nous avons testé jina-embeddings-v2-base-de face à quatre références renommées qui prennent également en charge l'allemand et l'anglais. Celles-ci incluent :
- Multilingual-E5-large et Multilingual-E5-base de Microsoft
- Le Cross English & German RoBERTa for Sentence Embeddings de T-Systems
- Sentence-BERT (
distiluse-base-multilingual-cased-v2)
Nos benchmarks incluent les tâches MTEB pour l'anglais et notre propre benchmark personnalisé. En l'absence d'une suite complète de benchmarks pour les embeddings allemands, nous avons pris l'initiative de développer la nôtre, inspirée par MTEB. Nous sommes fiers de partager ici nos découvertes et avancées.
 jina-ai
jina-ai
tagTaille compacte, résultats supérieurs
jina-embeddings-v2-base-de démontre des performances exceptionnelles, particulièrement dans les tâches en langue allemande. Il surpasse le modèle E5 base tout en étant moins d'un tiers de sa taille. De plus, il rivalise avec le modèle E5 large, qui est sept fois plus grand, démontrant son efficacité et sa puissance. Cette efficacité fait de jina-embeddings-v2-base-de un véritable changement de donne, particulièrement en comparaison avec d'autres modèles d'embedding bilingues et multilingues populaires.
tagExcellence en recherche interlingue allemand-anglais
Notre modèle ne se distingue pas seulement par sa taille et son efficacité ; il est également très performant dans les tâches de recherche interlingue anglais-allemand. Cela est évident dans ses performances sur divers benchmarks clés :
- WikiCLIR, pour la recherche de l'anglais vers l'allemand
- STS17, partie de l'évaluation MTEB pour la recherche de l'anglais vers l'allemand
- STS22, pour la recherche de l'allemand vers l'anglais, également partie de MTEB
- BUCC, pour la recherche de l'allemand vers l'anglais, inclus dans MTEB
Les performances dans ces benchmarks, particulièrement dans les tests d'évaluation MTEB (à l'exception de WikiCLIR), soulignent l'efficacité de jina-embeddings-v2-base-de dans le traitement de tâches bilingues complexes.
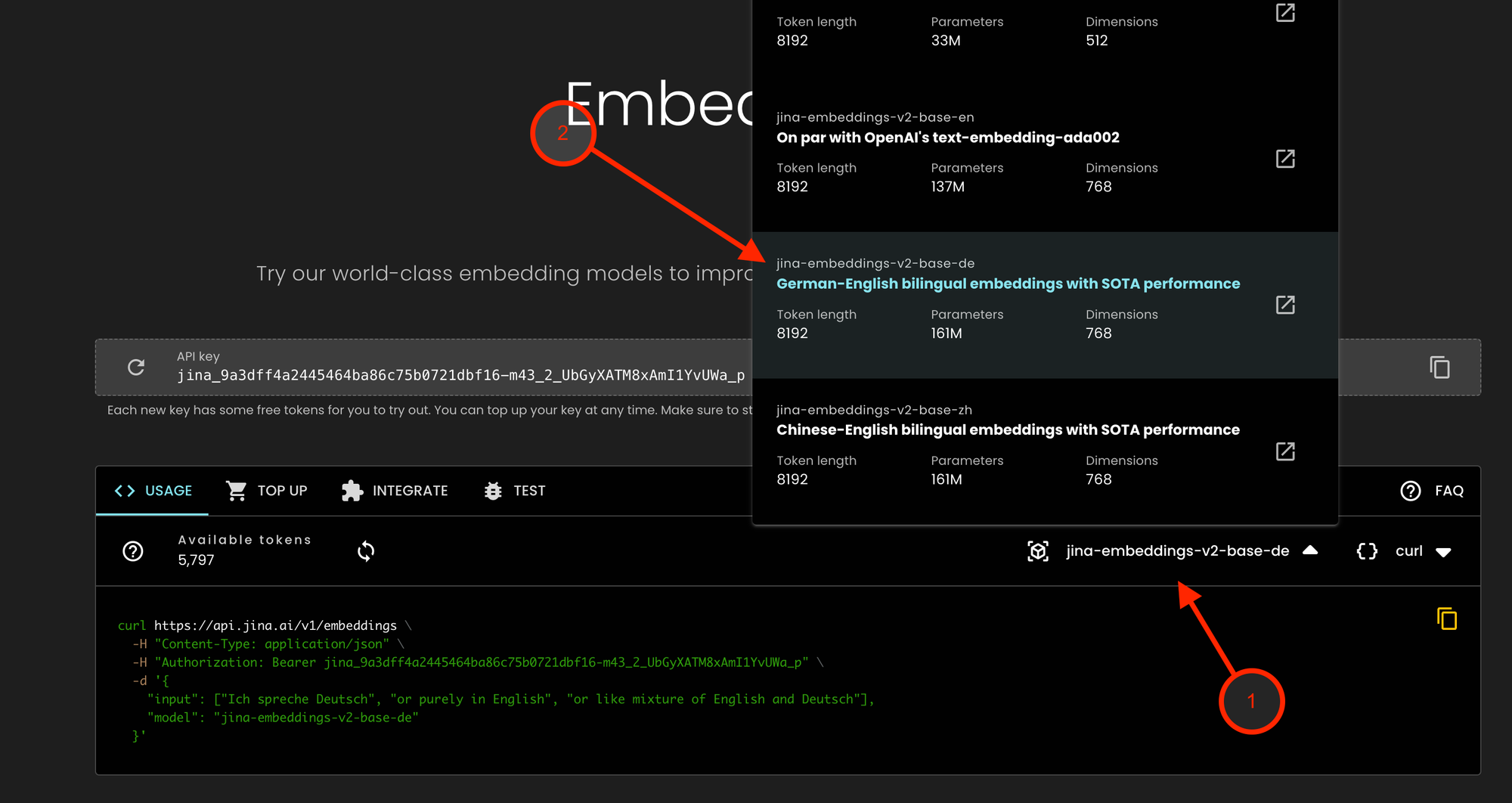
tagObtenir l'accès API
Nos offres pour nos utilisateurs entreprise qui privilégient la confidentialité et la conformité des données, incluant jina-embeddings-v2-base-de, sont accessibles via l'API Jina Embeddings :
- Visitez Jina Embeddings API et cliquez sur le menu déroulant des modèles
- Sélectionnez jina-embeddings-v2-base-de

Nous rendrons ce modèle disponible très prochainement sur AWS Sagemaker marketplace pour les utilisateurs du cloud Amazon et en téléchargement sur HuggingFace.
tagJina 8K Embeddings : La pierre angulaire d'applications d'IA diversifiées
Les embeddings sont cruciaux pour une large gamme d'applications d'IA, incluant la recherche d'informations, le contrôle de la qualité des données, la classification et la recommandation. Ils sont fondamentaux pour améliorer de nombreuses tâches d'IA.
Jina AI s'engage à faire progresser l'état de l'art en matière de technologie d'embedding, en maintenant nos composants d'IA centraux transparents, accessibles et abordables pour les entreprises de tous types et tailles qui valorisent la confidentialité et la conformité des données. En plus de jina-embeddings-v2-base-de, Jina AI a publié des modèles d'embedding à la pointe de la technologie pour le chinois et des modèles monolingues anglais haute performance. Cela fait partie de notre mission de rendre la technologie d'IA plus inclusive et applicable mondialement.
Nous valorisons vos retours. Rejoignez notre canal communautaire pour contribuer avec vos commentaires et rester informé de nos avancées. Ensemble, nous façonnons un avenir de l'IA plus robuste et inclusif.


