



Les développeurs et les ingénieurs opérationnels accordent une grande importance à une infrastructure facile à configurer, rapide à démarrer et, par la suite, efficace à déployer dans un environnement de production à grande échelle sans complications supplémentaires. Pour cette raison, Milvus Lite, la dernière base de données vectorielle légère de notre partenaire Milvus, est un outil important pour les développeurs Python qui souhaitent développer rapidement des applications de recherche, en particulier lorsqu'il est utilisé avec des modèles de recherche fondamentaux de haute qualité et faciles à utiliser.
Dans cet article, nous décrirons comment Milvus Lite intègre Jina Embeddings v2 et Jina Reranker v1 en utilisant l'exemple d'une application de Retrieval Augmented Generation (RAG) construite sur les discussions des canaux publics internes d'une entreprise fictive pour permettre aux employés d'obtenir des réponses précises et utiles à leurs questions liées à l'organisation.
tagAperçu de Milvus Lite, Jina Embeddings et Jina Reranker
Milvus Lite est une nouvelle version légère de la base de données vectorielle leader Milvus, qui est maintenant également proposée comme bibliothèque Python. Milvus Lite partage la même API que Milvus déployé sur Docker ou Kubernetes mais peut être facilement installé via une simple commande pip, sans configuration de serveur.
Avec l'intégration de Jina Embeddings v2 et Jina Reranker v1 dans pymilvus, le SDK Python de Milvus, vous avez maintenant la possibilité d'intégrer directement des documents en utilisant le même client Python pour n'importe quel mode de déploiement de Milvus, y compris Milvus Lite. Vous pouvez trouver les détails de l'intégration de Jina Embeddings et Reranker sur les pages de documentation de pymilvus.
Avec sa fenêtre de contexte de 8k tokens et ses capacités multilingues, Jina Embeddings v2 encode la sémantique large du texte et assure une récupération précise. En ajoutant Jina Reranker v1 au pipeline, vous pouvez affiner davantage vos résultats en effectuant un encodage croisé des résultats récupérés directement avec la requête pour une compréhension contextuelle plus approfondie.
tagMilvus et les Modèles Jina AI en Action
Ce tutoriel se concentrera sur un cas d'utilisation pratique : l'interrogation de l'historique des conversations Slack d'une entreprise pour répondre à un large éventail de questions basées sur les conversations passées.
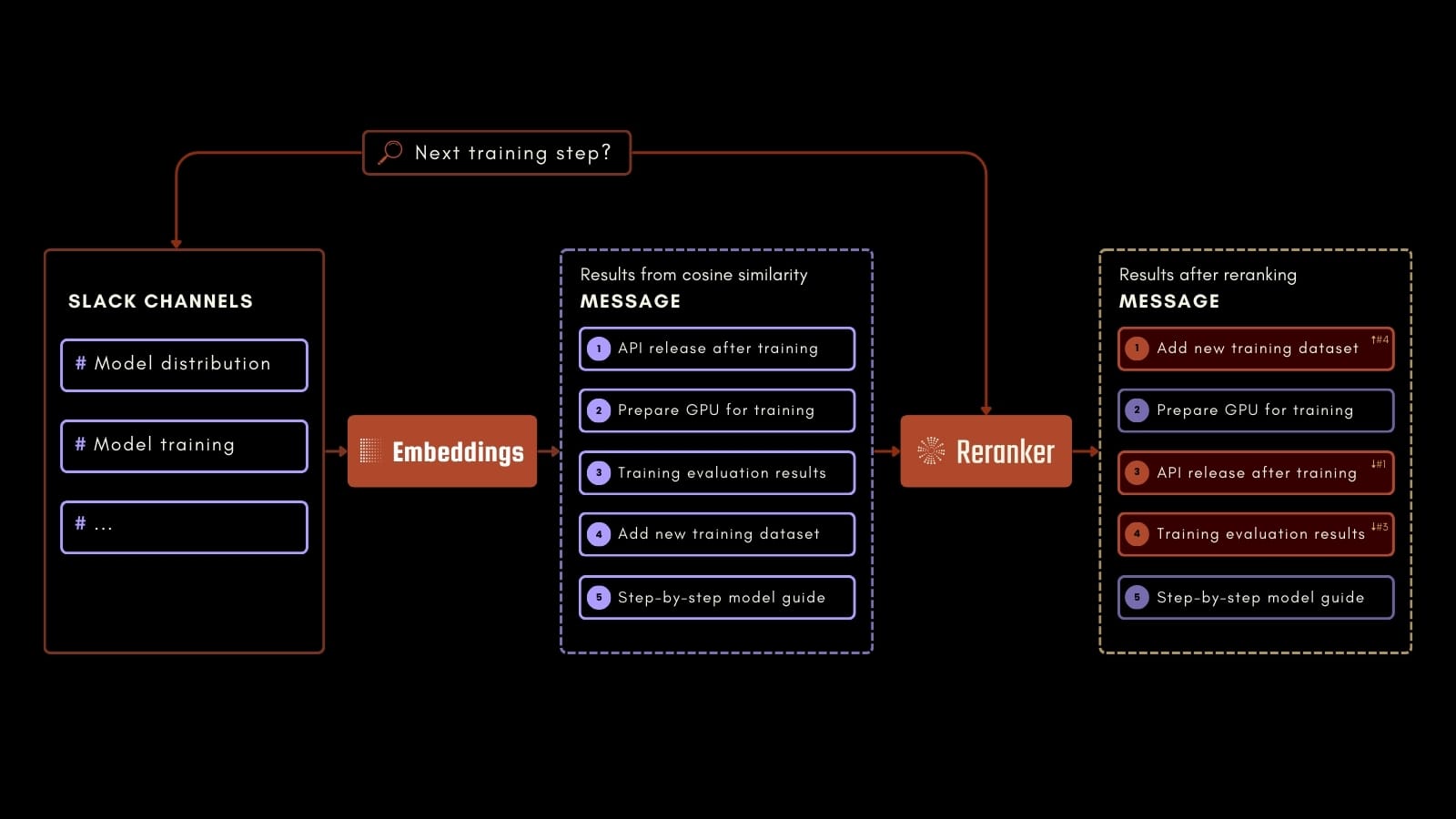
Par exemple, un employé pourrait poser des questions sur la prochaine étape d'un processus de formation en IA, comme dans le schéma de processus ci-dessus. En utilisant Jina Embeddings, Jina Reranker et Milvus, nous pouvons identifier avec précision les informations pertinentes dans les messages Slack enregistrés. Cette application peut améliorer votre productivité au travail en facilitant l'accès aux informations précieuses des communications passées.
Pour générer les réponses, nous utiliserons Mixtral 7B Instruct via l'intégration HuggingFace dans Langchain. Pour utiliser le modèle, vous avez besoin d'un token d'accès HuggingFace que vous pouvez générer comme décrit ici.
Vous pouvez suivre dans Colab ou en téléchargeant le notebook.


tagÀ propos du Dataset
Le dataset utilisé dans ce tutoriel a été généré en utilisant GPT-4 et est destiné à reproduire l'historique des conversations des canaux Slack de Blueprint AI. Blueprint est une startup fictive d'IA développant ses propres modèles fondamentaux. Vous pouvez télécharger le dataset ici.
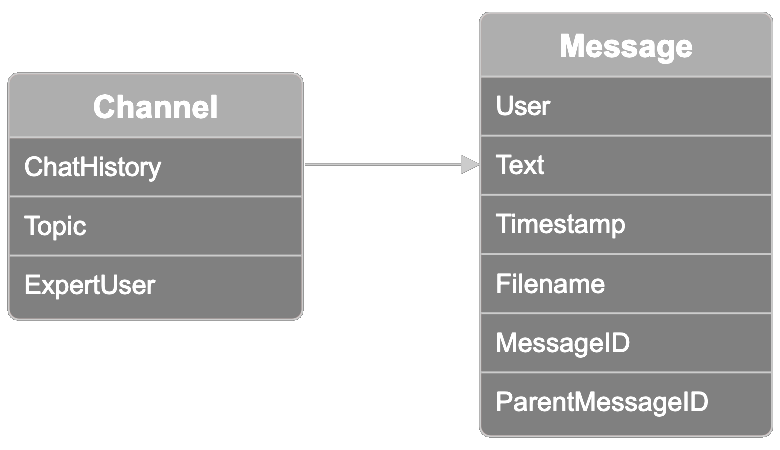
Les données sont organisées en canaux, chacun représentant une collection de fils de discussion Slack connexes. Chaque canal a une étiquette thématique, parmi dix options : model distribution, model training, model fine-tuning, ethics and bias mitigation, user feedback, sales, marketing, model onboarding, creative design, et product management. Un participant est désigné comme "expert user". Vous pouvez utiliser ce champ pour valider les résultats de la recherche de l'utilisateur le plus expert dans un domaine, ce que nous vous montrerons ci-dessous.
Chaque canal contient également un historique de chat avec des fils de conversation allant jusqu'à 100 messages par canal. Chaque message dans le dataset contient les informations suivantes :
- L'utilisateur qui a envoyé le message
- Le texte du message envoyé par l'utilisateur
- L'horodatage du message
- Le nom du fichier que l'utilisateur a pu joindre au message
- L'ID du message
- L'ID du message parent si le message faisait partie d'un fil issu d'un autre message
tagConfiguration de l'Environnement
Pour commencer, installez tous les composants nécessaires :
pip install -U pymilvus
pip install -U "pymilvus[model]"
pip install langchain
pip install langchain-community
Téléchargez le dataset :
import os
if not os.path.exists("chat_history.json"):
!wget https://raw.githubusercontent.com/jina-ai/workshops/main/notebooks/embeddings/milvus/chat_history.jsonDéfinissez votre clé API Jina AI dans une variable d'environnement. Vous pouvez en générer une ici.
import os
import getpass
os.environ["JINAAI_API_KEY"] = getpass.getpass(prompt="Jina AI API Key: ")Faites de même pour votre Token Hugging Face. Vous pouvez trouver comment en générer un ici. Assurez-vous qu'il est défini sur READ pour accéder au Hugging Face Hub.
os.environ["HUGGINGFACEHUB_API_TOKEN"] = getpass.getpass(prompt="Hugging Face Token: ")tagCréation de la Collection Milvus
Créez la Collection Milvus pour indexer les données :
from pymilvus import MilvusClient, DataType
# Specify a local file name as uri parameter of MilvusClient to use Milvus Lite
client = MilvusClient("milvus_jina.db")
schema = MilvusClient.create_schema(
auto_id=True,
enable_dynamic_field=True,
)
schema.add_field(field_name="id", datatype=DataType.INT64, description="The Primary Key", is_primary=True)
schema.add_field(field_name="embedding", datatype=DataType.FLOAT_VECTOR, description="The Embedding Vector", dim=768)
index_params = client.prepare_index_params()
index_params.add_index(field_name="embedding", metric_type="COSINE", index_type="AUTOINDEX")
client.create_collection(collection_name="milvus_jina", schema=schema, index_params=index_params)tagPréparer les données
Analyser l'historique des conversations et extraire les métadonnées :
import json
with open("chat_history.json", "r", encoding="utf-8") as file:
chat_data = json.load(file)
messages = []
metadatas = []
for channel in chat_data:
chat_history = channel["chat_history"]
chat_topic = channel["topic"]
chat_expert = channel["expert_user"]
for message in chat_history:
text = f"""{message["user"]}: {message["message"]}"""
messages.append(text)
meta = {
"time_stamp": message["time_stamp"],
"file_name": message["file_name"],
"parent_message_nr": message["parent_message_nr"],
"channel": chat_topic,
"expert": True if message["user"] == chat_expert else False
}
metadatas.append(meta)
tagIntégrer les données de chat
Créer des embeddings pour chaque message en utilisant Jina Embeddings v2 pour récupérer les informations pertinentes des conversations :
from pymilvus.model.dense import JinaEmbeddingFunction
jina_ef = JinaEmbeddingFunction("jina-embeddings-v2-base-en")
embeddings = jina_ef.encode_documents(messages)tagIndexer les données de chat
Indexer les messages, leurs embeddings et les métadonnées associées :
collection_data = [{
"message": message,
"embedding": embedding,
"metadata": metadata
} for message, embedding, metadata in zip(messages, embeddings, metadatas)]
data = client.insert(
collection_name="milvus_jina",
data=collection_data
)tagInterroger l'historique des conversations
Il est temps de poser une question :
query = "Who knows the most about encryption protocols in my team?"Maintenant, intégrer la requête et récupérer les messages pertinents. Ici, nous récupérons les cinq messages les plus pertinents et les reclassons en utilisant Jina Reranker v1 :
from pymilvus.model.reranker import JinaRerankFunction
query_vectors = jina_ef.encode_queries([query])
results = client.search(
collection_name="milvus_jina",
data=query_vectors,
limit=5,
)
results = results[0]
ids = [results[i]["id"] for i in range(len(results))]
results = client.get(
collection_name="milvus_jina",
ids=ids,
output_fields=["id", "message", "metadata"]
)
jina_rf = JinaRerankFunction("jina-reranker-v1-base-en")
documents = [results[i]["message"] for i in range(len(results))]
reranked_documents = jina_rf(query, documents)
reranked_messages = []
for reranked_document in reranked_documents:
idx = reranked_document.index
reranked_messages.append(results[idx])Enfin, générer une réponse à la requête en utilisant Mixtral 7B Instruct et les messages reclassés comme contexte :
from langchain.prompts import PromptTemplate
from langchain_community.llms import HuggingFaceEndpoint
llm = HuggingFaceEndpoint(repo_id="mistralai/Mixtral-8x7B-Instruct-v0.1")
prompt = """<s>[INST] Context information is below.\\n
It includes the five most relevant messages to the query, sorted based on their relevance to the query.\\n
---------------------\\n
{context_str}\\\\n
---------------------\\n
Given the context information and not prior knowledge,
answer the query. Please be brief, concise, and complete.\\n
If the context information does not contain an answer to the query,
respond with \\"No information\\".\\n
Query: {query_str}[/INST] </s>"""
prompt = PromptTemplate(template=prompt, input_variables=["query_str", "context_str"])
llm_chain = prompt | llm
answer = llm_chain.invoke({"query_str":query, "context_str":reranked_messages})
print(f"\n\nANSWER:\n\n{answer}")La réponse à notre question est :
« D'après les informations contextuelles, User5 semble être le plus compétent en matière de protocoles de chiffrement dans votre équipe. Ils ont mentionné que les nouveaux protocoles améliorent significativement la sécurité des données, en particulier pour les déploiements cloud. »
Si vous lisez les messages dans chat_history.json, vous pouvez vérifier par vous-même si User5 est l'utilisateur le plus expert.
tagRésumé
Nous avons vu comment configurer Milvus Lite, intégrer des données de chat en utilisant Jina Embeddings v2 et affiner les résultats de recherche avec Jina Reranker v1, le tout dans un cas d'utilisation pratique de recherche dans un historique de chat Slack. Milvus Lite simplifie le développement d'applications Python sans nécessiter de configurations serveur complexes. Son intégration avec Jina Embeddings et Reranker vise à augmenter la productivité en facilitant l'accès aux informations précieuses de votre lieu de travail.
tagUtilisez les modèles Jina AI et Milvus maintenant
Milvus Lite avec l'intégration de Jina Embeddings et Reranker vous fournit un pipeline de traitement complet, prêt à l'emploi avec seulement quelques lignes de code.
Nous aimerions beaucoup entendre parler de vos cas d'utilisation et discuter de la façon dont l'extension Jina AI Milvus peut répondre à vos besoins professionnels. Contactez-nous via notre site web ou notre canal Discord pour partager vos commentaires et rester à jour avec nos derniers modèles. Pour les questions concernant l'intégration de Milvus et Jina AI, rejoignez la communauté Milvus.
