


Jina CLIP v1 (jina-clip-v1) est un nouveau modèle d'embedding multimodal qui étend les capacités du modèle CLIP original d'OpenAI. Avec ce nouveau modèle, les utilisateurs disposent d'un modèle d'embedding unique qui offre des performances état de l'art à la fois dans la recherche de texte seul et dans la recherche cross-modale texte-image. Jina AI a amélioré les performances d'OpenAI CLIP de 165% dans la recherche de texte seul, et de 12% dans la recherche d'image à image, avec des performances identiques ou légèrement meilleures dans les tâches de texte vers image et d'image vers texte. Cette performance améliorée rend Jina CLIP v1 indispensable pour travailler avec des entrées multimodales.
Dans cet article, nous discuterons d'abord des lacunes du modèle CLIP original et de la façon dont nous les avons abordées en utilisant une méthode unique de co-entraînement. Ensuite, nous démontrerons l'efficacité de notre modèle sur divers benchmarks de recherche. Enfin, nous fournirons des instructions détaillées sur la façon dont les utilisateurs peuvent commencer avec Jina CLIP v1 via notre API Embeddings et Hugging Face.
tagL'Architecture CLIP pour l'IA Multimodale
En janvier 2021, OpenAI a publié le modèle CLIP (Contrastive Language–Image Pretraining). CLIP possède une architecture simple mais ingénieuse : il combine deux modèles d'embedding, un pour les textes et un pour les images, en un seul modèle avec un espace d'embedding unique. Ses embeddings de texte et d'image sont directement comparables entre eux, rendant la distance entre un embedding de texte et un embedding d'image proportionnelle à la qualité de la description de l'image par le texte, et vice versa.
Cela s'est avéré très utile dans la recherche d'informations multimodales et la classification d'images zero-shot. Sans entraînement spécial supplémentaire, CLIP a bien performé dans le classement d'images dans des catégories avec des étiquettes en langage naturel.

Le modèle d'embedding de texte dans le CLIP original était un réseau neuronal personnalisé avec seulement 63 millions de paramètres. Côté image, OpenAI a publié CLIP avec une sélection de modèles ResNet et ViT. Chaque modèle a été pré-entraîné pour sa modalité individuelle puis entraîné avec des images légendées pour produire des embeddings similaires pour les paires image-texte préparées.
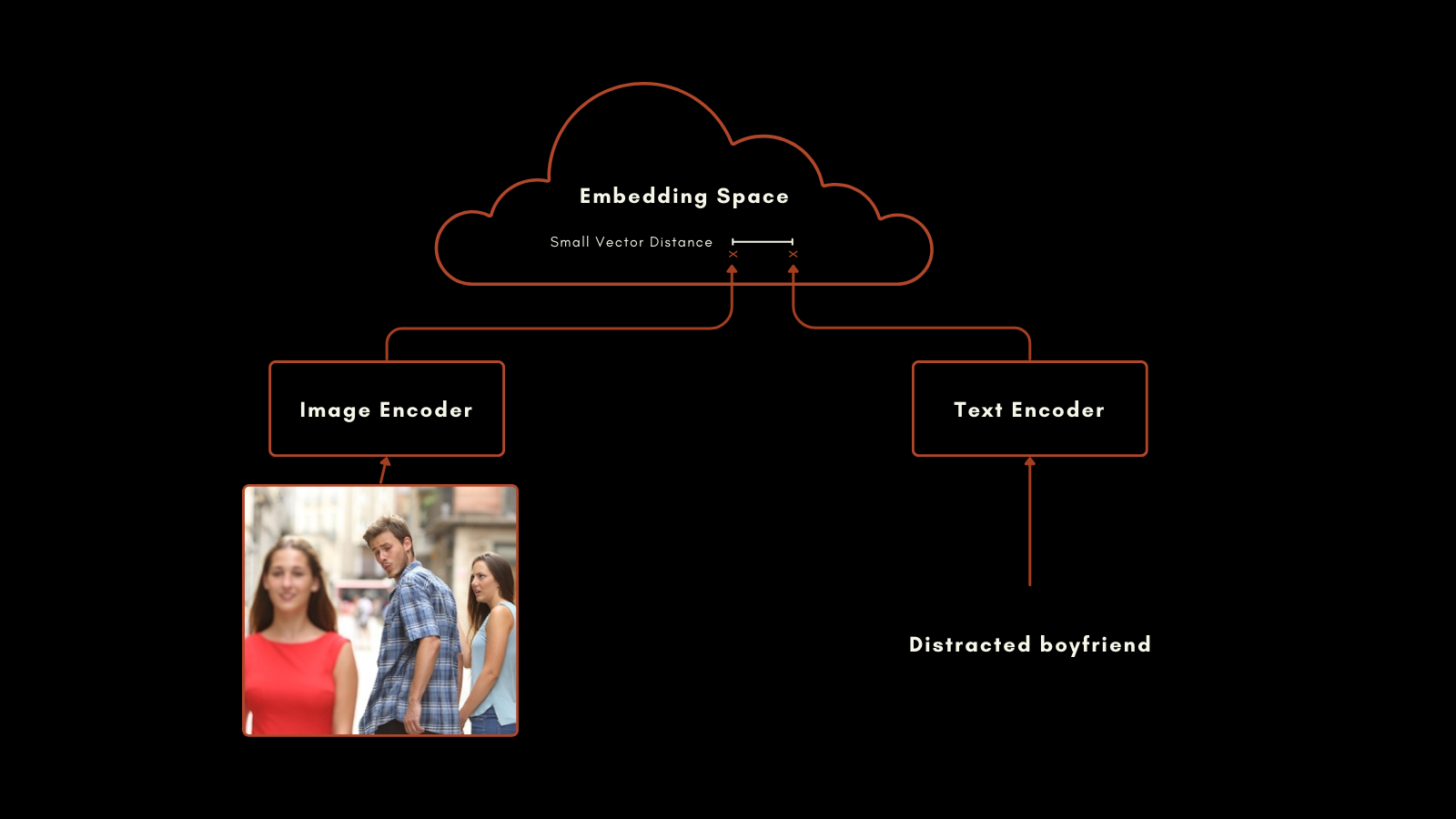
Cette approche a donné des résultats impressionnants. Particulièrement notable est sa performance en classification zero-shot. Par exemple, même si les données d'entraînement ne comprenaient pas d'images étiquetées d'astronautes, CLIP pouvait correctement identifier des photos d'astronautes basé sur sa compréhension des concepts connexes dans les textes et les images.
Cependant, le CLIP d'OpenAI présente deux inconvénients importants :
- Premièrement, sa capacité d'entrée de texte très limitée. Il peut prendre un maximum de 77 tokens en entrée, mais l'analyse empirique montre qu'en pratique il n'utilise pas plus de 20 tokens pour produire ses embeddings. Cela est dû au fait que CLIP a été entraîné à partir d'images avec des légendes, et les légendes ont tendance à être très courtes. Cela contraste avec les modèles d'embedding de texte actuels qui supportent plusieurs milliers de tokens.
- Deuxièmement, la performance de ses embeddings de texte dans les scénarios de recherche texte seul est très faible. Les légendes d'images sont un type de texte très limité, et ne reflètent pas la large gamme de cas d'utilisation qu'un modèle d'embedding de texte devrait supporter.
Dans la plupart des cas d'utilisation réels, la recherche texte seul et image-texte sont combinées ou au moins les deux sont disponibles pour les tâches. Maintenir un second modèle d'embeddings pour les tâches texte seul double effectivement la taille et la complexité de votre framework d'IA.
Le nouveau modèle de Jina AI traite directement ces problèmes, et jina-clip-v1 profite des progrès réalisés ces dernières années pour apporter des performances état de l'art aux tâches impliquant toutes les combinaisons de modalités texte et image.
tagPrésentation de Jina CLIP v1
Jina CLIP v1 conserve le schéma original de CLIP d'OpenAI : deux modèles co-entraînés pour produire une sortie dans le même espace d'embedding.
Pour l'encodage de texte, nous avons adapté l'architecture Jina BERT v2 utilisée dans les modèles Jina Embeddings v2. Cette architecture supporte une fenêtre d'entrée état de l'art de 8k tokens et produit des vecteurs de 768 dimensions, produisant des embeddings plus précis à partir de textes plus longs. C'est plus de 100 fois les 77 tokens d'entrée supportés dans le modèle CLIP original.
Pour les embeddings d'images, nous utilisons le dernier modèle de l'Académie de Pékin pour l'Intelligence Artificielle : le modèle EVA-02. Nous avons empiriquement comparé un certain nombre de modèles d'IA d'image, les testant dans des contextes cross-modaux avec un pré-entraînement similaire, et EVA-02 a clairement surpassé les autres. Il est également comparable à l'architecture Jina BERT en taille de modèle, de sorte que les charges de calcul pour les tâches de traitement d'image et de texte sont à peu près identiques.
Ces choix produisent des avantages importants pour les utilisateurs :
- De meilleures performances sur tous les benchmarks et toutes les combinaisons modales, et particulièrement des améliorations importantes dans les performances d'embedding texte seul.
- Les performances empiriquement supérieures d'
EVA-02à la fois dans les tâches image-texte et image seule, avec l'avantage supplémentaire de l'entraînement additionnel de Jina AI, améliorant les performances image seule. - Support pour des entrées de texte beaucoup plus longues. Le support d'entrée de 8k tokens de Jina Embeddings rend possible le traitement d'informations textuelles détaillées et leur corrélation avec des images.
- Une importante économie nette en espace, calcul, maintenance de code et complexité car ce modèle multimodal est très performant même dans des scénarios non multimodaux.
tagEntraînement
Une partie de notre recette pour l'IA multimodale haute performance réside dans nos données d'entraînement et notre procédure. Nous remarquons que la très courte longueur des textes utilisés dans les légendes d'images est la cause majeure des faibles performances texte seul dans les modèles de type CLIP, et notre entraînement est explicitement conçu pour remédier à cela.
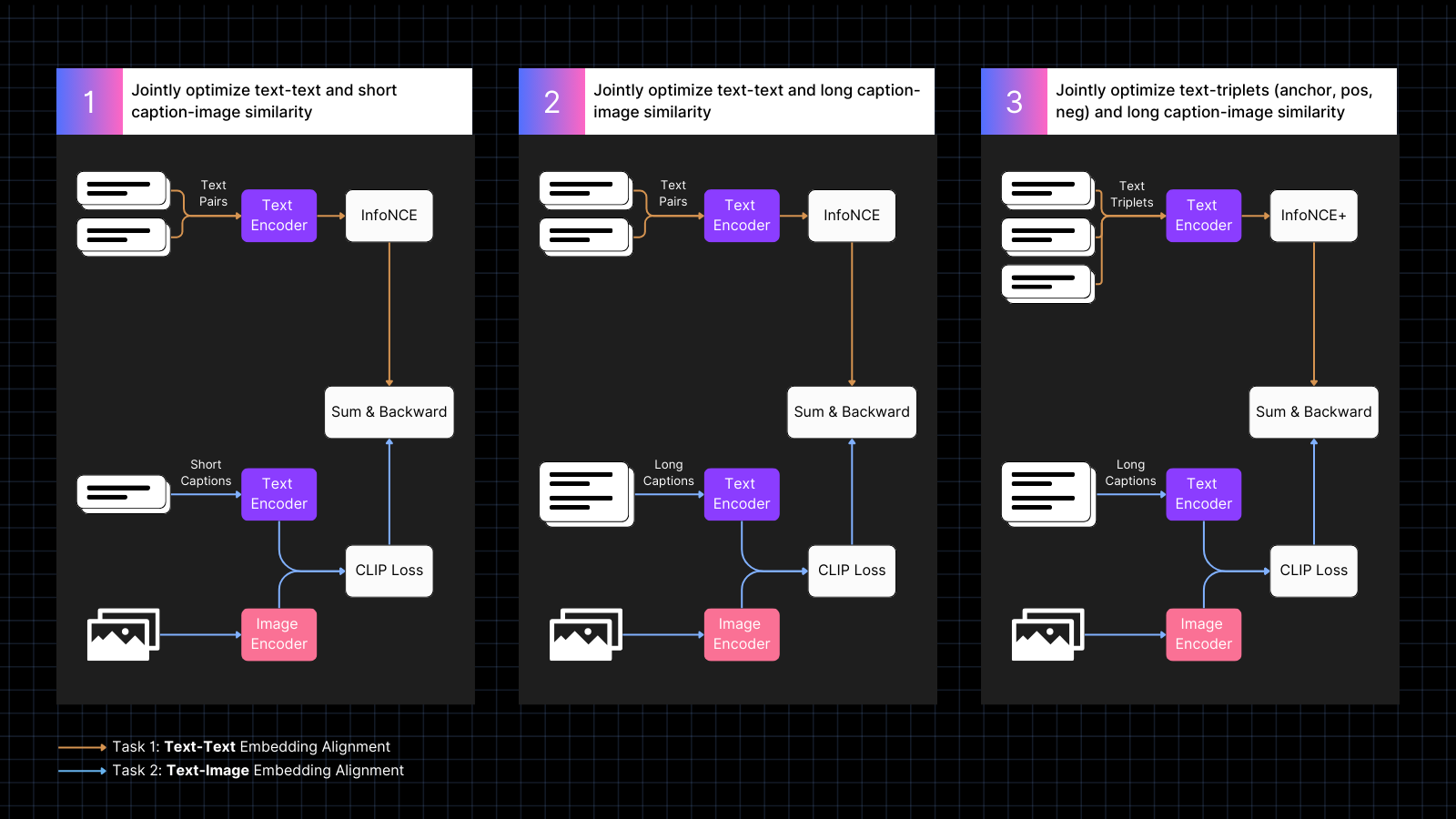
L'entraînement se déroule en trois étapes :
- Utiliser des données d'images légendées pour apprendre à aligner les embeddings d'image et de texte, entrelacées avec des paires de textes ayant des significations similaires. Ce co-entraînement optimise conjointement les deux types de tâches. Les performances texte seul du modèle diminuent pendant cette phase, mais pas autant que si nous avions entraîné uniquement avec des paires image-texte.
- Entraîner en utilisant des données synthétiques qui alignent les images avec des textes plus longs, générés par un modèle d'IA, qui décrivent l'image. Continuer l'entraînement avec des paires texte seul en même temps. Pendant cette phase, le modèle apprend à prêter attention à des textes plus longs en conjonction avec des images.
- Utiliser des triplets de texte avec des négatifs difficiles pour améliorer davantage les performances texte seul en apprenant à faire des distinctions sémantiques plus fines. En même temps, continuer l'entraînement en utilisant des paires synthétiques d'images et de longs textes. Pendant cette phase, les performances texte seul s'améliorent dramatiquement sans que le modèle ne perde ses capacités image-texte.
Pour plus d'informations sur les détails de l'entraînement et l'architecture du modèle, veuillez lire notre article récent :
tagNouvel état de l'art en embeddings multimodaux
Nous avons évalué les performances de Jina CLIP v1 sur des tâches textuelles uniquement, des tâches d'images uniquement et des tâches cross-modales impliquant les deux modalités d'entrée. Nous avons utilisé le benchmark de recherche MTEB pour évaluer les performances textuelles. Pour les tâches d'images uniquement, nous avons utilisé le benchmark CIFAR-100. Pour les tâches cross-modales, nous évaluons sur Flickr8k, Flickr30K, et MSCOCO Captions, qui sont inclus dans le CLIP Benchmark.
Les résultats sont résumés dans le tableau ci-dessous :
| Model | Text-Text | Text-to-Image | Image-to-Text | Image-Image |
|---|---|---|---|---|
| jina-clip-v1 | 0.429 | 0.899 | 0.803 | 0.916 |
| openai-clip-vit-b16 | 0.162 | 0.881 | 0.756 | 0.816 |
| % increase vs OpenAI CLIP |
165% | 2% | 6% | 12% |
Vous pouvez voir d'après ces résultats que jina-clip-v1 surpasse le CLIP original d'OpenAI dans toutes les catégories, et est nettement meilleur dans la recherche de texte uniquement et d'images uniquement. En moyenne sur toutes les catégories, c'est une amélioration de 46 % des performances.
Vous pouvez trouver une évaluation plus détaillée dans notre récent article.
tagPremiers pas avec l'API Embeddings
Vous pouvez facilement intégrer Jina CLIP v1 dans vos applications en utilisant l'API Jina Embeddings.
Le code ci-dessous vous montre comment appeler l'API pour obtenir des embeddings pour des textes et des images, en utilisant le package requests en Python. Il transmet une chaîne de texte et une URL d'image au serveur Jina AI et renvoie les deux encodages.
<YOUR_JINA_AI_API_KEY> par une clé API Jina activée. Vous pouvez obtenir une clé d'essai avec un million de tokens gratuits sur la page web Jina Embeddings.import requests
import numpy as np
from numpy.linalg import norm
cos_sim = lambda a,b: (a @ b.T) / (norm(a)*norm(b))
url = 'https://api.jina.ai/v1/embeddings'
headers = {
'Content-Type': 'application/json',
'Authorization': 'Bearer <YOUR_JINA_AI_API_KEY>'
}
data = {
'input': [
{"text": "Bridge close-shot"},
{"url": "https://fastly.picsum.photos/id/84/1280/848.jpg?hmac=YFRYDI4UsfbeTzI8ZakNOR98wVU7a-9a2tGF542539s"}],
'model': 'jina-clip-v1',
'encoding_type': 'float'
}
response = requests.post(url, headers=headers, json=data)
sim = cos_sim(np.array(response.json()['data'][0]['embedding']), np.array(response.json()['data'][1]['embedding']))
print(f"Cosine text<->image: {sim}")
tagIntégration avec les principaux frameworks LLM
Jina CLIP v1 est déjà disponible pour LlamaIndex et LangChain :
- LlamaIndex : Utilisez
JinaEmbeddingavec la classe de baseMultimodalEmbedding, et invoquezget_image_embeddingsouget_text_embeddings. - LangChain : Utilisez
JinaEmbeddings, et invoquezembed_imagesouembed_documents.
tagTarification
Les entrées de texte et d'image sont facturées par consommation de tokens.
Pour le texte en anglais, nous avons calculé empiriquement qu'en moyenne vous aurez besoin de 1,1 tokens pour chaque mot.
Pour les images, nous comptons le nombre de tuiles de 224x224 pixels nécessaires pour couvrir votre image. Certaines de ces tuiles peuvent être partiellement vides mais comptent de la même manière. Chaque tuile coûte 1 000 tokens à traiter.
Exemple
Pour une image de dimensions 750x500 pixels :
- L'image est divisée en tuiles de 224x224 pixels.
- Pour calculer le nombre de tuiles, prenez la largeur en pixels et divisez par 224, puis arrondissez à l'entier supérieur.
750/224 ≈ 3,35 → 4 - Répétez pour la hauteur en pixels :
500/224 ≈ 2,23 → 3
- Pour calculer le nombre de tuiles, prenez la largeur en pixels et divisez par 224, puis arrondissez à l'entier supérieur.
- Le nombre total de tuiles requises dans cet exemple est :
4 (horizontal) x 3 (vertical) = 12 tuiles - Le coût sera de 12 x 1 000 = 12 000 tokens
tagSupport Entreprise
Nous introduisons un nouveau bénéfice pour les utilisateurs qui achètent le plan Production Deployment avec 11 milliards de tokens. Cela comprend :
- Trois heures de consultation avec nos équipes produit et ingénierie pour discuter de vos cas d'utilisation et besoins spécifiques.
- Un notebook Python personnalisé conçu pour votre cas d'utilisation RAG (Retrieval-Augmented Generation) ou de recherche vectorielle, démontrant comment intégrer les modèles de Jina AI dans votre application.
- Attribution d'un responsable de compte et support par email prioritaire pour s'assurer que vos besoins sont satisfaits rapidement et efficacement.
tagJina CLIP v1 Open Source sur Hugging Face
Jina AI s'engage pour une base de recherche open source, et dans ce but, nous rendons ce modèle disponible gratuitement sous une licence Apache 2.0, sur Hugging Face.
Vous pouvez trouver du code exemple pour télécharger et exécuter ce modèle sur votre propre système ou installation cloud sur la page du modèle Hugging Face pour jina-clip-v1.

tagRésumé
Le dernier modèle de Jina AI — jina-clip-v1 — représente une avancée significative dans les modèles d'embedding multimodaux, offrant des gains de performance substantiels par rapport au CLIP d'OpenAI. Avec des améliorations notables dans les tâches de recherche texte uniquement et image uniquement, ainsi que des performances compétitives dans les tâches texte-vers-image et image-vers-texte, il s'impose comme une solution prometteuse pour les cas d'utilisation d'embeddings complexes.
Ce modèle ne prend actuellement en charge que les textes en anglais en raison de contraintes de ressources. Nous travaillons à étendre ses capacités à d'autres langues.




