



Aujourd'hui, nous sommes ravis d'annoncer jina-embeddings-v3, un modèle d'embedding de texte de pointe avec 570 millions de paramètres. Il atteint des performances état de l'art sur les données multilingues et les tâches de recherche à contexte long, supportant une longueur d'entrée jusqu'à 8192 tokens. Le modèle dispose d'adaptateurs Low-Rank Adaptation (LoRA) spécifiques aux tâches, lui permettant de générer des embeddings de haute qualité pour diverses tâches dont la recherche requête-document, le clustering, la classification et la correspondance de texte.
Dans les évaluations sur MTEB English, Multilingual et LongEmbed, jina-embeddings-v3 surpasse les derniers embeddings propriétaires d'OpenAI et Cohere sur les tâches en anglais, tout en dépassant également multilingual-e5-large-instruct sur toutes les tâches multilingues. Avec une dimension de sortie par défaut de 1024, les utilisateurs peuvent arbitrairement tronquer les dimensions d'embedding jusqu'à 32 sans sacrifier les performances, grâce à l'intégration du Matryoshka Representation Learning (MRL).


jina-embeddings-v2-(zh/es/de) fait référence à notre suite de modèles bilingues, qui n'a été testée que sur les tâches monolingues et interlingues en chinois, espagnol et allemand, excluant toutes les autres langues. De plus, nous ne rapportons pas les scores pour openai-text-embedding-3-large et cohere-embed-multilingual-v3.0, car ces modèles n'ont pas été évalués sur l'ensemble complet des tâches MTEB multilingues et interlingues.
baai-bge-m3 et l'approche basée sur ALiBi utilisée dans jina-embeddings-v2.À sa sortie le 18 septembre 2024, jina-embeddings-v3 est le meilleur modèle multilingue et se classe 2ème sur le classement MTEB English pour les modèles de moins d'un milliard de paramètres. v3 prend en charge 89 langues au total, dont 30 langues avec les meilleures performances : arabe, bengali, chinois, danois, néerlandais, anglais, finnois, français, géorgien, allemand, grec, hindi, indonésien, italien, japonais, coréen, letton, norvégien, polonais, portugais, roumain, russe, slovaque, espagnol, suédois, thaï, turc, ukrainien, ourdou et vietnamien.
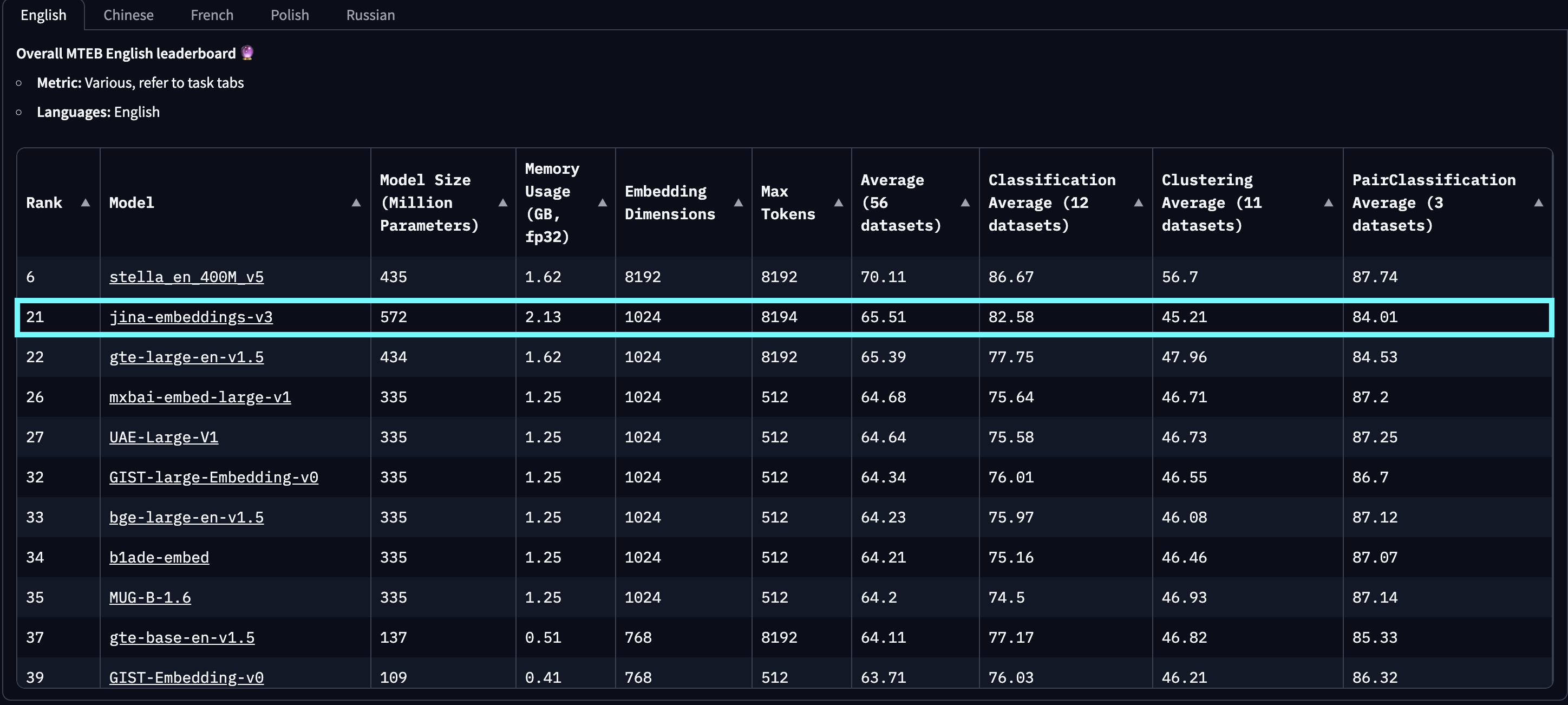

jina-embeddings-v2. Ce graphique a été créé en sélectionnant les 100 meilleurs modèles d'embedding du classement MTEB, excluant ceux sans information de taille, généralement des modèles propriétaires ou fermés. Les soumissions identifiées comme du trolling évident ont également été filtrées.De plus, comparé aux embeddings basés sur les LLM qui ont récemment attiré l'attention, comme e5-mistral-7b-instruct, qui a une taille de paramètres de 7,1 milliards (12x plus grand) et une dimension de sortie de 4096 (4x plus grande) mais n'offre qu'une amélioration de 1% sur les tâches MTEB en anglais, jina-embeddings-v3 est une solution beaucoup plus rentable, la rendant plus adaptée à la production et au calcul en périphérie.
tagArchitecture du Modèle
| Caractéristique | Description |
|---|---|
| Base | jina-XLM-RoBERTa |
| Paramètres Base | 559M |
| Paramètres avec LoRA | 572M |
| Tokens d'entrée max | 8192 |
| Dimensions de sortie max | 1024 |
| Couches | 24 |
| Vocabulaire | 250K |
| Langues prises en charge | 89 |
| Attention | FlashAttention2, fonctionne aussi sans |
| Pooling | Mean pooling |
L'architecture de jina-embeddings-v3 est présentée dans la figure ci-dessous. Pour implémenter l'architecture de base, nous avons adapté le modèle XLM-RoBERTa avec plusieurs modifications clés : (1) permettre l'encodage efficace de longues séquences de texte, (2) permettre l'encodage d'embeddings spécifiques à la tâche, et (3) améliorer l'efficacité globale du modèle avec les techniques les plus récentes. Nous continuons à utiliser le tokenizer original de XLM-RoBERTa. Bien que jina-embeddings-v3, avec ses 570 millions de paramètres, soit plus grand que jina-embeddings-v2 avec ses 137 millions, il reste beaucoup plus petit que les modèles d'embedding fine-tunés à partir des LLMs.

jina-XLM-RoBERTa, avec cinq adaptateurs LoRA pour quatre tâches différentes.L'innovation clé dans jina-embeddings-v3 est l'utilisation des adaptateurs LoRA. Cinq adaptateurs LoRA spécifiques aux tâches sont introduits pour optimiser les embeddings pour quatre tâches. L'entrée du modèle se compose de deux parties : le texte (le long document à encoder) et la tâche. jina-embeddings-v3 prend en charge quatre tâches et implémente cinq adaptateurs au choix : retrieval.query et retrieval.passage pour les embeddings de requêtes et de passages dans les tâches de recherche asymétrique, separation pour les tâches de clustering, classification pour les tâches de classification, et text-matching pour les tâches impliquant la similarité sémantique, comme STS ou la recherche symétrique. Les adaptateurs LoRA représentent moins de 3 % du total des paramètres, ajoutant très peu de surcharge au calcul.
Pour améliorer davantage les performances et réduire la consommation de mémoire, nous intégrons FlashAttention 2, prenons en charge le checkpointing des activations et utilisons le framework DeepSpeed pour un entraînement distribué efficace.
tagPour Commencer
tagVia l'API Search Foundation de Jina AI
La façon la plus simple d'utiliser jina-embeddings-v3 est de visiter la page d'accueil de Jina AI et de naviguer vers la section API Search Foundation. À partir d'aujourd'hui, ce modèle est défini par défaut pour tous les nouveaux utilisateurs. Vous pouvez explorer différents paramètres et fonctionnalités directement à partir de là.
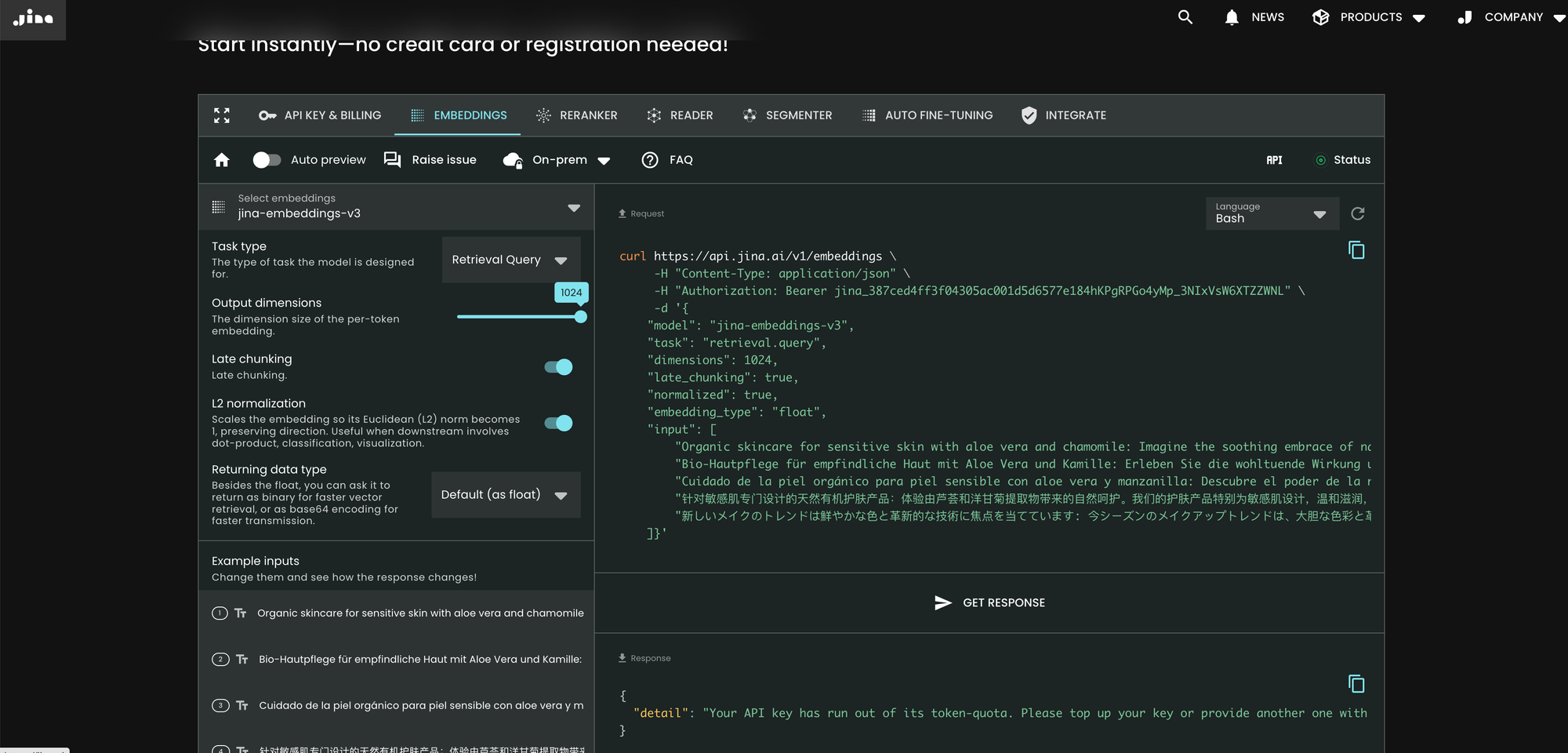
curl https://api.jina.ai/v1/embeddings \
-H "Content-Type: application/json" \
-H "Authorization: Bearer jina_387ced4ff3f04305ac001d5d6577e184hKPgRPGo4yMp_3NIxVsW6XTZZWNL" \
-d '{
"model": "jina-embeddings-v3",
"task": "text-matching",
"dimensions": 1024,
"late_chunking": true,
"input": [
"Organic skincare for sensitive skin with aloe vera and chamomile: ...",
"Bio-Hautpflege für empfindliche Haut mit Aloe Vera und Kamille: Erleben Sie die wohltuende Wirkung...",
"Cuidado de la piel orgánico para piel sensible con aloe vera y manzanilla: Descubre el poder ...",
"针对敏感肌专门设计的天然有机护肤产品:体验由芦荟和洋甘菊提取物带来的自然呵护。我们的护肤产品特别为敏感肌设计,...",
"新しいメイクのトレンドは鮮やかな色と革新的な技術に焦点を当てています: 今シーズンのメイクアップトレンドは、大胆な色彩と革新的な技術に注目しています。..."
]}'
Par rapport à v2, v3 introduit trois nouveaux paramètres dans l'API : task, dimensions et late_chunking.
Paramètre task
Le paramètre task est crucial et doit être défini en fonction de la tâche en aval. Les embeddings résultants seront optimisés pour cette tâche spécifique. Pour plus de détails, référez-vous à la liste ci-dessous.
Valeur de task |
Description de la tâche |
|---|---|
retrieval.passage |
Embedding des documents dans une tâche de recherche requête-document |
retrieval.query |
Embedding des requêtes dans une tâche de recherche requête-document |
separation |
Clustering de documents, visualisation d'un corpus |
classification |
Classification de texte |
text-matching |
(Par défaut) Similarité sémantique de texte, recherche symétrique générale, recommandation, recherche d'éléments similaires, déduplication |
Notez que l'API ne génère pas d'abord un meta-embedding générique pour ensuite l'adapter avec un MLP fine-tuné additionnel. Au lieu de cela, elle insère l'adaptateur LoRA spécifique à la tâche dans chaque couche transformeur (un total de 24 couches) et effectue l'encodage en une seule fois. Plus de détails peuvent être trouvés dans notre article arXiv.
Paramètre dimensions
Le paramètre dimensions permet aux utilisateurs de choisir un compromis entre l'efficacité spatiale et les performances au moindre coût. Grâce à la technique MRL utilisée dans jina-embeddings-v3, vous pouvez réduire les dimensions des embeddings autant que vous le souhaitez (même jusqu'à une seule dimension !). Des embeddings plus petits sont plus économes en stockage pour les bases de données vectorielles, et leur coût en performance peut être estimé à partir de la figure ci-dessous.

Paramètre late_chunking
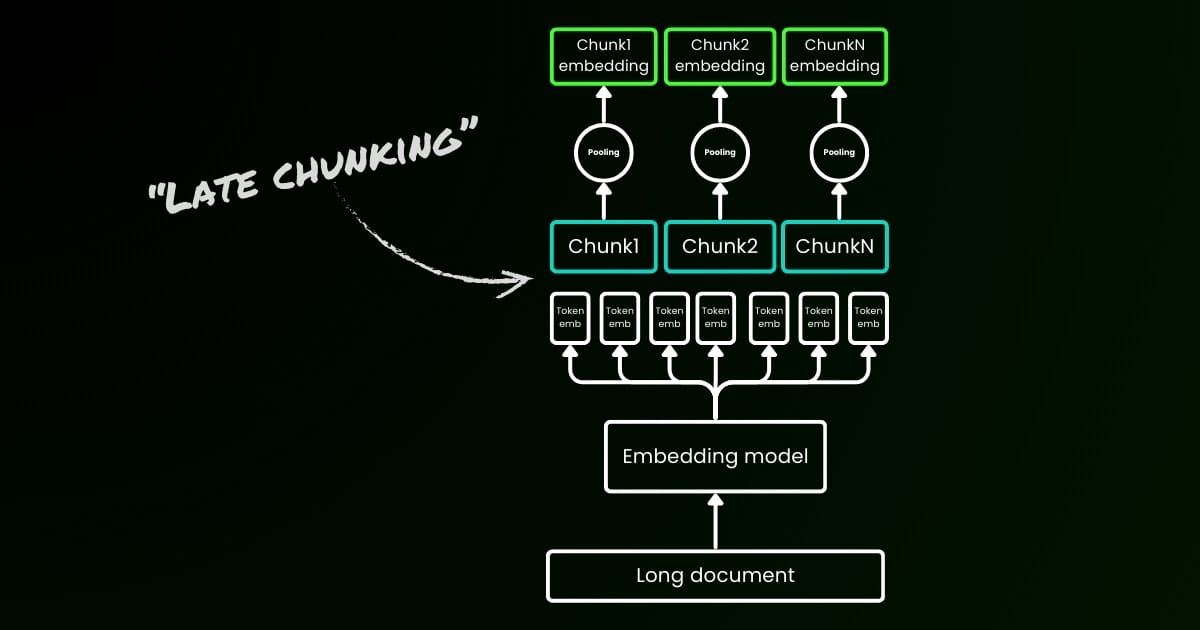
Enfin, le paramètre late_chunking contrôle l'utilisation de la nouvelle méthode de découpage que nous avons introduite le mois dernier pour l'encodage d'un lot de phrases. Lorsqu'il est défini sur true, notre API concaténera toutes les phrases dans le champ input et les alimentera comme une seule chaîne au modèle. En d'autres termes, nous traitons les phrases en entrée comme si elles provenaient originellement de la même section, paragraphe ou document. En interne, le modèle encode cette longue chaîne concaténée puis effectue le découpage tardif, retournant une liste d'embeddings qui correspond à la taille de la liste d'entrée. Chaque embedding dans la liste est donc conditionné par les embeddings précédents.
Du point de vue de l'utilisateur, la définition de late_chunking ne change pas le format d'entrée ou de sortie. Vous ne remarquerez qu'un changement dans les valeurs des embeddings, car elles sont maintenant calculées en fonction de tout le contexte précédent plutôt qu'indépendamment. Ce qu'il est important de savoir lors de l'utilisation delate_chunking=True signifie que le nombre total de tokens (en additionnant tous les tokens dans input) par requête est limité à 8192, qui est la longueur maximale de contexte autorisée pour jina-embeddings-v3. Lorsque late_chunking=False, il n'y a pas une telle restriction; le nombre total de tokens est uniquement soumis à la limite de débit de l'API Embedding.
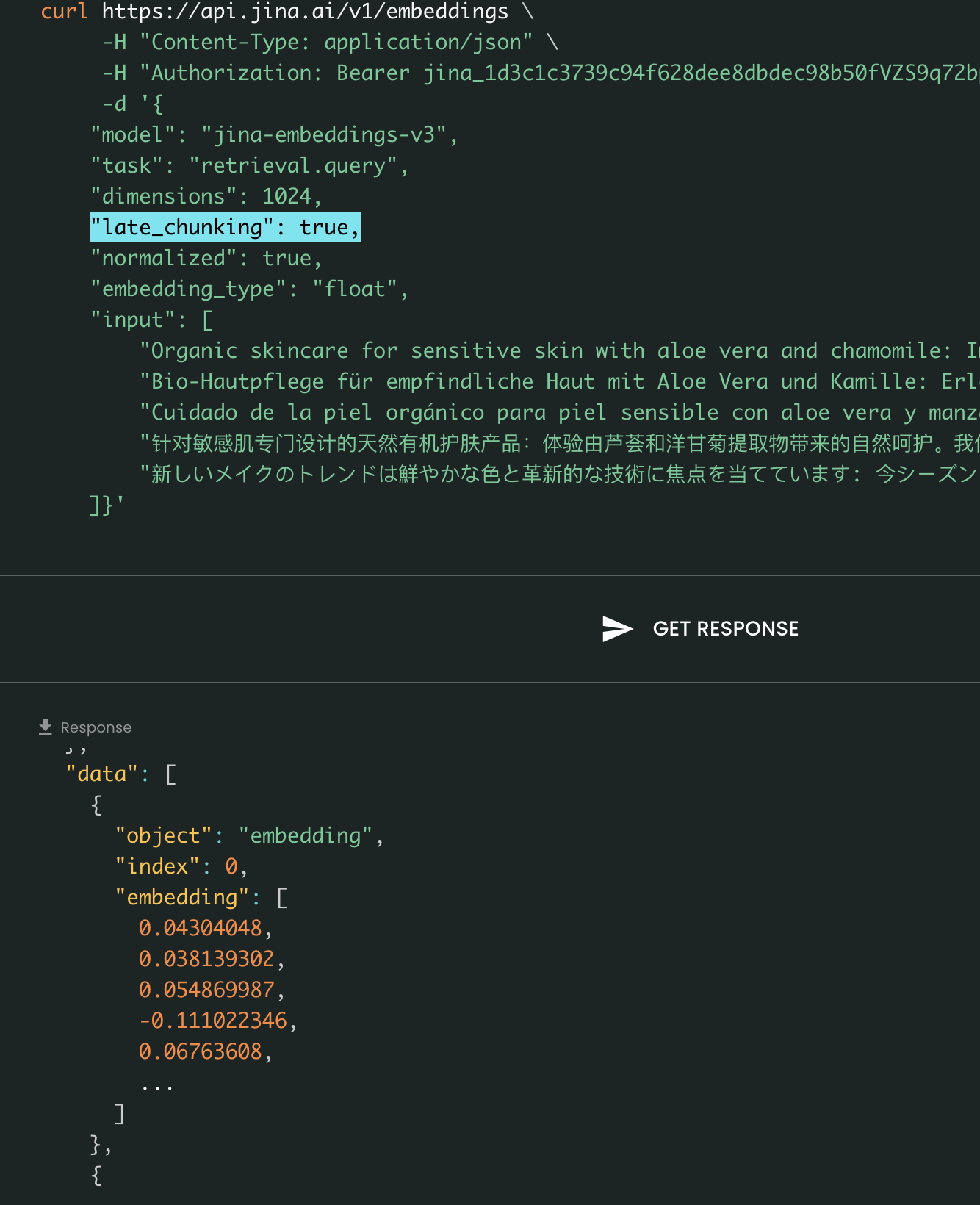
Late Chunking activé vs désactivé : Le format d'entrée et de sortie reste le même, la seule différence étant les valeurs d'embedding. Lorsque late_chunking est activé, les embeddings sont influencés par tout le contexte précédent dans input, alors que sans lui, les embeddings sont calculés indépendamment.
tagVia Azure & AWS
jina-embeddings-v3 est maintenant disponible sur AWS SageMaker et Azure Marketplace.


Si vous devez l'utiliser au-delà de ces plateformes ou sur site au sein de votre entreprise, notez que le modèle est sous licence CC BY-NC 4.0. Pour toute demande d'utilisation commerciale, n'hésitez pas à nous contacter.
tagVia les bases de données vectorielles & partenaires
Nous collaborons étroitement avec les fournisseurs de bases de données vectorielles comme Pinecone, Qdrant et Milvus, ainsi qu'avec les frameworks d'orchestration LLM comme LlamaIndex, Haystack et Dify. Au moment de la sortie, nous sommes heureux d'annoncer que Pinecone, Qdrant, Milvus et Haystack ont déjà intégré le support de jina-embeddings-v3, y compris les trois nouveaux paramètres : task, dimensions et late_chunking. Les autres partenaires qui ont déjà intégré l'API v2 devraient également supporter v3 en changeant simplement le nom du modèle en jina-embeddings-v3. Cependant, ils ne prennent peut-être pas encore en charge les nouveaux paramètres introduits dans v3.
Via Pinecone

Via Qdrant

Via Milvus

Via Haystack

tagConclusion
En octobre 2023, nous avons publié jina-embeddings-v2-base-en, le premier modèle d'embedding open-source au monde avec une longueur de contexte de 8K. C'était le seul modèle d'embedding de texte qui supportait un long contexte et égalait le text-embedding-ada-002 d'OpenAI. Aujourd'hui, après une année d'apprentissage, d'expérimentation et de leçons précieuses, nous sommes fiers de publier jina-embeddings-v3 — une nouvelle frontière dans les modèles d'embedding de texte et une étape importante pour notre entreprise.
Avec cette version, nous continuons d'exceller dans ce pour quoi nous sommes connus : les embeddings à long contexte, tout en répondant également à la fonctionnalité la plus demandée par l'industrie et la communauté — les embeddings multilingues. En même temps, nous poussons les performances vers de nouveaux sommets. Avec de nouvelles fonctionnalités telles que le LoRA spécifique aux tâches, le MRL et le late chunking, nous pensons que jina-embeddings-v3 servira véritablement de modèle d'embedding fondamental pour diverses applications, y compris le RAG, les agents et plus encore. Comparé aux embeddings récents basés sur les LLM comme NV-embed-v1/v2, notre modèle est très efficace en termes de paramètres, le rendant beaucoup plus adapté à la production et aux appareils edge.
À l'avenir, nous prévoyons de nous concentrer sur l'évaluation et l'amélioration des performances de jina-embeddings-v3 sur les langues à ressources limitées et d'analyser davantage les échecs systématiques causés par la disponibilité limitée des données. De plus, les poids du modèle de jina-embeddings-v3, ainsi que ses fonctionnalités innovantes et ses points forts, serviront de base pour nos prochains modèles, y compris jina-clip-v2,jina-reranker-v3, et reader-lm-v2.
