
La mise en contexte (grounding) est absolument essentielle pour les applications GenAI.
Vous avez probablement vu de nombreux outils, prompts et pipelines RAG conçus pour améliorer la factualité des LLMs depuis 2023. Pourquoi ? Parce que le principal obstacle empêchant les entreprises de déployer les LLMs auprès de millions d'utilisateurs est la confiance : La réponse est-elle authentique ou est-ce une simple hallucination du modèle ? C'est un problème pour toute l'industrie, et Jina AI travaille très dur pour le résoudre. Aujourd'hui, avec la nouvelle fonctionnalité de recherche contextuelle de Jina Reader, vous pouvez simplement utiliser https://s.jina.ai/YOUR_SEARCH_QUERY pour rechercher les connaissances les plus récentes sur le web. Avec cela, vous êtes un pas plus près d'améliorer la factualité des LLMs, rendant leurs réponses plus fiables et utiles.

API, démo disponible sur la page produit
tagLe Problème de Factualité des LLMs
Nous savons tous que les LLMs peuvent inventer des choses et nuire à la confiance des utilisateurs. Les LLMs peuvent dire des choses qui ne sont pas factuelles (aussi appelées hallucinations), particulièrement concernant des sujets qu'ils n'ont pas appris pendant leur entraînement. Cela peut être soit de nouvelles informations créées depuis l'entraînement, soit des connaissances de niche qui ont été "marginalisées" pendant l'entraînement.
Par conséquent, pour des questions comme "Quel temps fait-il aujourd'hui ?" ou "Qui a gagné l'Oscar de la meilleure actrice cette année ?", le modèle répondra soit "Je ne sais pas" soit donnera des informations obsolètes.
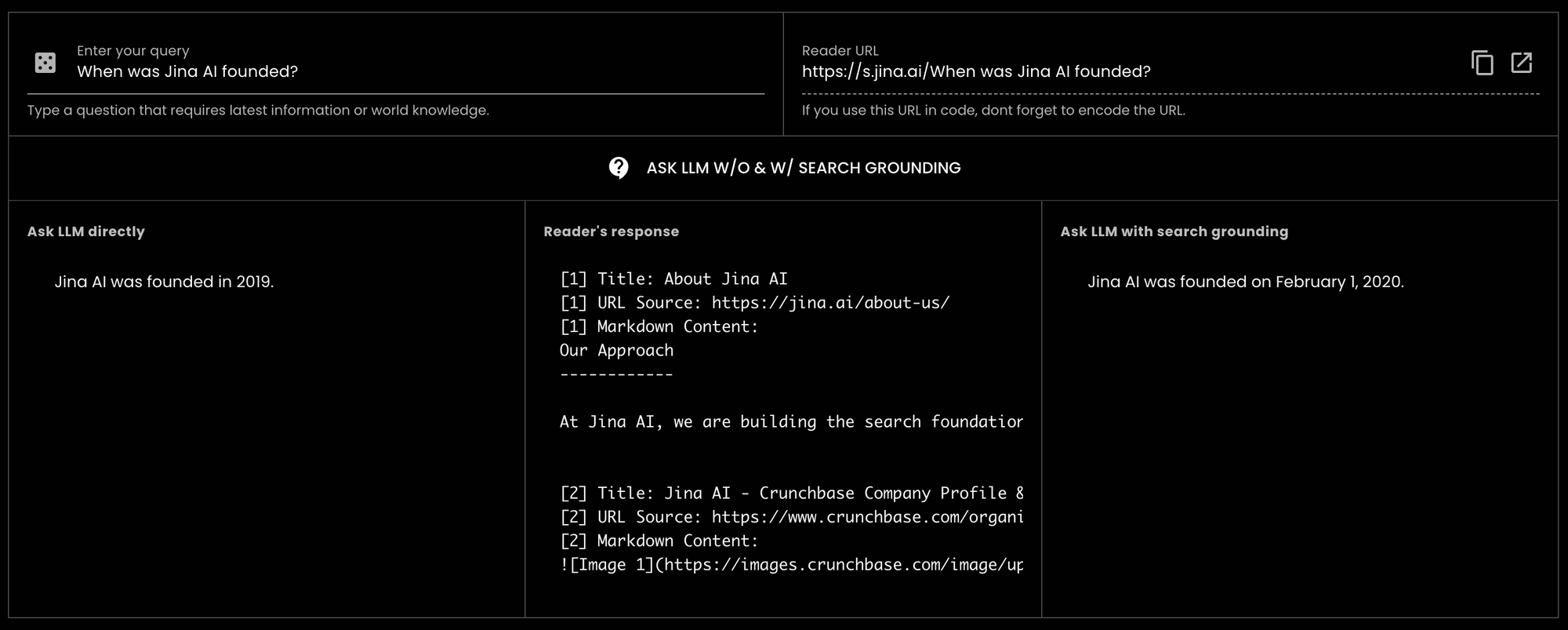
GPT-3.5-turbo "Quand a été fondée Jina AI ?" et reçu une réponse incorrecte. Cependant, en utilisant Reader pour la recherche contextuelle, le même LLM a pu fournir la bonne réponse. En fait, il était précis jusqu'à la date exacte.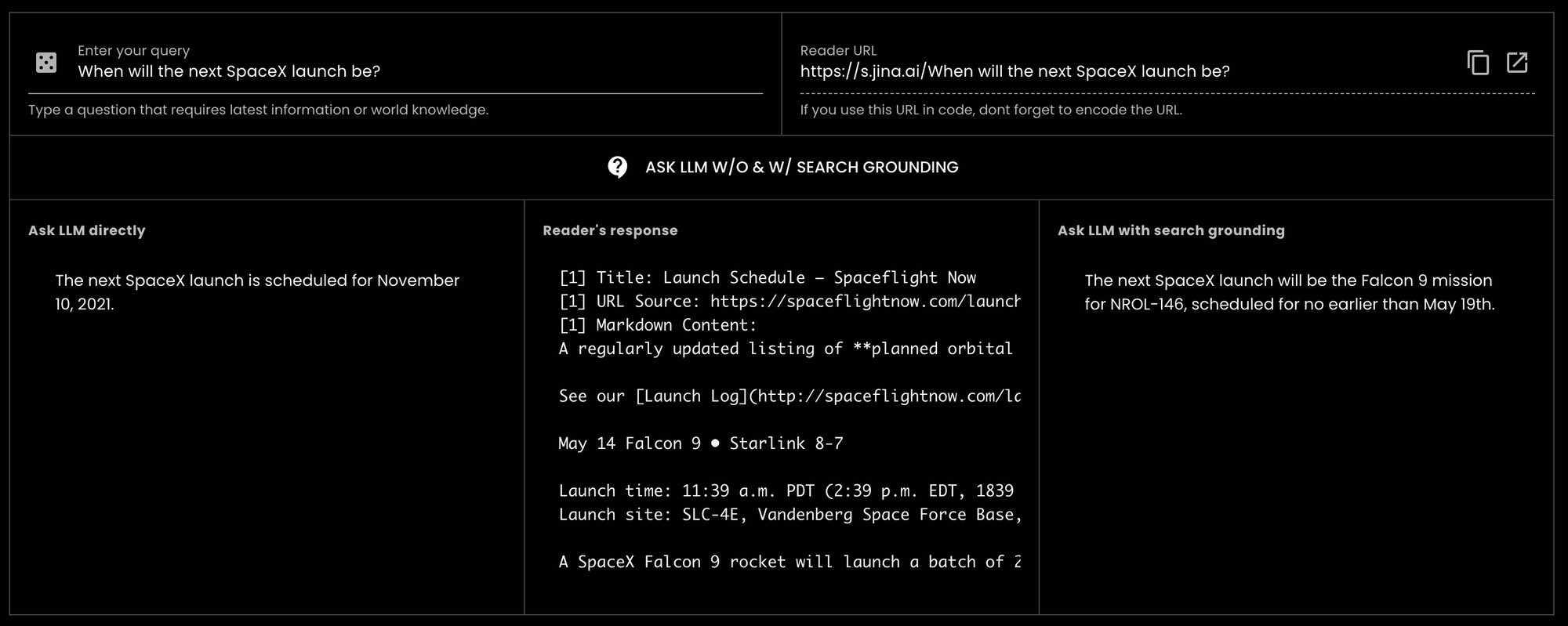
GPT-3.5-turbo "Quand aura lieu le prochain lancement SpaceX ?" (aujourd'hui est le 14 mai 2024) et le modèle a répondu avec de vieilles informations datant de 2021.tagComment Jina Reader Aide à une Meilleure Mise en Contexte
Auparavant, les utilisateurs pouvaient facilement préfixer https://r.jina.ai pour lire le contenu texte et image d'une URL particulière dans un format compatible LLM et l'utiliser pour la vérification contextuelle et la vérification des faits. Depuis sa première sortie le 15 avril, nous avons servi plus de 18 millions de requêtes dans le monde, suggérant sa popularité.
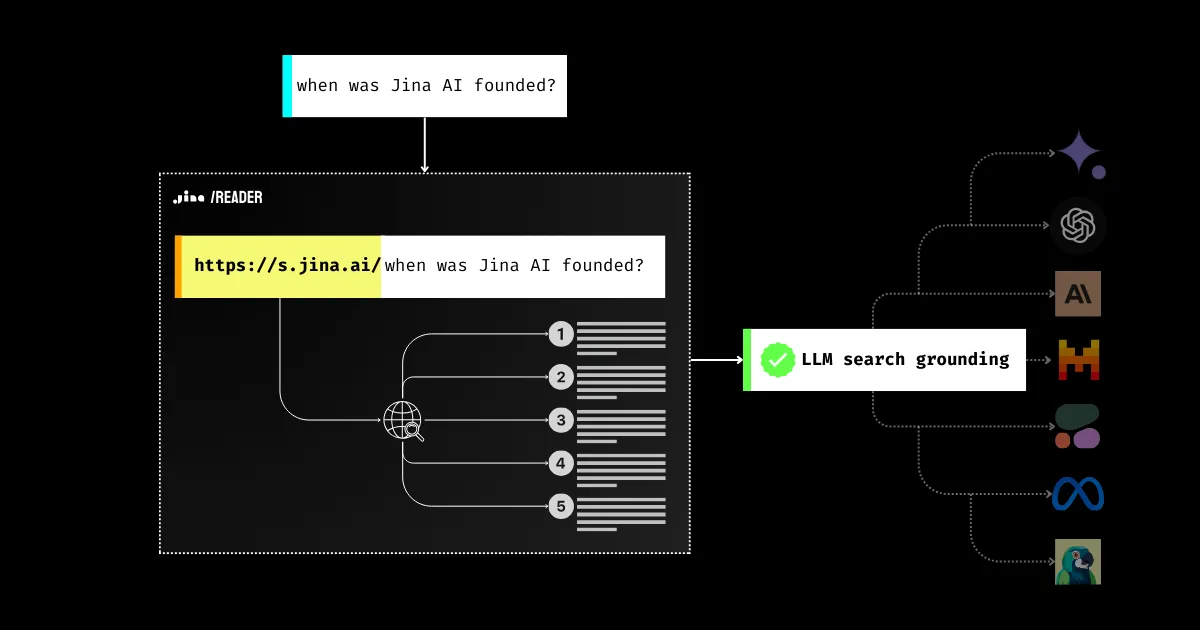
Aujourd'hui, nous sommes ravis d'aller plus loin en introduisant l'API de recherche contextuelle https://s.jina.ai. En le préfixant simplement avant votre requête, Reader recherchera sur le web et récupérera les 5 meilleurs résultats. Chaque résultat inclut un titre, du markdown compatible LLM (contenu complet ! pas un résumé), et une URL qui permet d'attribuer la source. Voici un exemple ci-dessous, vous êtes également encouragé à essayer notre démo en direct ici.
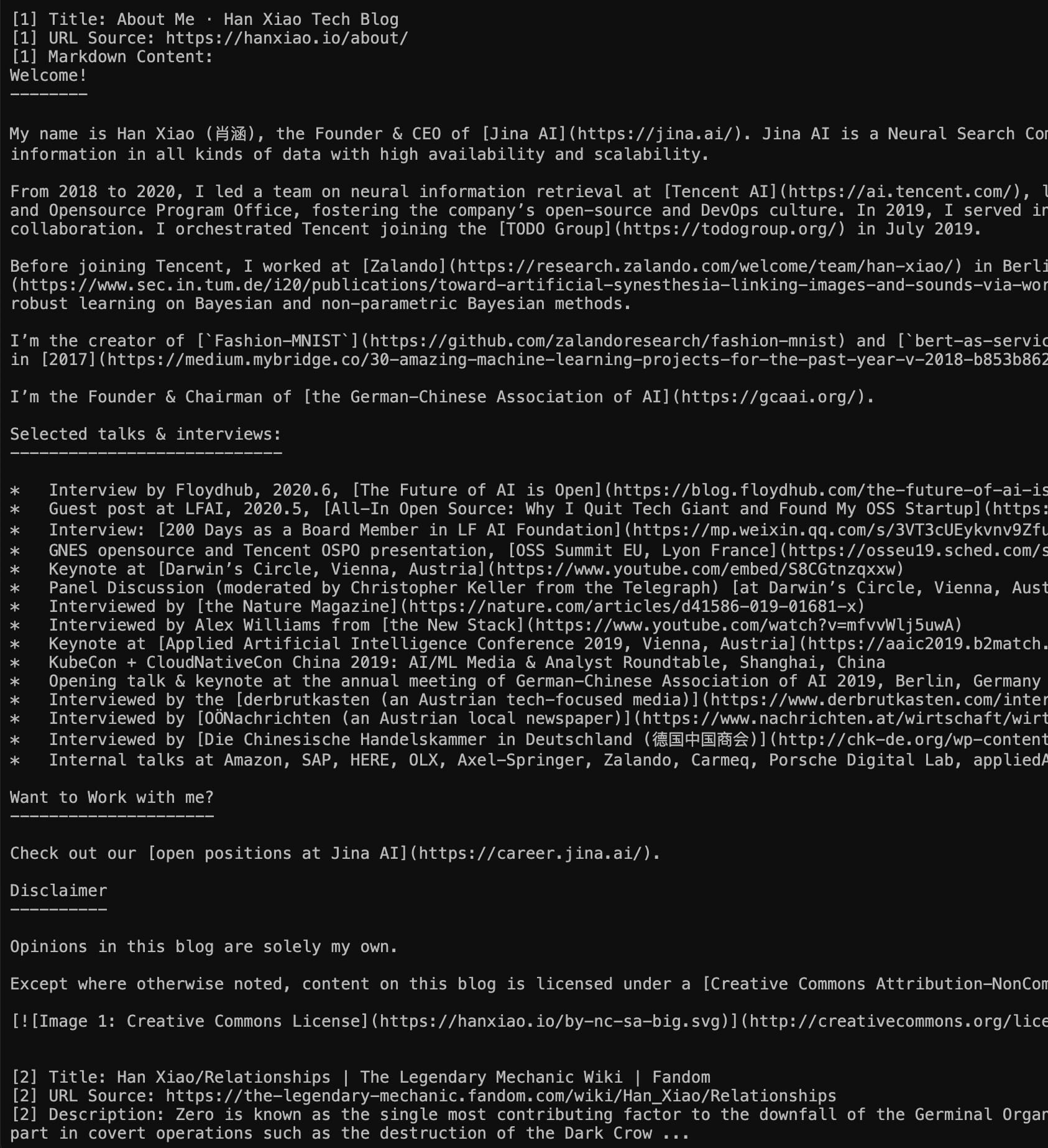
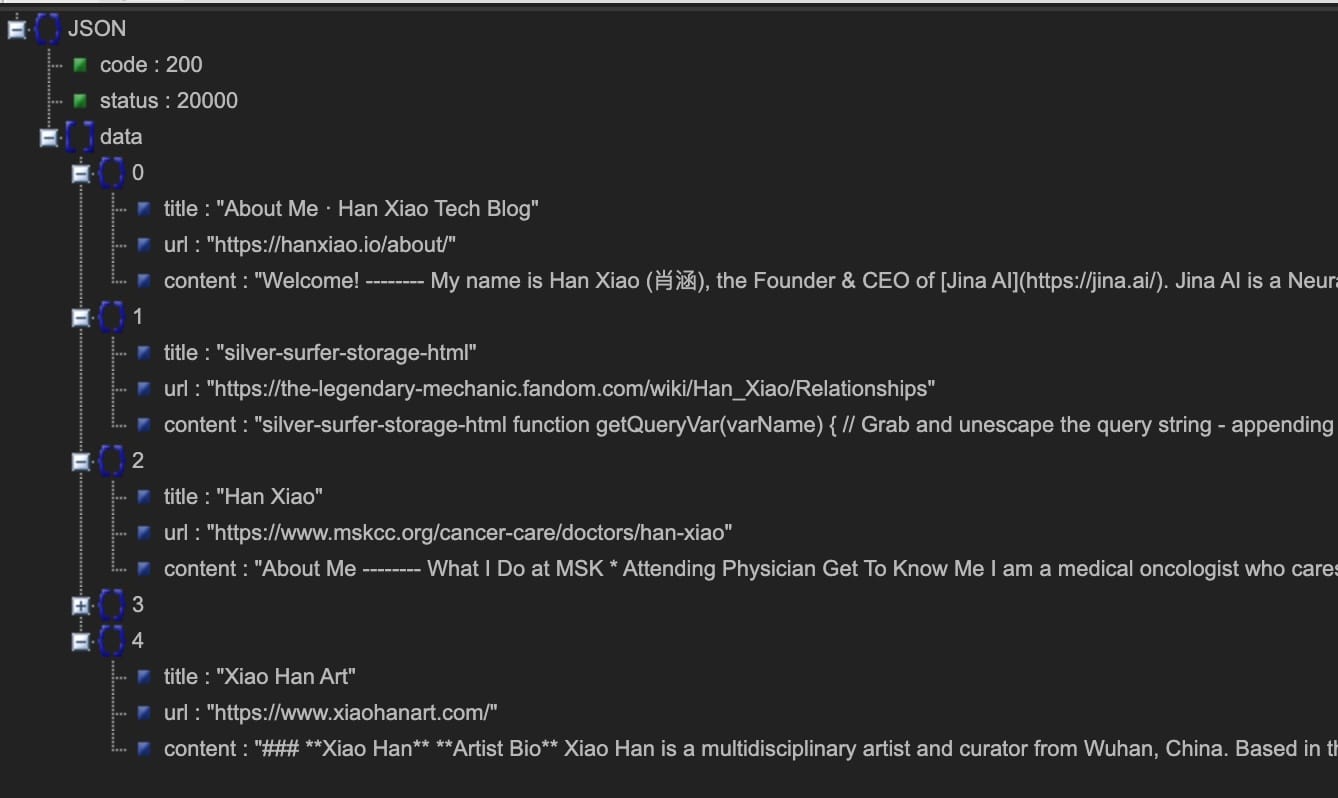
Gauche : Mode Markdown (visitez directement https://s.jina.ai/who+is+han+xiao) ; Droite : Mode JSON (utilisant curl https://s.jina.ai/who+is+han+xiao -H 'accept: application/json'). Au fait, une question ego comme celle-ci sert toujours de bon cas test.
Il y a trois principes dans la conception de la recherche contextuelle dans Reader :
- Améliorer la factualité ;
- Accéder aux informations à jour, c'est-à-dire aux connaissances mondiales ;
- Relier une réponse à sa source.
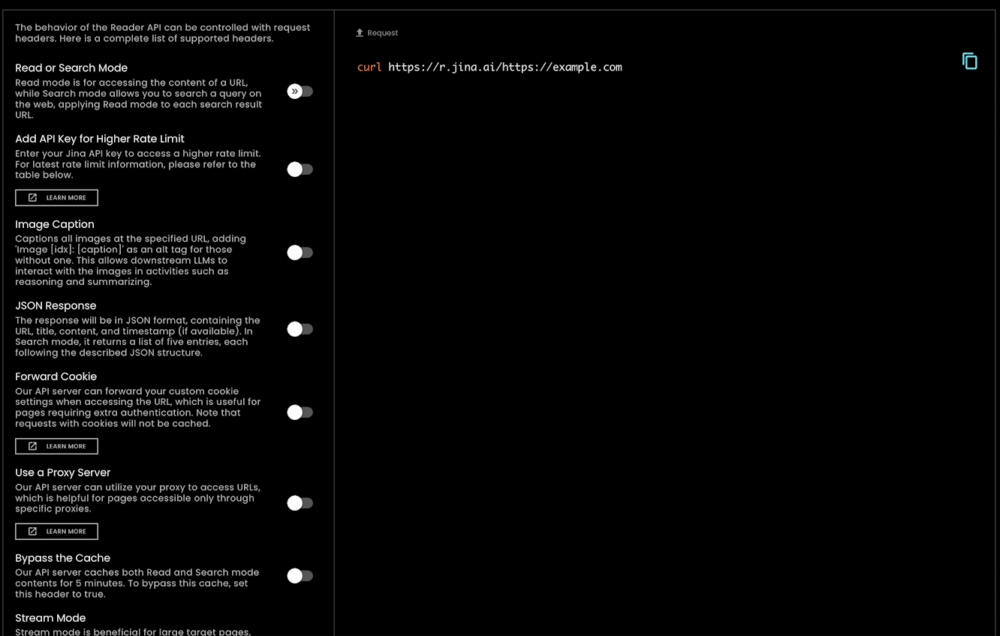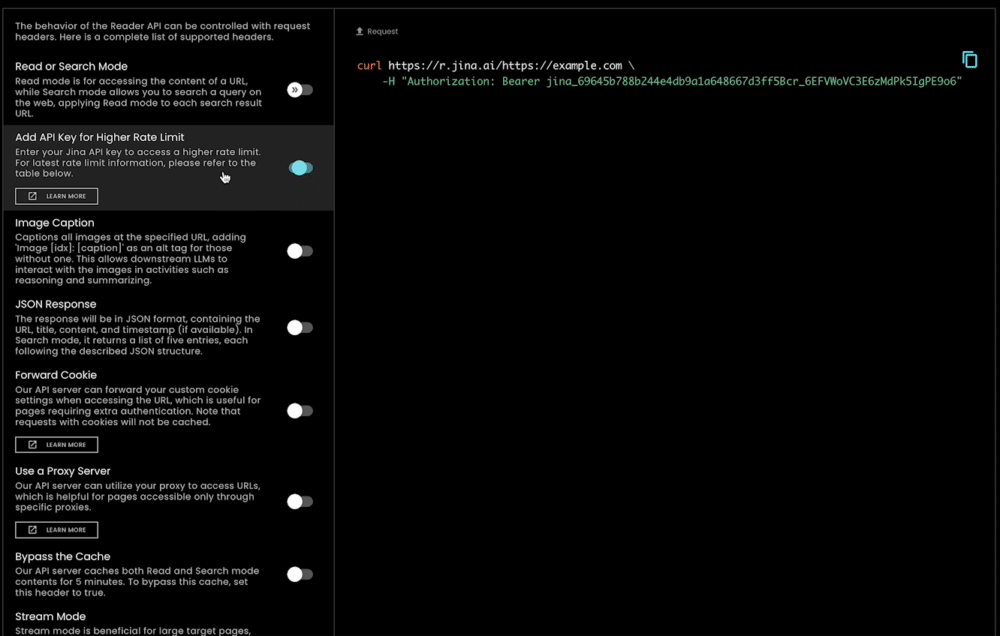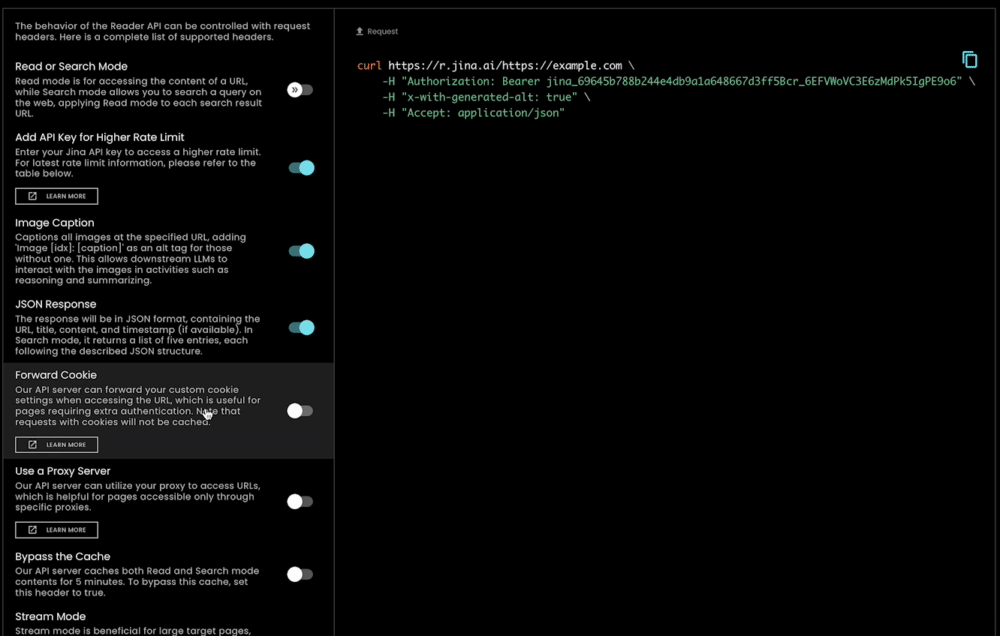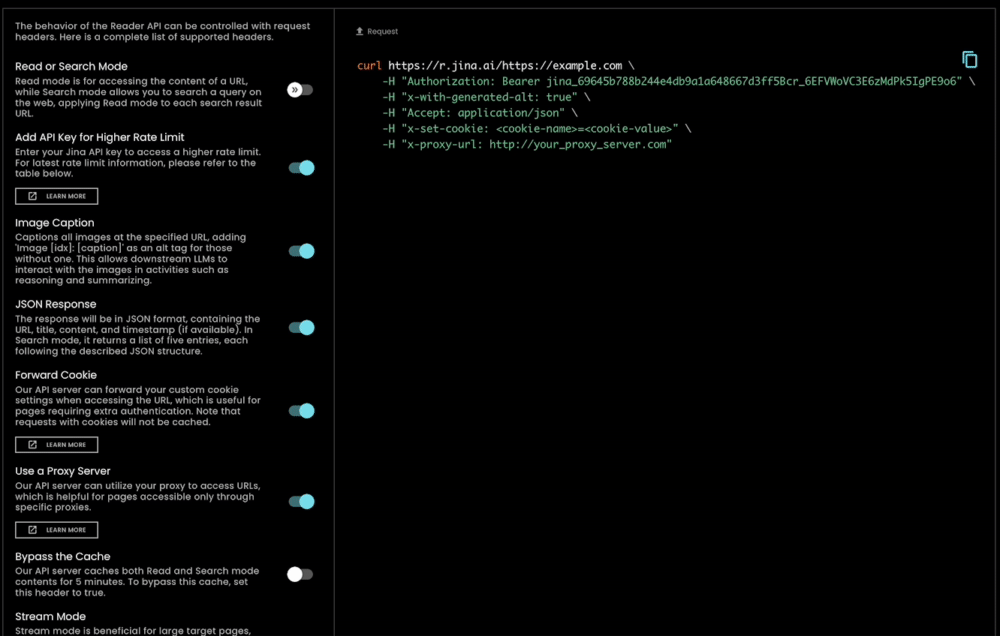
En plus d'être extrêmement facile à utiliser, s.jina.ai est également hautement évolutif et personnalisable car il exploite l'infrastructure flexible et évolutive existante de r.jina.ai. Vous pouvez définir des paramètres pour contrôler la description des images, la granularité du filtrage, etc., via les en-têtes de requête.
tagJina Reader comme Solution Complète de Mise en Contexte

Si nous combinons la recherche contextuelle (s.jina.ai) et la vérification contextuelle (r.jina.ai), nous pouvons construire une solution de mise en contexte très complète pour les LLMs, les agents et les systèmes RAG. Dans un flux de travail RAG fiable typique, Jina Reader fonctionne comme suit :
- L'utilisateur saisit une question ;
- Récupère les dernières informations du web en utilisant
s.jina.ai; - Génère une réponse initiale avec une citation du résultat de recherche de l'étape précédente ;
- Utilise
r.jina.aipour ancrer la réponse avec votre propre URL ; ou lire les URLs contenus dans la source retournée à l'étape 3 pour un ancrage plus approfondi ; - Génération de la réponse finale et mise en évidence des affirmations potentiellement non ancrées pour l'utilisateur.
tagLimites de taux plus élevées avec les clés API
Les utilisateurs peuvent profiter gratuitement du nouvel endpoint de recherche ancrée sans autorisation. De plus, en fournissant une clé API Jina AI dans l'en-tête de la requête (la même clé peut être utilisée dans l'API d'Embedding/Reranking), vous pouvez immédiatement bénéficier de 200 requêtes par minute par IP pour r.jina.ai et 40 requêtes par minute par IP pour s.jina.ai. Les détails se trouvent dans le tableau ci-dessous :
| Endpoint | Description | Limite de taux sans clé API | Limite de taux avec clé API | Schéma de comptage des tokens | Latence moyenne |
|---|---|---|---|---|---|
r.jina.ai | Lit une URL et retourne son contenu, utile pour vérifier l'ancrage | 20 RPM | 200 RPM | Basé sur les tokens de sortie | 3 secondes |
s.jina.ai | Recherche sur le web et retourne les 5 meilleurs résultats, utile pour l'ancrage de recherche | 5 RPM | 40 RPM | Basé sur les tokens de sortie pour les 5 résultats de recherche | 30 secondes |
tagConclusion
Nous croyons que l'ancrage est essentiel pour les applications GenAI, et la construction de solutions ancrées devrait être facile pour tous. C'est pourquoi nous avons introduit le nouvel endpoint d'ancrage de recherche, s.jina.ai, qui permet aux développeurs d'intégrer facilement les connaissances du monde dans leurs applications GenAI. Nous voulons que les développeurs établissent la confiance des utilisateurs, fournissent des réponses explicables et inspirent la curiosité à des millions d'utilisateurs.




