





Aujourd'hui, nous publions Jina Reranker v2 (jina-reranker-v2-base-multilingual), notre dernier et plus performant modèle de reclassement neuronal de la famille search foundation. Avec Jina Reranker v2, les développeurs de systèmes RAG/recherche peuvent bénéficier de :
- Multilingue : Des résultats de recherche plus pertinents dans plus de 100 langues, surpassant
bge-reranker-v2-m3; - Agent : Un reclassement de documents à la pointe de la technologie, compatible avec function-calling et text-to-SQL pour le RAG agentique ;
- Recherche de code : Performance de pointe sur les tâches de recherche de code, et
- Ultra-rapide : Un débit 15 fois supérieur à
bge-reranker-v2-m3, et 6 fois supérieur à jina-reranker-v1-base-en.
Vous pouvez commencer à utiliser Jina Reranker v2 via notre API Reranker, où nous offrons 1M de tokens gratuits pour tous les nouveaux utilisateurs.

Dans cet article, nous détaillerons ces nouvelles fonctionnalités supportées par Jina Reranker v2, montrant comment notre modèle de reclassement se comporte par rapport à d'autres modèles de pointe (y compris Jina Reranker v1), et expliquerons le processus d'entraînement qui a permis à Jina Reranker v2 d'atteindre des performances optimales en termes de précision des tâches et de débit de documents.
tagRappel : Pourquoi vous avez besoin d'un Reranker
Bien que les modèles d'embedding soient le composant le plus largement utilisé et compris dans la search foundation, ils sacrifient souvent la précision au profit de la vitesse de recherche. Les modèles de recherche basés sur l'embedding sont généralement des modèles bi-encodeurs, où chaque document est intégré et stocké, puis les requêtes sont également intégrées et la recherche est basée sur la similarité entre l'embedding de la requête et les embeddings des documents. Dans ce modèle, de nombreuses nuances d'interactions au niveau des tokens entre les requêtes des utilisateurs et les documents correspondants sont perdues car la requête originale et les documents ne peuvent jamais se "voir" mutuellement – seuls leurs embeddings le peuvent. Cela peut avoir un coût en termes de précision de la recherche – un domaine où les modèles de reclassement cross-encoder excellent.

Les rerankers résolvent ce manque de sémantique fine en utilisant une architecture cross-encoder, où les paires requête-document sont encodées ensemble pour produire un score de pertinence au lieu d'un embedding. Les études ont montré que, pour la plupart des systèmes RAG, l'utilisation d'un modèle reranker améliore l'ancrage sémantique et réduit les hallucinations.
tagSupport multilingue avec Jina Reranker v2
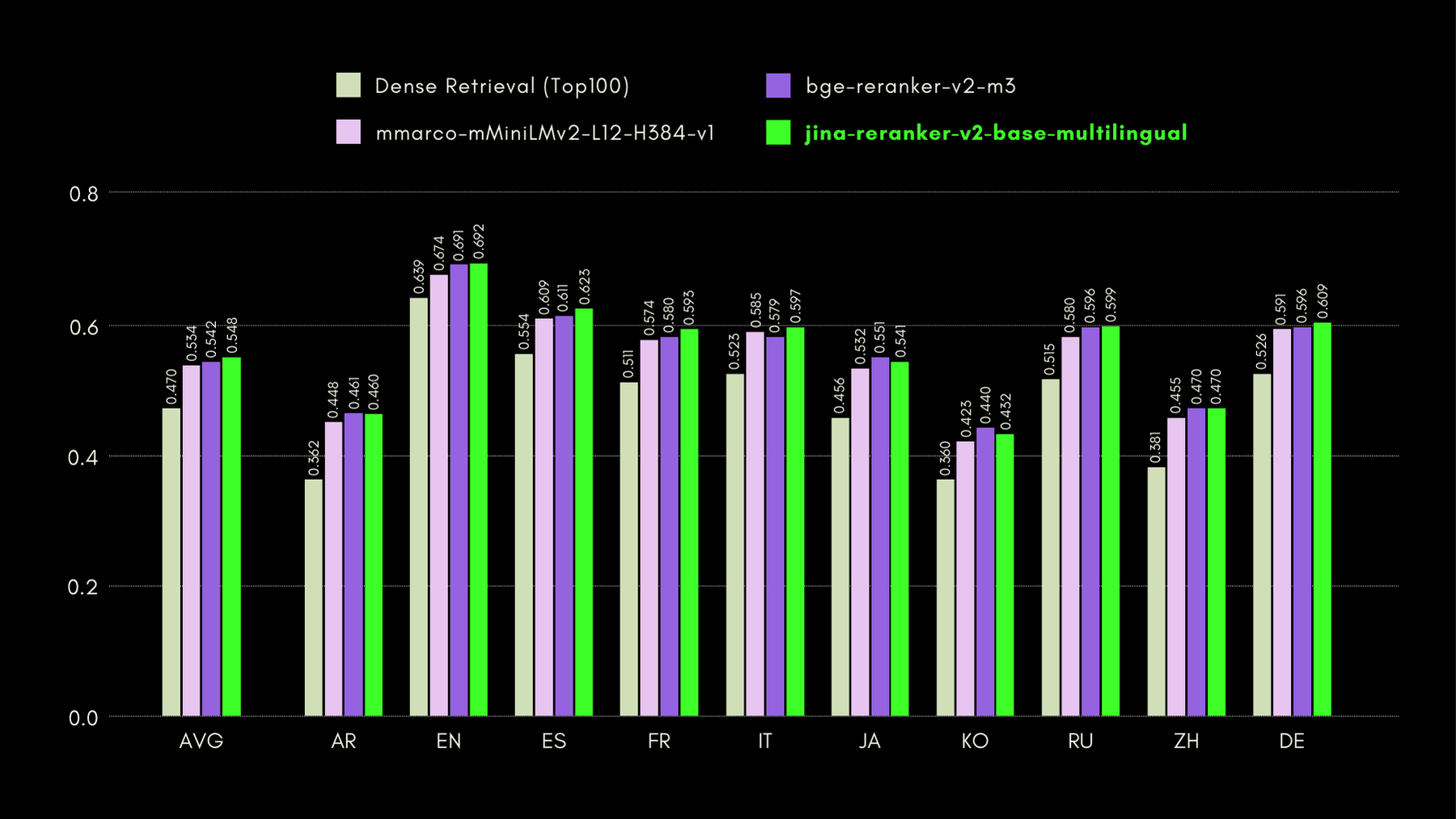
À l'époque, Jina Reranker v1 se démarquait en atteignant des performances état de l'art sur quatre benchmarks clés en anglais. Aujourd'hui, nous étendons significativement les capacités de reclassement dans Jina Reranker v2 avec un support multilingue pour plus de 100 langues et des tâches cross-linguistiques !
Pour évaluer les capacités cross-lingues et en langue anglaise de Jina Reranker v2, nous comparons ses performances à des modèles de reclassement similaires, sur les trois benchmarks suivants :
MKQA : Questions et Réponses de Connaissances Multilingues
Ce jeu de données comprend des questions et réponses en 26 langues, dérivées de bases de connaissances du monde réel, et est conçu pour évaluer la performance cross-lingue des systèmes de questions-réponses. MKQA se compose de requêtes en anglais et de leurs traductions manuelles dans des langues non anglaises, ainsi que de réponses en plusieurs langues, y compris l'anglais.
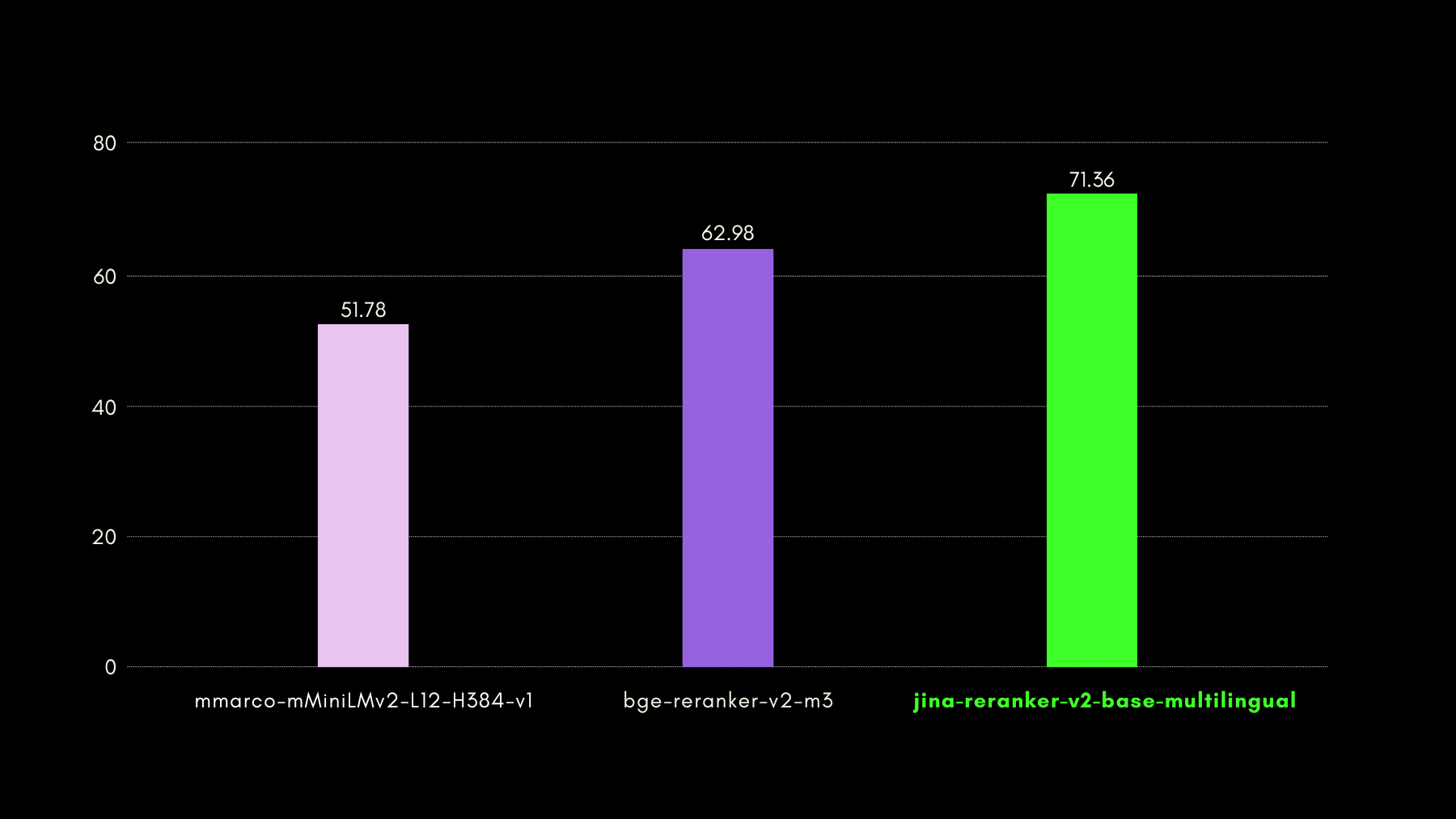
Dans le graphique ci-dessous, nous présentons les scores recall@10 pour chaque reranker inclus, y compris un "dense retriever" comme référence, effectuant une recherche traditionnelle basée sur les embeddings :
BEIR : Benchmark hétérogène sur diverses tâches IR
Ce référentiel open-source contient un benchmark de recherche pour de nombreuses langues, mais nous nous concentrons uniquement sur les tâches en anglais. Celles-ci consistent en 17 jeux de données, sans données d'entraînement, et l'accent est mis sur l'évaluation de la précision de récupération des retrievers neuronaux ou lexicaux.
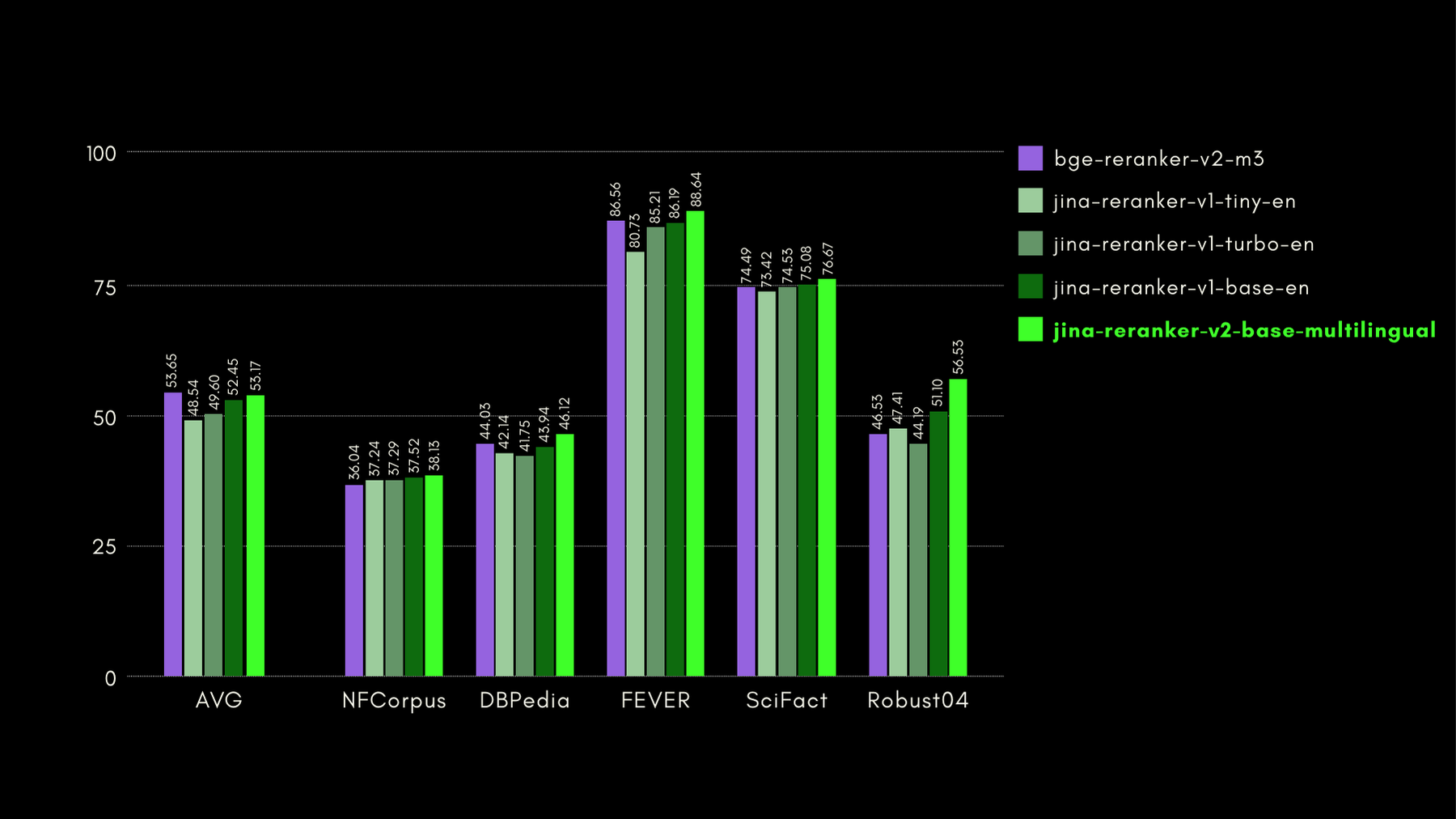
Dans le graphique ci-dessous, nous rapportons le NDCG@10 pour BEIR avec chaque reranker inclus. Les résultats sur BEIR montrent clairement que les nouvelles capacités multilingues de jina-reranker-v2-base-multilingual ne compromettent pas ses capacités de recherche en anglais, qui sont, de plus, significativement améliorées par rapport à jina-reranker-v1-base-en.
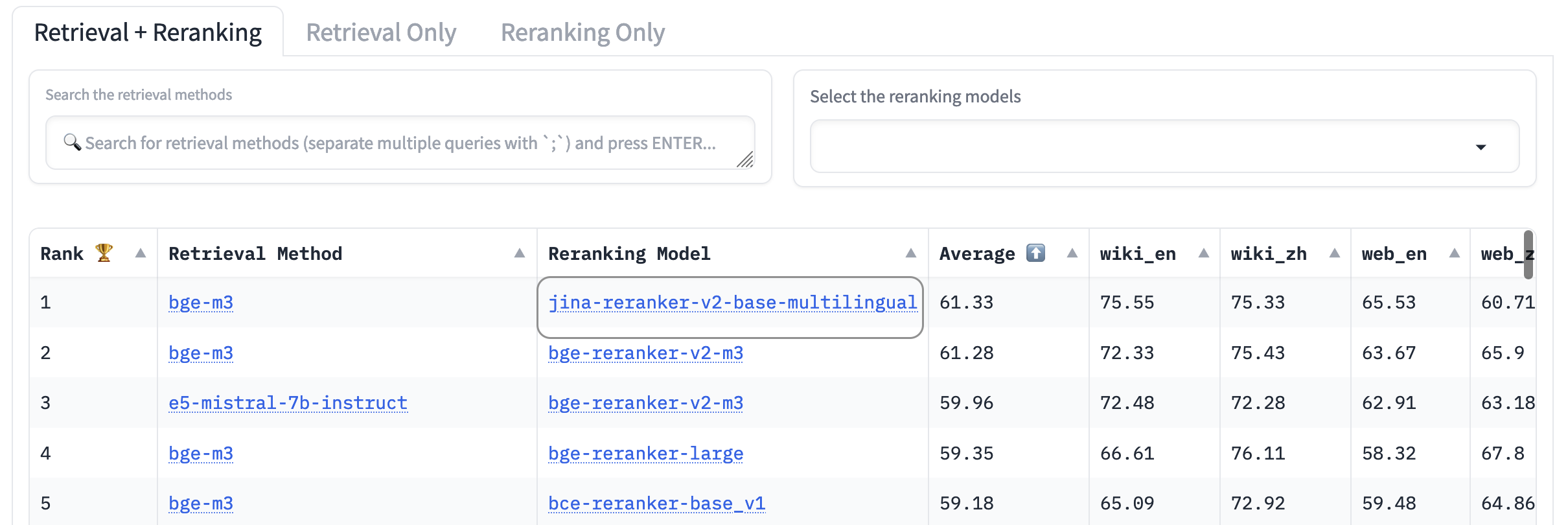
AirBench : Benchmark IR hétérogène automatisé
Nous avons co-créé et publié le benchmark AirBench pour les systèmes RAG, en collaboration avec BAAI. Ce benchmark utilise des données synthétiques générées automatiquement pour des domaines et des tâches personnalisés, sans publier la vérité terrain, de sorte que les modèles évalués n'ont aucune chance de surajuster le jeu de données.
Au moment de la rédaction, jina-reranker-v2-base-multilingual surpasse tous les autres modèles de reranking inclus, occupant la première place du classement.
tagRécapitulatif des Agents d'Outillage : Apprendre aux LLM à Utiliser des Outils
Depuis le début du boom de l'IA il y a quelques années, les gens ont constaté que les modèles d'IA sous-performent dans des domaines où les ordinateurs sont censés être performants. Par exemple, considérez cette conversation avec Mistral-7b-Instruct-v0.1 :

Cela peut sembler correct à première vue, mais en réalité 203 fois 7724 fait 1 567 972.
Alors pourquoi le LLM se trompe-t-il d'un facteur de plus de dix ? C'est parce que les LLM ne sont pas entraînés à faire des mathématiques ou tout autre type de raisonnement, et l'absence de récursion interne garantit presque qu'ils ne peuvent pas résoudre des problèmes mathématiques complexes. Ils sont entraînés à dire des choses ou à effectuer d'autres tâches qui ne sont pas intrinsèquement précises.
Les LLM n'hésitent pas à halluciner des réponses cependant. De leur point de vue, 15 824 772 est une réponse parfaitement plausible à 204 × 7 724. C'est juste qu'elle est totalement fausse.
Le RAG agentique change le rôle des LLM génératifs de ce en quoi ils sont mauvais — réfléchir et savoir des choses — à ce en quoi ils sont bons : la compréhension de lecture et la synthèse d'informations en langage naturel. Au lieu de simplement générer une réponse, le RAG trouve des informations pertinentes pour répondre à votre demande dans toutes les sources de données qui lui sont accessibles et les présente au modèle de langage. Son travail n'est pas d'inventer une réponse pour vous, mais de présenter les réponses trouvées par un système différent sous une forme naturelle et réactive.
Nous avons entraîné Jina Reranker v2 à être sensible aux schémas de bases de données SQL et aux appels de fonctions. Cela nécessite un type de sémantique différent de la récupération de texte conventionnelle. Il doit être conscient des tâches et du code, et nous avons entraîné notre reranker spécifiquement pour cette fonctionnalité.
tagJina Reranker v2 sur l'Interrogation de Données Structurées
Alors que les modèles d'embedding et de reranking traitent déjà les données non structurées comme des citoyens de première classe, le support des données tabulaires structurées fait encore défaut dans la plupart des modèles.
Jina Reranker v2 comprend l'intention en aval d'interroger une source de bases de données structurées, comme MySQL ou MongoDB, et attribue le score de pertinence correct à un schéma de table structurée, étant donné une requête d'entrée.
Vous pouvez le voir ci-dessous, où le reranker récupère les tables les plus pertinentes avant qu'un LLM ne soit invité à générer une requête SQL à partir d'une requête en langage naturel :
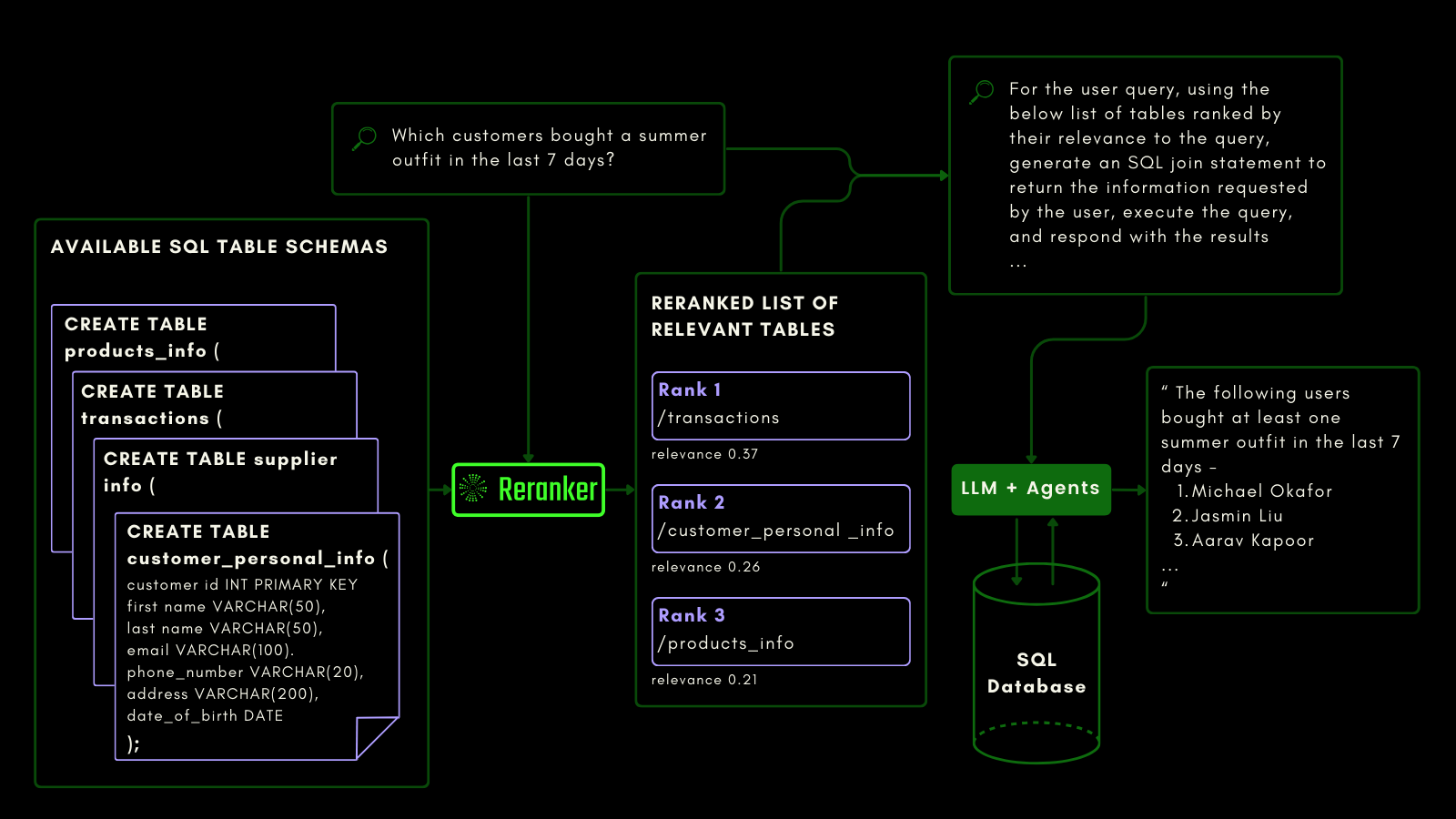
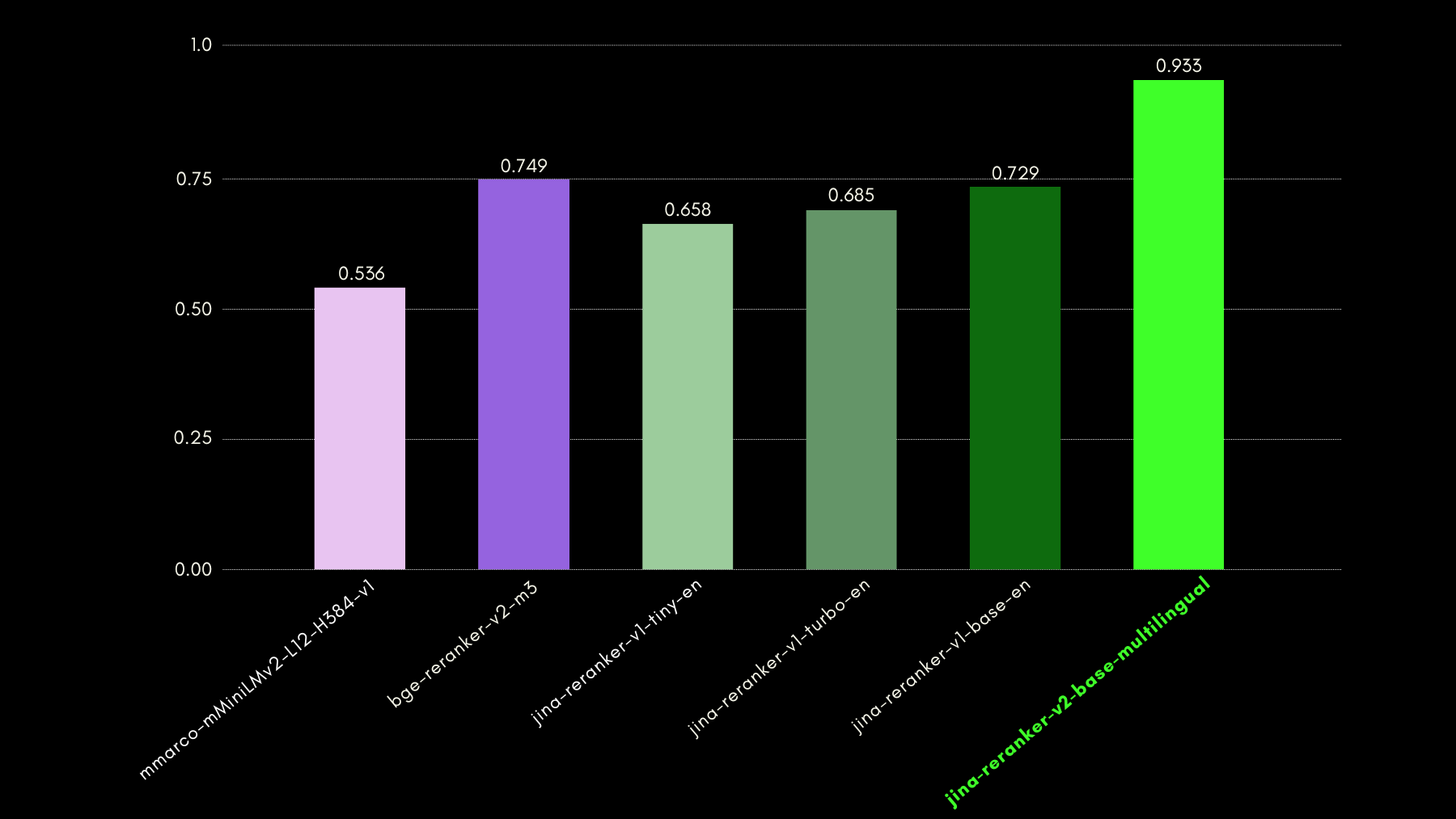
Nous avons évalué les capacités de conscience des requêtes en utilisant le benchmark du jeu de données NSText2SQL. Nous extrayons, de la colonne "instruction" du jeu de données original, des instructions écrites en langage naturel et le schéma de table correspondant.
Le graphique ci-dessous compare, en utilisant le recall@3, la réussite des modèles de reranking dans le classement du schéma de table correct correspondant à une requête en langage naturel.
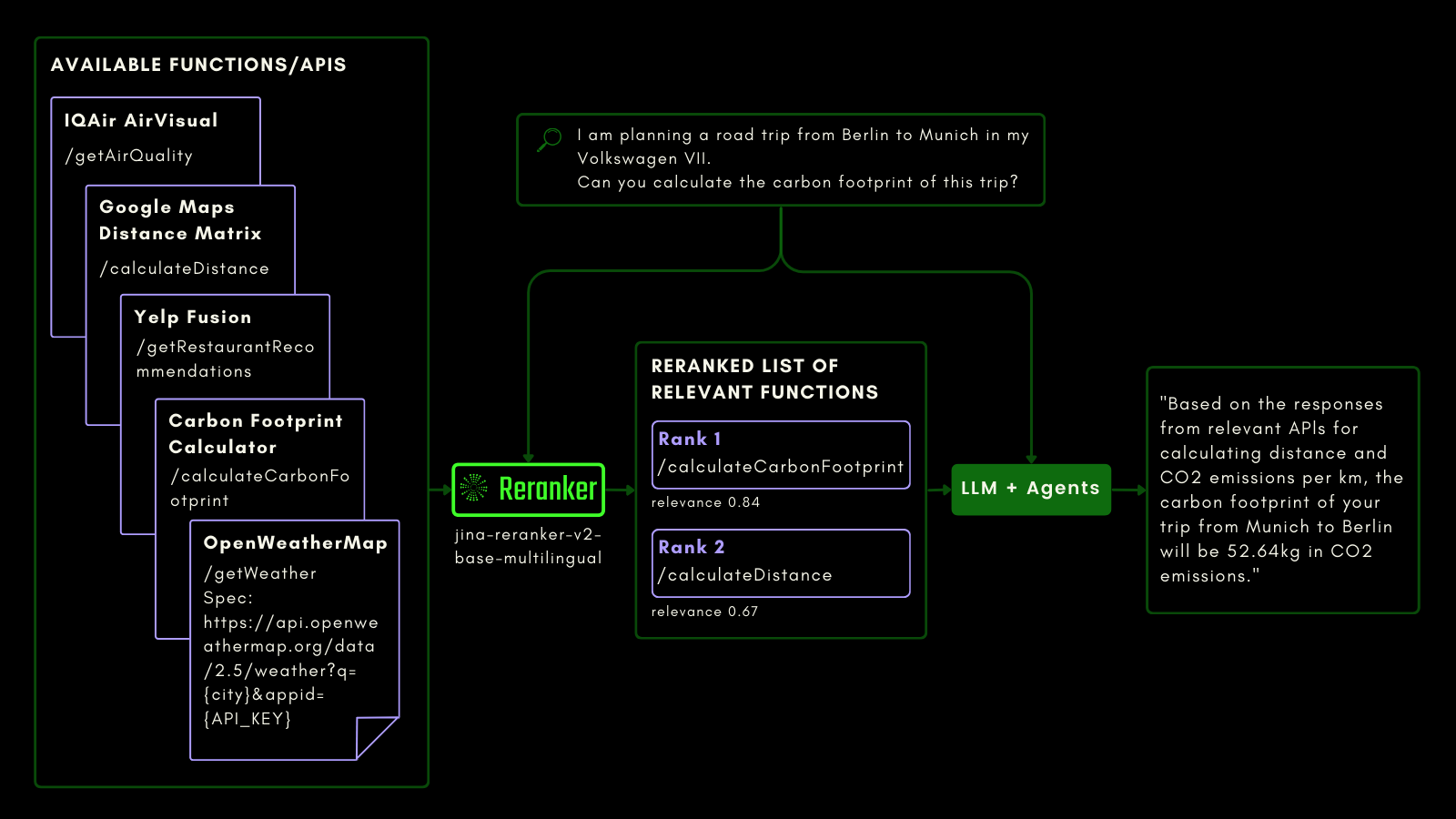
tagJina Reranker v2 sur l'Appel de Fonctions
Tout comme l'interrogation d'une table SQL, vous pouvez utiliser le RAG agentique pour invoquer des outils externes. Dans cette optique, nous avons intégré l'appel de fonctions dans Jina Reranker v2, lui permettant de comprendre votre intention pour les fonctions externes et d'attribuer des scores de pertinence aux spécifications de fonctions en conséquence.
Le schéma ci-dessous explique (avec un exemple) comment les LLM peuvent utiliser Reranker pour améliorer les capacités d'appel de fonctions et, finalement, l'expérience utilisateur de l'IA agentique.
Nous avons évalué les capacités de conscience des fonctions avec le benchmark ToolBench. Le benchmark collecte plus de 16 mille APIs publiques et les instructions générées synthétiquement correspondantes pour leur utilisation dans des contextes d'API unique et multiple.
Voici les résultats (métrique recall@3) comparés à d'autres modèles de reranking :
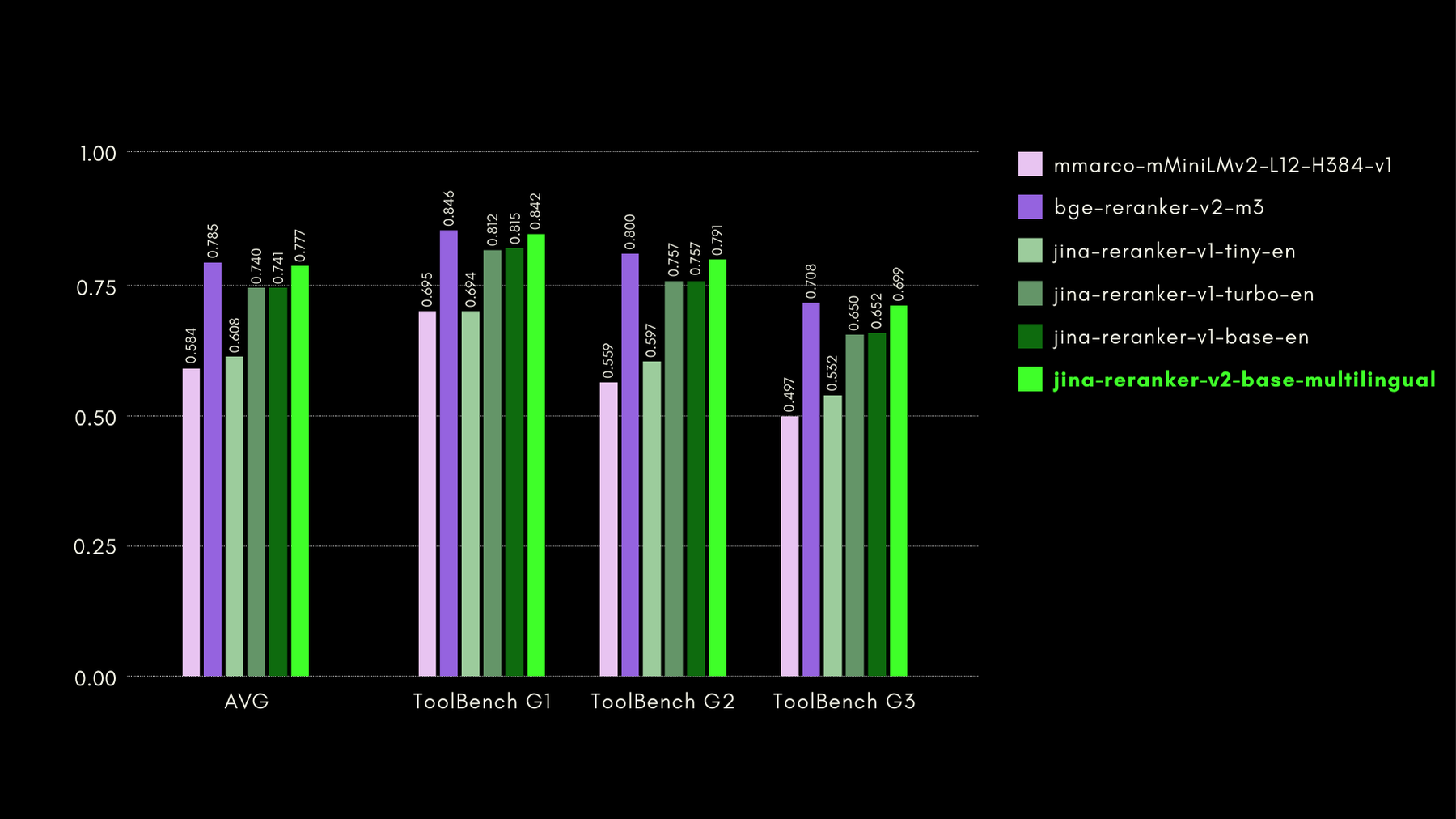
Comme nous le montrerons également dans les sections suivantes, la performance quasi état de l'art de jina-reranker-v2-base-multilingual s'accompagne de l'avantage d'être deux fois plus petit que bge-reranker-v2-m3 et presque 15 fois plus rapide.
tagJina Reranker v2 pour la recherche de code
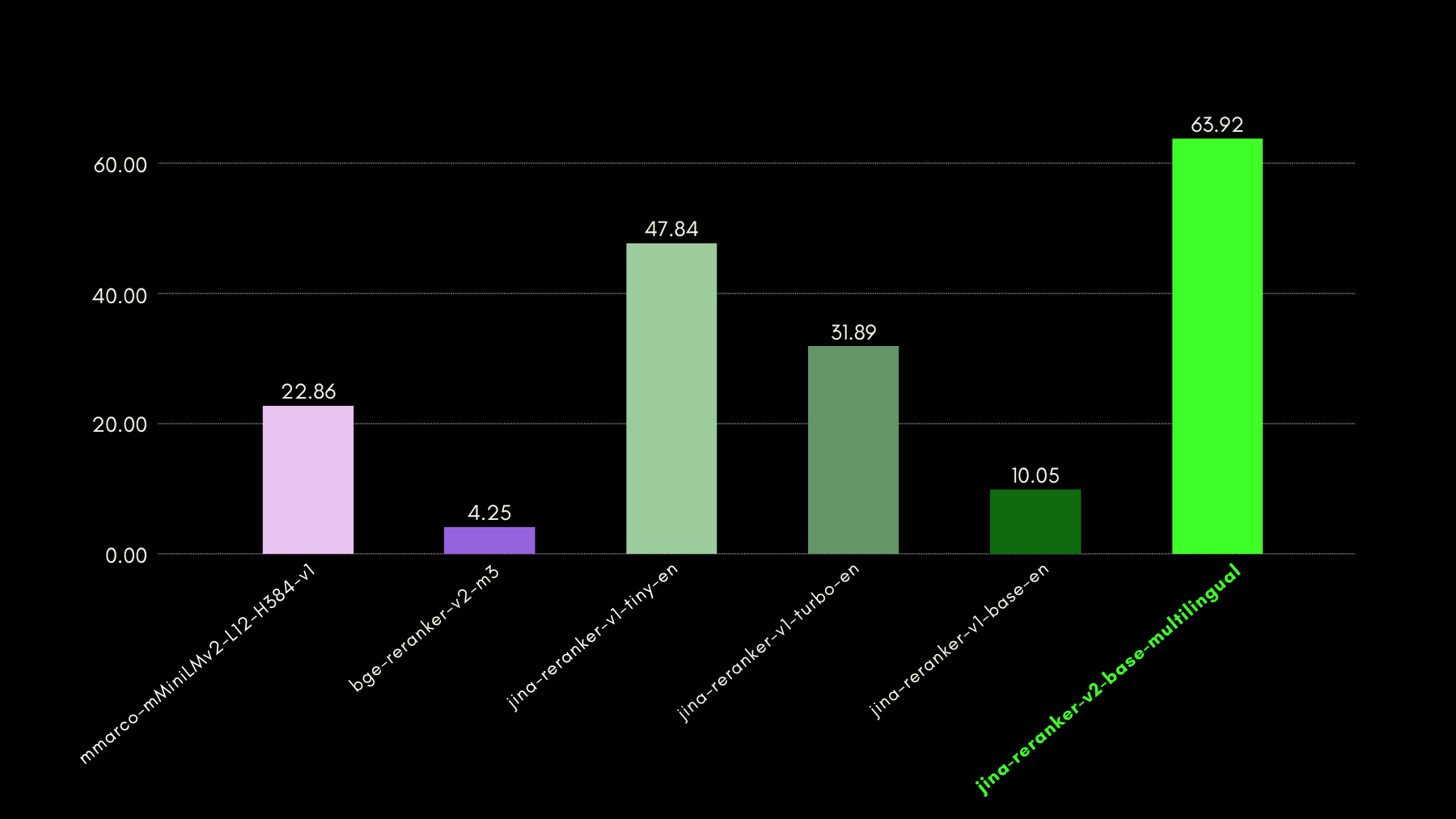
Jina Reranker v2, en plus d'être entraîné pour l'appel de fonctions et l'interrogation de données structurées, améliore également la recherche de code par rapport aux modèles concurrents de taille similaire. Nous avons évalué ses capacités de recherche de code en utilisant le benchmark CodeSearchNet. Le benchmark est une combinaison de requêtes au format docstring et en langage naturel, avec des segments de code étiquetés pertinents pour les requêtes.
Voici les résultats, utilisant MRR@10, comparés à d'autres modèles de reclassement :
tagInférence ultra-rapide avec Jina Reranker v2
Alors que les reclasseurs neuronaux de style cross-encoder excellent dans la prédiction de la pertinence d'un document récupéré, ils offrent une inférence plus lente que les modèles d'embedding. En effet, comparer une requête à n documents un par un est beaucoup plus lent que HNSW ou toute autre méthode de recherche rapide dans la plupart des bases de données vectorielles. Nous avons résolu cette lenteur avec Jina Reranker v2.
- Nos approches uniques d'entraînement (décrites dans la section suivante) ont permis à notre modèle d'atteindre des performances état de l'art en termes de précision avec seulement 278M paramètres. Comparé à, disons,
bge-reranker-v2-m3, avec 567M paramètres, Jina Reranker v2 est seulement deux fois plus petit. Cette réduction est la première raison de l'amélioration du débit (documents traités par 50ms). - Même avec une taille de modèle comparable, Jina Reranker v2 affiche un débit 6 fois supérieur à celui de notre précédent modèle état de l'art Jina Reranker v1 pour l'anglais. Cela est dû au fait que nous avons implémenté Jina Reranker v2 avec Flash Attention 2, qui introduit des optimisations de mémoire et de calcul dans la couche d'attention des modèles basés sur les transformers.
Vous pouvez voir le résultat des étapes ci-dessus en termes de performances de débit de Jina Reranker v2 :
tagComment nous avons entraîné Jina Reranker v2
Nous avons entraîné jina-reranker-v2-base-multilingual en quatre étapes :
- Préparation avec des données en anglais : Nous avons préparé la première version du modèle en entraînant un modèle de base avec uniquement des données en anglais, incluant des paires (entraînement contrastif) ou des triplets (requête, réponse correcte, réponse incorrecte), des paires requête-schéma de fonction et des paires requête-schéma de table.
- Ajout de données multilingues : Dans l'étape suivante, nous avons ajouté des jeux de données de paires et triplets multilingues pour améliorer les capacités multilingues du modèle de base sur les tâches de recherche spécifiquement.
- Ajout de toutes les données multilingues : À cette étape, nous avons concentré l'entraînement principalement sur l'assurance que le modèle voit la plus grande quantité possible de nos données. Nous avons affiné le point de contrôle du modèle de la deuxième étape avec tous les jeux de données de paires et de triplets, provenant de plus de 100 langues à faibles et hautes ressources.
- Affinage avec des exemples négatifs difficiles : Après avoir observé les performances de reclassement de la troisième étape, nous avons affiné le modèle en ajoutant plus de données de triplets avec spécifiquement plus d'exemples de négatifs difficiles pour les requêtes existantes - des réponses qui semblent superficiellement pertinentes pour la requête, mais sont en fait incorrectes.
Cette approche d'entraînement en quatre étapes était basée sur l'idée que l'inclusion de fonctions et de schémas tabulaires dans le processus d'entraînement le plus tôt possible permettait au modèle d'être particulièrement conscient de ces cas d'utilisation et d'apprendre à se concentrer sur la sémantique des documents candidats plutôt que sur les constructions linguistiques.
tagJina Reranker v2 en pratique
tagVia notre API Reranker
La façon la plus rapide et la plus facile de commencer avec Jina Reranker v2 est d'utiliser l'API Jina Reranker.
Rendez-vous dans la section API de cette page pour intégrer jina-reranker-v2-base-multilingual en utilisant le langage de programmation de votre choix.
Exemple 1 : Classement des appels de fonction
Pour classer la fonction/outil externe le plus pertinent, formatez la requête et les documents (schémas de fonction) comme indiqué ci-dessous :
curl -X 'POST' \
'https://api.jina.ai/v1/rerank' \
-H 'accept: application/json' \
-H 'Authorization: Bearer <YOUR JINA AI TOKEN HERE>' \
-H 'Content-Type: application/json' \
-d '{
"model": "jina-reranker-v2-base-multilingual",
"query": "I am planning a road trip from Berlin to Munich in my Volkswagen VII. Can you calculate the carbon footprint of this trip?",
"documents": [
"{'\''Name'\'': '\''getWeather'\'', '\''Specification'\'': '\''Provides current weather information for a specified city'\'', '\''spec'\'': '\''https://api.openweathermap.org/data/2.5/weather?q={city}&appid={API_KEY}'\'', '\''example'\'': '\''https://api.openweathermap.org/data/2.5/weather?q=Berlin&appid=YOUR_API_KEY'\''}",
"{'\''Name'\'': '\''calculateDistance'\'', '\''Specification'\'': '\''Calculates the driving distance and time between multiple locations'\'', '\''spec'\'': '\''https://maps.googleapis.com/maps/api/distancematrix/json?origins={startCity}&destinations={endCity}&key={API_KEY}'\'', '\''example'\'': '\''https://maps.googleapis.com/maps/api/distancematrix/json?origins=Berlin&destinations=Munich&key=YOUR_API_KEY'\''}",
"{'\''Name'\'': '\''calculateCarbonFootprint'\'', '\''Specification'\'': '\''Estimates the carbon footprint for various activities, including transportation'\'', '\''spec'\'': '\''https://www.carboninterface.com/api/v1/estimates'\'', '\''example'\'': '\''{type: vehicle, distance: distance, vehicle_model_id: car}'\''}"
]
}'N'oubliez pas de remplacer <YOUR JINA AI TOKEN HERE> par votre token personnel de l'API Reranker
Vous devriez obtenir :
{
"model": "jina-reranker-v2-base-multilingual",
"usage": {
"total_tokens": 383,
"prompt_tokens": 383
},
"results": [
{
"index": 2,
"document": {
"text": "{'Name': 'calculateCarbonFootprint', 'Specification': 'Estimates the carbon footprint for various activities, including transportation', 'spec': 'https://www.carboninterface.com/api/v1/estimates', 'example': '{type: vehicle, distance: distance, vehicle_model_id: car}'}"
},
"relevance_score": 0.5422876477241516
},
{
"index": 1,
"document": {
"text": "{'Name': 'calculateDistance', 'Specification': 'Calculates the driving distance and time between multiple locations', 'spec': 'https://maps.googleapis.com/maps/api/distancematrix/json?origins={startCity}&destinations={endCity}&key={API_KEY}', 'example': 'https://maps.googleapis.com/maps/api/distancematrix/json?origins=Berlin&destinations=Munich&key=YOUR_API_KEY'}"
},
"relevance_score": 0.23283305764198303
},
{
"index": 0,
"document": {
"text": "{'Name': 'getWeather', 'Specification': 'Provides current weather information for a specified city', 'spec': 'https://api.openweathermap.org/data/2.5/weather?q={city}&appid={API_KEY}', 'example': 'https://api.openweathermap.org/data/2.5/weather?q=Berlin&appid=YOUR_API_KEY'}"
},
"relevance_score": 0.05033063143491745
}
]
}Exemple 2 : Classement des requêtes SQL
De même, pour obtenir les scores de pertinence pour les schémas de tables structurées pour votre requête, vous pouvez utiliser l'exemple d'appel API suivant :
curl -X 'POST' \
'https://api.jina.ai/v1/rerank' \
-H 'accept: application/json' \
-H 'Authorization: Bearer <YOUR JINA AI TOKEN HERE>' \
-H 'Content-Type: application/json' \
-d '{
"model": "jina-reranker-v2-base-multilingual",
"query": "which customers bought a summer outfit in the past 7 days?",
"documents": [
"CREATE TABLE customer_personal_info (customer_id INT PRIMARY KEY, first_name VARCHAR(50), last_name VARCHAR(50));",
"CREATE TABLE supplier_company_info (supplier_id INT PRIMARY KEY, company_name VARCHAR(100), contact_name VARCHAR(50));",
"CREATE TABLE transactions (transaction_id INT PRIMARY KEY, customer_id INT, purchase_date DATE, FOREIGN KEY (customer_id) REFERENCES customer_personal_info(customer_id), product_id INT, FOREIGN KEY (product_id) REFERENCES products(product_id));",
"CREATE TABLE products (product_id INT PRIMARY KEY, product_name VARCHAR(100), season VARCHAR(50), supplier_id INT, FOREIGN KEY (supplier_id) REFERENCES supplier_company_info(supplier_id));"
]
}'La réponse attendue est :
{
"model": "jina-reranker-v2-base-multilingual",
"usage": {
"total_tokens": 253,
"prompt_tokens": 253
},
"results": [
{
"index": 2,
"document": {
"text": "CREATE TABLE transactions (transaction_id INT PRIMARY KEY, customer_id INT, purchase_date DATE, FOREIGN KEY (customer_id) REFERENCES customer_personal_info(customer_id), product_id INT, FOREIGN KEY (product_id) REFERENCES products(product_id));"
},
"relevance_score": 0.2789437472820282
},
{
"index": 0,
"document": {
"text": "CREATE TABLE customer_personal_info (customer_id INT PRIMARY KEY, first_name VARCHAR(50), last_name VARCHAR(50));"
},
"relevance_score": 0.06477169692516327
},
{
"index": 3,
"document": {
"text": "CREATE TABLE products (product_id INT PRIMARY KEY, product_name VARCHAR(100), season VARCHAR(50), supplier_id INT, FOREIGN KEY (supplier_id) REFERENCES supplier_company_info(supplier_id));"
},
"relevance_score": 0.027742892503738403
},
{
"index": 1,
"document": {
"text": "CREATE TABLE supplier_company_info (supplier_id INT PRIMARY KEY, company_name VARCHAR(100), contact_name VARCHAR(50));"
},
"relevance_score": 0.025516605004668236
}
]
}tagVia les frameworks RAG/LLM
Les intégrations existantes de Jina Reranker avec les frameworks d'orchestration LLM et RAG devraient déjà fonctionner immédiatement en utilisant le nom de modèle jina-reranker-v2-base-multilingual. Consultez leurs pages de documentation respectives pour en savoir plus sur l'intégration de Jina Reranker v2 dans vos applications.
- Haystack par deepset : Jina Reranker v2 peut être utilisé avec la classe JinaRanker dans Haystack :
from haystack import Document
from haystack_integrations.components.rankers.jina import JinaRanker
docs = [Document(content="Paris"), Document(content="Berlin")]
ranker = JinaRanker(model="jina-reranker-v2-base-multilingual", api_key="<YOUR JINA AI API KEY HERE>")
ranker.run(query="City in France", documents=docs, top_k=1)
- LlamaIndex : Jina Reranker v2 peut être utilisé comme module JinaRerank node postprocessor en l'initialisant :
import os
from llama_index.postprocessor.jinaai_rerank import JinaRerank
jina_rerank = JinaRerank(model="jina-reranker-v2-base-multilingual", api_key="<YOUR JINA AI API KEY HERE>", top_n=1)
- Langchain : Utilisez l'intégration Jina Rerank pour utiliser Jina Reranker 2 dans votre application existante. Le module JinaRerank doit être initialisé avec le bon nom de modèle :
from langchain_community.document_compressors import JinaRerank
reranker = JinaRerank(model="jina-reranker-v2-base-multilingual", jina_api_key="<YOUR JINA AI API KEY HERE>")
tagVia HuggingFace
Nous donnons également accès (sous licence CC-BY-NC-4.0) au modèle jina-reranker-v2-base-multilingual sur Hugging Face à des fins de recherche et d'évaluation.

Pour télécharger et exécuter le modèle depuis Hugging Face, installez les bibliothèques transformers et einops :
pip install transformers einops
pip install ninja
pip install flash-attn --no-build-isolation
Connectez-vous à votre compte Hugging Face via la CLI Hugging Face en utilisant votre token d'accès Hugging Face :
huggingface-cli login --token <"HF-Access-Token">
Téléchargez le modèle pré-entraîné :
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained(
'jinaai/jina-reranker-v2-base-multilingual',
torch_dtype="auto",
trust_remote_code=True,
)
model.to('cuda') # ou 'cpu' si aucun GPU n'est disponible
model.eval()
Définissez la requête et les documents à reclasser :
query = "Organic skincare products for sensitive skin"
documents = [
"Organic skincare for sensitive skin with aloe vera and chamomile.",
"New makeup trends focus on bold colors and innovative techniques",
"Bio-Hautpflege für empfindliche Haut mit Aloe Vera und Kamille",
"Neue Make-up-Trends setzen auf kräftige Farben und innovative Techniken",
"Cuidado de la piel orgánico para piel sensible con aloe vera y manzanilla",
"Las nuevas tendencias de maquillaje se centran en colores vivos y técnicas innovadoras",
"针对敏感肌专门设计的天然有机护肤产品",
"新的化妆趋势注重鲜艳的颜色和创新的技巧",
"敏感肌のために特別に設計された天然有機スキンケア製品",
"新しいメイクのトレンドは鮮やかな色と革新的な技術に焦点を当てています",
]
Construisez des paires de phrases et calculez les scores de pertinence :
sentence_pairs = [[query, doc] for doc in documents]
scores = model.compute_score(sentence_pairs, max_length=1024)
Les scores seront une liste de nombres flottants, où chaque nombre représente le score de pertinence du document correspondant par rapport à la requête. Des scores plus élevés signifient une plus grande pertinence.
Alternativement, utilisez la fonction rerank pour reclasser de grands textes en découpant automatiquement la requête et les documents en fonction de max_query_length etmax_length respectivement. Chaque fragment est évalué individuellement et les scores de chaque fragment sont ensuite combinés pour produire les résultats finaux du reclassement :
results = model.rerank(
query,
documents,
max_query_length=512,
max_length=1024,
top_n=3
)
Cette fonction renvoie non seulement le score de pertinence pour chaque document, mais aussi leur contenu et leur position dans la liste originale des documents.
tagVia le déploiement sur Cloud Privé
Les packages précompilés pour le déploiement privé de Jina Reranker v2 sur AWS et Azure seront bientôt disponibles sur nos pages vendeur sur AWS Marketplace et Azure Marketplace, respectivement.
tagPoints clés de Jina Reranker v2
Jina Reranker v2 représente une expansion importante des capacités pour search foundation :
- La récupération état de l'art utilisant le cross-encoding ouvre un large éventail de nouveaux domaines d'application.
- Les fonctionnalités multilingues et inter-langues améliorées éliminent les barrières linguistiques de vos cas d'utilisation.
- Le meilleur support de sa catégorie pour le function calling, associé à la prise en charge des requêtes de données structurées, élève vos capacités RAG agentiques au niveau supérieur de précision.
- Une meilleure récupération du code informatique et des données formatées peut aller bien au-delà de la simple récupération d'informations textuelles.
- Un débit de documents beaucoup plus rapide garantit que, quelle que soit la méthode de récupération, vous pouvez désormais reclasser beaucoup plus de documents récupérés plus rapidement, et déléguer la majorité des calculs de pertinence fine à jina-reranker-v2-base-multilingual.
Les systèmes RAG sont beaucoup plus précis avec Reranker v2, aidant vos solutions existantes de gestion de l'information à produire des résultats plus nombreux et plus exploitables. Le support multilingue rend tout cela directement accessible aux entreprises internationales et multilingues, avec une API facile à utiliser à un prix abordable.
En le testant avec des benchmarks dérivés de cas d'utilisation réels, vous pouvez constater par vous-même comment Jina Reranker v2 maintient des performances état de l'art pour les tâches pertinentes aux modèles d'entreprise réels, le tout dans un seul modèle d'IA, réduisant vos coûts et simplifiant votre stack technique.
