


Nouveau ! Partie II : plongée profonde dans les indices de frontière et les idées reçues.
Il y a environ un an, en octobre 2023, nous avons publié le premier modèle d'embedding open source au monde avec une longueur de contexte de 8K, jina-embeddings-v2-base-en. Depuis lors, il y a eu beaucoup de débats sur l'utilité du contexte long dans les modèles d'embedding. Pour de nombreuses applications, encoder un document de milliers de mots en une seule représentation d'embedding n'est pas idéal. De nombreux cas d'utilisation nécessitent de récupérer des portions plus petites du texte, et les systèmes de recherche basés sur des vecteurs denses fonctionnent souvent mieux avec des segments de texte plus petits, car la sémantique est moins susceptible d'être « sur-compressée » dans les vecteurs d'embedding.
La Génération Augmentée par Recherche (RAG) est l'une des applications les plus connues qui nécessite de diviser les documents en petits morceaux de texte (disons dans les 512 tokens). Ces chunks sont généralement stockés dans une base de données vectorielle, avec des représentations vectorielles générées par un modèle d'embedding de texte. Pendant l'exécution, le même modèle d'embedding encode une requête en une représentation vectorielle, qui est ensuite utilisée pour identifier les chunks de texte pertinents stockés. Ces chunks sont ensuite transmis à un grand modèle de langage (LLM), qui synthétise une réponse à la requête basée sur les textes récupérés.

En bref, l'embedding de plus petits chunks semble être préférable, en partie en raison des tailles d'entrée limitées des LLM en aval, mais aussi parce qu'il existe une préoccupation que les informations contextuelles importantes dans un long contexte puissent être diluées lorsqu'elles sont compressées en un seul vecteur.
Mais si l'industrie n'a jamais besoin que de modèles d'embedding avec une longueur de contexte de 512, quel est l'intérêt de former des modèles avec une longueur de contexte de 8192 ?
Dans cet article, nous revenons sur cette question importante, bien que délicate, en explorant les limites du pipeline naïf de découpage-embedding dans RAG. Nous introduisons une nouvelle approche appelée « Late Chunking », qui exploite les riches informations contextuelles fournies par les modèles d'embedding de longueur 8192 pour incorporer plus efficacement les chunks.
tagLe problème du contexte perdu
Le pipeline RAG simple de découpage-embedding-récupération-génération n'est pas sans défis. Plus précisément, ce processus peut détruire les dépendances contextuelles à longue distance. En d'autres termes, lorsque des informations pertinentes sont réparties sur plusieurs chunks, sortir des segments de texte de leur contexte peut les rendre inefficaces, rendant cette approche particulièrement problématique.
Dans l'image ci-dessous, un article Wikipédia est divisé en chunks de phrases. Vous pouvez voir que des expressions comme « its » et « the city » font référence à « Berlin », qui n'est mentionné que dans la première phrase. Cela rend plus difficile pour le modèle d'embedding de lier ces références à l'entité correcte, produisant ainsi une représentation vectorielle de moindre qualité.

Cela signifie que si nous divisons un long article en chunks de phrases, comme dans l'exemple ci-dessus, un système RAG pourrait avoir du mal à répondre à une requête comme « Quelle est la population de Berlin ? » Parce que le nom de la ville et la population n'apparaissent jamais ensemble dans un seul chunk, et sans contexte de document plus large, un LLM présenté avec l'un de ces chunks ne peut pas résoudre les références anaphoriques comme « it » ou « the city ».
Il existe certaines heuristiques pour atténuer ce problème, comme le rééchantillonnage avec une fenêtre glissante, l'utilisation de plusieurs longueurs de fenêtres de contexte et l'exécution de balayages de documents en plusieurs passes. Cependant, comme toutes les heuristiques, ces approches sont aléatoires ; elles peuvent fonctionner dans certains cas, mais il n'y a aucune garantie théorique de leur efficacité.
tagLa solution : Late Chunking
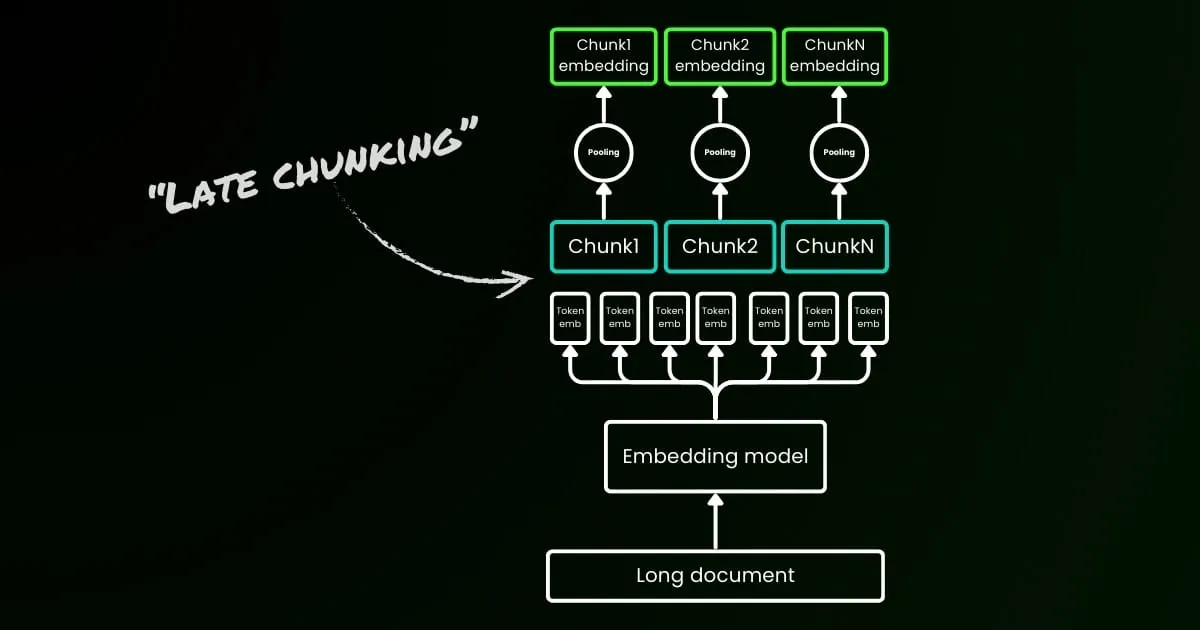
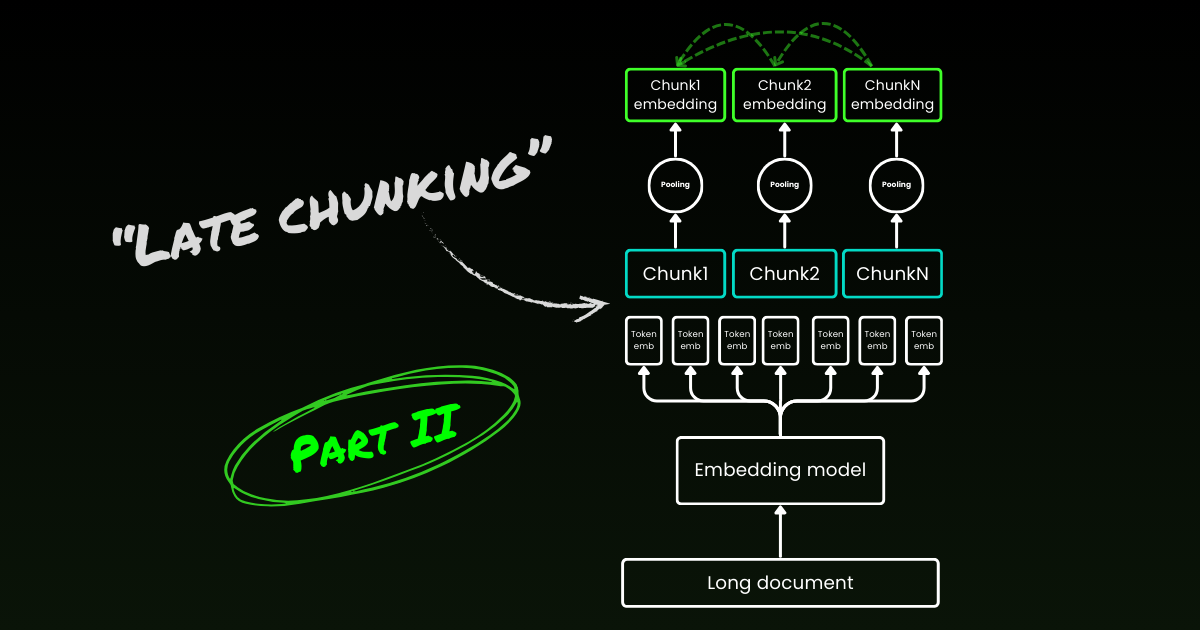
L'approche d'encodage naïve (comme on le voit sur le côté gauche de l'image ci-dessous) implique d'utiliser des phrases, des paragraphes ou des limites de longueur maximale pour diviser le texte a priori. Ensuite, un modèle d'embedding est appliqué de manière répétée à ces chunks résultants. Pour générer un seul embedding pour chaque chunk, de nombreux modèles d'embedding utilisent le mean pooling sur ces embeddings au niveau des tokens pour produire un seul vecteur d'embedding.

En revanche, l'approche « Late Chunking » que nous proposons dans cet article applique d'abord la couche transformer du modèle d'embedding à l'ensemble du texte ou autant que possible. Cela génère une séquence de représentations vectorielles pour chaque token qui englobe les informations textuelles de l'ensemble du texte. Ensuite, le mean pooling est appliqué à chaque chunk de cette séquence de vecteurs de tokens, produisant des embeddings pour chaque chunk qui prennent en compte le contexte du texte entier. Contrairement à l'approche d'encodage naïve, qui génère des embeddings de chunks indépendants et identiquement distribués (i.i.d.), le late chunking crée un ensemble d'embeddings de chunks où chacun est « conditionné par » les précédents, encodant ainsi plus d'informations contextuelles pour chaque chunk.
Évidemment, pour appliquer efficacement le late chunking, nous avons besoin de modèles d'embedding à contexte long comme jina-embeddings-v2-base-en, qui supportent jusqu'à 8192 tokens—environ dix pages standard de texte. Les segments de texte de cette taille sont beaucoup moins susceptibles d'avoir des dépendances contextuelles qui nécessitent un contexte encore plus long à résoudre.
Il est important de souligner que le late chunking nécessite toujours des indices de frontière, mais ces indices ne sont utilisés qu'après l'obtention des embeddings au niveau des tokens—d'où le terme « late » dans sa dénomination.
| Découpage naïf | Late Chunking | |
|---|---|---|
| Le besoin d'indices de frontière | Oui | Oui |
| L'utilisation des indices de frontière | Directement en prétraitement | Après l'obtention des embeddings au niveau des tokens de la couche transformer |
| Les embeddings de chunks résultants | i.i.d. | Conditionnels |
| Informations contextuelles des chunks voisins | Perdues. Quelques heuristiques (comme l'échantillonnage avec chevauchement) pour atténuer cela | Bien préservées par les modèles d'embedding à contexte long |
tagImplémentation et évaluation qualitative


L'implémentation du late chunking peut être trouvée dans le Google Colab lié ci-dessus. Ici, nous utilisons notre récente fonctionnalité publiée dans l'API Tokenizer, qui exploite tous les indices de frontière possibles pour segmenter un long document en chunks significatifs. Plus de discussions sur l'algorithme derrière cette fonctionnalité peuvent être trouvées sur X.

En appliquant le chunking tardif à l'exemple Wikipedia ci-dessus, on peut immédiatement constater une amélioration de la similarité sémantique. Par exemple, dans le cas de "la ville" et "Berlin" dans un article Wikipedia, les vecteurs représentant "la ville" contiennent maintenant des informations la reliant à la mention précédente de "Berlin", ce qui en fait une bien meilleure correspondance pour les requêtes impliquant ce nom de ville.
| Query | Chunk | Sim. on naive chunking | Sim. on late chunking |
|---|---|---|---|
| Berlin | Berlin is the capital and largest city of Germany, both by area and by population. | 0.849 | 0.850 |
| Berlin | Its more than 3.85 million inhabitants make it the European Union's most populous city, as measured by population within city limits. | 0.708 | 0.825 |
| Berlin | The city is also one of the states of Germany, and is the third smallest state in the country in terms of area. | 0.753 | 0.850 |
Vous pouvez observer cela dans les résultats numériques ci-dessus, qui comparent l'embedding du terme "Berlin" à diverses phrases de l'article sur Berlin en utilisant la similarité cosinus. La colonne "Sim. on IID chunk embeddings" montre les valeurs de similarité entre l'embedding de la requête "Berlin" et les embeddings utilisant le chunking a priori, tandis que "Sim. under contextual chunk embedding" représente les résultats avec la méthode de chunking tardif.
tagÉvaluation quantitative sur BEIR
Pour vérifier l'efficacité du chunking tardif au-delà d'un exemple simple, nous l'avons testé en utilisant certains des benchmarks de récupération de BeIR. Ces tâches de récupération consistent en un ensemble de requêtes, un corpus de documents textuels et un fichier QRels qui stocke les informations sur les ID des documents pertinents pour chaque requête.
Pour identifier les documents pertinents pour une requête, les documents sont découpés, encodés dans un index d'embeddings, et les chunks les plus similaires sont déterminés pour chaque embedding de requête en utilisant les k plus proches voisins (kNN). Puisque chaque chunk correspond à un document, le classement kNN des chunks peut être converti en un classement kNN des documents (en ne conservant que la première occurrence pour les documents apparaissant plusieurs fois dans le classement). Ce classement résultant est ensuite comparé au classement fourni par le fichier QRels de référence, et les métriques de récupération comme nDCG@10 sont calculées. Cette procédure est illustrée ci-dessous, et le script d'évaluation peut être trouvé dans ce référentiel pour la reproductibilité.
 jina-ai
jina-aiNous avons effectué cette évaluation sur différents jeux de données BeIR, en comparant le chunking naïf avec notre méthode de chunking tardif. Pour obtenir les indices de limite, nous avons utilisé une regex qui divise les textes en chaînes d'environ 256 tokens. L'évaluation du chunking naïf et tardif a utilisé jina-embeddings-v2-small-en comme modèle d'embedding ; une version plus petite du modèle v2-base-en qui prend toujours en charge jusqu'à 8192 tokens. Les résultats peuvent être trouvés dans le tableau ci-dessous.
| Dataset | Avg. Document Length (characters) | Naive Chunking (nDCG@10) | Late Chunking (nDCG@10) | No Chunking (nDCG@10) |
|---|---|---|---|---|
| SciFact | 1498.4 | 64.20% | 66.10% | 63.89% |
| TRECCOVID | 1116.7 | 63.36% | 64.70% | 65.18% |
| FiQA2018 | 767.2 | 33.25% | 33.84% | 33.43% |
| NFCorpus | 1589.8 | 23.46% | 29.98% | 30.40% |
| Quora | 62.2 | 87.19% | 87.19% | 87.19% |
Dans tous les cas, le chunking tardif a amélioré les scores par rapport à l'approche naïve. Dans certains cas, il a même surpassé l'encodage du document entier en un seul embedding, tandis que dans d'autres jeux de données, l'absence de chunking a donné les meilleurs résultats (bien sûr, l'absence de chunking n'a de sens que s'il n'est pas nécessaire de classer les chunks, ce qui est rare en pratique). Si nous traçons l'écart de performance entre l'approche naïve et le chunking tardif en fonction de la longueur du document, il devient évident que la longueur moyenne des documents est corrélée avec de plus grandes améliorations des scores nDCG grâce au chunking tardif. En d'autres termes, plus le document est long, plus la stratégie de chunking tardif devient efficace.

tagConclusion
Dans cet article, nous avons présenté une approche simple appelée "chunking tardif" pour intégrer de courts chunks en exploitant la puissance des modèles d'embedding à contexte long. Nous avons démontré comment l'embedding de chunk i.i.d. traditionnel ne préserve pas les informations contextuelles, conduisant à une récupération sous-optimale ; et comment le chunking tardif offre une solution simple mais très efficace pour maintenir et conditionner les informations contextuelles dans chaque chunk. L'efficacité du chunking tardif devient de plus en plus significative sur les documents plus longs — une capacité rendue possible uniquement par les modèles d'embedding à contexte long avancés comme jina-embeddings-v2-base-en. Nous espérons que ce travail non seulement valide l'importance des modèles d'embedding à contexte long mais inspire également des recherches supplémentaires sur ce sujet.
Continuez la lecture de la partie II : plongée approfondie dans les indices de limite et les idées fausses.





