




En avril 2024, nous avons lancé Jina Reader, une API simple qui convertit n'importe quelle URL en markdown compatible LLM avec un simple préfixe : r.jina.ai. Malgré la programmation réseau sophistiquée en coulisses, la partie « lecture » principale est assez simple. D'abord, nous utilisons un navigateur Chrome headless pour récupérer la source de la page web. Ensuite, nous utilisons le package Readability de Mozilla pour extraire le contenu principal, en supprimant les éléments comme les en-têtes, les pieds de page, les barres de navigation et les barres latérales. Enfin, nous convertissons le HTML nettoyé en markdown en utilisant des expressions régulières et la bibliothèque Turndown. Le résultat est un fichier markdown bien structuré, prêt à être utilisé par les LLM pour l'ancrage, le résumé et le raisonnement.
Dans les premières semaines suivant la sortie de Jina Reader, nous avons reçu beaucoup de retours, particulièrement concernant la qualité du contenu. Certains utilisateurs l'ont trouvé trop détaillé, tandis que d'autres estimaient qu'il ne l'était pas assez. Il y a également eu des signalements indiquant que le filtre Readability supprimait le mauvais contenu ou que Turndown avait du mal à convertir certaines parties du HTML en markdown. Heureusement, beaucoup de ces problèmes ont été résolus avec succès en corrigeant le pipeline existant avec de nouveaux motifs regex ou heuristiques.
Depuis lors, nous nous sommes posé une question : au lieu de le corriger avec plus d'heuristiques et de regex (qui deviennent de plus en plus difficiles à maintenir et ne sont pas multilingues), pouvons-nous résoudre ce problème de bout en bout avec un modèle de langage ?
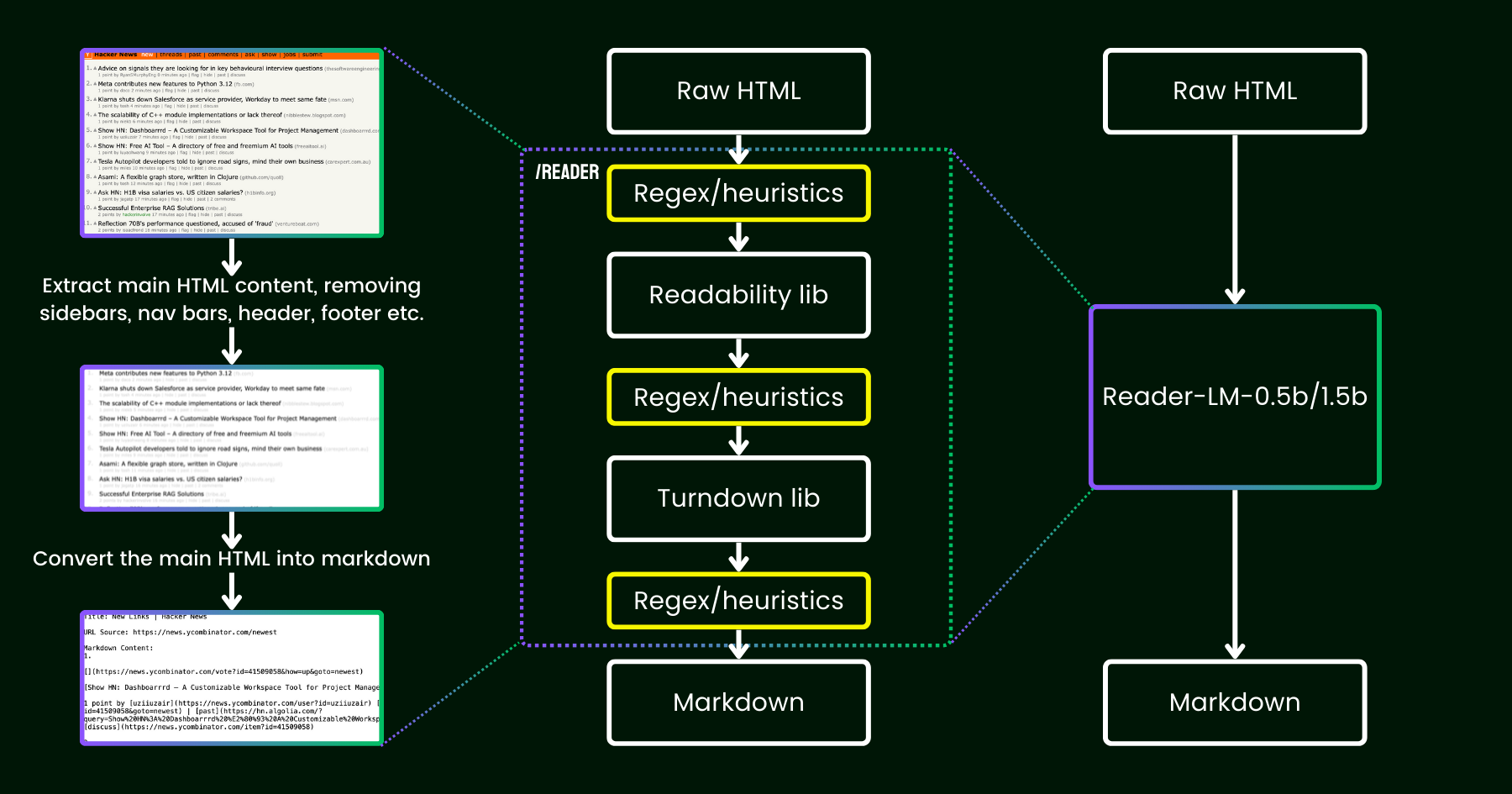
reader-lm, remplaçant le pipeline readability+turndown+heuristiques regex par un petit modèle de langage.À première vue, l'utilisation des LLM pour le nettoyage des données peut sembler excessive en raison de leur faible rapport coût-efficacité et de leur lenteur. Mais que se passe-t-il si nous envisageons un petit modèle de langage (SLM) — un modèle avec moins d'un milliard de paramètres qui peut fonctionner efficacement en périphérie ? Cela semble beaucoup plus attrayant, n'est-ce pas ? Mais est-ce vraiment faisable ou juste un vœu pieux ? Selon la loi d'échelle, moins de paramètres conduisent généralement à une réduction des capacités de raisonnement et de synthèse. Un SLM pourrait donc même avoir du mal à générer un contenu significatif si sa taille de paramètres est trop petite. Pour explorer cela plus en détail, examinons de plus près la tâche de conversion HTML vers Markdown :
- Premièrement, la tâche que nous envisageons n'est pas aussi créative ou complexe que les tâches LLM typiques. Dans le cas de la conversion HTML vers markdown, le modèle doit principalement copier sélectivement de l'entrée vers la sortie (c'est-à-dire ignorer le balisage HTML, les barres latérales, les en-têtes, les pieds de page), avec un effort minimal consacré à la génération de nouveau contenu (principalement l'insertion de syntaxe markdown). Cela contraste fortement avec les tâches plus larges que gèrent les LLM, comme la génération de poèmes ou l'écriture de code, où la sortie implique beaucoup plus de créativité et n'est pas une simple copie-colle de l'entrée. Cette observation suggère qu'un SLM pourrait fonctionner, car la tâche semble plus simple que la génération de texte plus générale.
- Deuxièmement, nous devons prioriser le support du contexte long. Le HTML moderne contient souvent beaucoup plus de bruit que le simple balisage
<div>. Le CSS en ligne et les scripts peuvent facilement faire gonfler le code à des centaines de milliers de tokens. Pour qu'un SLM soit pratique dans ce scénario, la longueur du contexte doit être suffisamment grande. Une longueur de tokens de 8K ou 16K n'est pas du tout utile.
Il semble que ce dont nous ayons besoin soit un SLM peu profond mais large. "Peu profond" dans le sens où la tâche est principalement un simple "copier-coller", donc moins de blocs transformers sont nécessaires ; et "large" dans le sens où il nécessite un support de contexte long pour être pratique, donc le mécanisme d'attention nécessite une certaine attention. Des recherches antérieures ont montré que la longueur du contexte et la capacité de raisonnement sont étroitement liées. Pour un SLM, il est extrêmement difficile d'optimiser les deux dimensions tout en gardant la taille des paramètres petite.
Aujourd'hui, nous sommes ravis d'annoncer la première version de cette solution avec la sortie de reader-lm-0.5b et reader-lm-1.5b, deux SLM spécifiquement entraînés pour générer du markdown propre directement à partir de HTML brut bruité. Les deux modèles sont multilingues et supportent une longueur de contexte allant jusqu'à 256K tokens. Malgré leur taille compacte, ces modèles atteignent des performances état de l'art sur cette tâche, surpassant leurs homologues LLM plus grands tout en ne faisant que 1/50ème de leur taille.

Voici les spécifications des deux modèles :
| reader-lm-0.5b | reader-lm-1.5b | |
|---|---|---|
| # Paramètres | 494M | 1.54B |
| Longueur de contexte | 256K | 256K |
| Hidden Size | 896 | 1536 |
| # Layers | 24 | 28 |
| # Query Heads | 14 | 12 |
| # KV Heads | 2 | 2 |
| Head Size | 64 | 128 |
| Intermediate Size | 4864 | 8960 |
| Multilingue | Oui | Oui |
| Dépôt HuggingFace | Lien | Lien |
tagDébuter avec Reader-LM
tagSur Google Colab
La façon la plus simple d'expérimenter reader-lm est d'exécuter notre notebook Colab, où nous démontrons comment utiliser reader-lm-1.5b pour convertir le site Hacker News en markdown. Le notebook est optimisé pour fonctionner sans problème sur le niveau GPU T4 gratuit de Google Colab. Vous pouvez également charger reader-lm-0.5b ou changer l'URL vers n'importe quel site web et explorer la sortie. Notez que l'entrée (c'est-à-dire le prompt) du modèle est le HTML brut — aucune instruction de préfixe n'est requise.

Veuillez noter que le GPU T4 de la version gratuite présente des limitations qui peuvent empêcher l'utilisation d'optimisations avancées lors de l'exécution du modèle. Des fonctionnalités comme bfloat16 et flash attention ne sont pas disponibles sur le T4, ce qui peut entraîner une utilisation plus élevée de la VRAM et des performances plus lentes pour les entrées plus longues. Pour les environnements de production, nous recommandons d'utiliser un GPU haut de gamme comme le RTX 3090/4090 pour des performances nettement meilleures.
tagEn Production : Bientôt Disponible sur Azure & AWS
Reader-LM est disponible sur Azure Marketplace et AWS SageMaker. Si vous devez utiliser ces modèles au-delà de ces plateformes ou sur site au sein de votre entreprise, notez que les deux modèles sont sous licence CC BY-NC 4.0. Pour toute demande d'utilisation commerciale, n'hésitez pas à nous contacter.


tagBenchmark
Pour évaluer quantitativement les performances de Reader-LM, nous l'avons comparé à plusieurs grands modèles de langage, notamment : GPT-4o, Gemini-1.5-Flash, Gemini-1.5-Pro, LLaMA-3.1-70B, Qwen2-7B-Instruct.
Les modèles ont été évalués selon les métriques suivantes :
- ROUGE-L (plus élevé est meilleur) : Cette métrique, largement utilisée pour les tâches de résumé et de questions-réponses, mesure le chevauchement entre la sortie prédite et la référence au niveau des n-grammes.
- Taux d'Erreur de Token (TER, plus bas est meilleur) : Cette métrique calcule le taux auquel les tokens markdown générés n'apparaissent pas dans le contenu HTML d'origine. Nous avons conçu cette métrique pour évaluer le taux d'hallucination du modèle, nous aidant à identifier les cas où le modèle produit du contenu qui n'est pas ancré dans le HTML. D'autres améliorations seront apportées sur la base d'études de cas.
- Taux d'Erreur de Mots (WER, plus bas est meilleur) : Couramment utilisé dans les tâches OCR et ASR, le WER prend en compte la séquence de mots et calcule les erreurs telles que les insertions (ADD), les substitutions (SUB) et les suppressions (DEL). Cette métrique fournit une évaluation détaillée des écarts entre le markdown généré et la sortie attendue.
Pour exploiter les LLM pour cette tâche, nous avons utilisé l'instruction uniforme suivante comme prompt de préfixe :
Your task is to convert the content of the provided HTML file into the corresponding markdown file. You need to convert the structure, elements, and attributes of the HTML into equivalent representations in markdown format, ensuring that no important information is lost. The output should strictly be in markdown format, without any additional explanations.Les résultats se trouvent dans le tableau ci-dessous.
| ROUGE-L | WER | TER | |
|---|---|---|---|
| reader-lm-0.5b | 0.56 | 3.28 | 0.34 |
| reader-lm-1.5b | 0.72 | 1.87 | 0.19 |
| gpt-4o | 0.43 | 5.88 | 0.50 |
| gemini-1.5-flash | 0.40 | 21.70 | 0.55 |
| gemini-1.5-pro | 0.42 | 3.16 | 0.48 |
| llama-3.1-70b | 0.40 | 9.87 | 0.50 |
| Qwen2-7B-Instruct | 0.23 | 2.45 | 0.70 |
tagÉtude Qualitative
Nous avons mené une étude qualitative en inspectant visuellement la sortie markdown. Nous avons sélectionné 22 sources HTML comprenant des articles d'actualité, des articles de blog, des pages d'accueil, des pages e-commerce et des posts de forum en plusieurs langues : anglais, allemand, japonais et chinois. Nous avons également inclus l'API Jina Reader comme référence, qui s'appuie sur des expressions régulières, des heuristiques et des règles prédéfinies.
L'évaluation s'est concentrée sur quatre dimensions clés de la sortie, chaque modèle étant noté sur une échelle de 1 (plus bas) à 5 (plus haut) :
- Extraction des en-têtes : Évalue la capacité de chaque modèle à identifier et formater les en-têtes h1, h2,..., h6 du document en utilisant la syntaxe markdown correcte.
- Extraction du contenu principal : Évalue la capacité des modèles à convertir avec précision le texte principal, en préservant les paragraphes, le formatage des listes et la cohérence de la présentation.
- Préservation de la structure riche : Analyse l'efficacité avec laquelle chaque modèle maintient la structure globale du document, y compris les titres, sous-titres, puces et listes ordonnées.
- Utilisation de la syntaxe Markdown : Évalue la capacité de chaque modèle à convertir correctement les éléments HTML tels que
<a>(liens),<strong>(texte en gras) et<em>(italique) en leurs équivalents markdown appropriés.
Les résultats se trouvent ci-dessous.

Reader-LM-1.5B performe de manière constante dans toutes les dimensions, excellant particulièrement dans la préservation de la structure et l'utilisation de la syntaxe markdown. Bien qu'il ne surpasse pas toujours l'API Jina Reader, ses performances sont compétitives avec des modèles plus grands comme Gemini 1.5 Pro, en faisant une alternative très efficace aux LLM plus grands. Reader-LM-0.5B, bien que plus petit, offre toujours des performances solides, particulièrement dans la préservation de la structure.
tagComment Nous Avons Entraîné Reader-LM
tagPréparation des Données
Nous avons utilisé l'API Jina Reader pour générer des paires d'entraînement de HTML brut et leur markdown correspondant. Durant l'expérience, nous avons constaté que les SLM sont particulièrement sensibles à la qualité des données d'entraînement. Nous avons donc construit un pipeline de données qui garantit que seules les entrées markdown de haute qualité sont incluses dans l'ensemble d'entraînement.
De plus, nous avons ajouté du HTML synthétique et leurs équivalents markdown, générés par GPT-4o. Par rapport au HTML du monde réel, les données synthétiques ont tendance à être beaucoup plus courtes, avec des structures plus simples et plus prévisibles, et un niveau de bruit significativement plus bas.
Enfin, nous avons concaténé le HTML et le markdown en utilisant un modèle de chat. Les données d'entraînement finales sont formatées comme suit :
<|im_start|>system
You are a helpful assistant.<|im_end|>
<|im_start|>user
{{RAW_HTML}}<|im_end|>
<|im_start|>assistant
{{MARKDOWN}}<|im_end|>
Les données d'entraînement complètes représentent 2,5 milliards de tokens.
tagEntraînement en Deux Étapes
Nous avons expérimenté avec différentes tailles de modèles, allant de 65M et 135M jusqu'à 3B paramètres. Les spécifications pour chaque modèle sont présentées dans le tableau ci-dessous.
| reader-lm-65m | reader-lm-135m | reader-lm-360m | reader-lm-0.5b | reader-lm-1.5b | reader-lm-1.7b | reader-lm-3b | |
|---|---|---|---|---|---|---|---|
| Hidden Size | 512 | 576 | 960 | 896 | 1536 | 2048 | 3072 |
| # Layers | 8 | 30 | 32 | 24 | 28 | 24 | 32 |
| # Query Heads | 16 | 9 | 15 | 14 | 12 | 32 | 32 |
| # KV Heads | 8 | 3 | 5 | 2 | 2 | 32 | 32 |
| Head Size | 32 | 64 | 64 | 64 | 128 | 64 | 96 |
| Intermediate Size | 2048 | 1536 | 2560 | 4864 | 8960 | 8192 | 8192 |
| Attention Bias | False | False | False | True | True | False | False |
| Embedding Tying | False | True | True | True | True | True | False |
| Vocabulary Size | 32768 | 49152 | 49152 | 151646 | 151646 | 49152 | 32064 |
| Base Model | Lite-Oute-1-65M-Instruct | SmolLM-135M | SmolLM-360M-Instruct | Qwen2-0.5B-Instruct | Qwen2-1.5B-Instruct | SmolLM-1.7B | Phi-3-mini-128k-instruct |
L'entraînement du modèle s'est déroulé en deux étapes :
- HTML court et simple : Dans cette étape, la longueur maximale des séquences (HTML + markdown) était fixée à 32K tokens, avec un total de 1,5 milliard de tokens d'entraînement.
- HTML long et complexe : la longueur de séquence a été étendue à 128K tokens, avec 1,2 milliard de tokens d'entraînement. Nous avons implémenté le mécanisme zigzag-ring-attention de « Ring Flash Attention » de Zilin Zhu (2024) pour cette étape.
Étant donné que les données d'entraînement incluaient des séquences allant jusqu'à 128K tokens, nous pensons que le modèle peut prendre en charge jusqu'à 256K tokens sans problème. Cependant, la gestion de 512K tokens pourrait être difficile, car l'extension des embeddings positionnels RoPE à quatre fois la longueur de la séquence d'entraînement pourrait entraîner une dégradation des performances.
Pour les modèles de 65M et 135M paramètres, nous avons observé qu'ils pouvaient atteindre un comportement de « copie » raisonnable, mais uniquement avec des séquences courtes (moins de 1K tokens). À mesure que la longueur d'entrée augmentait, ces modèles avaient du mal à produire une sortie raisonnable. Étant donné que le code source HTML moderne peut facilement dépasser 100K tokens, une limite de 1K tokens est loin d'être suffisante.
tagDégénération et boucles monotones
L'un des principaux défis que nous avons rencontrés était la dégénération, particulièrement sous forme de répétition et de bouclage. Après avoir généré quelques tokens, le modèle commençait à générer le même token de manière répétée ou se retrouvait piégé dans une boucle, répétant continuellement une courte séquence de tokens jusqu'à atteindre la longueur maximale de sortie autorisée.

Pour résoudre ce problème :
- Nous avons appliqué la recherche contrastive comme méthode de décodage et incorporé une perte contrastive pendant l'entraînement. D'après nos expériences, cette méthode a effectivement réduit la génération répétitive en pratique.
- Nous avons implémenté un critère simple d'arrêt des répétitions dans le pipeline transformer. Ce critère détecte automatiquement quand le modèle commence à répéter des tokens et arrête le décodage plus tôt pour éviter les boucles monotones. Cette idée s'est inspirée de cette discussion.
tagEfficacité d'entraînement sur les entrées longues
Pour atténuer le risque d'erreurs de mémoire insuffisante (OOM) lors du traitement d'entrées longues, nous avons implémenté un transfert de modèle par morceaux. Cette approche encode l'entrée longue avec des morceaux plus petits, réduisant l'utilisation de la VRAM.
Nous avons amélioré l'implémentation du regroupement des données dans notre framework d'entraînement, qui est basé sur Transformers Trainer. Pour optimiser l'efficacité de l'entraînement, plusieurs textes courts (par exemple, 2K tokens) sont concaténés en une seule longue séquence (par exemple, 30K tokens), permettant un entraînement sans remplissage. Cependant, dans l'implémentation originale, certains exemples courts étaient divisés en deux sous-textes et inclus dans différentes séquences d'entraînement longues. Dans ces cas, le second sous-texte perdait son contexte (par exemple, le contenu HTML brut dans notre cas), conduisant à des données d'entraînement corrompues. Cela force le modèle à s'appuyer sur ses paramètres plutôt que sur le contexte d'entrée, ce que nous considérons comme une source majeure d'hallucination.
Au final, nous avons sélectionné les modèles 0.5B et 1.5B pour publication. Le modèle 0.5B est le plus petit capable d'atteindre le comportement de « copie sélective » souhaité sur des entrées à long contexte, tandis que le modèle 1.5B est le plus petit modèle plus grand qui améliore significativement les performances sans atteindre les rendements décroissants par rapport à la taille des paramètres.
tagArchitecture alternative : Modèle Encoder-Only
Au début de ce projet, nous avons également exploré l'utilisation d'une architecture encoder-only pour aborder cette tâche. Comme mentionné précédemment, la tâche de conversion HTML vers Markdown semble être principalement une tâche de « copie sélective ». Étant donné une paire d'entraînement (HTML brut et markdown), nous pouvons étiqueter les tokens qui existent à la fois dans l'entrée et la sortie comme 1, et le reste comme 0. Cela transforme le problème en une tâche de classification de tokens, similaire à ce qui est utilisé dans la Reconnaissance d'Entités Nommées (NER).
Bien que cette approche semblait logique, elle présentait des défis significatifs en pratique. Premièrement, le HTML brut provenant de sources réelles est extrêmement bruyant et long, rendant les étiquettes 1 extrêmement éparses et donc difficiles à apprendre pour le modèle. Deuxièmement, l'encodage de la syntaxe markdown spéciale dans un schéma 0-1 s'est avéré problématique, car des symboles comme ## title, *bold*, et | table | n'existent pas dans l'entrée HTML brute. Troisièmement, les tokens de sortie ne suivent pas toujours strictement l'ordre de l'entrée. Des réorganisations mineures se produisent souvent, particulièrement avec les tableaux et les liens, rendant difficile la représentation de tels comportements de réorganisation dans un schéma simple 0-1. La réorganisation à courte distance pourrait potentiellement être gérée avec la programmation dynamique ou des algorithmes d'alignement-warping en introduisant des étiquettes comme -1, -2, +1, +2 pour représenter les décalages de distance, transformant le problème de classification binaire en une tâche de classification de tokens multi-classes.
En résumé, résoudre le problème avec une architecture encoder-only et le traiter comme une tâche de classification de tokens a son charme, d'autant plus que les séquences d'entraînement sont beaucoup plus courtes par rapport à un modèle decoder-only, ce qui le rend plus économe en VRAM. Cependant, le défi majeur réside dans la préparation de bonnes données d'entraînement. Lorsque nous avons réalisé que le temps et l'effort consacrés au prétraitement des données - utilisant la programmation dynamique et des heuristiques pour créer des séquences d'étiquetage parfaites au niveau des tokens - étaient écrasants, nous avons décidé d'abandonner cette approche.
tagConclusion
Reader-LM est un nouveau petit modèle de langage (SLM) conçu pour l'extraction et le nettoyage de données sur le web ouvert. Inspiré par Jina Reader, notre objectif était de créer une solution de modèle de langage de bout en bout capable de convertir du HTML brut et bruité en markdown propre. En parallèle, nous nous sommes concentrés sur l'efficacité des coûts, en gardant la taille du modèle réduite pour garantir que Reader-LM reste pratique et utilisable. C'est également le premier modèle décodeur uniquement à contexte long entraîné chez Jina AI.
Bien que la tâche puisse sembler initialement être un simple problème de "copie sélective", la conversion et le nettoyage du HTML vers markdown est loin d'être simple. Plus précisément, cela nécessite que le modèle excelle dans le raisonnement contextuel conscient de la position, ce qui exige une taille de paramètres plus importante, particulièrement dans les couches cachées. En comparaison, l'apprentissage de la syntaxe markdown est relativement simple.
Durant nos expériences, nous avons également constaté que l'entraînement d'un SLM à partir de zéro est particulièrement difficile. Commencer avec un modèle pré-entraîné et poursuivre avec un entraînement spécifique à la tâche a considérablement amélioré l'efficacité de l'entraînement. Il reste encore beaucoup de marge d'amélioration en termes d'efficacité et de qualité : l'extension de la longueur du contexte, l'accélération du décodage, et l'ajout du support des instructions dans l'entrée, ce qui permettrait à Reader-LM d'extraire des parties spécifiques d'une page web en markdown.
