
Depuis la sortie du modèle O1 par OpenAI, l'un des sujets les plus discutés dans la communauté IA a été le scaling test-time compute. Cela fait référence à l'allocation de ressources de calcul supplémentaires pendant l'inférence — la phase où un modèle d'IA génère des sorties en réponse à des entrées — plutôt que pendant le pré-entraînement. Un exemple bien connu est le raisonnement multi-étapes "chain of thought", qui permet aux modèles d'effectuer des délibérations internes plus approfondies, comme l'évaluation de plusieurs réponses potentielles, une planification plus poussée, une auto-réflexion avant d'arriver à une réponse finale. Cette stratégie améliore la qualité des réponses, particulièrement dans les tâches de raisonnement complexe. Le modèle QwQ-32B-Preview récemment publié par Alibaba suit cette tendance d'amélioration du raisonnement de l'IA grâce à l'augmentation du test-time compute.
Lors de l'utilisation du modèle O1 d'OpenAI, les utilisateurs peuvent clairement remarquer que l'inférence multi-étapes nécessite du temps supplémentaire pendant que le modèle construit des chaînes de raisonnement pour résoudre les problèmes.
Chez Jina AI, nous nous concentrons davantage sur les embeddings et les rerankers que sur les LLM, donc pour nous, il est naturel d'envisager le scaling test-time compute dans ce contexte : Comment le "chain-of-thought" peut-il être appliqué aux modèles d'embedding ? Bien que cela puisse ne pas sembler intuitif au premier abord, cet article explore une nouvelle perspective et démontre comment le scaling test-time compute peut être appliqué à jina-clip pour classifier des images hors distribution (OOD) — résolvant des tâches qui seraient autrement impossibles.

tagÉtude de cas

Notre expérience s'est concentrée sur la classification des Pokemon en utilisant le dataset TheFusion21/PokemonCards, qui contient des milliers d'images de cartes Pokemon. La tâche est la classification d'images où l'entrée est une illustration de carte Pokemon recadrée (avec tous les textes/descriptions supprimés) et la sortie est le nom correct du Pokemon parmi un ensemble prédéfini de noms. Cette tâche présente un défi particulièrement intéressant pour les modèles d'embedding CLIP car :
- Les noms et les visuels des Pokemon représentent des concepts de niche, hors distribution pour le modèle, rendant la classification directe difficile
- Chaque Pokemon possède des traits visuels clairs qui peuvent être décomposés en éléments de base (formes, couleurs, poses) que CLIP pourrait mieux comprendre
- L'illustration de la carte fournit un format visuel cohérent tout en introduisant de la complexité à travers des arrière-plans, poses et styles artistiques variés
- La tâche nécessite d'intégrer simultanément plusieurs caractéristiques visuelles, similaire aux chaînes de raisonnement complexes dans les modèles de langage

Absol G, Aerodactyl, Weedle, Caterpie, Azumarill, Bulbasaur, Venusaur, Absol, Aggron, Beedrill δ, Alakazam, Ampharos, Dratini, Ampharos, Ampharos, Arcanine, Blaine's Moltres, Aerodactyl, Celebi & Venusaur-GX, Caterpie]tagBase de référence
L'approche de base utilise une simple comparaison directe entre l'illustration des cartes Pokémon et les noms. Tout d'abord, nous recadrons chaque image de carte Pokémon pour supprimer toutes les informations textuelles (en-tête, pied de page, description) afin d'éviter toute devinette triviale du modèle CLIP due à l'apparition des noms de Pokémon dans ces textes. Ensuite, nous encodons à la fois les images recadrées et les noms des Pokémon à l'aide des modèles jina-clip-v1 et jina-clip-v2 pour obtenir leurs embeddings respectifs. La classification est effectuée en calculant la similarité cosinus entre ces embeddings d'images et de textes - chaque image est associée au nom qui a le score de similarité le plus élevé. Cela crée une correspondance directe un-à-un entre l'illustration de la carte et les noms de Pokémon, sans aucune information contextuelle ou d'attribut supplémentaire. Le pseudo-code ci-dessous résume la méthode de base.
# Preprocessing
cropped_images = [crop_artwork(img) for img in pokemon_cards] # Remove text, keep only art
pokemon_names = ["Absol", "Aerodactyl", ...] # Raw Pokemon names
# Get embeddings using jina-clip-v1
image_embeddings = model.encode_image(cropped_images)
text_embeddings = model.encode_text(pokemon_names)
# Classification by cosine similarity
similarities = cosine_similarity(image_embeddings, text_embeddings)
predicted_names = [pokemon_names[argmax(sim)] for sim in similarities]
# Evaluate
accuracy = mean(predicted_names == ground_truth_names)tag"Chaîne de Pensées" pour la Classification
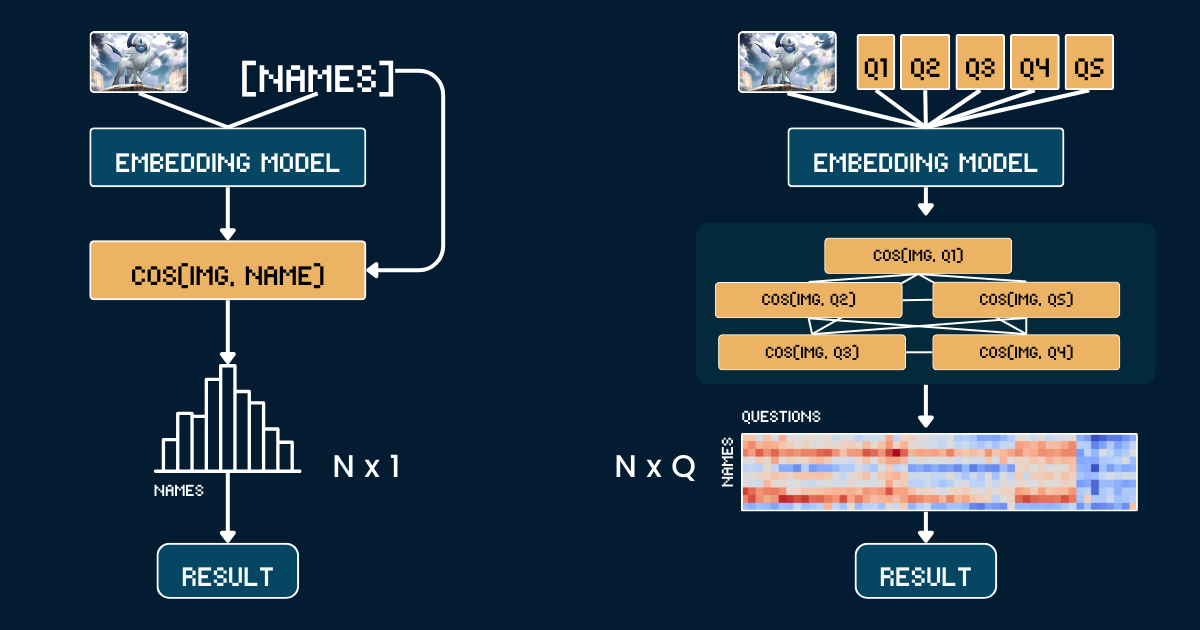
Au lieu de faire correspondre directement les images aux noms, nous décomposons la reconnaissance des Pokémon en un système structuré d'attributs visuels. Nous définissons cinq groupes d'attributs clés : la couleur dominante (par exemple, "blanc", "bleu"), la forme primaire (par exemple, "un loup", "un reptile ailé"), le trait caractéristique (par exemple, "une seule corne blanche", "grandes ailes"), la forme du corps (par exemple, "semblable à un loup sur quatre pattes", "ailé et élancé"), et la scène d'arrière-plan (par exemple, "l'espace", "forêt verte").
Pour chaque groupe d'attributs, nous créons des prompts textuels spécifiques (par exemple, "Ce Pokémon a un corps principalement de couleur {}") associés à des options pertinentes. Nous utilisons ensuite le modèle pour calculer les scores de similarité entre l'image et chaque option d'attribut. Ces scores sont convertis en probabilités à l'aide de softmax pour obtenir une mesure plus calibrée de la confiance.
La structure complète de la Chaîne de Pensées (CoT) se compose de deux parties : classification_groups qui décrit les groupes de prompts, et pokemon_rules qui définit quelles options d'attributs chaque Pokémon devrait correspondre. Par exemple, Absol devrait correspondre à "blanc" pour la couleur et "semblable à un loup" pour la forme. La CoT complète est montrée ci-dessous (nous expliquerons comment elle est construite plus tard) :
pokemon_system = {
"classification_cot": {
"dominant_color": {
"prompt": "This Pokémon's body is mainly {} in color.",
"options": [
"white", # Absol, Absol G
"gray", # Aggron
"brown", # Aerodactyl, Weedle, Beedrill δ
"blue", # Azumarill
"green", # Bulbasaur, Venusaur, Celebi&Venu, Caterpie
"yellow", # Alakazam, Ampharos
"red", # Blaine's Moltres
"orange", # Arcanine
"light blue"# Dratini
]
},
"primary_form": {
"prompt": "It looks like {}.",
"options": [
"a wolf", # Absol, Absol G
"an armored dinosaur", # Aggron
"a winged reptile", # Aerodactyl
"a rabbit-like creature", # Azumarill
"a toad-like creature", # Bulbasaur, Venusaur, Celebi&Venu
"a caterpillar larva", # Weedle, Caterpie
"a wasp-like insect", # Beedrill δ
"a fox-like humanoid", # Alakazam
"a sheep-like biped", # Ampharos
"a dog-like beast", # Arcanine
"a flaming bird", # Blaine's Moltres
"a serpentine dragon" # Dratini
]
},
"key_trait": {
"prompt": "Its most notable feature is {}.",
"options": [
"a single white horn", # Absol, Absol G
"metal armor plates", # Aggron
"large wings", # Aerodactyl, Beedrill δ
"rabbit ears", # Azumarill
"a green plant bulb", # Bulbasaur, Venusaur, Celebi&Venu
"a small red spike", # Weedle
"big green eyes", # Caterpie
"a mustache and spoons", # Alakazam
"a glowing tail orb", # Ampharos
"a fiery mane", # Arcanine
"flaming wings", # Blaine's Moltres
"a tiny white horn on head" # Dratini
]
},
"body_shape": {
"prompt": "The body shape can be described as {}.",
"options": [
"wolf-like on four legs", # Absol, Absol G
"bulky and armored", # Aggron
"winged and slender", # Aerodactyl, Beedrill δ
"round and plump", # Azumarill
"sturdy and four-legged", # Bulbasaur, Venusaur, Celebi&Venu
"long and worm-like", # Weedle, Caterpie
"upright and humanoid", # Alakazam, Ampharos
"furry and canine", # Arcanine
"bird-like with flames", # Blaine's Moltres
"serpentine" # Dratini
]
},
"background_scene": {
"prompt": "The background looks like {}.",
"options": [
"outer space", # Absol G, Beedrill δ
"green forest", # Azumarill, Bulbasaur, Venusaur, Weedle, Caterpie, Celebi&Venu
"a rocky battlefield", # Absol, Aggron, Aerodactyl
"a purple psychic room", # Alakazam
"a sunny field", # Ampharos
"volcanic ground", # Arcanine
"a red sky with embers", # Blaine's Moltres
"a calm blue lake" # Dratini
]
}
},
"pokemon_rules": {
"Absol": {
"dominant_color": 0,
"primary_form": 0,
"key_trait": 0,
"body_shape": 0,
"background_scene": 2
},
"Absol G": {
"dominant_color": 0,
"primary_form": 0,
"key_trait": 0,
"body_shape": 0,
"background_scene": 0
},
// ...
}
}
La classification finale combine ces probabilités d'attributs - au lieu d'une seule comparaison de similarité, nous faisons maintenant plusieurs comparaisons structurées et agrégeons leurs probabilités pour prendre une décision plus éclairée.
# Classification process
def classify_pokemon(image):
# Generate all text prompts
all_prompts = []
for group in classification_cot:
for option in group["options"]:
prompt = group["prompt"].format(option)
all_prompts.append(prompt)
# Get embeddings and similarities
image_embedding = model.encode_image(image)
text_embeddings = model.encode_text(all_prompts)
similarities = cosine_similarity(image_embedding, text_embeddings)
# Convert to probabilities per attribute group
probabilities = {}
for group_name, group_sims in group_similarities:
probabilities[group_name] = softmax(group_sims)
# Score each Pokemon based on matching attributes
scores = {}
for pokemon, rules in pokemon_rules.items():
score = 0
for group, target_idx in rules.items():
score += probabilities[group][target_idx]
scores[pokemon] = score
return max(scores, key=scores.get)tagAnalyse de la complexité
Supposons que nous voulions classer une image parmi N noms de Pokémon. L'approche de base nécessite de calculer N embeddings de texte (un pour chaque nom de Pokémon). En revanche, notre approche de calcul à l'échelle du temps de test nécessite de calculer Q embeddings de texte, où
Q représente le nombre total de combinaisons question-option pour toutes les questions. Les deux méthodes nécessitent le calcul d'un embedding d'image et une étape finale de classification, donc nous excluons ces opérations communes de notre comparaison. Dans cette étude de cas, notre N=13 et Q=52.Dans un cas extrême où Q = N, notre approche se réduirait essentiellement à la baseline. Cependant, la clé pour faire évoluer efficacement le calcul au moment du test est de :
- Construire des questions soigneusement choisies qui augmentent
Q - S'assurer que chaque question fournit des indices distincts et informatifs sur la réponse finale
- Concevoir des questions aussi orthogonales que possible pour maximiser leur gain d'information conjoint.
Cette approche est analogue au jeu des "Vingt Questions", où chaque question est stratégiquement choisie pour réduire efficacement les réponses possibles.
tagÉvaluation
Notre évaluation a été menée sur 117 images de test couvrant 13 classes différentes de Pokémon. Et le résultat est le suivant :
| Approach | jina-clip-v1 | jina-clip-v2 |
|---|---|---|
| Baseline | 31.36% | 16.10% |
| CoT | 46.61% | 38.14% |
| Improvement | +15.25% | +22.04% |
On peut voir que la même classification CoT offre des améliorations significatives pour les deux modèles (+15,25 % et +22,04 % respectivement) sur cette tâche inhabituelle ou OOD. Cela suggère également qu'une fois que le pokemon_system est construit, le même système CoT peut être efficacement transféré entre différents modèles ; et aucun fine-tuning ou post-training n'est nécessaire.
La performance relativement forte de la baseline de v1 (31,36 %) sur la classification Pokémon est remarquable. Ce modèle a été entraîné sur LAION-400M, qui incluait du contenu lié aux Pokémon. En revanche, v2 a été entraîné sur DFN-2B (sous-échantillonnage de 400M instances), un jeu de données de meilleure qualité mais plus filtré qui a peut-être exclu le contenu lié aux Pokémon, expliquant la performance de baseline plus faible de V2 (16,10 %) sur cette tâche spécifique.
tagConstruire pokemon_system efficacement
L'efficacité de notre approche de calcul au moment du test dépend fortement de la qualité de construction du pokemon_system. Il existe différentes approches pour construire ce système, de manuelle à entièrement automatisée.
Construction manuelle
L'approche la plus directe consiste à analyser manuellement le jeu de données Pokémon et à créer des groupes d'attributs, des prompts et des règles. Un expert du domaine devrait identifier les attributs visuels clés tels que la couleur, la forme et les caractéristiques distinctives. Il écrirait ensuite des prompts en langage naturel pour chaque attribut, énumérerait les options possibles pour chaque groupe d'attributs et associerait chaque Pokémon à ses options d'attributs correctes. Bien que cela fournisse des règles de haute qualité, c'est chronophage et ne s'adapte pas bien à un N plus grand.
Construction assistée par LLM
Nous pouvons utiliser les LLM pour accélérer ce processus en les incitant à générer le système de classification. Un prompt bien structuré demanderait des groupes d'attributs basés sur des caractéristiques visuelles, des modèles de prompts en langage naturel, des options complètes et mutuellement exclusives, et des règles de mapping pour chaque Pokémon. Le LLM peut rapidement générer une première version, bien que sa sortie puisse nécessiter une vérification.
I need help creating a structured system for Pokemon classification. For each Pokemon in this list: [Absol, Aerodactyl, Weedle, Caterpie, Azumarill, ...], create a classification system with:
1. Classification groups that cover these visual attributes:
- Dominant color of the Pokemon
- What type of creature it appears to be (primary form)
- Its most distinctive visual feature
- Overall body shape
- What kind of background/environment it's typically shown in
2. For each group:
- Create a natural language prompt template using "{}" for the option
- List all possible options that could apply to these Pokemon
- Make sure options are mutually exclusive and comprehensive
3. Create rules that map each Pokemon to exactly one option per attribute group, using indices to reference the options
Please output this as a Python dictionary with two main components:
- "classification_groups": containing prompts and options for each attribute
- "pokemon_rules": mapping each Pokemon to its correct attribute indices
Example format:
{
"classification_groups": {
"dominant_color": {
"prompt": "This Pokemon's body is mainly {} in color",
"options": ["white", "gray", ...]
},
...
},
"pokemon_rules": {
"Absol": {
"dominant_color": 0, # index for "white"
...
},
...
}
}Une approche plus robuste combine la génération par LLM avec la validation humaine. D'abord, le LLM génère un système initial. Ensuite, les experts humains examinent et corrigent les groupements d'attributs, l'exhaustivité des options et l'exactitude des règles. Le LLM affine le système en fonction de ce feedback, et le processus se répète jusqu'à l'obtention d'une qualité satisfaisante. Cette approche équilibre efficacité et précision.
Construction automatisée avec DSPy
Pour une approche entièrement automatisée, nous pouvons utiliser DSPy pour optimiser itérativement pokemon_system. Le processus commence avec un pokemon_system simple écrit soit manuellement soit par LLMs comme prompt initial. Chaque version est évaluée sur un ensemble de validation, utilisant la précision comme signal de feedback pour DSPy. Sur la base de cette performance, des prompts optimisés (c'est-à-dire de nouvelles versions de pokemon_system) sont générés. Ce cycle se répète jusqu'à convergence, et pendant tout le processus, le modèle d'embedding reste complètement fixe.
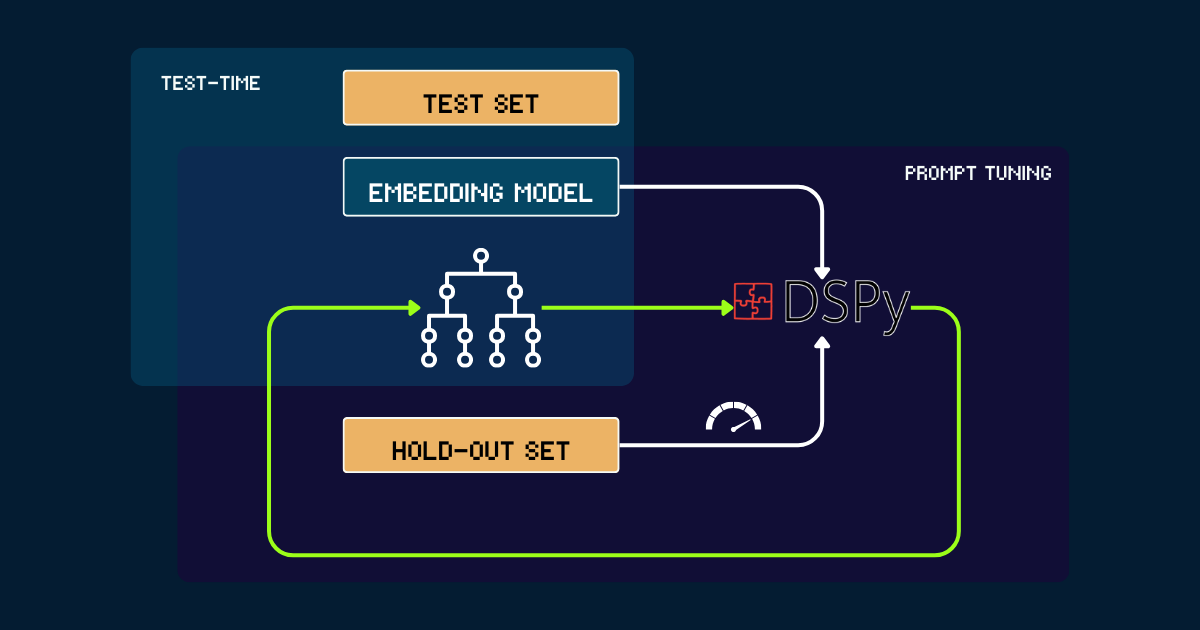
pokemon_system ; le processus d'optimisation ne doit être effectué qu'une seule fois pour chaque tâche.tagPourquoi faire évoluer le calcul au moment du test pour les modèles d'embedding ?
Parce que l'augmentation du pré-entraînement devient finalement économiquement impossible.
Depuis la sortie de la suite d'embeddings Jina — incluant jina-embeddings-v1, v2, v3, jina-clip-v1, v2, et jina-ColBERT-v1, v2 — chaque mise à niveau de modèle par le biais d'un pré-entraînement à grande échelle s'est accompagnée de coûts plus élevés. Par exemple, notre premier modèle, jina-embeddings-v1, sorti en juin 2023 avec 110M paramètres. Son entraînement à l'époque coûtait entre 5 000 et 10 000 $ selon la façon de mesurer. Avec jina-embeddings-v3, les améliorations sont significatives, mais elles proviennent principalement des ressources accrues investies. La trajectoire des coûts pour les modèles de pointe est passée de milliers à des dizaines de milliers de dollars et, pour les plus grandes entreprises d'IA, même des centaines de millions aujourd'hui. Bien que l'investissement de plus d'argent, de ressources et de données dans le pré-entraînement produise de meilleurs modèles, les rendements marginaux rendent finalement toute mise à l'échelle supplémentaire économiquement insoutenable.

D'autre part, les modèles d'embedding modernes deviennent de plus en plus puissants : multilingues, multitâches, multimodaux et capables de performances zero-shot et de suivi d'instructions solides. Cette versatilité laisse une grande marge pour les améliorations algorithmiques et l'augmentation du calcul au moment du test.
La question devient alors : quel est le coût que les utilisateurs sont prêts à payer pour une requête qui leur tient particulièrement à cœur ? Si tolérer des temps d'inférence plus longs pour des modèles pré-entraînés fixes améliore significativement la qualité des résultats, beaucoup trouveraient cela valable. À notre avis, il existe un potentiel substantiel inexploité dans l'augmentation du calcul au moment du test pour les modèles d'embedding. Cela représente un changement, passant de la simple augmentation de la taille du modèle pendant l'entraînement à l'amélioration de l'effort de calcul pendant la phase d'inférence pour obtenir de meilleures performances.
tagConclusion
Notre étude de cas sur le calcul au moment du test de jina-clip-v1/v2 montre plusieurs conclusions clés :
- Nous avons obtenu de meilleures performances sur des données inhabituelles ou hors distribution (OOD) sans aucun fine-tuning ou post-training sur les embeddings.
- Le système a fait des distinctions plus nuancées en affinant itérativement les recherches de similarité et les critères de classification.
- En incorporant des ajustements dynamiques de prompts et un raisonnement itératif, nous avons transformé le processus d'inférence du modèle d'embedding d'une simple requête en une chaîne de pensée plus sophistiquée.
Cette étude de cas ne fait qu'effleurer la surface de ce qui est possible avec le calcul au moment du test. Il reste une marge substantielle pour l'évolution algorithmique. Par exemple, nous pourrions développer des méthodes pour sélectionner itérativement les questions qui réduisent le plus efficacement l'espace des réponses, similaire à la stratégie optimale dans le jeu des "Vingt Questions". En faisant évoluer le calcul au moment du test, nous pouvons pousser les modèles d'embedding au-delà de leurs limitations actuelles et leur permettre d'aborder des tâches plus complexes et nuancées qui semblaient autrefois hors de portée.





