

En octobre 2023, nous avons introduit jina-embeddings-v2, la première famille de modèles d'embedding open-source capable de gérer des entrées allant jusqu'à 8 192 tokens. Dans la continuité, cette année nous avons lancé jina-embeddings-v3, offrant le même support étendu d'entrées avec des améliorations supplémentaires.

Dans cet article, nous allons approfondir les embeddings de contexte long et répondre à quelques questions : Quand est-il pratique de consolider un tel volume de texte en un seul vecteur ? La segmentation améliore-t-elle la recherche, et si oui, comment ? Comment pouvons-nous préserver le contexte des différentes parties d'un document tout en segmentant le texte ?
Pour répondre à ces questions, nous allons comparer plusieurs méthodes de génération d'embeddings :
- Embedding de contexte long (encodage jusqu'à 8 192 tokens dans un document) vs contexte court (c'est-à-dire troncature à 192 tokens).
- Sans découpage vs découpage naïf vs late chunking.
- Différentes tailles de chunks avec découpage naïf et late chunking.
tagLe Contexte Long Est-il Vraiment Utile ?
Avec la capacité d'encoder jusqu'à dix pages de texte dans un seul embedding, les modèles d'embedding de contexte long ouvrent des possibilités pour la représentation de texte à grande échelle. Mais est-ce vraiment utile ? Selon beaucoup de gens... non.




Sources : Citation de Nils Reimer dans le podcast How AI Is Built, tweet de brainlag, commentaire de egorfine sur Hacker News, commentaire de andy99 sur Hacker News
Nous allons aborder toutes ces préoccupations avec une investigation détaillée des capacités de contexte long, quand le contexte long est utile, et quand vous devriez (et ne devriez pas) l'utiliser. Mais d'abord, écoutons ces sceptiques et examinons certains des problèmes auxquels font face les modèles d'embedding de contexte long.
tagProblèmes avec les Embeddings de Contexte Long
Imaginons que nous construisons un système de recherche de documents pour des articles, comme ceux de notre blog Jina AI. Parfois, un seul article peut couvrir plusieurs sujets, comme le rapport sur notre visite à la conférence ICML 2024, qui contient :
- Une introduction, capturant des informations générales sur ICML (nombre de participants, lieu, portée, etc).
- La présentation de notre travail (jina-clip-v1).
- Des résumés d'autres articles de recherche intéressants présentés à ICML.
Si nous créons un seul embedding pour cet article, cet embedding représente un mélange de trois sujets disparates :
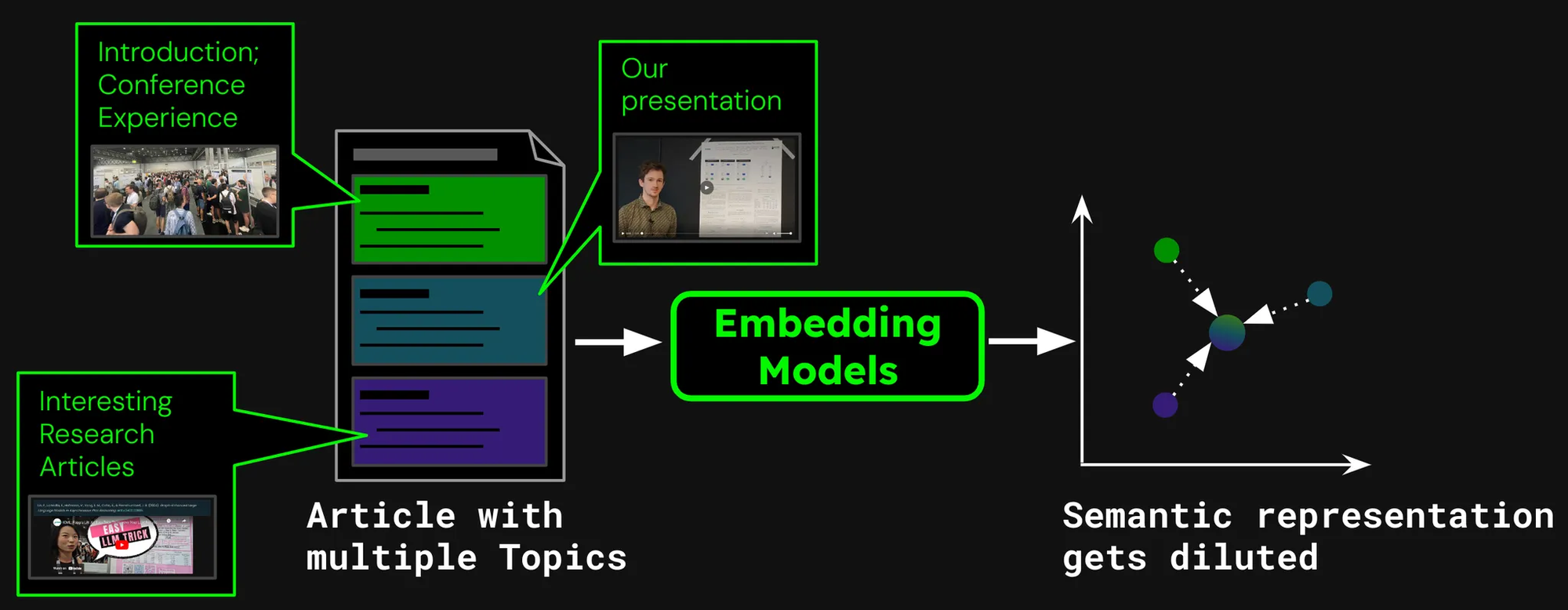
Cela conduit à plusieurs problèmes :
- Dilution de la Représentation : Bien que tous les sujets d'un texte donné puissent être liés, un seul peut être pertinent pour la requête de recherche d'un utilisateur. Cependant, un seul embedding (dans ce cas, celui de l'ensemble du billet de blog) n'est qu'un point dans l'espace vectoriel. À mesure que plus de texte est ajouté à l'entrée du modèle, l'embedding se déplace pour capturer le sujet global de l'article, le rendant moins efficace pour représenter le contenu couvert dans des paragraphes spécifiques.
- Capacité Limitée : Les modèles d'embedding produisent des vecteurs de taille fixe, indépendamment de la longueur d'entrée. Plus on ajoute de contenu à l'entrée, plus il devient difficile pour le modèle de représenter toutes ces informations dans le vecteur. C'est comme réduire une image à 16×16 pixels — Si vous réduisez une image de quelque chose de simple, comme une pomme, vous pouvez encore tirer du sens de l'image réduite. Réduire un plan des rues de Berlin ? Pas vraiment.
- Perte d'Information : Dans certains cas, même les modèles d'embedding de contexte long atteignent leurs limites ; De nombreux modèles prennent en charge l'encodage de texte jusqu'à 8 192 tokens. Les documents plus longs doivent être tronqués avant l'embedding, conduisant à une perte d'information. Si l'information pertinente pour l'utilisateur se trouve à la fin du document, elle ne sera pas du tout capturée par l'embedding.
- Vous Pourriez Avoir Besoin de Segmentation de Texte : Certaines applications nécessitent des embeddings pour des segments spécifiques du texte mais pas pour l'ensemble du document, comme l'identification du passage pertinent dans un texte.
tagContexte Long vs. Troncature
Pour voir si le contexte long est vraiment utile, examinons la performance de deux scénarios de recherche :
- Encodage de documents jusqu'à 8 192 tokens (environ 10 pages de texte).
- Troncature des documents à 192 tokens et encodage jusqu'à ce point.
Nous allons comparer les résultats en utilisantjina-embeddings-v3 avec la métrique de récupération nDCG@10. Nous avons testé les jeux de données suivants :
| Dataset | Description | Exemple de requête | Exemple de document | Longueur moyenne des documents (caractères) |
|---|---|---|---|---|
| NFCorpus | Un jeu de données de recherche médicale en texte intégral avec 3 244 requêtes et documents principalement issus de PubMed. | "Using Diet to Treat Asthma and Eczema" | "Statin Use and Breast Cancer Survival: A Nationwide Cohort Study from Finland Recent studies have suggested that [...]" | 326 753 |
| QMSum | Un jeu de données de résumé de réunions basé sur des requêtes nécessitant le résumé des segments pertinents de réunions. | "The professor was the one to raise the issue and suggested that a knowledge engineering trick [...]" | "Project Manager: Is that alright now ? {vocalsound} Okay . Sorry ? Okay , everybody all set to start the meeting ? [...]" | 37 445 |
| NarrativeQA | Jeu de données QA contenant de longues histoires et des questions correspondantes sur des contenus spécifiques. | "What kind of business Sophia owned in Paris?" | "The Project Gutenberg EBook of The Old Wives' Tale, by Arnold Bennett\n\nThis eBook is for the use of anyone anywhere [...]" | 53 336 |
| 2WikiMultihopQA | Un jeu de données QA multi-étapes avec jusqu'à 5 étapes de raisonnement, conçu avec des modèles pour éviter les raccourcis. | "What is the award that the composer of song The Seeker (The Who Song) earned?" | "Passage 1:\nMargaret, Countess of Brienne\nMarguerite d'Enghien (born 1365 - d. after 1394), was the ruling suo jure [...]" | 30 854 |
| SummScreenFD | Un jeu de données de résumés de scénarios avec des transcriptions et résumés de séries TV nécessitant l'intégration d'intrigues dispersées. | "Penny gets a new chair, which Sheldon enjoys until he finds out that she picked it up from [...]" | "[EXT. LAS VEGAS CITY (STOCK) - NIGHT]\n[EXT. ABERNATHY RESIDENCE - DRIVEWAY -- NIGHT]\n(The lamp post light over the [...]" | 1 613 |
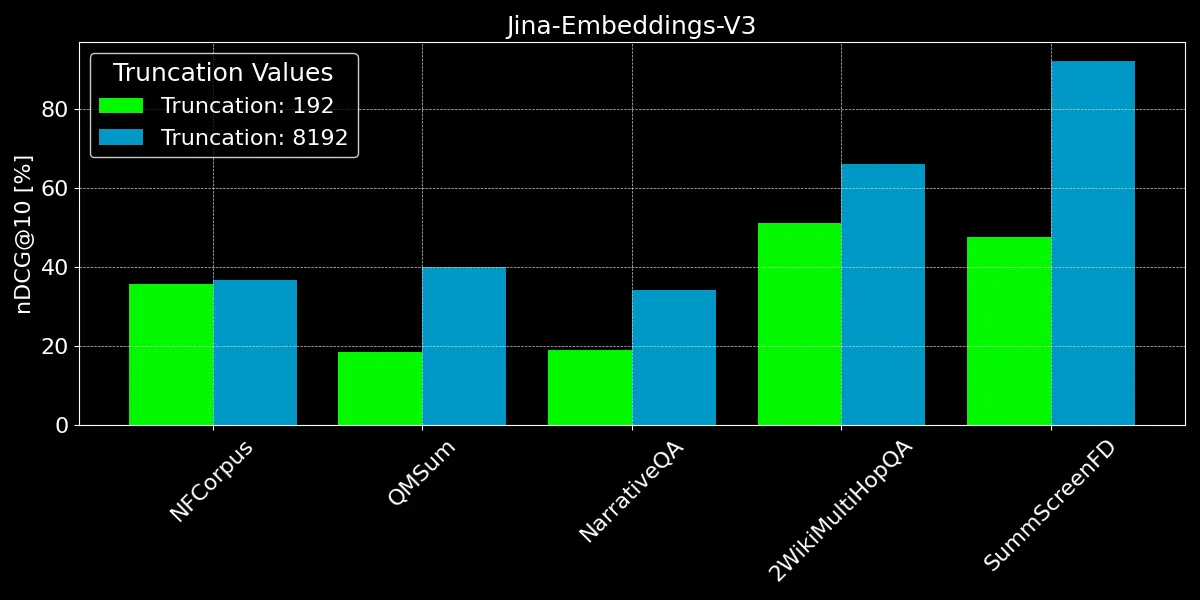
Comme nous pouvons le voir, l'encodage de plus de 192 tokens peut apporter des améliorations notables de performance :
Cependant, sur certains jeux de données, nous observons des améliorations plus importantes que sur d'autres :
- Pour NFCorpus, la troncature ne fait pratiquement aucune différence. Cela s'explique par le fait que les titres et les résumés se trouvent au début des documents, et ceux-ci sont très pertinents pour les termes de recherche typiques des utilisateurs. Que le texte soit tronqué ou non, les données les plus pertinentes restent dans la limite de tokens.
- QMSum et NarrativeQA sont considérés comme des tâches de "compréhension de lecture", où les utilisateurs recherchent généralement des faits spécifiques dans un texte. Ces faits sont souvent dispersés dans les détails du document et peuvent se trouver en dehors de la limite de 192 tokens. Par exemple, dans le document NarrativeQA Percival Keene, la réponse à la question "Qui est le tyran qui vole le déjeuner de Percival ?" se trouve bien au-delà de cette limite. De même, dans 2WikiMultiHopQA, les informations pertinentes sont dispersées dans l'ensemble des documents, obligeant les modèles à naviguer et à synthétiser les connaissances de plusieurs sections pour répondre efficacement aux requêtes.
- SummScreenFD est une tâche visant à identifier le scénario correspondant à un résumé donné. Comme le résumé englobe des informations réparties dans tout le scénario, l'encodage d'une plus grande partie du texte améliore la précision de l'association du résumé au bon scénario.
tagSegmentation du texte pour de meilleures performances de recherche
• Segmentation : Détection des marques de limite dans un texte d'entrée, par exemple, les phrases ou un nombre fixe de tokens.
• Chunking naïf : Division du texte en chunks basée sur les marques de segmentation, avant de l'encoder.
• Late chunking : Encodage du document d'abord puis segmentation (préservant le contexte entre les chunks).
Au lieu d'intégrer un document entier dans un seul vecteur, nous pouvons utiliser différentes méthodes pour d'abord segmenter le document en attribuant des marques de limite :

Quelques méthodes courantes incluent :
- Segmentation par taille fixe : Le document est divisé en segments d'un nombre fixe de tokens, déterminé par le tokenizer du modèle d'embedding. Cela garantit que la tokenisation des segments correspond à la tokenisation du document entier (segmenter par un nombre spécifique de caractères pourrait conduire à une tokenisation différente).
- Segmentation par phrase : Le document est segmenté en phrases, et chaque chunk se compose de n phrases.
- Segmentation par sémantique : Chaque segment correspond à plusieurs phrases et un modèle d'embedding détermine la similarité des phrases consécutives. Les phrases ayant des similarités d'embedding élevées sont assignées au même chunk.
Par souci de simplicité, nous utilisons la segmentation à taille fixe dans cet article.
tagRécupération de documents utilisant le chunking naïf
Une fois que nous avons effectué la segmentation à taille fixe, nous pouvons découper naïvement le document selon ces segments :
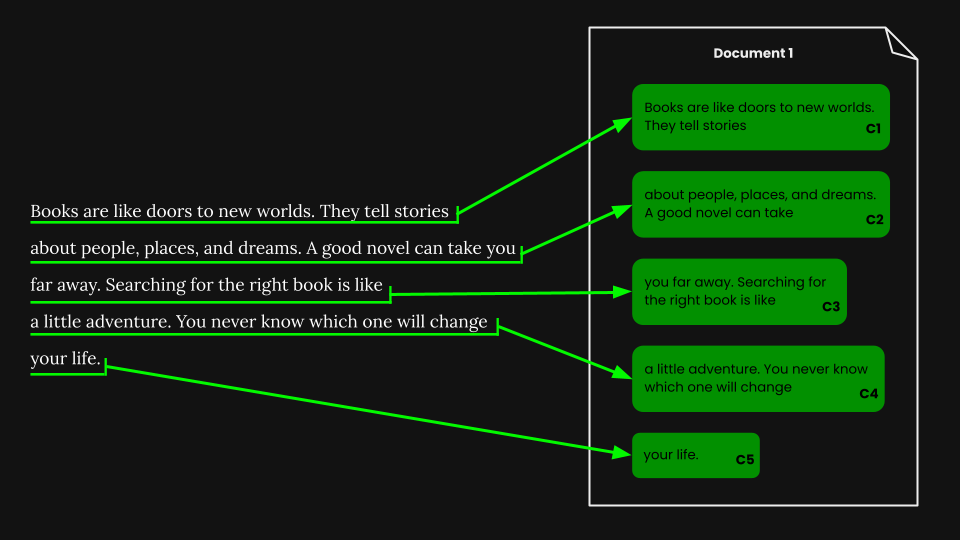
En utilisant jina-embeddings-v3, nous encodons chaque chunk en un embedding qui capture précisément sa sémantique, puis stockons ces embeddings dans une base de données vectorielle.
À l'exécution, le modèle encode la requête d'un utilisateur en un vecteur de requête. Nous comparons celui-ci à notre base de données vectorielle d'embeddings de chunks pour trouver le chunk ayant la plus haute similarité cosinus, puis retournons le document correspondant à l'utilisateur :
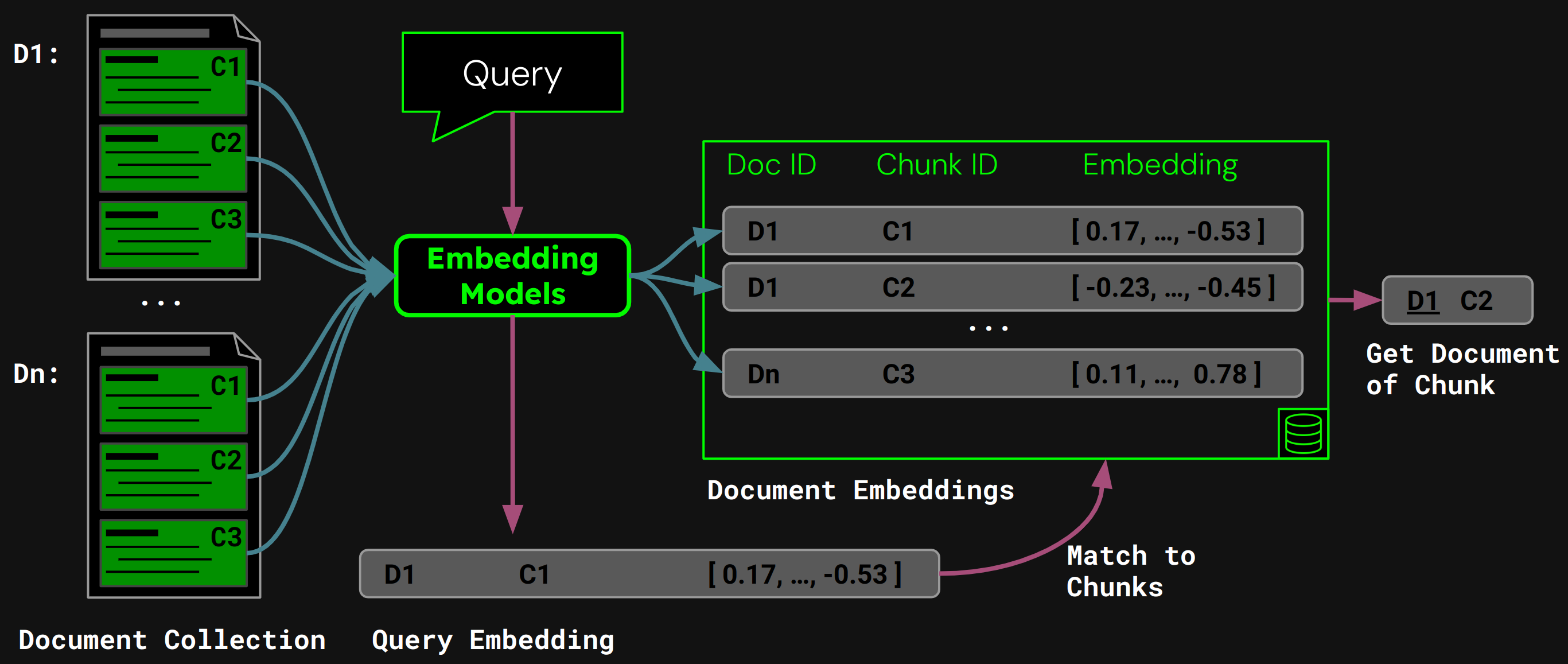
tagProblèmes avec le découpage naïf

Bien que le découpage naïf réponde à certaines limitations des modèles d'embedding à contexte long, il présente aussi des inconvénients :
- Perte de la vue d'ensemble : En ce qui concerne la recherche de documents, plusieurs embeddings de petits fragments peuvent ne pas saisir le sujet global du document. C'est comme ne pas voir la forêt à cause des arbres.
- Problème de contexte manquant : Les fragments ne peuvent pas être interprétés avec précision car les informations contextuelles sont manquantes, comme illustré dans la Figure 6.
- Efficacité : Plus de fragments nécessitent plus de stockage et augmentent le temps de recherche.
tagLe découpage tardif résout le problème de contexte
Le découpage tardif fonctionne en deux étapes principales :
- D'abord, il utilise les capacités de contexte long du modèle pour encoder l'ensemble du document en embeddings de tokens. Cela préserve le contexte complet du document.
- Ensuite, il crée des embeddings de fragments en appliquant un pooling moyen à des séquences spécifiques d'embeddings de tokens, correspondant aux indices de délimitation identifiés lors de la segmentation.
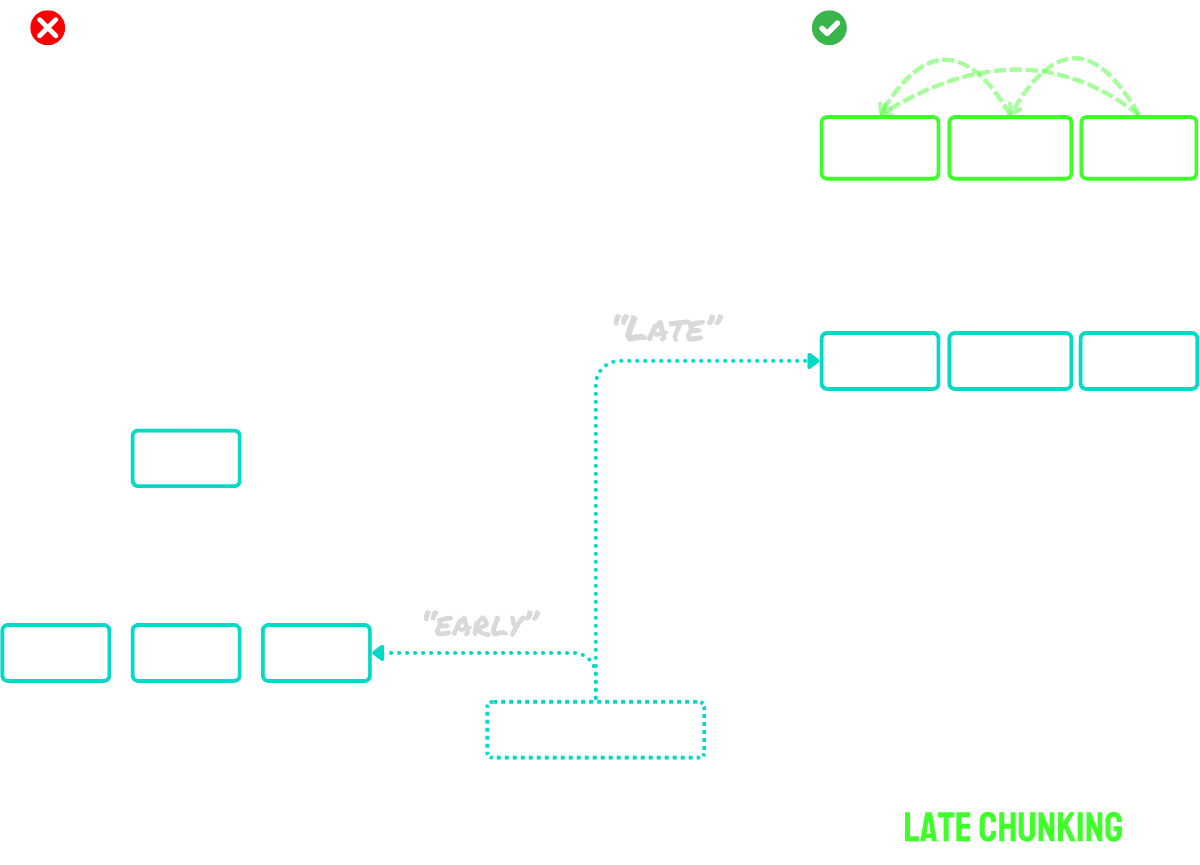
L'avantage principal de cette approche est que les embeddings de tokens sont contextualisés - ce qui signifie qu'ils capturent naturellement les références et les relations avec d'autres parties du document. Puisque le processus d'embedding se produit avant le découpage, chaque fragment conserve une conscience du contexte plus large du document, résolvant ainsi le problème de contexte manquant qui affecte les approches de découpage naïf.
Pour les documents qui dépassent la taille d'entrée maximale du modèle, nous pouvons utiliser le « découpage tardif long » :
- D'abord, nous divisons le document en « macro-fragments » qui se chevauchent. Chaque macro-fragment est dimensionné pour s'adapter à la longueur maximale de contexte du modèle (par exemple, 8 192 tokens).
- Le modèle traite ces macro-fragments pour créer des embeddings de tokens.
- Une fois que nous avons les embeddings de tokens, nous procédons au découpage tardif standard - en appliquant le pooling moyen pour créer les embeddings de fragments finaux.
Cette approche nous permet de gérer des documents de n'importe quelle longueur tout en préservant les avantages du découpage tardif. Considérez-la comme un processus en deux étapes : d'abord rendre le document digestible pour le modèle, puis appliquer la procédure de découpage tardif régulière.
En résumé :
- Découpage naïf : Segmenter le document en petits fragments, puis encoder chaque fragment séparément.
- Découpage tardif : Encoder l'ensemble du document en une fois pour créer des embeddings de tokens, puis créer des embeddings de fragments en regroupant les embeddings de tokens selon les limites des segments.
- Découpage tardif long : Diviser les grands documents en macro-fragments qui se chevauchent et qui s'adaptent à la fenêtre de contexte du modèle, les encoder pour obtenir des embeddings de tokens, puis appliquer le découpage tardif normalement.
Pour une description plus détaillée de l'idée, consultez notre article ou les articles de blog mentionnés ci-dessus.
tagDécouper ou ne pas découper ?
Nous avons déjà vu que l'embedding à contexte long surpasse généralement les embeddings de textes plus courts, et donné un aperçu des stratégies de découpage naïf et tardif. La question est maintenant : Le découpage est-il meilleur que l'embedding à contexte long ?
Pour effectuer une comparaison équitable, nous tronquons les valeurs de texte à la longueur maximale de séquence du modèle (8 192 tokens) avant de commencer à les segmenter. Nous utilisons une segmentation de taille fixe avec 64 tokens par segment (pour la segmentation naïve et le découpage tardif). Comparons trois scénarios :
- Pas de segmentation : Nous encodons chaque texte en un seul embedding. Cela conduit aux mêmes scores que l'expérience précédente (voir Figure 2), mais nous les incluons ici pour mieux les comparer.
- Découpage naïf : Nous segmentons les textes, puis appliquons un découpage naïf basé sur les indices de délimitation.
- Découpage tardif : Nous segmentons les textes, puis utilisons le découpage tardif pour déterminer les embeddings.
Pour le découpage tardif et la segmentation naïve, nous utilisons la recherche de fragments pour déterminer le document pertinent (comme montré dans la Figure 5, plus haut dans cet article).
Les résultats ne montrent pas de gagnant clair :
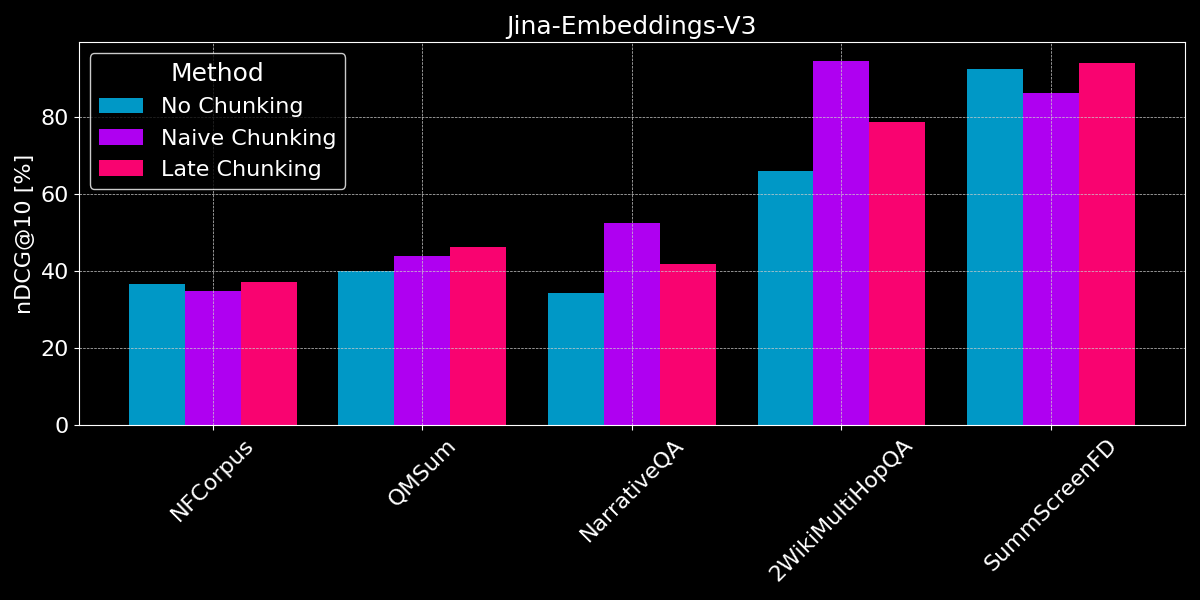
- Pour la recherche de faits, le découpage naïf est plus performant : Pour les jeux de données QMSum, NarrativeQA et 2WikiMultiHopQA, le modèle doit identifier les passages pertinents dans le document. Ici, le découpage naïf est clairement meilleur que l'encodage de tout en un seul embedding, car probablement seuls quelques fragments contiennent des informations pertinentes, et ces fragments les capturent beaucoup mieux qu'un seul embedding de l'ensemble du document.
- Le chunking tardif fonctionne mieux avec des documents cohérents et un contexte pertinent : Pour les documents couvrant un sujet cohérent où les utilisateurs recherchent des thèmes généraux plutôt que des faits spécifiques (comme dans NFCorpus), le chunking tardif surpasse légèrement l'absence de chunking, car il équilibre le contexte global du document avec les détails locaux. Cependant, bien que le chunking tardif soit généralement plus performant que le chunking naïf en préservant le contexte, cet avantage peut devenir un inconvénient lors de la recherche de faits isolés dans des documents contenant principalement des informations non pertinentes - comme le montrent les régressions de performance pour NarrativeQA et 2WikiMultiHopQA, où le contexte ajouté devient plus distrayant qu'utile.
tagLa Taille des Chunks Fait-elle une Différence ?
L'efficacité des méthodes de chunking dépend vraiment du dataset, soulignant combien la structure du contenu joue un rôle crucial :
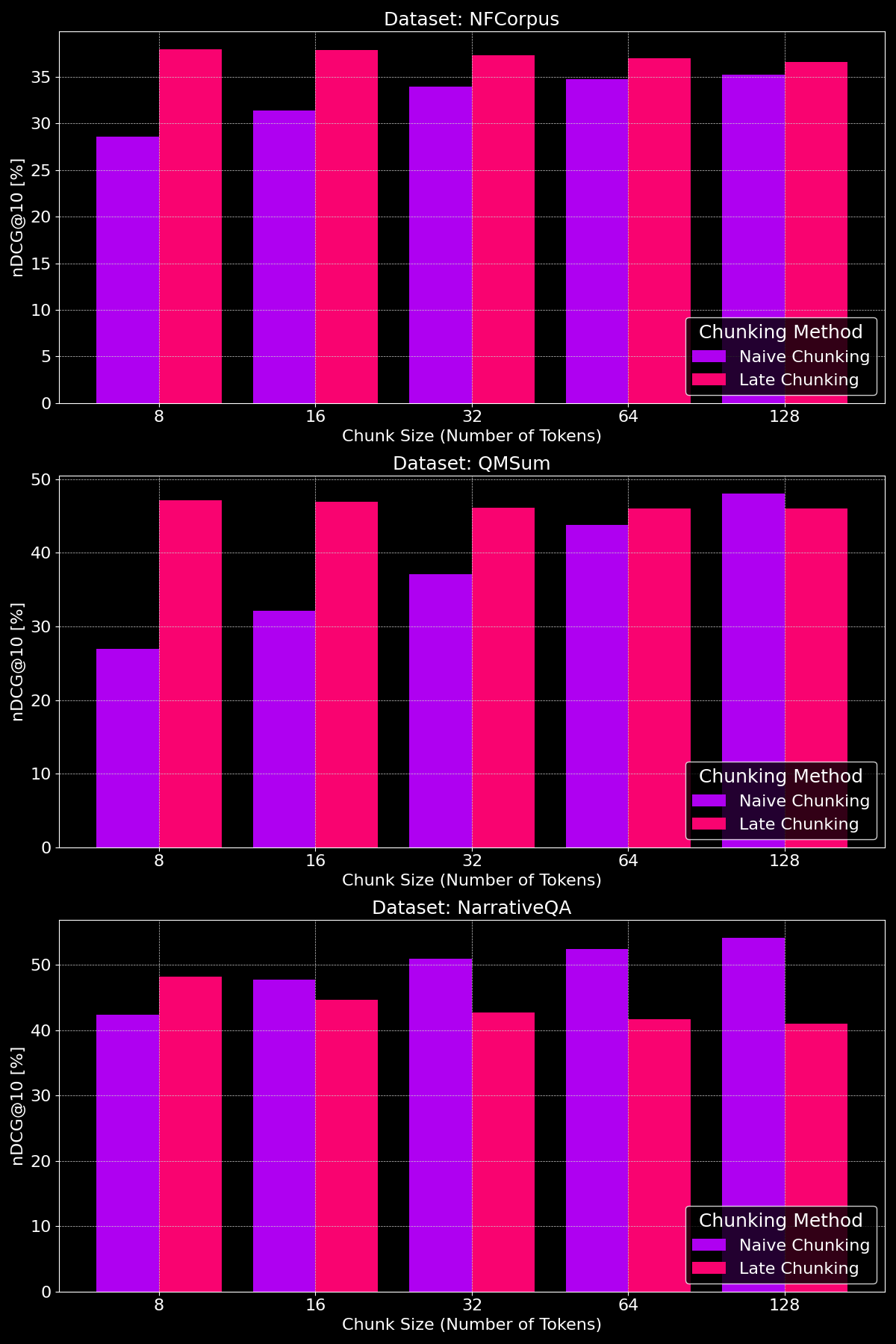
Comme nous pouvons le voir, le chunking tardif surpasse généralement le chunking naïf avec des tailles de chunks plus petites, car les chunks naïfs plus petits sont trop réduits pour contenir beaucoup de contexte, tandis que les chunks tardifs plus petits conservent le contexte du document entier, les rendant plus significatifs sémantiquement. L'exception à cela est le dataset NarrativeQA où il y a simplement tellement de contexte non pertinent que le chunking tardif est moins performant. Avec des tailles de chunks plus grandes, le chunking naïf montre une amélioration marquée (dépassant occasionnellement le chunking tardif) grâce au contexte accru, tandis que la performance du chunking tardif diminue progressivement.
tagConclusions : Quand Utiliser Quoi ?
Dans cet article, nous avons examiné différents types de tâches de recherche de documents pour mieux comprendre quand utiliser la segmentation et quand le chunking tardif aide. Alors, qu'avons-nous appris ?
tagQuand Devrais-je Utiliser l'Embedding à Long Contexte ?
En général, inclure autant de texte de vos documents que possible dans l'entrée de votre modèle d'embedding ne nuit pas à la précision de la recherche. Cependant, les modèles d'embedding à long contexte se concentrent souvent sur le début des documents, car ils contiennent du contenu comme les titres et l'introduction qui sont plus importants pour juger de la pertinence, mais les modèles peuvent manquer du contenu au milieu du document.
tagQuand Devrais-je Utiliser le Chunking Naïf ?
Lorsque les documents couvrent plusieurs aspects, ou que les requêtes des utilisateurs ciblent des informations spécifiques dans un document, le chunking améliore généralement les performances de recherche.
Finalement, les décisions de segmentation dépendent de facteurs comme la nécessité d'afficher du texte partiel aux utilisateurs (par exemple, comme Google présente les passages pertinents dans les aperçus des résultats de recherche), ce qui rend la segmentation essentielle, ou des contraintes de calcul et de mémoire, où la segmentation peut être moins favorable en raison de la surcharge de recherche accrue et de l'utilisation des ressources.
tagQuand Devrais-je Utiliser le Chunking Tardif ?
En encodant le document complet avant de créer des chunks, le chunking tardif résout le problème des segments de texte perdant leur signification en raison d'un contexte manquant. Cela fonctionne particulièrement bien avec des documents cohérents, où chaque partie est liée à l'ensemble. Nos expériences montrent que le chunking tardif est particulièrement efficace lors de la division du texte en plus petits chunks, comme démontré dans notre article. Cependant, il y a une mise en garde : si des parties du document n'ont pas de rapport entre elles, inclure ce contexte plus large peut en fait dégrader les performances de recherche, car cela ajoute du bruit aux embeddings.
tagConclusion
Le choix entre l'embedding à long contexte, le chunking naïf et le chunking tardif dépend des exigences spécifiques de votre tâche de recherche. Les embeddings à long contexte sont précieux pour les documents cohérents avec des requêtes générales, tandis que le chunking excelle dans les cas où les utilisateurs recherchent des faits ou des informations spécifiques dans un document. Le chunking tardif améliore davantage la recherche en conservant la cohérence contextuelle dans des segments plus petits. En fin de compte, la compréhension de vos données et de vos objectifs de recherche guidera l'approche optimale, équilibrant précision, efficacité et pertinence contextuelle.
Si vous explorez ces stratégies, envisagez d'essayer jina-embeddings-v3—ses capacités avancées de long contexte, son chunking tardif et sa flexibilité en font un excellent choix pour divers scénarios de recherche.






