


Récemment, Christoph Schuhmann, fondateur de LAION AI a partagé une observation intéressante concernant les modèles d'embedding de texte :
Lorsque les mots d'une phrase sont mélangés aléatoirement, la similarité cosinus entre leurs embeddings de texte reste étonnamment élevée par rapport à la phrase originale.
Par exemple, prenons deux phrases : Berlin is the capital of Germany et the Germany Berlin is capital of. Même si la deuxième phrase n'a aucun sens, les modèles d'embedding de texte ne peuvent pas vraiment les distinguer. En utilisant jina-embeddings-v3, ces deux phrases ont un score de similarité cosinus de 0,9295.
L'ordre des mots n'est pas le seul aspect pour lequel les embeddings semblent peu sensibles. Les transformations grammaticales peuvent modifier radicalement le sens d'une phrase mais avoir peu d'impact sur la distance d'embedding. Par exemple, She ate dinner before watching the movie et She watched the movie before eating dinner ont une similarité cosinus de 0,9833, bien qu'elles aient un ordre d'actions opposé.
La négation est également notoirement difficile à encoder de manière cohérente sans entraînement spécial — This is a useful model et This is not a useful model apparaissent pratiquement identiques dans l'espace d'embedding. Souvent, le remplacement de mots dans un texte par d'autres de la même classe, comme changer "today" par "yesterday", ou modifier le temps d'un verbe, ne modifie pas autant les embeddings qu'on pourrait le penser.
Cela a des implications sérieuses. Prenons deux requêtes de recherche : Flight from Berlin to Amsterdam et Flight from Amsterdam to Berlin. Elles ont des embeddings presque identiques, jina-embeddings-v3 leur attribuant une similarité cosinus de 0,9884. Pour une application réelle comme la recherche de voyages ou la logistique, cette lacune est fatale.
Dans cet article, nous examinons les défis auxquels font face les modèles d'embedding, en analysant leurs difficultés persistantes avec l'ordre des mots et le choix des mots. Nous analysons les principaux modes d'échec à travers les catégories linguistiques — y compris les contextes directionnels, temporels, causaux, comparatifs et négatifs — tout en explorant des stratégies pour améliorer les performances des modèles.
tagPourquoi les phrases mélangées ont-elles des scores cosinus étonnamment proches ?
Au début, nous pensions que cela pouvait être dû à la façon dont le modèle combine les sens des mots - il crée un embedding pour chaque mot (6-7 mots dans chacune de nos phrases d'exemple ci-dessus) puis fait la moyenne de ces embeddings avec le mean pooling. Cela signifie que très peu d'informations sur l'ordre des mots sont disponibles dans l'embedding final. Une moyenne est la même quel que soit l'ordre des valeurs.
Cependant, même les modèles qui utilisent le CLS pooling (qui examine un premier mot spécial pour comprendre la phrase entière et devrait être plus sensible à l'ordre des mots) ont le même problème. Par exemple, bge-1.5-base-en donne toujours un score de similarité cosinus de 0,9304 pour les phrases Berlin is the capital of Germany et the Germany Berlin is capital of.
Cela met en évidence une limitation dans la façon dont les modèles d'embedding sont entraînés. Bien que les modèles de langage apprennent initialement la structure des phrases pendant le pré-entraînement, ils semblent perdre une partie de cette compréhension pendant l'entraînement contrastif — le processus que nous utilisons pour créer des modèles d'embedding.
tagComment la longueur du texte et l'ordre des mots influencent-ils la similarité des embeddings ?
Pourquoi les modèles ont-ils des difficultés avec l'ordre des mots en premier lieu ? La première chose qui vient à l'esprit est la longueur (en tokens) du texte. Lorsque le texte est envoyé à la fonction d'encodage, le modèle génère d'abord une liste d'embeddings de tokens (c'est-à-dire que chaque mot tokenisé a un vecteur dédié représentant son sens), puis en fait la moyenne.
Pour voir comment la longueur du texte et l'ordre des mots influencent la similarité des embeddings, nous avons généré un jeu de données de 180 phrases synthétiques de longueurs variables, comme 3, 5, 10, 15, 20 et 30 tokens. Nous avons également mélangé aléatoirement les tokens pour former une variation de chaque phrase :

Voici quelques exemples :
| Longueur (tokens) | Phrase originale | Phrase mélangée |
|---|---|---|
| 3 | The cat sleeps | cat The sleeps |
| 5 | He drives his car carefully | drives car his carefully He |
| 15 | The talented musicians performed beautiful classical music at the grand concert hall yesterday | in talented now grand classical yesterday The performed musicians at hall concert the music |
| 30 | The passionate group of educational experts collaboratively designed and implemented innovative teaching methodologies to improve learning outcomes in diverse classroom environments worldwide | group teaching through implemented collaboratively outcomes of methodologies across worldwide diverse with passionate and in experts educational classroom for environments now by learning to at improve from innovative The designed |
Nous allons encoder le jeu de données en utilisant notre propre modèle jina-embeddings-v3 et le modèle open-source bge-base-en-v1.5, puis calculer la similarité cosinus entre la phrase originale et la phrase mélangée :
| Longueur (tokens) | Similarité cosinus moyenne | Écart-type de la similarité cosinus |
|---|---|---|
| 3 | 0,947 | 0,053 |
| 5 | 0,909 | 0,052 |
| 10 | 0,924 | 0,031 |
| 15 | 0,918 | 0,019 |
| 20 | 0,899 | 0,021 |
| 30 | 0,874 | 0,025 |
Nous pouvons maintenant générer un diagramme en boîte, qui rend la tendance de la similarité cosinus plus claire :
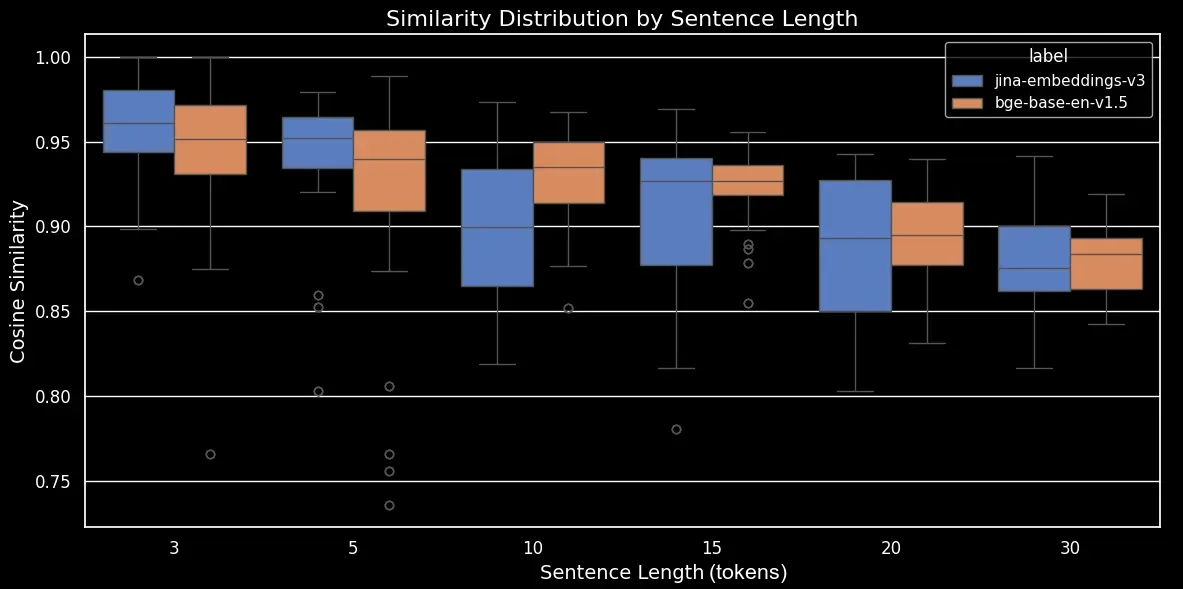
bge-base-en-1.5 (non affiné)Comme nous pouvons le voir, il existe une relation linéaire claire dans la similarité cosinus moyenne des embeddings. Plus le texte est long, plus le score moyen de similarité cosinus entre les phrases originales et mélangées aléatoirement est faible. Cela se produit probablement en raison du "déplacement des mots", c'est-à-dire la distance à laquelle les mots se sont déplacés de leurs positions d'origine après un mélange aléatoire. Dans un texte plus court, il y a simplement moins de "positions" possibles pour qu'un token soit mélangé, il ne peut donc pas se déplacer aussi loin, tandis qu'un texte plus long a un plus grand nombre de permutations potentielles et les mots peuvent se déplacer sur une plus grande distance.
Comme le montre la figure ci-dessous (Similarité cosinus vs Déplacement moyen des mots), plus le texte est long, plus le déplacement des mots est important :
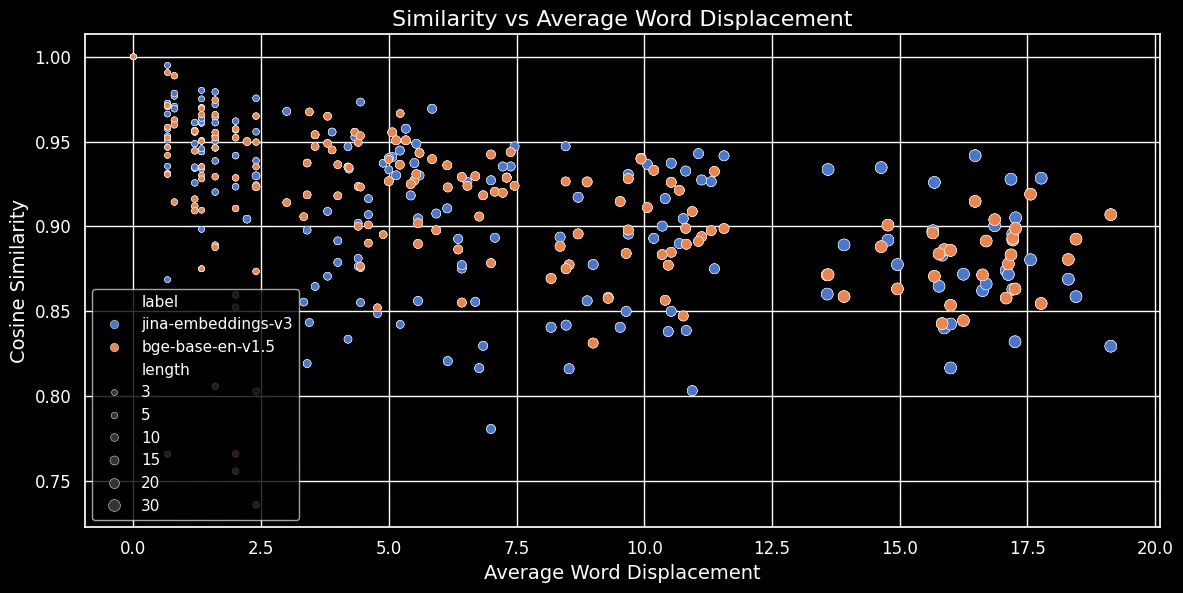
Les embeddings de tokens dépendent du contexte local, c'est-à-dire des mots les plus proches d'eux. Dans un texte court, réorganiser les mots ne peut pas beaucoup modifier ce contexte. Cependant, pour un texte plus long, un mot peut être déplacé très loin de son contexte d'origine, ce qui peut considérablement modifier son embedding de token. Par conséquent, mélanger les mots dans un texte plus long produit un embedding plus distant que pour un texte plus court. La figure ci-dessus montre que pour jina-embeddings-v3, utilisant le mean pooling, et bge-base-en-v1.5, utilisant le CLS pooling, la même relation s'applique : mélanger des textes plus longs et déplacer les mots plus loin entraîne des scores de similarité plus faibles.
tagLes modèles plus grands résolvent-ils le problème ?
Habituellement, face à ce type de problème, une tactique courante consiste à simplement utiliser un modèle plus grand. Mais un modèle d'embedding de texte plus grand peut-il vraiment capturer plus efficacement l'information sur l'ordre des mots ? Selon la loi d'échelle des modèles d'embedding de texte (référencée dans notre article sur la sortie de jina-embeddings-v3), les modèles plus grands offrent généralement de meilleures performances :
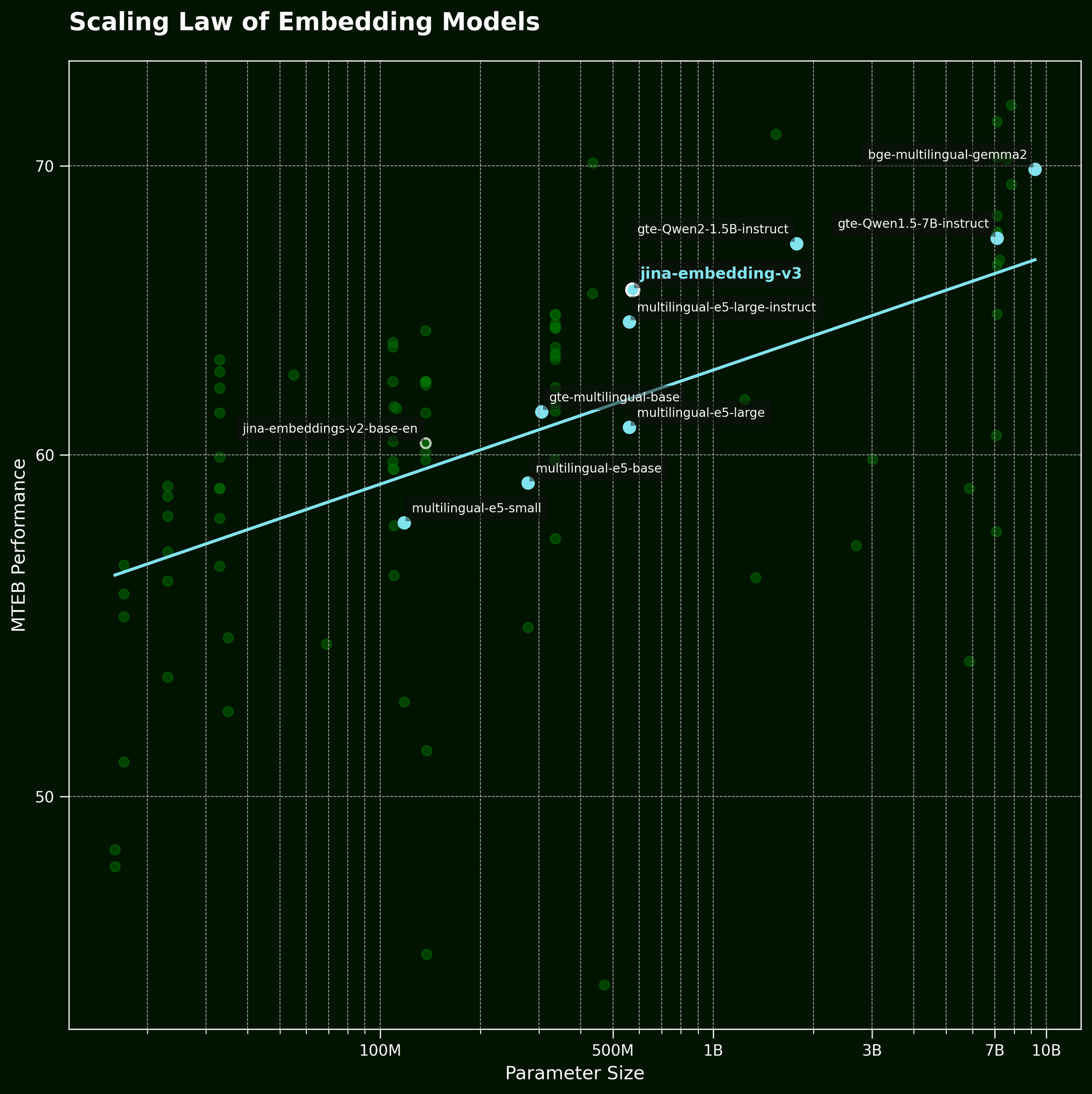
Mais un modèle plus grand peut-il capturer plus efficacement l'information sur l'ordre des mots ? Nous avons testé trois variations du modèle BGE : bge-small-en-v1.5, bge-base-en-v1.5, et bge-large-en-v1.5, avec respectivement 33 millions, 110 millions et 335 millions de paramètres.
Nous utiliserons les mêmes 180 phrases qu'auparavant, mais sans tenir compte de l'information sur la longueur. Nous encoderons à la fois les phrases originales et leurs mélanges aléatoires en utilisant les trois variantes du modèle et tracerons la similarité cosinus moyenne :
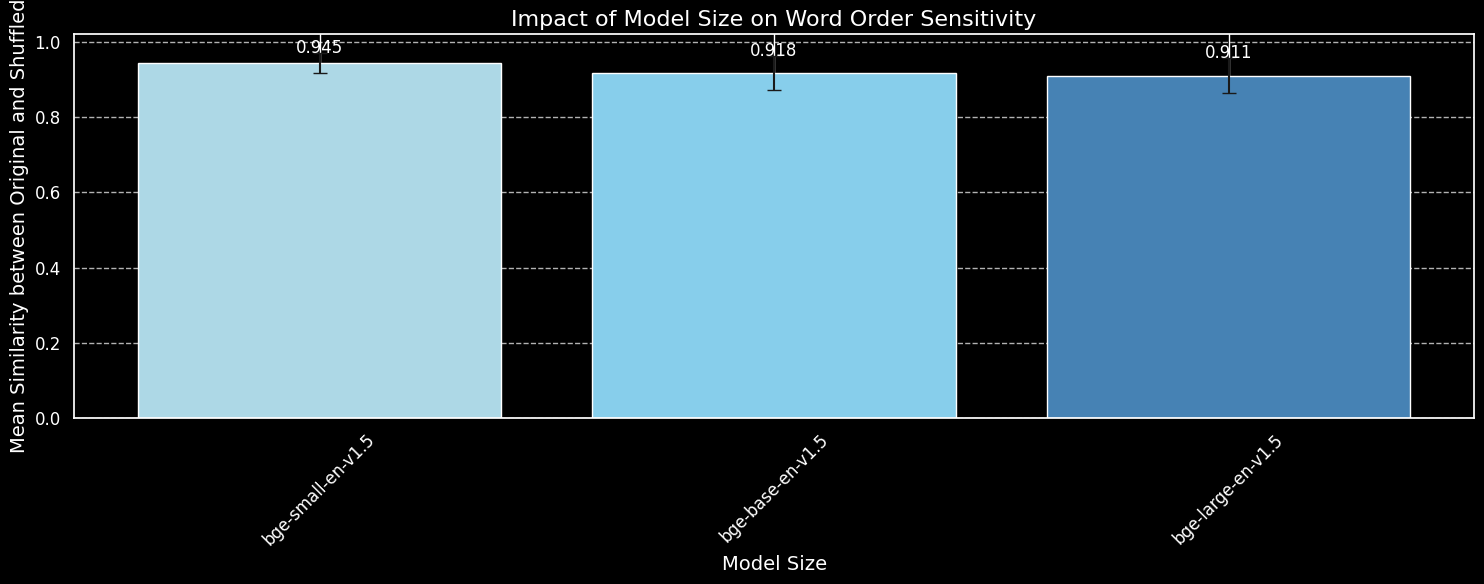
bge-small-en-v1.5, bge-base-en-v1.5, et bge-large-en-v1.5.Bien que nous puissions constater que les modèles plus grands sont plus sensibles aux variations de l'ordre des mots, la différence est faible. Même le bge-large-en-v1.5, beaucoup plus grand, n'est qu'un peu meilleur pour distinguer les phrases mélangées des phrases non mélangées. D'autres facteurs entrent en jeu pour déterminer la sensibilité d'un modèle d'embedding aux réorganisations de mots, en particulier les différences dans le régime d'entraînement. De plus, la similarité cosinus est un outil très limité pour mesurer la capacité d'un modèle à faire des distinctions. Cependant, nous pouvons voir que la taille du modèle n'est pas un facteur majeur. Nous ne pouvons pas simplement agrandir notre modèle et résoudre ce problème.
tagL'ordre des mots et le choix des mots dans le monde réel
jina-embeddings-v2 (pas notre modèle le plus récent, jina-embeddings-v3) car v2 est beaucoup plus petit et donc plus rapide pour expérimenter sur nos GPU locaux, avec 137m paramètres contre 580m pour v3.Comme nous l'avons mentionné dans l'introduction, l'ordre des mots n'est pas le seul défi pour les modèles d'embedding. Un défi plus réaliste dans le monde réel concerne le choix des mots. Il existe de nombreuses façons de modifier les mots dans une phrase — des façons qui ne se reflètent pas bien dans les embeddings. Nous pouvons prendre "Elle a volé de Paris à Tokyo" et le modifier pour obtenir "Elle a conduit de Tokyo à Paris", et les embeddings restent similaires. Nous avons cartographié cela à travers plusieurs catégories de modification :
| Catégorie | Exemple - Gauche | Exemple - Droite | Similarité cosinus (jina) |
|---|---|---|---|
| Directionnel | Elle a volé de Paris à Tokyo | Elle a conduit de Tokyo à Paris | 0.9439 |
| Temporel | Elle a dîné avant de regarder le film | Elle a regardé le film avant de dîner | 0.9833 |
| Causal | La température montante a fait fondre la neige | La neige fondante a refroidi la température | 0.8998 |
| Comparatif | Le café a meilleur goût que le thé | Le thé a meilleur goût que le café | 0.9457 |
| Négation | Il est debout près de la table | Il est debout loin de la table | 0.9116 |
Le tableau ci-dessus montre une liste de "cas d'échec" où un modèle d'embedding de texte échoue à capturer de subtiles altérations de mots. Cela correspond à nos attentes : les modèles d'embedding de texte n'ont pas la capacité de raisonner. Par exemple, le modèle ne comprend pas la relation entre "de" et "vers". Les modèles d'embedding de texte effectuent une correspondance sémantique, la sémantique étant généralement capturée au niveau des tokens puis compressée en un seul vecteur dense après pooling. En revanche, les LLM (modèles autorégressifs) entraînés sur des jeux de données plus importants, à l'échelle du billion de tokens, commencent à démontrer des capacités émergentes de raisonnement.
Cela nous a fait nous demander : pouvons-nous affiner le modèle d'embedding avec un apprentissage contrastif utilisant des triplets pour rapprocher la requête et le positif, tout en éloignant la requête du négatif ?

Par exemple, "Vol d'Amsterdam à Berlin" pourrait être considéré comme la paire négative de "Vol de Berlin à Amsterdam". En fait, dans le rapport technique de jina-embeddings-v1 (Michael Guenther, et al.), nous avons brièvement abordé ce problème à petite échelle : nous avons affiné le modèle jina-embeddings-v1 sur un jeu de données de négation de 10 000 exemples générés par des modèles de langage.

Les résultats, rapportés dans le lien du rapport ci-dessus, étaient prometteurs :
Nous observons que pour toutes les tailles de modèles, l'affinement sur les données en triplets (qui inclut notre jeu de données d'entraînement sur la négation) améliore considérablement les performances, en particulier sur la tâche HardNegation.
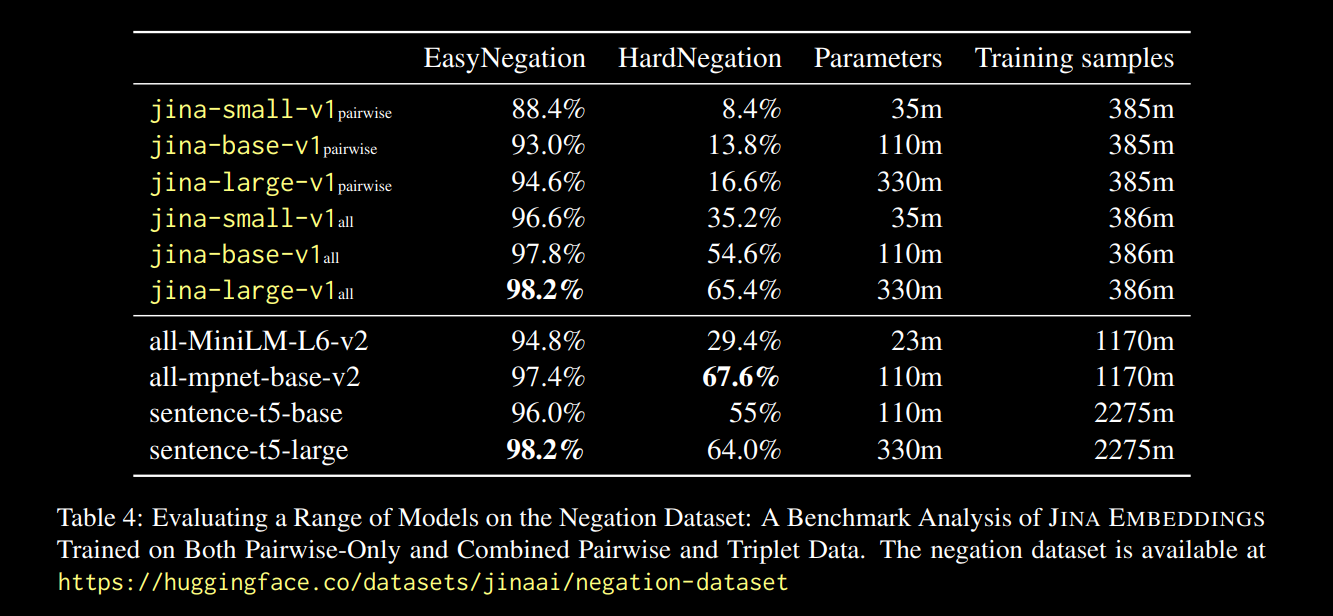
jina-embeddings avec un entraînement par paires et un entraînement combiné triplets/paires.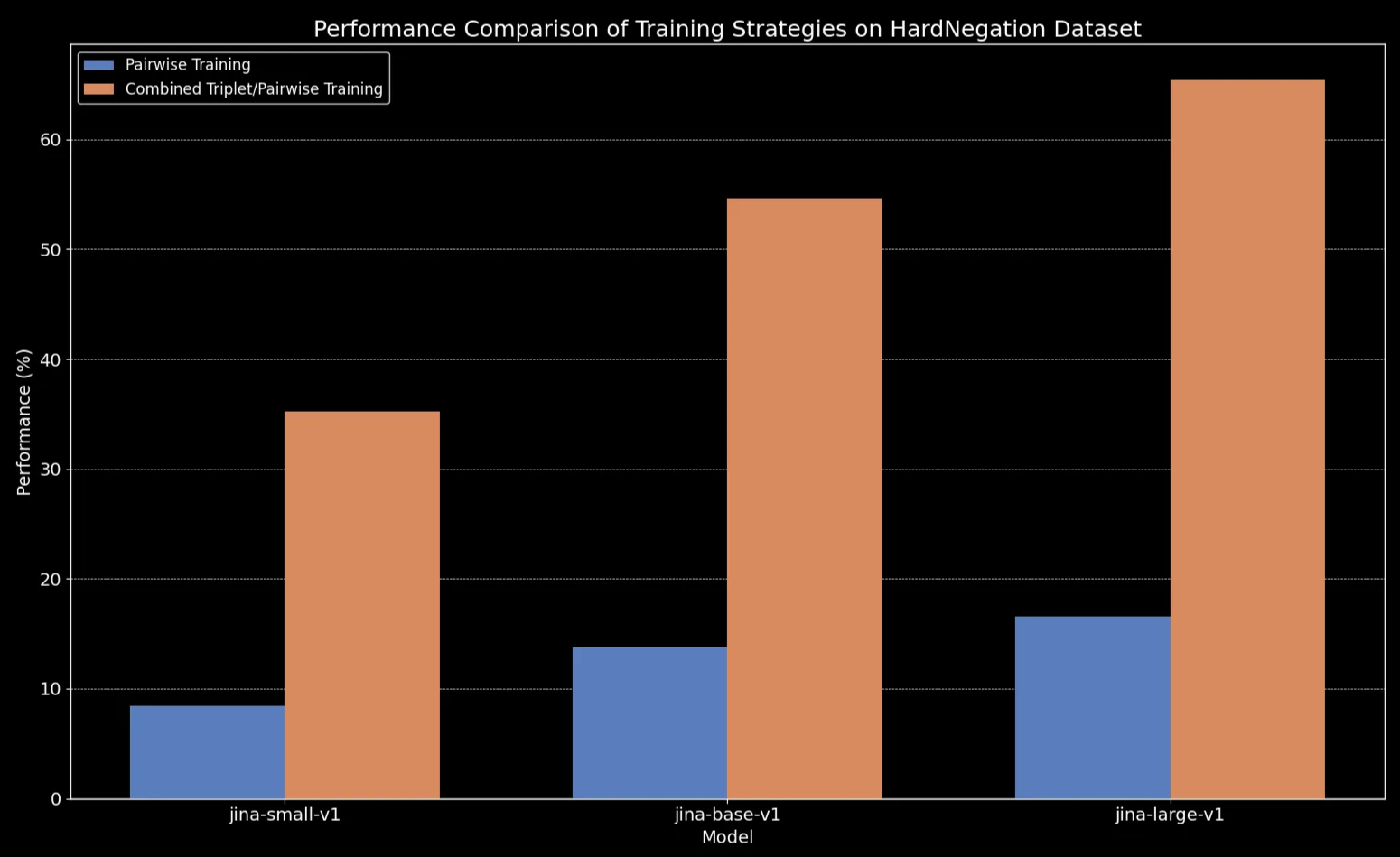
jina-embeddings.tagAffinage des modèles d'embedding de texte avec des jeux de données curés
Dans les sections précédentes, nous avons exploré plusieurs observations clés concernant les embeddings de texte :
- Les textes plus courts sont plus sujets aux erreurs de capture de l'ordre des mots.
- Augmenter la taille du modèle d'embedding de texte n'améliore pas nécessairement la compréhension de l'ordre des mots.
- L'apprentissage contrastif pourrait offrir une solution potentielle à ces problèmes.
Dans cette optique, nous avons affiné jina-embeddings-v2-base-en et bge-base-en-1.5 sur nos jeux de données de négation et d'ordre des mots (environ 11 000 échantillons d'entraînement au total) :


Pour aider à évaluer l'affinage, nous avons généré un jeu de données de 1 000 triplets composés d'une query, d'un cas positive (pos), et d'un cas negative (neg) :

Voici un exemple de ligne :
| Anchor | The river flows from the mountains to the sea |
| Positive | Water travels from mountain peaks to ocean |
| Negative | The river flows from the sea to the mountains |
Ces triplets sont conçus pour couvrir divers cas d'échec, y compris les changements de sens directionnels, temporels et causaux dus aux changements d'ordre des mots.
Nous pouvons maintenant évaluer les modèles sur trois ensembles d'évaluation différents :
- L'ensemble de 180 phrases synthétiques (du début de cet article), mélangées aléatoirement.
- Cinq exemples vérifiés manuellement (du tableau directionnel/causal/etc. ci-dessus).
- 94 triplets curés de notre jeu de données de triplets que nous venons de générer.
Voici la différence pour les phrases mélangées avant et après l'affinage :
| Longueur de phrase (tokens) | Similarité cosinus moyenne (jina) |
Similarité cosinus moyenne (jina-ft) |
Similarité cosinus moyenne (bge) |
Similarité cosinus moyenne (bge-ft) |
|---|---|---|---|---|
| 3 | 0.970 | 0.927 | 0.929 | 0.899 |
| 5 | 0.958 | 0.910 | 0.940 | 0.916 |
| 10 | 0.953 | 0.890 | 0.934 | 0.910 |
| 15 | 0.930 | 0.830 | 0.912 | 0.875 |
| 20 | 0.916 | 0.815 | 0.901 | 0.879 |
| 30 | 0.927 | 0.819 | 0.877 | 0.852 |
Le résultat semble clair : malgré un processus de fine-tuning qui ne prend que cinq minutes, nous observons une amélioration spectaculaire des performances sur le jeu de données de phrases mélangées aléatoirement :
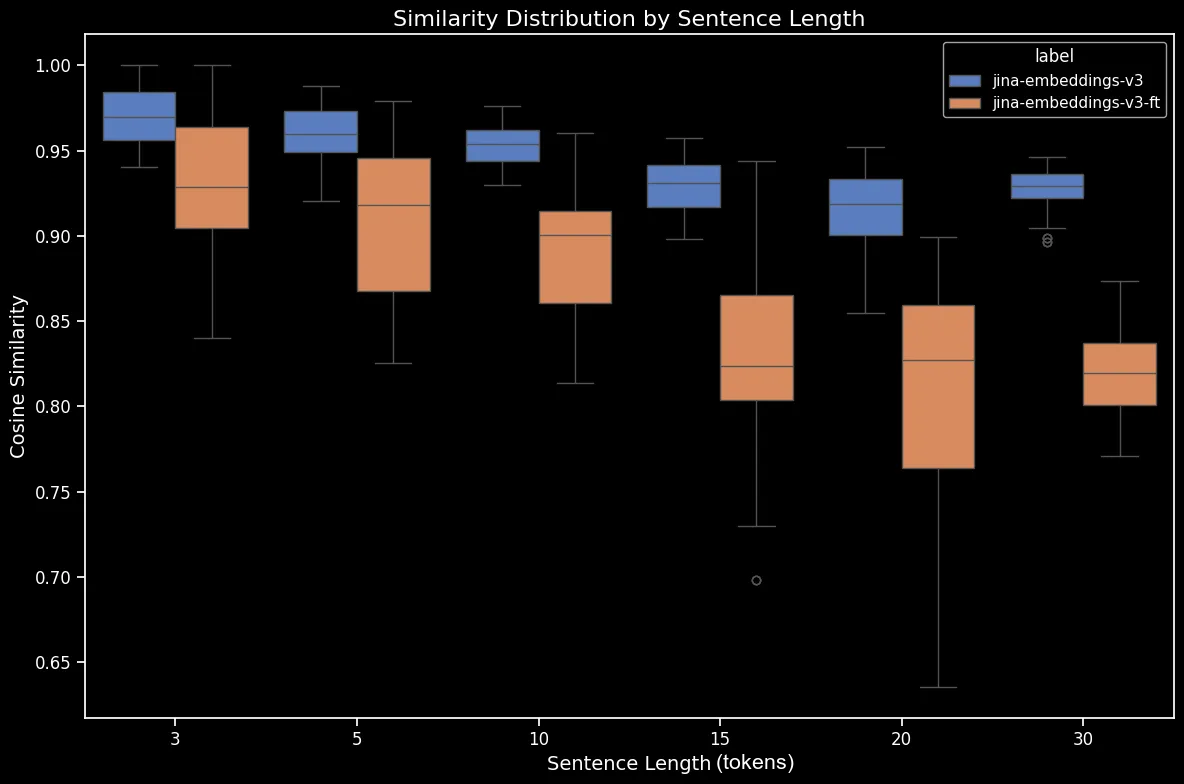
bge-base-en-1.5 (fine-tuné).Nous observons également des gains sur les cas directionnels, temporels, causaux et comparatifs. Le modèle montre une amélioration substantielle des performances reflétée par une baisse de la similarité cosinus moyenne. Le gain de performance le plus important concerne le cas de la négation, grâce à notre jeu de données de fine-tuning contenant 10 000 exemples de négation.
| Catégorie | Exemple - Gauche | Exemple - Droite | Similarité Cosinus Moyenne (jina) |
Similarité Cosinus Moyenne (jina-ft) |
Similarité Cosinus Moyenne (bge) |
Similarité Cosinus Moyenne (bge-ft) |
|---|---|---|---|---|---|---|
| Directionnel | She flew from Paris to Tokyo. | She drove from Tokyo to Paris | 0.9439 | 0.8650 | 0.9319 | 0.8674 |
| Temporel | She ate dinner before watching the movie | She watched the movie before eating dinner | 0.9833 | 0.9263 | 0.9683 | 0.9331 |
| Causal | The rising temperature melted the snow | The melting snow cooled the temperature | 0.8998 | 0.7937 | 0.8874 | 0.8371 |
| Comparatif | Coffee tastes better than tea | Tea tastes better than coffee | 0.9457 | 0.8759 | 0.9723 | 0.9030 |
| Négation | He is standing by the table | He is standing far from the table | 0.9116 | 0.4478 | 0.8329 | 0.4329 |
tagConclusion
Dans cet article, nous explorons les défis auxquels sont confrontés les modèles d'embedding de texte, en particulier leur difficulté à gérer efficacement l'ordre des mots. Pour résumer, nous avons identifié cinq types principaux d'échecs : Directionnel, Temporel, Causal, Comparatif, et Négation. Ce sont les types de requêtes où l'ordre des mots est vraiment important, et si votre cas d'utilisation implique l'un de ces aspects, il est important de connaître les limites de ces modèles.
Nous avons également mené une expérience rapide, en étendant un jeu de données axé sur la négation pour couvrir les cinq catégories d'échecs. Les résultats sont prometteurs : le fine-tuning avec des « hard negatives » soigneusement choisis a permis au modèle de mieux reconnaître quels éléments vont ensemble et lesquels ne le font pas. Cela dit, il reste encore du travail à faire. Les prochaines étapes comprennent une analyse plus approfondie de l'impact de la taille et de la qualité du jeu de données sur les performances.





