

Lors d'expérimentations avec des modèles de type ColPali, l'un de nos ingénieurs a créé une visualisation en utilisant notre modèle jina-clip-v2 récemment publié. Il a cartographié la similarité entre les embeddings de tokens et les embeddings de patchs pour des paires image-texte données, créant des superpositions de cartes de chaleur qui ont produit des aperçus visuels intrigants.

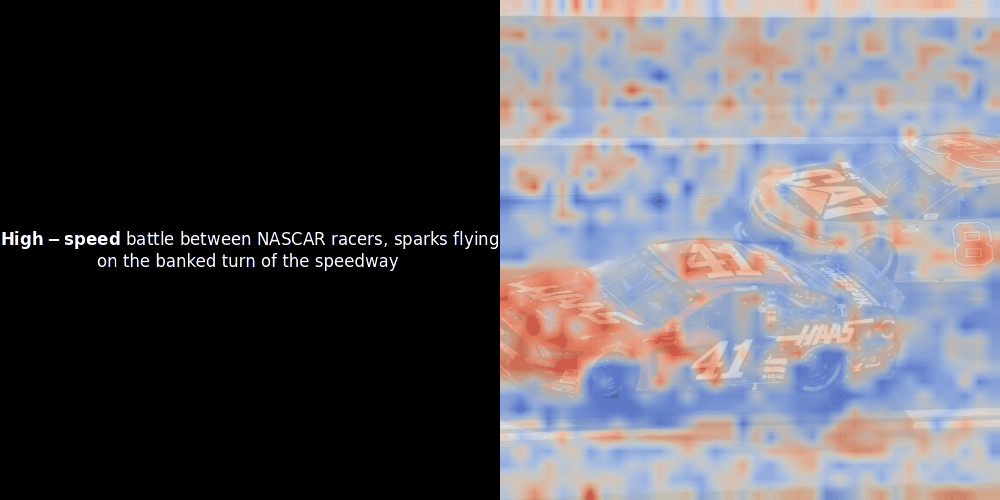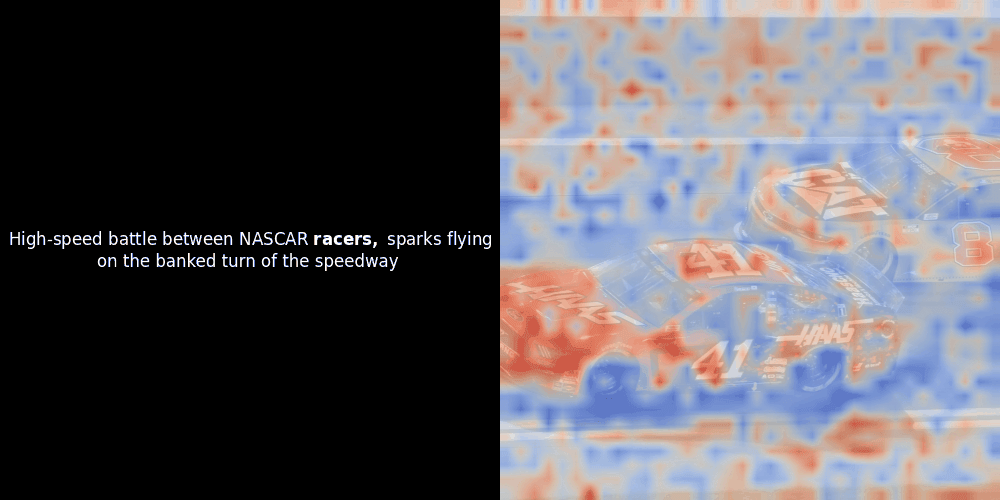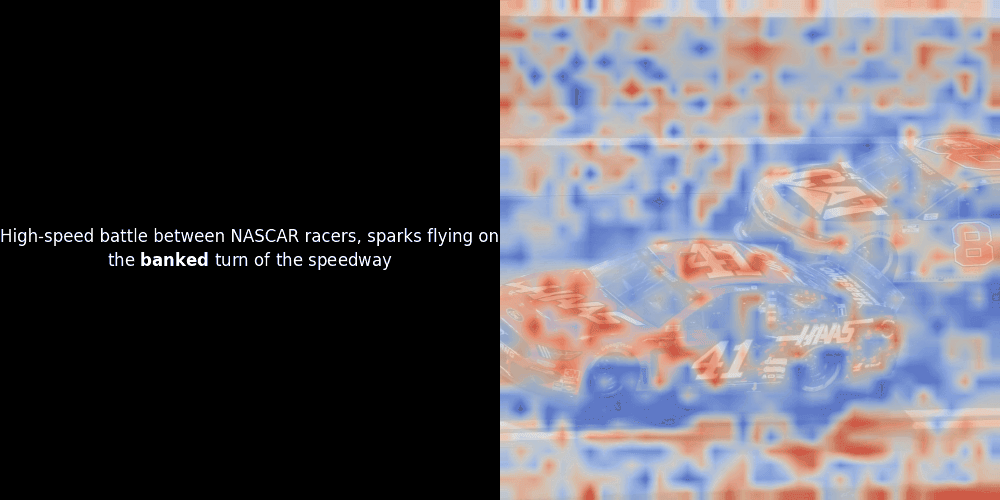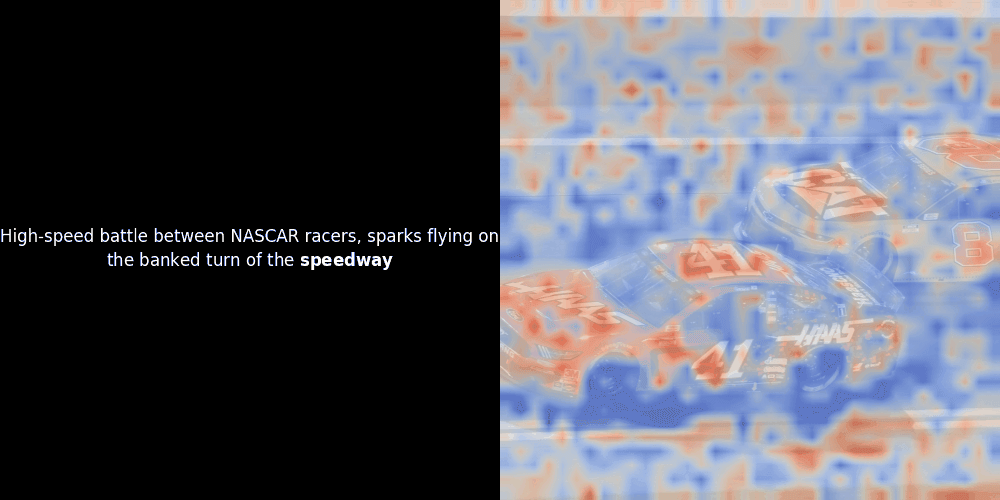
Malheureusement, il ne s'agit que d'une visualisation heuristique - pas d'un mécanisme explicite ou garanti. Bien que l'alignement contrastif global de type CLIP puisse (et souvent) créer incidemment des alignements locaux approximatifs entre les patchs et les tokens, il s'agit d'un effet secondaire non intentionnel plutôt que d'un objectif délibéré du modèle. Laissez-moi expliquer pourquoi.
tagComprendre le Code

Examinons ce que fait le code à haut niveau. Notez que jina-clip-v2 n'expose en réalité aucune API pour accéder aux embeddings au niveau des tokens ou des patchs par défaut - cette visualisation a nécessité quelques modifications post-hoc pour fonctionner.
Calcul des embeddings au niveau des mots
En définissant model.text_model.output_tokens = True, l'appel à text_model(x=...,)[1] renverra un deuxième élément (batch_size, seq_len, embed_dim) pour les embeddings des tokens. Il prend donc une phrase en entrée, la tokenise avec le tokenizer Jina CLIP, puis regroupe les tokens de sous-mots en "mots" en faisant la moyenne des embeddings de tokens correspondants. Il détecte le début d'un nouveau mot en vérifiant si la chaîne de token commence par le caractère _ (typique des tokenizers basés sur SentencePiece). Il produit une liste d'embeddings au niveau des mots et une liste de mots (ainsi "Dog" est un embedding, "and" est un embedding, etc.).
Calcul des embeddings au niveau des patchs
Pour la tour d'image, vision_model(..., return_all_features=True) renverra (batch_size, n_patches+1, embed_dim), où le premier token est le token [CLS]. À partir de là, le code extrait les embeddings pour chaque patch (c'est-à-dire les tokens de patch du transformateur de vision). Il redimensionne ensuite ces embeddings de patch en une grille 2D, patch_side × patch_side, qui est ensuite sur-échantillonnée pour correspondre à la résolution de l'image d'origine.
Visualisation de la similarité mot-patch
Le calcul de similarité et la génération ultérieure de carte de chaleur sont des techniques d'interprétabilité "post-hoc" standard : vous sélectionnez un embedding de texte, calculez la similarité cosinus avec chaque embedding de patch, puis générez une carte de chaleur montrant quels patchs ont la plus grande similarité avec cet embedding de token spécifique. Enfin, il parcourt chaque token de la phrase, met ce token en gras à gauche et superpose la carte de chaleur basée sur la similarité sur l'image d'origine à droite. Toutes les images sont compilées en un GIF animé.
tagEst-ce une Explicabilité Significative ?
D'un point de vue purement code, oui, la logique est cohérente et produira une carte de chaleur pour chaque token. Vous obtiendrez une série d'images qui mettent en évidence les similarités des patchs, donc le script "fait ce qu'il dit".
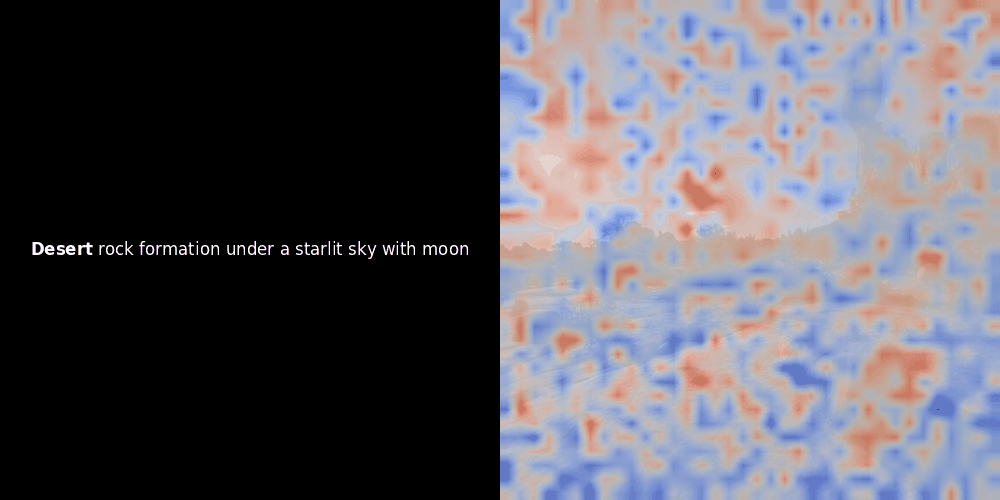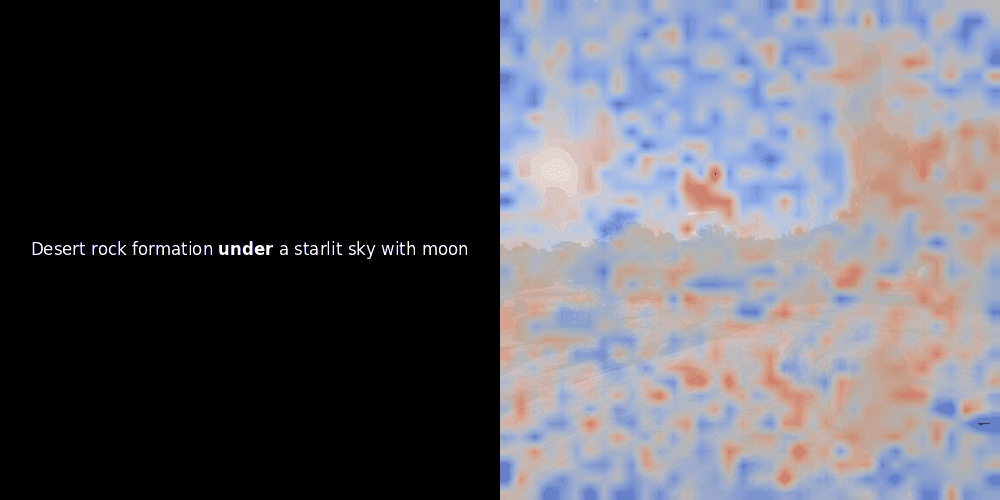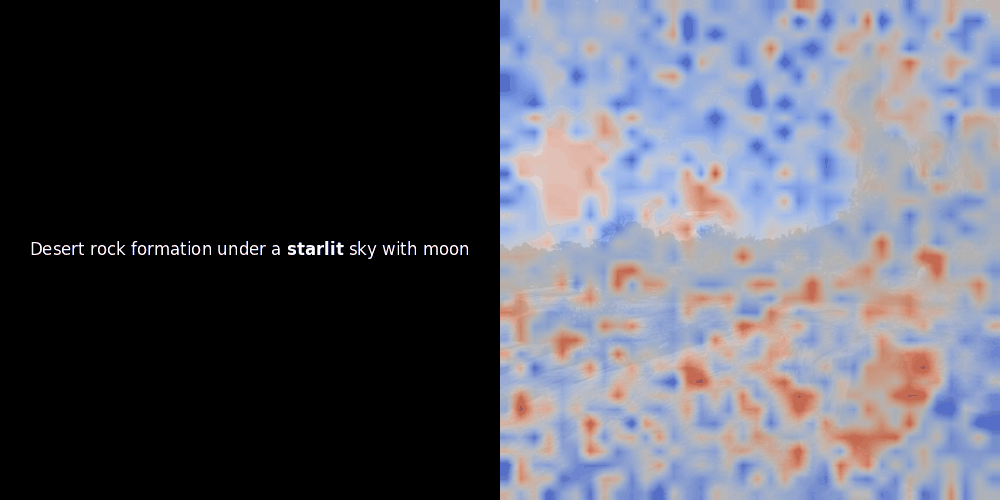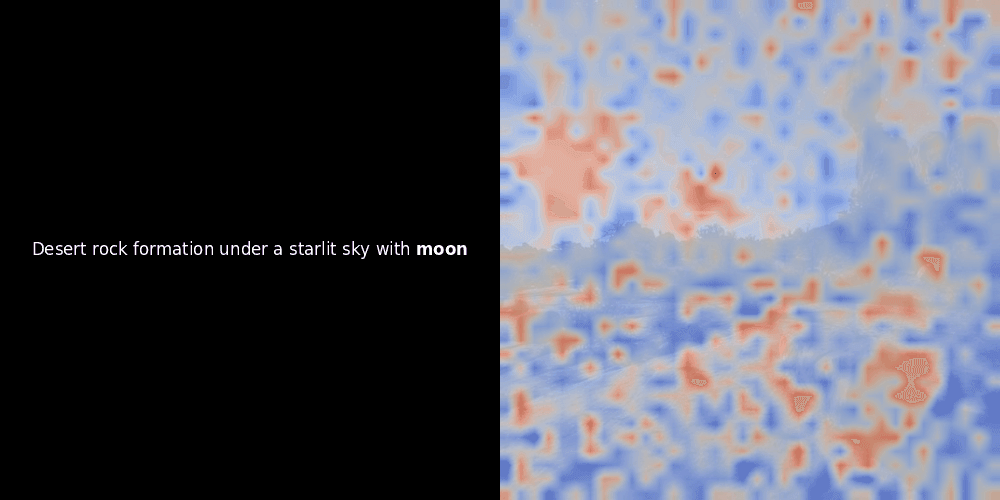

En regardant les exemples ci-dessus, nous voyons que des mots comme moon et branches semblent bien s'aligner avec leurs patchs visuels correspondants dans l'image d'origine. Mais voici la question clé : s'agit-il d'un alignement significatif, ou voyons-nous simplement une coïncidence heureuse ?
C'est une question plus profonde. Pour comprendre les mises en garde, rappelons comment CLIP est entraîné :

- CLIP utilise un alignement contrastif global entre une image entière et un texte entier. Pendant l'entraînement, l'encodeur d'image produit un seul vecteur (représentation groupée), et l'encodeur de texte produit un autre vecteur unique ; CLIP est entraîné pour que ceux-ci correspondent pour les paires texte-image correspondantes et ne correspondent pas dans le cas contraire.
- Il n'y a aucune supervision explicite au niveau 'le patch X correspond au token Y'. Le modèle n'est pas directement entraîné à mettre en évidence "cette région de l'image est le chien, cette région est le chat", etc. Au lieu de cela, on lui apprend que la représentation de l'image entière doit correspondre à la représentation du texte entier.
- Comme l'architecture de CLIP est un Vision Transformer côté image et un transformateur de texte côté texte—formant tous deux des encodeurs séparés—il n'y a pas de module d'attention croisée qui aligne naturellement les patchs aux tokens. Au lieu de cela, vous obtenez purement de l'auto-attention dans chaque tour, plus une projection finale pour les embeddings globaux d'image ou de texte.
En bref, c'est une visualisation heuristique. Le fait qu'un embedding de patch donné puisse être proche ou éloigné d'un embedding de token particulier est quelque peu émergent. C'est plus une astuce d'interprétabilité post-hoc qu'une "attention" robuste ou officielle du modèle.
tagPourquoi l'Alignement Local Pourrait-il Émerger ?
Alors pourquoi pourrions-nous parfois repérer des alignements locaux au niveau mot-patch ? Voici la chose : même si CLIP est entraîné sur un objectif contrastif global image-texte, il utilise toujours l'auto-attention (dans les encodeurs d'image basés sur ViT) et les couches transformer (pour le texte). Au sein de ces couches d'auto-attention, différentes parties des représentations d'images peuvent interagir entre elles, tout comme le font les mots dans les représentations de texte. Grâce à l'entraînement sur des ensembles de données massifs image-texte, le modèle développe naturellement des structures latentes internes qui l'aident à faire correspondre les images globales à leurs descriptions textuelles correspondantes.

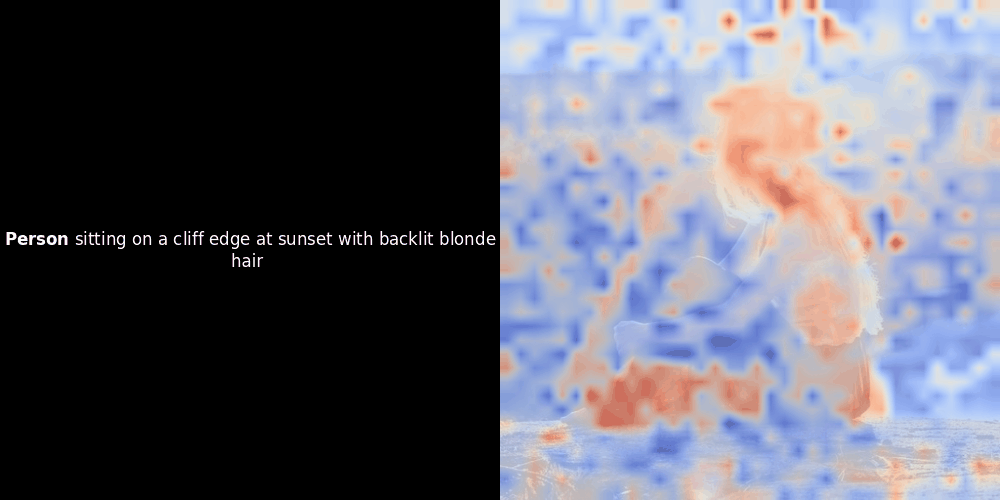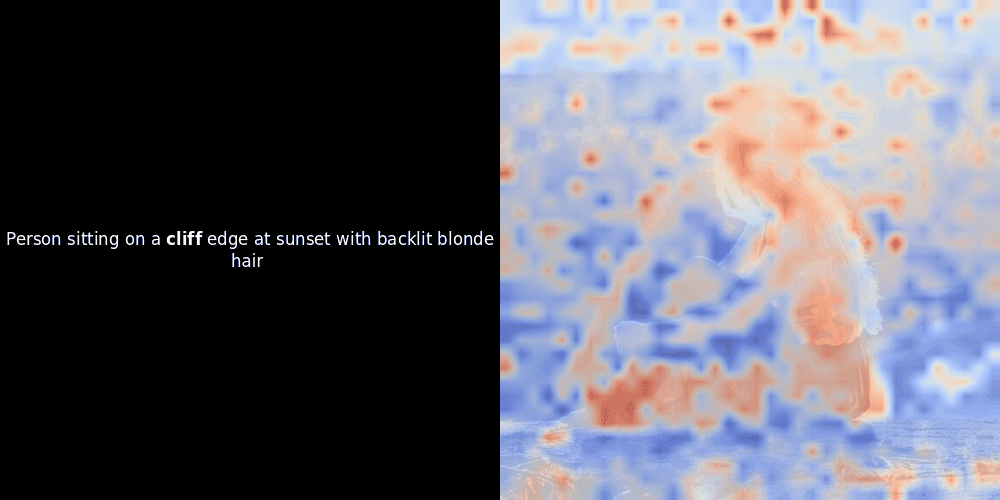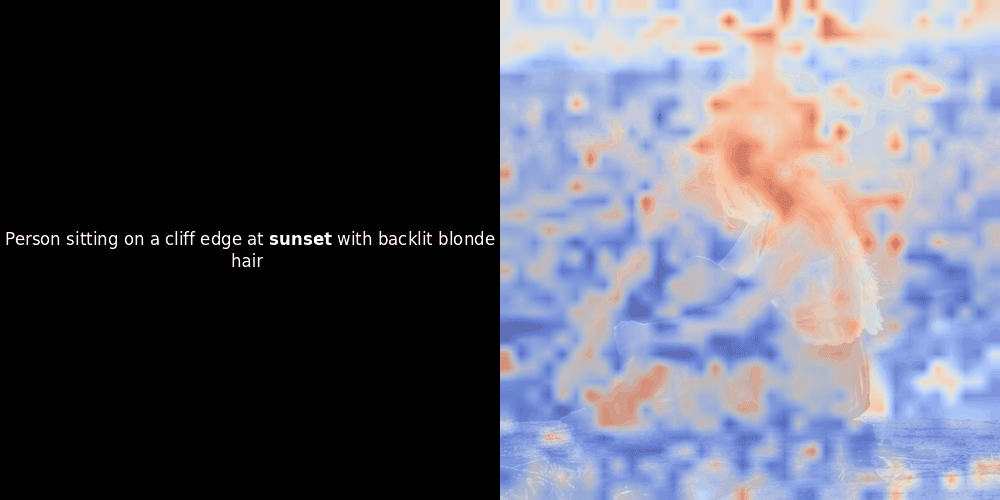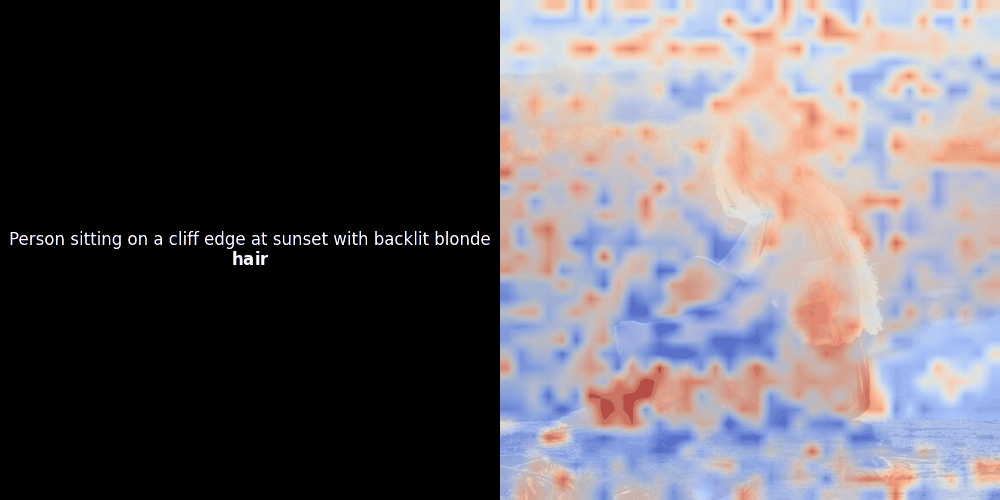
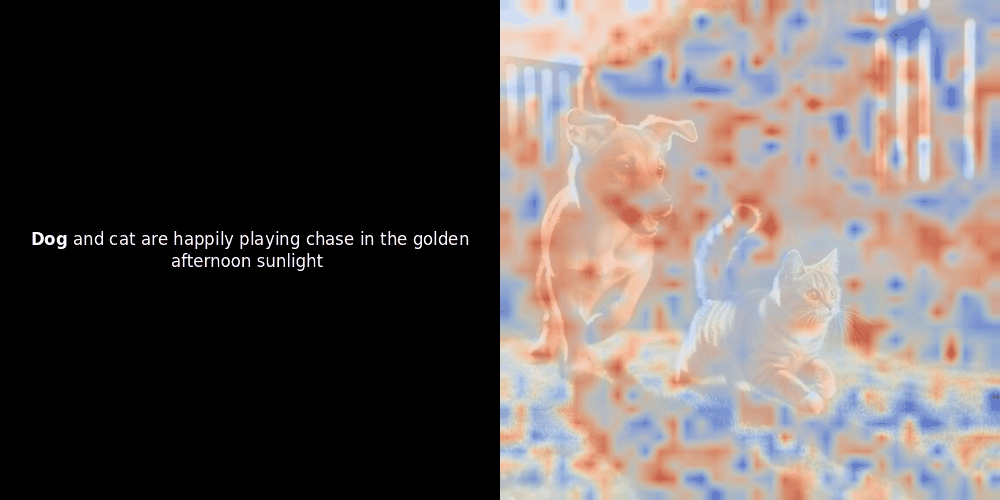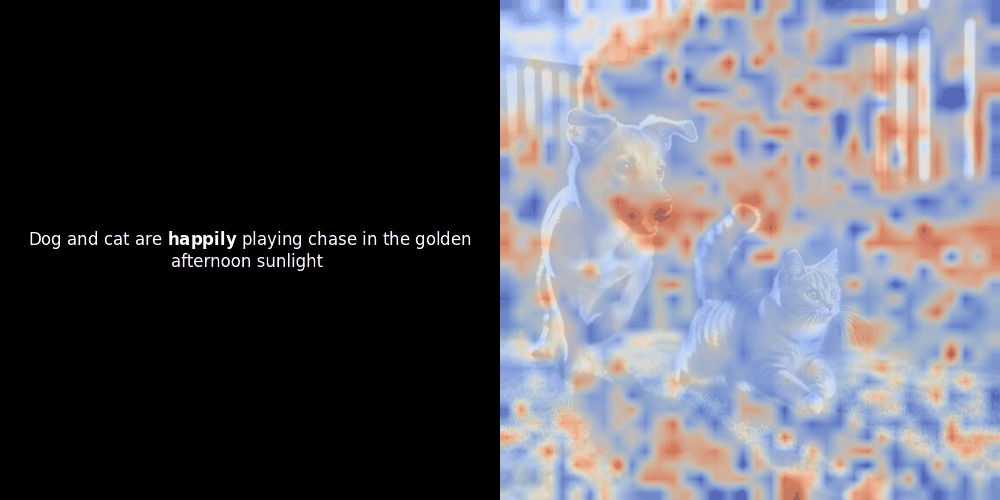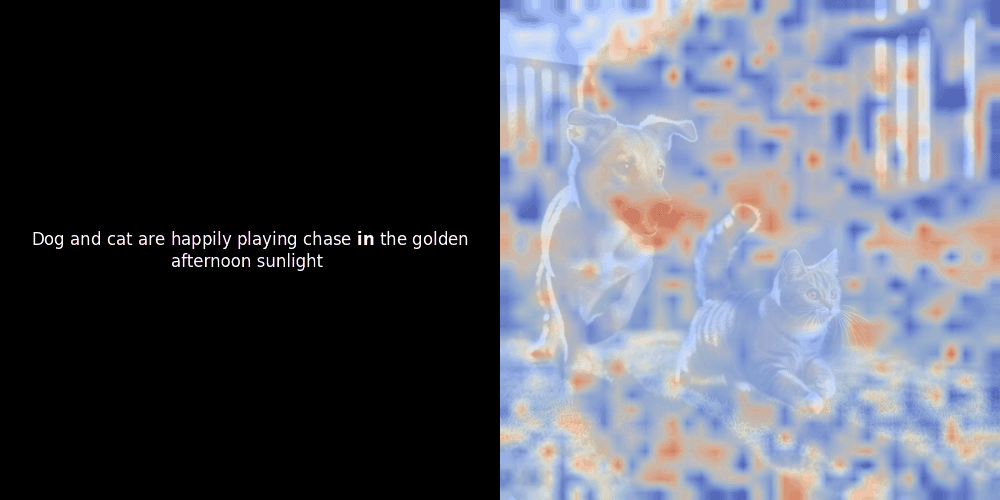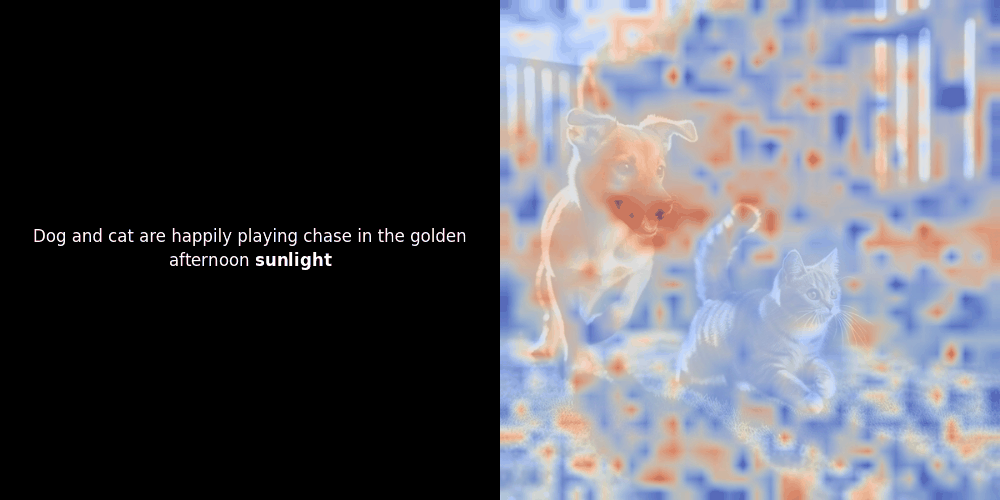
L'alignement local peut apparaître dans ces représentations latentes pour au moins deux raisons :
- Schémas de co-occurrence : Si un modèle voit de nombreuses images de "chiens" à côté de nombreuses images de "chats" (souvent étiquetées ou décrites avec ces mots), il peut apprendre des caractéristiques latentes qui correspondent approximativement à ces concepts. Ainsi, l'embedding pour "chien" pourrait se rapprocher des patchs locaux qui représentent une forme ou une texture de chien. Ce n'est pas explicitement supervisé au niveau du patch, mais émerge de l'association répétée entre les paires image/texte de chiens.
- Self-attention : Dans les Vision Transformers, les patches s'attendent mutuellement. Les patches distinctifs (comme le visage d'un chien) peuvent finir par avoir une "signature" latente cohérente, car le modèle essaie de produire une seule représentation globalement précise de toute la scène. Si cela aide à minimiser la perte contrastive globale, cela sera renforcé.
tagAnalyse théorique
L'objectif d'apprentissage contrastif de CLIP vise à maximiser la similarité cosinus entre les paires image-texte correspondantes tout en la minimisant pour les paires non correspondantes. Supposons que les encodeurs de texte et d'image produisent respectivement des embeddings de tokens et de patches :
La similarité globale peut être représentée comme un agrégat de similarités locales :
Lorsque des paires token-patch spécifiques co-occurrent fréquemment dans les données d'entraînement, le modèle renforce leur similarité par des mises à jour graduelles cumulatives :
, où est le nombre de co-occurrences. Cela conduit à une augmentation significative de , favorisant un alignement local plus fort pour ces paires. Cependant, la perte contrastive distribue les mises à jour du gradient sur toutes les paires token-patch, limitant la force des mises à jour pour une paire spécifique :
Cela empêche un renforcement significatif des similarités individuelles token-patch.
tagConclusion
Les visualisations token-patch de CLIP capitalisent sur un alignement fortuit et émergent entre les représentations textuelles et visuelles. Cet alignement, bien qu'intriguant, découle de l'entraînement contrastif global de CLIP et manque de la robustesse structurelle nécessaire pour une explicabilité précise et fiable. Les visualisations qui en résultent présentent souvent du bruit et des incohérences, limitant leur utilité pour des applications interprétatives approfondies.

Les modèles d'interaction tardive comme ColBERT et ColPali répondent à ces limitations en intégrant architecturalement des alignements explicites et détaillés entre les tokens de texte et les patches d'image. En traitant les modalités indépendamment et en effectuant des calculs de similarité ciblés à un stade ultérieur, ces modèles garantissent que chaque token de texte est associé de manière significative aux régions d'image pertinentes.





