



Les embeddings sémantiques sont au cœur des modèles d'IA modernes, y compris les chatbots et les modèles d'art IA. Ils sont parfois cachés aux utilisateurs, mais ils sont toujours là, tapis juste sous la surface.
La théorie des embeddings ne comporte que deux parties :
- Les choses — les éléments externes au modèle d'IA, comme les textes et les images — sont représentées par des vecteurs créés par les modèles d'IA à partir des données sur ces choses.
- Les relations entre les choses externes au modèle d'IA sont représentées par des relations spatiales entre ces vecteurs. Nous entraînons spécifiquement les modèles d'IA pour créer des vecteurs qui fonctionnent de cette manière.
Lorsque nous créons un modèle multimodal image-texte, nous entraînons le modèle de sorte que les embeddings des images et les embeddings des textes décrivant ou liés à ces images soient relativement proches les uns des autres. Les similarités sémantiques entre les choses que ces deux vecteurs représentent — une image et un texte — se reflètent dans la relation spatiale entre les deux vecteurs.
Par exemple, nous pourrions raisonnablement nous attendre à ce que les vecteurs d'embedding pour une image d'orange et le texte "une orange fraîche" soient plus proches l'un de l'autre que la même image et le texte "une pomme fraîche".
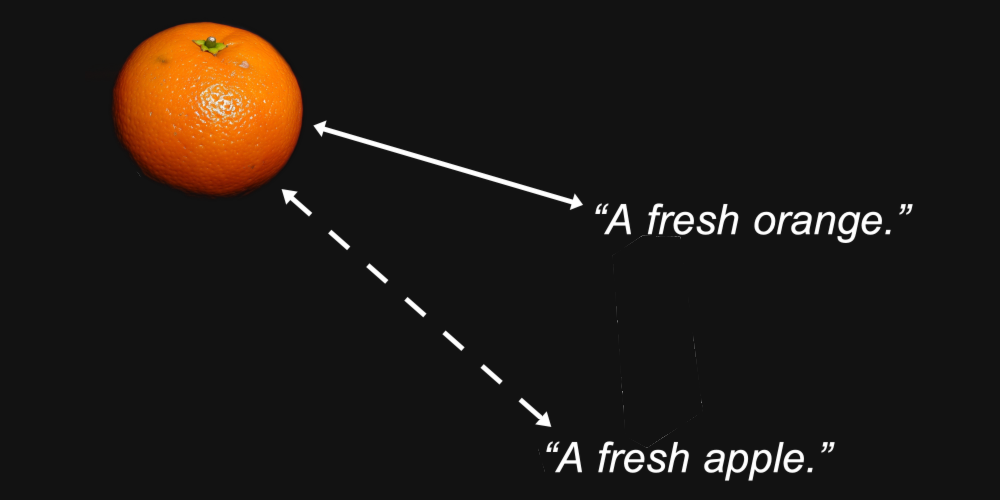
C'est le but d'un modèle d'embedding : Générer des représentations où les caractéristiques qui nous intéressent — comme le type de fruit représenté dans une image ou nommé dans un texte — sont préservées dans la distance entre eux.
Mais la multimodalité introduit autre chose. Nous pourrions découvrir qu'une image d'orange est plus proche d'une image de pomme qu'elle ne l'est du texte "une orange fraîche", et que le texte "une pomme fraîche" est plus proche d'un autre texte que d'une image de pomme.
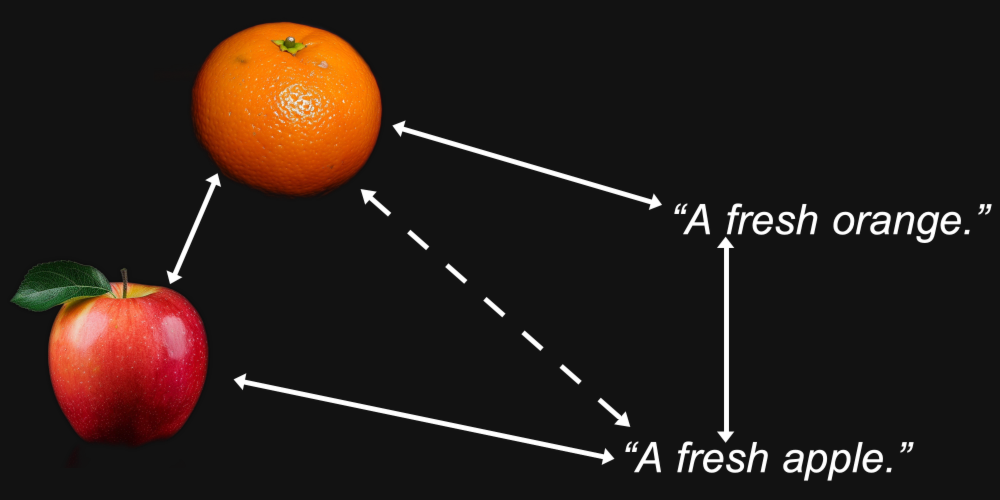
Il s'avère que c'est exactement ce qui se passe avec les modèles multimodaux, y compris le modèle Jina CLIP de Jina AI (jina-clip-v1).
Pour tester cela, nous avons échantillonné 1 000 paires texte-image du jeu de test Flickr8k. Chaque paire contient cinq textes de légende (donc techniquement pas une paire) et une seule image, les cinq textes décrivant la même image.
Par exemple, l'image suivante (1245022983_fb329886dd.jpg dans le dataset Flickr8k) :

Ses cinq légendes :
A child in all pink is posing nearby a stroller with buildings in the distance.
A little girl in pink dances with her hands on her hips.
A small girl wearing pink dances on the sidewalk.
The girl in a bright pink skirt dances near a stroller.
The little girl in pink has her hands on her hips.
Nous avons utilisé Jina CLIP pour intégrer les images et les textes puis :
- Comparer les similarités cosinus des embeddings d'images avec les embeddings de leurs textes de légende.
- Prendre les embeddings des cinq textes de légende qui décrivent la même image et comparer leurs similarités cosinus entre eux.
Le résultat est un écart étonnamment important, visible dans la Figure 1 :
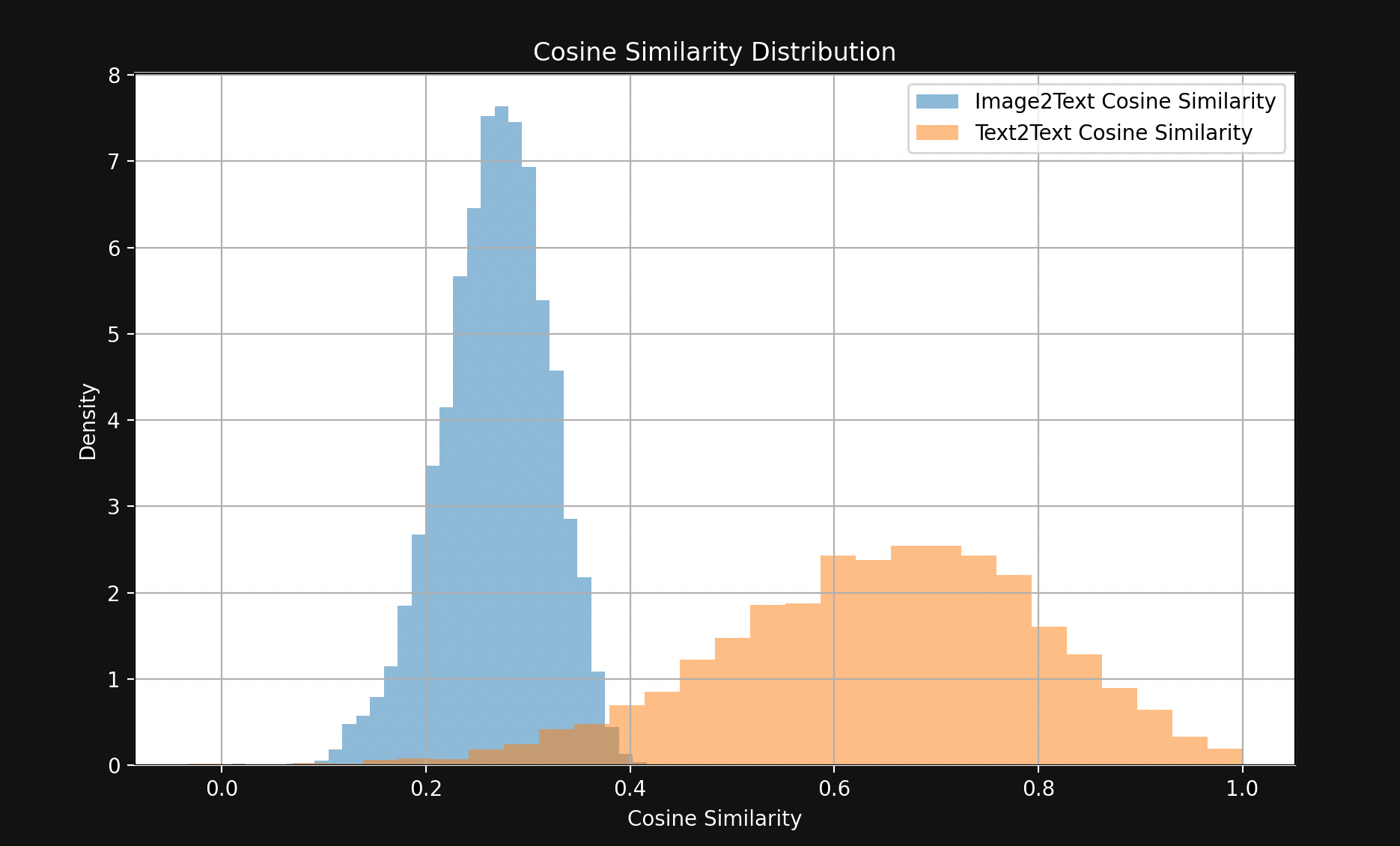
À quelques exceptions près, les paires de textes correspondantes sont beaucoup plus proches les unes des autres que les paires image-texte correspondantes. Cela indique fortement que Jina CLIP encode les textes dans une partie de l'espace d'embedding et les images dans une partie largement disjointe relativement éloignée. Cet espace entre les textes et les images est le fossé multimodal.

Les modèles d'embedding multimodaux encodent plus que l'information sémantique qui nous intéresse : ils encodent le médium de leur entrée. Selon Jina CLIP, une image ne vaut pas, comme le dit le dicton, mille mots. Elle a un contenu qu'aucune quantité de mots ne pourra jamais vraiment égaler. Elle encode le médium d'entrée dans la sémantique de ses embeddings sans que personne ne l'ait jamais entraînée à le faire.
Ce phénomène a été étudié dans l'article Mind the Gap : Understanding the Modality Gap in Multi-modal Contrastive Representation Learning [Liang et al., 2022] qui le désigne comme le "fossé modal". Le fossé modal est la séparation spatiale, dans l'espace d'embedding, entre les entrées dans un médium et les entrées dans un autre. Bien que les modèles ne soient pas intentionnellement entraînés à avoir un tel fossé, ils sont omniprésents dans les modèles multimodaux.
Nos investigations sur le fossé modal dans Jina CLIP s'appuient fortement sur Liang et al. [2022].
tagD'où vient le fossé modal ?
Liang et al. [2022] identifient trois sources principales derrière le fossé modal :
- Un biais d'initialisation qu'ils appellent "l'effet cône".
- Des réductions de température (aléatoire) pendant l'entraînement qui rendent très difficile de "désapprendre" ce biais.
- Des procédures d'apprentissage contrastif, largement utilisées dans les modèles multimodaux, qui renforcent involontairement le fossé.
Nous examinerons chacun à tour de rôle.
tagEffet cône
Un modèle construit avec une architecture CLIP ou de type CLIP est en réalité composé de deux modèles d'embedding distincts reliés ensemble. Pour les modèles multimodaux image-texte, cela signifie un modèle pour encoder les textes, et un autre complètement séparé pour encoder les images, comme dans le schéma ci-dessous.
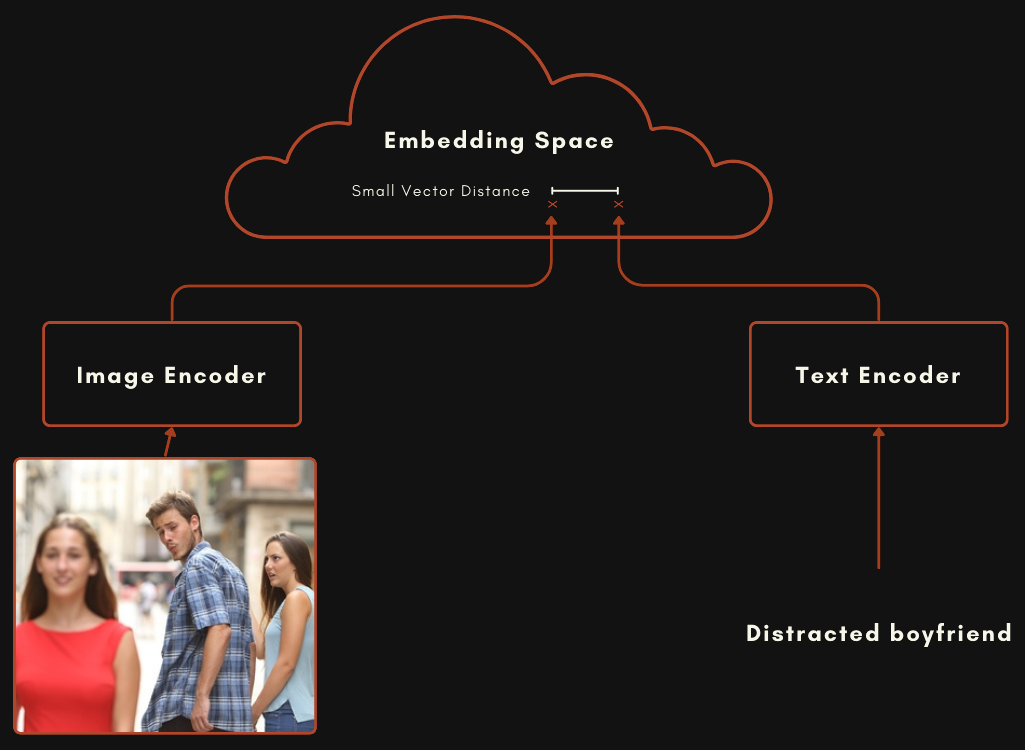
Ces deux modèles sont entraînés de manière à ce qu'un embedding d'image et un embedding de texte soient relativement proches lorsque le texte décrit bien l'image.
Vous pouvez entraîner un tel modèle en randomisant les poids dans les deux modèles, puis en lui présentant des paires image-texte ensemble, en l'entraînant à partir de zéro pour minimiser la distance entre les deux sorties. Le modèle CLIP original d'OpenAI a été entraîné de cette manière. Cependant, cela nécessite beaucoup de paires image-texte et un entraînement très coûteux en calcul. Pour le premier modèle CLIP, OpenAI a extrait 400 millions de paires image-texte de contenus légendés sur Internet.
Les modèles plus récents de type CLIP utilisent des composants pré-entraînés. Cela signifie entraîner chaque composant séparément comme un bon modèle d'embedding unimodal, un pour les textes et un pour les images. Ces deux modèles sont ensuite entraînés ensemble en utilisant des paires image-texte, un processus appelé contrastive tuning. Des paires image-texte alignées sont utilisées pour "pousser" progressivement les poids à rapprocher les embeddings de texte et d'image correspondants, et à éloigner ceux qui ne correspondent pas.
Cette approche nécessite généralement moins de données de paires image-texte, qui sont difficiles et coûteuses à obtenir, et de grandes quantités de textes simples et d'images sans légendes, qui sont beaucoup plus faciles à obtenir. Jina CLIP (jina-clip-v1) a été entraîné en utilisant cette dernière méthode. Nous avons pré-entraîné un modèle JinaBERT v2 pour l'encodage de texte en utilisant des données textuelles générales et utilisé un encodeur d'images EVA-02 pré-entraîné, puis les avons entraînés davantage en utilisant diverses techniques d'entraînement contrastif, comme décrit dans Koukounas et al. [2024]
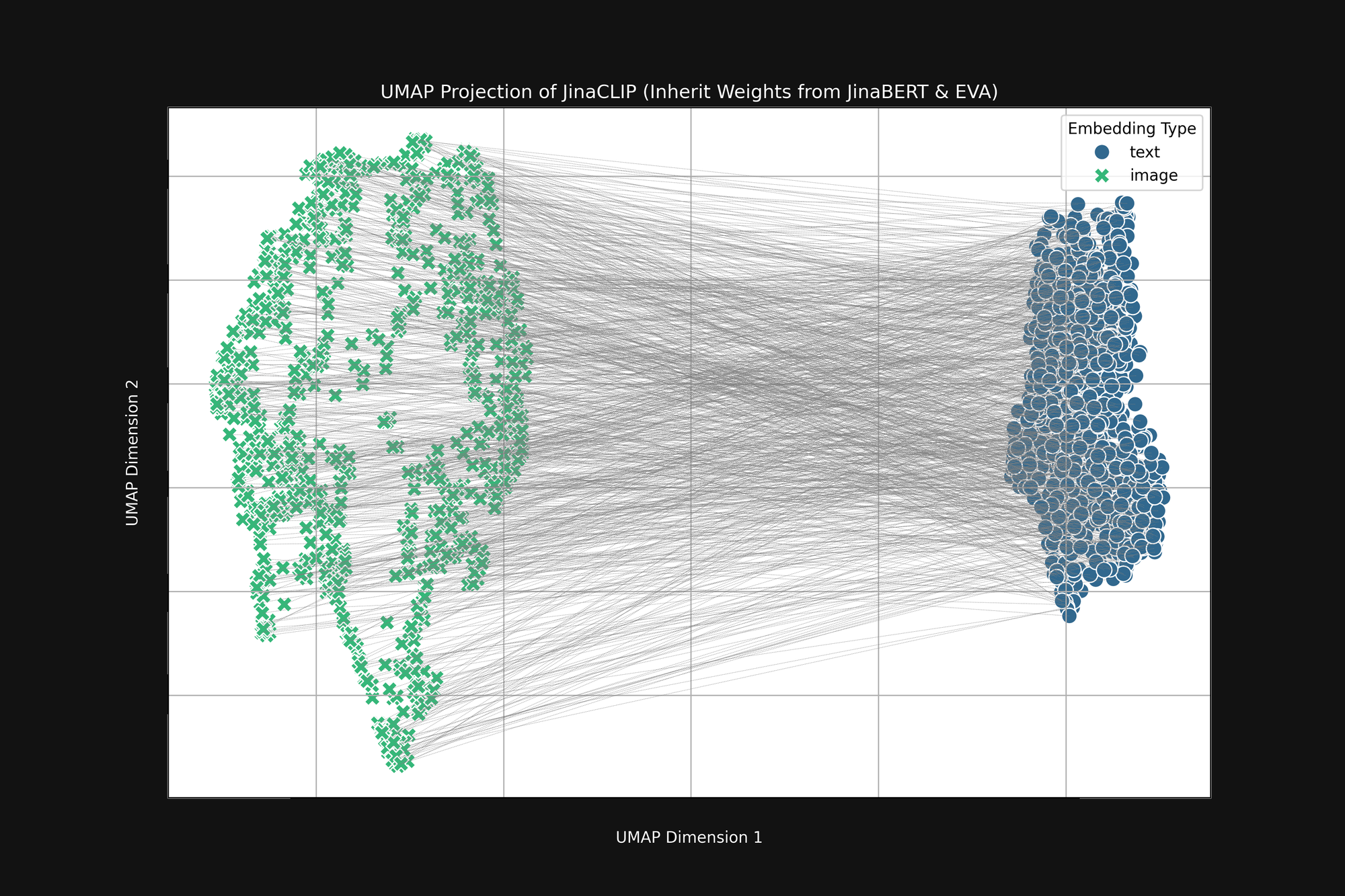
Si nous prenons ces deux modèles pré-entraînés et examinons leur sortie, avant de les entraîner avec des paires image-texte, nous remarquons quelque chose d'important. La Figure 2 (ci-dessus) est une projection UMAP en deux dimensions des embeddings d'images produits par l'encodeur EVA-02 pré-entraîné et des embeddings de texte produits par JinaBERT v2 pré-entraîné, avec les lignes grises indiquant les paires image-texte correspondantes. Ceci est avant tout entraînement intermodal.
Le résultat est une sorte de "cône" tronqué, avec les embeddings d'images à une extrémité et les embeddings de texte à l'autre. Cette forme conique est mal traduite dans les projections bidimensionnelles mais vous pouvez globalement la voir dans l'image ci-dessus. Tous les textes se regroupent dans une partie de l'espace d'embedding, et toutes les images dans une autre partie. Si, après l'entraînement, les textes restent plus similaires à d'autres textes qu'aux images correspondantes, cet état initial en est une raison majeure. L'objectif de mieux faire correspondre les images aux textes, les textes aux textes et les images aux images est totalement compatible avec cette forme conique.
Le modèle est biaisé dès sa naissance et ce qu'il apprend ne change pas cela. La Figure 3 (ci-dessous) est la même analyse du modèle Jina CLIP tel que publié, après un entraînement complet utilisant des paires image-texte. Si quelque chose, l'écart multimodal est encore plus prononcé.
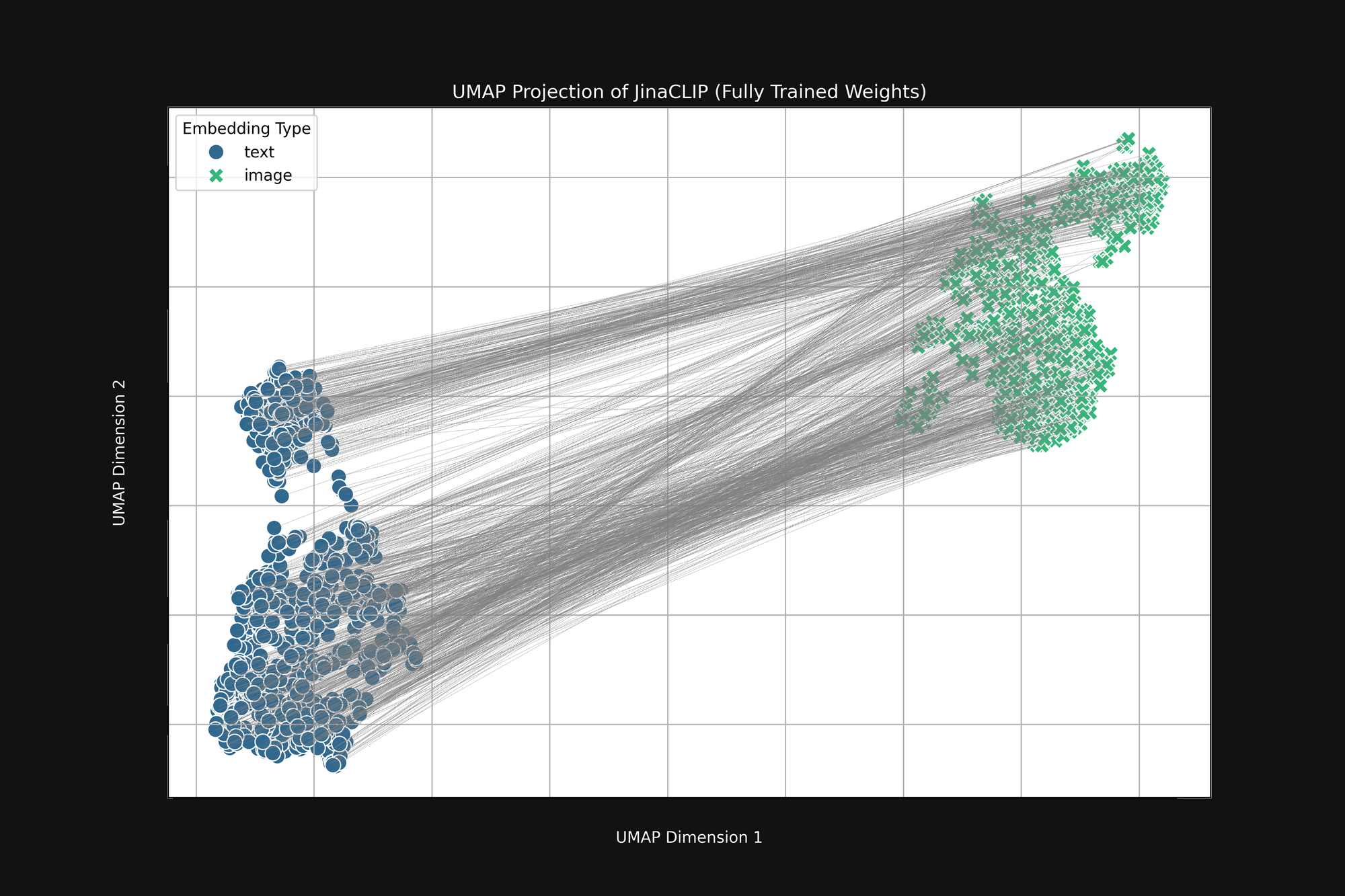
Même après un entraînement approfondi, Jina CLIP encode toujours le medium comme partie du message.
L'utilisation de l'approche plus coûteuse d'OpenAI, avec une initialisation purement aléatoire, n'élimine pas ce biais. Nous avons pris l'architecture CLIP originale d'OpenAI et complètement randomisé tous les poids, puis effectué la même analyse que ci-dessus. Le résultat est toujours une forme de cône tronqué, comme on le voit dans la Figure 4 :
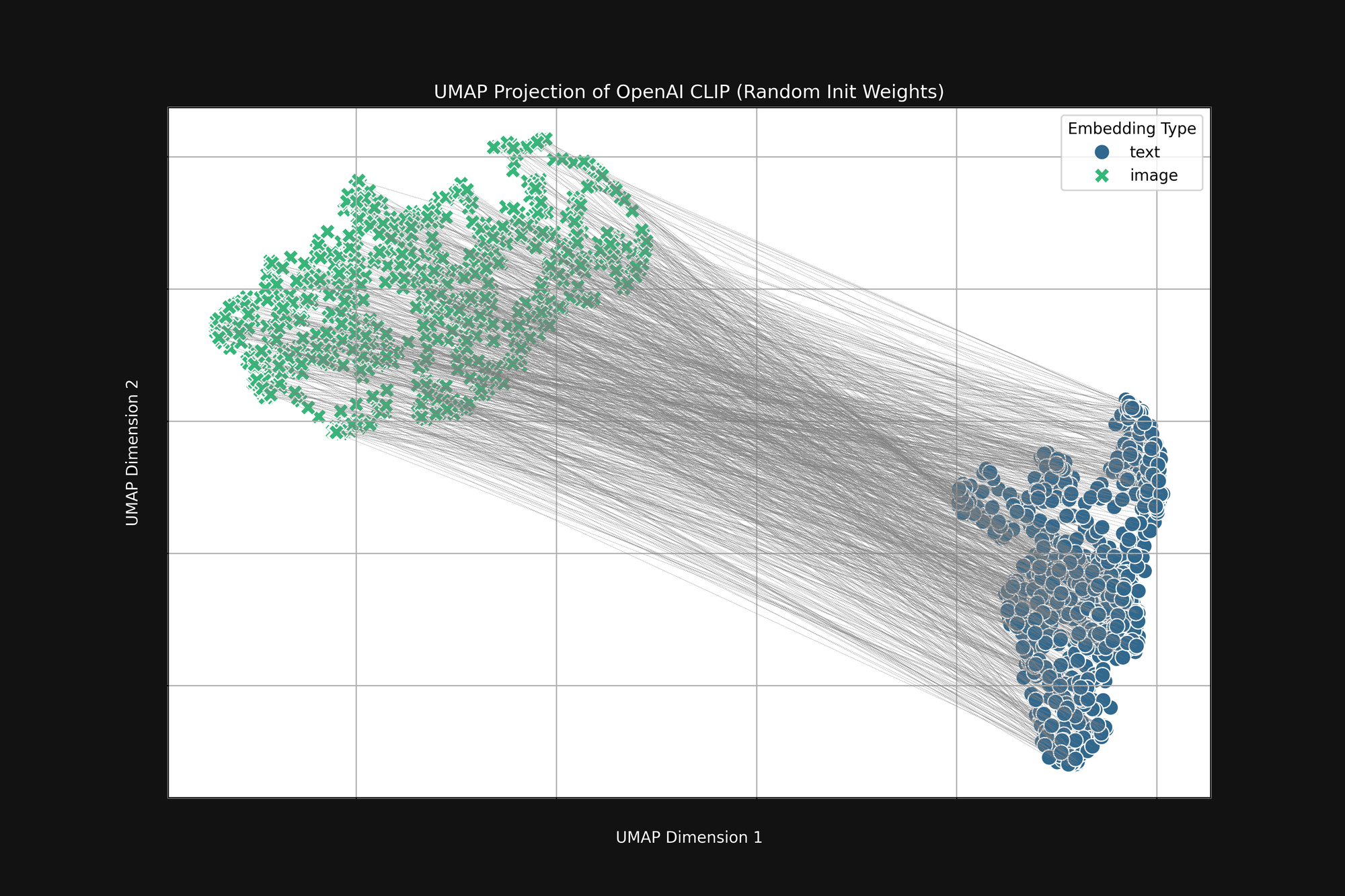
Ce biais est un problème structurel, et peut ne pas avoir de solution. Si c'est le cas, nous ne pouvons que chercher des moyens de le corriger ou de l'atténuer pendant l'entraînement.
tagTempérature d'entraînement
Pendant l'entraînement des modèles d'IA, nous ajoutons généralement un peu d'aléatoire au processus. Nous calculons à quel point un lot d'échantillons d'entraînement devrait modifier les poids dans le modèle, puis ajoutons un petit facteur aléatoire à ces modifications avant de réellement changer les poids. Nous appelons la quantité d'aléatoire la température, par analogie avec la façon dont nous utilisons l'aléatoire en thermodynamique.
Les températures élevées créent de grands changements dans les modèles très rapidement, tandis que les basses températures réduisent la quantité de changement qu'un modèle peut subir chaque fois qu'il voit des données d'entraînement. En conséquence, avec des températures élevées, nous pouvons nous attendre à ce que les embeddings individuels se déplacent beaucoup dans l'espace d'embedding pendant l'entraînement, et avec des températures basses, ils se déplaceront beaucoup plus lentement.
La meilleure pratique pour l'entraînement des modèles d'IA est de commencer avec une température élevée puis de la réduire progressivement. Cela aide le modèle à faire de grands bonds dans l'apprentissage au début lorsque les poids sont soit aléatoires soit loin de là où ils doivent être, puis lui permet d'apprendre les détails de manière plus stable.
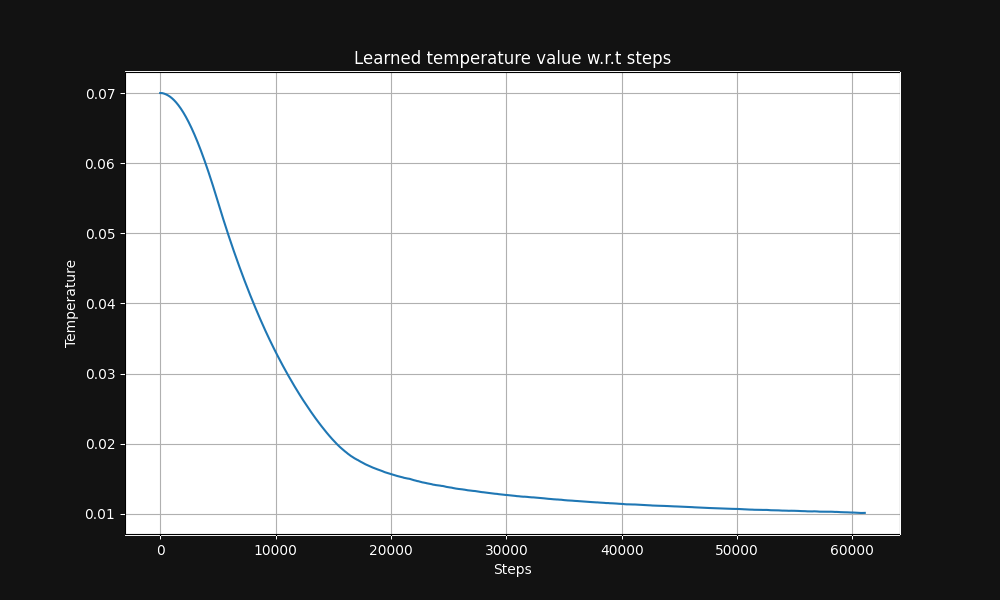
L'entraînement par paires image-texte de Jina CLIP commence avec une température de 0,07 (c'est une température relativement élevée) et la réduit exponentiellement au cours de l'entraînement jusqu'à 0,01, comme montré dans la Figure 5 ci-dessous, un graphique de la température en fonction des étapes d'entraînement :
Nous voulions savoir si l'augmentation de la température — l'ajout d'aléatoire — réduirait l'effet de cône et rapprocherait globalement les embeddings d'images et de textes. Nous avons donc réentraîné Jina CLIP avec une température fixe de 0,1 (une valeur très élevée). Après chaque époque d'entraînement, nous avons vérifié la distribution des distances entre les paires image-texte et les paires texte-texte, comme dans la Figure 1. Les résultats sont ci-dessous dans la Figure 6 :
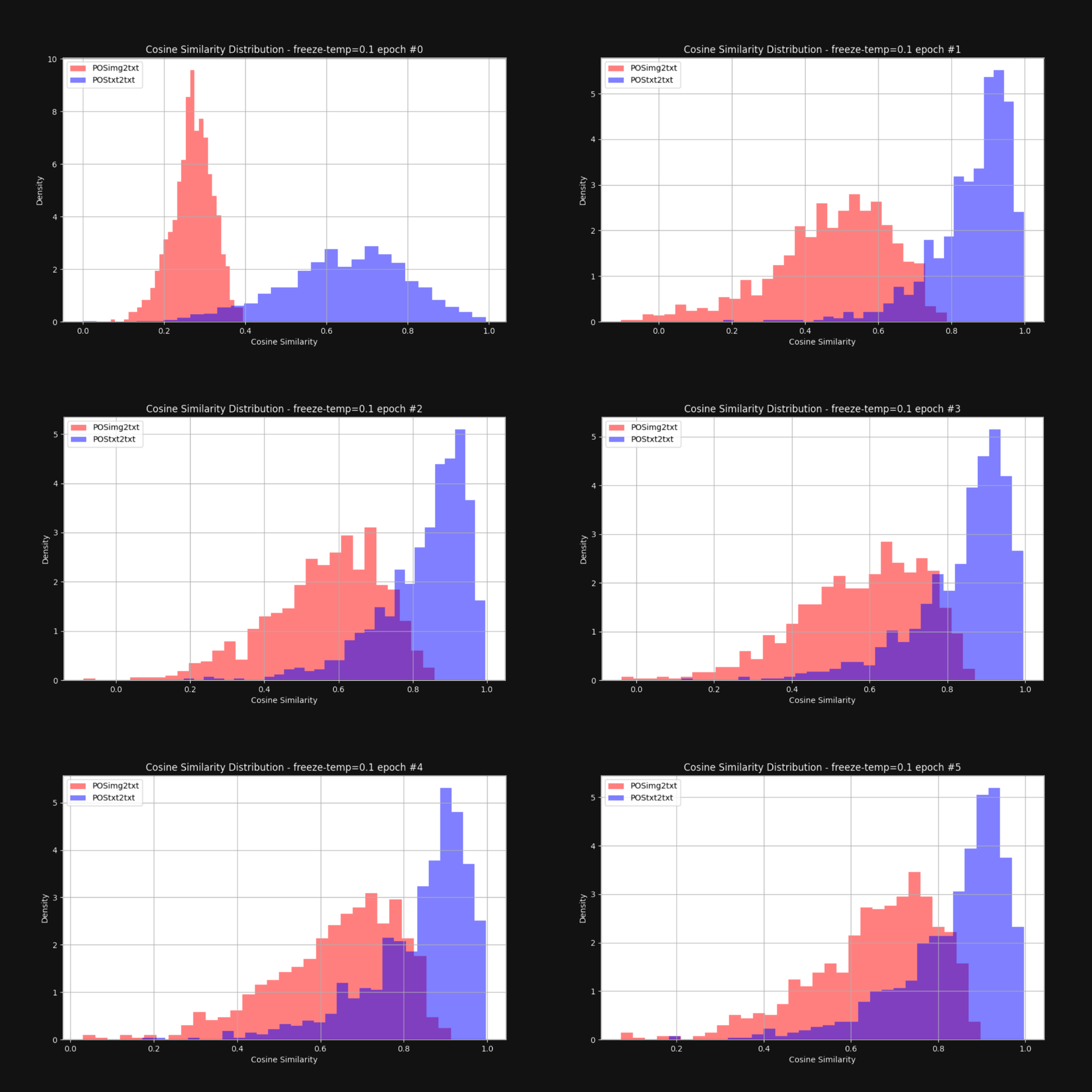
Comme vous pouvez le voir, le maintien d'une température élevée réduit considérablement l'écart multimodal. Permettre aux embeddings de beaucoup bouger pendant l'entraînement contribue grandement à surmonter le biais initial dans leur distribution.
Cependant, cela a un coût. Nous avons également testé les performances du modèle en utilisant six tests de récupération différents : trois tests de récupération texte-texte et trois tests de récupération texte-image, à partir des jeux de données MS-COCO, Flickr8k, et Flickr30k. Dans tous les tests, nous observons une chute des performances au début de l'entraînement, suivie d'une remontée très lente, comme vous pouvez le voir dans la Figure 7 :
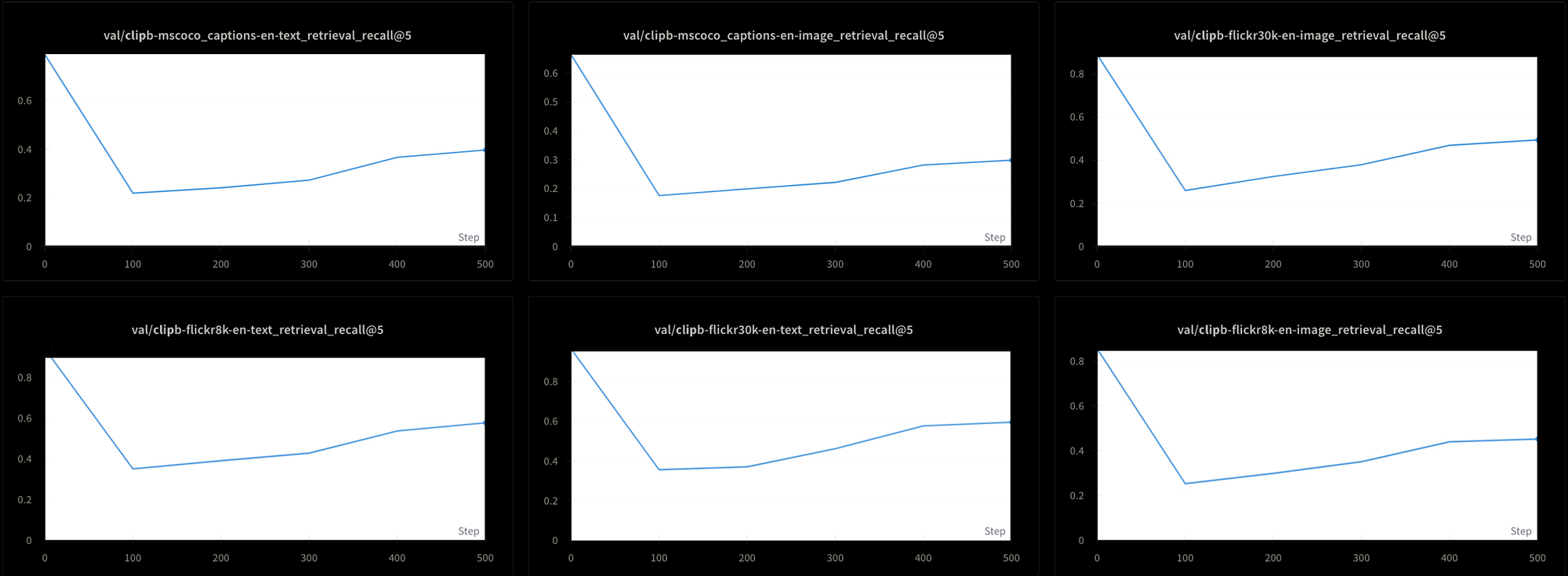
Il serait probablement extrêmement long et coûteux d'entraîner un modèle comme Jina CLIP en utilisant cette température élevée constante. Bien que théoriquement possible, ce n'est pas une solution pratique.
tagL'apprentissage contrastif et le problème des faux négatifs
Liang et al. [2022] ont également découvert que les pratiques standard d'apprentissage contrastif — le mécanisme que nous utilisons pour entraîner les modèles multimodaux de type CLIP — tendent à renforcer l'écart multimodal.
L'apprentissage contrastif est fondamentalement un concept simple. Nous avons un embedding d'image et un embedding de texte dont nous savons qu'ils devraient être plus proches, nous ajustons donc les poids du modèle pendant l'entraînement pour y parvenir. Nous procédons lentement, en ajustant les poids par petites quantités, et nous les ajustons proportionnellement à l'écart entre les deux embeddings : plus ils sont proches, plus le changement est petit.
Cette technique fonctionne beaucoup mieux si nous ne nous contentons pas de rapprocher les embeddings lorsqu'ils correspondent, mais que nous les éloignons également lorsqu'ils ne correspondent pas. Nous voulons avoir non seulement des paires image-texte qui vont ensemble, mais aussi des paires dont nous savons qu'elles doivent être séparées.
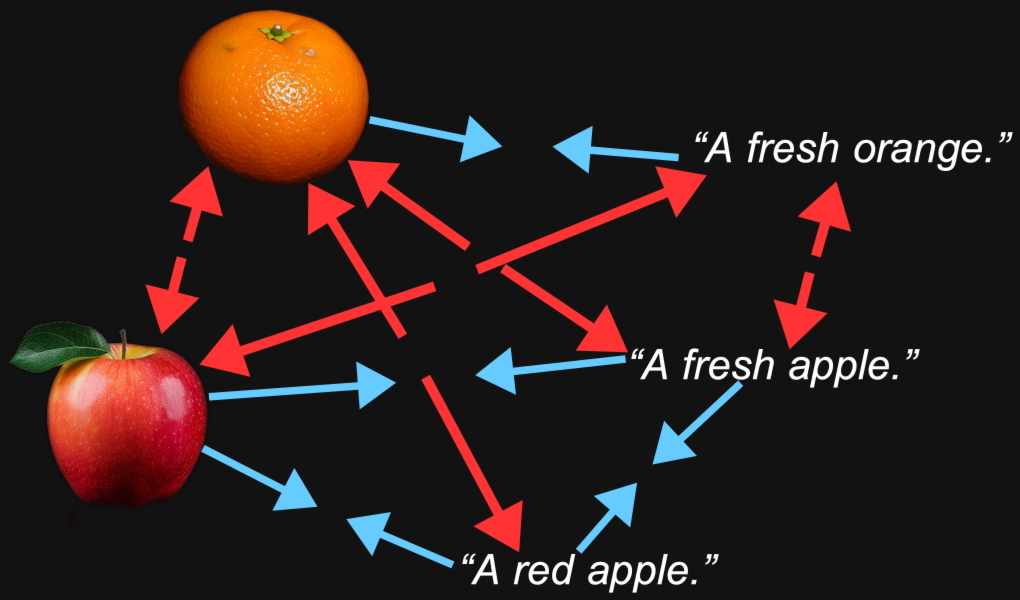
Cela pose quelques problèmes :
- Nos sources de données ne contiennent que des paires correspondantes. Personne ne créerait une base de données de textes et d'images dont un humain a vérifié qu'ils ne sont pas liés, et on ne pourrait pas non plus en construire une facilement en explorant le web ou une autre technique non supervisée ou semi-supervisée.
- Même les paires image-texte qui semblent superficiellement complètement disjointes ne le sont pas nécessairement. Nous n'avons pas de théorie de la sémantique qui nous permette de faire objectivement de tels jugements négatifs. Par exemple, une photo d'un chat allongé sur un porche n'est pas totalement incompatible avec le texte "un homme dormant sur un canapé". Les deux impliquent d'être allongé sur quelque chose.
Idéalement, nous voudrions entraîner avec des paires image-texte dont nous savons avec certitude qu'elles sont liées et non liées, mais il n'y a pas de moyen évident d'obtenir des paires connues comme non liées. Il est possible de demander aux gens "Cette phrase décrit-elle cette image ?" et d'attendre des réponses cohérentes. Il est beaucoup plus difficile d'obtenir des réponses cohérentes en demandant "Cette phrase n'a-t-elle absolument rien à voir avec cette image ?"
À la place, nous obtenons des paires image-texte non liées en sélectionnant aléatoirement des images et des textes de nos données d'entraînement, en supposant qu'ils seront pratiquement toujours de mauvaises correspondances. En pratique, nous divisons nos données d'entraînement en lots. Pour entraîner Jina CLIP, nous avons utilisé des lots contenant 32 000 paires image-texte correspondantes, mais pour cette expérience, les tailles de lots n'étaient que de 16.
Le tableau ci-dessous présente 16 paires image-texte échantillonnées aléatoirement depuis Flickr8k :
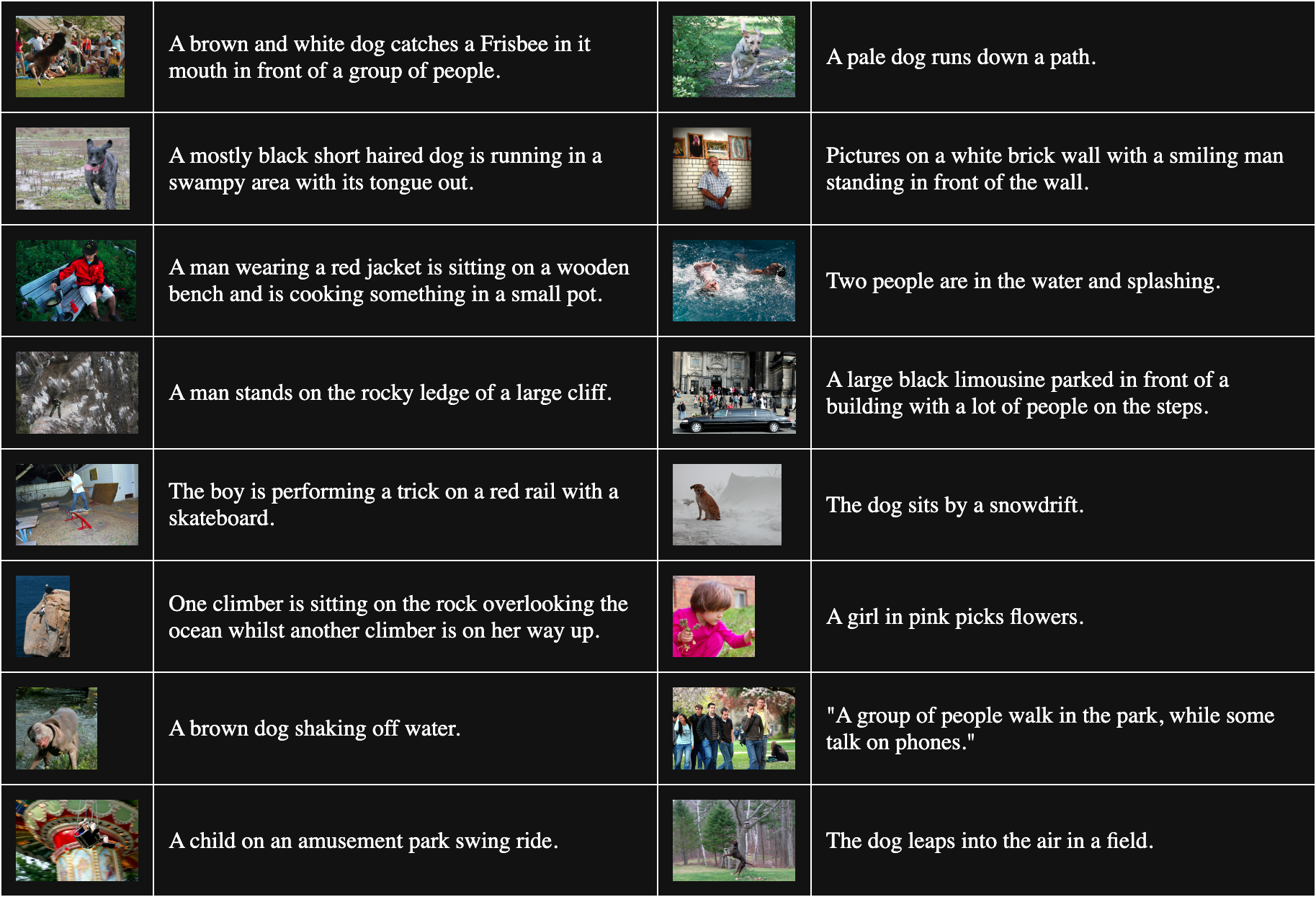
Pour obtenir des paires non correspondantes, nous combinons chaque image du lot avec tous les textes autres que celui qui lui correspond. Par exemple, la paire suivante est une image et un texte non correspondants :

Légende : Une fille en rose cueille des fleurs.
Mais cette procédure suppose que tous les textes correspondant à d'autres images sont également de mauvaises correspondances. Ce n'est pas toujours vrai. Par exemple :

Légende : Le chien est assis près d'un banc de neige.
Bien que le texte ne décrive pas cette image, ils ont un chien en commun. Traiter cette paire comme non correspondante aura tendance à éloigner le mot "chien" de toute image de chien.
Liang et al. [2022] montrent que ces paires non correspondantes imparfaites poussent toutes les images et les textes à s'éloigner les uns des autres.
Nous avons entrepris de vérifier leur affirmation avec un modèle d'image vit-b-32 entièrement initialisé aléatoirement et un modèle de texte JinaBERT v2 similairement randomisé, avec une température d'entraînement constante fixée à 0,02 (une température modérément basse). Nous avons construit deux ensembles de données d'entraînement :
- Un avec des lots aléatoires tirés de Flickr8k, avec des paires non correspondantes construites comme décrit ci-dessus.
- Un où les lots sont intentionnellement construits avec plusieurs copies de la même image avec différents textes dans chaque lot. Cela garantit qu'un nombre significatif de paires "non correspondantes" sont en fait des correspondances correctes les unes pour les autres.
Nous avons ensuite entraîné deux modèles pendant une époque, un avec chaque jeu de données d'entraînement, et mesuré la distance cosinus moyenne entre 1 000 paires texte-image dans le jeu de données Flickr8k pour chaque modèle. Le modèle entraîné avec des lots aléatoires avait une distance cosinus moyenne de 0,7521, tandis que celui entraîné avec beaucoup de paires "non correspondantes" intentionnellement correspondantes avait une distance cosinus moyenne de 0,7840. L'effet des paires "non correspondantes" incorrectes est assez significatif. Étant donné que l'entraînement réel du modèle est beaucoup plus long et utilise beaucoup plus de données, nous pouvons voir comment cet effet grandirait et accentuerait l'écart entre les images et les textes dans leur ensemble.
tagLe medium est le message
Le théoricien canadien des communications Marshall McLuhan a inventé l'expression "Le medium est le message" dans son livre de 1964 Understanding Media: The Extensions of Man pour souligner que les messages ne sont pas autonomes. Ils nous parviennent dans un contexte qui affecte fortement leur signification, et il affirmait célèbrement que l'une des parties les plus importantes de ce contexte est la nature du medium de communication.
L'écart multimodal nous offre une opportunité unique d'étudier une classe de phénomènes sémantiques émergents dans les modèles d'IA. Personne n'a dit à Jina CLIP d'encoder le support des données sur lesquelles il a été entraîné — il l'a fait de lui-même. Même si nous n'avons pas résolu le problème pour les modèles multimodaux, nous avons au moins une bonne compréhension théorique de l'origine du problème.
Nous devrions supposer que nos modèles encodent d'autres choses que nous n'avons pas encore recherchées en raison du même type de biais. Par exemple, nous avons probablement le même problème dans les modèles d'embedding multilingues. L'entraînement conjoint sur deux langues ou plus conduit probablement au même écart entre les langues, d'autant plus que des méthodes d'entraînement similaires sont largement utilisées. Les solutions au problème de l'écart peuvent avoir des implications très larges.
Une investigation sur le biais d'initialisation dans un plus large éventail de modèles mènera probablement aussi à de nouvelles découvertes. Si le support est le message pour un modèle d'embedding, qui sait quoi d'autre est encodé dans nos modèles à notre insu ?
