


Un dimanche soir. Vous cliquez sur "publier" pour cet article dans lequel vous avez mis tout votre cœur tout le week-end. Chaque mot, chaque idée - uniquement les vôtres. Quelques "j'aime" commencent à apparaître. Pas viral, mais c'est le vôtre.
Trois jours plus tard, en faisant défiler votre fil d'actualité, vous le voyez : L'âme de votre article dans le corps de quelqu'un d'autre ! Ils ont réarrangé les mots, mais vous reconnaissez votre propre création. Le pire ? Leur version est partout, un succès viral construit sur votre créativité volée. Ce n'est pas l'économie créative pour laquelle nous avons signé.
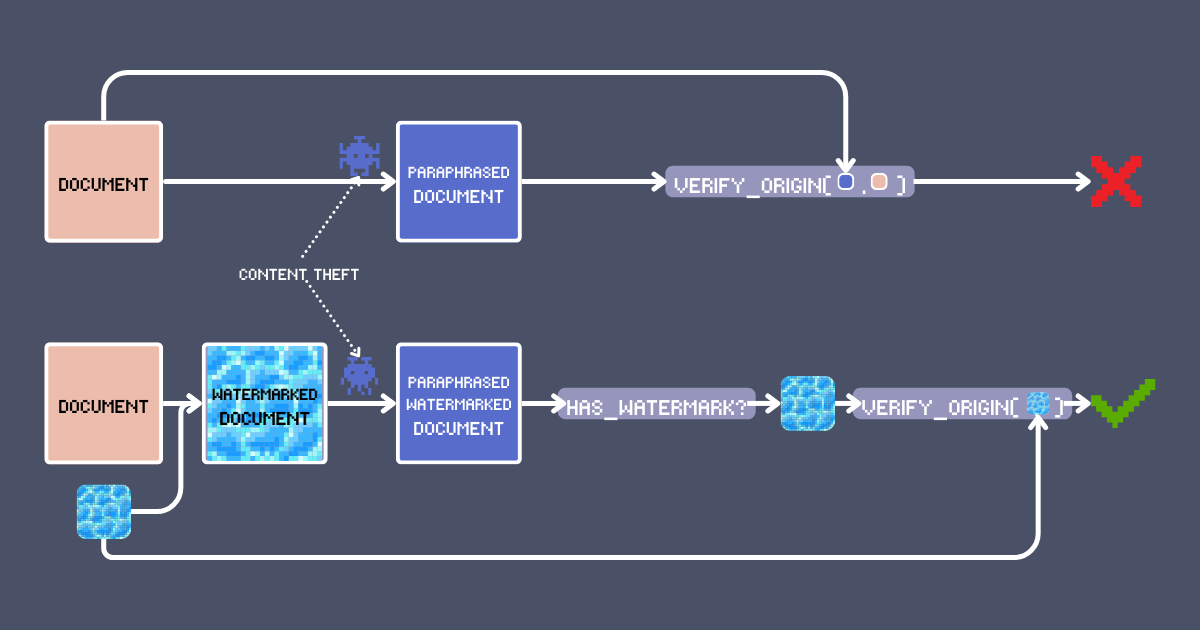
La solution évidente est d'apposer votre nom sur votre travail. Mais soyons honnêtes - c'est aussi la chose la plus facile à supprimer. Pouvons-nous faire mieux ? Dans cet article, nous allons vous montrer une technique de filigrane utilisant des modèles d'embedding qui peut à la fois signer et détecter le contenu original. Ce n'est pas qu'un autre cliché de recherche/RAG - il exploite les caractéristiques uniques de jina-embeddings-v3 comme le contexte long et l'alignement multilingue pour créer un système d'authentification robuste, et nous permet de maintenir une vérification fiable du contenu à travers les transformations comme la paraphrase par LLM ou même la traduction.
tagComprendre les Filigranes de Texte
Les filigranes numériques sont depuis des années une pierre angulaire de la protection du contenu. Quand vous trouvez un mème avec un logo semi-transparent superposé, vous voyez la forme la plus basique de filigrane d'image. Les techniques modernes de filigrane ont largement évolué au-delà des simples superpositions visuelles – beaucoup sont maintenant imperceptibles pour les lecteurs humains tout en restant lisibles par la machine.
Le filigrane de texte suit des principes similaires mais opère dans l'espace sémantique. Au lieu de modifier les pixels, un filigrane de texte modifie subtilement le contenu de manière à préserver le sens original tout en intégrant une signature détectable. Ainsi, les exigences clés pour un filigrane de texte efficace sont :
- Préservation sémantique : Le texte filigrané doit maintenir son sens original et sa lisibilité, tout comme un filigrane visuel ne devrait pas masquer les éléments clés d'une image.
- Imperceptibilité : Le filigrane doit être imperceptible pour les lecteurs humains, garantissant qu'ils ne peuvent pas intentionnellement le préserver ou le supprimer lors de la transformation du contenu.
- Détectable par machine : Bien que le filigrane puisse être subtil pour les lecteurs humains, il doit créer des motifs clairs et mesurables que les algorithmes peuvent identifier de manière fiable.
- Invariant aux transformations : Toute transformation du contenu (comme la paraphrase ou la traduction), qu'elle soit intentionnelle ou non consciente de l'existence du filigrane, doit soit préserver le filigrane, soit nécessiter des changements si substantiels qu'ils altèrent fondamentalement la structure ou le sens du contenu original.
tagUtilisation des Embeddings pour le Filigrane de Texte
Construisons un système de filigrane de texte utilisant les embeddings. D'abord, définissons les composants clés de ce système :
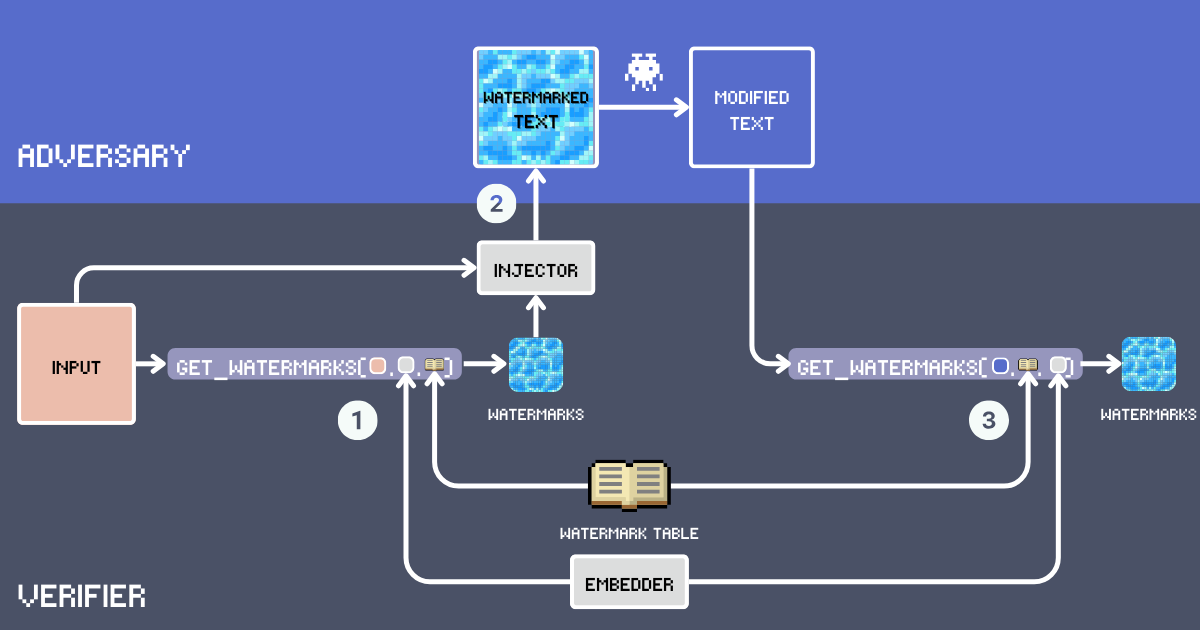
- Input : Le texte original à filigraner.
- Table de Filigranes : Un lexique secret contenant des mots candidats pour le filigrane. Pour une efficacité optimale du filigrane, les mots doivent être suffisamment courants pour s'intégrer naturellement dans divers contextes. Le vocabulaire exclut les mots fonctionnels, les noms propres et les mots rares qui pourraient sembler déplacés, par exemple
delve into,embarksont de bons candidats tandis quegoodest trop commun. Ci-dessous, nous construirons notre WatermarkTable en utilisant des mots du vocabulaire anglais avancé. - Embedder : Un modèle d'embedding qui sert deux objectifs : il sélectionne des mots sémantiquement appropriés de la
WatermarkTablebasés sur le texteinputet aide à détecter les filigranes dans le texte potentiellement paraphrasé. Nous utilisons jina-embeddings-v3 car il gère très bien les textes très longs et différentes langues. Cela signifie que nous pouvons filigraner de longs documents et attraper les copieurs même s'ils traduisent le texte. - Filigranes : Mots sélectionnés dans la WatermarkTable en calculant la similarité cosinus entre l'embedding du texte d'entrée et les embeddings dans la table. Le nombre de mots est déterminé par un ratio d'insertion, typiquement 12% du nombre de mots d'entrée.
- Injecteur : Un LLM suivant des instructions qui intègre les mots du filigrane dans le texte d'entrée tout en maintenant la cohérence, l'exactitude factuelle, le flux naturel et une distribution uniforme des mots du filigrane dans le texte.
- Texte Filigrané : La sortie après que l'Injecteur a inséré les mots du filigrane dans l'
input. - Adversaire (Vol de Contenu) : Une entité qui tente de réutiliser le texte filigrané sans attribution, typiquement par paraphrase, traduction ou modifications mineures. Aujourd'hui, cela signifie simplement utiliser un LLM invité avec
Paraphrase [text]pour la réécriture automatisée. - Texte Modifié : Le résultat après les modifications de l'adversaire sur le texte filigrané. C'est le texte que nous devons vérifier pour les filigranes.
tagAlgorithme


tagConclusion
À partir de ces exemples, nous pouvons constater que notre filigrane basé sur les embeddings est très robuste, même avec cette configuration de base. Ce qui est particulièrement remarquable, c'est que les filigranes restent détectables même après la traduction. Cette robustesse entre les langues est rendue possible grâce aux puissantes capacités multilingues du modèle jina-embeddings-v3 ; sans de solides capacités multilingues et inter-langues, une telle persistance à travers la traduction ne serait pas réalisable.
Il existe plusieurs façons d'améliorer la précision et la robustesse de ce système de filigrane. Tout d'abord, la table des filigranes pourrait être élargie et soigneusement construite pour assurer la diversité. C'est important car un vocabulaire plus large et plus diversifié offre une meilleure couverture des espaces sémantiques, facilitant ainsi la recherche de filigranes contextuellement appropriés pour n'importe quel texte tout en réduisant le risque de motifs répétitifs ou évidents.
Le composant Injector pourrait être amélioré en implémentant des stratégies d'insertion plus sophistiquées. Par exemple, il pourrait être programmé pour distribuer les filigranes uniformément dans le texte afin de maintenir leur imperceptibilité. De plus, nous pourrions utiliser la technique de late chunking pour générer des filigranes pour des segments ou des phrases individuels, permettant à l'Injector de prendre des décisions plus nuancées sur le placement des filigranes. Cela aiderait à maintenir à la fois l'imperceptibilité globale et la cohérence sémantique dans le texte final.
Pour les lecteurs intéressés par une exploration plus approfondie, "POSTMARK : A Robust Blackbox Watermark for Large Language Models" (Chang et al., EMNLP 2024) présente un cadre complet incluant des formulations mathématiques et des expériences approfondies. Les auteurs explorent systématiquement la construction du vocabulaire de filigrane, les stratégies d'insertion optimales et la robustesse face à diverses attaques. Ils analysent également en profondeur le compromis entre la détection du filigrane et la qualité du texte grâce à des évaluations automatisées et humaines.
