

Le chunking d'un long document présente deux problèmes : premièrement, déterminer les points de rupture—c'est-à-dire comment segmenter le document. Vous pouvez envisager des longueurs fixes de tokens, un nombre fixe de phrases, ou des techniques plus avancées comme regex ou des modèles de segmentation sémantique. Des limites de chunks précises améliorent non seulement la lisibilité des résultats de recherche, mais garantissent aussi que les chunks fournis à un LLM dans un système RAG sont précis et suffisants—ni plus, ni moins.
Le second problème est la perte de contexte dans chaque chunk. Une fois le document segmenté, l'étape logique suivante pour la plupart des gens est d'encoder chaque chunk séparément dans un processus par lots. Cependant, cela conduit à une perte du contexte global du document original. De nombreux travaux antérieurs ont d'abord abordé le premier problème, soutenant qu'une meilleure détection des limites améliore la représentation sémantique. Par exemple, le "chunking sémantique" regroupe les phrases ayant une similarité cosinus élevée dans l'espace d'embedding pour minimiser la perturbation des unités sémantiques.
De notre point de vue, ces deux problèmes sont presque orthogonaux et peuvent être traités séparément. Si nous devions établir une priorité, nous dirions que le 2ème problème est plus critique.
| Problème 2 : Information contextuelle | |||
|---|---|---|---|
| Préservée | Perdue | ||
| Problème 1 : Points de rupture | Bons | Scénario idéal | Mauvais résultats de recherche |
| Mauvais | Bons résultats de recherche, mais les résultats peuvent ne pas être lisibles par l'humain ou pour le raisonnement LLM | Pire scénario |
tagLate Chunking pour la Perte de Contexte
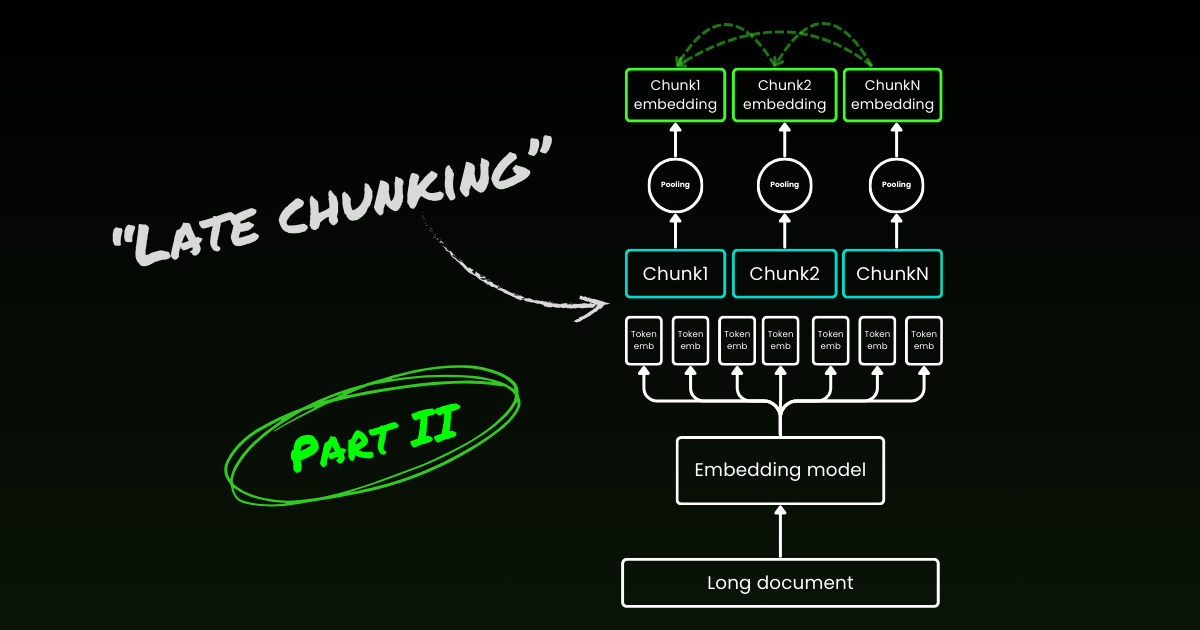
Le late chunking commence par aborder le second problème : la perte de contexte. Il ne s'agit pas de trouver les points de rupture ou les frontières sémantiques idéaux. Vous devez toujours utiliser regex, des heuristiques ou d'autres techniques pour diviser un long document en petits chunks. Mais au lieu d'encoder chaque chunk dès qu'il est segmenté, le late chunking encode d'abord l'ensemble du document dans une fenêtre de contexte (pour jina-embeddings-v3 c'est 8192 tokens). Ensuite, il suit les indices de frontière pour appliquer le mean pooling pour chaque chunk—d'où le terme "late" dans late chunking.

tagLe Late Chunking est Résistant aux Mauvais Indices de Frontière
Ce qui est vraiment intéressant, c'est que les expériences montrent que le late chunking élimine le besoin de frontières sémantiques parfaites, ce qui résout partiellement le premier problème mentionné ci-dessus. En fait, le late chunking appliqué aux frontières de tokens fixes surpasse le chunking naïf avec des indices de frontière sémantique. Les modèles de segmentation simples, comme ceux utilisant des frontières de longueur fixe, fonctionnent aussi bien que les algorithmes avancés de détection de frontières lorsqu'ils sont associés au late chunking. Nous avons testé trois tailles différentes de modèles d'embedding, et les résultats montrent qu'ils bénéficient tous constamment du late chunking sur tous les jeux de données de test. Cela dit, le modèle d'embedding lui-même reste le facteur le plus significatif dans la performance—il n'y a pas un seul cas où un modèle plus faible avec late chunking surpasse un modèle plus fort sans lui.

jina-embeddings-v2-small avec des indices de frontière de longueur de token fixe et chunking naïf). Dans le cadre d'une étude d'ablation, nous avons testé le late chunking avec différents indices de frontière (longueur de token fixe, frontières de phrases et frontières sémantiques) et différents modèles (jina-embeddings-v2-small, nomic-v1, et jina-embeddings-v3). Basé sur leurs performances sur MTEB, le classement de ces trois modèles d'embedding est : jina-embeddings-v2-small < nomic-v1 < jina-embeddings-v3. Cependant, l'objectif de cette expérience n'est pas d'évaluer la performance des modèles d'embedding eux-mêmes, mais de comprendre comment un meilleur modèle d'embedding interagit avec le late chunking et les indices de frontière. Pour les détails de l'expérience, veuillez consulter notre article de recherche.| Combo | SciFact | NFCorpus | FiQA | TRECCOVID |
|---|---|---|---|---|
| Baseline | 64.2 | 23.5 | 33.3 | 63.4 |
| Late | 66.1 | 30.0 | 33.8 | 64.7 |
| Nomic | 70.7 | 35.3 | 37.0 | 72.9 |
| Jv3 | 71.8 | 35.6 | 46.3 | 73.0 |
| Late + Nomic | 70.6 | 35.3 | 38.3 | 75.0 |
| Late + Jv3 | 73.2 | 36.7 | 47.6 | 77.2 |
| SentBound | 64.7 | 28.3 | 30.4 | 66.5 |
| Late + SentBound | 65.2 | 30.0 | 33.9 | 66.6 |
| Nomic + SentBound | 70.4 | 35.3 | 34.8 | 74.3 |
| Jv3 + SentBound | 71.4 | 35.8 | 43.7 | 72.4 |
| Late + Nomic + SentBound | 70.5 | 35.3 | 36.9 | 76.1 |
| Late + Jv3 + SentBound | 72.4 | 36.6 | 47.6 | 76.2 |
| SemanticBound | 64.3 | 27.4 | 30.3 | 66.2 |
| Late + SemanticBound | 65.0 | 29.3 | 33.7 | 66.3 |
| Nomic + SemanticBound | 70.4 | 35.3 | 34.8 | 74.3 |
| Jv3 + SemanticBound | 71.2 | 36.1 | 44.0 | 74.7 |
| Late + Nomic + SemanticBound | 70.5 | 36.9 | 36.9 | 76.1 |
| Late + Jv3 + SemanticBound | 72.4 | 36.6 | 47.6 | 76.2 |
Notez que le fait d'être résistant aux mauvaises frontières ne signifie pas qu'on peut les ignorer — elles restent importantes pour la lisibilité humaine et celle des LLM. Voici notre point de vue : lors de l'optimisation de la segmentation, c'est-à-dire le 1er problème mentionné précédemment, nous pouvons nous concentrer entièrement sur la lisibilité sans nous soucier de la perte sémantique/contextuelle. Le Late Chunking gère bien ou mal les points de rupture, donc la lisibilité est la seule chose dont vous devez vous soucier.
tagLe Late Chunking est Bidirectionnel
Une autre idée fausse courante concernant le late chunking est que ses embeddings de chunks conditionnels ne dépendent que des chunks précédents sans "regarder en avant". C'est incorrect. La dépendance conditionnelle dans le late chunking est en réalité bidirectionnelle, et non unidirectionnelle. Cela est dû au fait que la matrice d'attention dans le modèle d'embedding — un transformeur encodeur seul — est entièrement connectée, contrairement à la matrice triangulaire masquée utilisée dans les modèles auto-régressifs. Formellement, l'embedding du chunk , , plutôt que , où désigne une factorisation du modèle de langage. Cela explique également pourquoi le late chunking ne dépend pas d'un placement précis des frontières.

tagLe Late Chunking peut être Entraîné
Le late chunking ne nécessite pas d'entraînement supplémentaire pour les modèles d'embedding. Il peut être appliqué à n'importe quel modèle d'embedding à contexte long utilisant le mean pooling, ce qui le rend très attractif pour les praticiens. Cela dit, si vous travaillez sur des tâches comme la question-réponse ou la recherche document-requête, les performances peuvent encore être améliorées avec un peu de fine-tuning. Plus précisément, les données d'entraînement se composent de tuples contenant :
- Une requête (par exemple, une question ou un terme de recherche).
- Un document qui contient des informations pertinentes pour répondre à la requête.
- Un segment pertinent dans le document, qui est la partie spécifique du texte qui répond directement à la requête.
Le modèle est entraîné en associant les requêtes à leurs segments pertinents, en utilisant une fonction de perte contrastive comme InfoNCE. Cela garantit que les segments pertinents sont étroitement alignés avec la requête dans l'espace des embeddings, tandis que les segments non liés sont repoussés plus loin. Ainsi, le modèle apprend à se concentrer sur les parties les plus pertinentes du document lors de la génération des embeddings de chunks. Pour plus de détails, veuillez consulter notre article de recherche.
tagLate Chunking vs. Recherche Contextuelle
Peu après l'introduction du late chunking, Anthropic a introduit une stratégie distincte appelée Recherche Contextuelle. La méthode d'Anthropic est une approche force brute pour résoudre le problème de la perte de contexte, et fonctionne comme suit :
- Chaque chunk est envoyé au LLM avec le document complet.
- Le LLM ajoute du contexte pertinent à chaque chunk.
- Cela résulte en des embeddings plus riches et plus informatifs.
Selon nous, il s'agit essentiellement d'un enrichissement de contexte, où le contexte global est explicitement codé en dur dans chaque chunk en utilisant un LLM, ce qui est coûteux en termes de coût, de temps et de stockage. De plus, il n'est pas certain que cette approche soit résistante aux frontières de chunks, car le LLM s'appuie sur des chunks précis et lisibles pour enrichir efficacement le contexte. En revanche, le late chunking est très résistant aux indices de frontière, comme démontré ci-dessus. Il ne nécessite pas de stockage supplémentaire puisque la taille de l'embedding reste la même. Bien qu'il exploite la longueur de contexte complète du modèle d'embedding, il reste significativement plus rapide que l'utilisation d'un LLM pour générer l'enrichissement. Dans l'étude qualitative de notre article de recherche, nous montrons que la recherche contextuelle d'Anthropic offre des performances similaires au late chunking. Cependant, le late chunking fournit une solution plus bas niveau, générique et naturelle en exploitant les mécaniques inhérentes du transformeur encodeur seul.
tagQuels Modèles d'Embedding Supportent le Late Chunking ?
Le late chunking n'est pas exclusif à jina-embeddings-v3 ou v2. C'est une approche assez générique qui peut être appliquée à n'importe quel modèle d'embedding à contexte long utilisant le mean pooling. Par exemple, dans cet article, nous montrons que nomic-v1 le supporte également. Nous encourageons vivement tous les fournisseurs d'embedding à implémenter le support du late chunking dans leurs solutions.
En tant qu'utilisateur de modèle, lorsque vous évaluez un nouveau modèle ou une nouvelle API d'embedding, vous pouvez suivre ces étapes pour vérifier s'il pourrait supporter le late chunking :
- Sortie unique : Le modèle/API ne vous donne-t-il qu'un seul embedding final par phrase au lieu d'embeddings au niveau des tokens ? Si oui, il ne pourra probablement pas prendre en charge le chunking tardif (en particulier pour les API web).
- Support des longs contextes : Le modèle/API gère-t-il des contextes d'au moins 8192 tokens ? Si non, le chunking tardif ne sera pas applicable — ou plus précisément, cela n'a pas de sens d'adapter le chunking tardif pour un modèle à contexte court. Si oui, assurez-vous qu'il fonctionne réellement bien avec les longs contextes, et pas seulement qu'il prétend les supporter. Vous pouvez généralement trouver ces informations dans le rapport technique du modèle, comme les évaluations sur LongMTEB ou d'autres benchmarks de longs contextes.
- Mean Pooling : Pour les modèles auto-hébergés ou les API qui fournissent des embeddings au niveau des tokens avant le pooling, vérifiez si la méthode de pooling par défaut est le mean pooling. Les modèles utilisant CLS ou max pooling ne sont pas compatibles avec le chunking tardif.
En résumé, si un modèle d'embedding supporte les longs contextes et utilise le mean pooling par défaut, il peut facilement prendre en charge le chunking tardif. Consultez notre dépôt GitHub pour les détails d'implémentation et plus de discussions.
tagConclusion
Alors, qu'est-ce que le chunking tardif ? Le chunking tardif est une méthode simple pour générer des embeddings de chunks en utilisant des modèles d'embedding à long contexte. C'est rapide, résistant aux indices de frontière et très efficace. Ce n'est pas une heuristique ou du sur-engineering — c'est une conception réfléchie ancrée dans une compréhension approfondie du mécanisme transformer.
Aujourd'hui, l'engouement autour des LLM est indéniable. Dans de nombreux cas, des problèmes qui pourraient être efficacement traités par des modèles plus petits comme BERT sont plutôt confiés aux LLM, motivés par l'attrait de solutions plus grandes et plus complexes. Il n'est pas surprenant que les grands fournisseurs de LLM poussent à une plus grande adoption de leurs modèles, tandis que les fournisseurs d'embeddings défendent les embeddings — les deux jouent sur leurs forces commerciales. Mais au final, ce n'est pas une question d'engouement, c'est une question d'action, de ce qui fonctionne vraiment. Laissons la communauté, l'industrie et, surtout, le temps révéler quelle approche est vraiment plus légère, plus efficace et construite pour durer.
Assurez-vous de lire notre article de recherche, et nous vous encourageons à tester le chunking tardif dans divers scénarios et à partager vos retours avec nous.
