

Ci sono molte barriere alla comprensione dei modelli AI, alcune piuttosto significative, che possono ostacolare l'implementazione dei processi AI. Ma la prima che molte persone incontrano è capire cosa intendiamo quando parliamo di token.

Uno dei parametri pratici più importanti nella scelta di un modello linguistico AI è la dimensione della sua finestra di contesto — la dimensione massima del testo in input — che viene espressa in token, non in parole o caratteri o altre unità automaticamente riconoscibili.
Inoltre, i servizi di embedding sono tipicamente calcolati "per token", il che significa che i token sono importanti per comprendere la fattura.
Questo può essere molto confuso se non si ha chiaro cosa sia un token.
Ma tra tutti gli aspetti confusi dell'AI moderna, i token sono probabilmente i meno complicati. Questo articolo cercherà di chiarire cosa sia la tokenizzazione, cosa fa e perché la facciamo in questo modo.
tagtl;dr
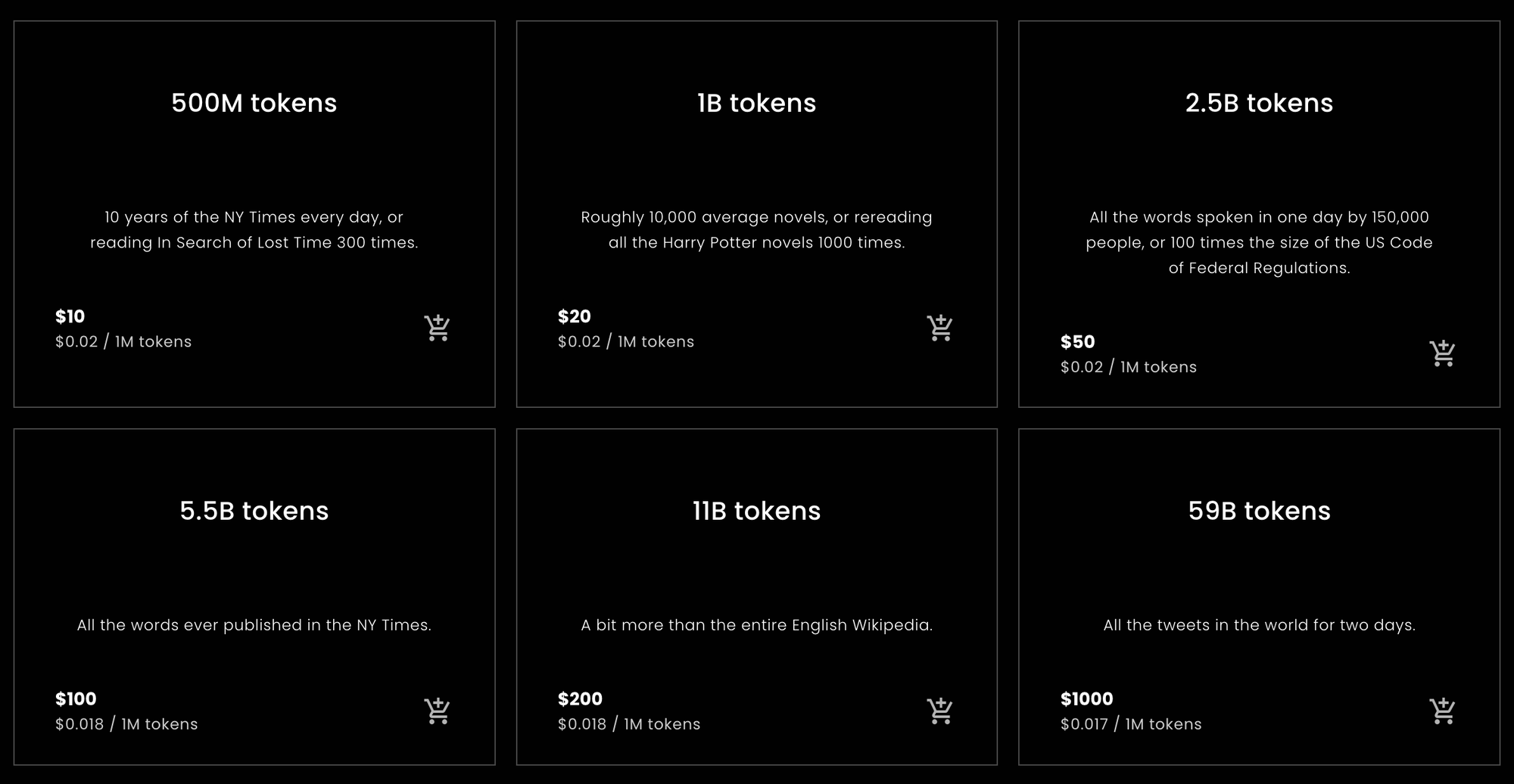
Per coloro che desiderano o necessitano di una risposta rapida per calcolare quanti token acquistare da Jina Embeddings o una stima di quanti prevedono di dover acquistare, ecco le statistiche che state cercando.
tagToken per Parola Inglese
Durante i test empirici, descritti più avanti in questo articolo, una varietà di testi in inglese è stata convertita in token con un rapporto di circa il 10% in più di token rispetto alle parole, utilizzando i modelli solo inglese di Jina Embeddings. Questo risultato è stato piuttosto robusto.
I modelli Jina Embeddings v2 hanno una finestra di contesto di 8192 token. Questo significa che se passi a un modello Jina un testo in inglese più lungo di 7.400 parole, c'è una buona probabilità che venga troncato.
tagToken per Carattere Cinese
Per il cinese, i risultati sono più variabili. A seconda del tipo di testo, i rapporti variano da 0,6 a 0,75 token per carattere cinese (汉字). I testi in inglese dati a Jina Embeddings v2 per il cinese producono approssimativamente lo stesso numero di token di Jina Embeddings v2 per l'inglese: circa il 10% in più rispetto al numero di parole.
tagToken per Parola Tedesca
I rapporti parola-token in tedesco sono più variabili rispetto all'inglese ma meno del cinese. A seconda del genere del testo, ho ottenuto in media dal 20% al 30% in più di token rispetto alle parole. Dare testi in inglese a Jina Embeddings v2 per tedesco e inglese usa alcuni token in più rispetto ai modelli solo inglese e cinese/inglese: dal 12% al 15% in più di token rispetto alle parole.
tagAttenzione!
Questi sono calcoli semplici, ma dovrebbero essere approssimativamente corretti per la maggior parte dei testi in linguaggio naturale e per la maggior parte degli utenti. In definitiva, possiamo solo promettere che il numero di token sarà sempre non superiore al numero di caratteri nel tuo testo, più due. In pratica sarà sempre molto meno di quello, ma non possiamo promettere in anticipo alcun conteggio specifico.
Queste sono stime basate su calcoli statisticamente ingenui. Non garantiamo quanti token richiederà una particolare richiesta.
Se ti serve solo un consiglio su quanti token acquistare per Jina Embeddings, puoi fermarti qui. Altri modelli di embedding, di aziende diverse da Jina AI, potrebbero non avere gli stessi rapporti token-parola e token-carattere-cinese dei modelli Jina, ma in generale non saranno molto diversi.
Se vuoi capire il perché, il resto di questo articolo è un'analisi più approfondita della tokenizzazione per i modelli linguistici.
tagParole, Token, Numeri
La tokenizzazione fa parte dell'elaborazione del linguaggio naturale da prima che esistessero i moderni modelli AI.
È un po' un cliché dire che tutto in un computer è solo un numero, ma è anche per lo più vero. Il linguaggio, tuttavia, non è naturalmente solo un insieme di numeri. Potrebbe essere parlato, composto da onde sonore, o scritto, fatto di segni su carta, o anche un'immagine di un testo stampato o un video di qualcuno che usa il linguaggio dei segni. Ma la maggior parte delle volte, quando parliamo di usare i computer per elaborare il linguaggio naturale, intendiamo testi composti da sequenze di caratteri: lettere (a, b, c, ecc.), numeri (0, 1, 2…), punteggiatura e spazi, in diverse lingue e codifiche testuali.
Gli ingegneri informatici le chiamano "stringhe".
I modelli linguistici AI prendono sequenze di numeri come input. Quindi, potresti scrivere la frase:
What is today's weather in Berlin?
Ma, dopo la tokenizzazione, il modello AI riceve come input:
[101, 2054, 2003, 2651, 1005, 1055, 4633, 1999, 4068, 1029, 102]
La tokenizzazione è il processo di conversione di una stringa di input in una specifica sequenza di numeri che il tuo modello AI può comprendere.
Quando usi un modello AI tramite un'API web che addebita agli utenti per token, ogni richiesta viene convertita in una sequenza di numeri come quella sopra. Il numero di token nella richiesta è la lunghezza di quella sequenza di numeri. Quindi, chiedere a Jina Embeddings v2 for English di darti un embedding per "What is today's weather in Berlin?" ti costerà 11 token perché ha convertito quella frase in una sequenza di 11 numeri prima di passarla al modello AI.
I modelli AI basati sull'architettura Transformer hanno una finestra di contesto di dimensione fissa misurata in token. A volte viene chiamata "finestra di input", "dimensione del contesto" o "lunghezza della sequenza" (specialmente sulla classifica MTEB di Hugging Face). Significa la dimensione massima del testo che il modello può vedere in una volta.
Quindi, se vuoi usare un modello di embedding, questa è la dimensione massima di input consentita.
I modelli Jina Embeddings v2 hanno tutti una finestra di contesto di 8.192 token. Altri modelli avranno finestre di contesto diverse (tipicamente più piccole). Questo significa che qualunque sia la quantità di testo che inserisci, il tokenizer associato a quel modello Jina Embeddings deve convertirlo in non più di 8.192 token.
tagMappare il Linguaggio in Numeri
Il modo più semplice per spiegare la logica dei token è questo:
Per i modelli di linguaggio naturale, la parte di stringa che un token rappresenta è una parola, una parte di una parola o un pezzo di punteggiatura. Gli spazi generalmente non ricevono alcuna rappresentazione esplicita nell'output del tokenizer.
La tokenizzazione fa parte di un gruppo di tecniche nell'elaborazione del linguaggio naturale chiamate segmentazione del testo, e il modulo che esegue la tokenizzazione è chiamato, molto logicamente, tokenizer.
Per mostrare come funziona la tokenizzazione, tokenizzeremo alcune frasi usando il più piccolo modello Jina Embeddings v2 per l'inglese: jina-embeddings-v2-small-en. L'altro modello solo inglese di Jina Embeddings — jina-embeddings-v2-base-en — usa lo stesso tokenizer, quindi non ha senso scaricare megabyte extra di modello AI che non useremo in questo articolo.
Prima, installa il modulo transformers nel tuo ambiente Python o notebook. Usa ilIl flag -U assicura l'aggiornamento all'ultima versione poiché questo modello non funzionerà con alcune versioni precedenti:
pip install -U transformers
Quindi, scarica jina-embeddings-v2-small-en usando AutoModel.from_pretrained:
from transformers import AutoModel
model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-small-en', trust_remote_code=True)
Per tokenizzare una stringa, usa il metodo encode dell'oggetto tokenizer del modello:
model.tokenizer.encode("What is today's weather in Berlin?")
Il risultato è una lista di numeri:
[101, 2054, 2003, 2651, 1005, 1055, 4633, 1999, 4068, 1029, 102]
Per convertire questi numeri in forma di stringa, usa il metodo convert_ids_to_tokens dell'oggetto tokenizer:
model.tokenizer.convert_ids_to_tokens([101, 2054, 2003, 2651, 1005, 1055, 4633, 1999, 4068, 1029, 102])
Il risultato è una lista di stringhe:
['[CLS]', 'what', 'is', 'today', "'", 's', 'weather', 'in',
'berlin', '?', '[SEP]']
Nota che il tokenizer del modello ha:
- Aggiunto
[CLS]all'inizio e[SEP]alla fine. Questo è necessario per ragioni tecniche e significa che ogni richiesta di embedding costerà due token extra, oltre a qualsiasi numero di token richieda il testo. - Separato la punteggiatura dalle parole, trasformando "Berlin?" in:
berline?, e "today's" intoday,', es. - Messo tutto in minuscolo. Non tutti i modelli lo fanno, ma questo può aiutare durante l'addestramento quando si usa l'inglese. Potrebbe essere meno utile in lingue dove la capitalizzazione ha un significato diverso.
Diversi algoritmi di conteggio parole in programmi diversi potrebbero contare le parole in questa frase in modo differente. OpenOffice la conta come sei parole. L'algoritmo di segmentazione del testo Unicode (Unicode Standard Annex #29) conta sette parole. Altri software potrebbero arrivare a numeri diversi, a seconda di come gestiscono la punteggiatura e i clitici come "'s".
Il tokenizer per questo modello produce nove token per quelle sei o sette parole, più i due token extra necessari per ogni richiesta.
Ora, proviamo con un nome di luogo meno comune di Berlino:
token_ids = model.tokenizer.encode("I live in Kinshasa.")
tokens = model.tokenizer.convert_ids_to_tokens(token_ids)
print(tokens)
Il risultato:
['[CLS]', 'i', 'live', 'in', 'kin', '##sha', '##sa', '.', '[SEP]']
Il nome "Kinshasa" è diviso in tre token: kin, ##sha, e ##sa. Il ## indica che questo token non è l'inizio di una parola.
Se diamo al tokenizer qualcosa di completamente estraneo, il numero di token rispetto al numero di parole aumenta ancora di più:
token_ids = model.tokenizer.encode("Klaatu barada nikto")
tokens = model.tokenizer.convert_ids_to_tokens(token_ids)
print(tokens)
['[CLS]', 'k', '##la', '##at', '##u', 'bar', '##ada', 'nik', '##to', '[SEP]']
Tre parole diventano otto token, più i token [CLS] e [SEP].
La tokenizzazione in tedesco è simile. Con il modello Jina Embeddings v2 per il tedesco, possiamo tokenizzare una traduzione di "What is today's weather in Berlin?" allo stesso modo del modello inglese.
german_model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-de', trust_remote_code=True)
token_ids = german_model.tokenizer.encode("Wie wird das Wetter heute in Berlin?")
tokens = german_model.tokenizer.convert_ids_to_tokens(token_ids)
print(tokens)
Il risultato:
['<s>', 'Wie', 'wird', 'das', 'Wetter', 'heute', 'in', 'Berlin', '?', '</s>']
Questo tokenizer è leggermente diverso da quello inglese in quanto <s> e </s> sostituiscono [CLS] e [SEP] ma svolgono la stessa funzione. Inoltre, il testo non viene normalizzato in maiuscole/minuscole - maiuscole e minuscole rimangono come scritte - perché in tedesco la capitalizzazione ha un significato diverso rispetto all'inglese.
(Per semplificare questa presentazione, ho rimosso un carattere speciale che indica l'inizio di una parola.)
Ora, proviamo con una frase più complessa da un testo giornalistico:
Ein Großteil der milliardenschweren Bauern-Subventionen bleibt liegen – zu genervt sind die Landwirte von bürokratischen Gängelungen und Regelwahn.
sentence = """
Ein Großteil der milliardenschweren Bauern-Subventionen
bleibt liegen – zu genervt sind die Landwirte von
bürokratischen Gängelungen und Regelwahn.
"""
token_ids = german_model.tokenizer.encode(sentence)
tokens = german_model.tokenizer.convert_ids_to_tokens(token_ids)
print(tokens)Il risultato tokenizzato:
['<s>', 'Ein', 'Großteil', 'der', 'mill', 'iarden', 'schwer',
'en', 'Bauern', '-', 'Sub', 'ventionen', 'bleibt', 'liegen',
'–', 'zu', 'gen', 'ervt', 'sind', 'die', 'Landwirte', 'von',
'büro', 'krat', 'ischen', 'Gän', 'gel', 'ungen', 'und', 'Regel',
'wahn', '.', '</s>']
Qui si vede che molte parole tedesche sono state suddivise in pezzi più piccoli e non necessariamente seguendo le regole grammaticali tedesche. Il risultato è che una parola tedesca lunga, che verrebbe contata come una sola parola da un contatore di parole, potrebbe corrispondere a un numero qualsiasi di token per il modello AI di Jina.
Facciamo lo stesso in cinese, traducendo "What is today's weather in Berlin?" come:
柏林今天的天气怎么样?
chinese_model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-zh', trust_remote_code=True)
token_ids = chinese_model.tokenizer.encode("柏林今天的天气怎么样?")
tokens = chinese_model.tokenizer.convert_ids_to_tokens(token_ids)
print(tokens)
Il risultato tokenizzato:
['<s>', '柏林', '今天的', '天气', '怎么样', '?', '</s>']
In cinese, solitamente non ci sono spazi tra le parole nel testo scritto, ma il tokenizer di Jina Embeddings frequentemente unisce più caratteri cinesi insieme:
| Token string | Pinyin | Significato |
|---|---|---|
| 柏林 | Bólín | Berlino |
| 今天的 | jīntiān de | di oggi |
| 天气 | tiānqì | tempo |
| 怎么样 | zěnmeyàng | come |
Usiamo una frase più complessa da un giornale di Hong Kong:
sentence = """
新規定執行首日,記者在下班高峰前的下午5時來到廣州地鐵3號線,
從繁忙的珠江新城站啟程,向機場北方向出發。
"""
token_ids = chinese_model.tokenizer.encode(sentence)
tokens = chinese_model.tokenizer.convert_ids_to_tokens(token_ids)
print(tokens)
(Traduzione: "Il primo giorno dell'entrata in vigore delle nuove norme, questo giornalista è arrivato alla Linea 3 della Metropolitana di Guangzhou alle 17:00, durante l'ora di punta, partendo dalla Stazione Zhujiang New Town in direzione nord verso l'aeroporto.")
Il risultato:
['<s>', '新', '規定', '執行', '首', '日', ',', '記者', '在下', '班',
'高峰', '前的', '下午', '5', '時', '來到', '廣州', '地', '鐵', '3',
'號', '線', ',', '從', '繁忙', '的', '珠江', '新城', '站', '啟',
'程', ',', '向', '機場', '北', '方向', '出發', '。', '</s>']
Questi token non corrispondono a nessun dizionario specifico di parole cinesi (词典). Per esempio, "啟程" - qǐchéng (partire, mettersi in viaggio) sarebbe tipicamente categorizzato come una singola parola ma qui è diviso nei suoi due caratteri costituenti. Similmente, "在下班" sarebbe normalmente riconosciuto come due parole, con la divisione tra "在" - zài (in, durante) e "下班" - xiàbān (fine della giornata lavorativa, ora di punta), non tra "在下" e "班" come ha fatto il tokenizer in questo caso.
In tutte e tre le lingue, i punti in cui il tokenizer divide il testo non sono direttamente correlati ai punti logici in cui un lettore umano li dividerebbe.
Questa non è una caratteristica specifica dei modelli Jina Embeddings. Questo approccio alla tokenizzazione è quasi universale nello sviluppo di modelli AI. Sebbene due diversi modelli AI possano non avere tokenizer identici, nello stato attuale dello sviluppo, praticamente tutti useranno tokenizer con questo tipo di comportamento.
La prossima sezione discuterà l'algoritmo specifico utilizzato nella tokenizzazione e la logica alla sua base.
tagPerché Tokenizziamo? E Perché in Questo Modo?
I modelli linguistici AI prendono in input sequenze di numeri che rappresentano sequenze di testo, ma succede qualcosa in più prima di eseguire la rete neurale sottostante e creare un embedding. Quando viene presentata una lista di numeri che rappresentano piccole sequenze di testo, il modello cerca ogni numero in un dizionario interno che memorizza un vettore unico per ogni numero. Poi li combina, e questo diventa l'input per la rete neurale.
Questo significa che il tokenizer deve essere in grado di convertire qualsiasi testo di input che gli diamo in token che appaiono nel dizionario dei vettori di token del modello. Se prendessimo i nostri token da un dizionario convenzionale, la prima volta che incontrassimo un errore di ortografia o un nome proprio raro o una parola straniera, l'intero modello si fermerebbe. Non potrebbe processare quell'input.
Nell'elaborazione del linguaggio naturale, questo è chiamato il problema del fuori-vocabolario (OOV), ed è pervasivo in tutti i tipi di testo e in tutte le lingue. Ci sono alcune strategie per affrontare il problema OOV:
- Ignorarlo. Sostituire tutto ciò che non è nel dizionario con un token "sconosciuto".
- Aggirarlo. Invece di usare un dizionario che mappa sequenze di testo a vettori, usarne uno che mappa singoli caratteri a vettori. L'inglese usa solo 26 lettere la maggior parte delle volte, quindi questo deve essere più piccolo e più robusto contro i problemi OOV rispetto a qualsiasi dizionario.
- Trovare sottosequenze frequenti nel testo, metterle nel dizionario e usare caratteri (token a singola lettera) per tutto il resto.
La prima strategia significa che molte informazioni importanti vengono perse. Il modello non può nemmeno imparare dai dati che ha visto se prendono la forma di qualcosa che non è nel dizionario. Molte cose nel testo ordinario non sono presenti nemmeno nei dizionari più grandi.
La seconda strategia è possibile, e i ricercatori l'hanno investigata. Tuttavia, significa che il modello deve accettare molti più input e deve imparare molto di più. Questo significa un modello molto più grande e molti più dati di addestramento per un risultato che non si è mai dimostrato migliore della terza strategia.
I modelli linguistici AI implementano praticamente tutti la terza strategia in qualche forma. La maggior parte usa qualche variante dell'algoritmo Wordpiece [Schuster e Nakajima 2012] o una tecnica simile chiamata Byte-Pair Encoding (BPE). [Gage 1994, Senrich et al. 2016] Questi algoritmi sono language-agnostic. Ciò significa che funzionano allo stesso modo per tutte le lingue scritte senza alcuna conoscenza oltre a un elenco completo dei possibili caratteri. Sono stati progettati per modelli multilingue come BERT di Google che prendono qualsiasi input dal web scraping - centinaia di lingue e testi diversi dal linguaggio umano come programmi per computer - in modo da poter essere addestrati senza fare linguistica complicata.
Alcune ricerche mostrano miglioramenti significativi utilizzando tokenizer più specifici e consapevoli della lingua. [Rust et al. 2021] Ma costruire tokenizer in questo modo richiede tempo, denaro e competenza. Implementare una strategia universale come BPE o Wordpiece è molto più economico e facile.
Tuttavia, di conseguenza, non c'è modo di sapere quanti token rappresenta un testo specifico se non facendolo passare attraverso un tokenizer e poi contando il numero di token che ne escono. Poiché la sottoseqeunza più piccola possibile di un testo è una lettera, si può essere sicuri che il numero di token non sarà maggiore del numero di caratteri (meno gli spazi) più due.
Per ottenere una buona stima, dobbiamo sottoporre molto testo al nostro tokenizer e calcolare empiricamente quanti token otteniamo in media, rispetto a quante parole o caratteri inseriamo. Nella prossima sezione, faremo alcune misurazioni empiriche non molto sistematiche per tutti i modelli Jina Embeddings v2 attualmente disponibili.
tagStime Empiriche delle Dimensioni di Output dei Token
Per l'inglese e il tedesco, ho utilizzato l'algoritmo di segmentazione del testo Unicode (Unicode Standard Annex #29) per ottenere il conteggio delle parole per i testi. Questo algoritmo è ampiamente utilizzato per selezionare frammenti di testo quando si fa doppio clic su qualcosa. È la cosa più vicina disponibile a un contatore di parole universale oggettivo.
Ho installato la libreria polyglot in Python, che implementa questo segmentatore di testo:
pip install -U polyglot
Per ottenere il conteggio delle parole di un testo, puoi utilizzare un codice come questo snippet:
from polyglot.text import Text
txt = "What is today's weather in Berlin?"
print(len(Text(txt).words))
Il risultato dovrebbe essere 7.
Per ottenere un conteggio dei token, segmenti del testo sono stati passati ai tokenizer di vari modelli Jina Embeddings, come descritto di seguito, e ogni volta, ho sottratto due dal numero di token restituiti.
tagInglese
(jina-embeddings-v2-small-en e jina-embeddings-v2-base-en)
Per calcolare le medie, ho scaricato due corpora di testo inglese da Wortschatz Leipzig, una collezione di corpora liberamente scaricabili in diverse lingue e configurazioni ospitata dall'Università di Leipzig:
- Un corpus di un milione di frasi di notizie in inglese del 2020 (
eng_news_2020_1M) - Un corpus di un milione di frasi da Wikipedia inglese del 2016 (
eng_wikipedia_2016_1M)
Entrambi si possono trovare sulla loro pagina di download inglese.
Per diversità, ho anche scaricato la traduzione di Hapgood de I Miserabili di Victor Hugo da Project Gutenberg, e una copia della Bibbia di Re Giacomo, tradotta in inglese nel 1611.
Per tutti e quattro i testi, ho contato le parole usando il segmentatore Unicode implementato in polyglot, poi ho contato i token creati da jina-embeddings-v2-small-en, sottraendo due token per ogni richiesta di tokenizzazione. I risultati sono i seguenti:
| Testo | Conteggio parole (Segmentatore Unicode) | Conteggio token (Jina Embeddings v2 per inglese) | Rapporto token/parole (a 3 decimali) |
|---|---|---|---|
eng_news_2020_1M | 22.825.712 | 25.270.581 | 1,107 |
eng_wikipedia_2016_1M | 24.243.607 | 26.813.877 | 1,106 |
les_miserables_en | 688.911 | 764.121 | 1,109 |
kjv_bible | 1.007.651 | 1.099.335 | 1,091 |
L'uso di numeri precisi non significa che questo sia un risultato preciso. Il fatto che documenti di generi così diversi abbiano tutti tra il 9% e l'11% di token in più rispetto alle parole indica che probabilmente ci si può aspettare circa il 10% di token in più rispetto alle parole, come misurato dal segmentatore Unicode. I word processor spesso non contano la punteggiatura, mentre il segmentatore Unicode lo fa, quindi non ci si può aspettare che il conteggio delle parole del software da ufficio corrisponda necessariamente a questo.
tagTedesco
(jina-embeddings-v2-base-de)
Per il tedesco, ho scaricato tre corpora dalla pagina tedesca di Wortschatz Leipzig:
deu_mixed-typical_2011_1M— Un milione di frasi da una miscela bilanciata di testi di diversi generi, risalenti al 2011.deu_newscrawl-public_2019_1M— Un milione di frasi di testo giornalistico del 2019.deu_wikipedia_2021_1M— Un milione di frasi estratte dalla Wikipedia tedesca nel 2021.
E per diversità, ho anche scaricato tutti e tre i volumi del Kapital di Karl Marx dal Deutsches Textarchiv.
Ho quindi seguito la stessa procedura utilizzata per l'inglese:
| Testo | Conteggio parole (Unicode Segmenter) | Conteggio token (Jina Embeddings v2 per tedesco e inglese) | Rapporto token/parole (a 3 decimali) |
|---|---|---|---|
deu_mixed-typical_2011_1M | 7.924.024 | 9.772.652 | 1,234 |
deu_newscrawl-public_2019_1M | 17.949.120 | 21.711.555 | 1,210 |
deu_wikipedia_2021_1M | 17.999.482 | 22.654.901 | 1,259 |
marx_kapital | 784.336 | 1.011.377 | 1,289 |
Questi risultati hanno una dispersione maggiore rispetto al modello solo inglese ma suggeriscono comunque che il testo tedesco produrrà, in media, dal 20% al 30% di token in più rispetto alle parole.
I testi inglesi producono più token con il tokenizzatore tedesco-inglese rispetto a quello solo inglese:
| Testo | Conteggio parole (Unicode Segmenter) | Conteggio token (Jina Embeddings v2 per tedesco e inglese) | Rapporto token/parole (a 3 decimali) |
|---|---|---|---|
eng_news_2020_1M | 24.243.607 | 27.758.535 | 1,145 |
eng_wikipedia_2016_1M | 22.825.712 | 25.566.921 | 1,120 |
Ci si dovrebbe aspettare di aver bisogno del 12-15% di token in più rispetto alle parole per incorporare testi inglesi con il modello bilingue tedesco/inglese rispetto a quello solo inglese.
tagCinese
(jina-embeddings-v2-base-zh)
Il cinese è tipicamente scritto senza spazi e non aveva una nozione tradizionale di "parole" prima del XX secolo. Di conseguenza, la dimensione di un testo cinese viene tipicamente misurata in caratteri (字数). Quindi, invece di utilizzare il segmentatore Unicode, ho misurato la lunghezza dei testi cinesi rimuovendo tutti gli spazi e ottenendo semplicemente la lunghezza dei caratteri.
Ho scaricato tre corpora dalla pagina del corpus cinese di Wortschatz Leipzig:
zho_wikipedia_2018_1M— Un milione di frasi dalla Wikipedia in lingua cinese, estratte nel 2018.zho_news_2007-2009_1M— Un milione di frasi da fonti di notizie cinesi, raccolte dal 2007 al 2009.zho-trad_newscrawl_2011_1M— Un milione di frasi da fonti di notizie che utilizzano esclusivamente caratteri cinesi tradizionali (繁體字).
Inoltre, per avere una maggiore diversità, ho utilizzato anche La vera storia di Ah Q (阿Q正傳), una novella di Lu Xun (魯迅) scritta all'inizio degli anni '20. Ho scaricato la versione in caratteri tradizionali da Project Gutenberg.
| Testo | Conteggio caratteri (字数) | Conteggio token (Jina Embeddings v2 per cinese e inglese) | Rapporto token/caratteri (a 3 decimali) |
|---|---|---|---|
zho_wikipedia_2018_1M | 45.116.182 | 29.193.028 | 0,647 |
zho_news_2007-2009_1M | 44.295.314 | 28.108.090 | 0,635 |
zho-trad_newscrawl_2011_1M | 54.585.819 | 40.290.982 | 0,738 |
Ah_Q | 41.268 | 25.346 | 0,614 |
Questa variazione nei rapporti token-caratteri è inaspettata, e in particolare l'anomalia nel corpus di caratteri tradizionali merita ulteriori indagini. Tuttavia, possiamo concludere che per il cinese, ci si deve aspettare di aver bisogno di meno token rispetto al numero di caratteri nel testo. A seconda del contenuto, ci si può aspettare di aver bisogno del 25-40% in meno.
I testi in inglese in Jina Embeddings v2 per cinese e inglese hanno prodotto approssimativamente lo stesso numero di token come nel modello solo inglese:
| Text | Word count (Unicode Segmenter) | Token count (Jina Embeddings v2 for Chinese and English) | Ratio of tokens to words (to 3 decimal places) |
|---|---|---|---|
eng_news_2020_1M | 24.243.607 | 26.890.176 | 1,109 |
eng_wikipedia_2016_1M | 22.825.712 | 25.060.352 | 1,097 |
tagPrendere sul serio i Token
I token sono un'importante impalcatura per i modelli di linguaggio AI, e la ricerca in questo settore è in corso.
Uno dei campi in cui i modelli AI si sono dimostrati rivoluzionari è la scoperta che sono molto robusti contro i dati rumorosi. Anche se un particolare modello non utilizza la strategia di tokenizzazione ottimale, se la rete è abbastanza grande, con dati sufficienti e adeguatamente addestrata, può imparare a fare la cosa giusta anche da input imperfetti.
Di conseguenza, viene speso molto meno sforzo nel migliorare la tokenizzazione rispetto ad altre aree, ma questo potrebbe cambiare.
Come utente di embeddings, che li acquista tramite una API come Jina Embeddings, non puoi sapere esattamente quanti token ti serviranno per un compito specifico e potresti dover fare alcuni test per ottenere numeri precisi. Ma le stime fornite qui — circa il 110% del conteggio delle parole per l'inglese, circa il 125% del conteggio delle parole per il tedesco e circa il 70% del conteggio dei caratteri per il cinese — dovrebbero essere sufficienti per un budget di base.






