


Uno dei problemi di lunga data dei modelli di AI è che le reti neurali non spiegano come producono i loro output. Non è sempre chiaro quanto questo sia un vero problema per l'intelligenza artificiale. Quando chiediamo agli umani di spiegare il loro ragionamento, essi di routine razionalizzano, tipicamente del tutto inconsapevoli di farlo, fornendo spiegazioni plausibili per le loro azioni senza alcuna indicazione di ciò che realmente accade nelle loro menti.
Sappiamo già come far produrre ai modelli di AI risposte plausibili. Forse l'intelligenza artificiale è più simile agli umani in questo senso di quanto vorremmo ammettere.
Cinquant'anni fa, il filosofo americano Thomas Nagel scrisse un influente saggio intitolato Che Effetto Fa Essere un Pipistrello? Egli sosteneva che deve esserci qualcosa che si prova ad essere un pipistrello: vedere il mondo come lo vede un pipistrello e percepire l'esistenza come fa un pipistrello. Tuttavia, secondo Nagel, anche se conoscessimo ogni fatto conoscibile su come funzionano il cervello, i sensi e il corpo di un pipistrello, non sapremmo ancora che effetto fa essere un pipistrello.
La spiegabilità dell'AI è lo stesso tipo di problema. Conosciamo ogni fatto c'è da sapere su un determinato modello di AI. È solo una grande quantità di numeri a precisione finita organizzati in una sequenza di matrici. Possiamo verificare facilmente che ogni output del modello è il risultato di calcoli corretti, ma questa informazione è inutile come spiegazione.
Non c'è una soluzione generale a questo problema per l'AI più di quanto non ci sia per gli umani. Tuttavia, l'architettura ColBERT, e in particolare il modo in cui usa la "late interaction" quando viene utilizzata come reranker, ti permette di ottenere intuizioni significative dai tuoi modelli sul perché fornisce risultati specifici in casi particolari.
Questo articolo ti mostra come la late interaction permette la spiegabilità, usando il modello Jina-ColBERT jina-colbert-v1-en e la libreria Python Matplotlib.
tagUna Breve Panoramica di ColBERT
ColBERT è stato introdotto in Khattab & Zaharia (2020) come un'estensione del modello BERT introdotto nel 2018 da Google. I modelli Jina-ColBERT di Jina AI si basano su questo lavoro e sulla successiva architettura ColBERT v2 proposta in Santhanam, et al. (2021). I modelli di tipo ColBERT possono essere usati per creare embedding, ma hanno alcune funzionalità aggiuntive quando usati come modello di reranking. Il principale beneficio è la late interaction, che è un modo di strutturare il problema della similarità semantica del testo diversamente dai modelli di embedding standard.
tagModelli di Embedding
In un modello di embedding tradizionale, confrontiamo due testi generando vettori rappresentativi per essi chiamati embedding, e poi confrontiamo questi embedding attraverso metriche di distanza come la distanza coseno o di Hamming. La quantificazione della similarità semantica di due testi segue generalmente una procedura comune.
Prima, creiamo embedding per i due testi separatamente. Per ogni singolo testo:
- Un tokenizer divide il testo in chunk approssimativamente delle dimensioni di una parola.
- Ogni token viene mappato su un vettore.
- I vettori dei token interagiscono attraverso il sistema di attention e i layer convoluzionali, aggiungendo informazioni contestuali alla rappresentazione di ciascun token.
- Un layer di pooling trasforma questi vettori di token modificati in un singolo vettore di embedding.
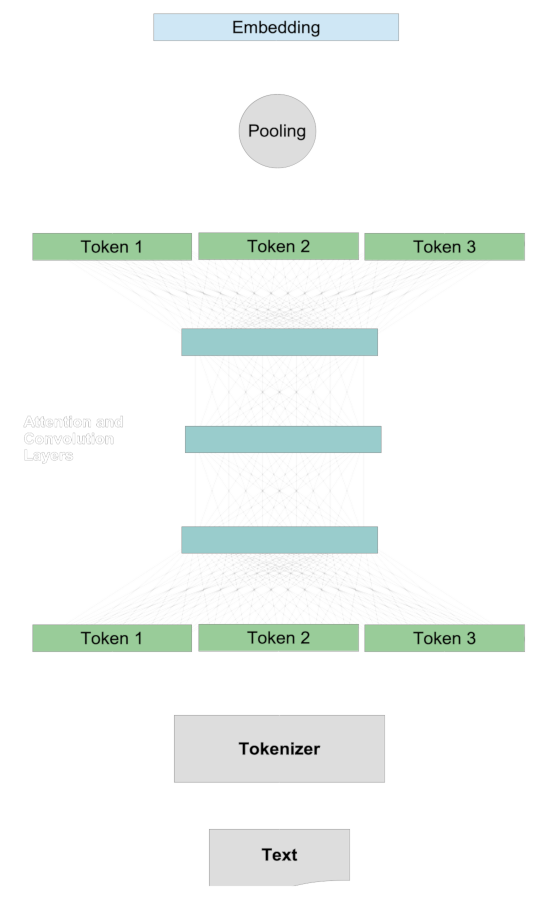
Poi, quando c'è un embedding per ciascun testo, li confrontiamo l'uno con l'altro, tipicamente usando la metrica del coseno o la distanza di Hamming.
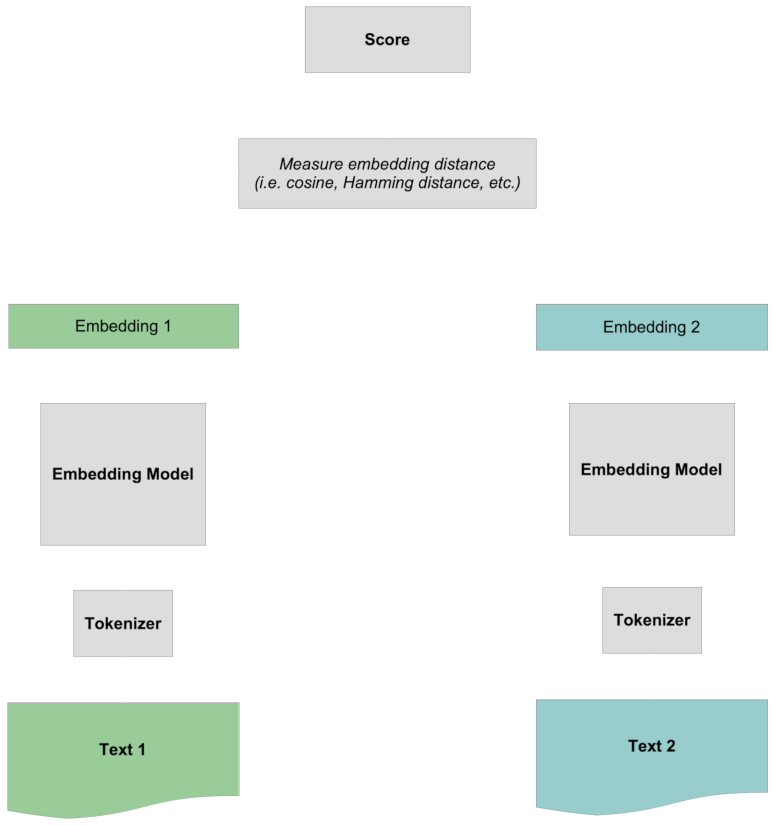
Il punteggio viene calcolato confrontando i due embedding completi tra loro, senza alcuna informazione specifica sui token. Tutta l'interazione tra i token è "precoce" poiché avviene prima che i due testi vengano confrontati tra loro.
tagModelli di Reranking
I modelli di reranking funzionano diversamente.
Prima, invece di creare un embedding per qualsiasi testo, prende un testo, chiamato query, e una collezione di altri testi che chiameremo documenti target e poi assegna un punteggio a ciascun documento target rispetto al testo della query. Questi numeri non sono normalizzati e non sono come il confronto di embedding, ma sono ordinabili. I documenti target che ottengono il punteggio più alto rispetto alla query sono i testi che sono semanticamente più correlati alla query secondo il modello.
Vediamo come funziona concretamente con il modello reranker jina-colbert-v1-en, usando la Jina Reranker API e Python.
Il codice seguente è anche in un notebook che puoi scaricare o eseguire in Google Colab.
Dovresti prima installare la versione più recente della libreria requests nel tuo ambiente Python. Puoi farlo con il seguente comando:
pip install requests -U
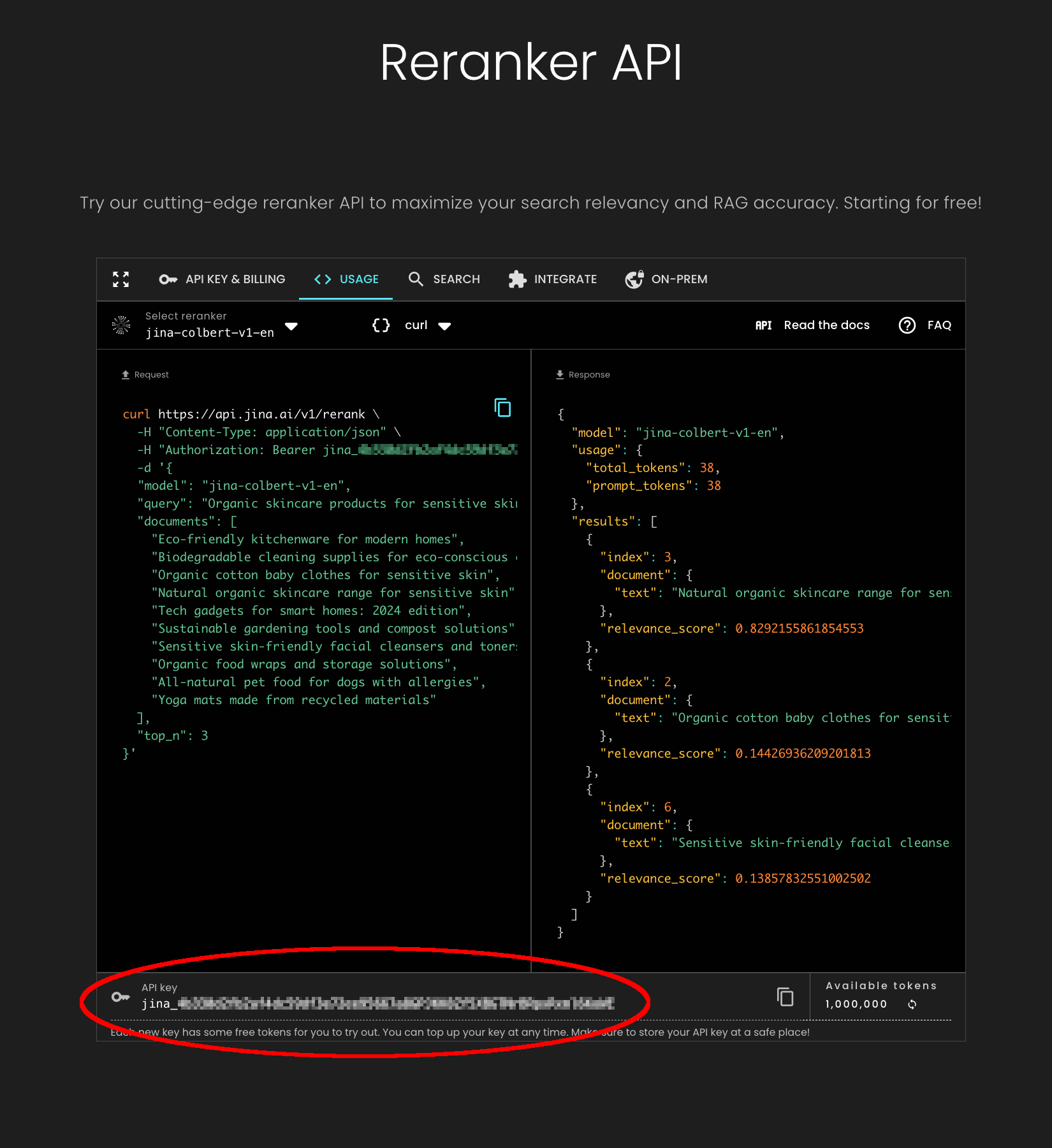
Successivamente, visita la pagina della Jina Reranker API e ottieni un token API gratuito, valido fino a un milione di token di elaborazione del testo. Copia la chiave del token API dal fondo della pagina, come mostrato di seguito:
Useremo il seguente testo di query:
- "Elephants eat 150 kg of food per day."
E confronteremo questa query con tre testi:
- "Elephants eat 150 kg of food per day."
- "Every day, the average elephant consumes roughly 150 kg of plants."
- "The rain in Spain falls mainly on the plain."
Il primo documento è identico alla query, il secondo è una riformulazione del primo, e l'ultimo testo è completamente non correlato.
Usa il seguente codice Python per ottenere i punteggi, assegnando il tuo token API Jina Reranker alla variabile jina_api_key:
import requests
url = "<https://api.jina.ai/v1/rerank>"
jina_api_key = "<YOUR JINA RERANKER API TOKEN HERE>"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {jina_api_key}"
}
data = {
"model": "jina-colbert-v1-en",
"query": "Elephants eat 150 kg of food per day.",
"documents": [
"Elephants eat 150 kg of food per day.",
"Every day, the average elephant consumes roughly 150 kg of food.",
"The rain in Spain falls mainly on the plain.",
],
"top_n": 3
}
response = requests.post(url, headers=headers, json=data)
for item in response.json()['results']:
print(f"{item['relevance_score']} : {item['document']['text']}")
Eseguire questo codice da un file Python o in un notebook dovrebbe produrre il seguente risultato:
11.15625 : Elephants eat 150 kg of food per day.
9.6328125 : Every day, the average elephant consumes roughly 150 kg of food.
1.568359375 : The rain in Spain falls mainly on the plain.
La corrispondenza esatta ha il punteggio più alto, come ci aspetteremmo, mentre la riformulazione ha il secondo punteggio più alto, e un testo completamente non correlato ha un punteggio molto più basso.
tagPunteggio usando ColBERT
Ciò che rende il reranking ColBERT diverso dal punteggio basato su embedding è che i token dei due testi vengono confrontati tra loro durante il processo di assegnazione del punteggio. I due testi non hanno mai i propri embedding.
Prima, usiamo la stessa architettura dei modelli di embedding per creare nuove rappresentazioni per ogni token che includono informazioni contestuali dal testo. Poi, confrontiamo ogni token dalla query con ogni token dal documento.
Per ogni token nella query, identifichiamo il token nel documento che ha l'interazione più forte con esso, e sommiamo questi punteggi di interazione per calcolare un valore numerico finale.
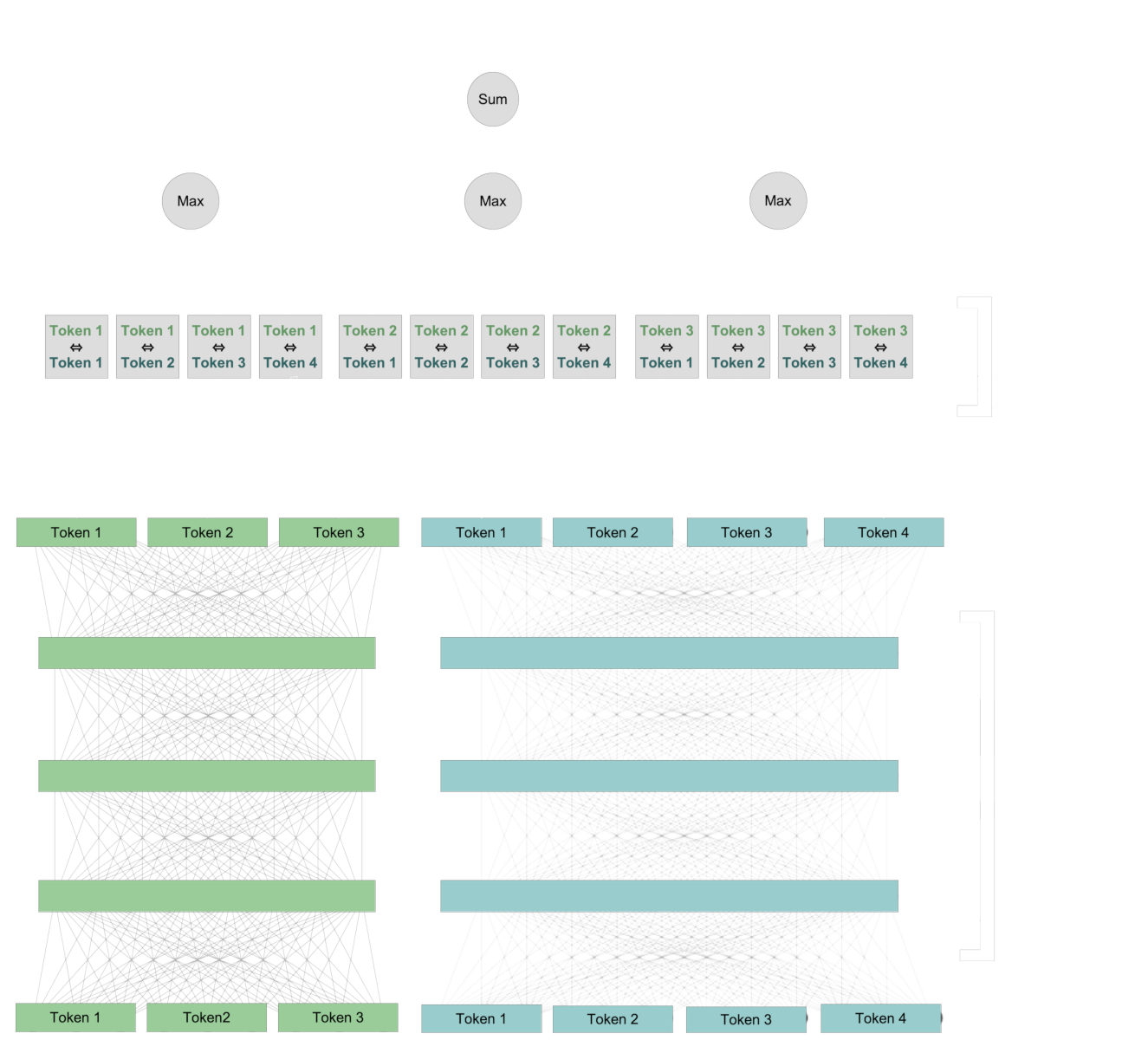
Questa interazione è "tardiva": i token interagiscono tra i due testi quando li confrontiamo tra loro. Ma ricorda, l'interazione "tardiva" non esclude l'interazione "precoce". Le coppie di vettori di token che vengono confrontate contengono già informazioni sui loro contesti specifici.
Questo schema di interazione tardiva preserva le informazioni a livello di token, anche se queste informazioni sono specifiche del contesto. Ciò ci permette di vedere, in parte, come il modello ColBERT calcola il suo punteggio perché possiamo identificare quali coppie di token contestualizzati contribuiscono al punteggio finale.
tagSpiegare i Ranking con le Mappe di Calore
Le mappe di calore sono una tecnica di visualizzazione utile per vedere cosa succede in Jina-ColBERT quando crea i punteggi. In questa sezione, useremo le librerie seaborn e matplotlib per creare mappe di calore dallo strato di interazione tardiva di jina-colbert-v1-en, mostrando come i token della query interagiscono con i token del testo di destinazione.
tagConfigurazione
Abbiamo creato un file di libreria Python contenente il codice per accedere al modello jina-colbert-v1-en e utilizzare seaborn, matplotlib e Pillow per creare mappe di calore. Puoi scaricare questa libreria direttamente da GitHub, o utilizzare il notebook fornito sul tuo sistema, oppure su Google Colab.
Prima, installa i requisiti. Avrai bisogno dell'ultima versione della libreria requests nel tuo ambiente Python. Quindi, se non l'hai già fatto, esegui:
pip install requests -U
Poi, installa le librerie principali:
pip install matplotlib seaborn torch Pillow
Successivamente, scarica jina_colbert_heatmaps.py da GitHub. Puoi farlo tramite browser web o dalla riga di comando se wget è installato:
wget https://raw.githubusercontent.com/jina-ai/workshops/main/notebooks/heatmaps/jina_colbert_heatmaps.py
Con le librerie installate, dobbiamo solo dichiarare una funzione per il resto di questo articolo:
from jina_colbert_heatmaps import JinaColbertHeatmapMaker
def create_heatmap(query, document, figsize=None):
heat_map_maker = JinaColbertHeatmapMaker(jina_api_key=jina_api_key)
# get token embeddings for the query
query_emb = heat_map_maker.embed(query, is_query=True)
# get token embeddings for the target document
document_emb = heat_map_maker.embed(document, is_query=False)
return heat_map_maker.compute_heatmap(document_emb[0], query_emb[0], figsize)
tagRisultati
Ora che possiamo creare mappe di calore, creiamone alcune e vediamo cosa ci dicono.
Esegui il seguente comando in Python:
create_heatmap("Elephants eat 150 kg of food per day.", "Elephants eat 150 kg of food per day.")Il risultato sarà una mappa di calore che assomiglia a questa:
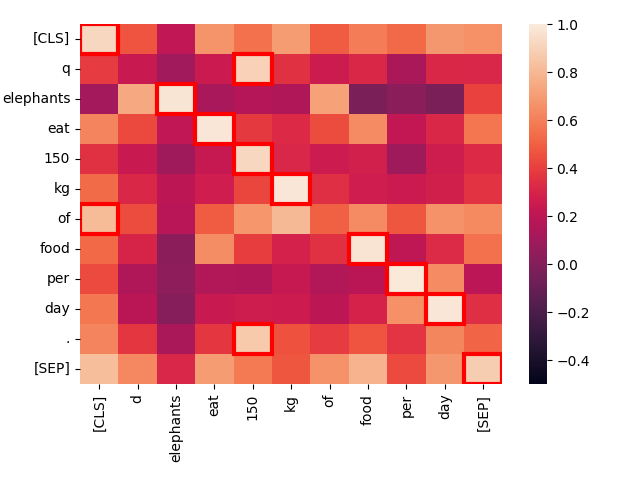
Questa è una mappa di calore dei livelli di attivazione tra coppie di token quando confrontiamo due testi identici. Ogni quadrato mostra l'interazione tra due token, uno da ciascun testo. I token aggiuntivi [CLS] e [SEP] indicano rispettivamente l'inizio e la fine del testo, e q e d vengono inseriti subito dopo il token [CLS] nelle query e nei documenti target rispettivamente. Questo permette al modello di tenere conto delle interazioni tra i token e l'inizio e la fine dei testi, ma permette anche alle rappresentazioni dei token di essere sensibili al fatto che si trovino in query o in target.
Più luminoso è il quadrato, maggiore è l'interazione tra i due token, il che indica una relazione semantica. Il punteggio di interazione di ogni coppia di token è nell'intervallo da -1.0 a 1.0. I quadrati evidenziati da una cornice rossa sono quelli che contano per il punteggio finale: Per ogni token nella query, il suo livello di interazione più alto con qualsiasi token del documento è il valore che conta.
I migliori match — i punti più luminosi — e i valori massimi incorniciati in rosso sono quasi tutti esattamente sulla diagonale e hanno un'interazione molto forte. Le uniche eccezioni sono i token "tecnici" [CLS], q, e d, oltre alla parola "of" che è una "stop word" ad alta frequenza in inglese che porta pochissime informazioni indipendenti.
Prendiamo una frase strutturalmente simile — "Cats eat 50 g of food per day." — e vediamo come interagiscono i token:
create_heatmap("Elephants eat 150 kg of food per day.", "Cats eat 50 g of food per day.")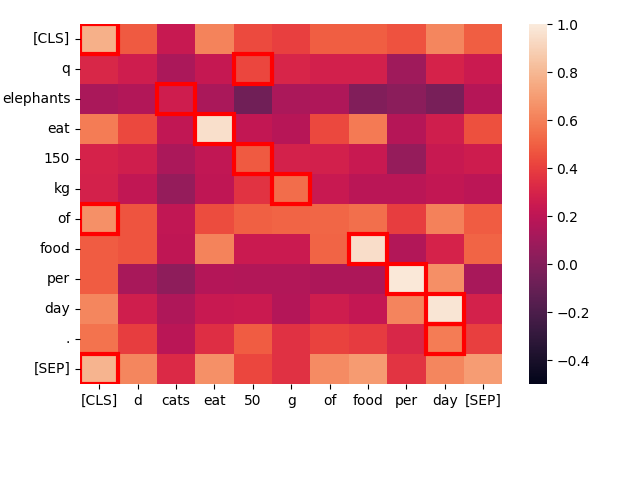
Ancora una volta, i migliori match sono principalmente sulla diagonale perché le parole sono spesso le stesse e la struttura della frase è quasi identica. Anche "cats" e "elephants" corrispondono, a causa dei loro contesti comuni, anche se non molto bene.
Meno simile è il contesto, peggiore è il match. Consideriamo il testo "Employees eat at the company canteen."
create_heatmap("Elephants eat 150 kg of food per day.", "Employees eat at the company canteen.")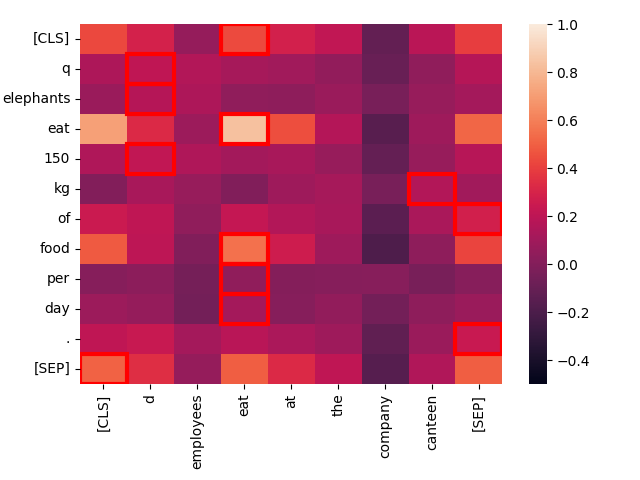
Sebbene strutturalmente simili, l'unica corrispondenza forte qui è tra le due istanze di "eat". A livello tematico, queste sono frasi molto diverse, anche se le loro strutture sono altamente parallele.
Guardando l'oscurità dei colori nei quadrati incorniciati in rosso, possiamo vedere come il modello li classificherebbe come match per "Elephants eat 150 kg of food per day", e jina-colbert-v1-en conferma questa intuizione:
| Score | Text |
|---|---|
| 11.15625 | Elephants eat 150 kg of food per day. |
| 8.3671875 | Cats eat 50 g of food per day. |
| 3.734375 | Employees eat at the company canteen. |
Ora, confrontiamo "Elephants eat 150 kg of food per day." con una frase che ha essenzialmente lo stesso significato ma una formulazione diversa: "Every day, the average elephant consumes roughly 150 kg of food."
create_heatmap("Elephants eat 150 kg of food per day.", "Every day, the average elephant consumes roughly 150 kg of food.")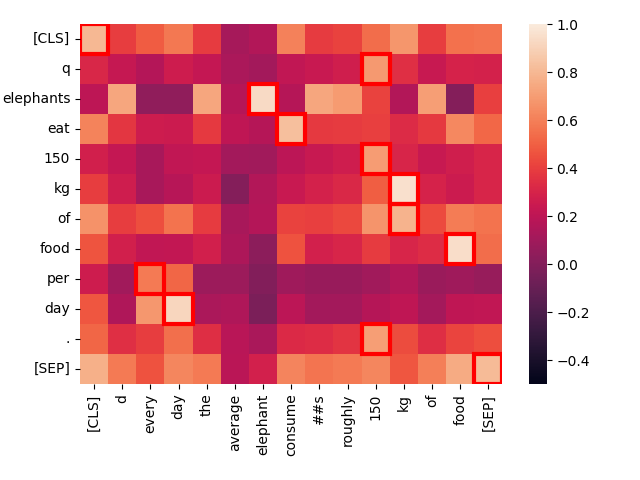
Nota l'intensa interazione tra "eat" nella prima frase e "consume" nella seconda. La differenza nel vocabolario non impedisce a Jina-ColBERT di riconoscere il significato comune.
Inoltre, "every day" corrisponde fortemente a "per day", anche se si trovano in posizioni completamente diverse. Solo la parola di basso valore "of" risulta essere un'anomala non corrispondenza.
Ora, confrontiamo la stessa query con un testo totalmente non correlato: "The rain in Spain falls mainly on the plain."
create_heatmap("Elephants eat 150 kg of food per day.", "The rain in Spain falls mainly on the plain.")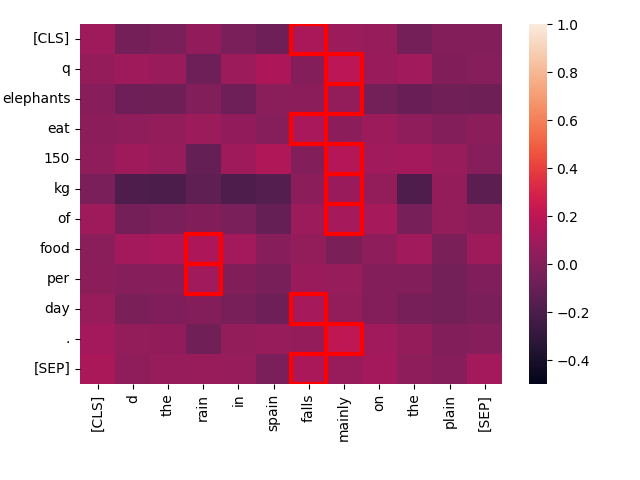
Si può notare che le interazioni "migliori corrispondenze" hanno punteggi molto più bassi per questa coppia, e c'è pochissima interazione tra le parole dei due testi. Intuitivamente, ci aspetteremmo un punteggio basso rispetto a "Every day, the average elephant consumes roughly 150 kg of food", e jina-colbert-v1-en concorda:
| Score | Text |
|---|---|
| 9.6328125 | Every day, the average elephant consumes roughly 150 kg of food. |
| 1.568359375 | The rain in Spain falls mainly on the plain. |
tagTesti Lunghi
Questi sono esempi semplificati per dimostrare il funzionamento dei modelli di reranking stile ColBERT. Nei contesti di information retrieval, come la generazione aumentata tramite retrieval, le query tendono ad essere testi brevi mentre i documenti candidati tendono ad essere più lunghi, spesso quanto la finestra di contesto di input del modello.
I modelli Jina-ColBERT supportano tutti contesti di input di 8192 token, equivalenti a circa 16 pagine standard di testo con interlinea singola.
Possiamo generare mappe di calore anche per questi casi asimmetrici. Per esempio, prendiamo la prima sezione della pagina Wikipedia sugli Elefanti Indiani:
Per vedere questo come testo semplice, come passato a jina-colbert-v1-en, clicca questo link.
Questo testo è lungo 364 parole, quindi la nostra mappa di calore non apparirà molto quadrata:
create_heatmap("Elephants eat 150 kg of food per day.", wikipedia_elephants, figsize=(50,7))
Vediamo che "elephants" corrisponde a molti punti nel testo. Questo non sorprende in un testo sugli elefanti. Ma possiamo anche vedere un'area dove c'è un'interazione molto più forte:
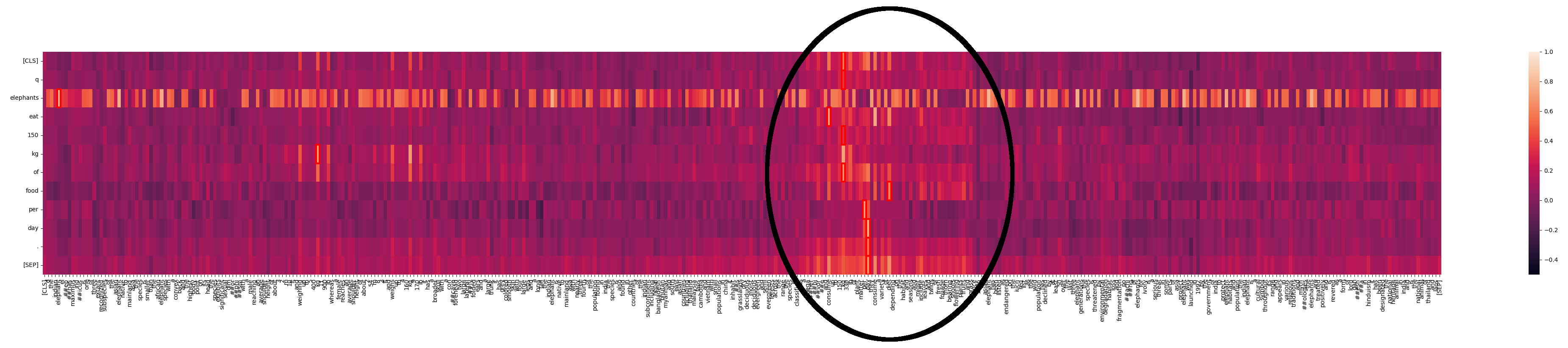
Cosa sta succedendo qui? Con Jina-ColBERT, possiamo trovare la parte del testo più lungo che corrisponde a questo. Si scopre che è la quarta frase del secondo paragrafo:
The species is classified as a megaherbivore and consume up to 150 kg (330 lb) of plant matter per day.
Questa riafferma la stessa informazione presente nel testo della query. Se guardiamo la mappa di calore solo per questa frase possiamo vedere le forti corrispondenze:
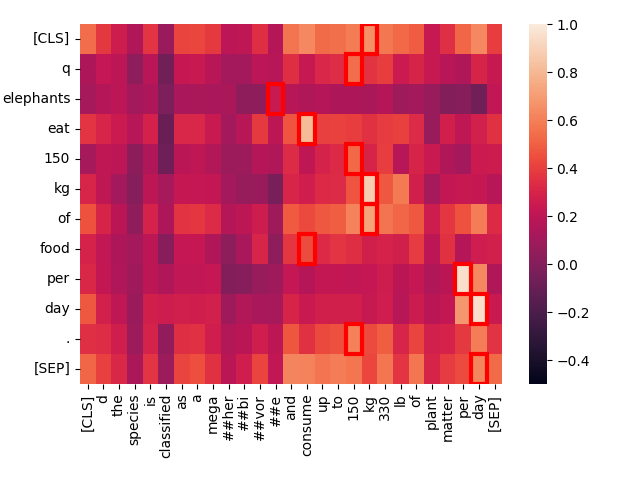
Jina-ColBERT ti fornisce i mezzi per vedere esattamente quali aree in un testo lungo hanno causato la corrispondenza con la query. Questo porta a un migliore debugging, ma anche a una maggiore spiegabilità. Non serve alcuna sofisticazione per vedere come viene fatta una corrispondenza.
tagSpiegare i risultati dell'AI con Jina-ColBERT
Gli embedding sono una tecnologia fondamentale nell'AI moderna. Quasi tutto ciò che facciamo si basa sull'idea che relazioni complesse e apprendibili nei dati di input possano essere espresse nella geometria di spazi ad alte dimensioni. Tuttavia, è molto difficile per i semplici umani dare un senso alle relazioni spaziali in migliaia o milioni di dimensioni.
ColBERT è un passo indietro da quel livello di astrazione. Non è una risposta completa al problema di spiegare cosa fa un modello di AI, ma ci indica direttamente quali parti dei nostri dati sono responsabili dei nostri risultati.
A volte, l'AI deve essere una scatola nera. Le matrici giganti che fanno tutto il lavoro pesante sono troppo grandi perché un umano le tenga a mente. Ma l'architettura ColBERT getta un po' di luce nella scatola e dimostra che è possibile fare di più.
Il modello Jina-ColBERT è attualmente disponibile solo per l'inglese (jina-colbert-v1-en) ma altre lingue e contesti d'uso sono in arrivo. Questa linea di modelli, che non solo esegue information retrieval allo stato dell'arte ma può anche dirti perché ha trovato una corrispondenza, dimostra l'impegno di Jina AI nel rendere le tecnologie AI sia accessibili che utili.
