


A tarda notte, un poliziotto trova un ubriaco che striscia a quattro zampe sotto un lampione. L'ubriaco dice all'agente che sta cercando il suo portafoglio. Quando l'agente gli chiede se è sicuro di averlo perso proprio lì, l'uomo risponde che molto probabilmente l'ha perso dall'altra parte della strada. Allora perché lo sta cercando qui? chiede l'agente confuso. Perché qui c'è più luce, spiega l'ubriaco.
David H. Friedman, Why Scientific Studies Are So Often Wrong: The Streetlight Effect, Discover magazine, Dic. 2010
I benchmark sono una componente fondamentale delle moderne pratiche di machine learning e lo sono da tempo, ma hanno un problema molto serio: non possiamo dire se i nostri benchmark misurino qualcosa di utile.
Questo è un grande problema, e questo articolo introdurrà parte di una soluzione: l'AIR-Bench. Questo progetto congiunto con la Beijing Academy of Artificial Intelligence è un approccio innovativo alle metriche AI progettato per migliorare la qualità e l'utilità dei nostri benchmark.


tagL'Effetto Lampione
La ricerca scientifica e operativa pone molta enfasi sulle misurazioni, ma le misurazioni non sono una cosa semplice. In uno studio sulla salute, potresti voler sapere se un farmaco o un trattamento ha reso i destinatari più sani, longevi o ha migliorato la loro condizione in qualche modo. Ma la salute e il miglioramento della qualità della vita sono cose difficili da misurare direttamente, e possono servire decenni per scoprire se un trattamento ha prolungato la vita di qualcuno.
Quindi i ricercatori usano dei proxy. In uno studio sulla salute, potrebbero essere cose come la forza fisica, la riduzione del dolore, l'abbassamento della pressione sanguigna o qualche altra variabile facilmente misurabile. Uno dei problemi della ricerca sulla salute è che il proxy potrebbe non essere realmente indicativo del miglior risultato sulla salute che si vuole ottenere da un farmaco o un trattamento.
Una misurazione è un proxy per qualcosa di utile che ti interessa. Potresti non essere in grado di misurare quella cosa, quindi misuri qualcos'altro, qualcosa che puoi misurare, che hai motivo di credere sia correlato alla cosa utile che ti interessa veramente.
Concentrarsi sulla misurazione è stato un importante sviluppo della ricerca operativa del XX secolo e ha avuto alcuni effetti profondi e positivi. Il Total Quality Management, un insieme di dottrine a cui viene attribuita l'ascesa del Giappone al dominio economico negli anni '80, riguarda quasi completamente la misurazione costante di variabili proxy e l'ottimizzazione delle pratiche su questa base.
Ma un focus sulla misurazione pone alcuni problemi noti e importanti:
- Una misurazione può smettere di essere un buon proxy quando si prendono decisioni basate su di essa.
- Spesso ci sono modi per gonfiare una misura che non migliorano nulla, portando alla possibilità di imbrogliare o credere di fare progressi facendo cose che non stanno aiutando.
Alcune persone credono che la maggior parte della ricerca medica potrebbe essere semplicemente sbagliata in parte a causa di questo problema. La disconnessione tra le cose che puoi misurare e gli obiettivi reali è una delle ragioni citate per la calamità della guerra americana in Vietnam.
Questo viene talvolta chiamato "Effetto Lampione", dalle storie, come quella all'inizio di questa pagina, dell'ubriaco che cerca qualcosa non dove l'ha perso, ma dove c'è più luce. Una misura proxy è come guardare dove c'è luce perché non c'è luce sulla cosa che vogliamo vedere.
Nella letteratura più tecnica, l'"Effetto Lampione" è tipicamente collegato alla Legge di Goodhart, attribuita alle critiche dell'economista britannico Charles Goodhart al governo Thatcher, che aveva posto molta enfasi sulle misure proxy della prosperità. La Legge di Goodhart ha diverse formulazioni, ma quella qui sotto è la più citata:
[O]gni misura che diventa un obiettivo diventa una cattiva misura[…]
Keith Hoskins, 1996 The 'awful idea of accountability': inscribing people into the measurement of objects.
Nell'AI, un famoso esempio di questo è la metrica BLEU usata nella ricerca sulla traduzione automatica. Sviluppato nel 2001 presso IBM, BLEU è un modo per automatizzare la valutazione dei sistemi di traduzione automatica, ed è stato un fattore cruciale nel boom della traduzione automatica degli anni 2000. Una volta che era facile dare un punteggio al tuo sistema, potevi lavorare per migliorarlo. E i punteggi BLEU sono migliorati costantemente. Dal 2010, era quasi impossibile far pubblicare un articolo di ricerca sulla traduzione automatica in una rivista o conferenza se non superava il punteggio BLEU stato dell'arte, non importava quanto innovativo fosse l'articolo né quanto bene potesse gestire alcuni problemi specifici che altri sistemi stavano gestendo male.
Il modo più facile per essere ammessi a una conferenza era trovare qualche modo minore per modificare i parametri del tuo modello, ottenere un punteggio BLEU leggermente superiore a quello di Google Translate, e poi presentare. Questi risultati erano essenzialmente inutili. Bastava prendere alcuni nuovi testi da tradurre per dimostrare che raramente erano migliori e spesso erano peggiori dello stato dell'arte.
Invece di usare BLEU per valutare i progressi nella traduzione automatica, ottenere un punteggio BLEU migliore è diventato l'obiettivo. Non appena questo è accaduto, ha smesso di essere un modo utile per valutare i progressi.
tagI Nostri Benchmark AI Sono Buoni Proxy?
Il benchmark più utilizzato per i modelli di embedding è il set di test MTEB, che consiste in 56 test specifici. Questi vengono mediati per categoria e tutti insieme per produrre una collezione di punteggi specifici per classe. Al momento della scrittura, la parte superiore della classifica MTEB appare così:
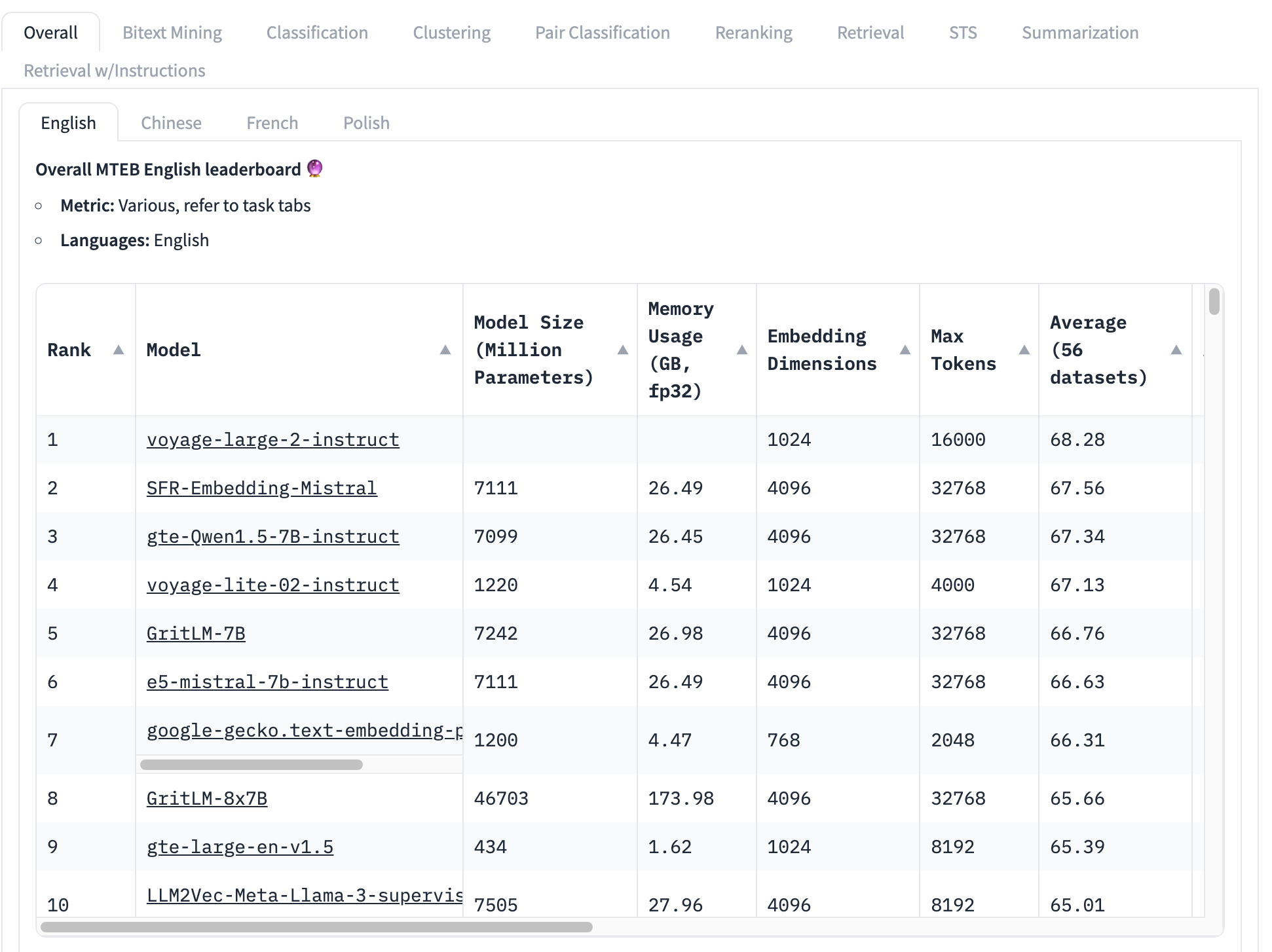
Il modello di embedding in cima alla classifica ha un punteggio medio complessivo di 68,28, il secondo più alto è 67,56. È molto difficile, guardando questa tabella, sapere se questa sia una grande differenza o no. Se è una piccola differenza, allora altri fattori potrebbero essere più importanti di quale modello ha il punteggio più alto:
- Dimensione del modello: I modelli hanno dimensioni diverse, che riflettono diverse richieste di risorse di calcolo. I modelli piccoli funzionano più velocemente, con meno memoria e richiedono hardware meno costoso. Vediamo, in questa top 10, modelli che vanno dai 434 milioni di parametri a oltre 46 miliardi — una differenza di 100 volte!
- Dimensione dell'embedding: Le dimensioni degli embedding variano. Una dimensionalità più piccola fa sì che i vettori di embedding utilizzino meno memoria e storage e rende i confronti tra vettori (l'uso principale degli embedding) molto più veloci. In questo elenco, vediamo dimensioni di embedding da 768 a 4096 — solo una differenza di cinque volte ma comunque significativa quando si costruiscono applicazioni commerciali.
- Dimensione della finestra di contesto in input: Le finestre di contesto variano sia in dimensione che in qualità, da 2048 token a 32768. Inoltre, diversi modelli utilizzano approcci diversi per la codifica posizionale e la gestione degli input, che possono creare bias a favore di parti specifiche dell'input.
In breve, la media complessiva è un modo molto incompleto per determinare quale modello di embedding sia il migliore.
Anche se guardiamo i punteggi specifici per attività, come quelli sotto per il recupero, affrontiamo gli stessi problemi ancora una volta. Non importa quale sia il punteggio di un modello su questo set di test, non c'è modo di sapere quali modelli si comporteranno meglio per il tuo particolare caso d'uso unico.
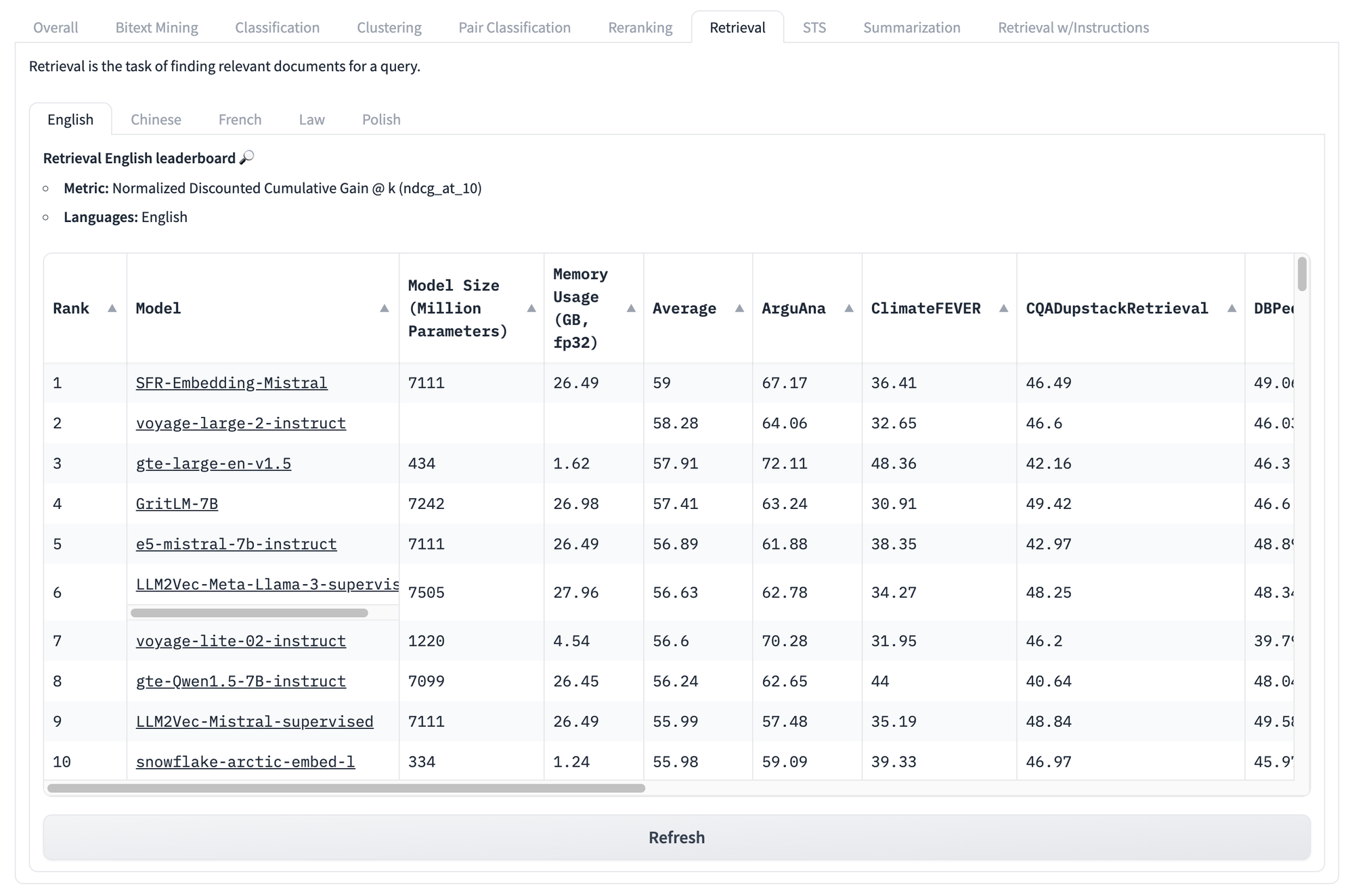
Ma i problemi con questo tipo di benchmark non finiscono qui.
L'intuizione principale della Legge di Goodhart è che una metrica può sempre essere manipolata, spesso anche involontariamente. Per esempio, i benchmark MTEB consistono in dati provenienti da fonti pubbliche che probabilmente sono già presenti nei tuoi dati di training. A meno che non ti impegni specificamente per rimuovere i dati di benchmark dal training, i tuoi punteggi benchmark saranno statisticamente poco affidabili.
Non esiste una soluzione semplice e completa. Un benchmark è un indicatore e non possiamo mai essere certi che rifletta ciò che vogliamo sapere ma non possiamo misurare direttamente.
Tuttavia, identifichiamo tre problemi principali con i benchmark AI che possiamo mitigare:
- I benchmark sono fissi per natura: gli stessi compiti, con gli stessi testi.
- I benchmark sono generici: non sono molto informativi riguardo scenari reali.
- I benchmark sono inflessibili: non possono rispondere a casi d'uso diversi.
L'AI crea problemi come questi, ma a volte crea anche soluzioni. Crediamo di poter utilizzare i modelli AI per affrontare questi problemi, almeno per quanto riguarda i benchmark AI.
tagUsare l'AI per valutare l'AI: AIR-Bench
AIR-Bench è open source e disponibile sotto licenza MIT. Puoi visualizzare o scaricare il codice dal suo repository su GitHub.
 AIR-Bench
AIR-BenchtagCosa fa?
AIR-Bench introduce alcune funzionalità importanti nel benchmarking AI:
- Specializzazione per Applicazioni di Retrieval e RAG
Questo benchmark è orientato verso applicazioni realistiche di information retrieval e pipeline di retrieval-augmented generation. - Flessibilità di Dominio e Lingua
AIR rende molto più facile creare benchmark da dati specifici di un dominio o per un'altra lingua, o persino da dati specifici per un determinato compito. - Generazione Automatica dei Dati
AIR-Bench genera dati di test e il dataset riceve aggiornamenti regolari, riducendo il rischio di data leakage.
tagClassifica AIR-Bench su HuggingFace
Stiamo gestendo una classifica, simile a quella MTEB, per l'attuale release dei task generati da AIR-Bench. Rigenereremo regolarmente i benchmark, ne aggiungeremo di nuovi ed espanderemo la copertura a più modelli AI.

tagCome funziona?
L'intuizione principale dell'approccio AIR è che possiamo utilizzare i large language model (LLM) per generare nuovi testi e nuovi task che non possono essere presenti in nessun set di training.
AIR-Bench sfrutta le capacità creative degli LLM chiedendo loro di simulare uno scenario. L'utente sceglie una collezione di documenti — una collezione reale che potrebbe essere parte dei dati di training di alcuni modelli — e poi immagina un utente con un ruolo definito e una situazione in cui avrebbe bisogno di utilizzare quel corpus di documenti.

Poi, l'utente seleziona un documento dal corpus e lo passa all'LLM insieme al profilo utente e alla descrizione della situazione. L'LLM viene sollecitato a creare query appropriate per quell'utente e quella situazione che dovrebbero trovare quel documento.
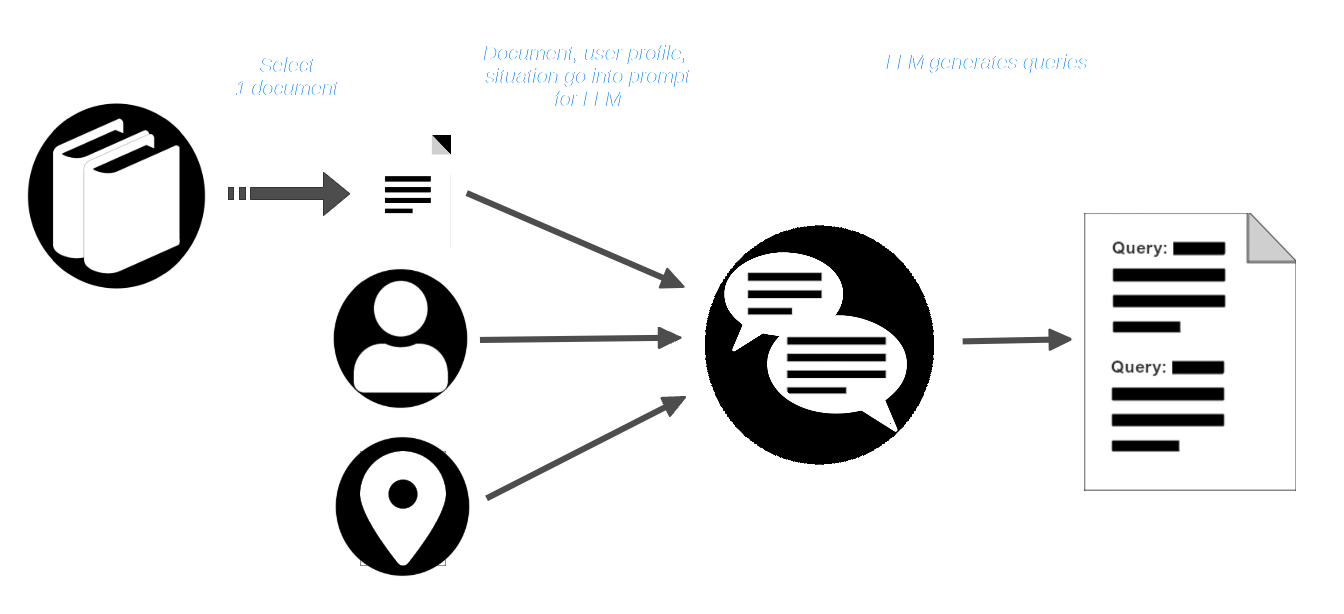
La pipeline AIR-Bench quindi fornisce all'LLM il documento e la query e genera documenti sintetici che sono simili a quello fornito ma che non dovrebbero corrispondere alla query.
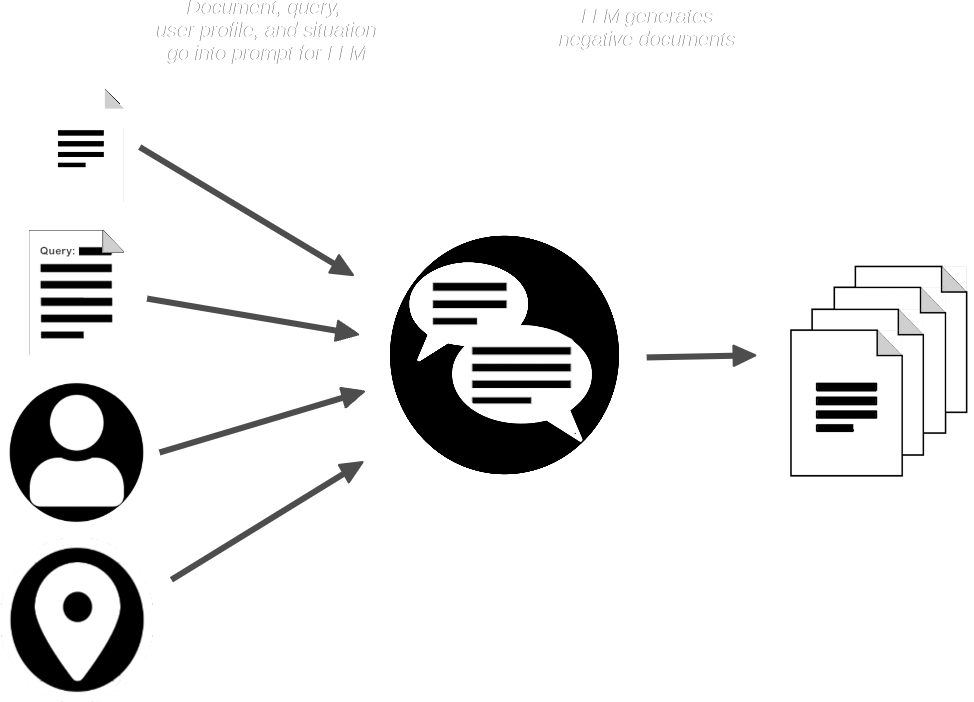
Ora abbiamo:
- Una collezione di query
- Un documento reale corrispondente per ogni query
- Una piccola collezione di documenti sintetici che non dovrebbero corrispondere
AIR-Bench unisce i documenti sintetici con la collezione di documenti reali e quindi utilizza uno o più modelli di embedding e reranking per verificare che le query dovrebbero essere in grado di recuperare i documenti corrispondenti. Utilizza anche l'LLM per verificare che ogni query sia rilevante per i documenti che dovrebbe recuperare.
Per maggiori dettagli su questo processo di generazione e controllo qualità basato su AI, leggi la documentazione sulla Generazione dei Dati nel repository AIR-Bench su GitHub.
AIR-BenchIl risultato è un insieme di coppie query-corrispondenza di alta qualità e un dataset semi-sintetico su cui eseguirle. Anche se la collezione originale di documenti reali fa parte del suo training, i documenti sintetici aggiunti e le query stesse sono dati nuovi e mai visti prima che non avrebbe potuto apprendere in precedenza.
tagBenchmark Specifici per Dominio e Test Basati sulla Realtà
La sintesi di query e documenti impedisce che i dati di benchmark trapelino nel training, ma aiuta anche molto a risolvere il problema dei benchmark generici.
Fornendo agli LLM dati scelti, un profilo utente e uno scenario, AIR-Bench rende molto facile costruire benchmark per casi d'uso particolari. Inoltre, costruendo query per un tipo specifico di utente e scenario d'uso, AIR-Bench può produrre query di test più vicine all'uso nel mondo reale rispetto ai benchmark tradizionali. La creatività e l'immaginazione limitate di un LLM potrebbero non corrispondere completamente a uno scenario reale, ma è comunque un'alternativa migliore rispetto a un dataset di test statico creato con dati disponibili ai ricercatori.
Come sottoprodotto di questa flessibilità, AIR-Bench supporta tutte le lingue supportate da GPT-4.
Inoltre, AIR-Bench si concentra specificamente sul recupero realistico delle informazioni basato sull'AI, di gran lunga l'applicazione più diffusa dei modelli di embedding. Non fornisce punteggi per altri tipi di attività come il clustering o la classificazione.
tagLa Distribuzione AIR-Bench
AIR-Bench è disponibile per il download, l'uso e la modifica tramite il suo repository GitHub.
AIR-BenchAIR-Bench supporta due tipi di benchmark:
- Un'attività di recupero delle informazioni basata sulla valutazione del corretto recupero di documenti rilevanti per specifiche query.
- Un'attività "documento lungo" che imita la parte di recupero delle informazioni di una pipeline di generazione potenziata dal recupero.
Abbiamo anche pre-generato una serie di benchmark, in inglese e cinese, insieme agli script per generarli come esempi pratici di come utilizzare AIR-Bench. Questi utilizzano set di dati facilmente disponibili.
Per esempio, per una selezione di 6.738.498 pagine di Wikipedia in inglese, abbiamo generato 1.727 query che corrispondono a 4.260 documenti e altri 7.882 documenti sintetici non corrispondenti ma simili. Offriamo benchmark convenzionali di recupero delle informazioni per otto dataset in lingua inglese e sei in cinese. Per le attività "documento lungo", forniamo quindici benchmark, tutti in inglese.
Per vedere l'elenco completo e maggiori dettagli, visita la pagina dei Task Disponibili nel repository AIR-Bench su GitHub.
AIR-BenchtagPartecipa
AIR-Benchmark è stato progettato per essere uno strumento per la comunità di Search Foundations, in modo che gli utenti coinvolti possano creare benchmark più adatti alle loro esigenze. Quando i tuoi test sono informativi sui tuoi casi d'uso, informano anche noi, così possiamo costruire prodotti che soddisfino meglio le tue esigenze.
