



Recentemente si è scritto molto sui pericoli delle aziende di AI che aspirano tutti i dati da internet, che abbiano o meno il "permesso" di farlo. Parleremo del "permesso" più avanti - c'è un motivo per cui abbiamo messo la parola tra virgolette. Ma cosa significa per i LLM quando il web aperto è stato completamente sfruttato, i fornitori di contenuti hanno chiuso le loro porte e c'è a malapena un flusso di nuovi dati da raccogliere?
tagI Pericoli dello Scraping AI
Le aziende di AI stanno trattando internet come un buffet di dati a volontà, senza preoccuparsi delle buone maniere. Basta guardare Runway che raccoglie video da YouTube per addestrare il loro modello (contro i termini di servizio di YouTube), Anthropic che colpisce iFixit un milione di volte al giorno e il New York Times che fa causa a OpenAI e Microsoft per l'uso di opere protette da copyright.
Tentare di bloccare gli scraper nel proprio robots.txt o nei termini di servizio non aiuta in alcun modo. Gli scraper che non si preoccupano scraperanno comunque, mentre quelli più attenti verranno bloccati. Non c'è alcun incentivo per gli scraper a comportarsi bene. Possiamo vederlo in azione nel recente documento della Data Provenance Initiative:
Questo non è solo un problema astratto - iFixit perde denaro e vede le proprie risorse DevOps impegnate. ReadTheDocs ha accumulato oltre $5,000 in costi di banda in un solo mese, con quasi 10 TB in un singolo giorno, a causa di crawler abusivi. Se gestisci un sito web e vieni colpito da un crawler che non segue le regole? Potrebbe essere la fine.
Quindi, cosa può fare un sito web? Se le aziende di AI non seguiranno le regole, aspettatevi che i paywall aumentino e i contenuti liberamente disponibili diminuiscano. Il web libero non esiste più. Tutto quello che resta è il pay-to-play.
tagLo Scraping è Legale?
Lo scraping è problematico? Sì. È legale? Anche sì. Il web scraping è legale negli Stati Uniti, nell'Unione Europea, in Giappone, Corea del Sud e Canada. Nessun paese sembra avere leggi che affrontino specificamente questa pratica, ma i tribunali di tutto il mondo generalmente concordano che è legale utilizzare l'automazione per visitare siti web aperti a tutti e fare copie private dei loro contenuti.
Alcune persone credono che inserendo un avviso stampato su una pagina web o in un file robots.txt, possano vietare lo scraping o altri usi legali del loro sito web e dei suoi contenuti. Questo non funziona davvero. Avvisi del genere non hanno alcun significato legale, e robots.txt è una convenzione IETF che non ha forza di legge. Senza un atto di conferma, come minimo cliccando il pulsante "Accetto i Termini di Servizio", non si possono imporre condizioni ai visitatori del proprio sito web, e anche in quel caso sono spesso legalmente inapplicabili.
 Joshua J. Kaufman
Joshua J. KaufmanTuttavia, mentre lo scraping è legale, ci sono alcune limitazioni:
- Pratiche che potrebbero ridurre l'usabilità di un sito web per altri, come colpirlo troppo spesso o troppo velocemente con il web-scraper, possono avere conseguenze civili o persino penali in casi estremi.
- Molti paesi hanno leggi che criminalizzano l'accesso non autorizzato ai computer. Se ci sono parti di un sito web che chiaramente non sono destinate all'accesso pubblico, potrebbe essere illegale eseguirne lo scraping.
- Molti paesi hanno leggi che rendono illegale aggirare le tecnologie anti-copia. Se un sito web ha messo in atto misure per impedire il download di alcuni contenuti, potresti infrangere la legge se ne fai comunque lo scraping.
- I siti web che hanno termini di servizio espliciti e richiedono di confermare l'accettazione possono vietare lo scraping e portarti in tribunale se lo fai, ma i risultati sono irregolari.
Negli Stati Uniti non esiste una legge esplicita sullo scraping, ma i tentativi di utilizzare il Computer Fraud and Abuse Act del 1986 per vietarlo sono falliti, più recentemente nel caso del Nono Circuito hiQ Labs v. LinkedIn nel 2019. La legge statunitense è complessa, con molte distinzioni create dai tribunali e un sistema di giurisdizioni statali e federali che significa che, a meno che la Corte Suprema non si pronunci su qualcosa, non è necessariamente definitivo. (E a volte non lo è nemmeno allora.)
L'UE non ha leggi specifiche che affrontano lo scraping, ma è stata una pratica comune e non contestata per molto tempo. La clausola sul Text and Data Mining nella Direttiva UE sul Copyright del 2019 implica fortemente che lo scraping sia generalmente legale.
I maggiori problemi legali non riguardano l'atto dello scraping ma ciò che accade dopo. Il copyright si applica ancora ai dati che raccogli dal web. Puoi conservare una copia personale, ma non puoi redistribuirla o rivenderla, non senza potenziali problemi legali.
Fare web scraping su larga scala significa quasi sempre fare copie di "dati personali", come definito in varie leggi sulla protezione dei dati e sulla privacy. Il GDPR europeo (General Data Protection Regulation) definisce i "dati personali" come:
[Q]ualsiasi informazione riguardante una persona fisica identificata o identificabile ('interessato'); si considera identificabile la persona fisica che può essere identificata, direttamente o indirettamente, in particolare mediante riferimento a un identificatore come il nome, un numero di identificazione, dati relativi all'ubicazione, un identificativo online o a uno o più elementi caratteristici della sua identità fisica, fisiologica, genetica, psichica, economica, culturale o sociale;
[GDPR, Art. 4.1]
Se possiedi un archivio di dati personali riguardanti qualsiasi persona residente nell'UE o attività che si svolge nell'UE, hai responsabilità legali ai sensi del GDPR. Il suo ambito è così ampio che dovresti presumere che sia vero per qualsiasi grande raccolta di dati. Non importa se hai raccolto tu i dati o qualcun altro, se li hai ora, ne sei responsabile. Se non adempi ai tuoi obblighi GDPR, l'UE può punirti indipendentemente dal paese in cui vivi o dove i dati sono archiviati o elaborati.
Il PIPEDA canadese (Personal Information Protection and Electronic Documents Act) è simile al GDPR. L'APPI giapponese (Act on the Protection of Personal Information) copre gran parte dello stesso terreno. Il Regno Unito ha incorporato la maggior parte degli elementi del GDPR nelle proprie leggi nazionali dopo l'uscita dall'UE, e a meno che non vengano modificate in seguito, sono ancora in vigore.
Gli Stati Uniti non hanno una legge comparabile sulla protezione dei dati a livello federale, ma il CCPA (California Consumer Privacy Act) ha termini simili al GDPR e si applica se hai dati su persone o attività nello stato della California.
La maggior parte dei paesi sviluppati ha leggi sulla protezione dei dati che limitano, almeno in alcuni aspetti, ciò che puoi fare con raccolte massive di dati dal web. La maggior parte dei procedimenti legali in tutto il mondo riguardanti lo scraping hanno riguardato come i dati sono stati utilizzati, non come sono stati raccolti.
Quindi, il web scraping è quasi sempre legale. È quello che succede dopo che diventa complicato.
tagÈ Legale Addestrare l'AI dallo Scraping?
Probabilmente.
Uno scraping del web includerà, in quasi tutti i casi realistici, contenuti protetti da copyright. La vera domanda è: Si possono utilizzare contenuti protetti da copyright per addestrare un'AI senza il permesso del proprietario?
Ci sono molti punti legali individuali che non sono completamente risolti, ma:
- In Europa, l'Articolo 4 della Direttiva UE sul Copyright del 2019 sembra renderlo legale con alcune limitazioni.
- In Giappone, l'Articolo 30(4) della Legge sul Copyright, modificato nel 2018, è stato interpretato come permissivo nell'uso di opere protette da copyright per addestrare l'AI senza autorizzazione.
- Negli Stati Uniti, nessuna legge affronta specificamente questa situazione, tuttavia, è stato dato per scontato per molti anni che l'analisi statistica di materiali protetti da copyright sia legale, anche quando il risultato è un prodotto commerciale. Sebbene le cause Authors Guild, Inc. v. Google, Inc. e Authors Guild, Inc. v. HathiTrust non affrontino specificamente l'AI, espandono l'ambito del "fair use" secondo la legge statunitense in modo così ampio che è difficile vedere come l'addestramento dell'AI possa essere illegale. Il sistema legale americano non offre una risposta esplicita e diversi casi che mettono alla prova questa conclusione stanno facendo il loro corso nei tribunali.
Diverse giurisdizioni minori hanno anche stabilito che è legale e, per quanto ne so, nessuna l'ha finora dichiarato illegale.
La legge europea sul copyright permette ai proprietari di dati protetti da copyright di limitare l'uso delle loro opere per l'addestramento dell'AI indicandolo "in modo appropriato". Attualmente non ci sono linee guida su come dovrebbero farlo.
La legge giapponese sul copyright limita l'uso di materiali protetti da copyright dove potrebbe "pregiudicare irragionevolmente gli interessi del titolare del copyright". Questo tipicamente indica che un titolare del copyright dovrebbe dimostrare come uno specifico modello di AI riduca il valore economico della loro opera per poter presentare un caso.
Dobbiamo notare che Google, Microsoft, OpenAI, Adobe e Shutterstock hanno offerto di indennizzare qualsiasi utente dei loro prodotti di AI generativa che affronta una sfida legale per motivi di copyright. Questo è un forte indizio che i loro avvocati pensano che ciò che stanno facendo sia legale secondo la legge americana.
tagCosa Significa lo Scraping Vorace per l'AI
La corsa allo scraping dell'AI sta trasformando il web in un Far West digitale. Questi scraper stanno trattando il robots.txt come se fosse cosa del passato, bombardando siti web come iFixit con infinite richieste. Non è solo fastidioso - è potenzialmente un problema che può compromettere il web e ci sta costringendo a ripensare come funziona l'internet aperto. O come potrebbe non funzionare nel prossimo futuro. Solo dal punto di vista economico e sociale, ci sono così tante cose che potrebbero cambiare:
Crollo della fiducia: Questa frenesia di alimentazione dell'AI potrebbe portare a un massiccio crollo della fiducia in tutto il web. Immagina un futuro dove ogni sito web ti accoglie con occhio scettico, costringendoti a dimostrare che sei umano prima di poter anche solo dare un'occhiata ai loro contenuti. Parliamo di più CAPTCHA, più muri di login, più test "clicca su tutti i semafori". È come cercare di entrare in uno speakeasy, ma invece di una password segreta, devi convincere il buttafuori che non sei una macchina molto intelligente.
Contenuti generati da umani limitati: I creatori di contenuti, già diffidenti del fatto che il loro lavoro venga rubato, stanno iniziando a chiudere i battenti. Potremmo vedere un'ondata di paywall, sezioni solo per abbonati e blocchi dei contenuti. I giorni di navigazione e apprendimento liberi potrebbero diventare un ricordo nostalgico, come i suoni del modem dial-up o i messaggi di assenza di AIM. Se gli umani normali non possono accedervi, diventa ancora più difficile per uno scraper fuorilegge entrarvi.
Casi legali: Potrebbero volerci anni o addirittura decenni prima che tutte le questioni legali riguardanti l'AI siano risolte. Abbiamo avuto Internet per circa trent'anni, e alcune delle sue questioni legali sono ancora in sospeso oggi. Che tu abbia ragione o no, se non puoi permetterti di passare anni in tribunale per scoprire cosa è permesso e cosa no, hai di che preoccuparti.
I piccoli falliscono, i ricchi si arricchiscono: Questa frenesia di scraping non è solo un fastidio - sta mettendo una vera pressione sull'infrastruttura web. I siti che affrontano ingorghi di traffico causati dall'AI potrebbero dover passare a server più potenti, il che non è economico. I siti più piccoli e i progetti appassionati potrebbero essere esclusi dal gioco, lasciandoci con un web (e dati di training per LLM) dominato da chi è abbastanza grande da resistere alla tempesta o firmare accordi di licenza con le aziende di AI. È uno scenario di "sopravvivenza del più ricco" che potrebbe rendere internet (e la conoscenza degli LLM) molto meno diversificato e interessante. Chiudendo la porta ai dati liberamente disponibili, possono poi far pagare una quota d'ingresso alle corporazioni di AI, o semplicemente concedere la licenza al miglior offerente. Non hai i soldi? Il buttafuori ti mostrerà la porta.
tagI Dati Generati dall'AI al Salvataggio?
L'acquisizione di dati non sta solo scuotendo i siti web - sta preparando il terreno per una potenziale carestia di conoscenza dell'AI. Mentre il web aperto alza i suoi ponti levatoi, i modelli di AI si troveranno a morire di fame per dati freschi e di alta qualità.
Questa scarsità di dati potrebbe portare a un brutto caso di visione a tunnel dell'AI. Senza un flusso costante di nuove informazioni, i modelli di AI rischiano di diventare camere d'eco di conoscenze obsolete. Immagina di chiedere a un'AI di eventi attuali e ricevere risposte che sembrano dell'anno scorso - o peggio, di un universo parallelo dove i fatti sono andati in vacanza.
Se i dati generati dagli umani sono chiusi a chiave, le aziende devono comunque ottenere i loro dati di training da qualche parte. Un esempio di questo sono i dati sintetici: Dati creati da LLM per addestrare altri LLM. Questo include tecniche ampiamente utilizzate come la distillazione del modello e la generazione di dati di training per compensare il bias.

Usare dati sintetici significa non dover passare attraverso ostacoli per ottenere licenze di dati generati dagli umani, che come abbiamo visto sta diventando sempre più difficile. Aiuta anche a bilanciare le cose - molti dati su internet non rappresentano la diversità del mondo reale. Generare dati sintetici può aiutare a rendere un modello più rappresentativo della realtà (o a volte no). Infine, per i casi d'uso sanitari e legali, i dati sintetici eliminano la necessità di sanificare i dati per rimuovere le informazioni personalmente identificabili.
Tuttavia, il rovescio della medaglia è che i modelli futuri saranno anche addestrati su dati generati dall'AI che davvero non vorresti usare per addestrarli, ovvero lo "Slop": dati di bassa qualità generati dall'AI, come un blog tecnologico un tempo amato che ora pubblica articoli di basso valore generati dall'AI sotto i nomi del suo vecchio staff, ricette generate dall'AI per piatti improbabili come mojito nella pentola a cottura lenta e gelato al bratwurst, o Gesù Gamberetto che invade Facebook.
Poiché questo è molto più economico e facile da creare rispetto ai buoni vecchi contenuti artigianali, sta rapidamente inondando internet.
Basandoci su quello che vediamo oggi, i contenuti generati dall'AI stanno superando i contenuti generati dagli umani disponibili. GPT-5 sarà addestrato (in parte) su dati creati da GPT-4. GPT-6, a sua volta, sarà addestrato su dati creati da GPT-5. E così via, e così via.
tagIl Collasso del Modello e Come Evitarlo
Usare i propri output come input è dannoso sia per gli umani che per gli LLM. Anche se sei molto selettivo sulla quantità di dati sintetici che usi e sul tipo, non puoi garantire che il tuo modello non peggiori
Per i modelli di AI generativa nel loro insieme, il calo di qualità e diversità dell'output è sperimentalmente misurabile e avviene piuttosto rapidamente. I modelli di generazione di immagini sviluppano anomalie dopo poche generazioni, e in un articolo, un modello linguistico di grandi dimensioni addestrato su dati di Wikipedia che dava risposte coerenti e accurate ai prompt, alla nona generazione di addestramento sui propri output, rispondeva ai prompt ripetendo le parole "lepri dalla coda" più e più volte.
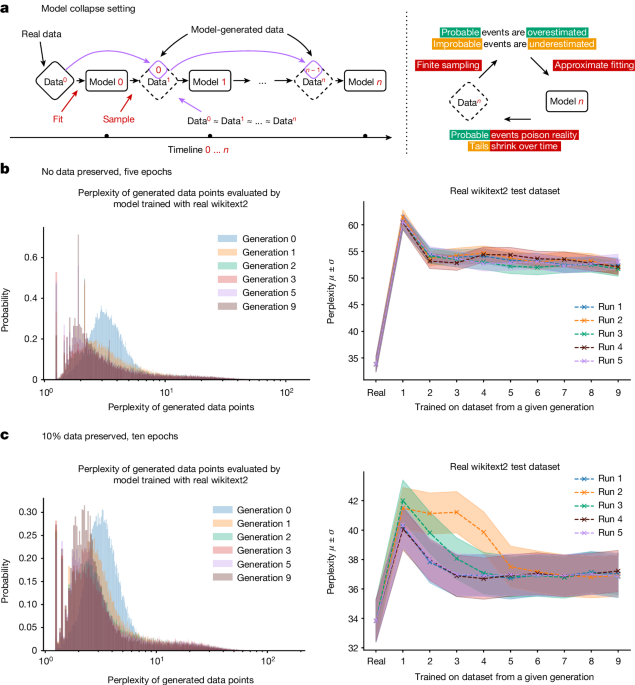
È abbastanza semplice da spiegare: un modello AI è un'approssimazione dei suoi dati di addestramento. Un modello AI addestrato sull'output di un modello AI è un'approssimazione di un'approssimazione. Ad ogni ciclo di addestramento, la differenza tra l'approssimazione e i dati "veri" del mondo reale diventa sempre più grande.
Lo chiamiamo "collasso del modello".
Man mano che i dati generati dall'AI diventano sempre più diffusi, addestrare nuovi modelli da dati raccolti da Internet rischia di ridurre le prestazioni del modello. Abbiamo ragione di credere che finché la quantità di dati reali, creati dall'uomo, non diminuisce, i nostri modelli non peggioreranno molto, ma non miglioreranno nemmeno. Tuttavia, richiederanno più tempo per l'addestramento se non riusciamo a separare i dati creati dall'AI da quelli creati dall'uomo. I nuovi modelli diventeranno più costosi da realizzare, senza miglioramenti.
L'ironia qui è forte. L'appetito vorace dell'AI per i dati potrebbe portare a una carestia di dati. Il Disturbo dell'Autofagia del Modello è come la malattia della mucca pazza per l'AI: proprio come nutrire le mucche con scarti di manzo ha portato a un nuovo tipo di malattia cerebrale parassitaria, addestrare l'AI con quantità crescenti di output AI porta a patologie mentali devastanti.
La buona notizia è che l'AI non può permettersi di sostituire l'umanità perché ha bisogno dei nostri dati. La cattiva notizia è che potrebbe ostacolare la propria crescita rovinando le sue fonti di dati.
Per evitare questa prevedibile carestia di conoscenza AI, dobbiamo ripensare a come addestriamo e utilizziamo i modelli AI. Stiamo già vedendo soluzioni come la Retrieval-Augmented Generation, che cerca di evitare l'uso di modelli AI come fonte di informazioni fattuali e li vede invece come dispositivi per valutare e riorganizzare fonti di informazioni esterne. Un'altra via da seguire è attraverso la specializzazione, dove adattiamo i modelli per eseguire specifiche classi di compiti, utilizzando dati di addestramento curati focalizzati su domini ristretti. Potremmo sostituire i presunti modelli per scopi generali come ChatGPT con AI specializzate: LawLLM, MedLLM, MyLittlePonyLLM, e così via.
Ci sono altre possibilità, ed è difficile dire quali nuove tecniche scopriranno i ricercatori. Forse c'è un modo migliore per generare dati sintetici o modi per ottenere modelli migliori da meno dati. Ma non c'è garanzia che più ricerca risolverà il problema.
Alla fine, questa sfida potrebbe costringere la comunità AI a diventare creativa. Dopotutto, la necessità è la madre dell'invenzione, e un panorama AI affamato di dati potrebbe innescare alcune soluzioni veramente innovative. Chi lo sa? La prossima grande svolta nell'AI potrebbe non venire da più dati, ma dal capire come fare di più con meno.
tagCosa succede se solo le Megacorporation possono permettersi lo scraping?
Per molte persone oggi, internet è Facebook, Instagram e X, visti attraverso un rettangolo di vetro nero che tengono in mano. È omogeneizzato, "sicuro" e controllato da guardiani che decidono (attraverso politiche e i loro algoritmi) cosa (e chi) vedi e cosa no.
Non è sempre stato così. Solo un paio di decenni fa avevamo blog generati dagli utenti, siti web indipendenti e molto altro. Negli anni Ottanta, c'erano decine di sistemi operativi e standard hardware in competizione. Ma entro gli anni 2010, Apple e Microsoft avevano vinto la partita, iniziando la tendenza all'omogeneizzazione.
Vediamo la stessa cosa con i browser web, gli smartphone e i social media. Iniziamo con un'esplosione di diversità e nuove idee prima che i grandi giocatori si accaparrino la palla e rendano difficile per chiunque altro competere.
Detto questo, mentre quei giocatori avevano un monopolio, alcuni pesci più piccoli sono comunque riusciti a entrare. (Prendi Linux e Firefox, per esempio). "Il perdente che ce la fa" è improbabile che accada con gli LLM però. Quando i piccoli attori non hanno la forza finanziaria per accedere a dati di addestramento vari e aggiornati, non possono creare modelli di alta qualità. E senza questo, come possono rimanere in attività?
I giganti hanno le risorse per mantenere i loro modelli AI a nutrirsi con una dieta costante di informazioni fresche, anche mentre il web più ampio stringe la cinghia. Nel frattempo, i piccoli attori e le startup sono lasciati a raschiare il fondo del barile dei dati, lottando per nutrire i loro algoritmi con briciole stantie. È un divario di conoscenza che potrebbe aumentare a valanga. Mentre i ricchi di dati diventano più ricchi in intuizioni e capacità, i poveri di dati rischiano di rimanere sempre più indietro, con le loro AI che diventano più obsolete e meno competitive giorno dopo giorno. Non si tratta solo di chi ha i giocattoli AI più lucenti - si tratta di chi può plasmare il futuro della tecnologia, del commercio e persino di come accediamo alle informazioni. Stiamo guardando verso un futuro dove una manciata di colossi tecnologici potrebbe detenere le chiavi dei regni AI più avanzati, mentre tutti gli altri sono lasciati a sbirciare dal medioevo digitale.
Con tutti i contenuti succulenti che galleggiano in giro per essere concessi in licenza, è improbabile che una sola Megacorporation sarà quella che li concederà tutti in licenza, come Netflix nei vecchi tempi. Ti ricordi? Ti iscrivevi a un servizio e ottenevi ogni show che avevi mai sognato. Oggi, gli show sono sparsi tra Hulu, Netflix, Disney+ e come stanno chiamando HBO Max questa settimana. A volte uno show che ami può semplicemente evaporare nell'etere. Questo potrebbe essere il futuro degli LLM: Google ha accesso prioritario a Reddit, mentre OpenAI ottiene accesso al Financial Times. iFixit? Quei dati semplicemente non esistono più, sono solo memorizzati come embedding polverosi, e mai aggiornati. Invece di un modello per dominarli tutti, potremmo guardare verso una frammentazione e capacità mutevoli mentre i diritti di licenza vengono giocolati tra i fornitori di AI.
tagIn Conclusione
Lo scraping è destinato a rimanere, che ci piaccia o no. I fornitori di contenuti stanno già erigendo barriere per limitare l'accesso, aprendo le porte solo a chi può permettersi di acquistare le licenze dei contenuti. Questo limita gravemente le risorse da cui ogni LLM può apprendere e, allo stesso tempo, le aziende più piccole vengono escluse dalla guerra delle offerte per i contenuti redditizi, mentre il resto del bottino viene spartito tra gli LLM dei colossi tecnologici. È come il mondo post-Netflix dello streaming che si ripete, solo che questa volta riguarda la conoscenza.
Mentre i dati generati dall'uomo diminuiscono, il "pattume" generato dall'AI è in forte crescita. Addestrare i modelli su questi contenuti può portare a un rallentamento del miglioramento o persino al collasso del modello. L'unico modo per risolvere il problema è pensare fuori dagli schemi - qualcosa per cui le startup, con la loro cultura dell'innovazione e della disruption, sono idealmente adatte. Tuttavia, proprio i dati che vengono concessi in licenza solo ai grandi player sono l'elemento vitale di cui queste startup hanno bisogno per sopravvivere.
Limitando l'accesso equo ai dati, le mega-corporazioni non stanno solo soffocando la competizione - stanno soffocando il futuro stesso dell'AI, strangolando proprio quell'innovazione che potrebbe portarci oltre questo potenziale medioevo digitale.
La rivoluzione dell'AI non è il futuro, l'AI è adesso. Nelle parole di William Gibson: "[I]l futuro è già qui, solo che non è distribuito in modo uniforme." E potrebbe facilmente diventare ancora più disegualmente distribuito.
