

Recentemente ho esaminato DSPy, un framework all'avanguardia sviluppato dal gruppo Stanford NLP volto all'ottimizzazione algoritmica dei prompt per i modelli linguistici (LM). Negli ultimi tre giorni, ho raccolto alcune prime impressioni e spunti preziosi su DSPy. Si noti che le mie osservazioni non intendono sostituire la documentazione ufficiale di DSPy. In effetti, consiglio vivamente di leggere la loro documentazione e il README almeno una volta prima di approfondire questo post. La mia discussione qui riflette una comprensione preliminare di DSPy, avendo trascorso alcuni giorni ad esplorarne le capacità. Ci sono diverse funzionalità avanzate, come DSPy Assertions, Typed Predictor e il tuning dei pesi LM, che non ho ancora esplorato a fondo.
 stanfordnlp
stanfordnlpNonostante il mio background con Jina AI, che si concentra principalmente sulle fondamenta della ricerca, il mio interesse per DSPy non è stato direttamente guidato dal suo potenziale nella Retrieval-Augmented Generation (RAG). Piuttosto, ero incuriosito dalla possibilità di sfruttare DSPy per il tuning automatico dei prompt per affrontare alcuni task di generazione.
Se sei nuovo a DSPy e cerchi un punto di ingresso accessibile, o se hai già familiarità con il framework ma trovi la documentazione ufficiale confusa o travolgente, questo articolo è pensato per te. Ho anche scelto di non aderire strettamente all'idioma di DSPy, che potrebbe sembrare scoraggiante per i principianti. Detto questo, approfondiamo.
tagCosa mi piace di DSPy
tagDSPy chiude il ciclo del Prompt Engineering
Ciò che mi entusiasma di più di DSPy è il suo approccio alla chiusura del ciclo del prompt engineering, trasformando quello che spesso è un processo manuale, artigianale in un workflow di machine learning strutturato e ben definito: ovvero preparare dataset, definire il modello, addestrare, valutare e testare. A mio parere, questo è l'aspetto più rivoluzionario di DSPy.
Viaggiando nella Bay Area e parlando con molti founder di startup focalizzate sulla valutazione degli LLM, ho incontrato frequenti discussioni su metriche, allucinazioni, osservabilità e compliance. Tuttavia, queste conversazioni spesso non progrediscono verso i passaggi critici successivi: Con tutte queste metriche in mano, cosa facciamo dopo? Può modificare la formulazione nei nostri prompt, nella speranza che certe parole magiche (ad esempio "mia nonna sta morendo") possano migliorare le nostre metriche, essere considerato un approccio strategico? Questa domanda è rimasta senza risposta da parte di molte startup di valutazione LLM, ed era una domanda a cui non potevo rispondere nemmeno io, fino a quando non ho scoperto DSPy. DSPy introduce un metodo chiaro e programmatico per ottimizzare i prompt basati su metriche specifiche, o persino per ottimizzare l'intera pipeline LLM, inclusi sia i prompt che i pesi LLM.
Harrison, il CEO di LangChain, e Logan, l'ex Head of Developer Relations di OpenAI, hanno entrambi affermato nel podcast Unsupervised Learning che il 2024 sarà un anno cruciale per la valutazione degli LLM. È per questo motivo che credo che DSPy meriti più attenzione di quella che sta ricevendo ora, poiché DSPy fornisce il cruciale pezzo mancante del puzzle.
tagDSPy separa la logica dalla rappresentazione testuale
Un altro aspetto di DSPy che mi impressiona è che formula il prompt engineering in un modulo riproducibile e LLM-agnostico. Per raggiungere questo obiettivo, estrae la logica dal prompt, creando una chiara separazione delle responsabilità tra la logica e la rappresentazione testuale, come illustrato di seguito.
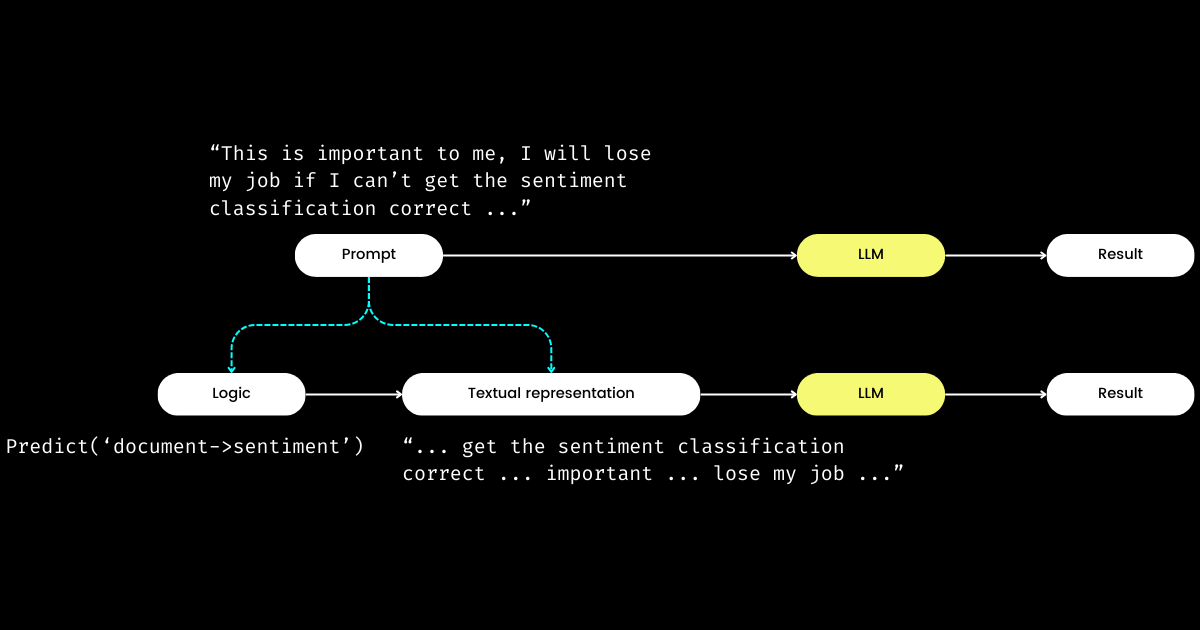
dspy.Module,) e nella sua rappresentazione testuale. La logica è immutabile, riproducibile, testabile e LLM-agnostica. La rappresentazione testuale è solo la conseguenza della logica.Il concetto di DSPy della logica come "causa" immutabile, testabile e LLM-agnostica, con la rappresentazione testuale meramente come sua "conseguenza", può inizialmente sembrare sconcertante. Questo è particolarmente vero alla luce della diffusa convinzione che "il futuro del linguaggio di programmazione è il linguaggio naturale." Abbracciando l'idea che "il prompt engineering è il futuro", si potrebbe sperimentare un momento di confusione nell'incontrare la filosofia di design di DSPy. Contrariamente all'aspettativa di semplificazione, DSPy introduce una serie di moduli e sintassi di signature, apparentemente facendo regredire il prompting in linguaggio naturale alla complessità della programmazione in C!
Ma perché adottare questo approccio? Secondo la mia comprensione, al cuore della programmazione dei prompt risiede la logica fondamentale, con la comunicazione che funge da amplificatore, potenzialmente migliorando o diminuendo la sua efficacia. La direttiva "Do sentiment classification" rappresenta la logica fondamentale, mentre una frase come "Follow these demonstrations or I will fire you" è un modo per comunicarla. Analogamente alle interazioni nella vita reale, le difficoltà nel portare a termine le cose spesso non derivano da una logica difettosa ma da comunicazioni problematiche. Questo spiega perché molti, in particolare i non madrelingua, trovano difficile il prompt engineering. Ho osservato ingegneri software altamente competenti nella mia azienda lottare con il prompt engineering, non per mancanza di logica, ma perché non "parlano il linguaggio." Separando la logica dal prompt, DSPy permette la programmazione deterministica della logica attraverso dspy.Module, consentendo agli sviluppatori di concentrarsi sulla logica nello stesso modo in cui farebbero nell'ingegneria tradizionale, indipendentemente dall'LLM utilizzato.
Quindi, se gli sviluppatori si concentrano sulla logica, chi gestisce la rappresentazione testuale? DSPy assume questo ruolo, utilizzando i tuoi dati e le metriche di valutazione per raffinare la rappresentazione testuale—tutto, dalla determinazione del focus narrativo all'ottimizzazione dei suggerimenti e alla scelta di buone dimostrazioni. Sorprendentemente, DSPy può persino utilizzare le metriche di valutazione per fare il fine-tuning dei pesi LLM!
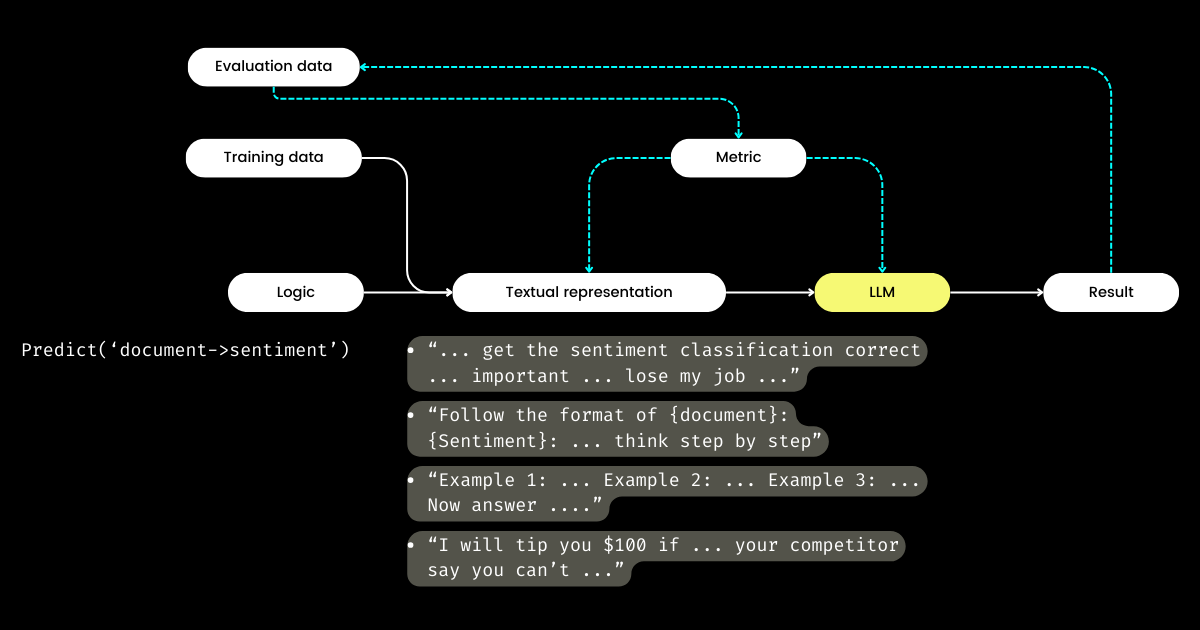
Per me, i contributi chiave di DSPy—chiudere il ciclo di training e valutazione nel prompt engineering e separare la logica dalla rappresentazione testuale—sottolineano la sua potenziale importanza per i sistemi LLM/Agent. Una visione ambiziosa sicuramente, ma decisamente necessaria!
tagCosa penso che DSPy possa migliorare
Innanzitutto, DSPy presenta una ripida curva di apprendimento per i principianti a causa dei suoi idiomi. Termini come signature, module, program, teleprompter, optimization e compile possono essere travolgenti. Anche per coloro che sono esperti nel prompt engineering, navigare tra questi concetti all'interno di DSPy può essere un labirinto impegnativo.
Questa complessità riflette la mia esperienza con Jina 1.0, dove abbiamo introdotto una serie di idiomi come chunk, document, driver, executor, pea, pod, querylang e flow (abbiamo persino creato degli adorabili adesivi per aiutare gli utenti a ricordare!).






La maggior parte di questi concetti iniziali sono stati rimossi nelle successive revisioni di Jina. Oggi, solo Executor, Document e Flow sono sopravvissuti alla "grande purga". Abbiamo aggiunto un nuovo concetto, Deployment, in Jina 3.0; quindi alla fine si pareggia. 🤷
Questo problema non è esclusivo di DSPy o Jina; ricordiamo i molteplici concetti e astrazioni introdotti da TensorFlow tra le versioni 0.x e 1.x. Credo che questo problema emerga spesso nelle prime fasi dei framework software, dove c'è una spinta a riflettere le notazioni accademiche direttamente nel codice per garantire la massima accuratezza e riproducibilità. Tuttavia, non tutti gli utenti apprezzano tali astrazioni granulari, con preferenze che variano dal desiderio di semplici one-liner alle richieste di maggiore flessibilità. Ho discusso ampiamente questo tema dell'astrazione nei framework software in un post del blog del 2020, che i lettori interessati potrebbero trovare utile.


In secondo luogo, la documentazione di DSPy talvolta manca di coerenza. Termini come module e program, teleprompter e optimizer, o optimize e compile (a volte riferiti come training o bootstrapping) sono usati in modo intercambiabile, aumentando la confusione. Di conseguenza, ho trascorso le mie prime ore con DSPy cercando di decifrare esattamente cosa optimizes e in cosa consiste il processo di bootstrapping.
Nonostante questi ostacoli, man mano che ci si addentra in DSPy e si rivede la documentazione, è probabile che si sperimentino momenti di chiarezza in cui tutto inizia ad avere senso, rivelando le connessioni tra la sua terminologia unica e i costrutti familiari visti in framework come PyTorch. Tuttavia, DSPy ha indubbiamente margini di miglioramento nelle versioni future, in particolare nel rendere il framework più accessibile agli ingegneri dei prompt senza un background in PyTorch.
tagOstacoli Comuni per i Principianti di DSPy
Nelle sezioni seguenti, ho compilato un elenco di domande che inizialmente hanno ostacolato il mio progresso con DSPy. Il mio obiettivo è condividere queste intuizioni nella speranza che possano chiarire sfide simili per altri studenti.
tagCosa sono teleprompter, optimization e compile? Cosa viene esattamente ottimizzato in DSPy?
In DSPy, "Teleprompters" è l'ottimizzatore (e sembra che @lateinteraction stia aggiornando la documentazione e il codice per chiarire questo). La funzione compile agisce al cuore di questo ottimizzatore, simile a chiamare optimizer.optimize(). Pensalo come l'equivalente del training in DSPy. Questo processo di compile() mira a ottimizzare:
- le dimostrazioni few-shot,
- le istruzioni,
- i pesi del LLM
Tuttavia, la maggior parte dei tutorial per principianti di DSPy non approfondisce l'ottimizzazione dei pesi e delle istruzioni, portando alla prossima domanda.
tagDi cosa si tratta il bootstrap in DSPy?
Bootstrap si riferisce alla creazione di dimostrazioni auto-generate per l'apprendimento in-context few-shot, una parte cruciale del processo compile() (cioè, ottimizzazione/training come ho menzionato sopra). Queste demo few-shot sono generate da dati etichettati forniti dall'utente; e una demo spesso consiste di input, output, ragionamento (ad esempio, nelle Catene di Pensiero), e input & output intermedi (per prompt multi-stadio). Naturalmente, le demo few-shot di qualità sono fondamentali per l'eccellenza dell'output. A tal fine, DSPy permette funzioni metriche definite dall'utente per garantire che vengano scelte solo le demo che soddisfano determinati criteri, portando alla prossima domanda.
tagCos'è la funzione metrica di DSPy?
Dopo l'esperienza pratica con DSPy, sono giunto a credere che la funzione metrica necessiti di molta più enfasi rispetto a quanto fornito dalla documentazione attuale. La funzione metrica in DSPy gioca un ruolo cruciale sia nelle fasi di valutazione che di training, fungendo anche da funzione di "loss", grazie alla sua natura implicita (controllata da trace=None):
def keywords_match_jaccard_metric(example, pred, trace=None):
# Jaccard similarity between example keywords and predicted keywords
A = set(normalize_text(example.keywords).split())
B = set(normalize_text(pred.keywords).split())
j = len(A & B) / len(A | B)
if trace is not None:
# act as a "loss" function
return j
return j > 0.8 # act as evaluationQuesto approccio differisce significativamente dal machine learning tradizionale, dove la funzione di loss è solitamente continua e differenziabile (ad esempio, hinge/MSE), mentre la metrica di valutazione potrebbe essere completamente diversa e discreta (ad esempio, NDCG). In DSPy, le funzioni di valutazione e di loss sono unificate nella funzione metrica, che può essere discreta e il più delle volte restituisce un valore booleano. La funzione metrica può anche integrare un LLM! Nell'esempio seguente, ho implementato un confronto fuzzy usando LLM per determinare se il valore predetto e la risposta standard sono simili in grandezza, ad esempio, "1 milione di dollari" e "$1M" restituirebbero vero.
class Assess(dspy.Signature):
"""Assess the if the prediction is in the same magnitude to the gold answer."""
gold_answer = dspy.InputField(desc='number, could be in natural language')
prediction = dspy.InputField(desc='number, could be in natural language')
assessment = dspy.OutputField(desc='yes or no, focus on the number magnitude, not the unit or exact value or wording')
def same_magnitude_correct(example, pred, trace=None):
return dspy.Predict(Assess)(gold_answer=example.answer, prediction=pred.answer).assessment.lower() == 'yes'Per quanto potente sia, la funzione metrica influenza significativamente l'esperienza utente di DSPy, determinando non solo la valutazione finale della qualità ma influenzando anche i risultati dell'ottimizzazione. Una funzione metrica ben progettata può portare a prompt ottimizzati, mentre una mal strutturata può causare il fallimento dell'ottimizzazione. Quando si affronta un nuovo problema con DSPy, potresti ritrovarti a dedicare tanto tempo alla progettazione della logica (cioè DSPy.Module) quanto alla funzione metrica. Questo duplice focus su logica e metriche può essere scoraggiante per i principianti.
tag"Bootstrapped 0 full traces after 20 examples in round 0" cosa significa?
Questo messaggio che appare silenziosamente durante compile() merita la massima attenzione, poiché significa essenzialmente che l'ottimizzazione/compilazione è fallita, e il prompt che ottieni non è migliore di un semplice few-shot. Cosa va storto? Ho riassunto alcuni suggerimenti per aiutarti a debuggare il tuo programma DSPy quando incontri questo messaggio:
La Tua Funzione Metrica è Incorretta
La funzione your_metric, usata in BootstrapFewShot(metric=your_metric), è implementata correttamente? Esegui alcuni unit test. your_metric restituisce mai True, o restituisce sempre False? Nota che restituire True è cruciale perché è il criterio che DSPy usa per considerare l'esempio bootstrappato come "successo." Se restituisci ogni valutazione come True, allora ogni esempio viene considerato un "successo" nel bootstrapping! Questo non è ideale, ovviamente, ma è così che puoi regolare la rigidità della funzione metrica per cambiare il risultato "Bootstrapped 0 full traces". Nota che sebbene la documentazione di DSPy indichi che le metriche possono restituire anche valori scalari, dopo aver esaminato il codice sottostante, non lo consiglierei ai principianti.
La Tua Logica (DSPy.Module) è Incorretta
Se la funzione metrica è corretta, allora devi controllare se la tua logica dspy.Module è implementata correttamente. Prima, verifica che la signature DSPy sia correttamente assegnata per ogni step. Le signature in-line, come dspy.Predict('question->answer'), sono facili da usare, ma per la qualità, suggerisco fortemente di implementare con signature basate su classi. In particolare, aggiungi alcune docstring descrittive alla classe, compila i campi desc per InputField e OutputField—questi forniscono tutti suggerimenti al LM su ogni campo. Di seguito ho implementato due DSPy.Module multi-stage per risolvere i problemi di Fermi, uno con signature in-line, uno con signature basata su classi.
class FermiSolver(dspy.Module):
def __init__(self):
super().__init__()
self.step1 = dspy.Predict('question -> initial_guess')
self.step2 = dspy.Predict('question, initial_guess -> calculated_estimation')
self.step3 = dspy.Predict('question, initial_guess, calculated_estimation -> variables_and_formulae')
self.step4 = dspy.ReAct('question, initial_guess, calculated_estimation, variables_and_formulae -> gathering_data')
self.step5 = dspy.Predict('question, initial_guess, calculated_estimation, variables_and_formulae, gathering_data -> answer')
def forward(self, q):
step1 = self.step1(question=q)
step2 = self.step2(question=q, initial_guess=step1.initial_guess)
step3 = self.step3(question=q, initial_guess=step1.initial_guess, calculated_estimation=step2.calculated_estimation)
step4 = self.step4(question=q, initial_guess=step1.initial_guess, calculated_estimation=step2.calculated_estimation, variables_and_formulae=step3.variables_and_formulae)
step5 = self.step5(question=q, initial_guess=step1.initial_guess, calculated_estimation=step2.calculated_estimation, variables_and_formulae=step3.variables_and_formulae, gathering_data=step4.gathering_data)
return step5Risolutore di problemi di Fermi che usa solo signature in-line
class FermiStep1(dspy.Signature):
question = dspy.InputField(desc='Fermi problems involve the use of estimation and reasoning')
initial_guess = dspy.OutputField(desc='Have a guess – don't do any calculations yet')
class FermiStep2(FermiStep1):
initial_guess = dspy.InputField(desc='Have a guess – don't do any calculations yet')
calculated_estimation = dspy.OutputField(desc='List the information you'll need to solve the problem and make some estimations of the values')
class FermiStep3(FermiStep2):
calculated_estimation = dspy.InputField(desc='List the information you'll need to solve the problem and make some estimations of the values')
variables_and_formulae = dspy.OutputField(desc='Write a formula or procedure to solve your problem')
class FermiStep4(FermiStep3):
variables_and_formulae = dspy.InputField(desc='Write a formula or procedure to solve your problem')
gathering_data = dspy.OutputField(desc='Research, measure, collect data and use your formula. Find the smallest and greatest values possible')
class FermiStep5(FermiStep4):
gathering_data = dspy.InputField(desc='Research, measure, collect data and use your formula. Find the smallest and greatest values possible')
answer = dspy.OutputField(desc='the final answer, must be a numerical value')
class FermiSolver2(dspy.Module):
def __init__(self):
super().__init__()
self.step1 = dspy.Predict(FermiStep1)
self.step2 = dspy.Predict(FermiStep2)
self.step3 = dspy.Predict(FermiStep3)
self.step4 = dspy.Predict(FermiStep4)
self.step5 = dspy.Predict(FermiStep5)
def forward(self, q):
step1 = self.step1(question=q)
step2 = self.step2(question=q, initial_guess=step1.initial_guess)
step3 = self.step3(question=q, initial_guess=step1.initial_guess, calculated_estimation=step2.calculated_estimation)
step4 = self.step4(question=q, initial_guess=step1.initial_guess, calculated_estimation=step2.calculated_estimation, variables_and_formulae=step3.variables_and_formulae)
step5 = self.step5(question=q, initial_guess=step1.initial_guess, calculated_estimation=step2.calculated_estimation, variables_and_formulae=step3.variables_and_formulae, gathering_data=step4.gathering_data)
return step5Risolutore di problemi di Fermi che usa signature basate su classi con descrizione più completa su ogni campo.
Inoltre, controlla la parte def forward(self, ). Per i Module multi-stage, assicurati che l'output (o tutti gli output come nel FermiSolver) dall'ultimo step sia fornito come input allo step successivo.
Il Tuo Problema è Semplicemente Troppo Difficile
Se sia la metrica che il modulo sembrano corretti, allora è possibile che il tuo problema sia semplicemente troppo impegnativo e la logica che hai implementato non sia sufficiente per risolverlo. Quindi, DSPy trova impossibile fare il bootstrap di qualsiasi demo data la tua logica e funzione metrica. A questo punto, ecco alcune opzioni che puoi considerare:
- Usa un LM più potente. Per esempio, sostituire
gpt-35-turbo-instructcongpt-4-turbocome LM studente, usa un LM più forte come insegnante. Questo può essere spesso molto efficace. Dopotutto, un modello più forte significa una migliore comprensione dei prompt. - Migliora la tua logica. Aggiungi o sostituisci alcuni step nel tuo
dspy.Modulecon altri più complicati. Ad esempio, sostituisciPredictconChainOfThoughtProgramOfThought, aggiungendo lo stepRetrieval. - Aggiungi più esempi di training. Se 20 esempi non sono sufficienti, punta a 100! Puoi quindi sperare che un esempio passi il controllo della metrica e venga scelto da
BootstrapFewShot. - Riformula il problema. Spesso, un problema diventa irrisolvibile quando la formulazione è incorretta. Ma se cambi angolazione per guardarlo, le cose potrebbero essere molto più facili e ovvie.
In pratica, il processo implica un mix di tentativi ed errori. Per esempio, ho affrontato un problema particolarmente impegnativo: generare un'icona SVG simile alle icone di Google Material Design basandomi su due o tre parole chiave. La mia strategia iniziale era utilizzare un semplice DSPy.Module che usa dspy.ChainOfThought('keywords -> svg'), associato a una funzione metrica che valutava la somiglianza visiva tra l'SVG generato e l'SVG Material Design di riferimento, simile a un algoritmo pHash. Ho iniziato con 20 esempi di training, ma dopo il primo round, mi sono ritrovato con "Bootstrapped 0 full traces after 20 examples in round 0", indicando che l'ottimizzazione era fallita. Aumentando il dataset a 100 esempi, rivedendo il mio modulo per incorporare più stadi e aggiustando la soglia della funzione metrica, alla fine ho ottenuto 2 dimostrazioni bootstrappate e sono riuscito a ottenere alcuni prompt ottimizzati.
