

La ricerca accurata all'interno di codice e documentazione è più critica che mai. Siamo entusiasti di presentare il nostro ultimo modello di embedding nel mondo della programmazione: jina-embeddings-v2-base-code. Questo nuovo modello open-source per l'embedding di linguaggi di programmazione è progettato per migliorare il modo in cui gli sviluppatori interagiscono con il codice e la documentazione. Supportando l'inglese e 30 linguaggi di programmazione popolari, si distingue come l'unico modello open-source del suo genere che può gestire fino a 8.192 token in input. Il jina-embeddings-v2-base-code è ora disponibile su HuggingFace sotto licenza Apache 2.0 e può essere liberamente accessibile tramite la nostra Embedding API.
Visita Embedding API e seleziona jina-embeddings-v2-base-code dal menu a tendina. Goditi 1M token gratuiti.
tagPerché Sviluppare un Modello di Embedding per il Codice?
Gli sviluppatori si trovano spesso a navigare attraverso vasti repository di codice, non alla ricerca di errori, ma per localizzare funzionalità specifiche o comprendere come certi processi sono implementati. Questo compito può richiedere molto tempo e, a volte, è come cercare un ago in un pagliaio. Gli Integrated Development Environments (IDE) hanno migliorato significativamente questo processo fornendo strumenti e funzionalità che automatizzano la ricerca di informazioni. Tuttavia, esiste il potenziale per un ulteriore miglioramento, ed è qui che entra in gioco il nostro modello di embedding.
tagCasi d'Uso di jina-embeddings-v2-base-code
Integrando capacità di ricerca basate sull'AI, non stiamo solo potenziando le funzionalità esistenti negli IDE; stiamo trasformando il modo in cui gli sviluppatori interagiscono con i repository di codice. Questa tecnologia va oltre la semplice ricerca testuale, offrendo una comprensione semantica che può interpretare l'intento dietro una query, riducendo così significativamente il tempo e lo sforzo richiesti per le revisioni del codice, i test unitari e la gestione complessiva della qualità.
Navigazione del Codice Migliorata
- Formato Query: Descrizione in linguaggio naturale della funzionalità o dello snippet di codice che stai cercando.
- Formato Risultato Restituito: File di codice o snippet rilevanti dove la funzionalità descritta è implementata, insieme ad annotazioni o evidenziazioni che puntano alle parti specifiche del codice.
Revisione del Codice Semplificata
- Formato Query: Descrizione dei concetti o pattern di programmazione che vuoi revisionare nel repository.
- Formato Risultato Restituito: Un elenco di snippet di codice o pull request che corrispondono ai concetti, pattern o best practice descritti, permettendo ai revisori di concentrarsi sulle aree critiche per il miglioramento.
Assistenza Automatizzata alla Documentazione
- Formato Query: Snippet di codice per cui hai bisogno di documentazione o una spiegazione.
- Formato Risultato Restituito: Docstring o voci di documentazione suggerite che spiegano la funzionalità del codice, i parametri e i tipi di ritorno, rendendo più facile mantenere una documentazione aggiornata e completa.
Affrontando questi casi d'uso specifici, jina-embeddings-v2-base-code non solo migliora l'esperienza di sviluppo ma promuove anche un ambiente di programmazione più collaborativo ed efficiente.
tagBenchmark delle Prestazioni
In un campo dove precisione e accuratezza sono fondamentali, jina-embeddings-v2-base-code ha superato i suoi concorrenti, guidando il gruppo in nove su quindici benchmark cruciali di CodeNetSearch. Inoltre, il nostro modello mantiene punteggi altamente competitivi nei benchmark rimanenti. Se confrontato con i suoi concorrenti più vicini, inclusi quelli di giganti tecnologici come Microsoft e Salesforce, jina-embeddings-v2-base-code non solo si classifica più in alto ma mostra anche il suo design e le sue capacità superiori.
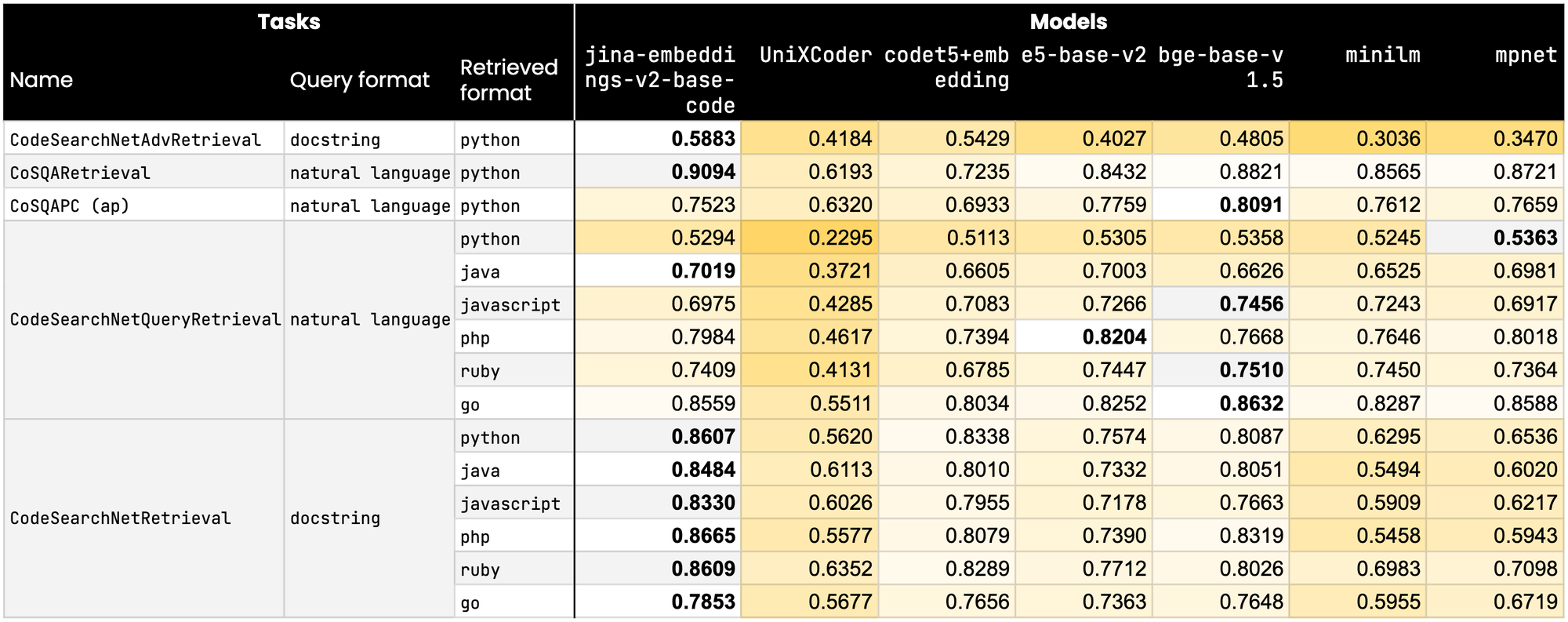
tagPunti di Forza del Modello
- Prestazioni allo Stato dell'Arte: Il nostro impegno per l'eccellenza si riflette nelle prestazioni dei modelli Jina Embedding, che costantemente dominano le classifiche dei benchmark rispetto ad altre offerte open-source e superano persino i modelli di Microsoft e Salesforce.
- Compatto ma Potente: Nel mondo dell'AI, l'efficienza è fondamentale. Con 161 milioni di parametri (307MB senza quantizzazione), jina-embeddings-v2-base-code è progettato per l'efficienza, offrendo prestazioni ad alta velocità e risparmi sui costi senza compromettere le capacità.
- Capacità di Contesto Estesa: La capacità di elaborare fino a 8192 token permette la gestione di funzioni di grandi dimensioni e numerosi file oggetto, fornendo una profondità di comprensione e un contesto che supera i limiti dei modelli che supportano solo poche centinaia di token.
tagIntegrazione API Senza Soluzione di Continuità
jina-embeddings-v2-base-code è progettato per una facile integrazione, supportando i principali database vettoriali come MongoDB, Qdrant e Weaviate, e framework come Haystack e LlamaIndex. Questo assicura che gli sviluppatori possano incorporare senza sforzo il nostro modello nei loro sistemi esistenti, sfruttando le sue capacità per migliorare i loro processi di recupero del codice e della documentazione.
Apprezziamo il vostro feedback su jina-embeddings-v2-base-code. Unitevi al nostro canale della community per contribuire con feedback e rimanere informati sui nostri progressi. Insieme, stiamo plasmando un futuro dell'AI più robusto e inclusivo.
