



Jina CLIP v1 (jina-clip-v1) è un nuovo modello di embedding multimodale che estende le capacità del modello CLIP originale di OpenAI. Con questo nuovo modello, gli utenti hanno un unico modello di embedding che offre prestazioni allo stato dell'arte sia nel recupero di solo testo che nel recupero cross-modale testo-immagine. Jina AI ha migliorato le prestazioni di OpenAI CLIP del 165% nel recupero di solo testo e del 12% nel recupero immagine-immagine, con prestazioni identiche o leggermente migliori nelle attività di testo-immagine e immagine-testo. Queste prestazioni migliorate rendono Jina CLIP v1 indispensabile per lavorare con input multimodali.
In questo articolo, discuteremo prima i limiti del modello CLIP originale e come li abbiamo affrontati utilizzando un metodo unico di co-training. Poi, dimostreremo l'efficacia del nostro modello su vari benchmark di recupero. Infine, forniremo istruzioni dettagliate su come gli utenti possono iniziare con Jina CLIP v1 tramite la nostra API Embeddings e Hugging Face.
tagL'Architettura CLIP per l'AI Multimodale
A gennaio 2021, OpenAI ha rilasciato il modello CLIP (Contrastive Language–Image Pretraining). CLIP ha un'architettura semplice ma ingegnosa: combina due modelli di embedding, uno per i testi e uno per le immagini, in un unico modello con un unico spazio di embedding di output. I suoi embedding di testo e immagine sono direttamente confrontabili tra loro, rendendo la distanza tra un embedding di testo e un embedding di immagine proporzionale a quanto bene quel testo descrive l'immagine, e viceversa.
Questo si è dimostrato molto utile nel recupero di informazioni multimodali e nella classificazione zero-shot delle immagini. Senza ulteriore training specifico, CLIP ha ottenuto buoni risultati nel collocare le immagini in categorie con etichette in linguaggio naturale.

Il modello di embedding del testo nel CLIP originale era una rete neurale personalizzata con solo 63 milioni di parametri. Per quanto riguarda le immagini, OpenAI ha rilasciato CLIP con una selezione di modelli ResNet e ViT. Ogni modello è stato pre-addestrato per la sua modalità individuale e poi addestrato con immagini con didascalie per produrre embedding simili per coppie immagine-testo preparate.
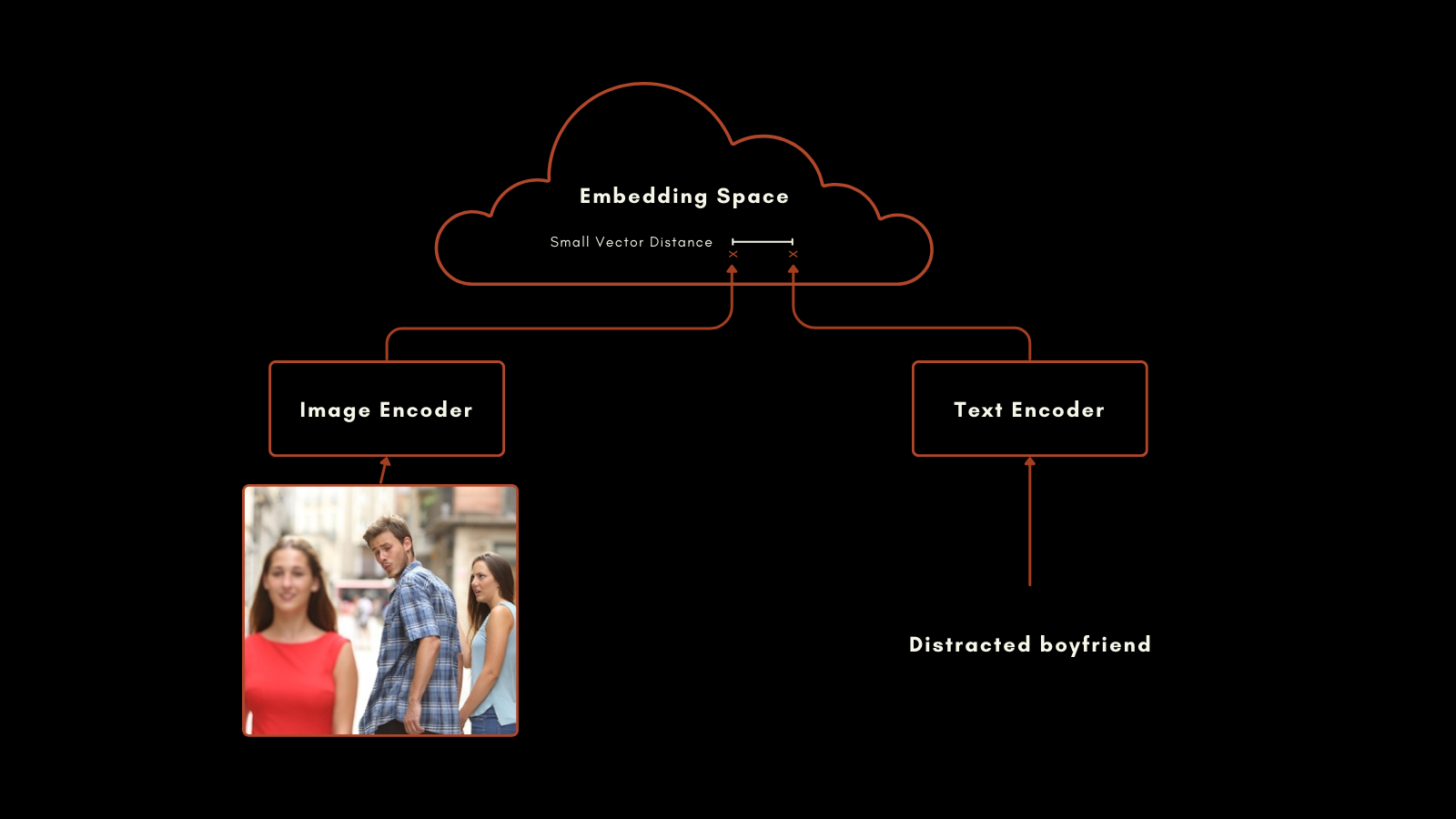
Questo approccio ha prodotto risultati impressionanti. Particolarmente notevoli sono le sue prestazioni nella classificazione zero-shot. Per esempio, anche se i dati di training non includevano immagini etichettate di astronauti, CLIP poteva identificare correttamente le immagini di astronauti basandosi sulla sua comprensione di concetti correlati nei testi e nelle immagini.
Tuttavia, CLIP di OpenAI ha due importanti limitazioni:
- La prima è la sua capacità di input testuale molto limitata. Può accettare un massimo di 77 token in input, ma l'analisi empirica mostra che nella pratica non usa più di 20 token per produrre i suoi embedding. Questo perché CLIP è stato addestrato da immagini con didascalie, e le didascalie tendono ad essere molto brevi. Questo contrasta con gli attuali modelli di embedding del testo che supportano diverse migliaia di token.
- Secondo, le prestazioni dei suoi embedding testuali in scenari di recupero di solo testo sono molto scarse. Le didascalie delle immagini sono un tipo molto limitato di testo e non riflettono l'ampia gamma di casi d'uso che ci si aspetterebbe che un modello di embedding del testo supporti.
Nella maggior parte dei casi d'uso reali, il recupero di solo testo e di immagine-testo sono combinati o almeno entrambi sono disponibili per le attività. Mantenere un secondo modello di embedding per attività di solo testo raddoppia effettivamente le dimensioni e la complessità del framework AI.
Il nuovo modello di Jina AI affronta direttamente questi problemi, e jina-clip-v1 sfrutta i progressi fatti negli ultimi anni per portare prestazioni allo stato dell'arte in compiti che coinvolgono tutte le combinazioni di modalità testo e immagine.
tagIntroduzione a Jina CLIP v1
Jina CLIP v1 mantiene lo schema originale di OpenAI CLIP: due modelli co-addestrati per produrre output nello stesso spazio di embedding.
Per la codifica del testo, abbiamo adattato l'architettura Jina BERT v2 utilizzata nei modelli Jina Embeddings v2. Questa architettura supporta una finestra di input di 8k token allo stato dell'arte e produce vettori a 768 dimensioni, producendo embedding più accurati da testi più lunghi. Questo è più di 100 volte i 77 token di input supportati nel modello CLIP originale.
Per gli embedding delle immagini, stiamo utilizzando l'ultimo modello della Beijing Academy for Artificial Intelligence: il modello EVA-02. Abbiamo empiricamente confrontato diversi modelli di AI per immagini, testandoli in contesti cross-modali con pre-training simile, e EVA-02 ha chiaramente superato gli altri. È anche paragonabile all'architettura Jina BERT nelle dimensioni del modello, quindi i carichi di calcolo per le attività di elaborazione di immagini e testo sono approssimativamente identici.
Queste scelte producono importanti benefici per gli utenti:
- Migliori prestazioni su tutti i benchmark e tutte le combinazioni modali, e specialmente grandi miglioramenti nelle prestazioni di embedding di solo testo.
- Le prestazioni empiricamente superiori di
EVA-02sia nei compiti immagine-testo che solo immagine, con il vantaggio aggiunto dell'addestramento addizionale di Jina AI, che migliora le prestazioni solo immagine. - Supporto per input di testo molto più lunghi. Il supporto per input di 8k token di Jina Embeddings rende possibile elaborare informazioni testuali dettagliate e correlarle con le immagini.
- Un grande risparmio netto in spazio, calcolo, manutenzione del codice e complessità perché questo modello multimodale è altamente performante anche in scenari non multimodali.
tagTraining
Parte della nostra ricetta per l'AI multimodale ad alte prestazioni sono i nostri dati di training e la procedura. Notiamo che la lunghezza molto breve dei testi usati nelle didascalie delle immagini è la causa principale delle scarse prestazioni di solo testo nei modelli stile CLIP, e il nostro training è esplicitamente progettato per rimediare a questo.
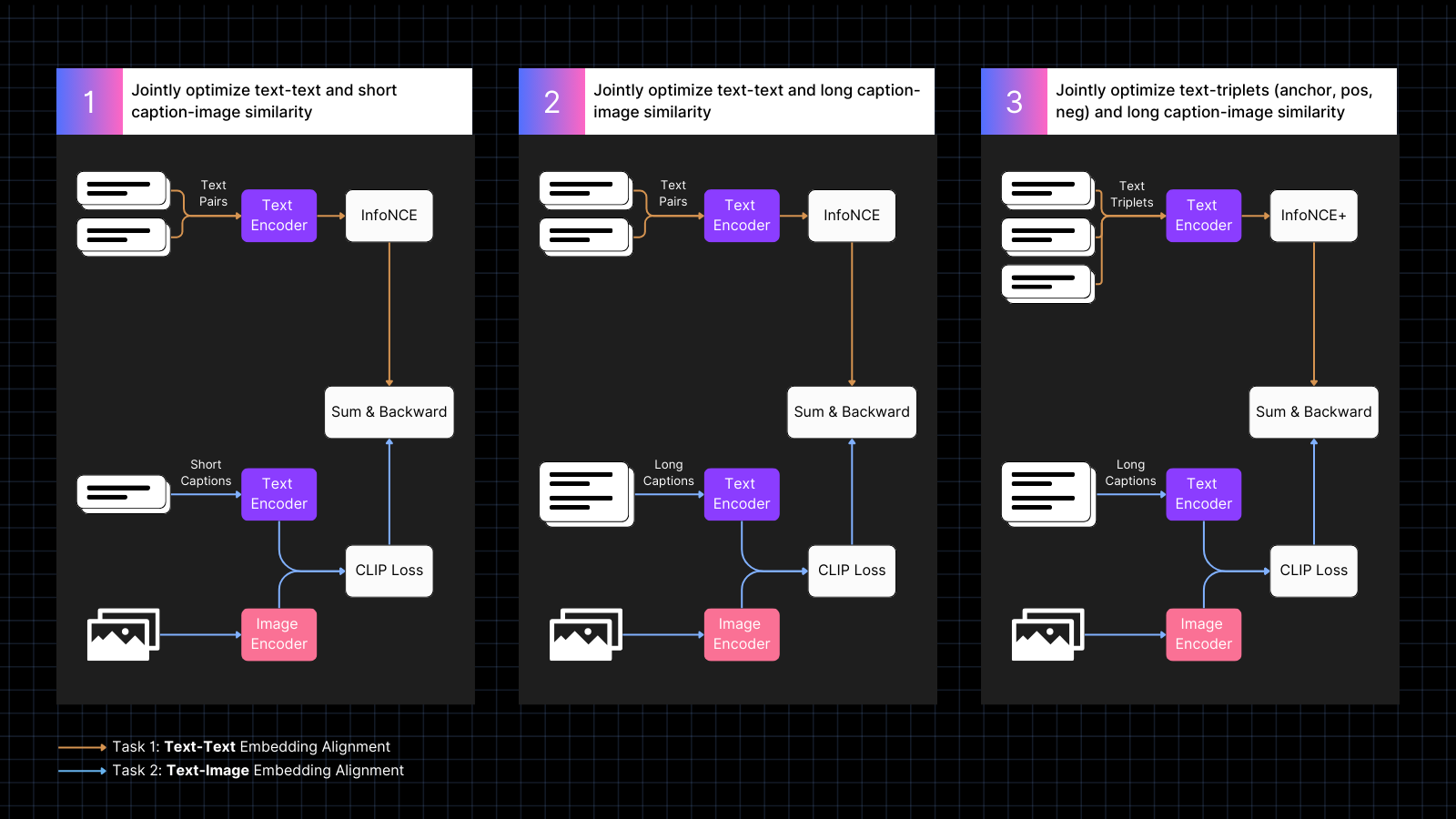
Il training avviene in tre fasi:
- Utilizzare dati di immagini con didascalie per imparare ad allineare gli embedding di immagini e testo, intervallati con coppie di testi con significati simili. Questo co-training ottimizza congiuntamente per i due tipi di compiti. Le prestazioni di solo testo del modello diminuiscono durante questa fase, ma non tanto quanto se avessimo addestrato solo con coppie immagine-testo.
- Addestrare utilizzando dati sintetici che allineano le immagini con testi più grandi, generati da un modello AI, che descrive l'immagine. Continuare l'addestramento con coppie di solo testo allo stesso tempo. Durante questa fase, il modello impara a prestare attenzione a testi più grandi in congiunzione con le immagini.
- Utilizzare triplette di testo con hard negative per migliorare ulteriormente le prestazioni di solo testo imparando a fare distinzioni semantiche più fini. Allo stesso tempo, continuare l'addestramento utilizzando coppie sintetiche di immagini e testi lunghi. Durante questa fase, le prestazioni di solo testo migliorano drasticamente senza che il modello perda alcuna capacità immagine-testo.
Per maggiori informazioni sui dettagli dell'addestramento e dell'architettura del modello, leggete il nostro recente articolo:
tagNuovo Stato dell'Arte negli Embedding Multimodali
Abbiamo valutato le prestazioni di Jina CLIP v1 in task di solo testo, solo immagini e cross-modali che coinvolgono entrambe le modalità di input. Abbiamo utilizzato il benchmark di recupero MTEB per valutare le prestazioni di solo testo. Per i task di sole immagini, abbiamo utilizzato il benchmark CIFAR-100. Per i task cross-modali, valutiamo su Flickr8k, Flickr30K e MSCOCO Captions, che sono inclusi nel CLIP Benchmark.
I risultati sono riassunti nella tabella seguente:
| Model | Text-Text | Text-to-Image | Image-to-Text | Image-Image |
|---|---|---|---|---|
| jina-clip-v1 | 0.429 | 0.899 | 0.803 | 0.916 |
| openai-clip-vit-b16 | 0.162 | 0.881 | 0.756 | 0.816 |
| % increase vs OpenAI CLIP |
165% | 2% | 6% | 12% |
Da questi risultati si può vedere che jina-clip-v1 supera il CLIP originale di OpenAI in tutte le categorie, ed è notevolmente migliore nel recupero di solo testo e sole immagini. In media su tutte le categorie, questo rappresenta un miglioramento del 46% nelle prestazioni.
Puoi trovare una valutazione più dettagliata nel nostro recente articolo.
tagIniziare con l'API degli Embedding
Puoi facilmente integrare Jina CLIP v1 nelle tue applicazioni utilizzando la Jina Embeddings API.
Il codice seguente mostra come chiamare l'API per ottenere embedding per testi e immagini, utilizzando il pacchetto requests in Python. Passa una stringa di testo e un URL a un'immagine al server Jina AI e restituisce entrambe le codifiche.
<YOUR_JINA_AI_API_KEY> con una chiave API Jina attivata. Puoi ottenere una chiave di prova con un milione di token gratuiti dalla pagina web Jina Embeddings.import requests
import numpy as np
from numpy.linalg import norm
cos_sim = lambda a,b: (a @ b.T) / (norm(a)*norm(b))
url = 'https://api.jina.ai/v1/embeddings'
headers = {
'Content-Type': 'application/json',
'Authorization': 'Bearer <YOUR_JINA_AI_API_KEY>'
}
data = {
'input': [
{"text": "Bridge close-shot"},
{"url": "https://fastly.picsum.photos/id/84/1280/848.jpg?hmac=YFRYDI4UsfbeTzI8ZakNOR98wVU7a-9a2tGF542539s"}],
'model': 'jina-clip-v1',
'encoding_type': 'float'
}
response = requests.post(url, headers=headers, json=data)
sim = cos_sim(np.array(response.json()['data'][0]['embedding']), np.array(response.json()['data'][1]['embedding']))
print(f"Cosine text<->image: {sim}")
tagIntegrazione con i principali Framework LLM
Jina CLIP v1 è già disponibile per LlamaIndex e LangChain:
- LlamaIndex: Usa
JinaEmbeddingcon la classe baseMultimodalEmbedding, e invocaget_image_embeddingsoget_text_embeddings. - LangChain: Usa
JinaEmbeddings, e invocaembed_imagesoembed_documents.
tagPrezzi
Sia gli input di testo che di immagini vengono addebitati per consumo di token.
Per il testo in inglese, abbiamo calcolato empiricamente che in media serviranno 1,1 token per ogni parola.
Per le immagini, contiamo il numero di tessere di 224x224 pixel necessarie per coprire l'immagine. Alcune di queste tessere potrebbero essere parzialmente vuote ma contano allo stesso modo. Ogni tessera costa 1.000 token da elaborare.
Esempio
Per un'immagine con dimensioni 750x500 pixel:
- L'immagine viene divisa in tessere di 224x224 pixel.
- Per calcolare il numero di tessere, prendere la larghezza in pixel e dividere per 224, poi arrotondare all'intero superiore.
750/224 ≈ 3,35 → 4 - Ripetere per l'altezza in pixel:
500/224 ≈ 2,23 → 3
- Per calcolare il numero di tessere, prendere la larghezza in pixel e dividere per 224, poi arrotondare all'intero superiore.
- Il numero totale di tessere richieste in questo esempio è:
4 (orizzontale) x 3 (verticale) = 12 tessere - Il costo sarà 12 x 1.000 = 12.000 token
tagSupporto Enterprise
Stiamo introducendo un nuovo beneficio per gli utenti che acquistano il piano Production Deployment con 11 miliardi di token. Questo include:
- Tre ore di consulenza con i nostri team di prodotto e ingegneria per discutere i vostri casi d'uso e requisiti specifici.
- Un notebook Python personalizzato progettato per il vostro caso d'uso RAG (Retrieval-Augmented Generation) o ricerca vettoriale, che dimostra come integrare i modelli di Jina AI nella vostra applicazione.
- Assegnazione a un account executive e supporto email prioritario per garantire che le vostre esigenze siano soddisfatte tempestivamente ed efficacemente.
tagJina CLIP v1 Open-Source su Hugging Face
Jina AI è impegnata in una base di ricerca open-source, e per questo scopo, stiamo rendendo questo modello disponibile gratuitamente sotto una licenza Apache 2.0, su Hugging Face.
Puoi trovare il codice di esempio per scaricare ed eseguire questo modello sul tuo sistema o installazione cloud nella pagina del modello Hugging Face per jina-clip-v1.

tagRiepilogo
L'ultimo modello di Jina AI — jina-clip-v1 — rappresenta un significativo avanzamento nei modelli di embedding multimodali, offrendo sostanziali miglioramenti delle prestazioni rispetto al CLIP di OpenAI. Con notevoli miglioramenti nei task di recupero di solo testo e sole immagini, oltre a prestazioni competitive nei task di testo-a-immagine e immagine-a-testo, si presenta come una soluzione promettente per casi d'uso complessi di embedding.
Questo modello attualmente supporta solo testi in lingua inglese a causa dei limiti di risorse. Stiamo lavorando per espandere le sue capacità ad altre lingue.
