


Oggi siamo entusiasti di annunciare jina-embeddings-v3, un modello di embedding testuale all'avanguardia con 570 milioni di parametri. Raggiunge prestazioni allo stato dell'arte su dati multilingue e task di recupero con contesto lungo, supportando una lunghezza di input fino a 8192 token. Il modello presenta adattatori Low-Rank Adaptation (LoRA) specifici per task, permettendogli di generare embedding di alta qualità per vari task tra cui recupero query-documento, clustering, classificazione e matching testuale.
Nelle valutazioni su MTEB English, Multilingual e LongEmbed, jina-embeddings-v3 supera gli ultimi embedding proprietari di OpenAI e Cohere sui task in inglese, superando anche multilingual-e5-large-instruct in tutti i task multilingue. Con una dimensione di output predefinita di 1024, gli utenti possono troncare arbitrariamente le dimensioni dell'embedding fino a 32 senza sacrificare le prestazioni, grazie all'integrazione del Matryoshka Representation Learning (MRL).


jina-embeddings-v2-(zh/es/de) si riferisce alla nostra suite di modelli bilingue, che è stata testata solo su task monolingue e cross-linguistici in cinese, spagnolo e tedesco, escludendo tutte le altre lingue. Inoltre, non riportiamo i punteggi per openai-text-embedding-3-large e cohere-embed-multilingual-v3.0, poiché questi modelli non sono stati valutati sull'intera gamma di task MTEB multilingue e cross-linguistici.
baai-bge-m3 sia l'approccio basato su ALiBi utilizzato in jina-embeddings-v2.Dal suo rilascio il 18 settembre 2024, jina-embeddings-v3 è il migliore modello multilingue e si classifica al 2° posto nella classifica MTEB English per modelli con meno di 1 miliardo di parametri. v3 supporta in totale 89 lingue, incluse 30 lingue con le migliori prestazioni: arabo, bengalese, cinese, danese, olandese, inglese, finlandese, francese, georgiano, tedesco, greco, hindi, indonesiano, italiano, giapponese, coreano, lettone, norvegese, polacco, portoghese, rumeno, russo, slovacco, spagnolo, svedese, thai, turco, ucraino, urdu e vietnamita.
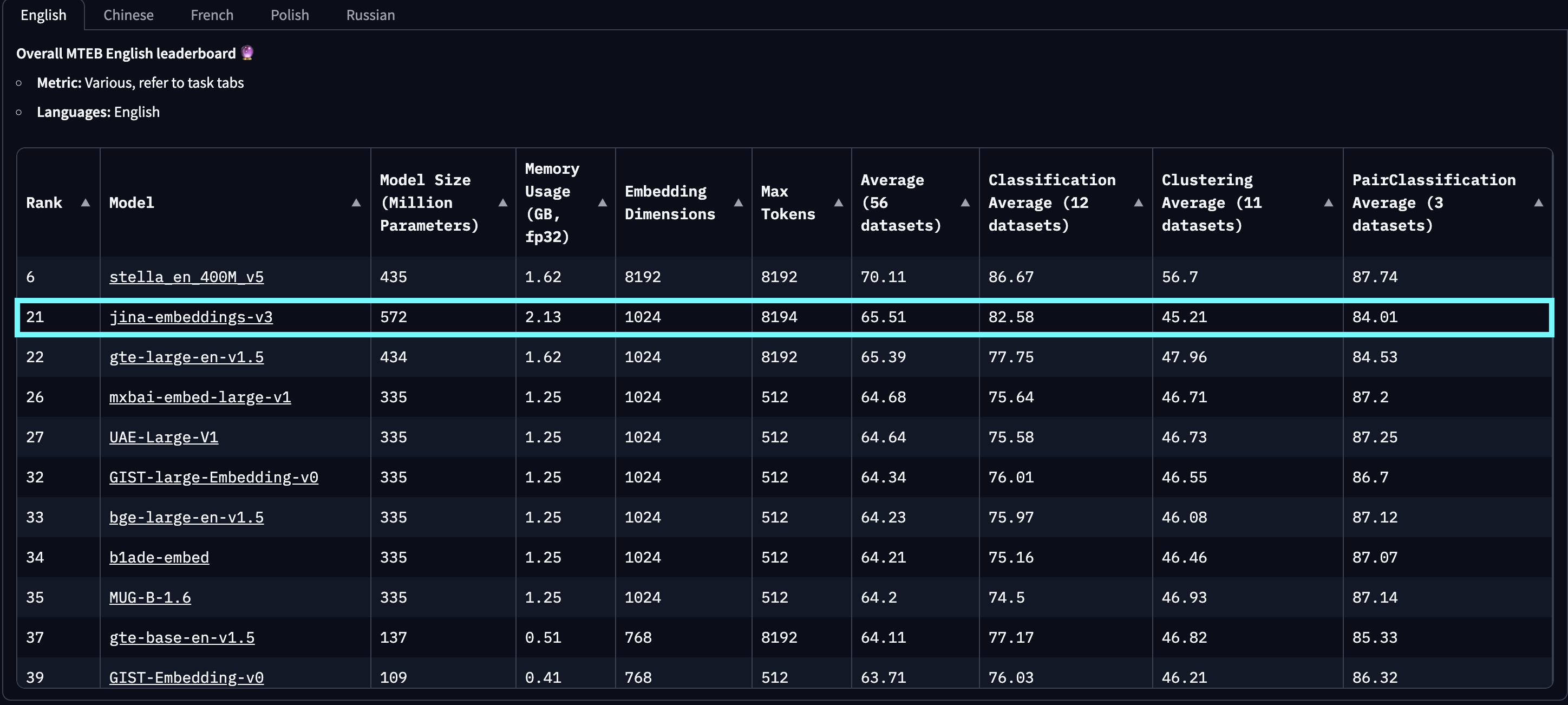

jina-embeddings-v2. Questo grafico è stato creato selezionando i primi 100 modelli di embedding dalla classifica MTEB, escludendo quelli senza informazioni sulle dimensioni, tipicamente modelli closed-source o proprietari. Sono state filtrate anche le submission identificate come trolling evidente.Inoltre, rispetto agli embedding basati su LLM che hanno recentemente attirato l'attenzione, come e5-mistral-7b-instruct, che ha una dimensione di parametri di 7,1 miliardi (12 volte più grande) e una dimensione di output di 4096 (4 volte più grande) ma offre solo un miglioramento dell'1% sui task MTEB in inglese, jina-embeddings-v3 è una soluzione molto più efficiente in termini di costi, rendendola più adatta per la produzione e il computing on-edge.
tagArchitettura del Modello
| Caratteristica | Descrizione |
|---|---|
| Base | jina-XLM-RoBERTa |
| Parametri Base | 559M |
| Parametri con LoRA | 572M |
| Token di input massimi | 8192 |
| Dimensioni di output massime | 1024 |
| Strati | 24 |
| Vocabolario | 250K |
| Lingue supportate | 89 |
| Attention | FlashAttention2, funziona anche senza |
| Pooling | Mean pooling |
L'architettura di jina-embeddings-v3 è mostrata nella figura sottostante. Per implementare l'architettura di base, abbiamo adattato il modello XLM-RoBERTa con diverse modifiche chiave: (1) abilitando la codifica efficace di sequenze di testo lunghe, (2) permettendo la codifica di embedding specifica per task, e (3) migliorando l'efficienza complessiva del modello con le tecniche più recenti. Continuiamo a utilizzare il tokenizer originale di XLM-RoBERTa. Mentre jina-embeddings-v3, con i suoi 570 milioni di parametri, è più grande di jina-embeddings-v2 che ne ha 137 milioni, rimane comunque molto più piccolo dei modelli di embedding ottimizzati dagli LLM.

jina-XLM-RoBERTa, con cinque adapter LoRA per quattro diversi task.L'innovazione chiave in jina-embeddings-v3 è l'uso degli adapter LoRA. Sono stati introdotti cinque adapter LoRA specifici per task per ottimizzare gli embedding per quattro task. L'input del modello consiste di due parti: il testo (il documento lungo da codificare) e il task. jina-embeddings-v3 supporta quattro task e implementa cinque adapter tra cui scegliere: retrieval.query e retrieval.passage per gli embedding di query e passaggi nei task di recupero asimmetrico, separation per i task di clustering, classification per i task di classificazione e text-matching per i task che coinvolgono la similarità semantica, come STS o il recupero simmetrico. Gli adapter LoRA rappresentano meno del 3% dei parametri totali, aggiungendo un sovraccarico minimo al calcolo.
Per migliorare ulteriormente le prestazioni e ridurre il consumo di memoria, integriamo FlashAttention 2, supportiamo il checkpointing delle attivazioni e utilizziamo il framework DeepSpeed per un training distribuito efficiente.
tagPer Iniziare
tagTramite l'API Search Foundation di Jina AI
Il modo più semplice per utilizzare jina-embeddings-v3 è visitare la homepage di Jina AI e navigare alla sezione Search Foundation API. Da oggi, questo modello è impostato come predefinito per tutti i nuovi utenti. Puoi esplorare diversi parametri e funzionalità direttamente da lì.
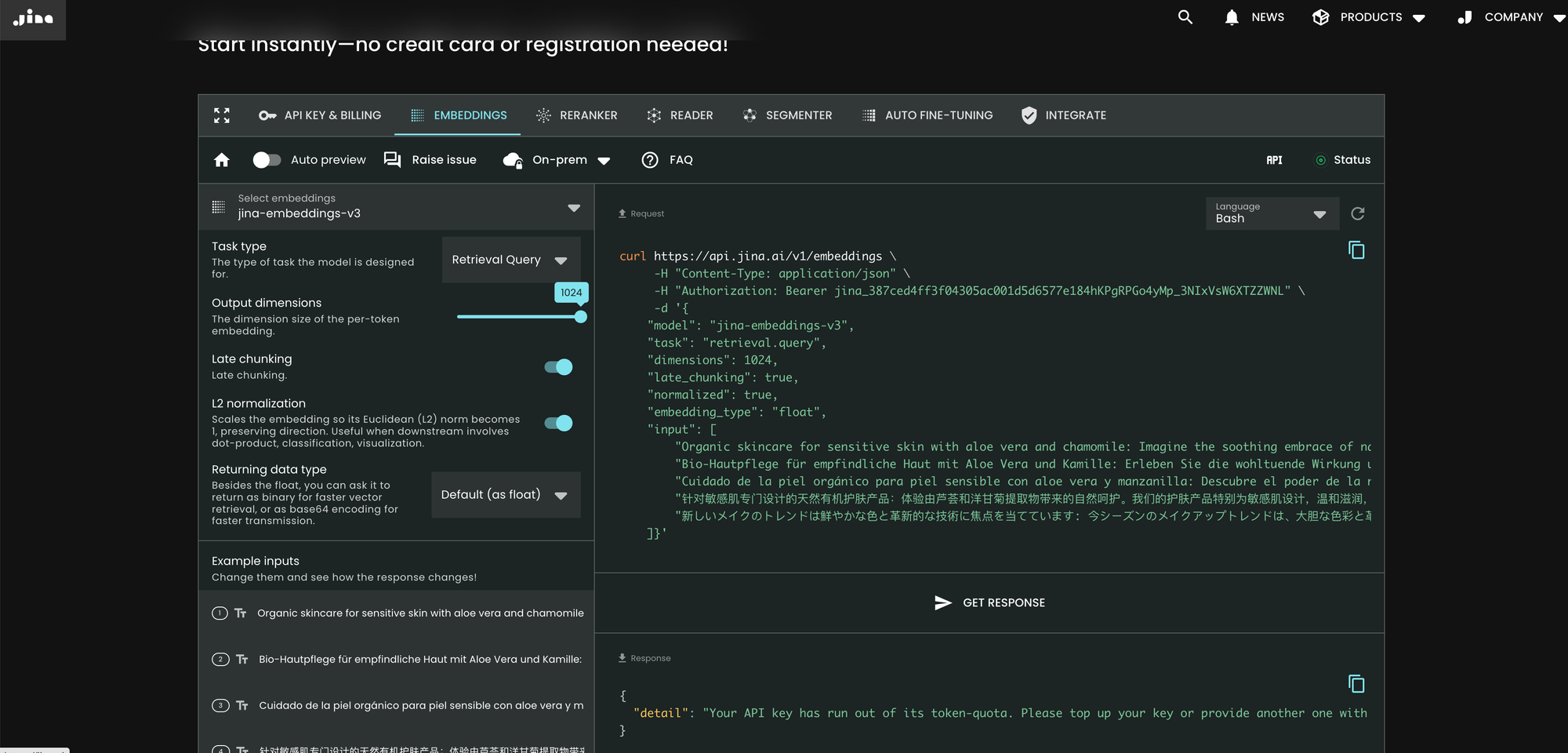
curl https://api.jina.ai/v1/embeddings \
-H "Content-Type: application/json" \
-H "Authorization: Bearer jina_387ced4ff3f04305ac001d5d6577e184hKPgRPGo4yMp_3NIxVsW6XTZZWNL" \
-d '{
"model": "jina-embeddings-v3",
"task": "text-matching",
"dimensions": 1024,
"late_chunking": true,
"input": [
"Organic skincare for sensitive skin with aloe vera and chamomile: ...",
"Bio-Hautpflege für empfindliche Haut mit Aloe Vera und Kamille: Erleben Sie die wohltuende Wirkung...",
"Cuidado de la piel orgánico para piel sensible con aloe vera y manzanilla: Descubre el poder ...",
"针对敏感肌专门设计的天然有机护肤产品:体验由芦荟和洋甘菊提取物带来的自然呵护。我们的护肤产品特别为敏感肌设计,...",
"新しいメイクのトレンドは鮮やかな色と革新的な技術に焦点を当てています: 今シーズンのメイクアップトレンドは、大胆な色彩と革新的な技術に注目しています。..."
]}'
Rispetto alla v2, la v3 introduce tre nuovi parametri nell'API: task, dimensions e late_chunking.
Parametro task
Il parametro task è cruciale e deve essere impostato in base al task downstream. Gli embedding risultanti saranno ottimizzati per quello specifico task. Per maggiori dettagli, consulta l'elenco qui sotto.
Valore di task |
Descrizione del Task |
|---|---|
retrieval.passage |
Embedding di documenti in un task di recupero query-documento |
retrieval.query |
Embedding di query in un task di recupero query-documento |
separation |
Clustering di documenti, visualizzazione di un corpus |
classification |
Classificazione del testo |
text-matching |
(Predefinito) Similarità semantica del testo, recupero simmetrico generale, raccomandazione, ricerca di elementi simili, deduplicazione |
Nota che l'API non genera prima un meta embedding generico per poi adattarlo con un MLP aggiuntivo ottimizzato. Invece, inserisce l'adapter LoRA specifico per il task in ogni strato del transformer (un totale di 24 strati) ed esegue la codifica in un'unica passata. Ulteriori dettagli possono essere trovati nel nostro paper su arXiv.
Parametro dimensions
Il parametro dimensions permette agli utenti di scegliere un compromesso tra efficienza dello spazio e prestazioni al minor costo. Grazie alla tecnica MRL utilizzata in jina-embeddings-v3, puoi ridurre le dimensioni degli embedding quanto desideri (persino fino a una singola dimensione!). Embedding più piccoli sono più efficienti in termini di archiviazione per i database vettoriali, e il loro costo in termini di prestazioni può essere stimato dalla figura sottostante.

Parametro late_chunking
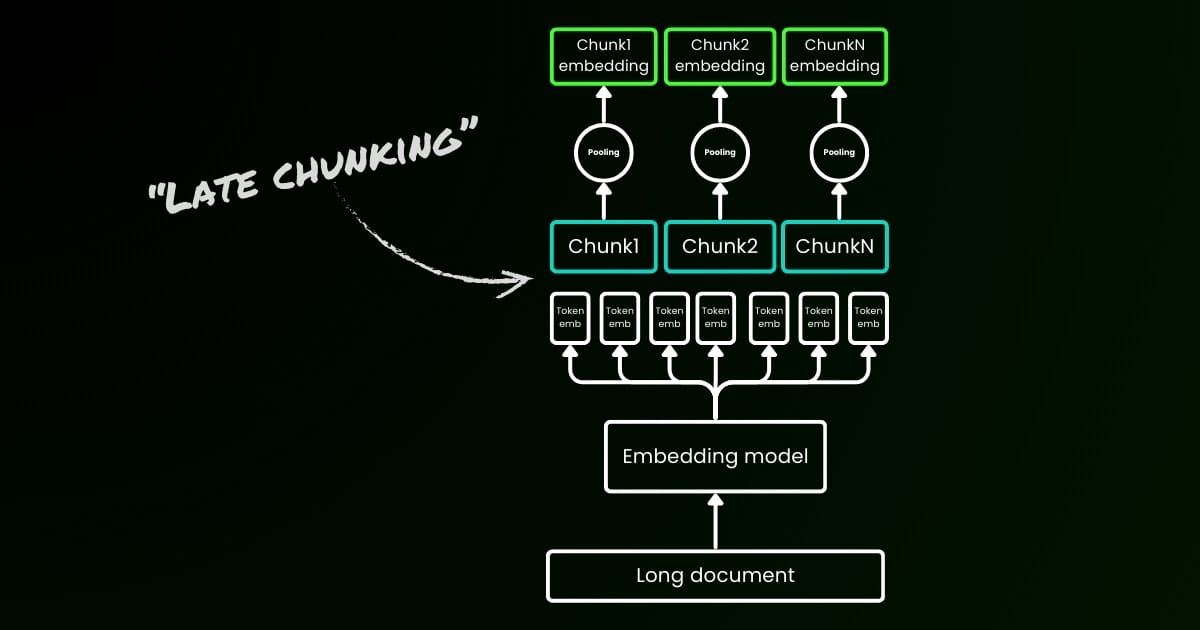
Infine, il parametro late_chunking controlla se utilizzare il nuovo metodo di chunking che abbiamo introdotto il mese scorso per la codifica di un batch di frasi. Quando impostato su true, la nostra API concatenerà tutte le frasi nel campo input e le fornirà come una singola stringa al modello. In altre parole, trattiamo le frasi nell'input come se provenissero originariamente dalla stessa sezione, paragrafo o documento. Internamente, il modello codifica questa lunga stringa concatenata e poi esegue il late chunking, restituendo una lista di embedding che corrisponde alla dimensione della lista di input. Ogni embedding nella lista è quindi condizionato dagli embedding precedenti.
Dal punto di vista dell'utente, l'impostazione di late_chunking non cambia il formato di input o output. Noterai solo un cambiamento nei valori degli embedding, poiché ora vengono calcolati basandosi sull'intero contesto precedente anziché indipendentemente. Ciò che è importante sapere quando si usalate_chunking=True significa che il numero totale di token (sommando tutti i token in input) per richiesta è limitato a 8192, che è la lunghezza massima del contesto consentita per jina-embeddings-v3. Quando late_chunking=False, non esiste tale restrizione; il numero totale di token è soggetto solo a il limite di rate della Embedding API.
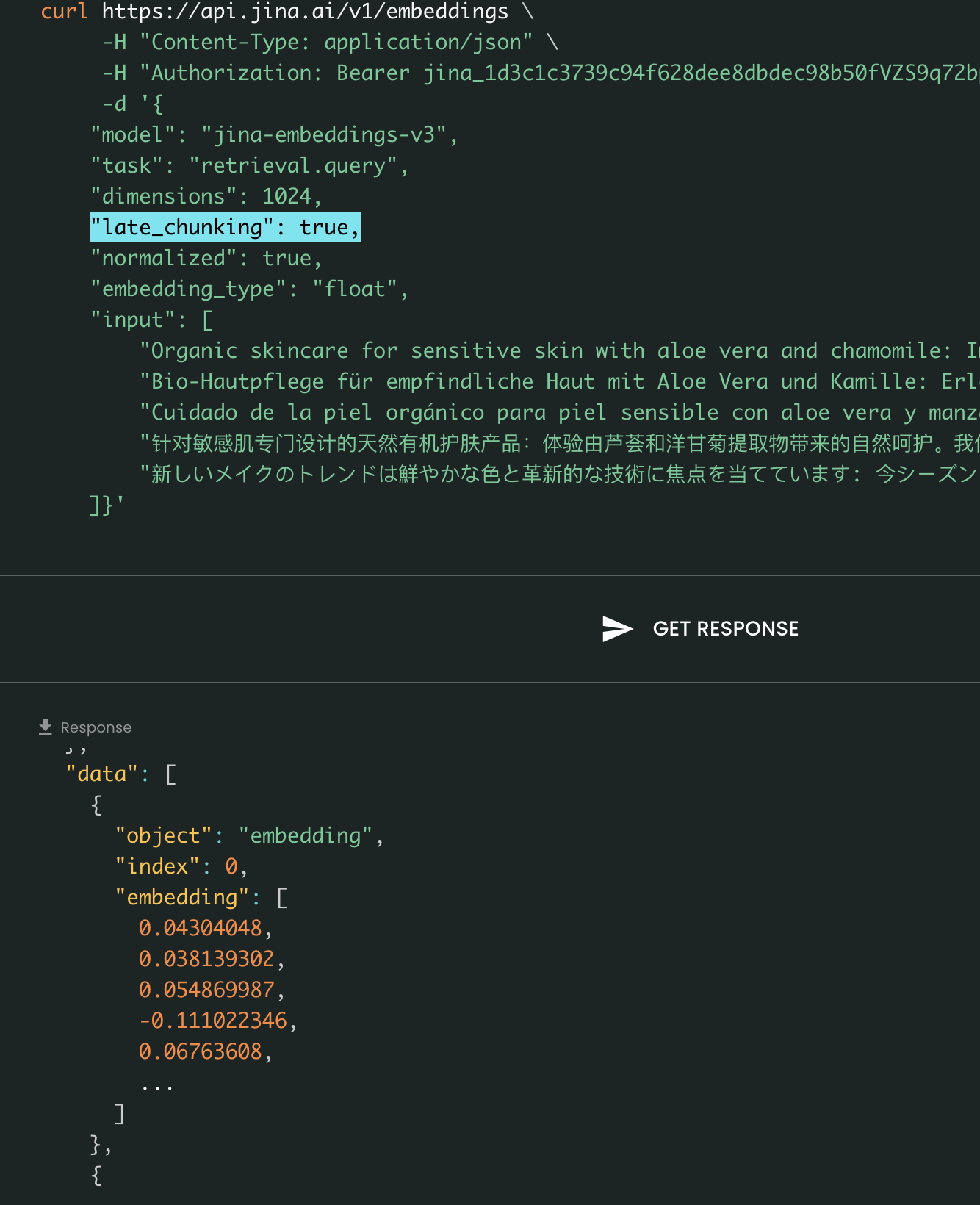
Late Chunking attivo vs disattivo: Il formato di input e output rimane lo stesso, con l'unica differenza nei valori di embedding. Quando late_chunking è abilitato, gli embedding sono influenzati dall'intero contesto precedente in input, mentre senza di esso, gli embedding vengono calcolati indipendentemente.
tagTramite Azure e AWS
jina-embeddings-v3 è ora disponibile su AWS SageMaker e Azure Marketplace.


Se hai bisogno di utilizzarlo al di fuori di queste piattaforme o on-premises all'interno della tua azienda, nota che il modello è concesso in licenza sotto CC BY-NC 4.0. Per richieste di utilizzo commerciale, non esitare a contattarci.
tagTramite Database Vettoriali e Partner
Collaboriamo strettamente con provider di database vettoriali come Pinecone, Qdrant e Milvus, così come con framework di orchestrazione LLM come LlamaIndex, Haystack e Dify. Al momento del rilascio, siamo lieti di annunciare che Pinecone, Qdrant, Milvus e Haystack hanno già integrato il supporto per jina-embeddings-v3, inclusi i tre nuovi parametri: task, dimensions e late_chunking. Altri partner che hanno già integrato l'API v2 dovrebbero supportare anche v3 semplicemente cambiando il nome del modello in jina-embeddings-v3. Tuttavia, potrebbero non supportare ancora i nuovi parametri introdotti in v3.
Tramite Pinecone

Tramite Qdrant

Tramite Milvus

Tramite Haystack

tagConclusione
Nell'ottobre 2023, abbiamo rilasciato jina-embeddings-v2-base-en, il primo modello di embedding open-source al mondo con una lunghezza di contesto di 8K. Era l'unico modello di embedding testuale che supportava il contesto lungo e si confrontava con text-embedding-ada-002 di OpenAI. Oggi, dopo un anno di apprendimento, sperimentazione e preziose lezioni, siamo orgogliosi di rilasciare jina-embeddings-v3—una nuova frontiera nei modelli di embedding testuale e una grande pietra miliare della nostra azienda.
Con questo rilascio, continuiamo ad eccellere in ciò per cui siamo conosciuti: embedding a lungo contesto, affrontando anche la funzionalità più richiesta sia dall'industria che dalla comunità—embedding multilingue. Allo stesso tempo, spingiamo le prestazioni a un nuovo massimo. Con nuove funzionalità come Task-specific LoRA, MRL e late chunking, crediamo che jina-embeddings-v3 servirà veramente come modello di embedding fondamentale per varie applicazioni, inclusi RAG, agenti e altro. Rispetto ai recenti embedding basati su LLM come NV-embed-v1/v2, il nostro modello è altamente efficiente in termini di parametri, rendendolo molto più adatto alla produzione e ai dispositivi edge.
Guardando al futuro, pianifichiamo di concentrarci sulla valutazione e il miglioramento delle prestazioni di jina-embeddings-v3 su lingue con risorse limitate e sull'ulteriore analisi dei fallimenti sistematici causati dalla limitata disponibilità di dati. Inoltre, i pesi del modello di jina-embeddings-v3, insieme alle sue funzionalità innovative e spunti interessanti, serviranno come base per i nostri prossimi modelli, incluso jina-clip-v2,jina-reranker-v3, e reader-lm-v2.



