





Oggi rilasciamo Jina Reranker v2 (jina-reranker-v2-base-multilingual), il nostro più recente e performante modello di neural reranker nella famiglia di search foundation. Con Jina Reranker v2, gli sviluppatori di sistemi RAG/search possono beneficiare di:
- Multilingua: Risultati di ricerca più rilevanti in oltre 100 lingue, superando
bge-reranker-v2-m3; - Agentico: Riordinamento all'avanguardia di documenti function-calling e text-to-SQL per RAG agentico;
- Recupero codice: Prestazioni superiori su attività di recupero codice, e
- Ultra-veloce: Throughput di 15 volte più documenti rispetto a
bge-reranker-v2-m3, e 6 volte più di jina-reranker-v1-base-en.
Puoi iniziare a utilizzare Jina Reranker v2 tramite la nostra API Reranker, dove offriamo 1M di token gratuiti per tutti i nuovi utenti.

In questo articolo, approfondiremo queste nuove funzionalità supportate da Jina Reranker v2, mostrando come il nostro modello reranker si comporta rispetto ad altri modelli all'avanguardia (incluso Jina Reranker v1), e spiegheremo il processo di training che ha portato Jina Reranker v2 a raggiungere prestazioni superiori in termini di accuratezza dei task e throughput dei documenti.
tagRiepilogo: Perché Hai Bisogno di un Reranker
Mentre i modelli di embedding sono il componente più ampiamente utilizzato e compreso nel search foundation, spesso sacrificano la precisione per la velocità di recupero. I modelli di ricerca basati su embedding sono tipicamente modelli bi-encoder, dove ogni documento viene incorporato e memorizzato, poi anche le query vengono incorporate e il recupero si basa sulla similarità tra l'embedding della query e gli embedding dei documenti. In questo modello, molte sfumature delle interazioni a livello di token tra le query degli utenti e i documenti corrispondenti vengono perse perché la query originale e i documenti non possono mai "vedersi" a vicenda – solo i loro embedding lo fanno. Questo può avere un costo in termini di accuratezza del recupero – un'area in cui i modelli reranker cross-encoder eccellono.

I reranker affrontano questa mancanza di semantica fine utilizzando un'architettura cross-encoder, dove le coppie query-documento vengono codificate insieme per produrre un punteggio di rilevanza invece di un embedding. Gli studi hanno dimostrato che, per la maggior parte dei sistemi RAG, l'uso di un modello reranker migliora il grounding semantico e riduce le allucinazioni.
tagSupporto Multilingua con Jina Reranker v2
In passato, Jina Reranker v1 si è distinto raggiungendo prestazioni all'avanguardia su quattro benchmark chiave in lingua inglese. Oggi, stiamo estendendo significativamente le capacità di reranking in Jina Reranker v2 con il supporto multilingua per più di 100 lingue e task cross-linguistici!
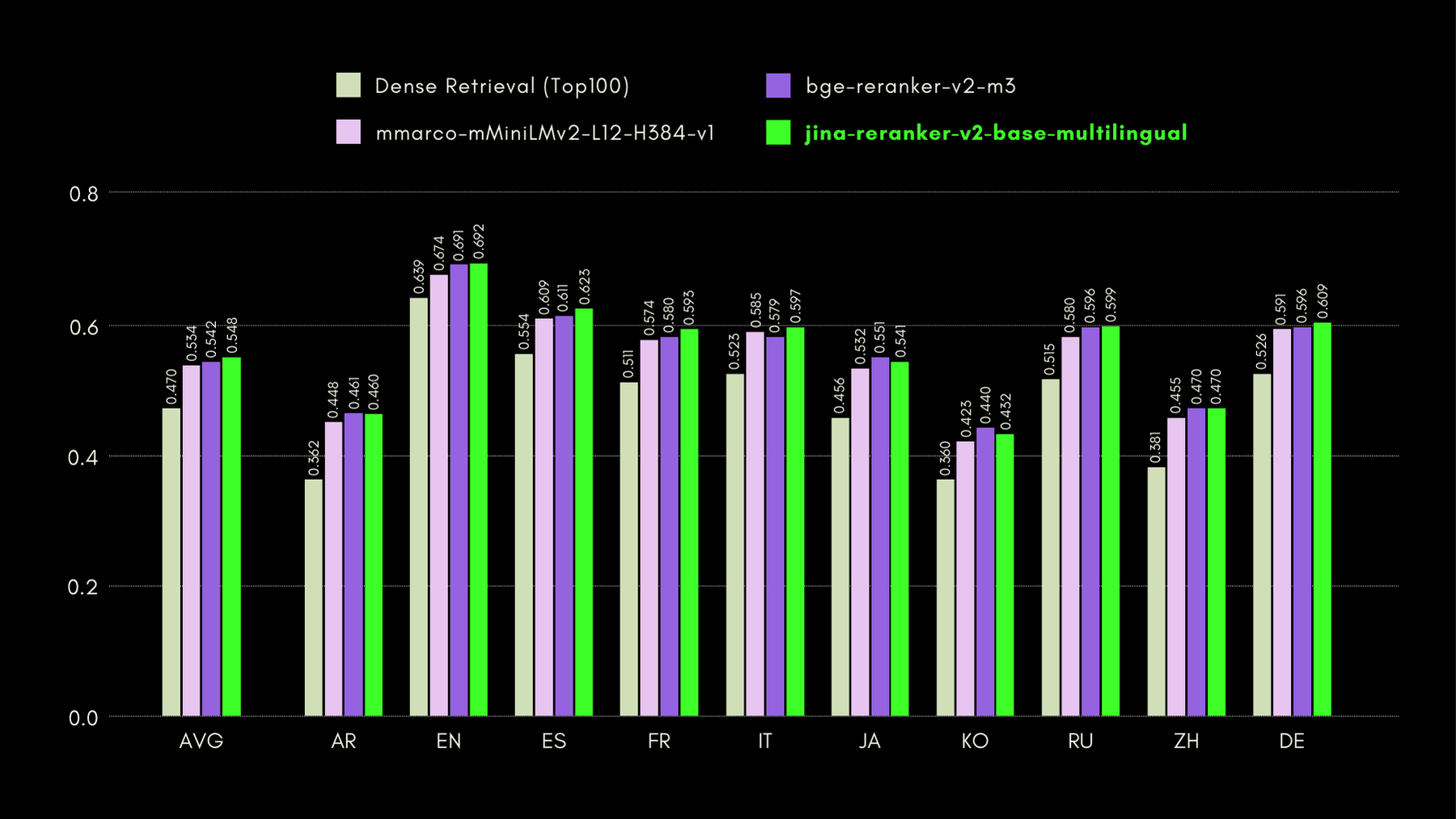
Per valutare le capacità cross-linguistiche e in lingua inglese di Jina Reranker v2, confrontiamo le sue prestazioni con modelli reranker simili, su tre benchmark elencati di seguito:
MKQA: Multilingual Knowledge Questions and Answers
Questo dataset comprende domande e risposte in 26 lingue, derivate da basi di conoscenza del mondo reale, ed è progettato per valutare le prestazioni cross-linguistiche dei sistemi di question-answering. MKQA consiste in query in lingua inglese e le loro traduzioni manuali in lingue non inglesi, insieme a risposte in più lingue incluso l'inglese.
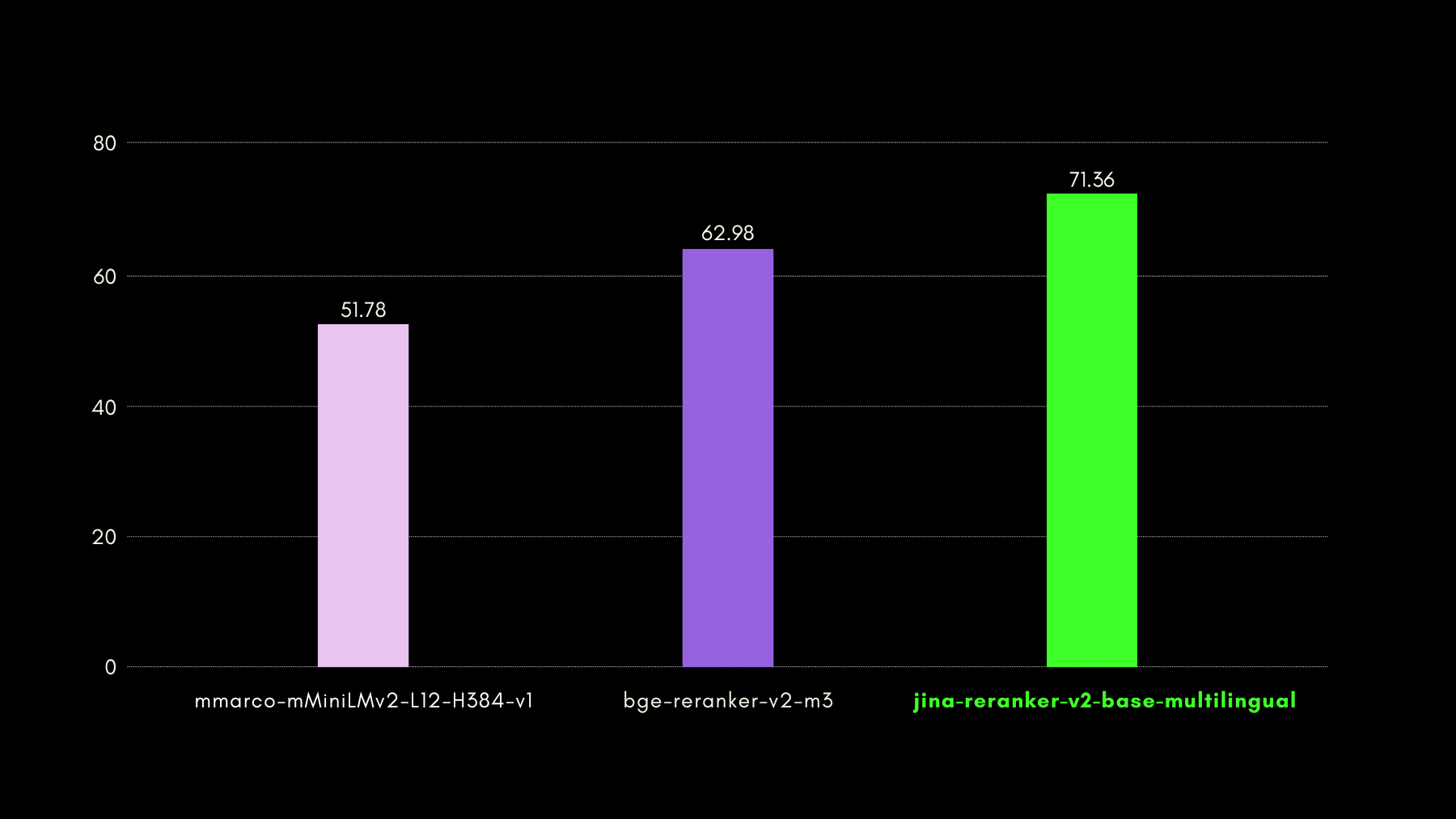
Nel grafico sottostante, riportiamo i punteggi recall@10 per ogni reranker incluso, compreso un "dense retriever" come baseline, che esegue la ricerca tradizionale basata su embedding:
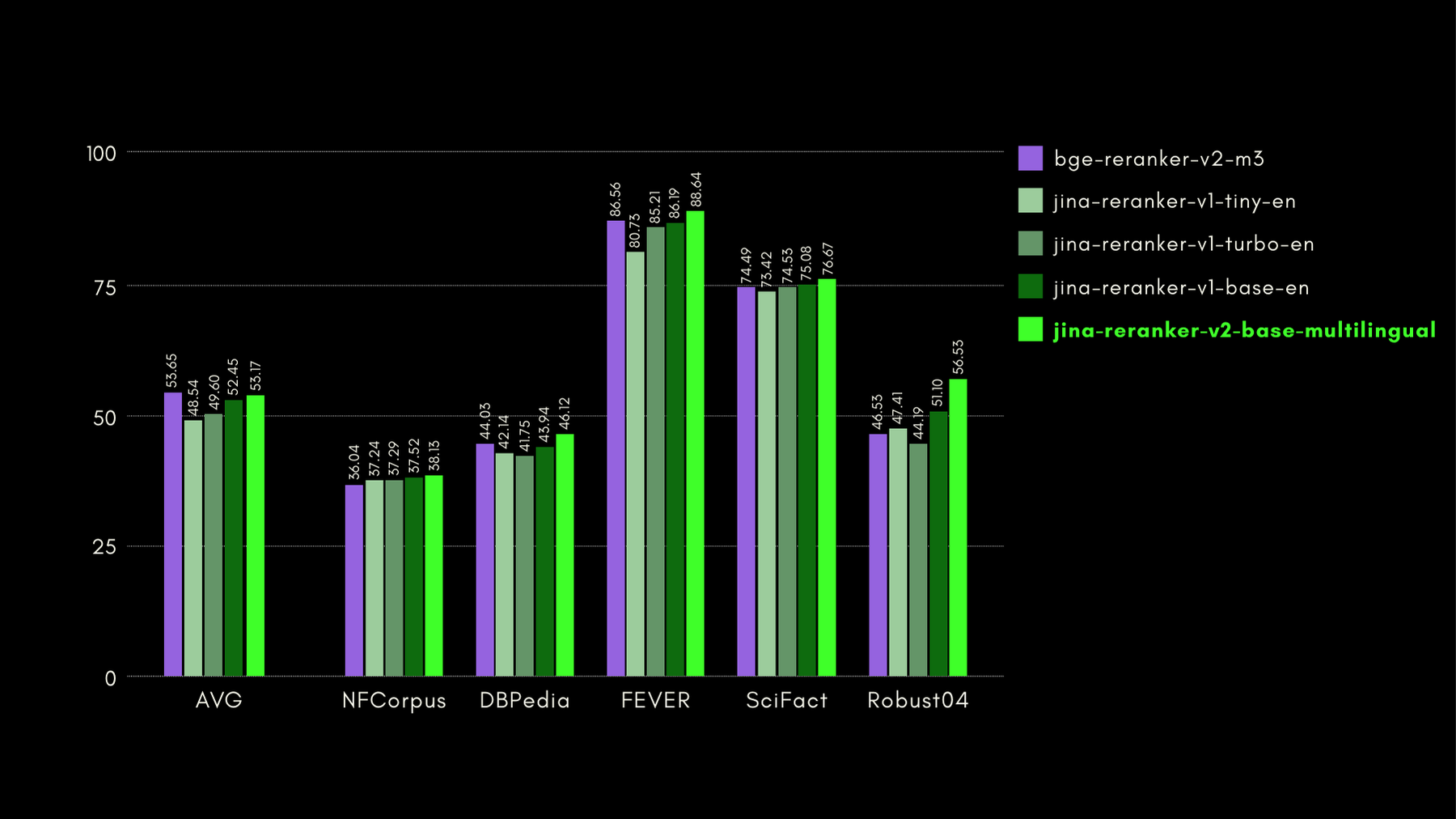
BEIR: Benchmark Eterogeneo su Diversi Task IR
Questo repository open-source contiene un benchmark di recupero per molte lingue, ma ci concentriamo solo sui task in lingua inglese. Questi consistono in 17 dataset, senza dati di training, e il focus di questi dataset è sulla valutazione dell'accuratezza di recupero di retriever neurali o lessicali.
Nel grafico sottostante, riportiamo NDCG@10 per BEIR con ogni reranker incluso. I risultati su BEIR mostrano chiaramente che le nuove capacità multilingua di jina-reranker-v2-base-multilingual non compromettono le sue capacità di recupero in lingua inglese, che sono, inoltre, significativamente migliorate rispetto a jina-reranker-v1-base-en.
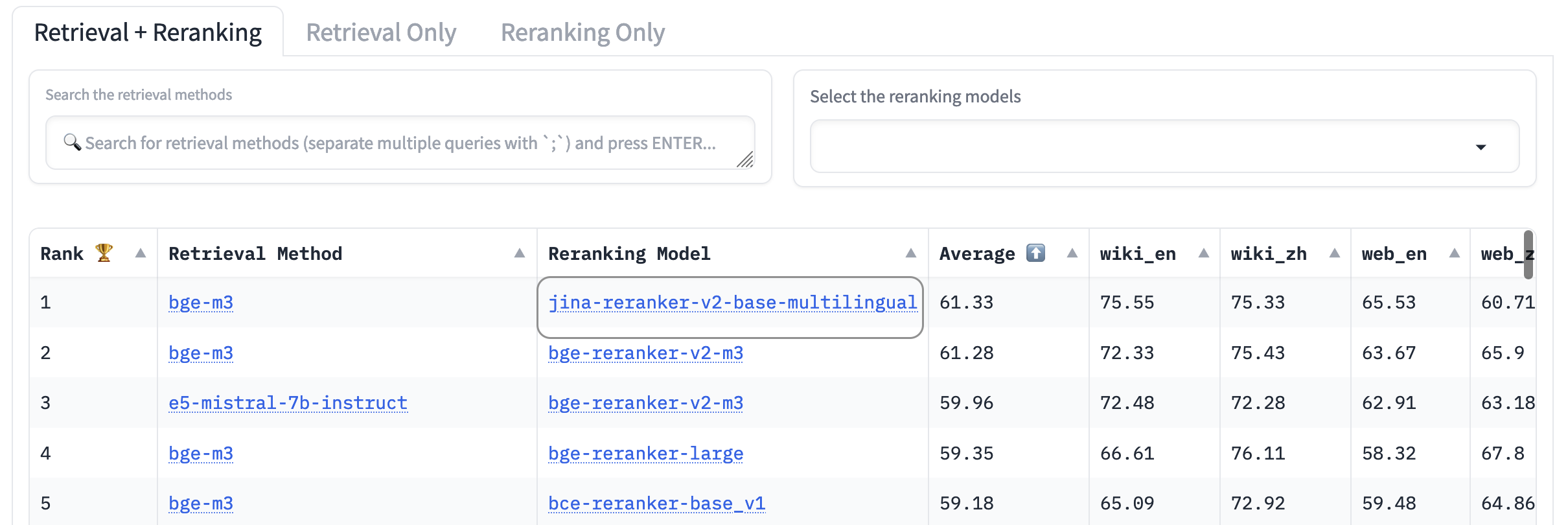
AirBench: Benchmark IR Eterogeneo Automatizzato
Abbiamo co-creato e pubblicato il benchmark AirBench per i sistemi RAG, insieme a BAAI. Questo benchmark utilizza dati sintetici generati automaticamente per domini e compiti personalizzati, senza rilasciare pubblicamente la ground truth in modo che i modelli valutati non abbiano possibilità di overfitting sul dataset.
Al momento della stesura, jina-reranker-v2-base-multilingual supera le prestazioni di ogni altro modello di reranking incluso, conquistando il primo posto nella classifica.
tagRiepilogo dei Tooling-Agents: Insegnare agli LLM a Utilizzare gli Strumenti
Da quando è iniziato il grande boom dell'IA alcuni anni fa, le persone hanno notato come i modelli di IA abbiano prestazioni insufficienti in compiti in cui i computer dovrebbero eccellere. Ad esempio, consideriamo questa conversazione con Mistral-7b-Instruct-v0.1:

Questo potrebbe sembrare corretto a prima vista, ma in realtà 203 per 7724 fa 1.567.972.
Quindi perché l'LLM sbaglia di un fattore superiore a dieci? Questo accade perché gli LLM non sono addestrati per fare calcoli matematici o qualsiasi altro tipo di ragionamento, e la mancanza di ricorsione interna garantisce quasi che non possano risolvere problemi matematici complessi. Sono addestrati per dire cose o svolgere altri compiti che non sono intrinsecamente precisi.
Gli LLM sono però pronti a allucinare risposte. Dal loro punto di vista, 15.824.772 è una risposta perfettamente plausibile per 204 × 7.724. È solo che è completamente sbagliata.
Il RAG Agentico cambia il ruolo degli LLM generativi da ciò in cui sono scarsi — pensare e conoscere le cose — a ciò in cui sono bravi: comprensione della lettura e sintesi delle informazioni in linguaggio naturale. Invece di generare semplicemente una risposta, il RAG trova informazioni rilevanti per rispondere alla tua richiesta in qualsiasi fonte di dati disponibile e le presenta al modello linguistico. Il suo compito non è inventare una risposta per te, ma presentare risposte trovate da un sistema diverso in forma naturale e reattiva.
Abbiamo addestrato Jina Reranker v2 per essere sensibile agli schemi dei database SQL e alle chiamate di funzione. Questo richiede un tipo diverso di semantica rispetto al recupero convenzionale di testo. Deve essere consapevole dei task e del codice, e abbiamo addestrato il nostro reranker specificamente per questa funzionalità.
tagJina Reranker v2 per l'Interrogazione di Dati Strutturati
Mentre i modelli di embedding e reranker già trattano i dati non strutturati come cittadini di prima classe, il supporto per i dati tabulari strutturati è ancora carente nella maggior parte dei modelli.
Jina Reranker v2 comprende l'intento a valle di interrogare una fonte di database strutturati, come MySQL o MongoDB, e assegna il punteggio di rilevanza corretto a uno schema di tabella strutturato, data una query in input.
Puoi vederlo qui sotto, dove il reranker recupera le tabelle più rilevanti prima che un LLM venga sollecitato a generare una query SQL da una query in linguaggio naturale:
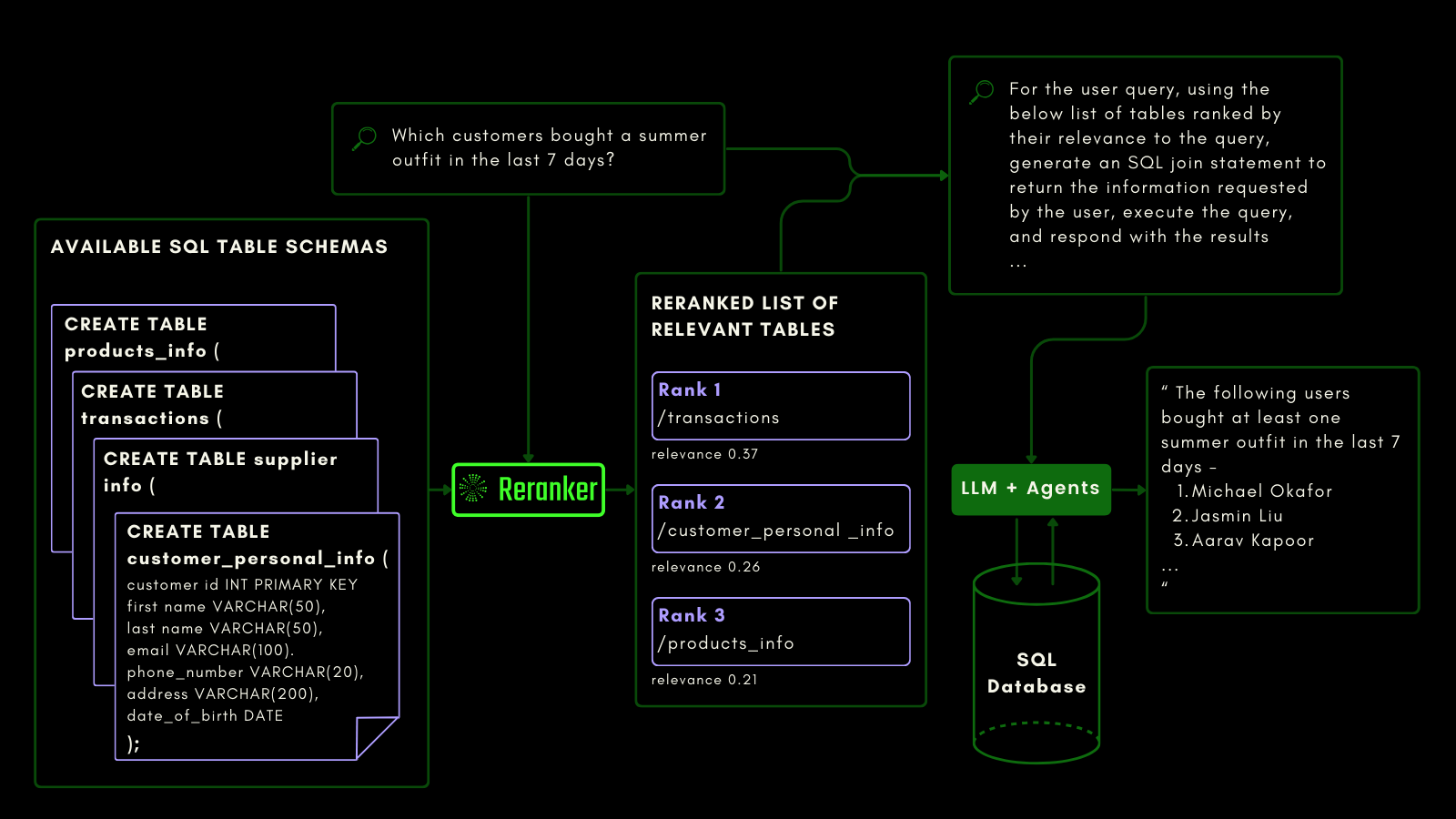
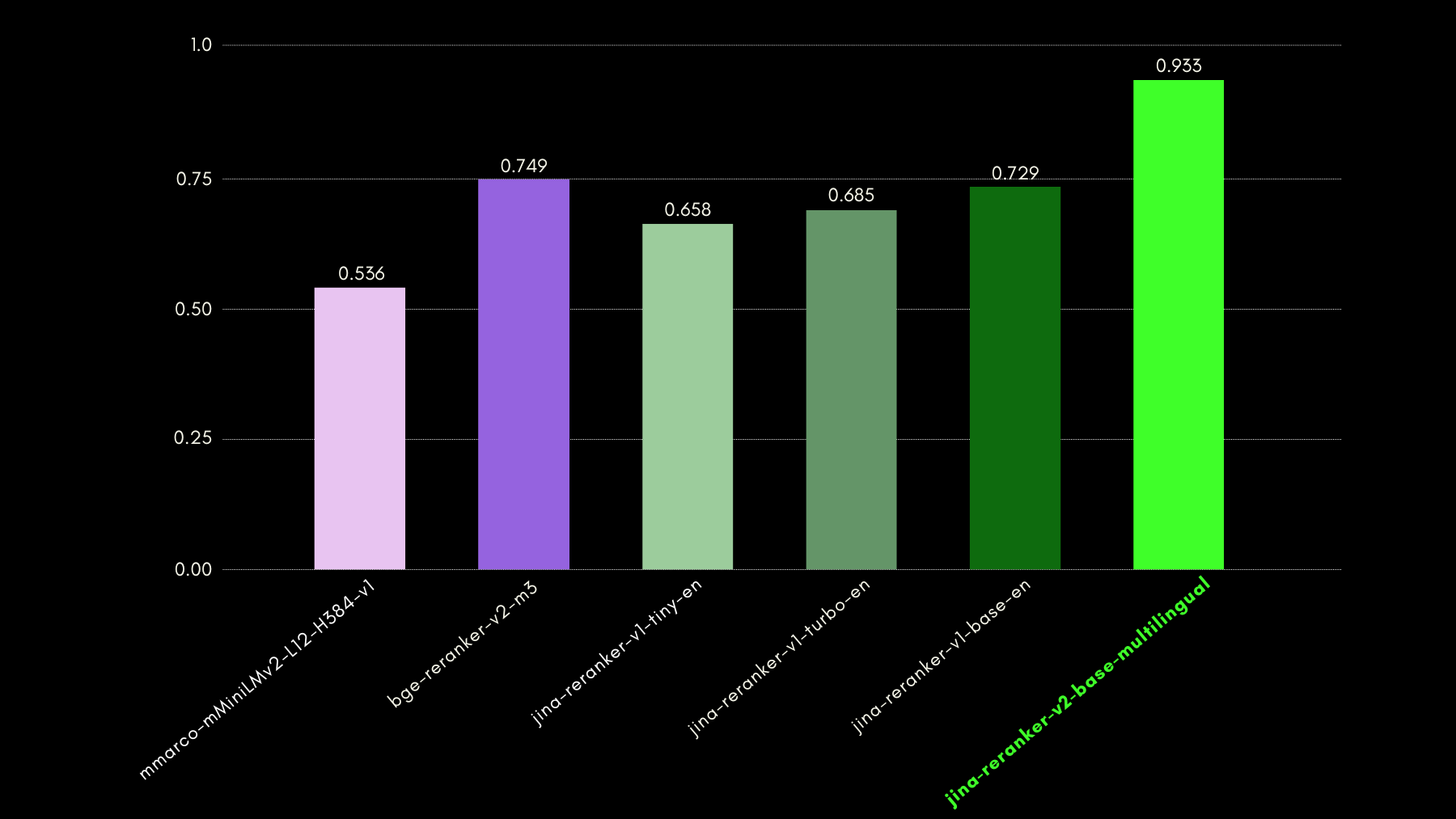
Abbiamo valutato le capacità di interrogazione consapevole utilizzando il benchmark del dataset NSText2SQL. Estraiamo, dalla colonna "instruction" del dataset originale, istruzioni scritte in linguaggio naturale e il corrispondente schema della tabella.
Il grafico qui sotto confronta, usando recall@3, quanto successo hanno i modelli di reranking nel classificare lo schema della tabella corretto corrispondente a una query in linguaggio naturale.
tagJina Reranker v2 per le Chiamate di Funzione
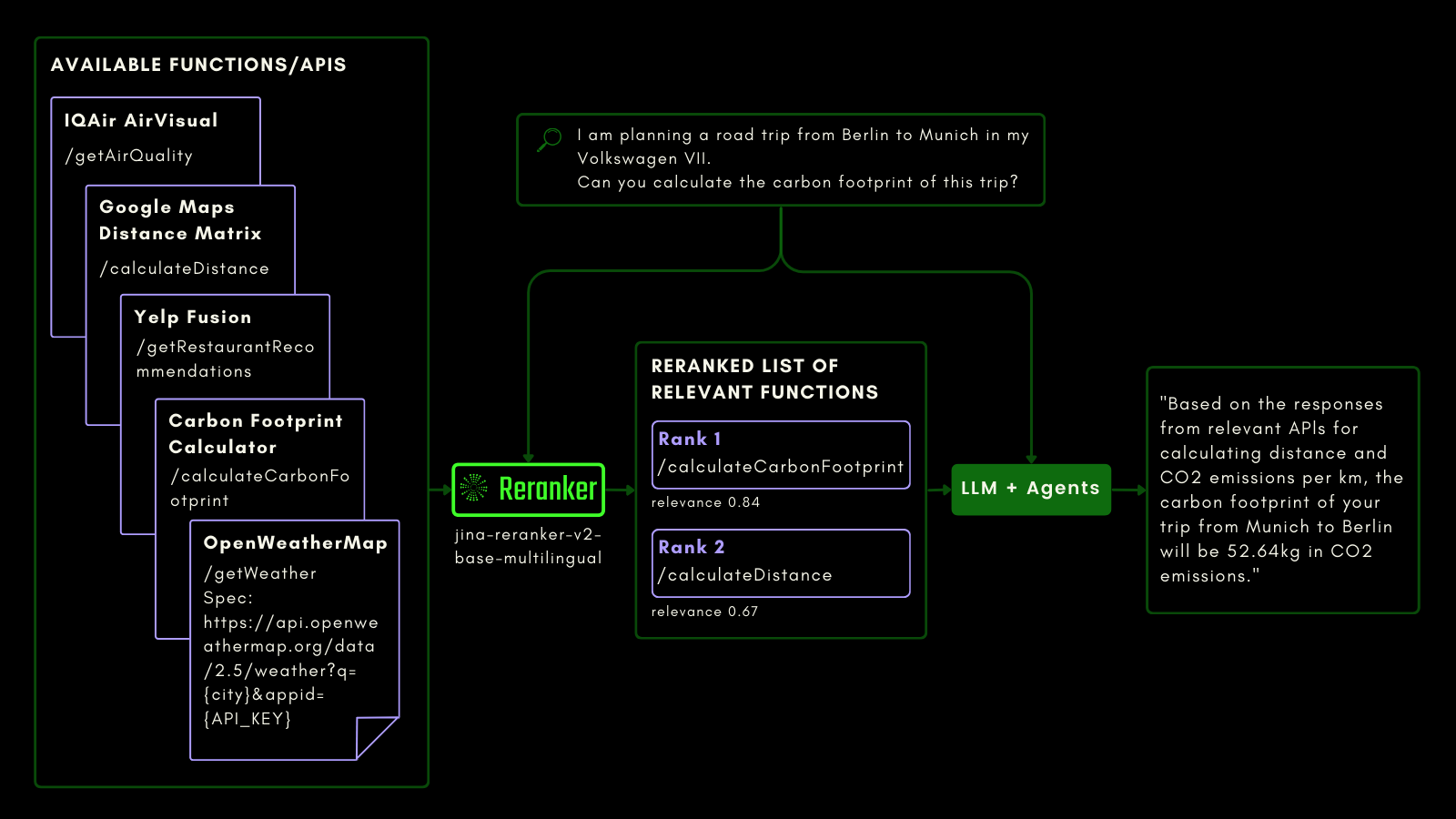
Proprio come interrogare una tabella SQL, puoi usare il RAG agentico per invocare strumenti esterni. Con questo in mente, abbiamo integrato la chiamata di funzione in Jina Reranker v2, permettendogli di comprendere il tuo intento per le funzioni esterne e assegnare di conseguenza punteggi di rilevanza alle specifiche delle funzioni.
Lo schema qui sotto spiega (con un esempio) come gli LLM possono usare Reranker per migliorare le capacità di chiamata delle funzioni e, in definitiva, l'esperienza utente dell'IA agentica.
Abbiamo valutato le capacità consapevoli delle funzioni con il benchmark ToolBench. Il benchmark raccoglie oltre 16 mila API pubbliche e corrispondenti istruzioni generate sinteticamente per utilizzarle in configurazioni con API singole e multiple.
Ecco i risultati (metrica recall@3) confrontati con altri modelli di reranking:
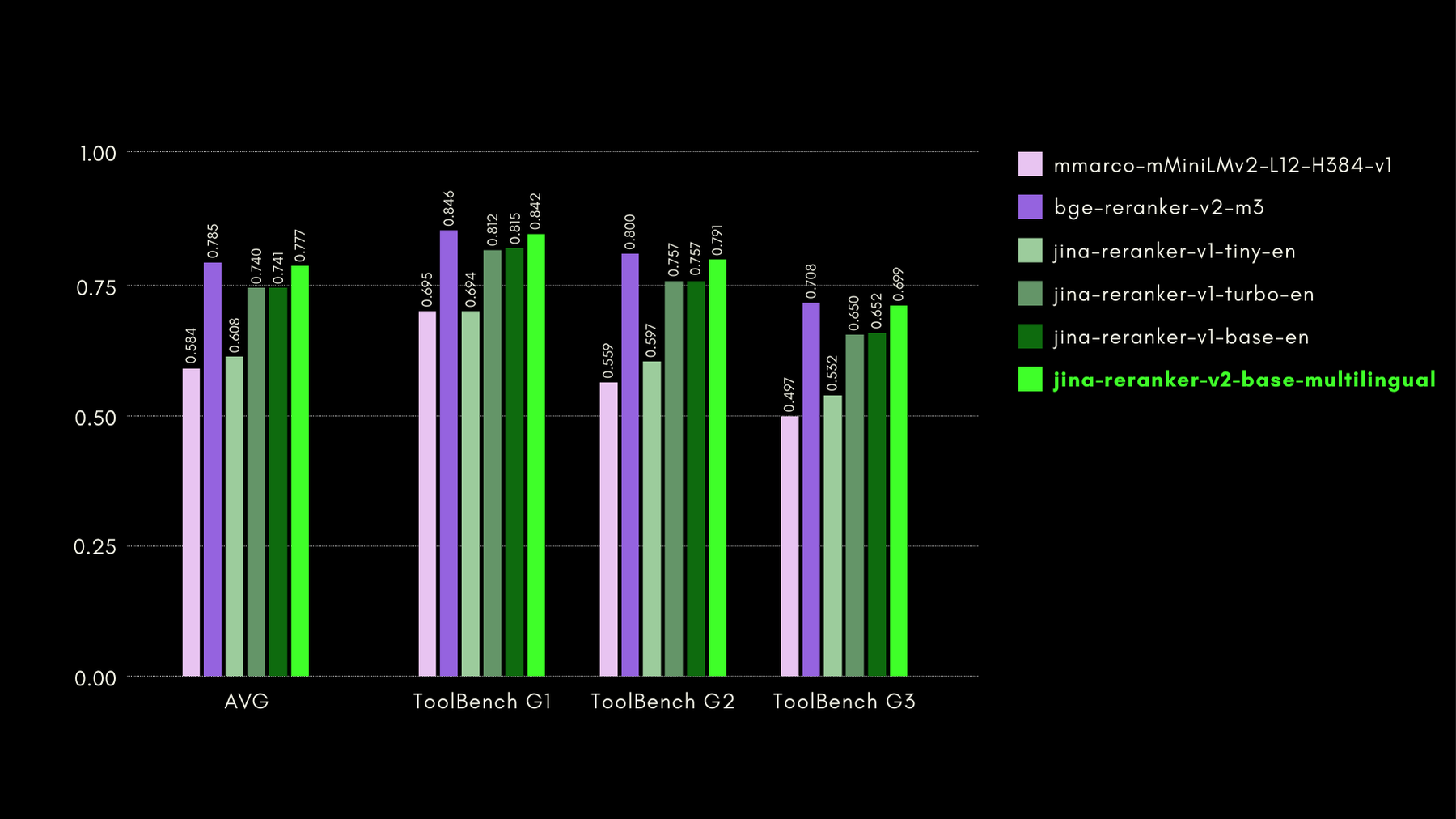
Come mostreremo anche nelle sezioni successive, le prestazioni quasi allo stato dell'arte di jina-reranker-v2-base-multilingual si accompagnano al vantaggio di avere dimensioni dimezzate rispetto a bge-reranker-v2-m3 e di essere quasi 15 volte più veloce.
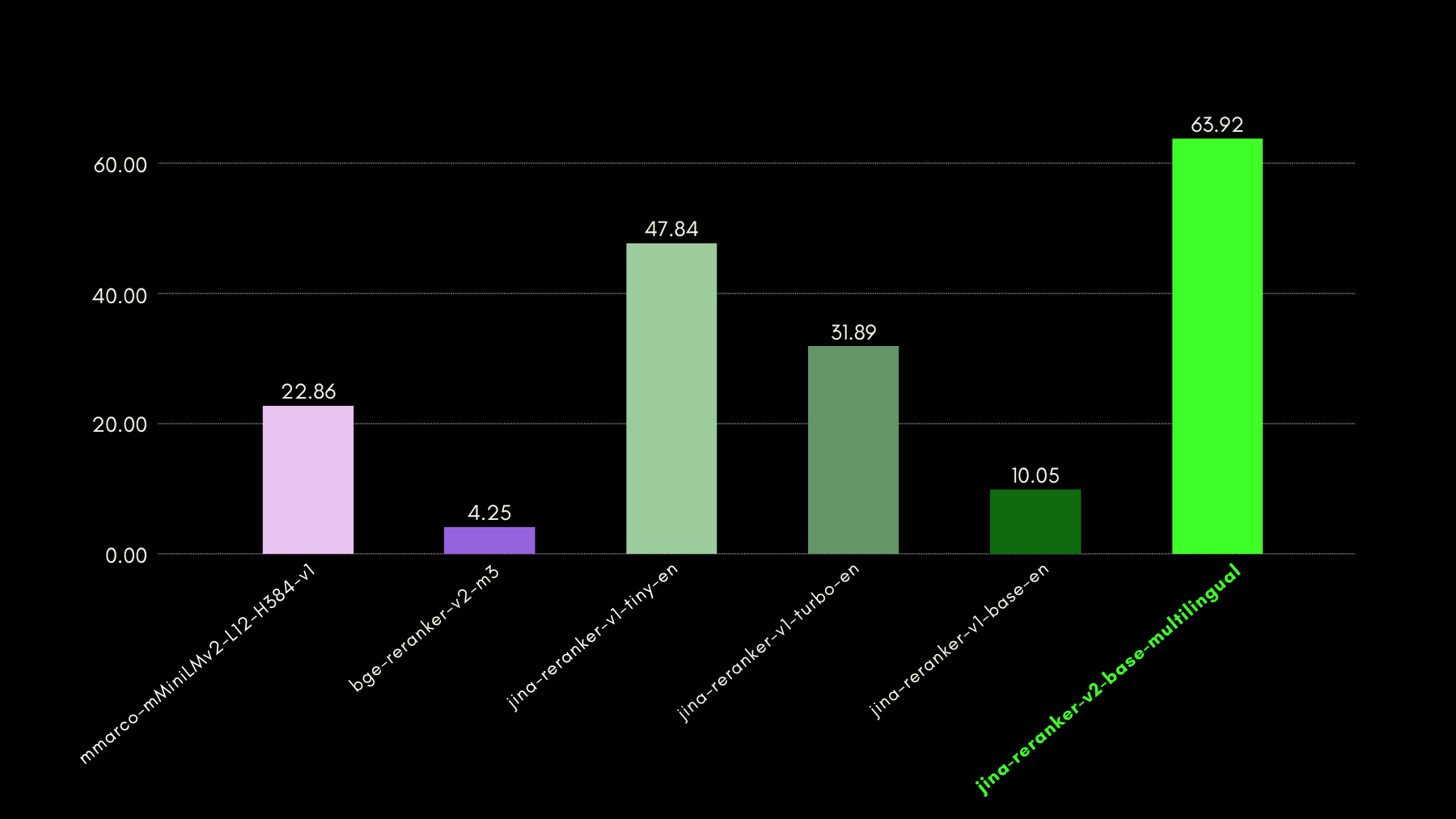
tagJina Reranker v2 sul Recupero di Codice
Jina Reranker v2, oltre ad essere addestrato per la chiamata di funzioni e l'interrogazione di dati strutturati, migliora anche il recupero di codice rispetto ai modelli concorrenti di dimensioni simili. Abbiamo valutato le sue capacità di recupero del codice utilizzando il benchmark CodeSearchNet. Il benchmark è una combinazione di query in formato docstring e linguaggio naturale, con segmenti di codice etichettati pertinenti alle query.
Ecco i risultati, utilizzando MRR@10, confrontati con altri modelli di riordinamento:
tagInferenza Ultra Veloce con Jina Reranker v2
Mentre i reranker neurali di tipo cross-encoder eccellono nel prevedere la rilevanza di un documento recuperato, offrono un'inferenza più lenta rispetto ai modelli di embedding. In particolare, confrontare una query con n documenti uno alla volta è molto più lento di HNSW o qualsiasi altro metodo di recupero rapido nella maggior parte dei database vettoriali. Abbiamo risolto questa lentezza con Jina Reranker v2.
- Le nostre intuizioni uniche nell'addestramento (descritte nella sezione successiva) hanno portato il nostro modello a raggiungere prestazioni allo stato dell'arte in termini di accuratezza con soli 278M parametri. Rispetto, ad esempio, a
bge-reranker-v2-m3, con 567M parametri, Jina Reranker v2 ha solo metà delle dimensioni. Questa riduzione è il primo motivo del miglioramento del throughput (documenti elaborati per 50ms). - Anche con dimensioni del modello comparabili, Jina Reranker v2 vanta un throughput 6 volte superiore rispetto al nostro precedente modello allo stato dell'arte Jina Reranker v1 per l'inglese. Questo perché abbiamo implementato Jina Reranker v2 con Flash Attention 2, che introduce ottimizzazioni di memoria e di calcolo nel layer di attenzione dei modelli basati su transformer.
Potete vedere il risultato dei passaggi precedenti, in termini di prestazioni di throughput di Jina Reranker v2:
tagCome Abbiamo Addestrato Jina Reranker v2
Abbiamo addestrato jina-reranker-v2-base-multilingual in quattro fasi:
- Preparazione con Dati in Inglese: Abbiamo preparato la prima versione del modello addestrando un modello backbone con dati solo in lingua inglese, incluse coppie (addestramento contrastivo) o triplette (query, risposta corretta, risposta errata), coppie query-schema di funzioni e coppie query-schema di tabelle.
- Aggiunta di Dati Cross-linguistici: Nella fase successiva, abbiamo aggiunto dataset di coppie e triplette cross-linguistiche, per migliorare le capacità multilingue del modello backbone specificamente sui compiti di recupero.
- Aggiunta di tutti i Dati Multilingue: In questa fase, ci siamo concentrati principalmente sull'assicurarci che il modello vedesse la maggior quantità possibile dei nostri dati. Abbiamo effettuato il fine-tuning del checkpoint del modello dalla seconda fase con tutti i dataset di coppie e triplette, da oltre 100 lingue a basse e alte risorse.
- Fine-Tuning con Hard-Negative Mining: Dopo aver osservato le prestazioni di riordinamento dalla terza fase, abbiamo effettuato il fine-tuning del modello aggiungendo più dati di triplette con specificamente più esempi di hard-negative per le query esistenti - risposte che sembrano superficialmente rilevanti per la query, ma sono in realtà errate.
Questo approccio di addestramento in quattro fasi si è basato sull'intuizione che includere funzioni e schemi tabulari nel processo di addestramento il prima possibile ha permesso al modello di essere particolarmente consapevole di questi casi d'uso e di imparare a concentrarsi sulla semantica dei documenti candidati più che sulle costruzioni linguistiche.
tagJina Reranker v2 in Pratica
tagTramite la Nostra API di Reranker
Il modo più veloce e semplice per iniziare con Jina Reranker v2 è utilizzare l'API di Jina Reranker.
Vai alla sezione API di questa pagina per integrare jina-reranker-v2-base-multilingual utilizzando il linguaggio di programmazione che preferisci.
Esempio 1: Classificazione delle Chiamate di Funzione
Per classificare la funzione/strumento esterno più rilevante, formatta la query e i documenti (schemi di funzione) come mostrato di seguito:
curl -X 'POST' \
'https://api.jina.ai/v1/rerank' \
-H 'accept: application/json' \
-H 'Authorization: Bearer <IL TUO TOKEN JINA AI QUI>' \
-H 'Content-Type: application/json' \
-d '{
"model": "jina-reranker-v2-base-multilingual",
"query": "Sto pianificando un viaggio in auto da Berlino a Monaco con la mia Volkswagen VII. Puoi calcolare l'\''impronta di carbonio di questo viaggio?",
"documents": [
"{'\''Name'\'': '\''getWeather'\'', '\''Specification'\'': '\''Fornisce informazioni meteo correnti per una città specificata'\'', '\''spec'\'': '\''https://api.openweathermap.org/data/2.5/weather?q={city}&appid={API_KEY}'\'', '\''example'\'': '\''https://api.openweathermap.org/data/2.5/weather?q=Berlin&appid=YOUR_API_KEY'\''}",
"{'\''Name'\'': '\''calculateDistance'\'', '\''Specification'\'': '\''Calcola la distanza di guida e il tempo tra più località'\'', '\''spec'\'': '\''https://maps.googleapis.com/maps/api/distancematrix/json?origins={startCity}&destinations={endCity}&key={API_KEY}'\'', '\''example'\'': '\''https://maps.googleapis.com/maps/api/distancematrix/json?origins=Berlin&destinations=Munich&key=YOUR_API_KEY'\''}",
"{'\''Name'\'': '\''calculateCarbonFootprint'\'', '\''Specification'\'': '\''Stima l'\''impronta di carbonio per varie attività, incluso il trasporto'\'', '\''spec'\'': '\''https://www.carboninterface.com/api/v1/estimates'\'', '\''example'\'': '\''{type: vehicle, distance: distance, vehicle_model_id: car}'\''}"
]
}'Ricordati di sostituire <IL TUO TOKEN JINA AI QUI> con il tuo token personale dell'API Reranker
Dovresti ottenere:
{
"model": "jina-reranker-v2-base-multilingual",
"usage": {
"total_tokens": 383,
"prompt_tokens": 383
},
"results": [
{
"index": 2,
"document": {
"text": "{'Name': 'calculateCarbonFootprint', 'Specification': 'Estimates the carbon footprint for various activities, including transportation', 'spec': 'https://www.carboninterface.com/api/v1/estimates', 'example': '{type: vehicle, distance: distance, vehicle_model_id: car}'}"
},
"relevance_score": 0.5422876477241516
},
{
"index": 1,
"document": {
"text": "{'Name': 'calculateDistance', 'Specification': 'Calculates the driving distance and time between multiple locations', 'spec': 'https://maps.googleapis.com/maps/api/distancematrix/json?origins={startCity}&destinations={endCity}&key={API_KEY}', 'example': 'https://maps.googleapis.com/maps/api/distancematrix/json?origins=Berlin&destinations=Munich&key=YOUR_API_KEY'}"
},
"relevance_score": 0.23283305764198303
},
{
"index": 0,
"document": {
"text": "{'Name': 'getWeather', 'Specification': 'Provides current weather information for a specified city', 'spec': 'https://api.openweathermap.org/data/2.5/weather?q={city}&appid={API_KEY}', 'example': 'https://api.openweathermap.org/data/2.5/weather?q=Berlin&appid=YOUR_API_KEY'}"
},
"relevance_score": 0.05033063143491745
}
]
}Esempio 2: Classificazione delle query SQL
Allo stesso modo, per ottenere i punteggi di rilevanza per gli schemi di tabelle strutturate per la tua query, puoi utilizzare il seguente esempio di chiamata API:
curl -X 'POST' \
'https://api.jina.ai/v1/rerank' \
-H 'accept: application/json' \
-H 'Authorization: Bearer <YOUR JINA AI TOKEN HERE>' \
-H 'Content-Type: application/json' \
-d '{
"model": "jina-reranker-v2-base-multilingual",
"query": "which customers bought a summer outfit in the past 7 days?",
"documents": [
"CREATE TABLE customer_personal_info (customer_id INT PRIMARY KEY, first_name VARCHAR(50), last_name VARCHAR(50));",
"CREATE TABLE supplier_company_info (supplier_id INT PRIMARY KEY, company_name VARCHAR(100), contact_name VARCHAR(50));",
"CREATE TABLE transactions (transaction_id INT PRIMARY KEY, customer_id INT, purchase_date DATE, FOREIGN KEY (customer_id) REFERENCES customer_personal_info(customer_id), product_id INT, FOREIGN KEY (product_id) REFERENCES products(product_id));",
"CREATE TABLE products (product_id INT PRIMARY KEY, product_name VARCHAR(100), season VARCHAR(50), supplier_id INT, FOREIGN KEY (supplier_id) REFERENCES supplier_company_info(supplier_id));"
]
}'La risposta attesa è:
{
"model": "jina-reranker-v2-base-multilingual",
"usage": {
"total_tokens": 253,
"prompt_tokens": 253
},
"results": [
{
"index": 2,
"document": {
"text": "CREATE TABLE transactions (transaction_id INT PRIMARY KEY, customer_id INT, purchase_date DATE, FOREIGN KEY (customer_id) REFERENCES customer_personal_info(customer_id), product_id INT, FOREIGN KEY (product_id) REFERENCES products(product_id));"
},
"relevance_score": 0.2789437472820282
},
{
"index": 0,
"document": {
"text": "CREATE TABLE customer_personal_info (customer_id INT PRIMARY KEY, first_name VARCHAR(50), last_name VARCHAR(50));"
},
"relevance_score": 0.06477169692516327
},
{
"index": 3,
"document": {
"text": "CREATE TABLE products (product_id INT PRIMARY KEY, product_name VARCHAR(100), season VARCHAR(50), supplier_id INT, FOREIGN KEY (supplier_id) REFERENCES supplier_company_info(supplier_id));"
},
"relevance_score": 0.027742892503738403
},
{
"index": 1,
"document": {
"text": "CREATE TABLE supplier_company_info (supplier_id INT PRIMARY KEY, company_name VARCHAR(100), contact_name VARCHAR(50));"
},
"relevance_score": 0.025516605004668236
}
]
}tagTramite Framework RAG/LLM
Le integrazioni esistenti di Jina Reranker con i framework di orchestrazione LLM e RAG dovrebbero già funzionare out-of-the-box utilizzando il nome del modello jina-reranker-v2-base-multilingual. Consulta le rispettive pagine di documentazione per saperne di più su come integrare Jina Reranker v2 nelle tue applicazioni.
- Haystack di deepset: Jina Reranker v2 può essere utilizzato con la classe JinaRanker in Haystack:
from haystack import Document
from haystack_integrations.components.rankers.jina import JinaRanker
docs = [Document(content="Paris"), Document(content="Berlin")]
ranker = JinaRanker(model="jina-reranker-v2-base-multilingual", api_key="<YOUR JINA AI API KEY HERE>")
ranker.run(query="City in France", documents=docs, top_k=1)
- LlamaIndex: Jina Reranker v2 può essere utilizzato come modulo JinaRerank node postprocessor inizializzandolo:
import os
from llama_index.postprocessor.jinaai_rerank import JinaRerank
jina_rerank = JinaRerank(model="jina-reranker-v2-base-multilingual", api_key="<YOUR JINA AI API KEY HERE>", top_n=1)
- Langchain: Utilizza l'integrazione Jina Rerank per utilizzare Jina Reranker 2 nella tua applicazione esistente. Il modulo JinaRerank deve essere inizializzato con il nome del modello corretto:
from langchain_community.document_compressors import JinaRerank
reranker = JinaRerank(model="jina-reranker-v2-base-multilingual", jina_api_key="<YOUR JINA AI API KEY HERE>")
tagTramite HuggingFace
Stiamo anche aprendo l'accesso (sotto CC-BY-NC-4.0) al modello jina-reranker-v2-base-multilingual su Hugging Face per scopi di ricerca e valutazione.

Per scaricare ed eseguire il modello da Hugging Face, installa le librerie transformers ed einops:
pip install transformers einops
pip install ninja
pip install flash-attn --no-build-isolation
Accedi al tuo account Hugging Face attraverso il login CLI di Hugging Face utilizzando il tuo token di accesso Hugging Face:
huggingface-cli login --token <"HF-Access-Token">
Scarica il modello pre-addestrato:
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained(
'jinaai/jina-reranker-v2-base-multilingual',
torch_dtype="auto",
trust_remote_code=True,
)
model.to('cuda') # o 'cpu' se non è disponibile una GPU
model.eval()
Definisci la query e i documenti da riordinare:
query = "Organic skincare products for sensitive skin"
documents = [
"Organic skincare for sensitive skin with aloe vera and chamomile.",
"New makeup trends focus on bold colors and innovative techniques",
"Bio-Hautpflege für empfindliche Haut mit Aloe Vera und Kamille",
"Neue Make-up-Trends setzen auf kräftige Farben und innovative Techniken",
"Cuidado de la piel orgánico para piel sensible con aloe vera y manzanilla",
"Las nuevas tendencias de maquillaje se centran en colores vivos y técnicas innovadoras",
"针对敏感肌专门设计的天然有机护肤产品",
"新的化妆趋势注重鲜艳的颜色和创新的技巧",
"敏感肌のために特別に設計された天然有機スキンケア製品",
"新しいメイクのトレンドは鮮やかな色と革新的な技術に焦点を当てています",
]
Costruisci coppie di frasi e calcola i punteggi di rilevanza:
sentence_pairs = [[query, doc] for doc in documents]
scores = model.compute_score(sentence_pairs, max_length=1024)
I punteggi saranno una lista di numeri float, dove ogni float rappresenta il punteggio di rilevanza del documento corrispondente rispetto alla query. Punteggi più alti indicano una maggiore rilevanza.
In alternativa, usa la funzione rerank per riordinare testi lunghi suddividendo automaticamente la query e i documenti in base a max_query_length e
max_length. Ogni blocco viene valutato individualmente e i punteggi di ciascun blocco vengono poi combinati per produrre i risultati finali del riordinamento:results = model.rerank(
query,
documents,
max_query_length=512,
max_length=1024,
top_n=3
)
Questa funzione non restituisce solo il punteggio di rilevanza per ogni documento, ma anche il loro contenuto e la posizione nell'elenco originale dei documenti.
tagTramite Distribuzione su Cloud Privato
I pacchetti precompilati per la distribuzione privata di Jina Reranker v2 su account AWS e Azure saranno presto disponibili sulle nostre pagine venditore su AWS Marketplace e Azure Marketplace, rispettivamente.
tagPunti Chiave di Jina Reranker v2
Jina Reranker v2 rappresenta un'importante espansione delle capacità per search foundation:
- Il recupero allo stato dell'arte utilizzando il cross-encoding apre un'ampia gamma di nuove aree di applicazione.
- La funzionalità multilingue e cross-language migliorata rimuove le barriere linguistiche dai tuoi casi d'uso.
- Il supporto best-in-class per la function calling, insieme alla consapevolezza delle query di dati strutturati, porta le tue capacità di RAG agentico al livello successivo di precisione.
- Un miglior recupero del codice informatico e dei dati in formato computer può andare ben oltre il semplice recupero di informazioni testuali.
- Una velocità di elaborazione dei documenti molto più elevata garantisce che, indipendentemente dal metodo di recupero, ora puoi riordinare molti più documenti recuperati più velocemente e delegare la maggior parte del calcolo della rilevanza dettagliata a jina-reranker-v2-base-multilingual.
I sistemi RAG sono molto più precisi con Reranker v2, aiutando le tue soluzioni esistenti di gestione delle informazioni a produrre risultati più numerosi e migliori. Il supporto cross-language rende tutto questo direttamente disponibile per le imprese multinazionali e multilingue, con un'API facile da usare a un prezzo accessibile.
Testandolo con benchmark derivati da casi d'uso reali, puoi vedere di persona come Jina Reranker v2 mantiene prestazioni allo stato dell'arte in compiti rilevanti per modelli di business reali, tutto in un unico modello di AI, mantenendo bassi i costi e il tuo stack tecnologico più semplice.
