


Novità! Parte II: approfondimento sui segnali di confine e sui malintesi.
Circa un anno fa, nell'ottobre 2023, abbiamo rilasciato il primo modello di embedding open-source al mondo con una lunghezza di contesto di 8K, jina-embeddings-v2-base-en. Da allora, c'è stato un notevole dibattito sull'utilità del contesto lungo nei modelli di embedding. Per molte applicazioni, codificare un documento di migliaia di parole in una singola rappresentazione di embedding non è ideale. Molti casi d'uso richiedono il recupero di porzioni più piccole del testo, e i sistemi di recupero basati su vettori densi spesso funzionano meglio con segmenti di testo più piccoli, poiché la semantica ha meno probabilità di essere "sovra-compressa" nei vettori di embedding.
La Retrieval-Augmented Generation (RAG) è una delle applicazioni più note che richiede la suddivisione dei documenti in chunk di testo più piccoli (diciamo entro 512 token). Questi chunk vengono solitamente memorizzati in un database vettoriale, con rappresentazioni vettoriali generate da un modello di embedding del testo. Durante l'esecuzione, lo stesso modello di embedding codifica una query in una rappresentazione vettoriale, che viene poi utilizzata per identificare i chunk di testo rilevanti memorizzati. Questi chunk vengono successivamente passati a un large language model (LLM), che sintetizza una risposta alla query basata sui testi recuperati.

In breve, l'embedding di chunk più piccoli sembra essere preferibile, in parte a causa delle dimensioni di input limitate degli LLM a valle, ma anche perché c'è la preoccupazione che le informazioni contestuali importanti in un contesto lungo possano essere diluite quando compresse in un singolo vettore.
Ma se l'industria ha bisogno solo di modelli di embedding con una lunghezza di contesto di 512, qual è il senso di addestrare modelli con una lunghezza di contesto di 8192?
In questo articolo, riesaminiamo questa domanda importante, anche se scomoda, esplorando i limiti della pipeline ingenua di chunking-embedding in RAG. Introduciamo un nuovo approccio chiamato "Late Chunking," che sfrutta le ricche informazioni contestuali fornite dai modelli di embedding da 8192 per incorporare i chunk in modo più efficace.
tagIl Problema del Contesto Perduto
La semplice pipeline RAG di chunking-embedding-retrieving-generating non è priva di sfide. In particolare, questo processo può distruggere le dipendenze contestuali a lunga distanza. In altre parole, quando le informazioni rilevanti sono distribuite su più chunk, estrarre segmenti di testo dal contesto può renderli inefficaci, rendendo questo approccio particolarmente problematico.
Nell'immagine sottostante, un articolo di Wikipedia è suddiviso in chunk di frasi. Si può vedere che frasi come "its" e "the city" si riferiscono a "Berlin", che è menzionata solo nella prima frase. Questo rende più difficile per il modello di embedding collegare questi riferimenti all'entità corretta, producendo così una rappresentazione vettoriale di qualità inferiore.

Questo significa che, se dividiamo un lungo articolo in chunk di lunghezza frase, come nell'esempio sopra, un sistema RAG potrebbe avere difficoltà a rispondere a una query come "Qual è la popolazione di Berlino?" Poiché il nome della città e la popolazione non appaiono mai insieme in un singolo chunk, e senza alcun contesto documentale più ampio, un LLM presentato con uno di questi chunk non può risolvere riferimenti anaforici come "it" o "the city".
Esistono alcune euristiche per alleviare questo problema, come il ricampionamento con una finestra scorrevole, l'uso di finestre di contesto multiple e l'esecuzione di scansioni del documento a più passaggi. Tuttavia, come tutte le euristiche, questi approcci sono aleatori; possono funzionare in alcuni casi, ma non c'è alcuna garanzia teorica della loro efficacia.
tagLa Soluzione: Late Chunking
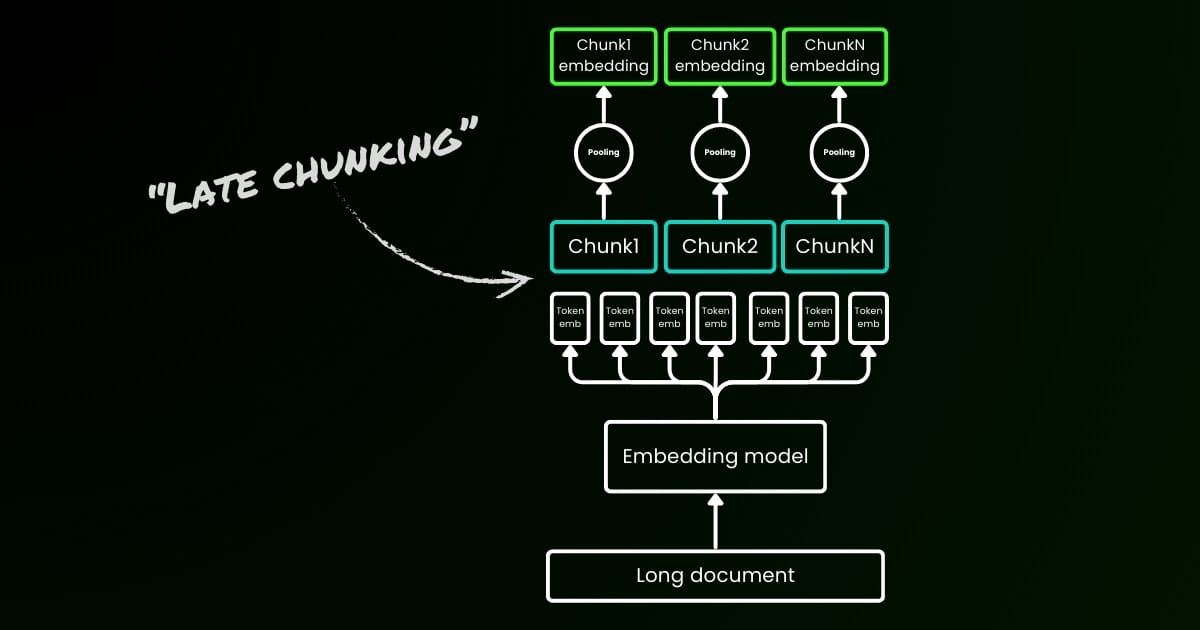
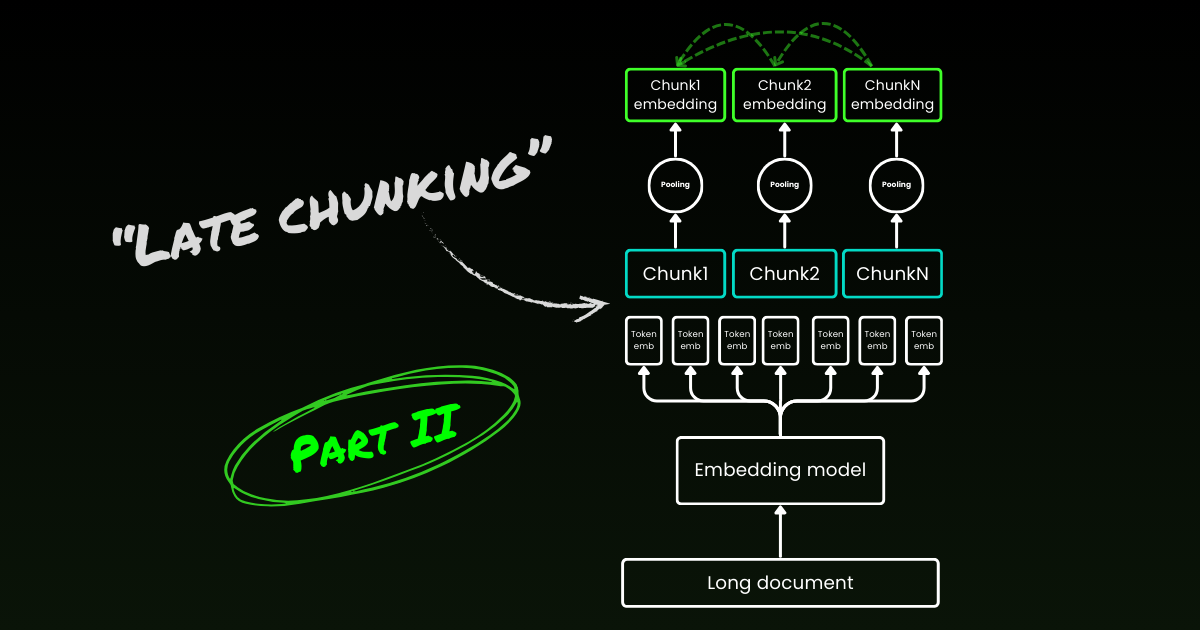
L'approccio di codifica ingenuo (come si vede sul lato sinistro dell'immagine sottostante) implica l'uso di frasi, paragrafi o limiti di lunghezza massima per dividere il testo a priori. Successivamente, un modello di embedding viene applicato ripetutamente a questi chunk risultanti. Per generare un singolo embedding per ogni chunk, molti modelli di embedding utilizzano il mean pooling su questi embedding a livello di token per produrre un singolo vettore di embedding.

Al contrario, l'approccio "Late Chunking" che proponiamo in questo articolo applica prima il layer transformer del modello di embedding a tutto il testo o a quanto più possibile. Questo genera una sequenza di rappresentazioni vettoriali per ogni token che comprende informazioni testuali dall'intero testo. Successivamente, il mean pooling viene applicato a ogni chunk di questa sequenza di vettori token, producendo embedding per ogni chunk che considerano il contesto dell'intero testo. A differenza dell'approccio di codifica ingenuo, che genera embedding di chunk indipendenti e identicamente distribuiti (i.i.d.), il late chunking crea un insieme di embedding di chunk dove ciascuno è "condizionato da" quelli precedenti, codificando così più informazioni contestuali per ogni chunk.
Ovviamente per applicare efficacemente il late chunking, abbiamo bisogno di modelli di embedding a lungo contesto come jina-embeddings-v2-base-en, che supportano fino a 8192 token—circa dieci pagine standard di testo. Segmenti di testo di questa dimensione hanno molte meno probabilità di avere dipendenze contestuali che richiedono un contesto ancora più lungo da risolvere.
È importante sottolineare che il late chunking richiede ancora segnali di confine, ma questi segnali vengono utilizzati solo dopo aver ottenuto gli embedding a livello di token—da qui il termine "late" nel suo nome.
| Chunking Ingenuo | Late Chunking | |
|---|---|---|
| Necessità di segnali di confine | Sì | Sì |
| Uso dei segnali di confine | Direttamente nel preprocessing | Dopo aver ottenuto gli embedding a livello di token dal layer transformer |
| Gli embedding di chunk risultanti | i.i.d. | Condizionati |
| Informazioni contestuali dei chunk vicini | Perse. Alcune euristiche (come il campionamento sovrapposto) per alleviare questo | Ben preservate dai modelli di embedding a lungo contesto |
tagImplementazione e Valutazione Qualitativa


L'implementazione del late chunking può essere trovata nel Google Colab linkato sopra. Qui, utilizziamo la nostra recente funzionalità rilasciata nella Tokenizer API, che sfrutta tutti i possibili segnali di confine per segmentare un lungo documento in chunk significativi. Ulteriori discussioni sull'algoritmo alla base di questa funzionalità possono essere trovate su X.

Quando si applica il late chunking all'esempio di Wikipedia sopra riportato, si può notare immediatamente un miglioramento nella similarità semantica. Per esempio, nel caso di "la città" e "Berlino" all'interno di un articolo di Wikipedia, i vettori che rappresentano "la città" contengono ora informazioni che la collegano alla precedente menzione di "Berlino", rendendola una corrispondenza molto migliore per le query che coinvolgono quel nome di città.
| Query | Chunk | Sim. on naive chunking | Sim. on late chunking |
|---|---|---|---|
| Berlin | Berlin is the capital and largest city of Germany, both by area and by population. | 0.849 | 0.850 |
| Berlin | Its more than 3.85 million inhabitants make it the European Union's most populous city, as measured by population within city limits. | 0.708 | 0.825 |
| Berlin | The city is also one of the states of Germany, and is the third smallest state in the country in terms of area. | 0.753 | 0.850 |
Puoi osservare questo nei risultati numerici sopra riportati, che confrontano l'embedding del termine "Berlin" con varie frasi dell'articolo su Berlino utilizzando la similarità del coseno. La colonna "Sim. on IID chunk embeddings" mostra i valori di similarità tra l'embedding della query "Berlin" e gli embedding utilizzando il chunking a priori, mentre "Sim. under contextual chunk embedding" rappresenta i risultati con il metodo di late chunking.
tagValutazione Quantitativa su BEIR
Per verificare l'efficacia del late chunking oltre un semplice esempio, lo abbiamo testato utilizzando alcuni dei benchmark di recupero da BeIR. Questi task di recupero consistono in un set di query, un corpus di documenti di testo e un file QRels che memorizza informazioni sugli ID dei documenti rilevanti per ciascuna query.
Per identificare i documenti rilevanti per una query, i documenti vengono suddivisi in chunk, codificati in un indice di embedding e i chunk più simili vengono determinati per ogni embedding di query utilizzando i k-nearest neighbors (kNN). Poiché ogni chunk corrisponde a un documento, il ranking kNN dei chunk può essere convertito in un ranking kNN dei documenti (mantenendo solo la prima occorrenza per i documenti che appaiono più volte nel ranking). Questo ranking risultante viene poi confrontato con il ranking fornito dal file QRels di ground-truth, e vengono calcolate metriche di recupero come nDCG@10. Questa procedura è illustrata di seguito, e lo script di valutazione può essere trovato in questo repository per la riproducibilità.
 jina-ai
jina-aiAbbiamo eseguito questa valutazione su vari dataset BeIR, confrontando il chunking naive con il nostro metodo di late chunking. Per ottenere gli indizi di confine, abbiamo utilizzato una regex che divide i testi in stringhe di circa 256 token. Sia la valutazione naive che quella late chunking hanno utilizzato jina-embeddings-v2-small-en come modello di embedding; una versione più piccola del modello v2-base-en che supporta ancora una lunghezza fino a 8192 token. I risultati si trovano nella tabella seguente.
| Dataset | Avg. Document Length (characters) | Naive Chunking (nDCG@10) | Late Chunking (nDCG@10) | No Chunking (nDCG@10) |
|---|---|---|---|---|
| SciFact | 1498.4 | 64.20% | 66.10% | 63.89% |
| TRECCOVID | 1116.7 | 63.36% | 64.70% | 65.18% |
| FiQA2018 | 767.2 | 33.25% | 33.84% | 33.43% |
| NFCorpus | 1589.8 | 23.46% | 29.98% | 30.40% |
| Quora | 62.2 | 87.19% | 87.19% | 87.19% |
In tutti i casi, il late chunking ha migliorato i punteggi rispetto all'approccio naive. In alcuni casi, ha anche superato la codifica dell'intero documento in un singolo embedding, mentre in altri dataset, non effettuare chunking ha prodotto i risultati migliori (Ovviamente, il no chunking ha senso solo se non c'è bisogno di classificare i chunk, cosa rara nella pratica). Se tracciamo il divario di prestazioni tra l'approccio naive e il late chunking rispetto alla lunghezza del documento, diventa evidente che la lunghezza media dei documenti è correlata a maggiori miglioramenti nei punteggi nDCG attraverso il late chunking. In altre parole, più lungo è il documento, più efficace diventa la strategia di late chunking.

tagConclusione
In questo articolo, abbiamo introdotto un approccio semplice chiamato "late chunking" per incorporare chunk brevi sfruttando la potenza dei modelli di embedding a lungo contesto. Abbiamo dimostrato come l'embedding di chunk i.i.d. tradizionale non riesca a preservare le informazioni contestuali, portando a un recupero subottimale; e come il late chunking offra una soluzione semplice ma altamente efficace per mantenere e condizionare le informazioni contestuali all'interno di ciascun chunk. L'efficacia del late chunking diventa sempre più significativa sui documenti più lunghi—una capacità resa possibile solo da modelli di embedding a lungo contesto avanzati come jina-embeddings-v2-base-en. Speriamo che questo lavoro non solo convalidi l'importanza dei modelli di embedding a lungo contesto ma ispiri anche ulteriori ricerche su questo argomento.
Continua a leggere la parte II: approfondimento sugli indizi di confine e sui malintesi.
