



late_chunking controlla se il modello elabora l'intero documento prima di dividerlo in chunks, preservando più contesto attraverso testi lunghi. Dal punto di vista dell'utente, i formati di input e output rimangono gli stessi, ma i valori di embedding rifletteranno il contesto completo del documento invece di essere calcolati indipendentemente per ogni chunk.- Quando si usa
late_chunking=True, il numero totale di token (sommato tra tutti i chunk ininput) per richiesta è limitato a 8192, la lunghezza massima del contesto consentita per v3. - Quando si usa
late_chunking=False, questo limite di token non si applica, e il totale dei token è limitato solo dal rate limit delle API di Embedding.
Per abilitare il late chunking, passa late_chunking=True nelle tue chiamate API.
Puoi vedere il vantaggio del late chunking cercando attraverso una cronologia di chat:
history = [
"Sita, have you decided where you'd like to go for dinner this Saturday for your birthday?",
"I'm not sure. I'm not too familiar with the restaurants in this area.",
"We could always check out some recommendations online.",
"That sounds great. Let's do that!",
"What type of food are you in the mood for on your special day?",
"I really love Mexican or Italian cuisine.",
"How about this place, Bella Italia? It looks nice.",
"Oh, I've heard of that! Everyone says it's fantastic!",
"Shall we go ahead and book a table there then?",
"Yes, I think that would be a perfect choice! Let's call and reserve a spot."
]
Se chiediamo What's a good restaurant? con Embeddings v2, i risultati non sono molto rilevanti:
| Document | Cosine Similarity |
|---|---|
| I'm not sure. I'm not too familiar with the restaurants in this area. | 0.7675 |
| I really love Mexican or Italian cuisine. | 0.7561 |
| How about this place, Bella Italia? It looks nice. | 0.7268 |
| What type of food are you in the mood for on your special day? | 0.7217 |
| Sita, have you decided where you'd like to go for dinner this Saturday for your birthday? | 0.7186 |
Con v3 e senza late chunking, otteniamo risultati simili:
| Document | Cosine Similarity |
|---|---|
| I'm not sure. I'm not too familiar with the restaurants in this area. | 0.4005 |
| I really love Mexican or Italian cuisine. | 0.3752 |
| Sita, have you decided where you'd like to go for dinner this Saturday for your birthday? | 0.3330 |
| How about this place, Bella Italia? It looks nice. | 0.3143 |
| Yes, I think that would be a perfect choice! Let's call and reserve a spot. | 0.2615 |
Tuttavia, vediamo un notevole miglioramento delle prestazioni quando utilizziamo v3 e late chunking, con il risultato più rilevante (un buon ristorante) in cima:
| Document | Cosine Similarity |
|---|---|
| How about this place, Bella Italia? It looks nice. | 0.5061 |
| Oh, I've heard of that! Everyone says it's fantastic! | 0.4498 |
| I really love Mexican or Italian cuisine. | 0.4373 |
| What type of food are you in the mood for on your special day? | 0.4355 |
| Yes, I think that would be a perfect choice! Let's call and reserve a spot. | 0.4328 |
Come puoi vedere, anche se la corrispondenza migliore non menziona affatto la parola "ristorante", il late chunking preserva il suo contesto originale e lo presenta come la risposta corretta in cima. Codifica "ristorante" nel nome del ristorante "Bella Italia" perché ne comprende il significato nel testo più ampio.
tagBilanciare Efficienza e Prestazioni con gli Embedding Matryoshka
Il parametro dimensions in Embeddings v3 ti dà la capacità di bilanciare l'efficienza dello storage con le prestazioni a costo minimo. Gli embedding Matryoshka di v3 ti permettono di troncare i vettori prodotti dal modello, riducendo le dimensioni quanto necessario mantenendo le informazioni utili. Embedding più piccoli sono ideali per risparmiare spazio nei database vettoriali e migliorare la velocità di recupero. Puoi stimare l'impatto sulle prestazioni in base a quanto vengono ridotte le dimensioni:
data = {
"model": "jina-embeddings-v3",
"task": "text-matching",
"dimensions": 768, # 1024 by default
"input": [
"The Force will be with you. Always.",
"力量与你同在。永远。",
"La Forza sarà con te. Sempre.",
"フォースと共にあらんことを。いつも。"
]
}
response = requests.post(url, headers=headers, json=data)
tagFAQ
tagSto già suddividendo i miei documenti prima di generare gli embedding. Il Late Chunking offre vantaggi rispetto al mio sistema?
Il late chunking offre vantaggi rispetto al pre-chunking perché elabora prima l'intero documento, preservando importanti relazioni contestuali attraverso il testo prima di dividerlo in chunk. Questo risulta in embedding più ricchi di contesto, che possono migliorare l'accuratezza del recupero, specialmente in documenti complessi o lunghi. Inoltre, il late chunking può aiutare a fornire risposte più rilevanti durante la ricerca o il recupero, poiché il modello ha una comprensione olistica del documento prima di segmentarlo. Questo porta a prestazioni generali migliori rispetto al pre-chunking, dove i chunk vengono trattati indipendentemente senza il contesto completo.
tagPerché v2 è migliore di v3 nella classificazione a coppie, e dovrei preoccuparmi?
Il motivo per cui i modelli v2-base-(zh/es/de) sembrano avere prestazioni migliori nella Pair Classification (PC) è principalmente dovuto a come viene calcolato il punteggio medio. In v2, solo il cinese viene considerato per le prestazioni PC, dove il modello embeddings-v2-base-zh eccelle, portando a un punteggio medio più alto. I benchmark di v3 includono quattro lingue: cinese, francese, polacco e russo. Di conseguenza, il suo punteggio complessivo appare più basso quando confrontato con il punteggio di v2 solo per il cinese. Tuttavia, v3 eguaglia o supera ancora modelli come multilingual-e5 in tutte le lingue per i task PC. Questa portata più ampia spiega la differenza percepita, e il calo delle prestazioni non dovrebbe essere motivo di preoccupazione, specialmente per applicazioni multilingue dove v3 rimane altamente competitivo.
tagv3 supera davvero le prestazioni dei modelli bilingue v2 nelle lingue specifiche?
Quando si confronta v3 con i modelli bilingue v2, la differenza di prestazioni dipende dalle lingue e dai compiti specifici.
I modelli bilingue v2 erano altamente ottimizzati per le loro rispettive lingue. Di conseguenza, in benchmark specifici per quelle lingue, come la Pair Classification (PC) in cinese, v2 potrebbe mostrare risultati superiori. Questo perché il design di embeddings-v2-base-zh era su misura specificamente per quella lingua, permettendogli di eccellere in quell'ambito ristretto.
Tuttavia, v3 è progettato per un supporto multilingue più ampio, gestendo 89 lingue ed essendo ottimizzato per una varietà di compiti con adattatori LoRA specifici per task. Questo significa che mentre v3 potrebbe non sempre superare v2 in ogni singolo compito per una lingua specifica (come PC per il cinese), tende a funzionare meglio nel complesso quando valutato su più lingue o in scenari più complessi e specifici per task come il recupero e la classificazione.
Per compiti multilingue o quando si lavora con diverse lingue, v3 offre una soluzione più bilanciata e completa, sfruttando una migliore generalizzazione tra le lingue. Tuttavia, per compiti molto specifici per lingua dove il modello bilingue era finemente sintonizzato, v2 potrebbe mantenere un vantaggio.
In pratica, il modello giusto dipende dalle esigenze specifiche del tuo compito. Se stai lavorando solo con una particolare lingua e v2 era ottimizzato per essa, potresti ancora vedere risultati competitivi con v2. Ma per applicazioni più generalizzate o multilingue, v3 è probabilmente la scelta migliore grazie alla sua versatilità e ottimizzazione più ampia.
tagPerché v2 è migliore di v3 nella sintetizzazione, e devo preoccuparmi di questo?
v2-base-en ha prestazioni migliori nella sintetizzazione (SM) perché la sua architettura era ottimizzata per compiti come la similarità semantica, che è strettamente correlata alla sintetizzazione. Al contrario, v3 è progettato per supportare una gamma più ampia di compiti, in particolare nei task di recupero e classificazione, ed è più adatto a scenari complessi e multilingue.
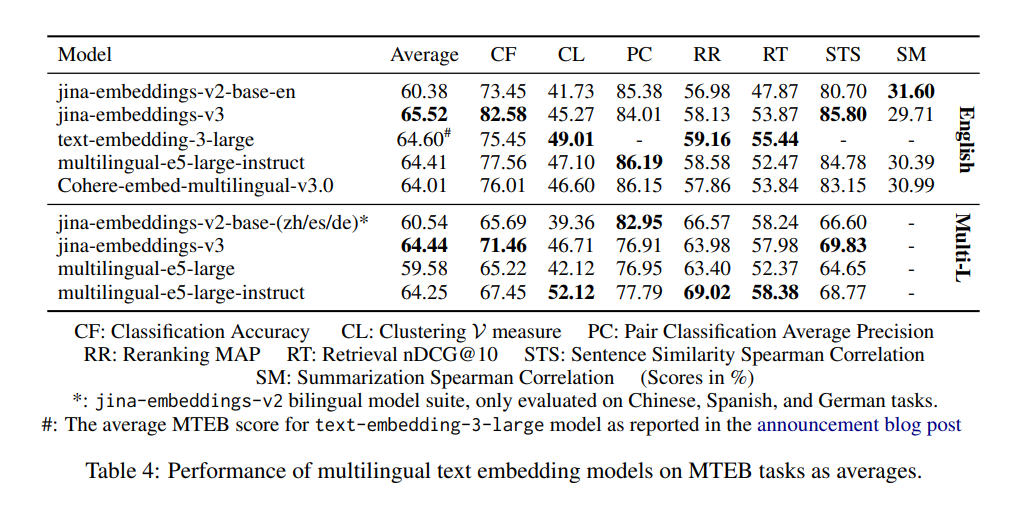
Tuttavia, questa differenza di prestazioni in SM non dovrebbe essere motivo di preoccupazione per la maggior parte degli utenti. La valutazione SM si basa su un solo task di sintetizzazione, SummEval, che misura principalmente la similarità semantica. Questo task da solo non è molto informativo o rappresentativo delle più ampie capacità del modello. Dato che v3 eccelle in altre aree critiche come il recupero, è probabile che la differenza nella sintetizzazione non influirà significativamente sui tuoi casi d'uso nel mondo reale.
