

Con il recente rilascio di jina-reranker-v2-multilingual, ho avuto un po' di tempo libero prima del mio viaggio all'ICML, così ho deciso di scrivere un articolo sul nostro modello di reranker. Mentre cercavo idee su internet, ho trovato un articolo che è apparso tra i miei primi risultati di ricerca, affermando che i reranker possono migliorare la SEO. Interessante, vero? Lo pensavo anch'io perché in Jina AI ci occupiamo di reranker, e come webmaster del sito web aziendale, sono sempre interessato a migliorare la nostra SEO.
Tuttavia, dopo aver letto l'intero articolo, ho scoperto che era completamente generato da ChatGPT. L'intero articolo si limita a parafrasare ripetutamente l'idea che "il Reranking è importante per il tuo business/sito web" senza mai spiegare come, quale sia la matematica dietro, o come implementarlo. È stato una perdita di tempo.
Non si possono unire Reranker e SEO. Lo sviluppatore del sistema di ricerca (o in generale il consumatore di contenuti) si preoccupa dei reranker, mentre il creatore di contenuti si preoccupa della SEO e del fatto che i suoi contenuti si classifichino più in alto in quel sistema. Sono fondamentalmente seduti ai lati opposti del tavolo e raramente si scambiano idee. Chiedere a un reranker di migliorare la SEO è come chiedere a un fabbro di potenziare il tuo incantesimo di palla di fuoco o ordinare sushi in un ristorante cinese. Non sono completamente irrilevanti, ma è ovviamente un obiettivo sbagliato.
Immagina se Google mi invitasse nel loro ufficio per chiedere la mia opinione se il loro reranker classifica abbastanza in alto jina.ai. O se avessi il pieno controllo sull'algoritmo di reranking di Google e codificassi jina.ai in cima ogni volta che qualcuno cerca "information retrieval". Nessuno dei due scenari ha senso. Quindi perché abbiamo questi articoli in primo luogo? Beh, se lo chiedi a ChatGPT, diventa molto ovvio da dove viene originariamente questa idea.

tagMotivazione
Se quell'articolo generato dall'IA si classifica in cima su Google, vorrei scrivere un articolo migliore e di qualità superiore per prendere il suo posto. Non voglio ingannare né gli umani né ChatGPT, quindi il mio punto in questo articolo è molto chiaro:
Nello specifico, in questo articolo, esamineremo le query di ricerca reali esportate da Google Search Console e vedremo se la loro relazione semantica con l'articolo suggerisce qualcosa sulle loro impressioni e clic su Google Search. Esamineremo tre modi diversi per valutare la relazione semantica: frequenza dei termini, modello di embedding (jina-embeddings-v2-base-en) e modello reranker (jina-reranker-v2-multilingual). Come in qualsiasi ricerca accademica, delineiamo prima le domande che vogliamo studiare:
- Il punteggio semantico (query, documento) è correlato alle impressioni o ai clic dell'articolo?
- Un modello più profondo è un predittore migliore di tale relazione? O la frequenza dei termini è sufficiente?
tagSetup Sperimentale
In questo esperimento, utilizziamo dati reali dal sito web jina.ai/news esportati da Google Search Console (GSC). GSC è uno strumento per webmaster che ti permette di analizzare il traffico di ricerca organico dagli utenti di Google, come quante persone aprono il tuo post del blog tramite Google Search e quali sono le query di ricerca. Ci sono molte metriche che puoi estrarre da GSC, ma per questo esperimento, ci concentriamo su tre: query, impressioni e clic. Le query sono ciò che gli utenti inseriscono nella casella di ricerca di Google. Le impressioni misurano quante volte Google mostra il tuo link nei risultati di ricerca, dando agli utenti la possibilità di vederlo. I clic misurano quante volte gli utenti lo aprono effettivamente. Nota che potresti ottenere molte impressioni se il "modello di recupero" di Google assegna al tuo articolo un punteggio di rilevanza alto rispetto alla query dell'utente. Tuttavia, se gli utenti trovano altri elementi in quella lista di risultati più interessanti, la tua pagina potrebbe comunque ottenere zero clic.
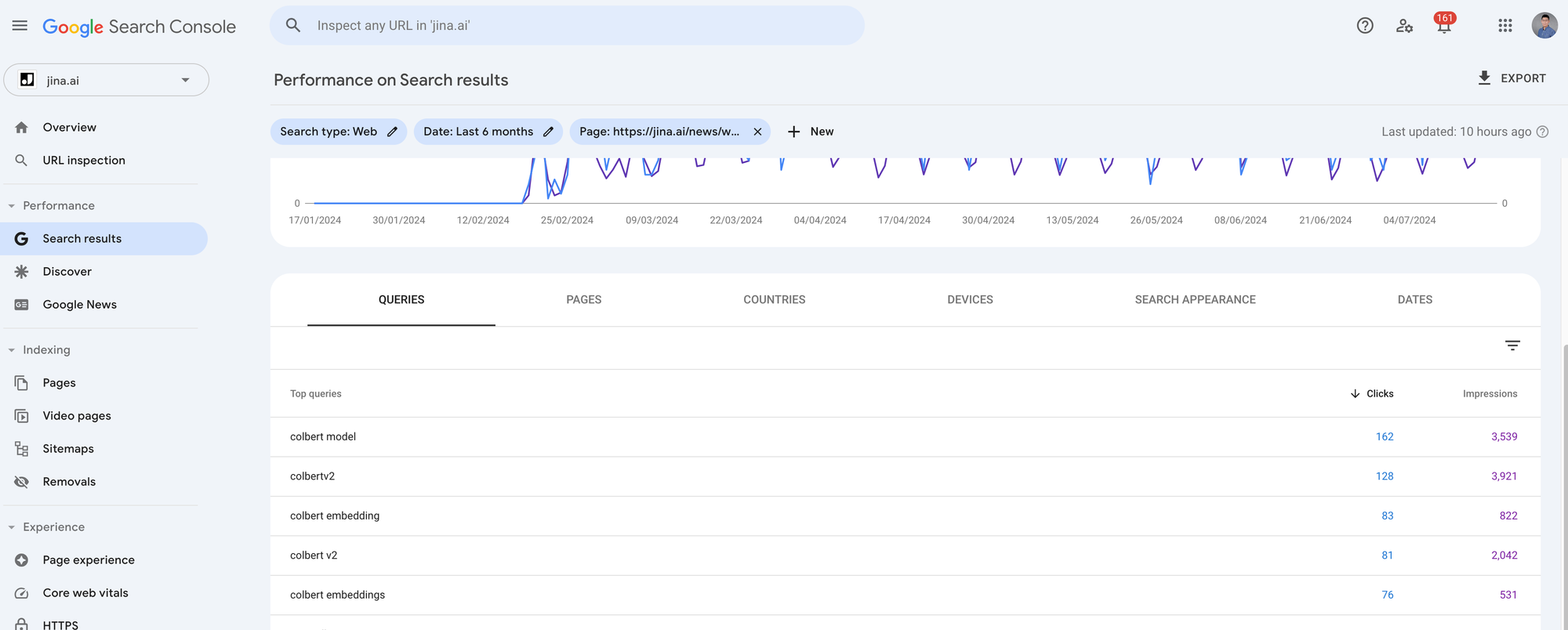
Ho esportato gli ultimi 4 mesi di metriche GSC per i 7 post del blog più cercati da jina.ai/news. Ogni articolo ha tra 1.000 e 5.000 clic e tra 10.000 e 90.000 impressioni. Poiché vogliamo esaminare la semantica query-articolo per ogni query di ricerca rispetto ai loro articoli corrispondenti, devi cliccare su ciascun articolo in GSC ed esportare i dati cliccando il pulsante Export in alto a destra. Ti darà un file zip e quando lo decomprimi, troverai un file Queries.csv. Questo è il file di cui abbiamo bisogno.
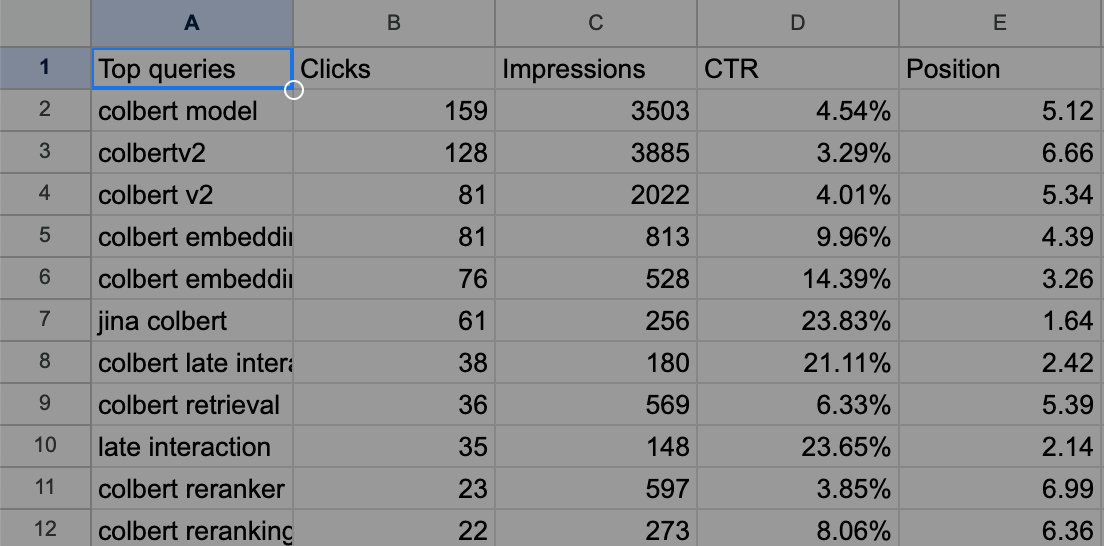
Come esempio, il file Queries.csv esportato appare come segue per il nostro post su ColBERT.
tagMetodologia
Okay, quindi i dati sono tutti pronti, e cosa vogliamo fare di nuovo?
Vogliamo verificare se la relazione semantica tra una query e l'articolo (indicata come ) correla con le loro impressioni e clic. Le impressioni possono essere considerate come il modello di recupero segreto di Google, . In altre parole, vogliamo utilizzare metodi pubblici come la frequenza dei termini, i modelli di embedding e i modelli reranker per modellare e vedere se approssima questo privato.
E i clic? I clic possono anche essere considerati come parte del modello di recupero segreto di Google ma sono influenzati da fattori umani indeterministici. Intuitivamente, i clic sono più difficili da modellare.
In ogni caso, allineare a è il nostro obiettivo. Questo significa che il nostro dovrebbe dare punteggi alti quando è alto e bassi quando è basso. Questo può essere meglio visualizzato con un grafico a dispersione, mettendo sull'asse X e sull'asse Y. Tracciando i valori di e per ogni query, possiamo vedere intuitivamente quanto bene il nostro modello di recupero si allinea con il modello di recupero di Google. Sovrapporre una linea di tendenza può aiutare a rivelare eventuali pattern affidabili.
Quindi, permettetemi di riassumere il metodo qui prima di mostrare i risultati:
- Vogliamo verificare se la relazione semantica tra una query e un articolo correla con le impressioni e i click su Google Search.
- L'algoritmo che Google usa per determinare la rilevanza del documento per una query è sconosciuto (), così come i fattori alla base dei click. Tuttavia, possiamo osservare questi numeri da GSC, cioè le impressioni e i click per ogni query.
- Puntiamo a vedere se i metodi di recupero pubblici () come term frequency, embedding models e reranker models, che forniscono tutti modi unici per valutare la rilevanza query-documento, sono buone approssimazioni di . In qualche modo, sappiamo già che non sono buone approssimazioni; altrimenti, tutti potrebbero essere Google. Ma vogliamo capire quanto sono distanti.
- Visualizzeremo i risultati in un grafico a dispersione per l'analisi qualitativa.
tagImplementazione
L'implementazione completa può essere trovata nel Google Colab qui sotto.


Prima estraiamo il contenuto del post del blog usando la Jina Reader API. La term frequency delle query è determinata dal conteggio base senza distinzione tra maiuscole e minuscole. Per il modello di embedding, raggruppiamo il contenuto del blog post e tutte le query di ricerca in una grande richiesta, così: [[blog1_content], [q1], [q2], [q3], ..., [q481]], e la inviamo alla Embedding API. Dopo aver ricevuto la risposta, calcoliamo la similarità basata sul coseno tra il primo embedding e tutti gli altri embedding per ottenere il punteggio semantico per query.
Per il modello reranker, costruiamo la richiesta in modo leggermente particolare: {query: [blog1_content], documents: [[q1], [q2], [q3], ..., [q481]]} e inviamo questa grande richiesta alla Reranker API. Il punteggio restituito può essere utilizzato direttamente come rilevanza semantica. Definisco questa costruzione particolare perché, di solito, i reranker vengono utilizzati per classificare i documenti data una query. In questo caso, invertiamo i ruoli di documento e query e utilizziamo il reranker per classificare le query dato un documento.
Nota che sia nelle API di Embedding che in quelle di Reranker, non devi preoccuparti della lunghezza dell'articolo (le query sono sempre corte, quindi nessun problema) perché entrambe le API supportano fino a 8K di lunghezza in input (in realtà, la nostra API Reranker supporta una lunghezza "infinita"). Tutto può essere fatto rapidamente in pochi secondi, e puoi ottenere una chiave API gratuita da 1M di token dal nostro sito web per questo esperimento.
tagRisultati
Finalmente, i risultati. Ma prima di mostrarli, vorrei prima dimostrare come appaiono i grafici di base. A causa del grafico a dispersione e della scala logaritmica sull'asse Y che useremo, può essere difficile immaginare come apparirebbero perfettamente buoni e terribilmente cattivi. Ho costruito due baseline ingenue: una dove è (ground truth), e l'altra dove (casuale). Diamo un'occhiata alle loro visualizzazioni.
tagBaseline


Ora abbiamo un'intuizione di come appaiono i predittori "perfettamente buoni" e "terribilmente cattivi". Tieni a mente questi due grafici insieme ai seguenti punti chiave che possono essere molto utili per l'ispezione visiva:
- Il grafico a dispersione di un buon predittore dovrebbe seguire la linea di tendenza logaritmica dal basso a sinistra all'alto a destra.
- La linea di tendenza di un buon predittore dovrebbe estendersi completamente sugli assi X e Y (vedremo più tardi che alcuni predittori non rispondono in questo modo).
- L'area di varianza di un buon predittore dovrebbe essere piccola (rappresentata come un'area opaca intorno alla linea di tendenza).
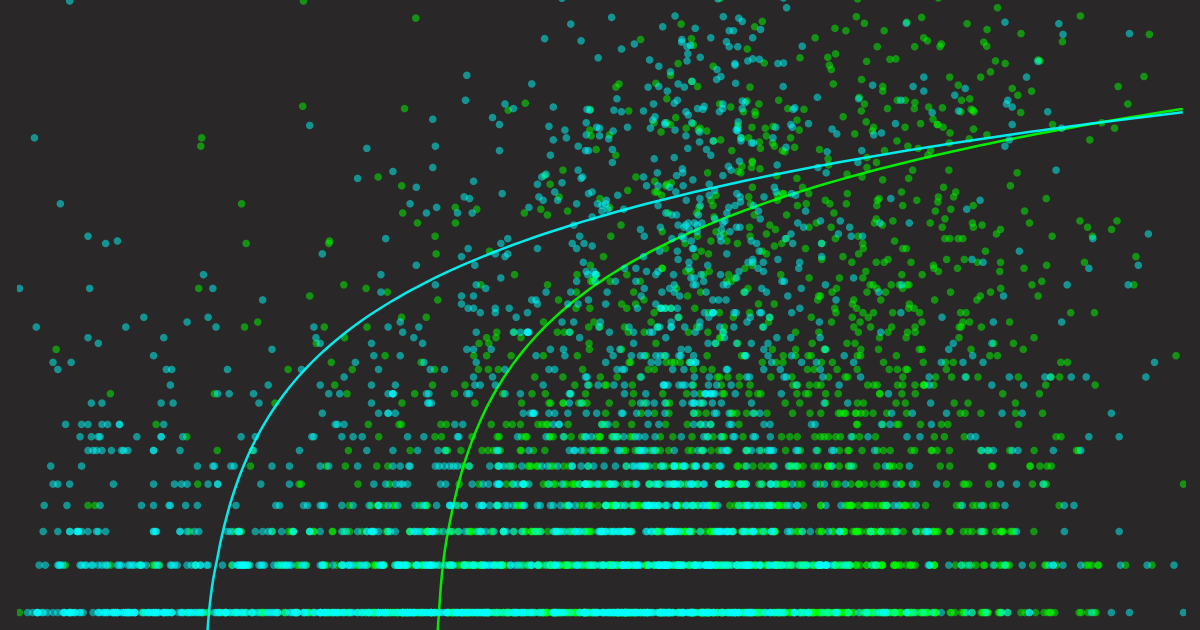
Successivamente, mostrerò tutti i grafici insieme, ogni predittore con due grafici: uno che mostra quanto bene predice le impressioni e uno che mostra quanto bene predice i click. Nota che ho aggregato i dati da tutti e 7 i post del blog, quindi in totale ci sono 3620 query, cioè 3620 punti dati in ogni grafico a dispersione.
Per favore, prenditi qualche minuto per scorrere su e giù ed esaminare questi grafici, confrontarli e prestare attenzione ai dettagli. Lascia che questo si sedimenti, e nella prossima sezione, concluderò i risultati.
tagTerm Frequency come Predittore


tagEmbedding Model come Predittore


tagReranker Model come Predittore


tagRisultati
Mettiamo tutti i grafici in un unico posto per facilitare il confronto. Ecco alcune osservazioni e spiegazioni:



Diversi predittori sulle impressioni. Ogni punto rappresenta una query, l'asse X rappresenta il punteggio semantico query-articolo; l'asse Y è il numero di impressioni esportato da GSC.



Diversi predittori sui click. Ogni punto rappresenta una query, l'asse X rappresenta il punteggio semantico query-articolo; l'asse Y è il numero di click esportato da GSC.
- In generale, tutti i grafici a dispersione dei click sono più sparsi rispetto ai loro grafici delle impressioni, anche se entrambi si basano sugli stessi dati. Questo perché, come menzionato prima, molte impressioni non garantiscono necessariamente dei click.
- I grafici della frequenza dei termini sono più sparsi rispetto agli altri. Questo perché la maggior parte delle query di ricerca reali da Google non appare esattamente nell'articolo, quindi il loro valore X è zero. Tuttavia, hanno comunque impressioni e click. Ecco perché si può vedere che il punto di partenza della linea di tendenza della frequenza dei termini non parte da Y-zero. Si potrebbe pensare che quando certe query appaiono più volte nell'articolo, le impressioni e i click probabilmente aumenteranno. La linea di tendenza lo conferma, ma anche la varianza della linea di tendenza cresce, suggerendo una mancanza di dati di supporto. In generale, la frequenza dei termini non è un buon predittore.
- Confrontando il predittore della frequenza dei termini con i grafici a dispersione del modello di embedding e del modello reranker, questi ultimi appaiono molto migliori: i punti dati sono meglio distribuiti e la varianza della linea di tendenza sembra ragionevole. Tuttavia, se li confronti con la linea di tendenza di riferimento mostrata sopra, noterai una differenza significativa - nessuna delle due linee di tendenza parte da X-zero. Questo significa che anche se ottieni una similarità semantica molto alta dal modello, è molto probabile che Google ti assegni zero impressioni/click. Questo diventa più evidente nel grafico a dispersione dei click, dove il punto di partenza è spinto ancora più a destra rispetto alla sua controparte delle impressioni. In breve, Google non sta usando il nostro modello di embedding e il modello reranker—grande sorpresa!
- Infine, se dovessi scegliere il miglior predittore tra questi tre, lo darei al modello reranker. Per due ragioni:
- La linea di tendenza del modello reranker sia per le impressioni che per i click è meglio distribuita sull'asse X rispetto alla linea di tendenza del modello di embedding, dandogli più "range dinamico", che lo rende più vicino alla linea di tendenza di riferimento.
- Il punteggio è ben distribuito tra 0 e 1. Nota che questo è principalmente perché il nostro ultimo modello Reranker v2 è calibrato, mentre il nostro precedente jina-embeddings-v2-base-en rilasciato a ottobre 2023 non lo era, quindi puoi vedere i suoi valori distribuiti tra 0,60 e 0,90. Detto questo, questa seconda ragione non ha nulla a che fare con la sua approssimazione a ; è solo che un punteggio semantico ben calibrato tra 0 e 1 è più intuitivo da capire e confrontare.
tagConsiderazioni Finali
Quindi, qual è la lezione per la SEO qui? Come influisce questo sulla tua strategia SEO? Onestamente, non molto.
I grafici elaborati sopra suggeriscono un principio SEO di base che probabilmente già conosci: scrivi contenuti che gli utenti stanno cercando e assicurati che siano correlati alle query popolari. Se hai un buon predittore come Reranker V2, forse puoi usarlo come una sorta di "copilota SEO" per guidare la tua scrittura.
O forse no. Forse scrivi semplicemente per il gusto della conoscenza, scrivi per migliorare te stesso, non per compiacere Google o chiunque altro. Perché se pensi senza scrivere, pensi solo di pensare.
