




Ad aprile 2024, abbiamo rilasciato Jina Reader, una semplice API che converte qualsiasi URL in markdown compatibile con LLM con un semplice prefisso: r.jina.ai. Nonostante la sofisticata programmazione di rete dietro le quinte, la parte centrale di "lettura" è piuttosto semplice. Prima, utilizziamo un browser Chrome headless per recuperare il codice sorgente della pagina web. Poi, sfruttiamo il pacchetto Readability di Mozilla per estrarre il contenuto principale, rimuovendo elementi come intestazioni, piè di pagina, barre di navigazione e barre laterali. Infine, convertiamo l'HTML ripulito in markdown utilizzando regex e la libreria Turndown. Il risultato è un file markdown ben strutturato, pronto per essere utilizzato dagli LLM per il grounding, il riassunto e il ragionamento.
Nelle prime settimane dopo il rilascio di Jina Reader, abbiamo ricevuto molti feedback, in particolare sulla qualità del contenuto. Alcuni utenti lo hanno trovato troppo dettagliato, mentre altri lo ritenevano non abbastanza dettagliato. Ci sono state anche segnalazioni che il filtro Readability rimuoveva il contenuto sbagliato o che Turndown aveva difficoltà a convertire alcune parti dell'HTML in markdown. Fortunatamente, molti di questi problemi sono stati risolti con successo correggendo la pipeline esistente con nuovi pattern regex o euristiche.
Da allora, ci siamo posti una domanda: invece di correggerlo con più euristiche e regex (che diventa sempre più difficile da mantenere e non è multilingue-friendly), possiamo risolvere questo problema end-to-end con un modello linguistico?
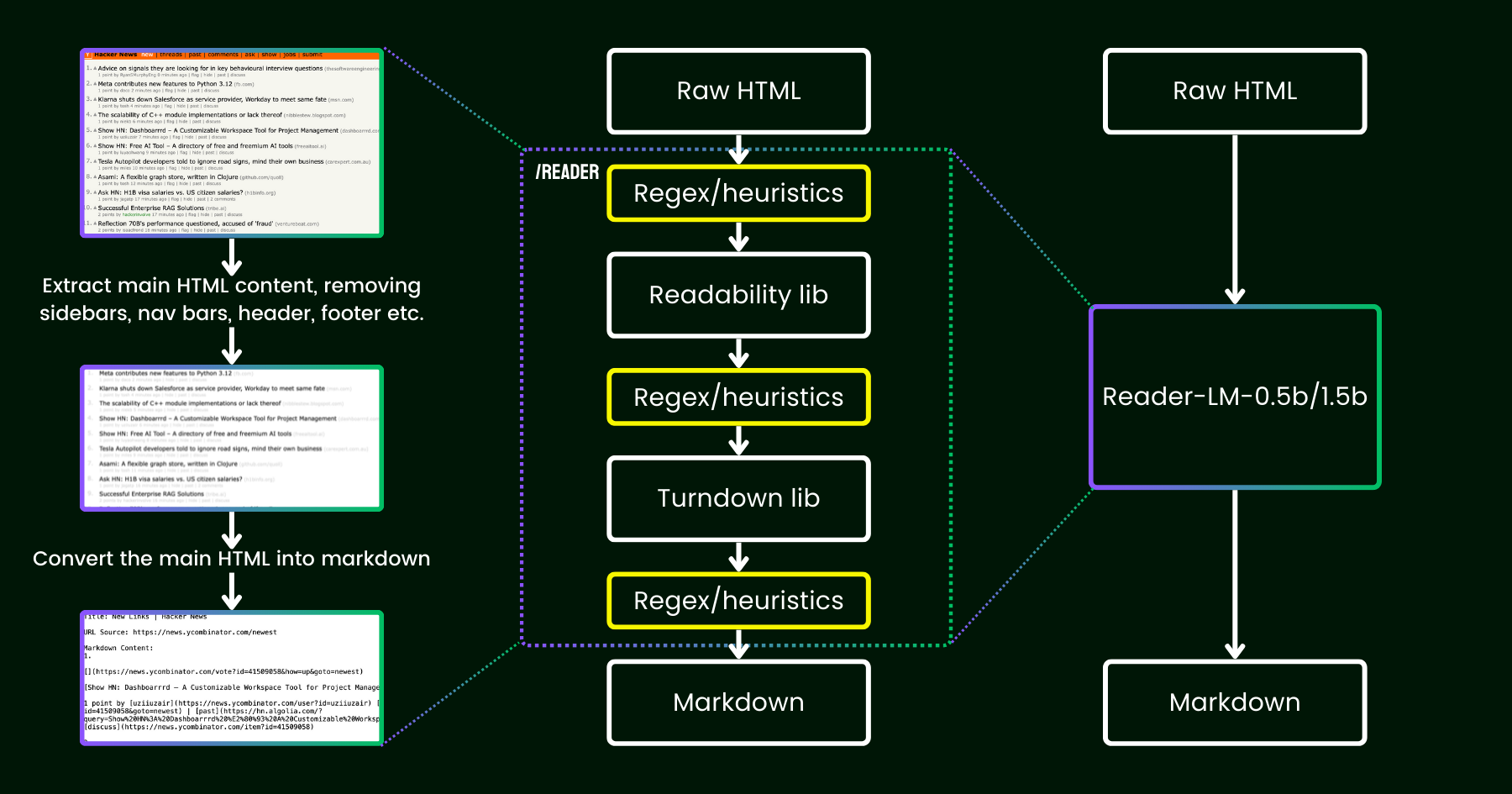
reader-lm, che sostituisce la pipeline di readability+turndown+regex euristiche utilizzando un piccolo modello linguistico.A prima vista, utilizzare LLM per la pulizia dei dati potrebbe sembrare eccessivo a causa della loro bassa efficienza in termini di costi e della velocità più lenta. Ma se considerassimo un small language model (SLM) — uno con meno di 1 miliardo di parametri che può funzionare efficacemente sull'edge? Suona molto più interessante, vero? Ma è veramente fattibile o solo un pensiero ottimistico? Secondo la legge di scaling, meno parametri generalmente portano a capacità ridotte di ragionamento e sintesi. Quindi un SLM potrebbe persino faticare a generare contenuti significativi se la sua dimensione parametrica è troppo piccola. Per esplorare ulteriormente questo aspetto, diamo uno sguardo più da vicino al task di conversione HTML-to-Markdown:
- Prima di tutto, il task che stiamo considerando non è creativo o complesso come i tipici task LLM. Nel caso della conversione da HTML a markdown, il modello deve principalmente copiare selettivamente dall'input all'output (cioè, saltare il markup HTML, le barre laterali, le intestazioni, i piè di pagina), con uno sforzo minimo speso per generare nuovo contenuto (principalmente inserendo la sintassi markdown). Questo contrasta nettamente con i task più ampi gestiti dagli LLM, come generare poesie o scrivere codice, dove l'output richiede molta più creatività e non è un semplice copia-incolla dall'input. Questa osservazione suggerisce che un SLM potrebbe funzionare, poiché il task sembra più semplice rispetto alla generazione di testo più generale.
- In secondo luogo, dobbiamo dare priorità al supporto per contesti lunghi. L'HTML moderno spesso contiene molto più rumore del semplice markup
<div>. CSS inline e script possono facilmente far lievitare il codice a centinaia di migliaia di token. Perché un SLM sia pratico in questo scenario, la lunghezza del contesto deve essere sufficientemente grande. Lunghezze di token come 8K o 16K non sono per nulla utili.
Sembra che ciò di cui abbiamo bisogno sia un SLM shallow-but-wide. "Shallow" nel senso che il task è principalmente un semplice "copia-incolla", quindi sono necessari meno blocchi transformer; e "wide" nel senso che richiede supporto per contesti lunghi per essere pratico, quindi il meccanismo di attenzione necessita di particolare cura. Ricerche precedenti hanno dimostrato che la lunghezza del contesto e la capacità di ragionamento sono strettamente interconnesse. Per un SLM, è estremamente impegnativo ottimizzare entrambe le dimensioni mantenendo piccola la dimensione dei parametri.
Oggi, siamo entusiasti di annunciare la prima versione di questa soluzione con il rilascio di reader-lm-0.5b e reader-lm-1.5b, due SLM specificamente addestrati per generare markdown pulito direttamente da HTML grezzo rumoroso. Entrambi i modelli sono multilingue e supportano una lunghezza di contesto fino a 256K token. Nonostante le loro dimensioni compatte, questi modelli raggiungono prestazioni allo stato dell'arte su questo task, superando controparti LLM più grandi pur essendo solo 1/50 delle loro dimensioni.

Di seguito sono riportate le specifiche dei due modelli:
| reader-lm-0.5b | reader-lm-1.5b | |
|---|---|---|
| # Parametri | 494M | 1.54B |
| Lunghezza contesto | 256K | 256K |
| Hidden Size | 896 | 1536 |
| # Layers | 24 | 28 |
| # Query Heads | 14 | 12 |
| # KV Heads | 2 | 2 |
| Head Size | 64 | 128 |
| Intermediate Size | 4864 | 8960 |
| Multilingue | Sì | Sì |
| Repository HuggingFace | Link | Link |
tagIniziare con Reader-LM
tagSu Google Colab
Il modo più semplice per sperimentare reader-lm è eseguire il nostro notebook Colab, dove dimostriamo come utilizzare reader-lm-1.5b per convertire il sito web di Hacker News in markdown. Il notebook è ottimizzato per funzionare senza problemi sul tier GPU T4 gratuito di Google Colab. Puoi anche caricare reader-lm-0.5b o cambiare l'URL in qualsiasi sito web ed esplorare l'output. Nota che l'input (cioè il prompt) al modello è l'HTML grezzo—non è richiesta alcuna istruzione di prefisso.

Si prega di notare che la GPU T4 del tier gratuito presenta limitazioni che potrebbero impedire l'uso di ottimizzazioni avanzate durante l'esecuzione del modello. Funzionalità come bfloat16 e flash attention non sono disponibili sulla T4, il che potrebbe comportare un maggior utilizzo di VRAM e prestazioni più lente per input più lunghi. Per ambienti di produzione, raccomandiamo l'utilizzo di una GPU di fascia alta come la RTX 3090/4090 per prestazioni significativamente migliori.
tagIn Produzione: Presto disponibile su Azure e AWS
Reader-LM è disponibile su Azure Marketplace e AWS SageMaker. Se hai bisogno di utilizzare questi modelli al di fuori di queste piattaforme o on-premises all'interno della tua azienda, nota che entrambi i modelli sono concessi in licenza sotto CC BY-NC 4.0. Per richieste di utilizzo commerciale, non esitare a contattarci.


tagBenchmark
Per valutare quantitativamente le prestazioni di Reader-LM, lo abbiamo confrontato con diversi modelli linguistici di grandi dimensioni, tra cui: GPT-4o, Gemini-1.5-Flash, Gemini-1.5-Pro, LLaMA-3.1-70B, Qwen2-7B-Instruct.
I modelli sono stati valutati utilizzando le seguenti metriche:
- ROUGE-L (più alto è meglio): Questa metrica, ampiamente utilizzata per compiti di riassunto e domanda-risposta, misura la sovrapposizione tra l'output previsto e il riferimento a livello di n-gram.
- Token Error Rate (TER, più basso è meglio): Questa metrica calcola il tasso con cui i token markdown generati non appaiono nel contenuto HTML originale. Abbiamo progettato questa metrica per valutare il tasso di allucinazione del modello, aiutandoci a identificare i casi in cui il modello produce contenuti non basati sull'HTML. Ulteriori miglioramenti saranno apportati in base agli studi dei casi.
- Word Error Rate (WER, più basso è meglio): Comunemente utilizzato nei compiti di OCR e ASR, WER considera la sequenza di parole e calcola errori come inserimenti (ADD), sostituzioni (SUB) ed eliminazioni (DEL). Questa metrica fornisce una valutazione dettagliata delle discrepanze tra il markdown generato e l'output previsto.
Per sfruttare i LLM per questo compito, abbiamo utilizzato la seguente istruzione uniforme come prompt di prefisso:
Your task is to convert the content of the provided HTML file into the corresponding markdown file. You need to convert the structure, elements, and attributes of the HTML into equivalent representations in markdown format, ensuring that no important information is lost. The output should strictly be in markdown format, without any additional explanations.I risultati sono disponibili nella tabella sottostante.
| ROUGE-L | WER | TER | |
|---|---|---|---|
| reader-lm-0.5b | 0.56 | 3.28 | 0.34 |
| reader-lm-1.5b | 0.72 | 1.87 | 0.19 |
| gpt-4o | 0.43 | 5.88 | 0.50 |
| gemini-1.5-flash | 0.40 | 21.70 | 0.55 |
| gemini-1.5-pro | 0.42 | 3.16 | 0.48 |
| llama-3.1-70b | 0.40 | 9.87 | 0.50 |
| Qwen2-7B-Instruct | 0.23 | 2.45 | 0.70 |
tagStudio Qualitativo
Abbiamo condotto uno studio qualitativo esaminando visivamente l'output markdown. Abbiamo selezionato 22 fonti HTML tra cui articoli di news, post di blog, landing page, pagine di e-commerce e post di forum in diverse lingue: inglese, tedesco, giapponese e cinese. Abbiamo incluso anche la Jina Reader API come baseline, che si basa su regex, euristiche e regole predefinite.
La valutazione si è concentrata su quattro dimensioni chiave dell'output, con ogni modello valutato su una scala da 1 (più basso) a 5 (più alto):
- Estrazione Header: Valutato quanto bene ogni modello ha identificato e formattato gli header h1,h2,..., h6 del documento usando la corretta sintassi markdown.
- Estrazione Contenuto Principale: Valutato la capacità dei modelli di convertire accuratamente il testo del corpo, preservando paragrafi, formattando liste e mantenendo la consistenza nella presentazione.
- Preservazione Struttura Complessa: Analizzato quanto efficacemente ogni modello ha mantenuto la struttura complessiva del documento, inclusi titoli, sottotitoli, punti elenco e liste ordinate.
- Utilizzo Sintassi Markdown: Valutato la capacità di ogni modello di convertire correttamente gli elementi HTML come
<a>(link),<strong>(testo in grassetto) e<em>(corsivo) nei loro equivalenti markdown appropriati.
I risultati sono disponibili di seguito.

Reader-LM-1.5B si comporta costantemente bene in tutte le dimensioni, eccellendo particolarmente nella preservazione della struttura e nell'utilizzo della sintassi markdown. Anche se non sempre supera Jina Reader API, le sue prestazioni sono competitive con modelli più grandi come Gemini 1.5 Pro, rendendolo un'alternativa altamente efficiente ai LLM più grandi. Reader-LM-0.5B, sebbene più piccolo, offre comunque prestazioni solide, in particolare nella preservazione della struttura.
tagCome Abbiamo Addestrato Reader-LM
tagPreparazione dei Dati
Abbiamo utilizzato la Jina Reader API per generare coppie di addestramento di HTML grezzo e il loro corrispondente markdown. Durante l'esperimento, abbiamo scoperto che gli SLM sono particolarmente sensibili alla qualità dei dati di addestramento. Quindi abbiamo costruito una pipeline di dati che assicura che solo voci markdown di alta qualità siano incluse nel set di addestramento.
Inoltre, abbiamo aggiunto alcuni HTML sintetici e i loro corrispondenti markdown, generati da GPT-4o. Rispetto all'HTML del mondo reale, i dati sintetici tendono ad essere molto più brevi, con strutture più semplici e prevedibili, e un livello di rumore significativamente inferiore.
Infine, abbiamo concatenato l'HTML e il markdown utilizzando un template di chat. I dati di addestramento finali sono formattati come segue:
<|im_start|>system
You are a helpful assistant.<|im_end|>
<|im_start|>user
{{RAW_HTML}}<|im_end|>
<|im_start|>assistant
{{MARKDOWN}}<|im_end|>
I dati di addestramento completi ammontano a 2,5 miliardi di token.
tagAddestramento in Due Fasi
Abbiamo sperimentato con diverse dimensioni di modello, partendo da 65M e 135M fino a 3B parametri. Le specifiche per ogni modello sono riportate nella tabella qui sotto.
| reader-lm-65m | reader-lm-135m | reader-lm-360m | reader-lm-0.5b | reader-lm-1.5b | reader-lm-1.7b | reader-lm-3b | |
|---|---|---|---|---|---|---|---|
| Hidden Size | 512 | 576 | 960 | 896 | 1536 | 2048 | 3072 |
| # Layers | 8 | 30 | 32 | 24 | 28 | 24 | 32 |
| # Query Heads | 16 | 9 | 15 | 14 | 12 | 32 | 32 |
| # KV Heads | 8 | 3 | 5 | 2 | 2 | 32 | 32 |
| Head Size | 32 | 64 | 64 | 64 | 128 | 64 | 96 |
| Intermediate Size | 2048 | 1536 | 2560 | 4864 | 8960 | 8192 | 8192 |
| Attention Bias | False | False | False | True | True | False | False |
| Embedding Tying | False | True | True | True | True | True | False |
| Vocabulary Size | 32768 | 49152 | 49152 | 151646 | 151646 | 49152 | 32064 |
| Base Model | Lite-Oute-1-65M-Instruct | SmolLM-135M | SmolLM-360M-Instruct | Qwen2-0.5B-Instruct | Qwen2-1.5B-Instruct | SmolLM-1.7B | Phi-3-mini-128k-instruct |
L'addestramento del modello è stato condotto in due fasi:
- HTML breve e semplice: In questa fase, la lunghezza massima della sequenza (HTML + markdown) è stata impostata a 32K token, con un totale di 1,5 miliardi di token di addestramento.
- HTML lungo e complesso: la lunghezza della sequenza è stata estesa a 128K token, con 1,2 miliardi di token di addestramento. Abbiamo implementato il meccanismo zigzag-ring-attention da Ring Flash Attention di Zilin Zhu (2024) per questa fase.
Poiché i dati di addestramento includevano sequenze fino a 128K token, riteniamo che il modello possa supportare fino a 256K token senza problemi. Tuttavia, gestire 512K token potrebbe essere problematico, poiché estendere gli embedding posizionali RoPE a quattro volte la lunghezza della sequenza di addestramento potrebbe comportare un degrado delle prestazioni.
Per i modelli da 65M e 135M parametri, abbiamo osservato che potevano ottenere un comportamento di "copia" ragionevole, ma solo con sequenze brevi (meno di 1K token). All'aumentare della lunghezza dell'input, questi modelli faticavano a produrre output ragionevoli. Considerando che il codice HTML moderno può facilmente superare i 100K token, un limite di 1K token è ben lontano dall'essere sufficiente.
tagDegenerazione e Loop Monotoni
Una delle sfide principali che abbiamo incontrato è stata la degenerazione, in particolare sotto forma di ripetizione e loop. Dopo aver generato alcuni token, il modello iniziava a generare ripetutamente lo stesso token o rimaneva bloccato in un loop, ripetendo continuamente una breve sequenza di token fino a raggiungere la lunghezza massima consentita dell'output.

Per affrontare questo problema:
- Abbiamo applicato la ricerca contrastiva come metodo di decodifica e incorporato la loss contrastiva durante l'addestramento. Dai nostri esperimenti, questo metodo ha ridotto efficacemente la generazione ripetitiva nella pratica.
- Abbiamo implementato un semplice criterio di interruzione della ripetizione all'interno della pipeline del transformer. Questo criterio rileva automaticamente quando il modello inizia a ripetere i token e interrompe la decodifica in anticipo per evitare loop monotoni. Questa idea è stata ispirata da questa discussione.
tagEfficienza di Addestramento su Input Lunghi
Per mitigare il rischio di errori di memoria insufficiente (OOM) durante la gestione di input lunghi, abbiamo implementato l'inoltro del modello a blocchi. Questo approccio codifica l'input lungo con blocchi più piccoli, riducendo l'utilizzo della VRAM.
Abbiamo migliorato l'implementazione del data packing nel nostro framework di addestramento, basato su Transformers Trainer. Per ottimizzare l'efficienza dell'addestramento, più testi brevi (ad esempio 2K token) vengono concatenati in un'unica sequenza lunga (ad esempio 30K token), consentendo un addestramento senza padding. Tuttavia, nell'implementazione originale, alcuni esempi brevi venivano divisi in due sotto-testi e inclusi in diverse sequenze di addestramento lunghe. In questi casi, il secondo sotto-testo avrebbe perso il suo contesto (ad esempio il contenuto HTML grezzo nel nostro caso), portando a dati di addestramento corrotti. Questo costringe il modello a fare affidamento sui suoi parametri piuttosto che sul contesto di input, che riteniamo sia una fonte principale di allucinazione.
Alla fine, abbiamo selezionato i modelli da 0,5B e 1,5B per la pubblicazione. Il modello da 0,5B è il più piccolo in grado di ottenere il comportamento desiderato di "copia selettiva" su input con contesto lungo, mentre il modello da 1,5B è il più piccolo modello più grande che migliora significativamente le prestazioni senza raggiungere rendimenti decrescenti in relazione alla dimensione dei parametri.
tagArchitettura Alternativa: Modello Solo Encoder
Nei primi giorni di questo progetto, abbiamo anche esplorato l'utilizzo di un'architettura solo encoder per affrontare questo compito. Come menzionato in precedenza, il compito di conversione da HTML a Markdown sembra essere principalmente un compito di "copia selettiva". Data una coppia di addestramento (HTML grezzo e markdown), possiamo etichettare i token che esistono sia nell'input che nell'output come 1, e il resto come 0. Questo converte il problema in un compito di classificazione dei token, simile a quello utilizzato nel Named Entity Recognition (NER).
Sebbene questo approccio sembrasse logico, ha presentato sfide significative nella pratica. Prima di tutto, l'HTML grezzo da fonti del mondo reale è estremamente rumoroso e lungo, rendendo le etichette 1 estremamente sparse e quindi difficili da apprendere per il modello. In secondo luogo, la codifica della sintassi markdown speciale in uno schema 0-1 si è rivelata problematica, poiché simboli come ## title, *bold*, e | table | non esistono nell'input HTML grezzo. In terzo luogo, i token di output non seguono sempre rigorosamente l'ordine dell'input. Si verificano spesso riordinamenti minori, in particolare con tabelle e link, rendendo difficile rappresentare tali comportamenti di riordinamento in un semplice schema 0-1. Il riordinamento a breve distanza potrebbe potenzialmente essere gestito con programmazione dinamica o algoritmi di allineamento-warping introducendo etichette come -1, -2, +1, +2 per rappresentare gli offset di distanza, trasformando il problema di classificazione binaria in un compito di classificazione token multi-classe.
In sintesi, risolvere il problema con un'architettura solo encoder e trattarlo come un compito di classificazione dei token ha il suo fascino, soprattutto perché le sequenze di addestramento sono molto più brevi rispetto a un modello solo decoder, rendendolo più efficiente in termini di VRAM. Tuttavia, la sfida principale risiede nella preparazione di buoni dati di addestramento. Quando ci siamo resi conto che il tempo e lo sforzo spesi nel preprocessare i dati—utilizzando programmazione dinamica ed euristiche per creare sequenze di etichettatura perfette a livello di token—era eccessivo, abbiamo deciso di interrompere questo approccio.
tagConclusione
Reader-LM è un innovativo small language model (SLM) progettato per l'estrazione e la pulizia dei dati dal web aperto. Ispirato da Jina Reader, il nostro obiettivo era creare una soluzione end-to-end basata su language model in grado di convertire HTML grezzo e rumoroso in markdown pulito. Al contempo, ci siamo concentrati sull'efficienza dei costi, mantenendo ridotte le dimensioni del modello per garantire che Reader-LM rimanga pratico e utilizzabile. È anche il primo modello decoder-only a lungo contesto addestrato presso Jina AI.
Anche se inizialmente il compito può sembrare un semplice problema di "copia selettiva", convertire e pulire l'HTML in markdown è tutt'altro che semplice. Nello specifico, richiede che il modello eccella nel ragionamento basato sul contesto e consapevole della posizione, che richiede una dimensione maggiore dei parametri, in particolare negli hidden layer. In confronto, l'apprendimento della sintassi markdown è relativamente semplice.
Durante i nostri esperimenti, abbiamo anche scoperto che addestrare un SLM da zero è particolarmente impegnativo. Iniziare con un modello pre-addestrato e proseguire con l'addestramento specifico per il compito ha migliorato significativamente l'efficienza dell'addestramento. C'è ancora molto spazio per miglioramenti sia in termini di efficienza che di qualità: espandere la lunghezza del contesto, velocizzare il decoding e aggiungere il supporto per le istruzioni nell'input, che permetterebbe a Reader-LM di estrarre parti specifiche di una pagina web in markdown.
