


Dopo l'integrazione di Jina Embeddings in Deepset's Haystack 2.0 e il rilascio di Jina Reranker, siamo entusiasti di annunciare che Jina Reranker è ora disponibile anche attraverso l'estensione Jina Haystack.


Haystack è un framework end-to-end che ti accompagna in ogni fase del ciclo di vita del progetto GenAI. Che tu voglia eseguire ricerche di documenti, retrieval-augmented generation (RAG), rispondere a domande o generare risposte, Haystack può orchestrare modelli di embedding e LLM all'avanguardia in pipeline per costruire applicazioni NLP end-to-end e risolvere i tuoi casi d'uso.
In questo post, mostreremo come usarli per creare il tuo motore di ricerca per ticket Jira per ottimizzare le tue operazioni e non perdere mai più tempo creando segnalazioni duplicate.
Per seguire questo tutorial, avrai bisogno di una chiave API Jina Reranker. Puoi crearne una con una quota di prova gratuita di un milione di token dal sito web di Jina Reranker.
tagRecupero dei Ticket di Supporto Jira
Qualsiasi team che si occupa di un progetto complesso ha sperimentato la frustrazione di avere un problema da segnalare senza sapere se esiste già un ticket per questo problema.
Nel seguente tutorial, ti mostreremo come puoi facilmente creare uno strumento utilizzando Jina Reranker e le pipeline Haystack, che suggerisce possibili ticket duplicati quando ne viene creato uno nuovo.
- Inserendo un ticket da verificare rispetto a tutti i ticket esistenti, la pipeline recupererà prima dal database tutte le segnalazioni correlate.
- Rimuoverà quindi il ticket iniziale dall'elenco (se già esisteva nel database) e qualsiasi ticket figlio (cioè i ticket il cui ID padre corrisponde al ticket originale).
- La selezione finale ora comprende solo le segnalazioni che potrebbero coprire lo stesso argomento del ticket originale ma non sono state contrassegnate come tali nel database attraverso i loro ID. Questi ticket vengono riordinati per garantire la massima rilevanza e permetterti di identificare le voci duplicate nel database.
tagOttenere il Dataset
Per implementare la nostra soluzione, abbiamo scelto tutti i ticket Jira "In Progress" per il progetto Apache Zookeeper. Questo è un servizio open-source per coordinare i processi di applicazioni distribuite.
Abbiamo inserito i ticket in un file JSON per renderli più convenienti. Per favore scarica il file nel tuo spazio di lavoro.
tagConfigurare i Prerequisiti
Per installare i requisiti, esegui:
pip install --q chromadb haystack-ai jina-haystack chroma-haystackPer inserire la chiave API, impostala come variabile d'ambiente:
import os
import getpass
os.environ["JINA_API_KEY"] = getpass.getpass()getpass.getpass() ti chiederà di inserire la chiave API sotto il blocco di codice corrispondente. Puoi inserire la chiave lì e premere invio per riprendere il tutorial. Se preferisci, puoi anche sostituire getpass.getpass() con la chiave API stessa.tagCostruire la Pipeline di Indicizzazione
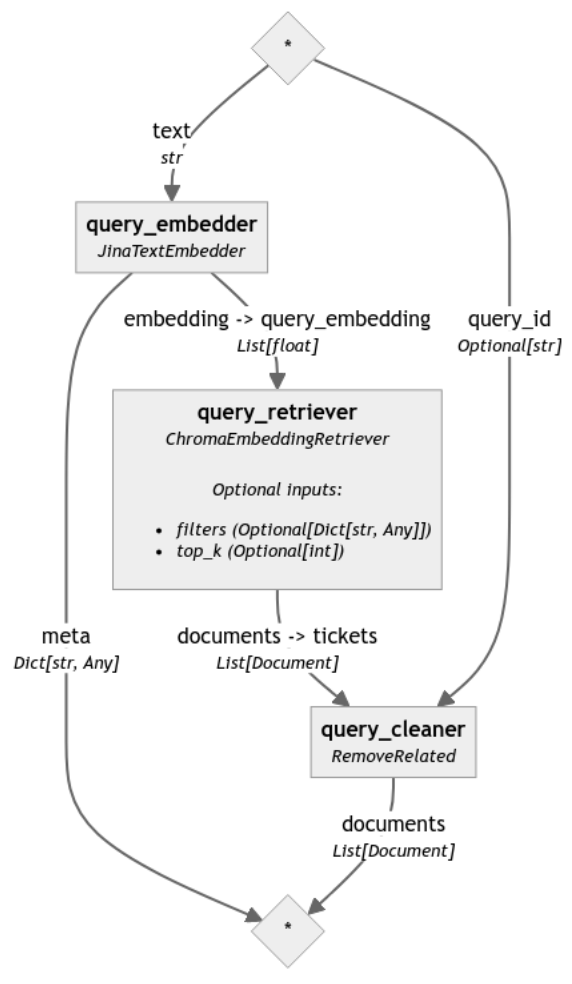
La pipeline di indicizzazione preprocesserà i ticket, li trasformerà in vettori e li memorizzerà. Useremo il Chroma DocumentStore come nostro database vettoriale per memorizzare gli embedding vettoriali, attraverso l'integrazione Chroma Document Store Haystack.
from haystack_integrations.document_stores.chroma import ChromaDocumentStore
document_store = ChromaDocumentStore()Inizieremo definendo il nostro preprocessore di dati personalizzato per considerare solo i campi documento rilevanti e eliminare tutte le voci vuote:
import json
from typing import List
from haystack import Document, component
relevant_keys = ['Summary', 'Issue key', 'Issue id', 'Parent id', 'Issue type', 'Status', 'Project lead', 'Priority', 'Assignee', 'Reporter', 'Creator', 'Created', 'Updated', 'Last Viewed', 'Due Date', 'Labels',
'Description', 'Comment', 'Comment__1', 'Comment__2', 'Comment__3', 'Comment__4', 'Comment__5', 'Comment__6', 'Comment__7', 'Comment__8', 'Comment__9', 'Comment__10', 'Comment__11', 'Comment__12',
'Comment__13', 'Comment__14', 'Comment__15']
@component
class RemoveKeys:
@component.output_types(documents=List[Document])
def run(self, file_name: str):
with open(file_name, 'r') as file:
tickets = json.load(file)
cleaned_tickets = []
for t in tickets:
t = {k: v for k, v in t.items() if k in relevant_keys and v}
cleaned_tickets.append(t)
return {'documents': cleaned_tickets}Dobbiamo poi creare un convertitore JSON personalizzato per trasformare i ticket in oggetti Document che Haystack può comprendere:
@component
class JsonConverter:
@component.output_types(documents=List[Document])
def run(self, tickets: List[Document]):
tickets_documents = []
for t in tickets:
if 'Parent id' in t:
t = Document(content=json.dumps(t), meta={'Issue key': t['Issue key'], 'Issue id': t['Issue id'], 'Parent id': t['Parent id']})
else:
t = Document(content=json.dumps(t), meta={'Issue key': t['Issue key'], 'Issue id': t['Issue id'], 'Parent id': ''})
tickets_documents.append(t)
return {'documents': tickets_documents}Infine, incorporiamo i Document e scriviamo questi embedding nel ChromaDocumentStore:
from haystack import Pipeline
from haystack.components.writers import DocumentWriter
from haystack_integrations.components.retrievers.chroma import ChromaEmbeddingRetriever
from haystack.document_stores.types import DuplicatePolicy
from haystack_integrations.components.embedders.jina import JinaDocumentEmbedder
retriever = ChromaEmbeddingRetriever(document_store=document_store)
retriever_reranker = ChromaEmbeddingRetriever(document_store=document_store)
indexing_pipeline = Pipeline()
indexing_pipeline.add_component('cleaner', RemoveKeys())
indexing_pipeline.add_component('converter', JsonConverter())
indexing_pipeline.add_component('embedder', JinaDocumentEmbedder(model='jina-embeddings-v2-base-en'))
indexing_pipeline.add_component('writer', DocumentWriter(document_store=document_store, policy=DuplicatePolicy.SKIP))
indexing_pipeline.connect('cleaner', 'converter')
indexing_pipeline.connect('converter', 'embedder')
indexing_pipeline.connect('embedder', 'writer')
indexing_pipeline.run({'cleaner': {'file_name': 'tickets.json'}})Questo dovrebbe creare una barra di progresso e produrre un breve JSON contenente informazioni su ciò che è stato memorizzato:
Calculating embeddings: 100%|██████████| 1/1 [00:01<00:00, 1.21s/it]
{'embedder': {'meta': {'model': 'jina-embeddings-v2-base-en',
'usage': {'total_tokens': 20067, 'prompt_tokens': 20067}}},
'writer': {'documents_written': 31}}tagCostruire la Pipeline di Query
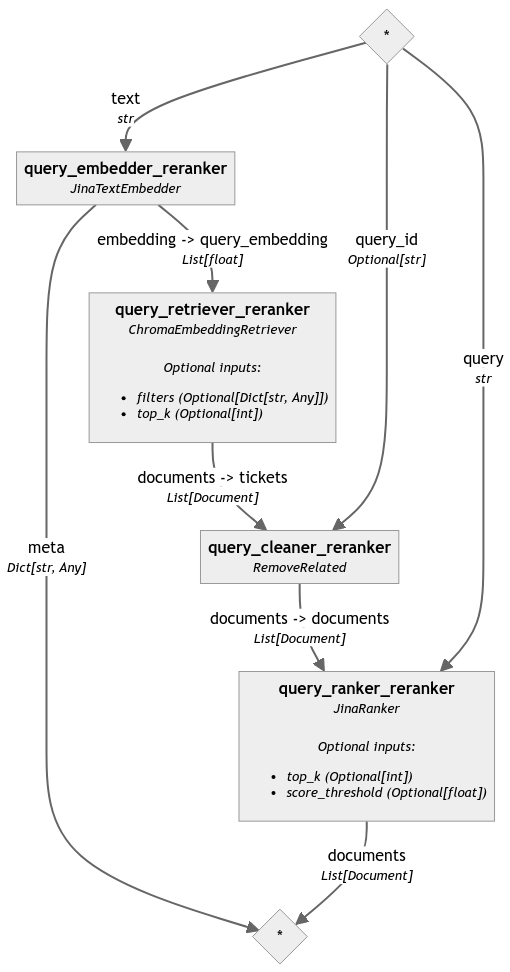
Creiamo una pipeline di query per poter iniziare a confrontare i ticket. In Haystack 2.0 i retriever sono strettamente accoppiati ai DocumentStore. Se passiamo il document store nel retriever che abbiamo inizializzato in precedenza, questa pipeline può accedere ai documenti che abbiamo generato e passarli al reranker. Il reranker confronta quindi questi documenti direttamente con la domanda e li classifica in base alla rilevanza.
Prima definiamo il cleaner personalizzato per rimuovere i ticket recuperati che contengono lo stesso ID del problema o ID genitore del problema passato come query:
from typing import Optional
@component
class RemoveRelated:
@component.output_types(documents=List[Document])
def run(self, tickets: List[Document], query_id: Optional[str]):
retrieved_tickets = []
for t in tickets:
if not t.meta['Issue id'] == query_id and not t.meta['Parent id'] == query_id:
retrieved_tickets.append(t)
return {'documents': retrieved_tickets}
Quindi incorporiamo la query, recuperiamo i documenti rilevanti, puliamo la selezione e infine la riordiniamo:
from haystack_integrations.components.embedders.jina import JinaTextEmbedder
from haystack_integrations.components.rankers.jina import JinaRanker
query_pipeline_reranker = Pipeline()
query_pipeline_reranker.add_component('query_embedder_reranker', JinaTextEmbedder(model='jina-embeddings-v2-base-en'))
query_pipeline_reranker.add_component('query_retriever_reranker', retriever_reranker)
query_pipeline_reranker.add_component('query_cleaner_reranker', RemoveRelated())
query_pipeline_reranker.add_component('query_ranker_reranker', JinaRanker())
query_pipeline_reranker.connect('query_embedder_reranker.embedding', 'query_retriever_reranker.query_embedding')
query_pipeline_reranker.connect('query_retriever_reranker', 'query_cleaner_reranker')
query_pipeline_reranker.connect('query_cleaner_reranker', 'query_ranker_reranker')
Per evidenziare la differenza causata dal reranker, abbiamo analizzato la stessa pipeline senza il passaggio finale di riordinamento (il codice corrispondente è stato omesso in questo post per motivi di leggibilità ma può essere trovato nel notebook):
Per confrontare i risultati di queste due pipeline, definiamo ora la nostra query sotto forma di ticket esistente, in questo caso "ZOOKEEPER-3282":
query_ticket_key = 'ZOOKEEPER-3282'
with open('tickets.json', 'r') as file:
tickets = json.load(file)
for ticket in tickets:
if ticket['Issue key'] == query_ticket_key:
query = str(ticket)
query_ticket_id = ticket['Issue id']
Riguarda "una grande rielaborazione per la documentazione" [sic]. Vedrai che, nonostante l'errore di ortografia, Jina Reranker recupererà correttamente ticket simili.
{
"Summary": "a big refactor for the documetations"
"Issue key": "ZOOKEEPER-3282"
"Issue id:: 13216608
"Parent id": ""
"Issue Type": "Task"
"Status": "In Progress"
"Project lead": "phunt"
"Priority": "Major"
"Assignee": "maoling"
"Reporter": "maoling"
"Creator": "maoling"
"Created": "19/Feb/19 11:50"
"Updated": "04/Aug/19 12:48"
"Last Viewed": "12/Mar/24 11:56"
"Description": "Hi guys: I'am working on doing a big refactor for the documetations.it aims to - 1.make a better reading experiences and help users know more about zookeeper quickly,as good as other projects' doc(e.g redis,hbase). - 2.have less changes to diff with the original docs as far as possible. - 3.solve the problem when we have some new features or improvements,but cannot find a good place to doc it. The new catalog may looks kile this: * is new one added. ** is the one to keep unchanged as far as possible. *** is the one modified. -------------------------------------------------------------- |---Overview |---Welcome ** [1.1] |---Overview ** [1.2] |---Getting Started ** [1.3] |---Release Notes ** [1.4] |---Developer |---API *** [2.1] |---Programmer's Guide ** [2.2] |---Recipes *** [2.3] |---Clients * [2.4] |---Use Cases * [2.5] |---Admin & Ops |---Administrator's Guide ** [3.1] |---Quota Guide ** [3.2] |---JMX ** [3.3] |---Observers Guide ** [3.4] |---Dynamic Reconfiguration ** [3.5] |---Zookeeper CLI * [3.6] |---Shell * [3.7] |---Configuration flags * [3.8] |---Troubleshooting & Tuning * [3.9] |---Contributor Guidelines |---General Guidelines * [4.1] |---ZooKeeper Internals ** [4.2] |---Miscellaneous |---Wiki ** [5.1] |---Mailing Lists ** [5.2] -------------------------------------------------------------- The Roadmap is: 1.(I pick up it : D) 1.1 write API[2.1], which includes the: 1.1.1 original API Docs which is a Auto-generated java doc,just give a link. 1.1.2. Restful-api (the apis under the /zookeeper-contrib-rest/src/main/java/org/apache/zookeeper/server/jersey/resources) 1.2 write Clients[2.4], which includes the: 1.2.1 C client 1.2.2 zk-python, kazoo 1.2.3 Curator etc....... look at an example from: https://redis.io/clients # write Recipes[2.3], which includes the: - integrate "Java Example" and "Barrier and Queue Tutorial"(Since some bugs in the examples and they are obsolete,we may delete something) into it. - suggest users to use the recipes implements of Curator and link to the Curator's recipes doc. # write Zookeeper CLI[3.6], which includes the: - about how to use the zk command line interface [./zkCli.sh] e.g ls /; get ; rmr;create -e -p etc....... - look at an example from redis: https://redis.io/topics/rediscli # write shell[3.7], which includes the: - list all usages of the shells under the zookeeper/bin. (e.g zkTxnLogToolkit.sh,zkCleanup.sh) # write Configuration flags[3.8], which includes the: - list all usages of configurations properties(e.g zookeeper.snapCount): - move the original Advanced Configuration part of zookeeperAdmin.md into it. look at an example from:https://coreos.com/etcd/docs/latest/op-guide/configuration.html # write Troubleshooting & Tuning[3.9], which includes the: - move the original "Gotchas: Common Problems and Troubleshooting" part of Administrator's Guide.md into it. - move the original "FAQ" into into it. - add some new contents (e.g https://www.yumpu.com/en/document/read/29574266/building-an-impenetrable-zookeeper-pdf-github). look at an example from:https://redis.io/topics/problems https://coreos.com/etcd/docs/latest/tuning.html # write General Guidelines[4.1], which includes the: - move the original "Logging" part of ZooKeeper Internals into it as the logger specification. - write specifications about code, git commit messages,github PR etc ... look at an example from: http://hbase.apache.org/book.html#hbase.commit.msg.format # write Use Cases[2.5], which includes the: - just move the context from: https://cwiki.apache.org/confluence/display/ZOOKEEPER/PoweredBy into it. - add some new contents.(e.g Apache Projects:Spark;Companies:twitter,fb) -------------------------------------------------------------- BTW: - Any insights or suggestions are very welcomed.After the dicussions,I will create a series of tickets(An umbrella) - Since these works can be done parallelly, if you are interested in them, please don't hesitate,just assign to yourself, pick it up. (Notice: give me a ping to avoid the duplicated work)."
}
Infine, eseguiamo la pipeline di query. In questo caso, recupera 20 ticket, elimina le voci correlate all'ID, le riordina e produce la selezione finale dei 10 problemi più rilevanti.
Prima del passaggio di riordino, l'output include 17 ticket:
| Rank | Issue ID | Issue Key | Summary |
|---|---|---|---|
| 1 | 13191544 | ZOOKEEPER-3170 | Umbrella for eliminating ZooKeeper flaky tests |
| 2 | 13400622 | ZOOKEEPER-4375 | Quota cannot limit the specify value when multiply clients create/set znodes |
| 3 | 13249579 | ZOOKEEPER-3499 | [admin server way] Add a complete backup mechanism for zookeeper internal |
| 4 | 13295073 | ZOOKEEPER-3775 | Wrong message in IOException |
| 5 | 13268474 | ZOOKEEPER-3617 | ZK digest ACL permissions gets overridden |
| 6 | 13296971 | ZOOKEEPER-3787 | Apply modernizer-maven-plugin to build |
| 7 | 13265507 | ZOOKEEPER-3600 | support the complete linearizable read and multiply read consistency level |
| 8 | 13222060 | ZOOKEEPER-3318 | [CLI way]Add a complete backup mechanism for zookeeper internal |
| 9 | 13262989 | ZOOKEEPER-3587 | Add a documentation about docker |
| 10 | 13262130 | ZOOKEEPER-3578 | Add a new CLI: multi |
| 11 | 13262828 | ZOOKEEPER-3585 | Add a documentation about RequestProcessors |
| 12 | 13262494 | ZOOKEEPER-3583 | Add new apis to get node type and ttl time info |
| 13 | 12998876 | ZOOKEEPER-2519 | zh->state should not be 0 while handle is active |
| 14 | 13536435 | ZOOKEEPER-4696 | Update for Zookeeper latest version |
| 15 | 13297249 | ZOOKEEPER-3789 | fix the build warnings about @see,@link,@return found by IDEA |
| 16 | 12728973 | ZOOKEEPER-1983 | Append to zookeeper.out (not overwrite) to support logrotation |
| 17 | 12478629 | ZOOKEEPER-915 | Errors that happen during sync() processing at the leader do not get propagated back to the client. |
Dopo aver incluso il reranker, eseguiamo ora la pipeline di query:
result = query_pipeline_reranker.run(data={'query_embedder_reranker':{'text': query},
'query_retriever_reranker': {'top_k': 20},
'query_cleaner_reranker': {'query_id': query_ticket_id},
'query_ranker_reranker': {'query': query, 'top_k': 10}
}
)
for idx, res in enumerate(result['query_ranker_reranker']['documents']):
print('Doc {}:'.format(idx + 1), res)
L'output finale è composto dai 10 ticket più rilevanti:
| Rank | Issue ID | Issue Key | Summary |
|---|---|---|---|
| 1 | 13262989 | ZOOKEEPER-3587 | Add a documentation about docker |
| 2 | 13265507 | ZOOKEEPER-3600 | support the complete linearizable read and multiply read consistency level |
| 3 | 13249579 | ZOOKEEPER-3499 | [admin server way] Add a complete backup mechanism for zookeeper internal |
| 4 | 12478629 | ZOOKEEPER-915 | Errors that happen during sync() processing at the leader do not get propagated back to the client. |
| 5 | 13262828 | ZOOKEEPER-3585 | Add a documentation about RequestProcessors |
| 6 | 13297249 | ZOOKEEPER-3789 | fix the build warnings about @see,@link,@return found by IDEA |
| 7 | 12998876 | ZOOKEEPER-2519 | zh->state should not be 0 while handle is active |
| 8 | 13536435 | ZOOKEEPER-4696 | Update for Zookeeper latest version |
| 9 | 12728973 | ZOOKEEPER-1983 | Append to zookeeper.out (not overwrite) to support logrotation |
| 10 | 13222060 | ZOOKEEPER-3318 | [CLI way]Add a complete backup mechanism for zookeeper internal |
tagVantaggi di Jina Embeddings e Reranker
Per riassumere questo tutorial, abbiamo costruito uno strumento di identificazione dei ticket duplicati basato su Jina Embeddings, Jina Reranker e Haystack 2.0. I risultati sopra mostrano chiaramente la necessità sia di Jina Embeddings per recuperare documenti rilevanti attraverso la ricerca vettoriale, sia di Jina Reranker per ottenere infine il contenuto più rilevante.
Se prendiamo, per esempio, i due problemi relativi all'aggiunta di documentazione, cioè "ZOOKEEPER-3585" e "ZOOKEEPER-3587", vediamo che dopo la fase di recupero, sono entrambi correttamente inclusi rispettivamente nelle posizioni 11 e 9. Dopo il riordino dei documenti, si trovano ora entrambi tra i 5 documenti più rilevanti rispettivamente alle posizioni 5 e 1, mostrando un miglioramento significativo.
Integrando entrambi i modelli nelle pipeline di Haystack, l'intero strumento è pronto all'uso. Questa combinazione rende l'estensione Jina Haystack la soluzione perfetta per la tua applicazione.
