


Dal rilascio del modello O1 di OpenAI, uno dei temi più discussi nella comunità AI è stato lo scaling test-time compute. Questo si riferisce all'allocazione di risorse computazionali aggiuntive durante l'inferenza—la fase in cui un modello AI genera output in risposta agli input—piuttosto che durante il pre-addestramento. Un esempio ben noto è il ragionamento multi-step "chain of thought", che permette ai modelli di eseguire deliberazioni interne più estese, come valutare multiple risposte potenziali, pianificazione più approfondita, auto-riflessione prima di arrivare a una risposta finale. Questa strategia migliora la qualità delle risposte, in particolare nei compiti di ragionamento complesso. Il modello QwQ-32B-Preview recentemente rilasciato da Alibaba segue questa tendenza di migliorare il ragionamento AI attraverso l'aumento del test-time compute.
Quando si utilizza il modello O1 di OpenAI, gli utenti possono notare chiaramente che l'inferenza multi-step richiede tempo aggiuntivo mentre il modello costruisce catene di ragionamento per risolvere i problemi.
A Jina AI, ci concentriamo più sugli embedding e i reranker che sui LLM, quindi per noi è naturale considerare lo scaling test-time compute in questo contesto: Come può essere applicato il "chain-of-thought" ai modelli di embedding? Anche se potrebbe non sembrare intuitivo all'inizio, questo articolo esplora una prospettiva innovativa e dimostra come lo scaling test-time compute può essere applicato a jina-clip per classificare immagini fuori distribuzione (OOD)—risolvendo compiti che altrimenti sarebbero impossibili.

tagCaso Studio

Il nostro esperimento si è concentrato sulla classificazione dei Pokemon utilizzando il dataset TheFusion21/PokemonCards, che contiene migliaia di immagini di carte Pokemon. Il compito è la classificazione delle immagini dove l'input è l'artwork ritagliato di una carta Pokemon (con tutti i testi/descrizioni rimossi) e l'output è il nome corretto del Pokemon da un insieme predefinito di nomi. Questo compito presenta una sfida particolarmente interessante per i modelli di embedding CLIP perché:
- I nomi e gli elementi visivi dei Pokemon rappresentano concetti di nicchia, fuori distribuzione per il modello, rendendo difficile la classificazione diretta
- Ogni Pokemon ha caratteristiche visive chiare che possono essere decomposte in elementi base (forme, colori, pose) che CLIP potrebbe comprendere meglio
- L'artwork delle carte fornisce un formato visivo consistente introducendo allo stesso tempo complessità attraverso sfondi, pose e stili artistici variabili
- Il compito richiede l'integrazione simultanea di multiple caratteristiche visive, simile alle catene di ragionamento complesse nei modelli linguistici

Absol G, Aerodactyl, Weedle, Caterpie, Azumarill, Bulbasaur, Venusaur, Absol, Aggron, Beedrill δ, Alakazam, Ampharos, Dratini, Ampharos, Ampharos, Arcanine, Blaine's Moltres, Aerodactyl, Celebi & Venusaur-GX, Caterpie]tagBaseline
L'approccio baseline utilizza un semplice confronto diretto tra le illustrazioni delle carte Pokemon e i nomi. Prima, ritagliamo ogni immagine della carta Pokemon per rimuovere tutte le informazioni testuali (intestazione, piè di pagina, descrizione) per evitare che il modello CLIP faccia ipotesi banali basate sui nomi Pokemon che appaiono in quei testi. Poi codifichiamo sia le immagini ritagliate che i nomi Pokemon usando i modelli jina-clip-v1 e jina-clip-v2 per ottenere i rispettivi embedding. La classificazione viene effettuata calcolando la similarità del coseno tra questi embedding di immagini e testo - ogni immagine viene abbinata al nome che ha il punteggio di similarità più alto. Questo crea una corrispondenza uno a uno diretta tra l'illustrazione della carta e i nomi dei Pokémon, senza alcun contesto o informazione aggiuntiva sugli attributi. Lo pseudo-codice qui sotto riassume il metodo baseline.
# Preprocessing
cropped_images = [crop_artwork(img) for img in pokemon_cards] # Remove text, keep only art
pokemon_names = ["Absol", "Aerodactyl", ...] # Raw Pokemon names
# Get embeddings using jina-clip-v1
image_embeddings = model.encode_image(cropped_images)
text_embeddings = model.encode_text(pokemon_names)
# Classification by cosine similarity
similarities = cosine_similarity(image_embeddings, text_embeddings)
predicted_names = [pokemon_names[argmax(sim)] for sim in similarities]
# Evaluate
accuracy = mean(predicted_names == ground_truth_names)tag"Chain of Thoughts" per la Classificazione
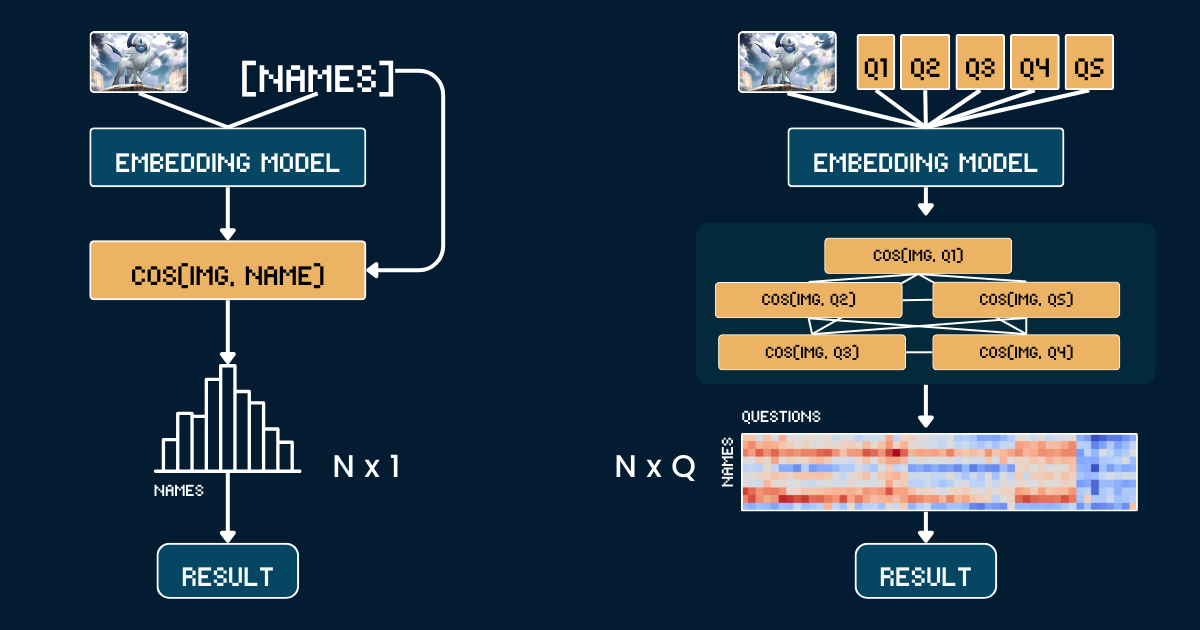
Invece di abbinare direttamente immagini a nomi, decomponiamo il riconoscimento dei Pokemon in un sistema strutturato di attributi visivi. Definiamo cinque gruppi chiave di attributi: colore dominante (es. "bianco", "blu"), forma primaria (es. "un lupo", "un rettile alato"), caratteristica principale (es. "un singolo corno bianco", "grandi ali"), forma del corpo (es. "simile a un lupo su quattro zampe", "alato e snello"), e scena di sfondo (es. "spazio esterno", "foresta verde").
Per ogni gruppo di attributi, creiamo prompt di testo specifici (es. "Questo Pokémon ha il corpo principalmente di colore {}") abbinati a opzioni pertinenti. Quindi usiamo il modello per calcolare i punteggi di similarità tra l'immagine e ciascuna opzione di attributo. Questi punteggi vengono convertiti in probabilità usando softmax per ottenere una misura più calibrata della confidenza.
La struttura completa Chain of Thought (CoT) consiste in due parti: classification_groups che descrive gruppi di prompt, e pokemon_rules che definisce quali opzioni di attributi dovrebbe corrispondere ogni Pokemon. Per esempio, Absol dovrebbe corrispondere a "bianco" per il colore e "simile a un lupo" per la forma. Il CoT completo è mostrato qui sotto (spiegheremo più avanti come viene costruito):
pokemon_system = {
"classification_cot": {
"dominant_color": {
"prompt": "This Pokémon's body is mainly {} in color.",
"options": [
"white", # Absol, Absol G
"gray", # Aggron
"brown", # Aerodactyl, Weedle, Beedrill δ
"blue", # Azumarill
"green", # Bulbasaur, Venusaur, Celebi&Venu, Caterpie
"yellow", # Alakazam, Ampharos
"red", # Blaine's Moltres
"orange", # Arcanine
"light blue"# Dratini
]
},
"primary_form": {
"prompt": "It looks like {}.",
"options": [
"a wolf", # Absol, Absol G
"an armored dinosaur", # Aggron
"a winged reptile", # Aerodactyl
"a rabbit-like creature", # Azumarill
"a toad-like creature", # Bulbasaur, Venusaur, Celebi&Venu
"a caterpillar larva", # Weedle, Caterpie
"a wasp-like insect", # Beedrill δ
"a fox-like humanoid", # Alakazam
"a sheep-like biped", # Ampharos
"a dog-like beast", # Arcanine
"a flaming bird", # Blaine's Moltres
"a serpentine dragon" # Dratini
]
},
"key_trait": {
"prompt": "Its most notable feature is {}.",
"options": [
"a single white horn", # Absol, Absol G
"metal armor plates", # Aggron
"large wings", # Aerodactyl, Beedrill δ
"rabbit ears", # Azumarill
"a green plant bulb", # Bulbasaur, Venusaur, Celebi&Venu
"a small red spike", # Weedle
"big green eyes", # Caterpie
"a mustache and spoons", # Alakazam
"a glowing tail orb", # Ampharos
"a fiery mane", # Arcanine
"flaming wings", # Blaine's Moltres
"a tiny white horn on head" # Dratini
]
},
"body_shape": {
"prompt": "The body shape can be described as {}.",
"options": [
"wolf-like on four legs", # Absol, Absol G
"bulky and armored", # Aggron
"winged and slender", # Aerodactyl, Beedrill δ
"round and plump", # Azumarill
"sturdy and four-legged", # Bulbasaur, Venusaur, Celebi&Venu
"long and worm-like", # Weedle, Caterpie
"upright and humanoid", # Alakazam, Ampharos
"furry and canine", # Arcanine
"bird-like with flames", # Blaine's Moltres
"serpentine" # Dratini
]
},
"background_scene": {
"prompt": "The background looks like {}.",
"options": [
"outer space", # Absol G, Beedrill δ
"green forest", # Azumarill, Bulbasaur, Venusaur, Weedle, Caterpie, Celebi&Venu
"a rocky battlefield", # Absol, Aggron, Aerodactyl
"a purple psychic room", # Alakazam
"a sunny field", # Ampharos
"volcanic ground", # Arcanine
"a red sky with embers", # Blaine's Moltres
"a calm blue lake" # Dratini
]
}
},
"pokemon_rules": {
"Absol": {
"dominant_color": 0,
"primary_form": 0,
"key_trait": 0,
"body_shape": 0,
"background_scene": 2
},
"Absol G": {
"dominant_color": 0,
"primary_form": 0,
"key_trait": 0,
"body_shape": 0,
"background_scene": 0
},
// ...
}
}
La classificazione finale combina queste probabilità di attributi - invece di un singolo confronto di similarità, ora stiamo facendo molteplici confronti strutturati e aggregando le loro probabilità per prendere una decisione più informata.
# Classification process
def classify_pokemon(image):
# Generate all text prompts
all_prompts = []
for group in classification_cot:
for option in group["options"]:
prompt = group["prompt"].format(option)
all_prompts.append(prompt)
# Get embeddings and similarities
image_embedding = model.encode_image(image)
text_embeddings = model.encode_text(all_prompts)
similarities = cosine_similarity(image_embedding, text_embeddings)
# Convert to probabilities per attribute group
probabilities = {}
for group_name, group_sims in group_similarities:
probabilities[group_name] = softmax(group_sims)
# Score each Pokemon based on matching attributes
scores = {}
for pokemon, rules in pokemon_rules.items():
score = 0
for group, target_idx in rules.items():
score += probabilities[group][target_idx]
scores[pokemon] = score
return max(scores, key=scores.get)tagAnalisi della Complessità
Supponiamo di voler classificare un'immagine in uno di N nomi di Pokémon. L'approccio baseline richiede di calcolare N embedding di testo (uno per ogni nome di Pokémon). Al contrario, il nostro approccio di calcolo scalato in fase di test richiede di calcolare Q embedding di testo, dove
Q è il numero totale di combinazioni domanda-opzione per tutte le domande. Entrambi i metodi richiedono il calcolo di un embedding dell'immagine e l'esecuzione di un passaggio finale di classificazione, quindi escludiamo queste operazioni comuni dal nostro confronto. In questo caso di studio, il nostro N=13 e Q=52.In un caso estremo dove Q = N, il nostro approccio si ridurrebbe essenzialmente al baseline. Tuttavia, la chiave per scalare efficacemente il calcolo in fase di test è:
- Costruire domande attentamente scelte che aumentino
Q - Assicurarsi che ogni domanda fornisca indizi distinti e informativi sulla risposta finale
- Progettare domande il più possibile ortogonali per massimizzare il loro guadagno informativo congiunto.
Questo approccio è analogo al gioco "Venti Domande", dove ogni domanda viene scelta strategicamente per restringere efficacemente le possibili risposte.
tagValutazione
La nostra valutazione è stata condotta su 117 immagini di test che coprono 13 diverse classi di Pokémon. E il risultato è il seguente:
| Approach | jina-clip-v1 | jina-clip-v2 |
|---|---|---|
| Baseline | 31.36% | 16.10% |
| CoT | 46.61% | 38.14% |
| Improvement | +15.25% | +22.04% |
Si può notare che la stessa classificazione CoT offre miglioramenti significativi per entrambi i modelli (+15,25% e +22,04% rispettivamente) su questo compito non comune o OOD. Questo suggerisce anche che una volta costruito il pokemon_system, lo stesso sistema CoT può essere efficacemente trasferito tra diversi modelli; e non è richiesto alcun fine-tuning o post-training.
È degna di nota la performance baseline relativamente forte di v1 (31,36%) sulla classificazione dei Pokemon. Questo modello è stato addestrato su LAION-400M, che includeva contenuti relativi ai Pokemon. Al contrario, v2 è stato addestrato su DFN-2B (sottocampionando 400M istanze), un dataset di qualità superiore ma più filtrato che potrebbe aver escluso contenuti relativi ai Pokemon, spiegando la performance baseline inferiore di V2 (16,10%) su questo compito specifico.
tagCostruire pokemon_system Efficacemente
L'efficacia del nostro approccio di calcolo scalato in fase di test dipende fortemente da quanto bene costruiamo il pokemon_system. Ci sono diversi approcci per costruire questo sistema, dal manuale al completamente automatizzato.
Costruzione Manuale
L'approccio più diretto è analizzare manualmente il dataset Pokemon e creare gruppi di attributi, prompt e regole. Un esperto del dominio dovrebbe identificare gli attributi visivi chiave come colore, forma e caratteristiche distintive. Dovrebbe poi scrivere prompt in linguaggio naturale per ogni attributo, enumerare le possibili opzioni per ogni gruppo di attributi e mappare ogni Pokemon alle sue corrette opzioni di attributi. Mentre questo fornisce regole di alta qualità, richiede molto tempo e non scala bene con N più grandi.
Costruzione Assistita da LLM
Possiamo sfruttare gli LLM per accelerare questo processo sollecitandoli a generare il sistema di classificazione. Un prompt ben strutturato richiederebbe gruppi di attributi basati su caratteristiche visive, template di prompt in linguaggio naturale, opzioni complete e mutualmente esclusive e regole di mappatura per ogni Pokemon. L'LLM può generare rapidamente una prima bozza, anche se il suo output potrebbe necessitare di verifica.
I need help creating a structured system for Pokemon classification. For each Pokemon in this list: [Absol, Aerodactyl, Weedle, Caterpie, Azumarill, ...], create a classification system with:
1. Classification groups that cover these visual attributes:
- Dominant color of the Pokemon
- What type of creature it appears to be (primary form)
- Its most distinctive visual feature
- Overall body shape
- What kind of background/environment it's typically shown in
2. For each group:
- Create a natural language prompt template using "{}" for the option
- List all possible options that could apply to these Pokemon
- Make sure options are mutually exclusive and comprehensive
3. Create rules that map each Pokemon to exactly one option per attribute group, using indices to reference the options
Please output this as a Python dictionary with two main components:
- "classification_groups": containing prompts and options for each attribute
- "pokemon_rules": mapping each Pokemon to its correct attribute indices
Example format:
{
"classification_groups": {
"dominant_color": {
"prompt": "This Pokemon's body is mainly {} in color",
"options": ["white", "gray", ...]
},
...
},
"pokemon_rules": {
"Absol": {
"dominant_color": 0, # index for "white"
...
},
...
}
}Un approccio più robusto combina la generazione LLM con la validazione umana. Prima, l'LLM genera un sistema iniziale. Poi, gli esperti umani rivedono e correggono i raggruppamenti degli attributi, la completezza delle opzioni e l'accuratezza delle regole. L'LLM perfeziona il sistema in base a questo feedback, e il processo si ripete fino al raggiungimento di una qualità soddisfacente. Questo approccio bilancia efficienza e accuratezza.
Costruzione Automatizzata con DSPy
Per un approccio completamente automatizzato, possiamo usare DSPy per ottimizzare iterativamente il pokemon_system. Il processo inizia con un semplice pokemon_system scritto manualmente o da LLM come prompt iniziale. Ogni versione viene valutata su un set di validazione, usando l'accuratezza come segnale di feedback per DSPy. Basandosi su questa performance, vengono generati prompt ottimizzati (cioè nuove versioni di pokemon_system). Questo ciclo si ripete fino alla convergenza, e durante l'intero processo, il modello di embedding rimane completamente fisso.
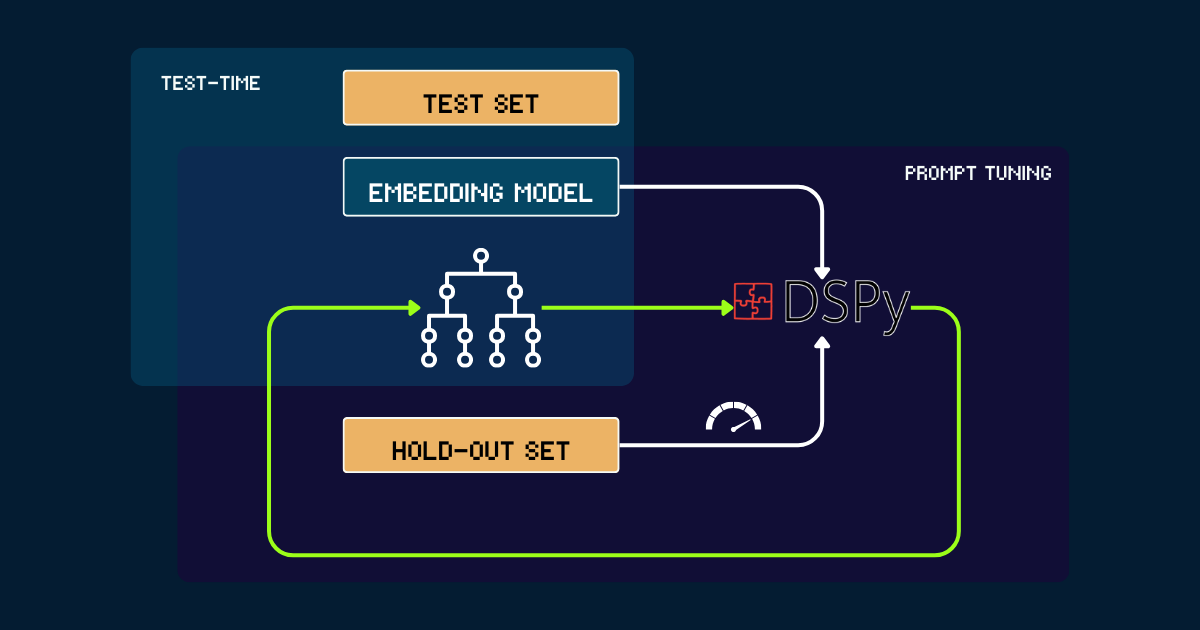
pokemon_system; il processo di tuning deve essere fatto solo una volta per ogni task.tagPerché Scalare il Calcolo in Fase di Test per i Modelli di Embedding?
Perché scalare il pre-training diventa alla fine economicamente intrattabile.
Dalla release della suite di embedding Jina—inclusi jina-embeddings-v1, v2, v3, jina-clip-v1, v2, e jina-ColBERT-v1, v2—ogni aggiornamento del modello attraverso il pre-training scalato è arrivato con costi maggiori. Per esempio, il nostro primo modello, jina-embeddings-v1, rilasciato a giugno 2023 con 110M parametri. Addestrarlo all'epoca costava tra 10.000 a seconda di come si misura. Con jina-embeddings-v3, i miglioramenti sono significativi, ma derivano principalmente dalle maggiori risorse investite. La traiettoria dei costi per i modelli di frontiera è passata da migliaia a decine di migliaia di dollari e, per le aziende AI più grandi, anche centinaia di milioni oggi. Mentre investire più soldi, risorse e dati nel pre-training produce modelli migliori, i rendimenti marginali rendono alla fine insostenibile economicamente un'ulteriore scalabilità.

D'altra parte, i moderni modelli di embedding stanno diventando sempre più potenti: multilingue, multitask, multimodali e capaci di forte performance zero-shot e di seguire istruzioni. Questa versatilità lascia ampio spazio per miglioramenti algoritmici e scaling del calcolo in fase di test.
La domanda diventa quindi: qual è il costo che gli utenti sono disposti a pagare per una query che gli sta particolarmente a cuore? Se tollerare tempi di inferenza più lunghi per modelli pre-addestrati fissi migliora significativamente la qualità dei risultati, molti lo troverebbero utile. Dal nostro punto di vista, c'è un notevole potenziale non sfruttato nello scaling del calcolo in fase di test per i modelli di embedding. Questo rappresenta un cambiamento dal semplice aumento della dimensione del modello durante l'addestramento all'aumento dello sforzo computazionale durante la fase di inferenza per ottenere prestazioni migliori.
tagConclusione
Il nostro caso di studio sul calcolo in fase di test di jina-clip-v1/v2 mostra diversi risultati chiave:
- Abbiamo ottenuto prestazioni migliori su dati non comuni o out-of-distribution (OOD) senza alcun fine-tuning o post-training sugli embedding.
- Il sistema ha fatto distinzioni più sfumate raffinando iterativamente le ricerche di similarità e i criteri di classificazione.
- Incorporando aggiustamenti dinamici dei prompt e ragionamento iterativo, abbiamo trasformato il processo di inferenza del modello di embedding da una singola query in una catena di pensiero più sofisticata.
Questo caso di studio tocca appena la superficie di ciò che è possibile con il calcolo in fase di test. Rimane ampio spazio per lo scaling algoritmico. Per esempio, potremmo sviluppare metodi per selezionare iterativamente le domande che restringono più efficientemente lo spazio delle risposte, similmente alla strategia ottimale nel gioco "Venti Domande". Scalando il calcolo in fase di test, possiamo spingere i modelli di embedding oltre i loro attuali limiti e permettere loro di affrontare compiti più complessi e sfumati che una volta sembravano fuori portata.
