



Nell'ottobre 2023, abbiamo introdotto jina-embeddings-v2, la prima famiglia di modelli di embedding open-source in grado di gestire input fino a 8.192 token. Basandoci su questo, quest'anno abbiamo lanciato jina-embeddings-v3, offrendo lo stesso ampio supporto per gli input con ulteriori miglioramenti.

In questo articolo approfondiremo gli embedding con contesto lungo e risponderemo ad alcune domande: Quando è pratico consolidare un volume così grande di testo in un singolo vettore? La segmentazione migliora il recupero e, in caso affermativo, come? Come possiamo preservare il contesto da diverse parti di un documento mentre segmentiamo il testo?
Per rispondere a queste domande, confronteremo diversi metodi per generare gli embedding:
- Embedding con contesto lungo (codifica fino a 8.192 token in un documento) vs contesto breve (cioè troncamento a 192 token).
- Nessun chunking vs. chunking naive vs. late chunking.
- Diverse dimensioni dei chunk sia con chunking naive che con late chunking.
tagIl Contesto Lungo è Davvero Utile?
Con la capacità di codificare fino a dieci pagine di testo in un singolo embedding, i modelli di embedding con contesto lungo aprono possibilità per la rappresentazione di testi su larga scala. Ma è davvero utile? Secondo molte persone... no.




Fonti: Citazione di Nils Reimer nel podcast How AI Is Built, tweet di brainlag, commento di egorfine su Hacker News, commento di andy99 su Hacker News
Affronteremo tutte queste preoccupazioni con un'indagine dettagliata sulle capacità del contesto lungo, quando il contesto lungo è utile e quando dovresti (e non dovresti) usarlo. Ma prima, ascoltiamo questi scettici e guardiamo alcuni dei problemi che i modelli di embedding con contesto lungo devono affrontare.
tagProblemi con gli Embedding a Contesto Lungo
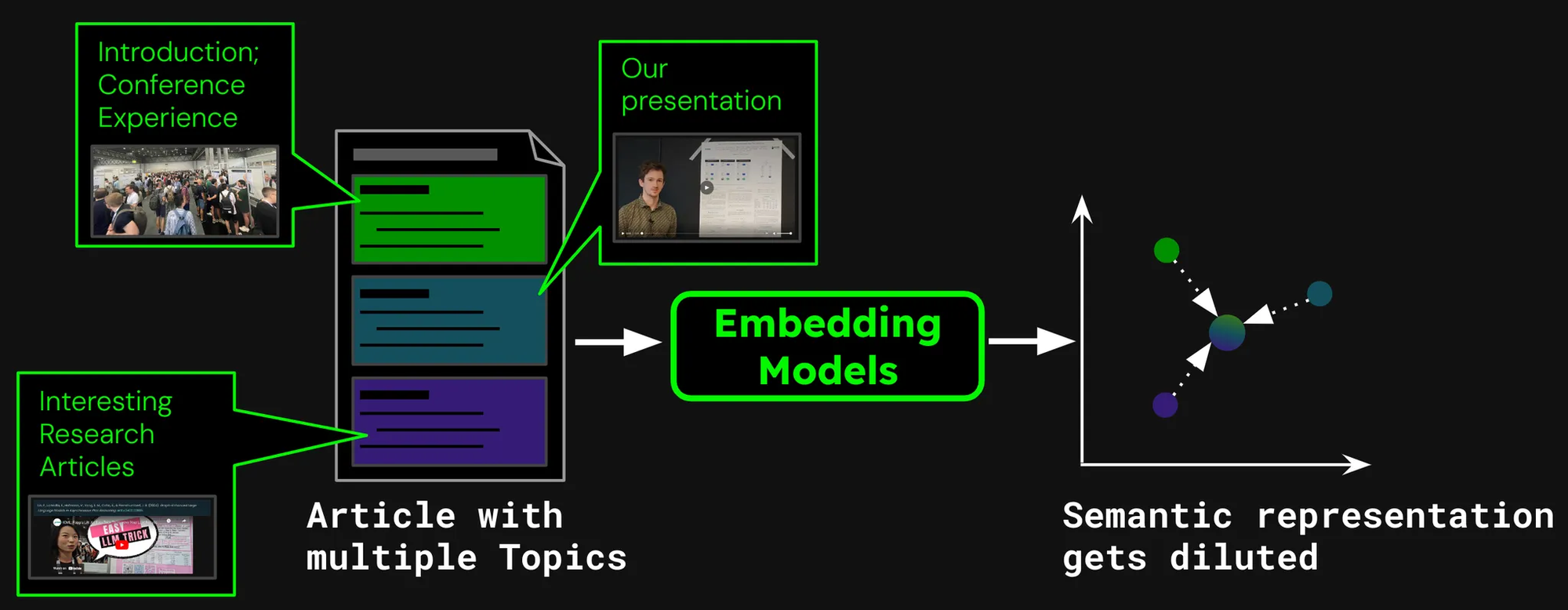
Immaginiamo di costruire un sistema di ricerca documenti per articoli, come quelli del nostro blog Jina AI. A volte un singolo articolo può coprire più argomenti, come il report sulla nostra visita alla conferenza ICML 2024, che contiene:
- Un'introduzione, che cattura informazioni generali su ICML (numero di partecipanti, luogo, scopo, ecc).
- La presentazione del nostro lavoro (jina-clip-v1).
- Riassunti di altri interessanti paper di ricerca presentati all'ICML.
Se creiamo un solo embedding per questo articolo, quell'embedding rappresenta una miscela di tre argomenti disparati:
Questo porta a diversi problemi:
- Diluizione della Rappresentazione: Mentre tutti gli argomenti in un dato testo potrebbero essere correlati, solo uno potrebbe essere rilevante per la query di ricerca dell'utente. Tuttavia, un singolo embedding (in questo caso, quello dell'intero post del blog) è solo un punto nello spazio vettoriale. Man mano che più testo viene aggiunto all'input del modello, l'embedding si sposta per catturare l'argomento generale dell'articolo, rendendolo meno efficace nel rappresentare il contenuto trattato in specifici paragrafi.
- Capacità Limitata: I modelli di embedding producono vettori di dimensione fissa, indipendentemente dalla lunghezza dell'input. Man mano che viene aggiunto più contenuto all'input, diventa più difficile per il modello rappresentare tutte queste informazioni nel vettore. Pensalo come scalare un'immagine a 16×16 pixel — Se ridimensioni l'immagine di qualcosa di semplice, come una mela, puoi ancora ricavare significato dall'immagine scalata. Scalare una mappa stradale di Berlino? Non proprio.
- Perdita di Informazioni: In alcuni casi, anche i modelli di embedding con contesto lungo raggiungono i loro limiti; Molti modelli supportano la codifica del testo fino a 8.192 token. I documenti più lunghi devono essere troncati prima dell'embedding, portando a una perdita di informazioni. Se l'informazione rilevante per l'utente si trova alla fine del documento, non verrà catturata affatto dall'embedding.
- Potresti Aver Bisogno della Segmentazione del Testo: Alcune applicazioni richiedono embedding per segmenti specifici del testo ma non per l'intero documento, come identificare il passaggio rilevante in un testo.
tagContesto Lungo vs. Troncamento
Per vedere se il contesto lungo è effettivamente utile, diamo un'occhiata alle prestazioni di due scenari di recupero:
- Codifica di documenti fino a 8.192 token (circa 10 pagine di testo).
- Troncamento dei documenti a 192 token e codifica fino a quel punto.
Confronteremo i risultati utilizzandojina-embeddings-v3 con la metrica di recupero nDCG@10. Abbiamo testato i seguenti dataset:
| Dataset | Descrizione | Esempio di Query | Esempio di Documento | Lunghezza Media Documento (caratteri) |
|---|---|---|---|---|
| NFCorpus | Un dataset di recupero di testi medici completi con 3.244 query e documenti principalmente da PubMed. | "Using Diet to Treat Asthma and Eczema" | "Statin Use and Breast Cancer Survival: A Nationwide Cohort Study from Finland Recent studies have suggested that [...]" | 326.753 |
| QMSum | Un dataset di riepilogo di riunioni basato su query che richiede il riepilogo di segmenti rilevanti delle riunioni. | "The professor was the one to raise the issue and suggested that a knowledge engineering trick [...]" | "Project Manager: Is that alright now ? {vocalsound} Okay . Sorry ? Okay , everybody all set to start the meeting ? [...]" | 37.445 |
| NarrativeQA | Dataset QA con lunghe storie e relative domande su contenuti specifici. | "What kind of business Sophia owned in Paris?" | "The Project Gutenberg EBook of The Old Wives' Tale, by Arnold Bennett\n\nThis eBook is for the use of anyone anywhere [...]" | 53.336 |
| 2WikiMultihopQA | Un dataset QA multi-hop con fino a 5 passaggi di ragionamento, progettato con template per evitare scorciatoie. | "What is the award that the composer of song The Seeker (The Who Song) earned?" | "Passage 1:\nMargaret, Countess of Brienne\nMarguerite d'Enghien (born 1365 - d. after 1394), was the ruling suo jure [...]" | 30.854 |
| SummScreenFD | Un dataset di riassunti di sceneggiature con trascrizioni di serie TV e riassunti che richiedono l'integrazione di trame disperse. | "Penny gets a new chair, which Sheldon enjoys until he finds out that she picked it up from [...]" | "[EXT. LAS VEGAS CITY (STOCK) - NIGHT]\n[EXT. ABERNATHY RESIDENCE - DRIVEWAY -- NIGHT]\n(The lamp post light over the [...]" | 1.613 |
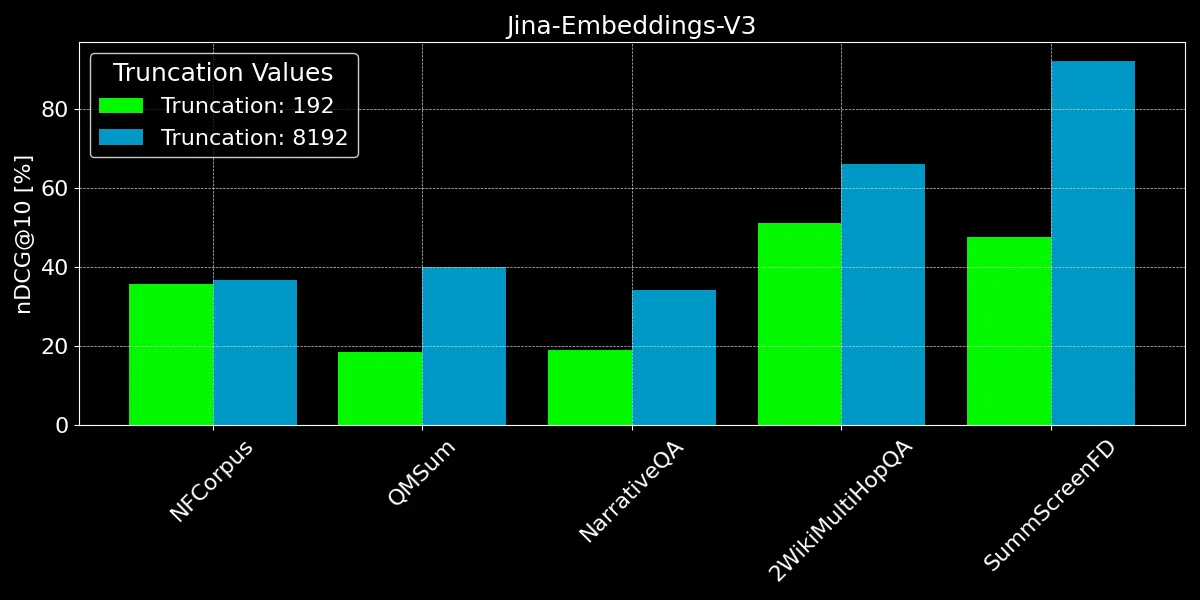
Come possiamo vedere, codificare più di 192 token può portare a notevoli miglioramenti delle prestazioni:
Tuttavia, su alcuni dataset vediamo miglioramenti maggiori rispetto ad altri:
- Per NFCorpus, il troncamento fa a malapena differenza. Questo perché i titoli e gli abstract sono proprio all'inizio dei documenti, e questi sono altamente rilevanti per le tipiche ricerche degli utenti. Che sia troncato o meno, i dati più pertinenti rimangono entro il limite di token.
- QMSum e NarrativeQA sono considerati compiti di "comprensione della lettura", dove gli utenti tipicamente cercano fatti specifici all'interno di un testo. Questi fatti sono spesso incorporati in dettagli sparsi in tutto il documento e possono cadere al di fuori del limite troncato di 192 token. Ad esempio, nel documento NarrativeQA Percival Keene, la risposta alla domanda "Chi è il bullo che ruba il pranzo di Percival?" si trova ben oltre questo limite. Similmente, in 2WikiMultiHopQA, le informazioni rilevanti sono disperse in tutto il documento, richiedendo ai modelli di navigare e sintetizzare conoscenze da più sezioni per rispondere efficacemente alle query.
- SummScreenFD è un compito mirato a identificare la sceneggiatura corrispondente a un dato riassunto. Poiché il riassunto comprende informazioni distribuite in tutta la sceneggiatura, codificare più testo migliora l'accuratezza nel far corrispondere il riassunto alla sceneggiatura corretta.
tagSegmentazione del testo per migliori prestazioni di recupero
• Segmentazione: Rilevamento di segnali di confine in un testo di input, per esempio, frasi o un numero fisso di token.
• Chunking ingenuo: Suddivisione del testo in chunks basata sui segnali di segmentazione, prima di codificarlo.
• Late chunking: Codifica del documento prima e poi segmentazione (preservando il contesto tra i chunks).
Invece di incorporare un intero documento in un unico vettore, possiamo utilizzare vari metodi per prima segmentare il documento assegnando segnali di confine:

Alcuni metodi comuni includono:
- Segmentazione per dimensione fissa: Il documento viene diviso in segmenti di un numero fisso di token, determinato dal tokenizer del modello di embedding. Questo assicura che la tokenizzazione dei segmenti corrisponda alla tokenizzazione dell'intero documento (segmentare per un numero specifico di caratteri potrebbe portare a una tokenizzazione diversa).
- Segmentazione per frase: Il documento viene segmentato in frasi, e ogni chunk consiste in n numero di frasi.
- Segmentazione per semantica: Ogni segmento corrisponde a più frasi e un modello di embedding determina la similarità delle frasi consecutive. Le frasi con alte similarità di embedding vengono assegnate allo stesso chunk.
Per semplicità, in questo articolo utilizziamo la segmentazione a dimensione fissa.
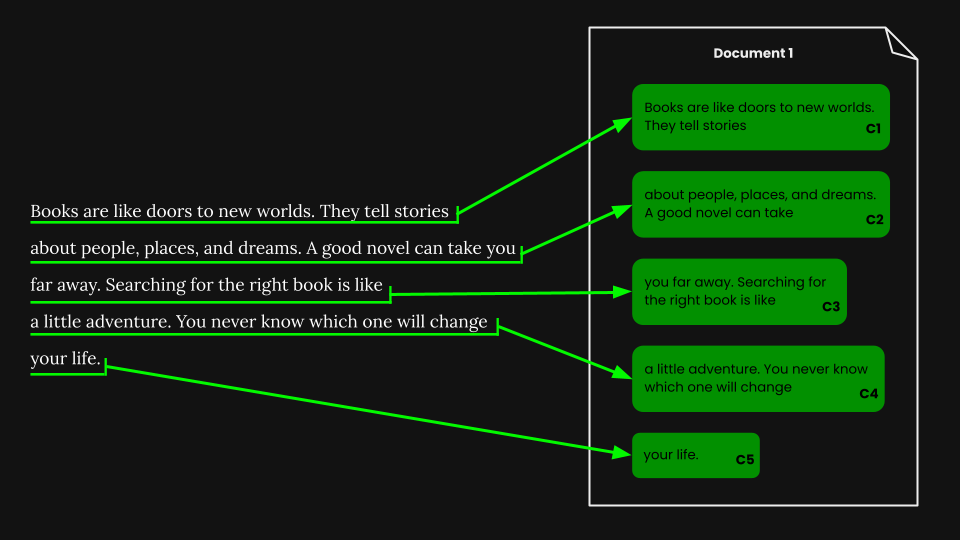
tagRecupero di documenti utilizzando il chunking ingenuo
Una volta eseguita la segmentazione a dimensione fissa, possiamo ingenuamente suddividere il documento secondo quei segmenti:
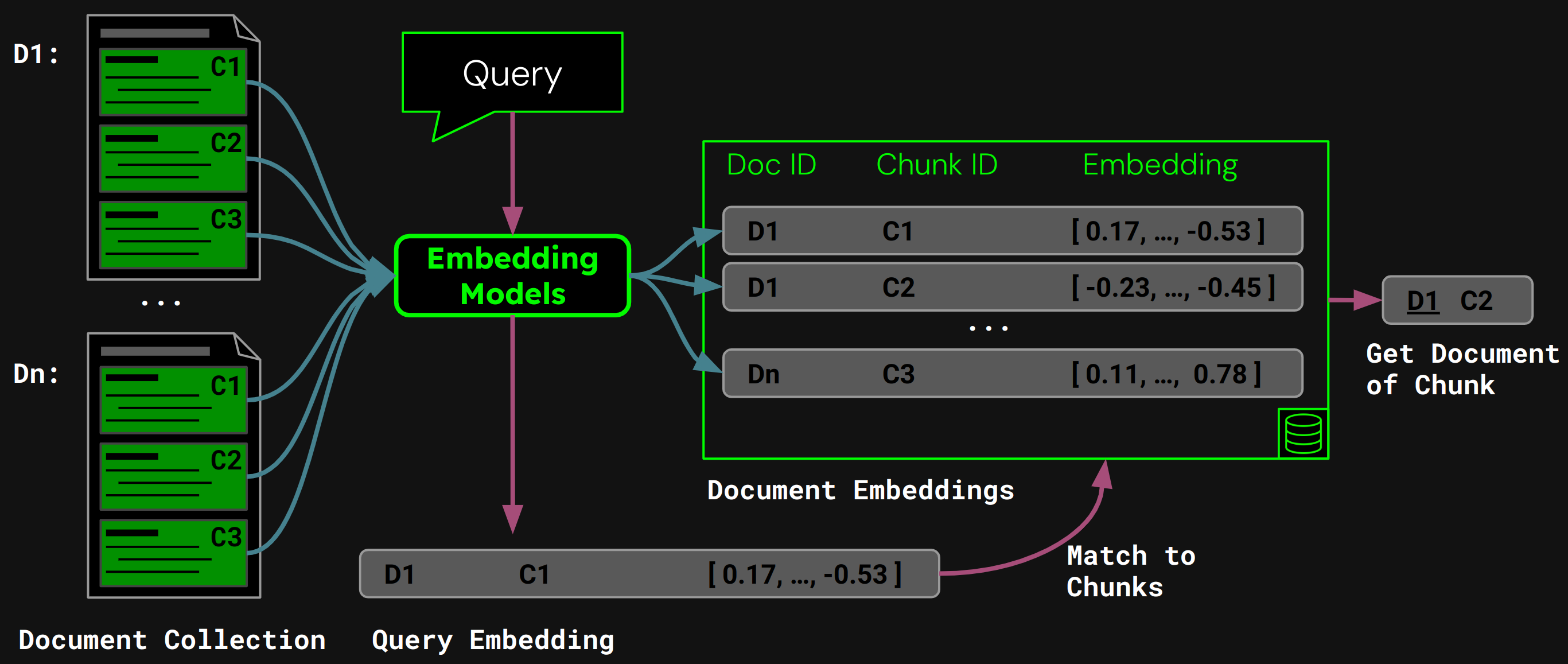
Usando jina-embeddings-v3, codifichiamo ogni chunk in un embedding che cattura accuratamente la sua semantica, poi memorizziamo questi embedding in un database vettoriale.
Durante l'esecuzione, il modello codifica la query dell'utente in un vettore di query. Lo confrontiamo con il nostro database vettoriale di embedding dei chunk per trovare il chunk con la più alta similarità del coseno, e poi restituiamo il documento corrispondente all'utente:
tagProblemi con il Chunking Ingenuo

Mentre il chunking ingenuo affronta alcune delle limitazioni dei modelli di embedding a lungo contesto, presenta anche degli svantaggi:
- Perdita del Quadro Generale: Per quanto riguarda il recupero dei documenti, più embedding di chunk più piccoli potrebbero non riuscire a catturare l'argomento generale del documento. È come non riuscire a vedere la foresta a causa degli alberi.
- Problema del Contesto Mancante: I chunk non possono essere interpretati accuratamente poiché mancano le informazioni contestuali, come illustrato nella Figura 6.
- Efficienza: Più chunk richiedono più spazio di archiviazione e aumentano il tempo di recupero.
tagIl Late Chunking Risolve il Problema del Contesto
Il late chunking funziona in due passaggi principali:
- Prima, utilizza le capacità di lungo contesto del modello per codificare l'intero documento in embedding di token. Questo preserva il contesto completo del documento.
- Poi, crea gli embedding dei chunk applicando il mean pooling a specifiche sequenze di embedding di token, corrispondenti ai segnali di confine identificati durante la segmentazione.
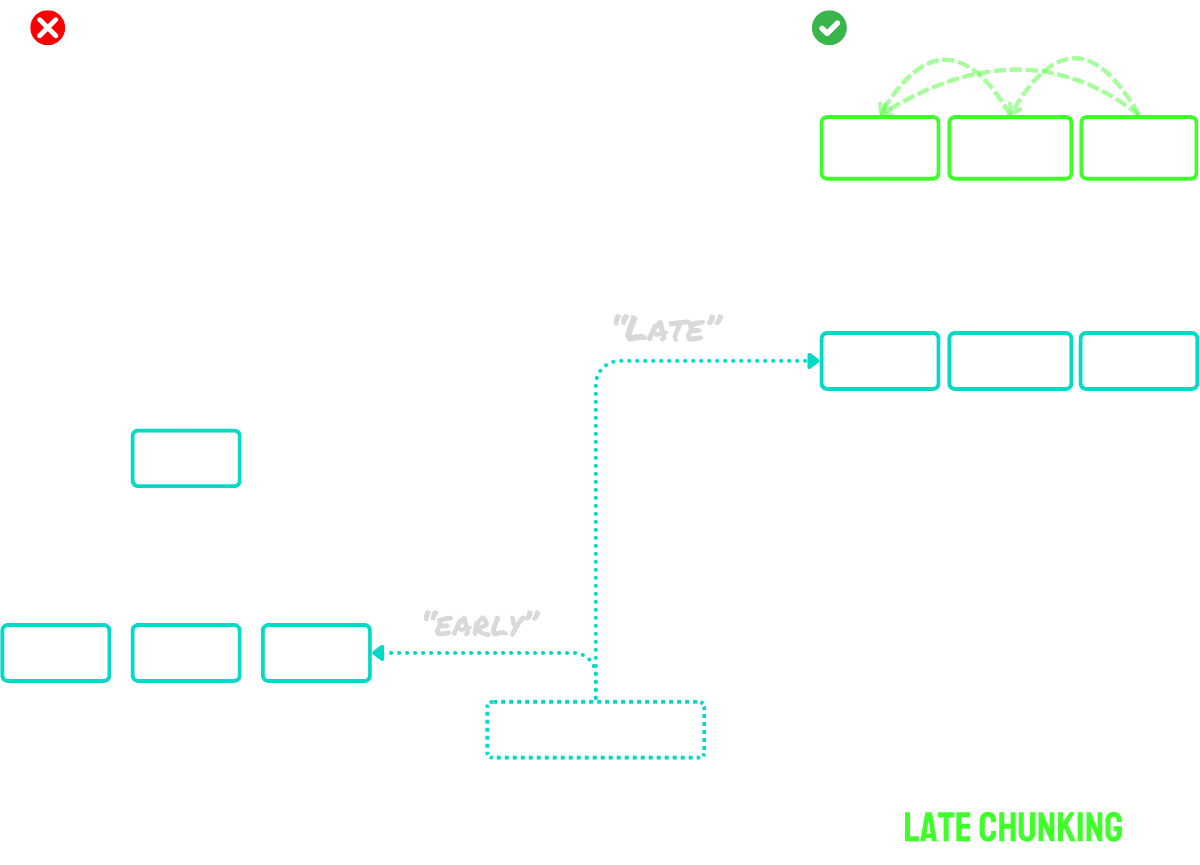
Il vantaggio principale di questo approccio è che gli embedding dei token sono contestualizzati - significa che catturano naturalmente riferimenti e relazioni con altre parti del documento. Poiché il processo di embedding avviene prima del chunking, ogni chunk mantiene la consapevolezza del contesto più ampio del documento, risolvendo il problema del contesto mancante che affligge gli approcci di chunking ingenuo.
Per documenti che superano la dimensione massima di input del modello, possiamo utilizzare il "long late chunking":
- Prima, dividiamo il documento in "macro-chunk" sovrapposti. Ogni macro-chunk è dimensionato per rientrare nella lunghezza massima del contesto del modello (per esempio, 8.192 token).
- Il modello elabora questi macro-chunk per creare gli embedding dei token.
- Una volta ottenuti gli embedding dei token, procediamo con il late chunking standard - applicando il mean pooling per creare gli embedding finali dei chunk.
Questo approccio ci permette di gestire documenti di qualsiasi lunghezza mantenendo i benefici del late chunking. Pensalo come un processo in due fasi: prima rendere il documento digeribile per il modello, poi applicare la procedura normale di late chunking.
In breve:
- Chunking ingenuo: Segmentare il documento in piccoli chunk, poi codificare ogni chunk separatamente.
- Late chunking: Codificare l'intero documento in una volta per creare gli embedding dei token, poi creare gli embedding dei chunk raggruppando gli embedding dei token basati sui confini dei segmenti.
- Long late chunking: Dividere documenti grandi in macro-chunk sovrapposti che si adattano alla finestra di contesto del modello, codificarli per ottenere gli embedding dei token, poi applicare il late chunking normalmente.
Per una descrizione più estesa dell'idea, dai un'occhiata al nostro paper o ai post del blog menzionati sopra.
tagFare Chunking o No?
Abbiamo già visto che l'embedding a lungo contesto generalmente supera gli embedding di testi più brevi, e abbiamo dato una panoramica delle strategie di chunking sia ingenuo che tardivo. La domanda ora è: Il chunking è migliore dell'embedding a lungo contesto?
Per condurre un confronto equo, tronchiamo i valori di testo alla lunghezza massima della sequenza del modello (8.192 token) prima di iniziare a segmentarli. Usiamo una segmentazione a dimensione fissa con 64 token per segmento (sia per la segmentazione ingenua che per il late chunking). Confrontiamo tre scenari:
- Nessuna segmentazione: Codifichiamo ogni testo in un singolo embedding. Questo porta agli stessi punteggi dell'esperimento precedente (vedi Figura 2), ma li includiamo qui per un migliore confronto.
- Chunking ingenuo: Segmentiamo i testi, poi applichiamo il chunking ingenuo basato sui segnali di confine.
- Late chunking: Segmentiamo i testi, poi usiamo il late chunking per determinare gli embedding.
Sia per il late chunking che per la segmentazione ingenua, utilizziamo il recupero dei chunk per determinare il documento rilevante (come mostrato nella Figura 5, precedentemente in questo post).
I risultati non mostrano un chiaro vincitore:
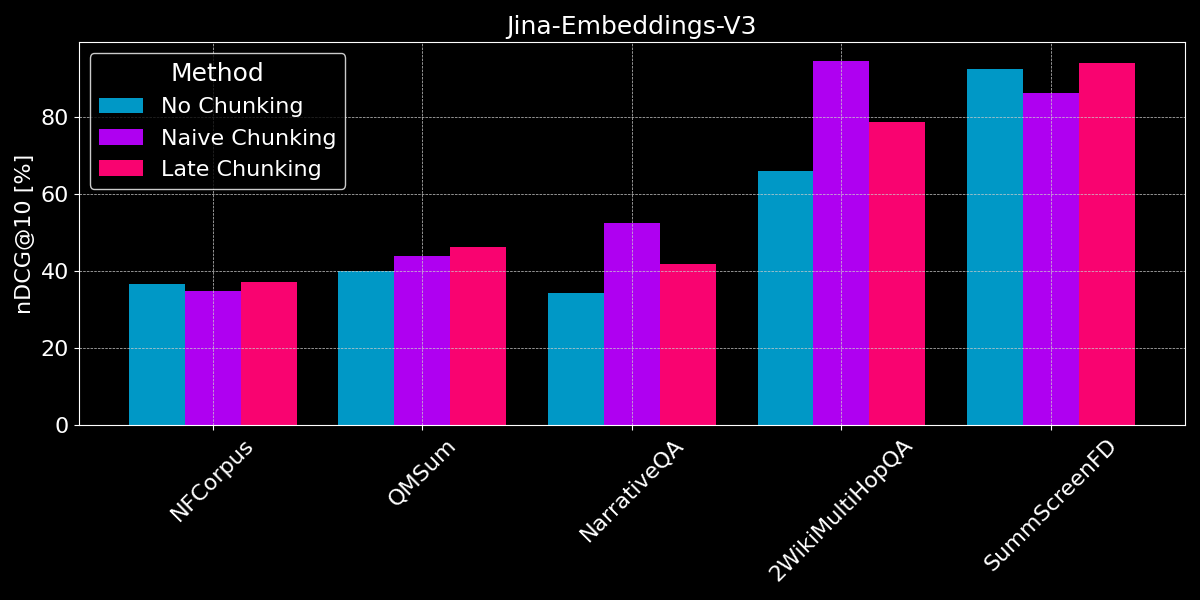
- Per il recupero dei fatti, il chunking ingenuo funziona meglio: Per i dataset QMSum, NarrativeQA e 2WikiMultiHopQA, il modello deve identificare i passaggi rilevanti nel documento. Qui, il chunking ingenuo è chiaramente migliore rispetto alla codifica di tutto in un singolo embedding, poiché probabilmente solo pochi chunk includono informazioni rilevanti, e tali chunk le catturano molto meglio di un singolo embedding dell'intero documento.
- Il chunking tardivo funziona meglio con documenti coerenti e contesto rilevante: Per documenti che trattano un argomento coerente dove gli utenti cercano temi generali piuttosto che fatti specifici (come in NFCorpus), il chunking tardivo ha prestazioni leggermente migliori rispetto al non chunking, poiché bilancia il contesto dell'intero documento con i dettagli locali. Tuttavia, mentre il chunking tardivo generalmente si comporta meglio del chunking ingenuo preservando il contesto, questo vantaggio può diventare uno svantaggio quando si cercano fatti isolati all'interno di documenti contenenti per lo più informazioni irrilevanti - come si vede nelle regressioni delle prestazioni per NarrativeQA e 2WikiMultiHopQA, dove il contesto aggiunto diventa più distraente che utile.
tagLa Dimensione dei Chunk Fa la Differenza?
L'efficacia dei metodi di chunking dipende davvero dal dataset, evidenziando come la struttura del contenuto giochi un ruolo cruciale:
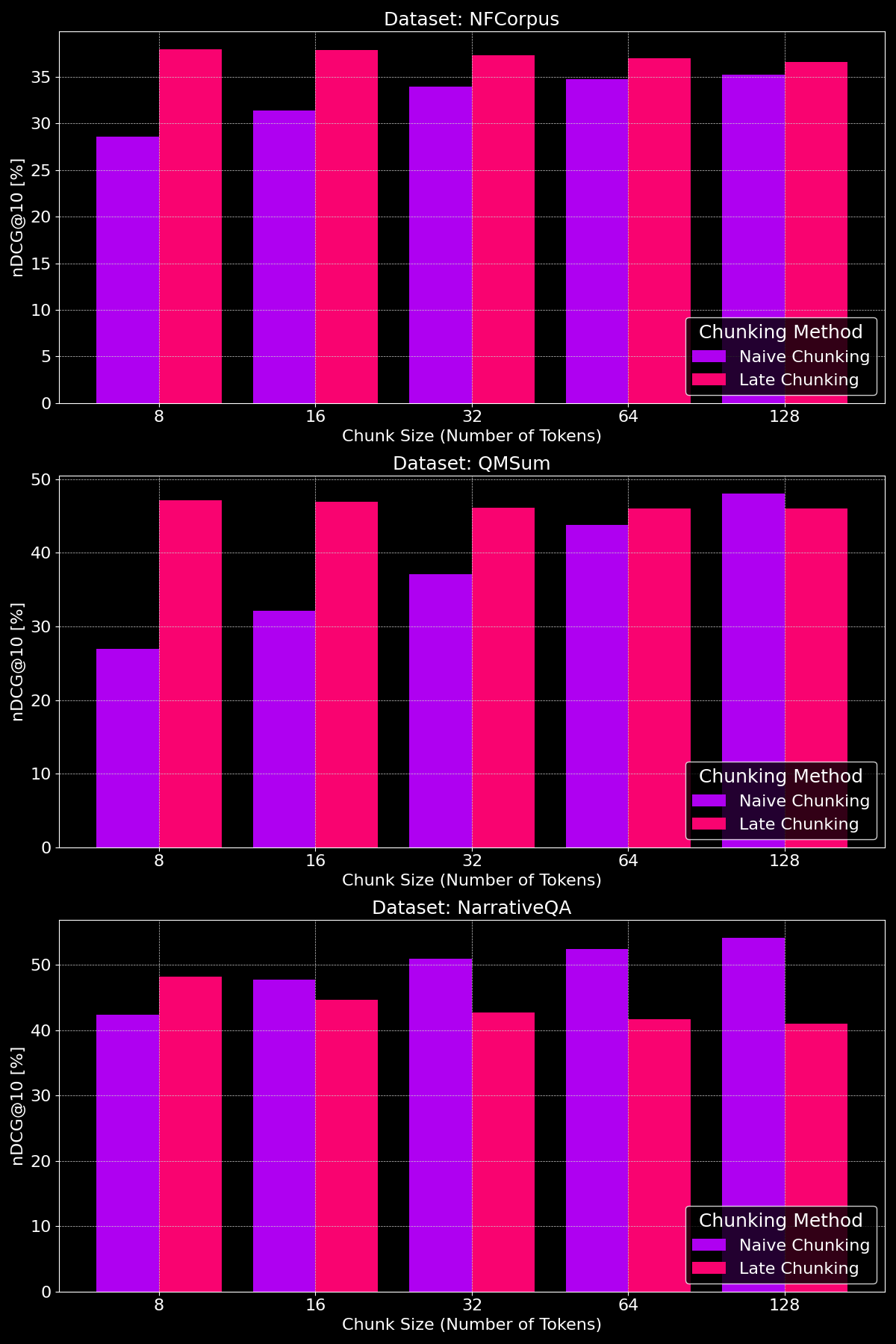
Come possiamo vedere, il chunking tardivo generalmente supera il chunking ingenuo con chunk di dimensioni minori, poiché i chunk ingenui più piccoli sono troppo ridotti per contenere molto contesto, mentre i chunk tardivi più piccoli mantengono il contesto dell'intero documento, rendendoli più significativi semanticamente. L'eccezione è il dataset NarrativeQA dove c'è semplicemente così tanto contesto irrilevante che il chunking tardivo perde terreno. Con chunk di dimensioni maggiori, il chunking ingenuo mostra un notevole miglioramento (occasionalmente superando il chunking tardivo) grazie all'aumento del contesto, mentre le prestazioni del chunking tardivo diminuiscono gradualmente.
tagConclusioni: Quando Usare Cosa?
In questo post, abbiamo esaminato diversi tipi di task di recupero documenti per capire meglio quando utilizzare la segmentazione e quando il chunking tardivo è utile. Quindi, cosa abbiamo imparato?
tagQuando Dovrei Usare l'Embedding con Contesto Lungo?
In generale, non danneggia l'accuratezza del recupero includere quanto più testo possibile dei tuoi documenti nell'input del tuo modello di embedding. Tuttavia, i modelli di embedding con contesto lungo spesso si concentrano sull'inizio dei documenti, poiché contengono contenuti come titoli e introduzione che sono più importanti per giudicare la rilevanza, ma i modelli potrebbero perdere contenuti nella parte centrale del documento.
tagQuando Dovrei Usare il Chunking Ingenuo?
Quando i documenti coprono molteplici aspetti, o le query degli utenti mirano a informazioni specifiche all'interno di un documento, il chunking generalmente migliora le prestazioni di recupero.
Alla fine, le decisioni sulla segmentazione dipendono da fattori come la necessità di mostrare testo parziale agli utenti (ad esempio come Google presenta i passaggi rilevanti nelle anteprime dei risultati di ricerca), che rende la segmentazione essenziale, o vincoli di calcolo e memoria, dove la segmentazione può essere meno favorevole a causa dell'aumento del sovraccarico di recupero e dell'utilizzo delle risorse.
tagQuando Dovrei Usare il Chunking Tardivo?
Codificando l'intero documento prima di creare i chunk, il chunking tardivo risolve il problema dei segmenti di testo che perdono il loro significato a causa del contesto mancante. Questo funziona particolarmente bene con documenti coerenti, dove ogni parte è correlata al tutto. I nostri esperimenti mostrano che il chunking tardivo è particolarmente efficace quando si divide il testo in chunk più piccoli, come dimostrato nel nostro paper. Tuttavia, c'è un'avvertenza: se parti del documento non sono correlate tra loro, includere questo contesto più ampio può effettivamente peggiorare le prestazioni di recupero, poiché aggiunge rumore agli embedding.
tagConclusione
La scelta tra embedding con contesto lungo, chunking ingenuo e chunking tardivo dipende dai requisiti specifici del tuo task di recupero. Gli embedding con contesto lungo sono preziosi per documenti coerenti con query generali, mentre il chunking eccelle nei casi in cui gli utenti cercano fatti o informazioni specifiche all'interno di un documento. Il chunking tardivo migliora ulteriormente il recupero mantenendo la coerenza contestuale all'interno di segmenti più piccoli. In definitiva, comprendere i tuoi dati e gli obiettivi di recupero guiderà l'approccio ottimale, bilanciando accuratezza, efficienza e rilevanza contestuale.
Se stai esplorando queste strategie, considera di provare jina-embeddings-v3—le sue avanzate capacità di contesto lungo, chunking tardivo e flessibilità lo rendono un'eccellente scelta per diversi scenari di recupero.

