



Recentemente, Christoph Schuhmann, fondatore di LAION AI ha condiviso un'interessante osservazione sui modelli di text embedding:
Quando le parole all'interno di una frase vengono mescolate in modo casuale, la similarità del coseno tra i loro text embedding rimane sorprendentemente alta rispetto alla frase originale.
Per esempio, consideriamo due frasi: Berlin is the capital of Germany e the Germany Berlin is capital of. Anche se la seconda frase non ha senso, i modelli di text embedding non riescono davvero a distinguerle. Usando jina-embeddings-v3, queste due frasi hanno un punteggio di similarità del coseno di 0,9295.
L'ordine delle parole non è l'unica cosa per cui gli embedding sembrano non essere molto sensibili. Le trasformazioni grammaticali possono cambiare drasticamente il significato di una frase ma avere poco impatto sulla distanza dell'embedding. Per esempio, She ate dinner before watching the movie e She watched the movie before eating dinner hanno una similarità del coseno di 0,9833, nonostante abbiano l'ordine opposto delle azioni.
Anche la negazione è notoriamente difficile da incorporare in modo coerente senza un addestramento speciale — This is a useful model e This is not a useful model appaiono praticamente identiche nello spazio degli embedding. Spesso, sostituire le parole in un testo con altre della stessa classe, come cambiare "today" in "yesterday", o modificare il tempo di un verbo, non modifica gli embedding tanto quanto si potrebbe pensare.
Questo ha serie implicazioni. Consideriamo due query di ricerca: Flight from Berlin to Amsterdam e Flight from Amsterdam to Berlin. Hanno embedding quasi identici, con jina-embeddings-v3 che assegna loro una similarità del coseno di 0,9884. Per un'applicazione del mondo reale come la ricerca di viaggi o la logistica, questa carenza è fatale.
In questo articolo, esaminiamo le sfide che affrontano i modelli di embedding, analizzando le loro persistenti difficoltà con l'ordine e la scelta delle parole. Analizziamo le principali modalità di fallimento attraverso categorie linguistiche—inclusi contesti direzionali, temporali, causali, comparativi e di negazione—mentre esploriamo strategie per migliorare le prestazioni del modello.
tagPerché le Frasi Mescolate Hanno Punteggi del Coseno Sorprendentemente Vicini?
Inizialmente, pensavamo che questo potesse dipendere da come il modello combina i significati delle parole - crea un embedding per ogni parola (6-7 parole in ciascuna delle nostre frasi di esempio sopra) e poi fa una media di questi embedding con il mean pooling. Questo significa che molto poca informazione sull'ordine delle parole è disponibile nell'embedding finale. Una media è la stessa indipendentemente dall'ordine dei valori.
Tuttavia, anche i modelli che utilizzano il CLS pooling (che esamina una speciale prima parola per comprendere l'intera frase e dovrebbe essere più sensibile all'ordine delle parole) hanno lo stesso problema. Per esempio, bge-1.5-base-en dà ancora un punteggio di similarità del coseno di 0,9304 per le frasi Berlin is the capital of Germany e the Germany Berlin is capital of.
Questo indica una limitazione nel modo in cui vengono addestrati i modelli di embedding. Mentre i modelli linguistici inizialmente apprendono la struttura della frase durante il pre-training, sembrano perdere parte di questa comprensione durante l'addestramento contrastivo — il processo che utilizziamo per creare modelli di embedding.
tagCome la Lunghezza del Testo e l'Ordine delle Parole Influenzano la Similarità degli Embedding?
Perché i modelli hanno problemi con l'ordine delle parole in primo luogo? La prima cosa che viene in mente è la lunghezza (in token) del testo. Quando il testo viene inviato alla funzione di codifica, il modello prima genera una lista di embedding dei token (cioè, ogni parola tokenizzata ha un vettore dedicato che rappresenta il suo significato), poi li media.
Per vedere come la lunghezza del testo e l'ordine delle parole influenzano la similarità degli embedding, abbiamo generato un dataset di 180 frasi sintetiche di varie lunghezze, come 3, 5, 10, 15, 20 e 30 token. Abbiamo anche mescolato casualmente i token per formare una variazione di ogni frase:

Ecco alcuni esempi:
| Lunghezza (token) | Frase originale | Frase mescolata |
|---|---|---|
| 3 | The cat sleeps | cat The sleeps |
| 5 | He drives his car carefully | drives car his carefully He |
| 15 | The talented musicians performed beautiful classical music at the grand concert hall yesterday | in talented now grand classical yesterday The performed musicians at hall concert the music |
| 30 | The passionate group of educational experts collaboratively designed and implemented innovative teaching methodologies to improve learning outcomes in diverse classroom environments worldwide | group teaching through implemented collaboratively outcomes of methodologies across worldwide diverse with passionate and in experts educational classroom for environments now by learning to at improve from innovative The designed |
Codificheremo il dataset utilizzando il nostro modello jina-embeddings-v3 e il modello open-source bge-base-en-v1.5, poi calcoleremo la similarità del coseno tra la frase originale e quella mescolata:
| Lunghezza (token) | Media similarità del coseno | Deviazione standard nella similarità del coseno |
|---|---|---|
| 3 | 0,947 | 0,053 |
| 5 | 0,909 | 0,052 |
| 10 | 0,924 | 0,031 |
| 15 | 0,918 | 0,019 |
| 20 | 0,899 | 0,021 |
| 30 | 0,874 | 0,025 |
Ora possiamo generare un box plot, che rende più chiara la tendenza nella similarità del coseno:
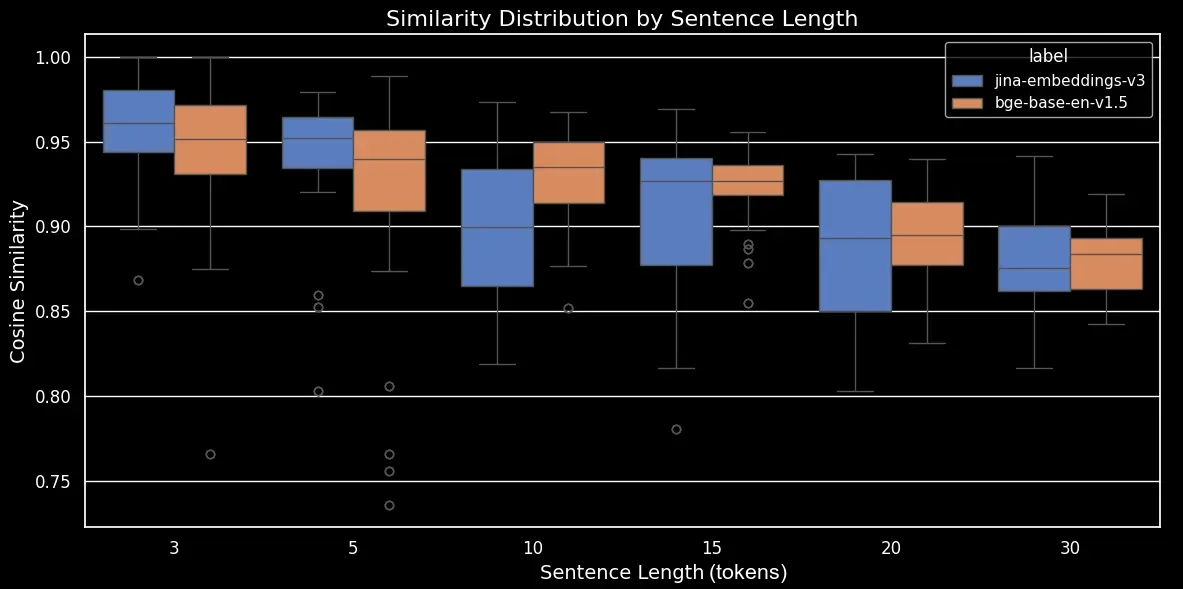
bge-base-en-1.5 (non affinato)Come possiamo vedere, c'è una chiara relazione lineare nella similarità media del coseno degli embedding. Più lungo è il testo, più basso è il punteggio medio di similarità del coseno tra le frasi originali e quelle mescolate casualmente. Questo probabilmente accade a causa dello "spostamento delle parole", ovvero quanto lontano le parole si sono spostate dalle loro posizioni originali dopo il mescolamento casuale. In un testo più breve, ci sono semplicemente meno "slot" in cui un token può essere mescolato quindi non può spostarsi così lontano, mentre un testo più lungo ha un maggior numero di permutazioni possibili e le parole possono spostarsi a una distanza maggiore.
Come mostrato nella figura sottostante (Similarità del coseno vs Spostamento medio delle parole), più lungo è il testo, maggiore è lo spostamento delle parole:
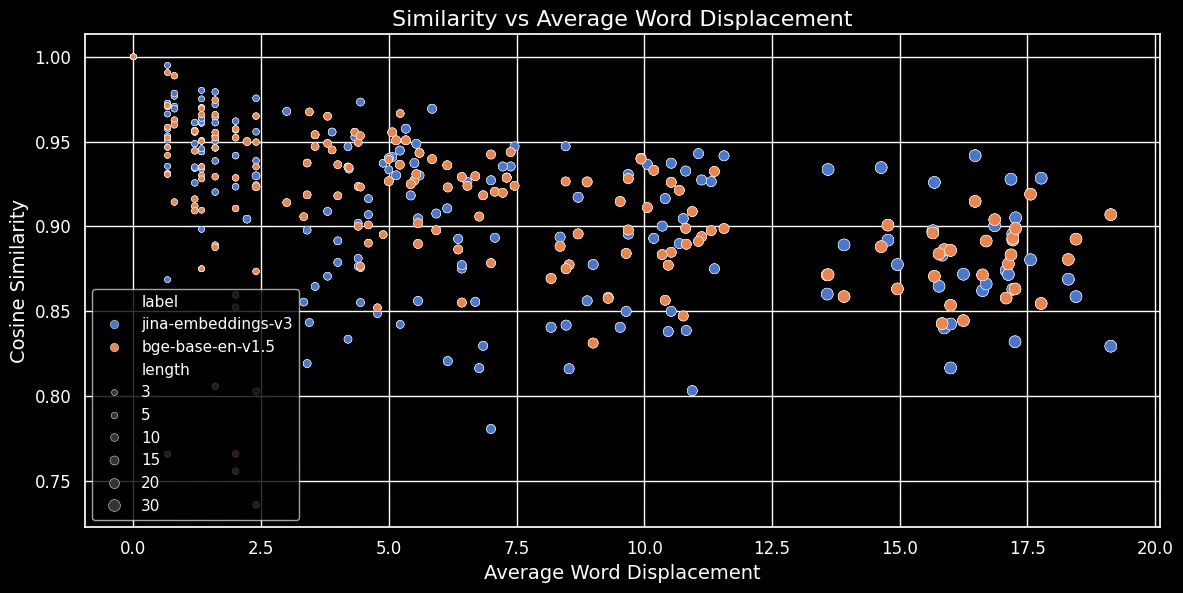
Gli embedding dei token dipendono dal contesto locale, cioè dalle parole più vicine ad essi. In un testo breve, riorganizzare le parole non può modificare molto quel contesto. Tuttavia, per un testo più lungo, una parola potrebbe essere spostata molto lontano dal suo contesto originale e questo può modificare notevolmente il suo embedding di token. Di conseguenza, mescolare le parole in un testo più lungo produce un embedding più distante rispetto a uno più breve. La figura sopra mostra che sia per jina-embeddings-v3, usando il mean pooling, sia per bge-base-en-v1.5, usando il CLS pooling, vale la stessa relazione: mescolare testi più lunghi e spostare le parole più lontano risulta in punteggi di similarità più bassi.
tagI modelli più grandi risolvono il problema?
Di solito, quando affrontiamo questo tipo di problema, una tattica comune è semplicemente utilizzare un modello più grande. Ma un modello di embedding testuale più grande può davvero catturare le informazioni sull'ordine delle parole in modo più efficace? Secondo la legge di scala dei modelli di embedding testuale (citata nel nostro post di rilascio di jina-embeddings-v3), i modelli più grandi generalmente forniscono prestazioni migliori:
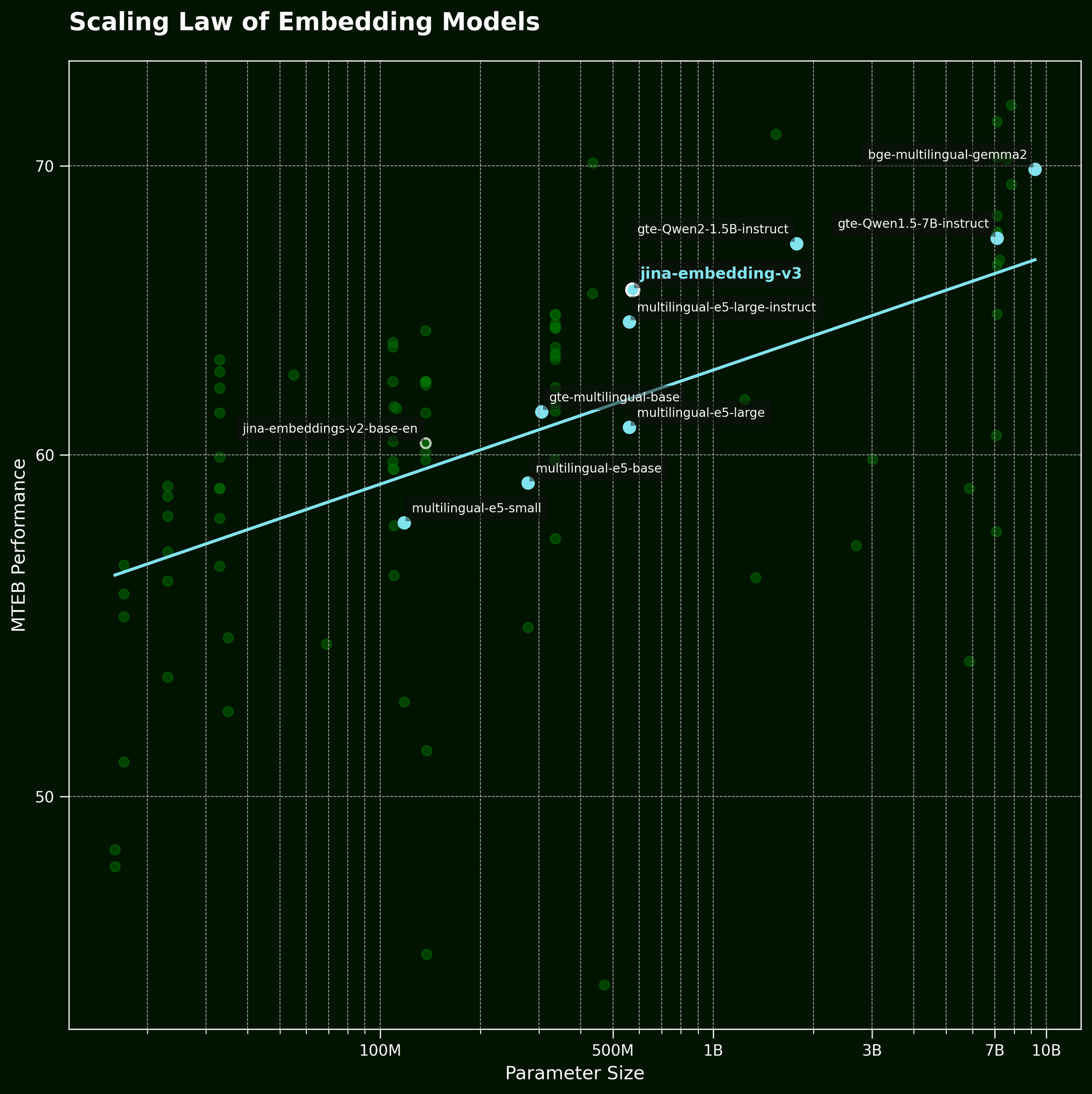
Ma un modello più grande può catturare le informazioni sull'ordine delle parole in modo più efficace? Abbiamo testato tre varianti del modello BGE: bge-small-en-v1.5, bge-base-en-v1.5, e bge-large-en-v1.5, con dimensioni dei parametri rispettivamente di 33 milioni, 110 milioni e 335 milioni.
Useremo le stesse 180 frasi di prima, ma ignoreremo le informazioni sulla lunghezza. Codificheremo sia le frasi originali che le loro permutazioni casuali usando le tre varianti del modello e tracceremo la similarità media del coseno:
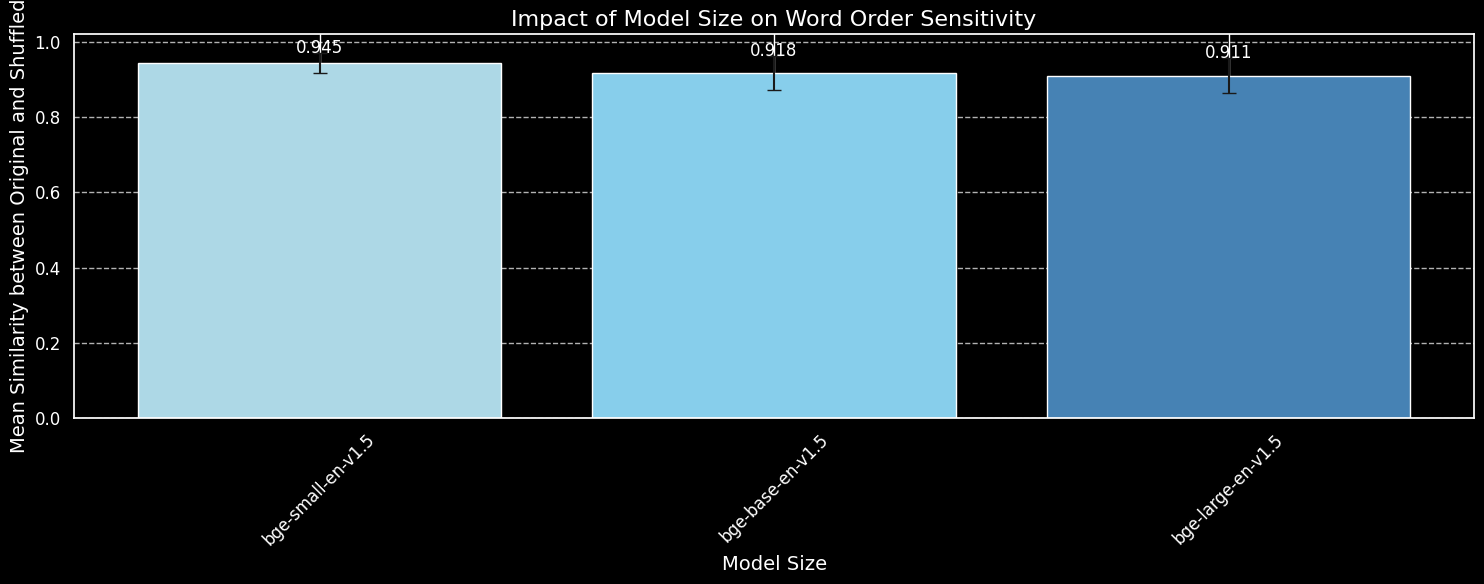
bge-small-en-v1.5, bge-base-en-v1.5, e bge-large-en-v1.5.Mentre possiamo vedere che i modelli più grandi sono più sensibili alla variazione dell'ordine delle parole, la differenza è piccola. Persino il molto più grande bge-large-en-v1.5 è solo leggermente migliore nel distinguere le frasi mescolate da quelle non mescolate. Altri fattori entrano in gioco nel determinare quanto un modello di embedding sia sensibile ai riordinamenti delle parole, in particolare le differenze nel regime di addestramento. Inoltre, la similarità del coseno è uno strumento molto limitato per misurare la capacità di un modello di fare distinzioni. Tuttavia, possiamo vedere che la dimensione del modello non è un fattore principale. Non possiamo semplicemente rendere il nostro modello più grande e risolvere questo problema.
tagOrdine delle parole e scelta delle parole nel mondo reale
jina-embeddings-v2 (non il nostro modello più recente, jina-embeddings-v3) poiché v2 è molto più piccolo e quindi più veloce per sperimentare sulle nostre GPU locali, con 137m di parametri contro i 580m di v3.Come abbiamo menzionato nell'introduzione, l'ordine delle parole non è l'unica sfida per i modelli di embedding. Una sfida più realistica nel mondo reale riguarda la scelta delle parole. Ci sono molti modi per cambiare le parole in una frase — modi che non si riflettono bene negli embedding. Possiamo prendere "Lei è volata da Parigi a Tokyo" e modificarla in "Lei ha guidato da Tokyo a Parigi", e gli embedding rimangono simili. Abbiamo mappato questo attraverso diverse categorie di alterazione:
| Categoria | Esempio - Sinistra | Esempio - Destra | Similarità del coseno (jina) |
|---|---|---|---|
| Direzionale | Lei è volata da Parigi a Tokyo | Lei ha guidato da Tokyo a Parigi | 0.9439 |
| Temporale | Ha cenato prima di guardare il film | Ha guardato il film prima di cenare | 0.9833 |
| Causale | L'aumento della temperatura ha sciolto la neve | La neve che si scioglieva ha raffreddato la temperatura | 0.8998 |
| Comparativo | Il caffè è più buono del tè | Il tè è più buono del caffè | 0.9457 |
| Negazione | Lui è in piedi vicino al tavolo | Lui è in piedi lontano dal tavolo | 0.9116 |
La tabella sopra mostra una lista di "casi di fallimento" dove un modello di text embedding non riesce a catturare sottili alterazioni delle parole. Questo è in linea con le nostre aspettative: i modelli di text embedding non hanno la capacità di ragionamento. Per esempio, il modello non comprende la relazione tra "da" e "a". I modelli di text embedding eseguono un matching semantico, con semantica tipicamente catturata a livello di token e poi compressa in un singolo vettore denso dopo il pooling. Al contrario, gli LLM (modelli autoregressivi) addestrati su dataset più grandi, a livello di trilioni di token, stanno iniziando a dimostrare capacità emergenti di ragionamento.
Questo ci ha fatto chiederci: possiamo fare fine-tuning del modello di embedding con apprendimento contrastivo usando triplette per avvicinare la query e il positivo, mentre allontaniamo la query e il negativo?

Per esempio, "Volo da Amsterdam a Berlino" potrebbe essere considerato la coppia negativa di "Volo da Berlino ad Amsterdam". In effetti, nel report tecnico di jina-embeddings-v1 (Michael Guenther, et al.), abbiamo brevemente affrontato questo problema su piccola scala: abbiamo fatto fine-tuning del modello jina-embeddings-v1 su un dataset di negazione di 10.000 esempi generati da large language model.

I risultati, riportati nel link del report sopra, sono stati promettenti:
Osserviamo che per tutte le dimensioni dei modelli, il fine-tuning sui dati delle triplette (che include il nostro dataset di training sulla negazione) migliora drammaticamente le prestazioni, in particolare sul task HardNegation.
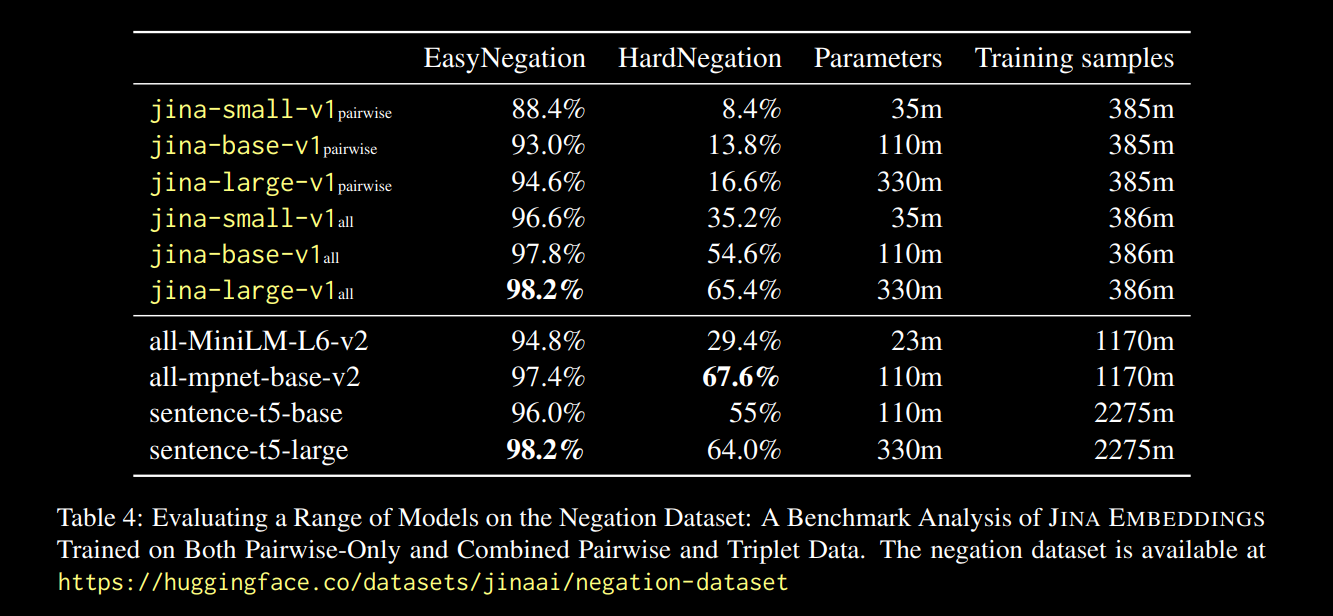
jina-embeddings con training sia a coppie che combinato triplette/coppie.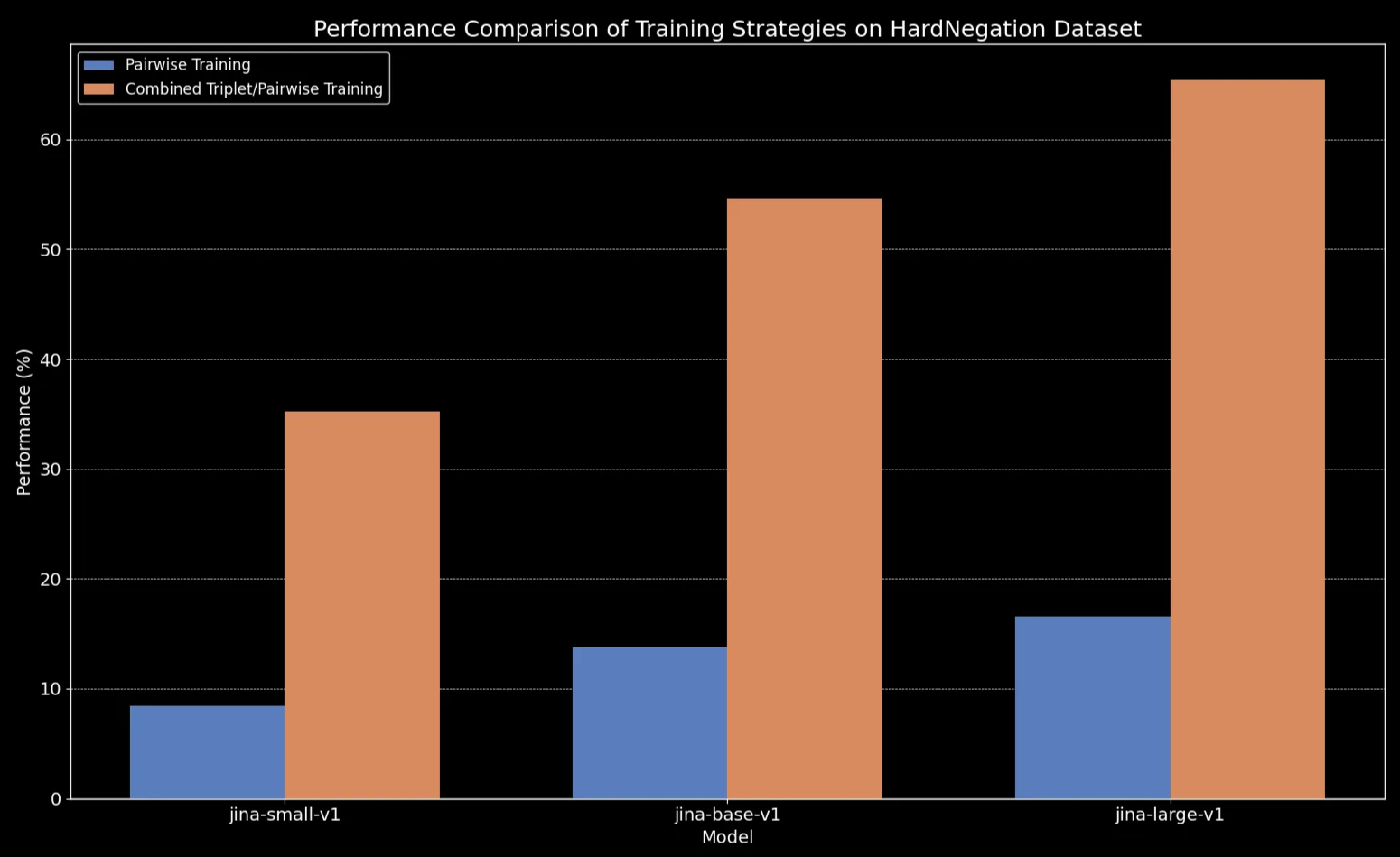
jina-embeddings.tagFine-Tuning dei Modelli di Text Embedding con Dataset Curati
Nelle sezioni precedenti, abbiamo esplorato diverse osservazioni chiave riguardo i text embedding:
- I testi più brevi sono più soggetti a errori nella cattura dell'ordine delle parole.
- Aumentare la dimensione del modello di text embedding non migliora necessariamente la comprensione dell'ordine delle parole.
- L'apprendimento contrastivo potrebbe offrire una potenziale soluzione a questi problemi.
Con questo in mente, abbiamo fatto fine-tuning di jina-embeddings-v2-base-en e bge-base-en-1.5 sui nostri dataset di negazione e ordine delle parole (circa 11.000 campioni di training in totale):


Per aiutare a valutare il fine-tuning, abbiamo generato un dataset di 1.000 triplette costituite da una query, un caso positive (pos) e un caso negative (neg):

Ecco un esempio di riga:
| Anchor | The river flows from the mountains to the sea |
| Positive | Water travels from mountain peaks to ocean |
| Negative | The river flows from the sea to the mountains |
Queste triplette sono progettate per coprire vari casi di fallimento, inclusi cambiamenti di significato direzionali, temporali e causali dovuti a cambiamenti nell'ordine delle parole.
Ora possiamo valutare i modelli su tre diversi set di valutazione:
- Il set di 180 frasi sintetiche (viste prima in questo post), mescolate casualmente.
- Cinque esempi controllati manualmente (dalla tabella direzionale/causale/ecc. sopra).
- 94 triplette curate dal nostro dataset di triplette appena generato.
Ecco la differenza per le frasi mescolate prima e dopo il fine-tuning:
| Lunghezza Frase (token) | Similarità Coseno Media (jina) |
Similarità Coseno Media (jina-ft) |
Similarità Coseno Media (bge) |
Similarità Coseno Media (bge-ft) |
|---|---|---|---|---|
| 3 | 0.970 | 0.927 | 0.929 | 0.899 |
| 5 | 0.958 | 0.910 | 0.940 | 0.916 |
| 10 | 0.953 | 0.890 | 0.934 | 0.910 |
| 15 | 0.930 | 0.830 | 0.912 | 0.875 |
| 20 | 0.916 | 0.815 | 0.901 | 0.879 |
| 30 | 0.927 | 0.819 | 0.877 | 0.852 |
Il risultato sembra chiaro: nonostante il processo di fine-tuning richieda solo cinque minuti, osserviamo un miglioramento drammatico nelle prestazioni sul dataset di frasi mescolate casualmente:
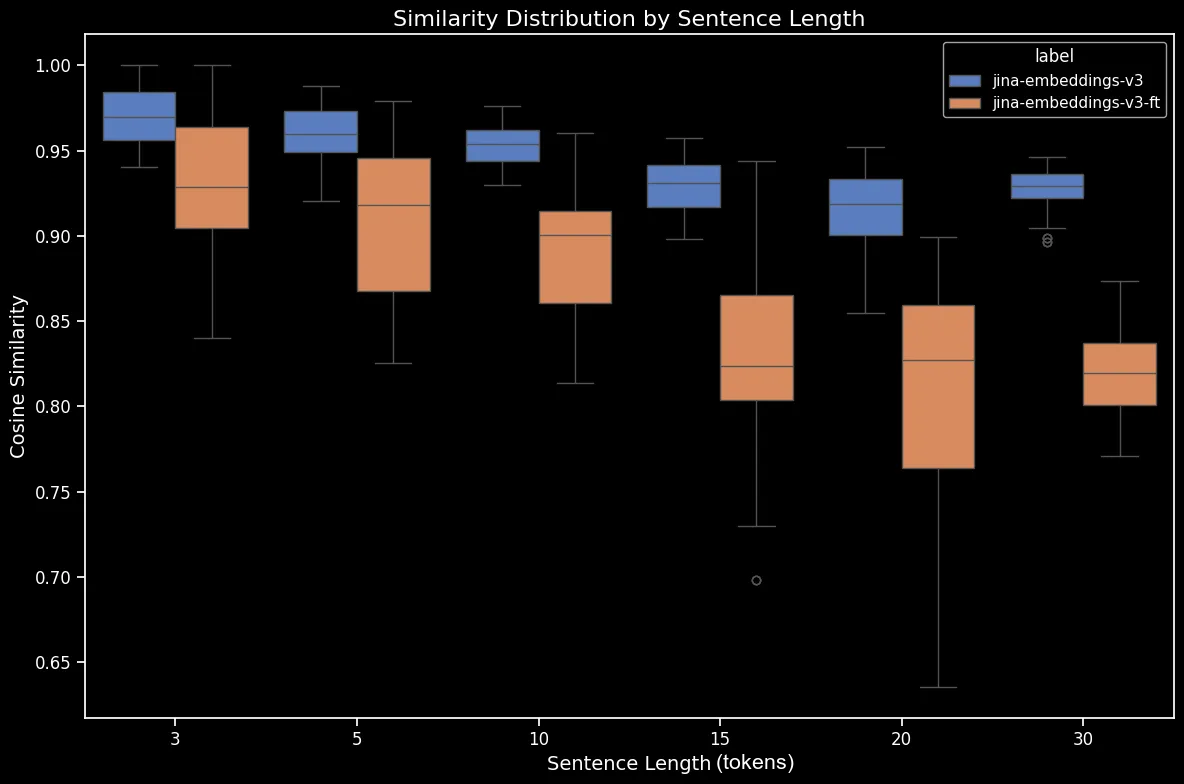
bge-base-en-1.5 (fine-tuned).Osserviamo anche miglioramenti nei casi direzionali, temporali, causali e comparativi. Il modello mostra un sostanziale miglioramento delle prestazioni riflesso da una diminuzione della similarità del coseno media. Il maggior guadagno di prestazioni si registra nel caso della negazione, grazie al nostro dataset di fine-tuning che contiene 10.000 esempi di training sulla negazione.
| Categoria | Esempio - Sinistra | Esempio - Destra | Similarità Coseno Media (jina) |
Similarità Coseno Media (jina-ft) |
Similarità Coseno Media (bge) |
Similarità Coseno Media (bge-ft) |
|---|---|---|---|---|---|---|
| Direzionale | She flew from Paris to Tokyo. | She drove from Tokyo to Paris | 0.9439 | 0.8650 | 0.9319 | 0.8674 |
| Temporale | She ate dinner before watching the movie | She watched the movie before eating dinner | 0.9833 | 0.9263 | 0.9683 | 0.9331 |
| Causale | The rising temperature melted the snow | The melting snow cooled the temperature | 0.8998 | 0.7937 | 0.8874 | 0.8371 |
| Comparativo | Coffee tastes better than tea | Tea tastes better than coffee | 0.9457 | 0.8759 | 0.9723 | 0.9030 |
| Negazione | He is standing by the table | He is standing far from the table | 0.9116 | 0.4478 | 0.8329 | 0.4329 |
tagConclusione
In questo post, approfondiamo le sfide che i modelli di text embedding affrontano, in particolare la loro difficoltà nel gestire efficacemente l'ordine delle parole. Per semplificare, abbiamo identificato cinque tipi principali di fallimento: Direzionale, Temporale, Causale, Comparativo e Negazione. Questi sono i tipi di query in cui l'ordine delle parole è realmente importante, e se il tuo caso d'uso ne coinvolge qualcuno, è importante conoscere i limiti di questi modelli.
Abbiamo anche condotto un rapido esperimento, espandendo un dataset focalizzato sulla negazione per coprire tutte e cinque le categorie di fallimento. I risultati sono stati promettenti: il fine-tuning con "hard negatives" attentamente selezionati ha reso il modello migliore nel riconoscere quali elementi appartengono insieme e quali no. Detto questo, c'è ancora molto lavoro da fare. I prossimi passi includono l'approfondimento di come la dimensione e la qualità del dataset influenzino le prestazioni.
