


Domenica sera. Premi "pubblica" su quell'articolo in cui hai messo il cuore tutto il weekend. Ogni parola, ogni idea - unicamente tua. Arrivano alcuni like. Non è virale, ma è tuo.
Tre giorni dopo, scorrendo il feed, eccolo lì: L'anima del tuo articolo nel corpo di qualcun altro! Hanno rimescolato le parole, ma riconosci la tua creazione. La cosa peggiore? La loro versione è ovunque, un successo virale costruito sulla tua creatività rubata. Non è questa l'economia creativa a cui abbiamo aderito.
La soluzione ovvia è mettere il tuo nome sul tuo lavoro. Ma siamo onesti - è anche la cosa più facile da rimuovere. Possiamo fare di meglio? In questo articolo, ti mostreremo una tecnica di watermarking che utilizza modelli di embedding che può sia firmare che rilevare contenuti originali. Non è solo un altro cliché di ricerca/RAG - sfrutta caratteristiche uniche di jina-embeddings-v3 come il contesto lungo e l'allineamento multilingue per creare un sistema di autenticazione robusto, e ci permette di mantenere una verifica affidabile dei contenuti attraverso trasformazioni come la parafrasi LLM o persino la traduzione.
tagComprendere i Watermark Testuali
I watermark digitali sono stati una pietra miliare della protezione dei contenuti per anni. Quando trovi un meme con un logo semi-trasparente sovrapposto, stai vedendo la forma più basilare di watermarking delle immagini. Le tecniche moderne di watermarking si sono evolute ben oltre le semplici sovrapposizioni visive – molte sono ora impercettibili per gli osservatori umani pur rimanendo leggibili dalle macchine.
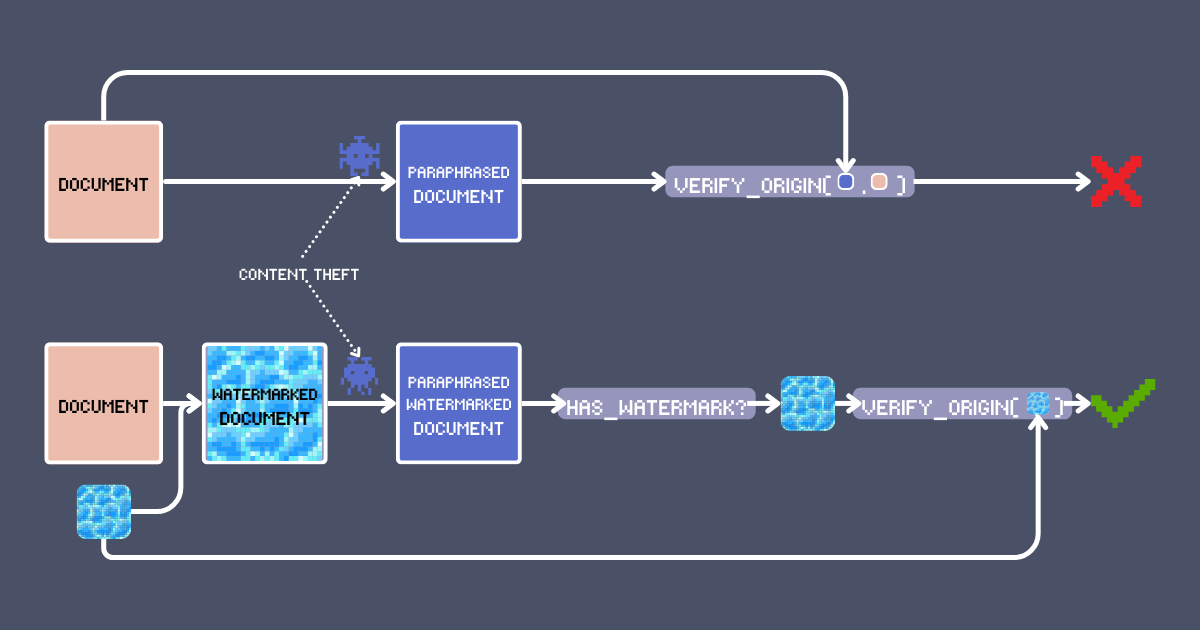
Il watermarking testuale segue principi simili ma opera nello spazio semantico. Invece di alterare i pixel, un watermark testuale modifica sottilmente il contenuto in modi che preservano il significato originale mentre incorpora una firma rilevabile. Quindi i requisiti chiave per un watermark testuale efficace sono:
- Preservazione semantica: Il testo con watermark dovrebbe mantenere il suo significato originale e la leggibilità, proprio come un watermark visivo non dovrebbe oscurare gli elementi chiave di un'immagine.
- Impercettibilità: Il watermark dovrebbe essere impercettibile ai lettori umani, assicurando che non possano intenzionalmente preservarlo o rimuoverlo durante la trasformazione del contenuto.
- Rilevabile dalle macchine: Mentre il watermark potrebbe essere sottile per i lettori umani, dovrebbe creare pattern chiari e misurabili che gli algoritmi possono identificare in modo affidabile.
- Invarianza alle trasformazioni: Qualsiasi trasformazione del contenuto (come parafrasi o traduzione), sia intenzionale che inconsapevole dell'esistenza del watermark, dovrebbe preservare il watermark o richiedere cambiamenti così sostanziali da alterare fondamentalmente la struttura o il significato del contenuto originale.
tagUtilizzare gli Embedding per il Watermarking Testuale
Costruiamo un sistema di watermarking testuale utilizzando gli embedding. Prima, definiamo i componenti chiave di questo sistema:
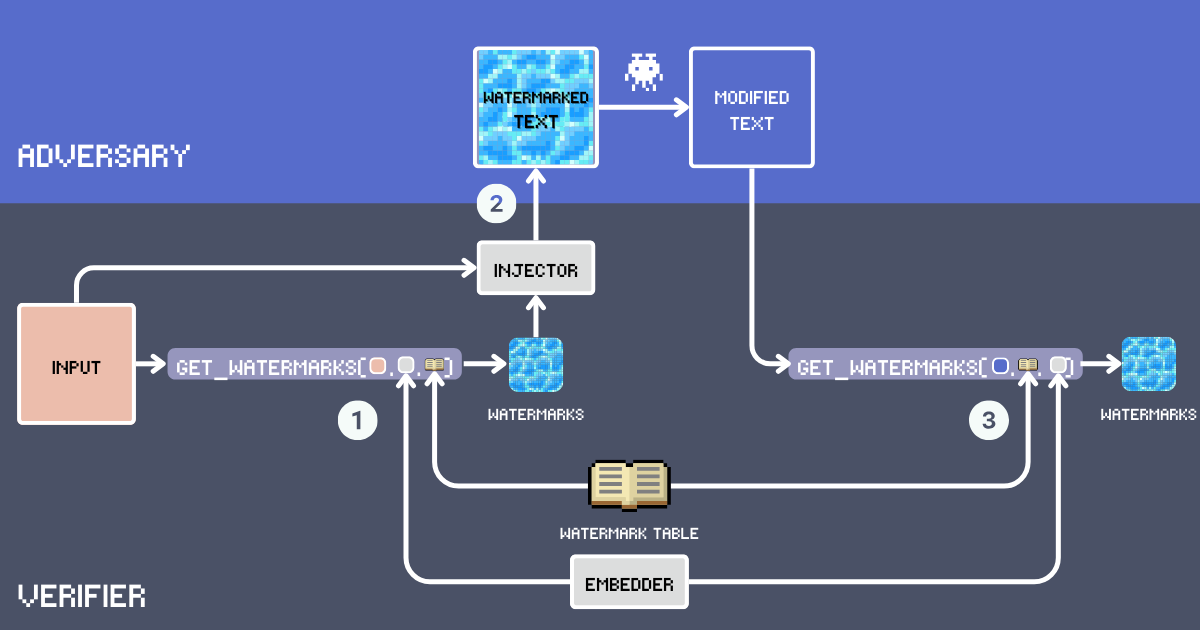
- Input: Il testo originale da marcare con watermark.
- Tabella Watermark: Un lessico segreto contenente parole candidate per il watermark. Per un'efficacia ottimale del watermarking, le parole dovrebbero essere abbastanza comuni da adattarsi naturalmente a vari contesti. Il vocabolario esclude parole funzionali, nomi propri e parole rare che potrebbero sembrare fuori posto, ad esempio
delve into,embarksono buoni candidati mentregoodè troppo comune. Di seguito, costruiremo la nostra WatermarkTable usando parole dal vocabolario inglese avanzato. - Embedder: Un modello di embedding che serve due scopi: seleziona parole semanticamente appropriate dalla
WatermarkTablebasandosi sul testo diinpute aiuta a rilevare watermark in testi potenzialmente parafrasati. Stiamo usando jina-embeddings-v3 perché gestisce bene sia testi molto lunghi che lingue diverse. Questo significa che possiamo marcare documenti lunghi e individuare comunque i copioni anche se traducono il testo. - Watermark: Parole selezionate dalla WatermarkTable calcolando la similarità del coseno tra l'embedding del testo di input e gli embedding nella tabella. Il numero di parole è determinato da un rapporto di inserimento, tipicamente il 12% del conteggio delle parole di input.
- Iniettore: Un LLM che segue istruzioni che integra le parole watermark nel testo di input mantenendo coerenza, accuratezza fattuale, flusso naturale e distribuzione uniforme delle parole watermark nel testo.
- Testo con Watermark: L'output dopo che l'Iniettore ha inserito le parole watermark nell'
input. - Avversario (Furto di Contenuti): Un'entità che tenta di riutilizzare il testo con watermark senza attribuzione, tipicamente attraverso parafrasi, traduzione o modifiche minori. Oggi, questo significa semplicemente usare un LLM sollecitato con
Paraphrase [text]per la riscrittura automatica. - Testo Modificato: Il risultato dopo le modifiche dell'avversario al testo con watermark. Questo è il testo che dobbiamo controllare per i watermark.
tagAlgoritmo


tagConclusione
Da questi esempi, possiamo vedere che la nostra filigrana basata su embedding è piuttosto robusta anche con questa configurazione di base. È particolarmente degno di nota il fatto che le filigrane rimangano rilevabili anche dopo la traduzione. Questa robustezza attraverso le lingue è resa possibile dalle potenti capacità multilingue del modello jina-embeddings-v3; senza forti capacità multilingue e cross-linguistiche, tale persistenza attraverso la traduzione non sarebbe realizzabile.
Ci sono diversi modi per migliorare l'accuratezza e la robustezza di questo sistema di filigrane. In primo luogo, la tabella delle filigrane potrebbe essere espansa e costruita attentamente per garantire la diversità. Questo è importante perché un vocabolario più ampio e diversificato fornisce una migliore copertura degli spazi semantici, rendendo più facile trovare filigrane contestualmente appropriate per qualsiasi testo, riducendo al contempo il rischio di schemi ripetitivi o ovvi.
Il componente Injector potrebbe essere migliorato implementando strategie di inserimento più sofisticate. Ad esempio, potrebbe essere istruito a distribuire le filigrane uniformemente in tutto il testo per mantenere l'impercettibilità. Inoltre, potremmo impiegare la tecnica di late chunking per generare filigrane per singoli segmenti o frasi, permettendo all'Injector di prendere decisioni più sfumate sul posizionamento delle filigrane. Questo aiuterebbe a mantenere sia l'impercettibilità complessiva che la coerenza semantica nel testo finale.
Per i lettori interessati a un'esplorazione più approfondita, "POSTMARK: A Robust Blackbox Watermark for Large Language Models" (Chang et al., EMNLP 2024) presenta un framework completo che include formulazioni matematiche ed esperimenti estesi. Gli autori esplorano sistematicamente la costruzione del vocabolario delle filigrane, le strategie ottimali di inserimento e la robustezza contro vari attacchi. Analizzano inoltre approfonditamente il compromesso tra il rilevamento delle filigrane e la qualità del testo attraverso valutazioni sia automatizzate che umane.
