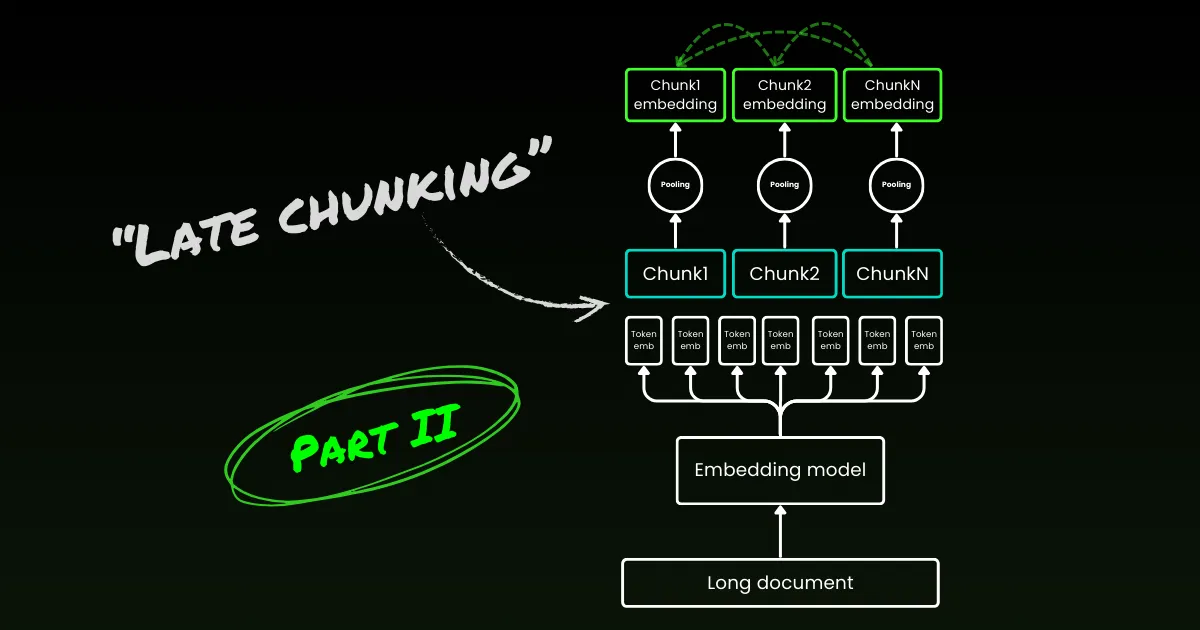

Il chunking di un documento lungo presenta due problemi: primo, determinare i punti di interruzione—ovvero, come segmentare il documento. Si potrebbero considerare lunghezze fisse di token, un numero fisso di frasi, o tecniche più avanzate come regex o modelli di segmentazione semantica. I confini accurati dei chunk non solo migliorano la leggibilità dei risultati di ricerca, ma assicurano anche che i chunk forniti a un LLM in un sistema RAG siano precisi e sufficienti—né più, né meno.
Il secondo problema è la perdita di contesto all'interno di ogni chunk. Una volta che il documento è segmentato, il passo logico successivo per la maggior parte delle persone è incorporare ogni chunk separatamente in un processo batch. Tuttavia, questo porta a una perdita del contesto globale del documento originale. Molti lavori precedenti hanno affrontato prima il primo problema, sostenendo che una migliore rilevazione dei confini migliora la rappresentazione semantica. Per esempio, il "semantic chunking" raggruppa le frasi con alta similarità del coseno nello spazio degli embedding per minimizzare l'interruzione delle unità semantiche.
Dal nostro punto di vista, questi due problemi sono quasi ortogonali e possono essere affrontati separatamente. Se dovessimo dare una priorità, diremmo che il secondo problema è più critico.
| Problema 2: Informazioni contestuali | |||
|---|---|---|---|
| Preservate | Perse | ||
| Problema 1: Punti di interruzione | Buoni | Scenario ideale | Risultati di ricerca scarsi |
| Scarsi | Buoni risultati di ricerca, ma i risultati potrebbero non essere leggibili dall'uomo o per il ragionamento LLM | Scenario peggiore |
tagLate Chunking per la Perdita di Contesto
Il late chunking inizia affrontando il secondo problema: la perdita di contesto. Non riguarda la ricerca dei punti di interruzione ideali o dei confini semantici. È ancora necessario utilizzare regex, euristiche o altre tecniche per dividere un documento lungo in piccoli chunk. Ma invece di incorporare ogni chunk non appena viene segmentato, il late chunking prima codifica l'intero documento in una finestra di contesto (per jina-embeddings-v3 è di 8192 token). Poi, segue gli indizi dei confini per applicare il mean pooling per ogni chunk—da qui il termine "late" nel late chunking.

tagIl Late Chunking è Resiliente agli Indizi di Confine Scarsi
Ciò che è davvero interessante è che gli esperimenti mostrano che il late chunking elimina la necessità di confini semantici perfetti, il che affronta parzialmente il primo problema menzionato sopra. In effetti, il late chunking applicato a confini di token fissi supera il chunking ingenuo con indizi di confine semantici. I modelli di segmentazione semplici, come quelli che utilizzano confini a lunghezza fissa, funzionano alla pari con algoritmi avanzati di rilevamento dei confini quando abbinati al late chunking. Abbiamo testato tre diverse dimensioni di modelli di embedding, e i risultati mostrano che tutti ne beneficiano costantemente attraverso tutti i dataset di test. Detto questo, il modello di embedding stesso rimane il fattore più significativo nelle prestazioni—non c'è un singolo caso in cui un modello più debole con late chunking superi un modello più forte senza di esso.

jina-embeddings-v2-small con indizi di confine a lunghezza di token fissa e chunking ingenuo). Come parte di uno studio di ablazione, abbiamo testato il late chunking con diversi indizi di confine (lunghezza di token fissa, confini di frase e confini semantici) e diversi modelli (jina-embeddings-v2-small, nomic-v1, e jina-embeddings-v3). In base alle loro prestazioni su MTEB, il ranking di questi tre modelli di embedding è: jina-embeddings-v2-small < nomic-v1 < jina-embeddings-v3. Tuttavia, il focus di questo esperimento non è sulla valutazione delle prestazioni dei modelli di embedding in sé, ma sulla comprensione di come un modello di embedding migliore interagisce con il late chunking e gli indicatori di confine. Per i dettagli dell'esperimento, si prega di consultare il nostro paper di ricerca.| Combo | SciFact | NFCorpus | FiQA | TRECCOVID |
|---|---|---|---|---|
| Baseline | 64.2 | 23.5 | 33.3 | 63.4 |
| Late | 66.1 | 30.0 | 33.8 | 64.7 |
| Nomic | 70.7 | 35.3 | 37.0 | 72.9 |
| Jv3 | 71.8 | 35.6 | 46.3 | 73.0 |
| Late + Nomic | 70.6 | 35.3 | 38.3 | 75.0 |
| Late + Jv3 | 73.2 | 36.7 | 47.6 | 77.2 |
| SentBound | 64.7 | 28.3 | 30.4 | 66.5 |
| Late + SentBound | 65.2 | 30.0 | 33.9 | 66.6 |
| Nomic + SentBound | 70.4 | 35.3 | 34.8 | 74.3 |
| Jv3 + SentBound | 71.4 | 35.8 | 43.7 | 72.4 |
| Late + Nomic + SentBound | 70.5 | 35.3 | 36.9 | 76.1 |
| Late + Jv3 + SentBound | 72.4 | 36.6 | 47.6 | 76.2 |
| SemanticBound | 64.3 | 27.4 | 30.3 | 66.2 |
| Late + SemanticBound | 65.0 | 29.3 | 33.7 | 66.3 |
| Nomic + SemanticBound | 70.4 | 35.3 | 34.8 | 74.3 |
| Jv3 + SemanticBound | 71.2 | 36.1 | 44.0 | 74.7 |
| Late + Nomic + SemanticBound | 70.5 | 36.9 | 36.9 | 76.1 |
| Late + Jv3 + SemanticBound | 72.4 | 36.6 | 47.6 | 76.2 |
Nota che essere resistente a confini inadeguati non significa che possiamo ignorarli - sono ancora importanti sia per la leggibilità umana che per gli LLM. Ecco come la vediamo: quando ottimizziamo la segmentazione, cioè il suddetto primo problema, possiamo concentrarci completamente sulla leggibilità senza preoccuparci della perdita di semantica/contesto. Il Late Chunking gestisce i punti di interruzione buoni o cattivi, quindi la leggibilità è l'unica cosa di cui devi preoccuparti.
tagIl Late Chunking è Bidirezionale
Un altro malinteso comune sul late chunking è che i suoi embedding condizionali dei chunk si basino solo sui chunk precedenti senza "guardare avanti". Questo è scorretto. La dipendenza condizionale nel late chunking è in realtà bi-direzionale, non uni-direzionale. Questo perché la matrice di attenzione nel modello di embedding - un transformer solo-encoder - è completamente connessa, a differenza della matrice triangolare mascherata usata nei modelli auto-regressivi. Formalmente, l'embedding del chunk , , piuttosto che , dove denota una fattorizzazione del modello linguistico. Questo spiega anche perché il late chunking non dipende dal posizionamento preciso dei confini.

tagIl Late Chunking Può Essere Addestrato
Il late chunking non richiede ulteriore addestramento per i modelli di embedding. Può essere applicato a qualsiasi modello di embedding a contesto lungo che utilizza il mean pooling, rendendolo molto attraente per i professionisti. Detto questo, se stai lavorando su task come domanda-risposta o recupero query-documento, le prestazioni possono essere ulteriormente migliorate con un po' di fine-tuning. Specificamente, i dati di addestramento consistono in tuple contenenti:
- Una query (ad esempio, una domanda o un termine di ricerca).
- Un documento che contiene informazioni rilevanti per rispondere alla query.
- Uno span rilevante all'interno del documento, che è lo specifico chunk di testo che risponde direttamente alla query.
Il modello viene addestrato accoppiando query con i loro span rilevanti, utilizzando una funzione di perdita contrastiva come InfoNCE. Questo assicura che gli span rilevanti siano strettamente allineati con la query nello spazio degli embedding, mentre gli span non correlati vengono spinti più lontano. Di conseguenza, il modello impara a concentrarsi sulle parti più rilevanti del documento quando genera gli embedding dei chunk. Per maggiori dettagli, si prega di fare riferimento al nostro paper di ricerca.
tagLate Chunking vs. Contextual Retrieval
Poco dopo l'introduzione del late chunking, Anthropic ha introdotto una strategia separata chiamata Contextual Retrieval. Il metodo di Anthropic è un approccio brute-force per affrontare il problema del contesto perso, e funziona come segue:
- Ogni chunk viene inviato all'LLM insieme al documento completo.
- L'LLM aggiunge contesto rilevante a ogni chunk.
- Questo risulta in embedding più ricchi e informativi.
Dal nostro punto di vista, questo è essenzialmente arricchimento del contesto, dove il contesto globale è esplicitamente hardcodato in ogni chunk usando un LLM, che è costoso in termini di costo, tempo e storage. Inoltre, non è chiaro se questo approccio sia resiliente ai confini dei chunk, poiché l'LLM si basa su chunk accurati e leggibili per arricchire efficacemente il contesto. Al contrario, il late chunking è altamente resiliente agli indicatori di confine, come dimostrato sopra. Non richiede storage aggiuntivo poiché la dimensione dell'embedding rimane la stessa. Nonostante sfrutti la lunghezza completa del contesto del modello di embedding, è ancora significativamente più veloce dell'uso di un LLM per generare arricchimento. Nello studio qualitativo del nostro paper di ricerca, mostriamo che il context retrieval di Anthropic ha prestazioni simili al late chunking. Tuttavia, il late chunking fornisce una soluzione più di basso livello, generica e naturale sfruttando le meccaniche intrinseche del transformer solo-encoder.
tagQuali Modelli di Embedding Supportano il Late Chunking?
Il late chunking non è esclusivo di jina-embeddings-v3 o v2. È un approccio abbastanza generico che può essere applicato a qualsiasi modello di embedding a contesto lungo che utilizza il mean pooling. Per esempio, in questo post, mostriamo che anche nomic-v1 lo supporta. Accogliamo calorosamente tutti i fornitori di embedding nell'implementare il supporto per il late chunking nelle loro soluzioni.
Come utente di modelli, quando valuti un nuovo modello di embedding o API, puoi seguire questi passaggi per verificare se potrebbe supportare il late chunking:
- Output Singolo: Il modello/API fornisce un solo embedding finale per frase invece di embedding a livello di token? Se sì, probabilmente non può supportare il late chunking (specialmente per le API web).
- Supporto per Contesti Lunghi: Il modello/API gestisce contesti di almeno 8192 token? Se no, il late chunking non sarà applicabile—o più precisamente, non ha senso adattare il late chunking per un modello con contesto breve. Se sì, assicurati che funzioni effettivamente bene con contesti lunghi, non solo che dichiari di supportarli. Di solito puoi trovare queste informazioni nel report tecnico del modello, come le valutazioni su LongMTEB o altri benchmark per contesti lunghi.
- Mean Pooling: Per i modelli self-hosted o le API che forniscono embedding a livello di token prima del pooling, verifica se il metodo di pooling predefinito è il mean pooling. I modelli che utilizzano CLS o max pooling non sono compatibili con il late chunking.
In sintesi, se un modello di embedding supporta contesti lunghi e utilizza il mean pooling come impostazione predefinita, può facilmente supportare il late chunking. Dai un'occhiata al nostro repository GitHub per dettagli implementativi e ulteriori discussioni.
tagConclusione
Quindi, cos'è il late chunking? Il late chunking è un metodo diretto per generare embedding di chunk utilizzando modelli di embedding per contesti lunghi. È veloce, resiliente ai segnali di confine e altamente efficace. Non è un'euristica o una sovra-ingegnerizzazione—è un design ragionato basato su una profonda comprensione del meccanismo transformer.
Oggi, l'hype che circonda gli LLM è innegabile. In molti casi, problemi che potrebbero essere affrontati efficientemente da modelli più piccoli come BERT vengono invece delegati agli LLM, guidati dal fascino di soluzioni più grandi e complesse. Non sorprende che i grandi fornitori di LLM spingano per una maggiore adozione dei loro modelli, mentre i fornitori di embedding promuovano gli embedding — entrambi stanno giocando sui loro punti di forza commerciali. Ma alla fine, non si tratta di hype, si tratta di azione, di ciò che funziona veramente. Lasciamo che la comunità, l'industria e, soprattutto, il tempo rivelino quale approccio sia veramente più snello, più efficiente e costruito per durare.
Assicurati di leggere il nostro paper di ricerca, e ti incoraggiamo a testare il late chunking in vari scenari e a condividere il tuo feedback con noi.





